If I were writing a textbook, I would have discussed the basics of functions before talking about injections and surjections, but this is not a textbook — it is a series of blog posts that provide a kind of commentary on some of the lecture courses. However, now that I have got on to the subject of functions, it probably makes sense to discuss them a bit more, especially as I hear that they have made an appearance in Numbers and Sets.
Let me start with the most basic question of all: what is a function? This is one of the first examples (of many, unfortunately) of a concept that you were probably reasonably happy with until your lecturer explained it to you. This is absolutely not a criticism of your lecturer (who is excellent, by the way). It’s more like a criticism of an entire mathematical tradition that goes back to the days when the foundations were laid for our subject in terms of set theory.
Let’s have some examples of functions. The ones you are likely to have come across are ones that take real numbers to real numbers: things like 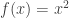 ,
,  or
or  . If someone asked, “Yes, but what are
. If someone asked, “Yes, but what are 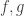 and
and  ?” then an appropriate response might be, “Well,
?” then an appropriate response might be, “Well,  is the result of doing something to
is the result of doing something to  that turns it into another real number.”
that turns it into another real number.”
Notice that in that last sentence I slightly avoided the issue. I didn’t say what  itself was — I just said what was. (It’s another real number.) Notice also that for a specific function we don’t feel quite as tempted to ask what it really is: we don’t say, “What is squared?” That’s because “squared” isn’t a noun, so it feels wrong to imagine that it must be a thing, just as you would expect strange looks if you went around asking, “What is and?” (That’s not to say that an answer isn’t possible: one could say that AND is a logical connective, and a logical connective is something that joins two statements to form a new statement, and it could, if you wanted, be regarded as a function from the set of all pairs of statements to the set of all statements, etc. etc.)
itself was — I just said what was. (It’s another real number.) Notice also that for a specific function we don’t feel quite as tempted to ask what it really is: we don’t say, “What is squared?” That’s because “squared” isn’t a noun, so it feels wrong to imagine that it must be a thing, just as you would expect strange looks if you went around asking, “What is and?” (That’s not to say that an answer isn’t possible: one could say that AND is a logical connective, and a logical connective is something that joins two statements to form a new statement, and it could, if you wanted, be regarded as a function from the set of all pairs of statements to the set of all statements, etc. etc.)
What really matters about a function is not so much its essence as the following fact.
If is a function from  to
to  and is an element of , then is an element of .
and is an element of , then is an element of .
Given a function 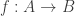 , we can define a natural notion of the graph of that function. It is the set of all points
, we can define a natural notion of the graph of that function. It is the set of all points 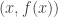 such that
such that  . To put it another way, it is the set of all points
. To put it another way, it is the set of all points  such that
such that 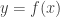 . This set has the property (discussed in the previous post) that for every there is exactly one
. This set has the property (discussed in the previous post) that for every there is exactly one  such that
such that  belongs to the graph of .
belongs to the graph of .
And now the officially correct thing to do is to turn everything on its head and make the following definition.
Let and be sets. A function from to is a subset of 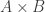 such that for every there is exactly one such that
such that for every there is exactly one such that  .
.
Then one goes on to say that it is traditional to write instead of . Equivalently, we define to be the unique  such that .
such that .
Why does anyone bother with this strange definition? One reason is that we sometimes want to talk about the set of all functions from to , or, even more commonly, the set of all functions from to that satisfy certain conditions. It’s one thing to be able to recognise a function when you see one, but how do you say what counts as a function? We somehow want to capture the idea that any way of associating with each some counts as a function, even if that “way of associating” isn’t given by a rule of any kind.
