The first “official” post of this Polymath project has passed 100 comments, so I think it is time to write a second post. Again I will try to extract some of the useful information from the comments (but not all, and my choice of what to include should not be taken as some kind of judgment). A good way of organizing this post seems to be list a few more methods of construction of interesting union-closed systems that have come up since the last post — where “interesting” ideally means that the system is a counterexample to a conjecture that is not obviously false.
Standard “algebraic” constructions
Quotients
If  is a union-closed family on a ground set
is a union-closed family on a ground set  , and
, and 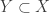 , then we can take the family
, then we can take the family  . The map
. The map  is a homomorphism (in the sense that
is a homomorphism (in the sense that  , so it makes sense to regard
, so it makes sense to regard 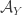 as a quotient of .
as a quotient of .
Subfamilies
If instead we take an equivalence relation  on , we can define a set-system
on , we can define a set-system  to be the set of all unions of equivalence classes that belong to
to be the set of all unions of equivalence classes that belong to  .
.
Thus, subsets of give quotient families and quotient sets of give subfamilies.
Products
Possibly the most obvious product construction of two families and  is to make their ground sets disjoint and then to take
is to make their ground sets disjoint and then to take  . (This is the special case with disjoint ground sets of the construction
. (This is the special case with disjoint ground sets of the construction 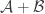 that Tom Eccles discussed earlier.)
that Tom Eccles discussed earlier.)
Note that we could define this product slightly differently by saying that it consists of all pairs 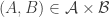 with the “union” operation
with the “union” operation  . This gives an algebraic system called a join semilattice, and it is isomorphic in an obvious sense to with ordinary unions. Looked at this way, it is not so obvious how one should define abundances, because
. This gives an algebraic system called a join semilattice, and it is isomorphic in an obvious sense to with ordinary unions. Looked at this way, it is not so obvious how one should define abundances, because 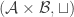 does not have a ground set. Of course, we can define them via the isomorphism to but it would be nice to do so more intrinsically.
does not have a ground set. Of course, we can define them via the isomorphism to but it would be nice to do so more intrinsically.
(more…)
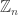





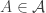 and then a random element
and then a random element  .
. 