It may seem as though the “take any old subset of as long as for each there’s exactly one such that belongs to that subset” is a pretty neat way of capturing this arbitrariness. And in a sense it is. I think psychologically we are happier with the idea of a completely arbitrary set than we are with the idea of a completely arbitrary “way of associating” elements of one set with elements of another. But just because we are happier with it, that doesn’t mean we should be happier with it. What is an “arbitrary” set of integers, say? Sets of integers defined by properties such as “the set of all  such that is a prime greater than 1000″ are fine, but how can we capture the idea of a “completely arbitrary” set of integers that doesn’t have a definition of that kind? It’s more or less the same problem as that of capturing the idea of a completely arbitrary function that isn’t given by a rule. So, I respectfully submit, the subset-of-Cartesian-product definition of functions achieves virtually nothing.
such that is a prime greater than 1000″ are fine, but how can we capture the idea of a “completely arbitrary” set of integers that doesn’t have a definition of that kind? It’s more or less the same problem as that of capturing the idea of a completely arbitrary function that isn’t given by a rule. So, I respectfully submit, the subset-of-Cartesian-product definition of functions achieves virtually nothing.
That will probably provoke a lot of disagreement, so let me qualify it slightly. It is useful for some purposes to “reduce everything to sets”. If I am working on the foundations of mathematics and I show that every statement to do with functions can be translated into an equivalent statement to do with sets, then I have shown that if I can sort sets out then I don’t have to do any further work to sort out functions as well. But in what one might call “everyday mathematics” I think that the definition of functions in terms of subsets of Cartesian products is of no use whatsoever.
Hmm, I’m worried that I’m still exaggerating. Let me consider a statement that might make it seem important to answer the question, “What is a function?” It is the following.
There are uncountably many functions from  to .
to .
You haven’t yet been told what this means, but for now just think of “uncountably many” as meaning “not just infinitely many but an extra-specially big infinitely many” or something like that. We obviously can’t prove a statement like that by listing a whole bunch of functions, so doesn’t that force us to have some general idea of what a function is?
Here are two arguments that it doesn’t. One is that I can prove this by reducing it to another problem. For each positive real number  I can define
I can define 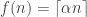 (this means the smallest integer greater than
(this means the smallest integer greater than 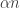 ). It’s easy to check that these are all different functions. And then we can appeal to the fact that there are uncountably many positive real numbers.
). It’s easy to check that these are all different functions. And then we can appeal to the fact that there are uncountably many positive real numbers.
The second argument is closely related. It is also true that there are uncountably many subsets of , but nobody feels that we have to say what a subset of is in order to make sense of this statement. We just need to know a few rules for dealing with sets: in particular, for defining new sets out of old ones.
Just before I move on, let me express particular distaste for any definition that begins, “A function from to is a relation such that …” I absolutely hate this. The reason I hate it is that functions and relations are, to any reasonable person, different kinds of things, except that I don’t want to call them things at all, so what I really mean is that they have a different grammar.
To illustrate what I mean by grammar, it’s rules like this.
1. If and denotes an element of , then denotes an element of .
2. If  and
and  denote statements, then
denote statements, then  denotes a statement.
denotes a statement.
3. If 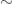 is a relation on , is an element of , and is an element of , then
is a relation on , is an element of , and is an element of , then 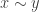 is a statement.
is a statement.
4. If is a property defined on a set  and
and  , then
, then  is a statement.
is a statement.
5. If is a property defined on a set , then  is a subset of .
is a subset of .
I’ll talk more about this kind of thing in a later post, but I hope these examples give you the idea. And 1 and 3 demonstrate that the grammar of functions is not the same as the grammar of relations. The fact that you can turn them into equivalent concepts that do have the same grammar is neither here nor there. You can do that with nouns and adjectives too. For example, I could decide that from now on I’m going to say, “There’s a red” where I used to say, “That’s red.” If I wanted to say, “My car is green,” I would say, “My car is a green,” just as I might say, “That dog is a Rottweiler.” It would be possible (basically, nouns and adjectives are both ways of picking out some subset of the set of all possible objects in the world) — but it would also be a bit weird.
But none of this what I really wanted to talk about. Rather, I wanted to discuss a few confusing bits of terminology.
To begin with, what are domains, ranges and codomains? What’s confusing about this is that there isn’t a standard terminology. The one I was taught as an undergraduate was this. If is a function, then is called the domain of and is called the range of . That’s the sense in which I’ve been using the words in these posts and I hope it agrees with what your lecturers have said.
However, some people use the word “codomain” for instead of “range”. Worse still (from the point of view of communication between mathematicians), people who call the codomain often use the word “range” to refer to the set of values taken by : that is, to the set 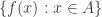 . I call that the image of , and I think that is probably the Cambridge standard.
. I call that the image of , and I think that is probably the Cambridge standard.
To give an example, let’s take the function 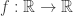 defined by . In my terminology, the domain and range are both
defined by . In my terminology, the domain and range are both  and the image is the set of non-negative real numbers. I’m also happy to call the codomain if you want — for me, “codomain” and “range” mean the same thing.
and the image is the set of non-negative real numbers. I’m also happy to call the codomain if you want — for me, “codomain” and “range” mean the same thing.
However, some people would say that the domain and codomain are while the range is the set of non-negative reals. I think they would regard “range” as synonymous with “image”.
So I suppose we would all get along fine if we just abolished the word “range”.
Unfortunately, that isn’t the end of the confusion, since some people use the word “domain” to mean “set of points where makes sense”. To give an example, they might say this: “Let us define by  . Then the domain of is the set of all real numbers apart from
. Then the domain of is the set of all real numbers apart from  and
and 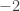 .” Apparently, this use of the word “domain” is quite common in schools. According to my terminology, the function just defined was not a function from to at all. Why not? Because it doesn’t assign a real number to 0 or to -2.
.” Apparently, this use of the word “domain” is quite common in schools. According to my terminology, the function just defined was not a function from to at all. Why not? Because it doesn’t assign a real number to 0 or to -2.
So if you want to be safe, then given a function you can call the domain, the codomain, and the image.
That is still not the end of the potential confusion. I said earlier that the one thing you need to know about a function is that if is an element of then is an element of . In a nice friendly world, you could deduce that whenever you see  , then whatever
, then whatever 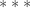 is must be an element of . Unfortunately that’s not the case in the world we actually inhabit: we often write
is must be an element of . Unfortunately that’s not the case in the world we actually inhabit: we often write 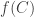 when
when  is a subset of .
is a subset of .
Now in a sense that’s just plain incorrect. Functions from to are little machines that turn elements of into elements of . So how can we write if is a subset of ? The answer is that the wrongness of doing that tells us one of two things:
(i) the writer has made a mistake;
(ii) the writer means something different.
You should have enough confidence in your lecturers and textbooks to assume that it is (ii) that holds and not (i). So what does mean? It means the set of all such that  , or in symbols
, or in symbols  . For example, if is the function from to that takes to
. For example, if is the function from to that takes to  and
and  is the set of all even numbers, then
is the set of all even numbers, then  . The set is a subset of and it is called the image of .
. The set is a subset of and it is called the image of .
The alarm bells should be ringing again. Earlier, I defined the image of to be the set , which we now see that we can write as 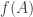 . So is the set the image of (as I said earlier) or the image of (as would be consistent with the more recent definition)? You just have to be alert to the context. Functions have images, but if you’re talking about a given function that’s clear from the context, then you also talk about images of subsets. Oh, and while we’re at it, if is an element of , then is called the image of .
. So is the set the image of (as I said earlier) or the image of (as would be consistent with the more recent definition)? You just have to be alert to the context. Functions have images, but if you’re talking about a given function that’s clear from the context, then you also talk about images of subsets. Oh, and while we’re at it, if is an element of , then is called the image of .
There is nothing for it but to get used to the fact that the same words and notation can be used for concepts with different — and confusable — meanings. If you see , then one of the first things you should do is look at what’s in those brackets and ask yourself what kind of object it is. If it’s an element of the domain (which will usually be indicated by a lower-case letter, which helps to reduce the confusion), then what you’ve got is an element of the codomain. If it’s a subset of the domain, then what you’ve got is a subset of the codomain.
Let me give a different example of this kind of use of “element notation applied to subsets”. If and are sets of integers, we sometimes write 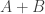 . You might object that this cannot be correct, on the grounds that and are sets and you don’t add sets together — you take things like unions and intersections. And that objection is right in the following sense: when we write we are not giving the usual meaning to the plus symbol. So what do we mean? We actually mean something fairly natural, which is the set of all numbers you can make by adding something in to something in . In symbols,
. You might object that this cannot be correct, on the grounds that and are sets and you don’t add sets together — you take things like unions and intersections. And that objection is right in the following sense: when we write we are not giving the usual meaning to the plus symbol. So what do we mean? We actually mean something fairly natural, which is the set of all numbers you can make by adding something in to something in . In symbols,  .
.
A quick example: if 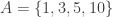 and
and  , then
, then  . Here, I’m not really adding sets: I’m adding the elements and forming a set out of all possible results. In a similar way, when I take the set , I’m not applying the function to the set : I’m applying to the elements of and forming a set out of all possible results. It’s a very important distinction.
. Here, I’m not really adding sets: I’m adding the elements and forming a set out of all possible results. In a similar way, when I take the set , I’m not applying the function to the set : I’m applying to the elements of and forming a set out of all possible results. It’s a very important distinction.
I’ve said that if and is an element of , then is called the image of . Something similar happens the other way round. If 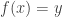 , then is called a preimage of . Note a very important distinction between these two definitions: I talked about the image but a preimage. That’s because the definition of a function requires there to be exactly one image for each element , but if I pick it might not have any preimages, and it might have more than one preimage.
, then is called a preimage of . Note a very important distinction between these two definitions: I talked about the image but a preimage. That’s because the definition of a function requires there to be exactly one image for each element , but if I pick it might not have any preimages, and it might have more than one preimage.
Finally, a rare situation where we don’t use the same word twice — however, we make up for this big time in our choice of symbolic notation. If we have a subset  of , then the inverse image of , denoted
of , then the inverse image of , denoted  , is defined to be the set of all preimages of elements of . Equivalently, it is the set of all such that
, is defined to be the set of all preimages of elements of . Equivalently, it is the set of all such that  . Equivalently again, it is the set
. Equivalently again, it is the set 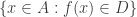 .
.
Here’s a quick example. Let  , let
, let 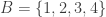 and define as follows:
and define as follows:  . Then the inverse image of the set
. Then the inverse image of the set  is
is  . Why? Because 1 and 2 are the elements of that have images that belong to the set .
. Why? Because 1 and 2 are the elements of that have images that belong to the set .
I hope you will have noticed something very important about that example, which is that the function in question does not have an inverse. In fact, it doesn’t even come close: the fact that  shows that it isn’t an injection (which means that if we tried to form an inverse
shows that it isn’t an injection (which means that if we tried to form an inverse  we wouldn’t be able to decide between setting
we wouldn’t be able to decide between setting 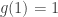 and
and  ) and the fact that 4 has no preimage shows that it isn’t a surjection either (we would have no idea what value to give to
) and the fact that 4 has no preimage shows that it isn’t a surjection either (we would have no idea what value to give to  ). And yet, I happily wrote
). And yet, I happily wrote 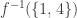 . (Actually, I didn’t write it, but I’m writing it now. And I’m happy.)
. (Actually, I didn’t write it, but I’m writing it now. And I’m happy.)
This is a very frequent source of confusion. Generation after generation of Cambridge undergraduates see an expression like and conclude, wrongly but not entirely unreasonably, that has an inverse. Indeed, it looks as though it must mean the image of under the inverse function of . But it doesn’t (except that if does happen to have an inverse, then does happen to be the image of under that inverse).
The best I can do to help you with understanding inverse images of sets is this. If you ever see a sentence of the form 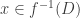 , then you are at liberty to translate it into the equivalent but more transparent sentence . What’s more, I recommend doing so.
, then you are at liberty to translate it into the equivalent but more transparent sentence . What’s more, I recommend doing so.
Suppose, for example, that you are asked to prove the following simple fact. (At least, it’s very simple once you are used to the definitions and to standard techniques for writing proofs.)
Fact. Let and  be sets and let
be sets and let 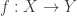 . Let be a subset of and be a subset of . Prove that
. Let be a subset of and be a subset of . Prove that  if and only if
if and only if  .
.
If you’re asked to prove an if and only if, then you start by assuming one side and deducing the other, and then you prove the implication in the opposite direction. So let’s begin by assuming that . What do we need to prove? We want to show that . How do we show something like that? If you’ve learnt the definition of “is a subset of”, then you will call up to the front of your brain the following statement as what we want to prove.
For every ,  .
.
And if you have taken on board advice in the post on injections and surjections, you will now immediately write “Let .” The task is now to prove that .
Aha! That is a sentence of exactly the form that allows us to get rid of that nasty and confusing 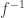 , since it is equivalent to the statement
, since it is equivalent to the statement 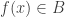 . So we know that and we want to prove that . What were we given? Oh yes, that . But , so
. So we know that and we want to prove that . What were we given? Oh yes, that . But , so 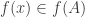 . But if and , it follows (directly from the definition of “is a subset of”) that , just as we wanted.
. But if and , it follows (directly from the definition of “is a subset of”) that , just as we wanted.
How about the other direction? This time we assume that and we want to prove that . So we want to prove that every element of is an element of . But every element of is of the form for some , so we can begin with, “Let ,” and know that our target is to prove that . (This is a slight elaboration of the “let” trick that is convenient for dealing with a situation where what we are sort of saying is, “For every with , such-and-such happens.”) We know that , and that and the hypothesis that tell us that .
Aha! We can get rid of that nasty and confusing : we now know that . Better still, that’s exactly what we were trying to prove.
Just in case I haven’t made it sufficiently clear, if , and , then it is incorrect to say that is an inverse image of (it is a preimage) and it is incorrect to write  (the function might not have an inverse, and if it doesn’t, then
(the function might not have an inverse, and if it doesn’t, then 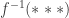 makes sense only if is a subset of the codomain of ). Similarly, if is a subset of then is not a preimage, or even the preimage, of (it is the inverse image). And the fact that we write does not mean that has an inverse.
makes sense only if is a subset of the codomain of ). Similarly, if is a subset of then is not a preimage, or even the preimage, of (it is the inverse image). And the fact that we write does not mean that has an inverse.
It only remains for me to apologize on behalf of the mathematical community for the historical accidents that have led to this jumble of overlapping terminology and notation. You have no choice but to learn it and be very careful about using it. The one thing I would say is that one gets used to it — so much so that it becomes hard to remember what it was like to find it confusing.
That reminds me that I haven’t finished discussing non-standardness of terminology to do with functions. You will often see the following alternative terminology for injections, surjections and bijections. Injections are called one-to-one functions, surjections are called onto functions, and bijections are called one-to-one correspondences. This terminology is pretty confusing –see Terence Tao’s comment on one-to-one functions — but you probably have to learn it too.
I’m mentioning this here because I want to recommend another of the quizzes, the one on functions. If you aren’t quite sure whether you have understood the material in this post and the previous one (and what your lecturers have said on similar topics), then trying out that quiz will soon tell you how you are doing. But it uses “one-to one function”, “onto function” and “one-to-one correspondence” instead of “injection”, “surjection” and “bijection”, so you’ll need to be ready to use that terminology.
Added later. I received an email from Imre Leader expressing disagreement with my assertion that the set-theoretic definition of functions achieves nothing. Since he had some valid points to make, and since we ended up agreeing with each other completely (I think), I’d like to report on our exchange.
Imre’s point is that, as I said above, people just are more comfortable with the idea of an arbitrary set not defined by a nice property than they are with the idea of an arbitrary function not defined by a nice rule. I maintain that this is irrational, but even if it is, I can’t deny that it is true. So if you give the set-theoretic definition of functions, then you make completely clear that functions can be just as arbitrary as sets.
My eventual response (after a certain amount of thought, and an email that Imre disagreed with in a number of places) was that I agreed that the set-theoretic definition of functions helps one to understand how arbitrary functions can be, but that that benefit can be achieved in a different and better way. Instead of saying that a function from to is a subset of such that for every there is exactly one such that , we should say that every function can be obtained from such a set. It turns out that Imre is entirely happy with that idea. (Also, he was at pains to stress that he is no fonder of turning everything into sets than I am.)
Here in detail is what I would say. Let  (to stand for “graph”) be a subset of such that for every there is exactly one with
(to stand for “graph”) be a subset of such that for every there is exactly one with  . Then we can define a function in terms of by letting be the unique such that . Moreover, every function from to can be obtained this way, since if is such a function we can define to be the set of all such that .
. Then we can define a function in terms of by letting be the unique such that . Moreover, every function from to can be obtained this way, since if is such a function we can define to be the set of all such that .
What I like about this approach is that it doesn’t feel unnecessarily paradoxical. I’m not saying, “Actually a function isn’t a function at all — it’s a funny kind of set.” Rather, I’m saying that there’s a one-to-one correspondence between functions and funny kinds of sets. This captures the arbitrariness of functions (if you believe that sets can be very arbitrary, then you can carry this arbitrariness over to functions), but it also preserves their function-like nature (given a set with certain properties, I then tell you a rule for associating elements of with elements of ).
This entry was posted on October 13, 2011 at 4:35 pm and is filed under Cambridge teaching, General concepts. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

October 13, 2011 at 5:45 pm |
I sympathize with your concerns about defining functions as relations, but I don’t think it’s completely fair to say that functions and relations don’t have the same grammar. After all, there is a category of sets and relations, and morphisms can be composed as usual in this category, and the category of sets and functions is a subcategory of this category, and so forth. What’s new about the category of relations, I guess, is that one can also define daggers (transposes) of relations.
October 13, 2011 at 6:11 pm
Perhaps what I ought to have said more clearly is that the standard examples of functions (things like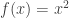 ) and the standard examples of relations (things like “is congruent mod
) and the standard examples of relations (things like “is congruent mod  to”) have different grammar. One converts elements of one set into elements of another, and the other goes between elements of two (usually equal) sets and produces a statement. It’s certainly possible to conceive of ways of talking about relations that make them feel much more function-like, and in some contexts (particularly, as I’ve discussed in the comments on a different post, when one is checking that a function is well-defined), I think there might even be some benefit in doing so.
to”) have different grammar. One converts elements of one set into elements of another, and the other goes between elements of two (usually equal) sets and produces a statement. It’s certainly possible to conceive of ways of talking about relations that make them feel much more function-like, and in some contexts (particularly, as I’ve discussed in the comments on a different post, when one is checking that a function is well-defined), I think there might even be some benefit in doing so.
October 13, 2011 at 7:25 pm
And conversely I think it’s beneficial at times to think about functions in a way that is more relation-like. For example, here’s a small observation. Abstractly, the inverse image construction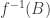 you describe in the post is a contravariant corepresentable functor
you describe in the post is a contravariant corepresentable functor  from the category of sets and functions to itself (or the category of Boolean algebras, etc.). The image construction
from the category of sets and functions to itself (or the category of Boolean algebras, etc.). The image construction 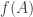 you describe is a covariant functor, but it isn’t representable in the category of sets and functions by a straightforward cardinality argument. It is, however, representable in the category of sets and relations, by
you describe is a covariant functor, but it isn’t representable in the category of sets and functions by a straightforward cardinality argument. It is, however, representable in the category of sets and relations, by  !
!
In fact inverse image and image for functions is a special case of inverse image and image for relations, which are related by transposition. Defining these constructions for functions only is, in a sense, breaking a natural symmetry.
October 14, 2011 at 12:16 am
My basic rule of thumb to determine whether an object X is “truly” a set, as opposed to merely being modeled or represented by a set, is to ask oneself whether a statement such as “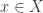 ” could conceivably be useful for doing mathematics; similarly, I would only view
” could conceivably be useful for doing mathematics; similarly, I would only view  as “truly” being a relation if sentences such as “
as “truly” being a relation if sentences such as “ ” could be viewed as useful mathematical statements.
” could be viewed as useful mathematical statements.
For instance, I do not consider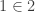 to be a useful statement, so I do not view the numbers 1 and 2 to be “equal” to sets such as the von Neumann ordinals
to be a useful statement, so I do not view the numbers 1 and 2 to be “equal” to sets such as the von Neumann ordinals 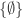 or
or 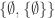 , instead viewing the latter merely as one possible model or representation of the former. Similarly, “
, instead viewing the latter merely as one possible model or representation of the former. Similarly, “ ” and “
” and “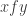 ” do not seem like a useful mathematical sentence to me if
” do not seem like a useful mathematical sentence to me if  is a function, so I do not view functions as “truly” equal to sets or relations, but instead merely being represented by them.
is a function, so I do not view functions as “truly” equal to sets or relations, but instead merely being represented by them.
In practice, these distinctions generally quite irrelevant, but occasionally it can be useful to maintain the distinction between a mathematical object and its representations, in order to be able to generalise the former in the absence of the latter. For instance, generalised functions such as distributions do not have any reasonable interpretations as sets or relations (at least, not in a fashion that recognisably corresponds to the analogous interpretations of classical functions), yet they still do many of the things that classical functions do (e.g. one can take linear combinations of generalised functions, limits of generalised functions, etc.). So this is one instance in which a dogmatic insistence that functions “are” sets or relations can get in the way of useful mathematical generalisation.
October 16, 2011 at 8:09 pm
I think functions as they are used in mathematical practice have a much more dynamic shape than relations and abstract sets. They have a strong directionality that suggests an irreversible process done by a machine, or perhaps the woes of time evolution. This is one reason why it may seem wrong to say that functions are relations or sets, but it seems okay to say that functions can be encoded as relations or sets.
The notion of function as set seems to be an artifact of a historical choice of foundations of mathematics. One could conceivably hatch an alternative, more computationally oriented foundation like a lambda calculus, where one does the same everyday mathematics, but where functions and processes are more primitive than sets and relations.
October 13, 2011 at 6:49 pm |
The “domain of a function not defined everywhere” can actually be called coimage.
For 1/x as a (pre)function from R to R in the category of sets (with morphisms relations with at most one output per input), the coimage is R^* -up to bijection.
October 13, 2011 at 7:18 pm
Actually what I write is wrong according to standard terminology, coimage as I used it would only coincide with the category theory concept for injective (pre)functions. (Coimage is ok for 1/x, but not for 1/x^2 for instance.)
October 13, 2011 at 8:12 pm |
I’m sure I’ve seen ‘preimage’ used to mean what you call the ‘inverse image’. The word ‘fibre’/’fiber’ is also popular in certain circles, though perhaps this means something more sophisticated than ‘inverse image’.
October 14, 2011 at 12:34 am |
I am enjoying these posts a lot. I wonder if you have encountered as much difficulty teaching “codomain” as I have. In my experience it is something of a pons asinorum for students in abstract mathematics: either they internalize it more or less immediately, or they never do. It presents many pedagogical difficulties.
One is that much of our intuition for functions— and most use of functions outside of pure mathematics— simply does not require a precise choice of codomain. It’s quite common to have a definite, fixed choice of domain and something you want to do on it, but no fixed idea (or perhaps several distinct fixed ideas) of how you want to regard the result. Anybody who has ever worked with with a strongly typed programming language has, sooner or later, run up against a reminder that our pure-mathematics function concept contains just a little bit more structure than our intuition seems to want it to have.
A second issue is that for many purposes the choice of codomain is arbitrary, subject to the restriction that it be a set containing all of the values f(x), for x in the domain. This is reflected in the “a function is a set of ordered pairs” definition, which popular in textbooks, despite the fact that it does not encode the codomain concept at all. By this definition, for example, the squaring function from real numbers to real numbers, is the same as the squaring function from real numbers to nonnegative real numbers. In many contexts this is innocuous or even desirable, for more or less the same reasons that the non-strict behavior of non-strongly-typed programming languages is innocuous or desirable. In other contexts this is unwanted— for example, textbooks using this definition of “function” will still insist on a difference between my examples, because one is surjective and the other isn’t. But the fact that this difference is not actually encoded in the definition is not that commonly noticed. For the reason, I’d say, that a lot of the time it just doesn’t matter. (And not encoding the difference serves a small but useful pedagogical purpose. I’m not sure that students have a better time with functions if, on the first go-round, they learned “functions are sets” not with the graph, but with an ordered triple consisting of two sets and then the graph. This draws almost too much attention to the arbitrary choices made in modeling mathematics within set theory.)
The arbitrariness of the codomain seems related in my mind to the general idea that often we want to identify sets with sets containing those sets, whenever doing so simplifies the discussion and suppresses irrelevant choices in formalism. (A positive-integer-valued function is a real-valued function is a complex-valued function…) It takes experience and sensitivity to context— the context in which a function is being used, not just the context inherent in the definition of the function concept— to understand when the choice of codomain really matters and is not just an irrelevant choice of formalism.
So: when teaching the subject, one is in the awkward position of drawing a useful technical distinction— between the image of a function and the function that the set is “to”— but then following this immediately with examples showing that the choice of the object that resolves this distinction is sometimes arbitrary, and sometimes crucially important. The best I have been able to do with teaching it, is to emphasize that the codomain is not really something intuitive, but extra structure we add to the intuition, to have useful notions available to us when we need them.
October 14, 2011 at 7:58 am |
The way you defined “functions from A to B” in this post, you very deftly ducked under a very common problem.
When “function” is naively defined as “set of pairs with the single-valued property”, then what you call the range (and what some call the codomain) becomes non-well-defined.
For instance, using that naive definition, if I say f:R->R is defined by f(x)=x^2; and if I see g:R->[0,infty) is defined by g(x)=x^2; then f and g are actually the same set, and so if range/codomain could be well-defined, f and g would have to have the same one.
Of course, the category theorists get around this by defining a function to be (say) a triple (f,A,B) where A and B are sets and f is what you’ve defined here as “a function from A to B”.
October 14, 2011 at 8:07 am
That was in fact deliberate. It was pointed out to me a year or two ago, and CD also mentions this above, that many textbooks get the definition of function wrong (or at any rate are inconsistent about it) and I wanted to be careful to avoid that mistake but without drawing attention to it too much.
November 8, 2011 at 6:56 pm
I always find this worrying: morally speaking, should a function “know” what its codomain is? The category theory approach certainly solves that one, but it doesn’t seem to be a common approach when introducing functions.
So, is the category theory approach the “right” one? If so, what would happen if we did try to teach that ordered triple version to starting undergraduates. CD says he isn’t sure this would be helpful. Has anyone tried it?
If we do try it, we would have to warn students that they will find variants on this definition in many books.
The “officially correct” definition in the original post says “A function from A to B is [a set of ordered pairs with certain properties] …”. Isn’t this in fact the “wrong” definition found in many textbooks, or is there a subtle difference, based on context, that I am missing?
The “officially correct” definition is, of course, the one I was taught as an undergraduate, and which I have always worked with, but subject to the concerns expressed above.
Joel
October 14, 2011 at 8:04 am |
From my topology teacher I adopted the square bracket notation for images and preimages of sets: \(f[A]\) and \(f^{-1}[A]\), respectively. Though it gets messy if A is an interval and written as such …
October 14, 2011 at 9:24 pm
Some textbooks call attention to the difference by decorating the f (e.g. if f is a function from A to B, then f^* is the function from the power set of A to the power set of B induced by f in the usual way). This convention has a lot to recommend it— among other things, it is not just a notational choice, but is functorial, and a subconscious introduction to the idea of a functor. And it allows one to enforce completely rigid interpretation of notation at an educational stage when some students might abuse and over-generalize the apparent flexibility of being able to write both f(element of domain) and f(subset of domain).
On the downside, there is no standardized notation for the induced function on power sets— the standard is to write both f(x) and f(A)— and to any extent that confusion is avoided by not doing the standard thing, it is only postponed to the moment when students meet somebody who does do the standard thing.
October 14, 2011 at 2:51 pm |
In my own personal notes, I *always* use “into” for injections, in contrast with “onto”. For example: Stereographically project the plane into the sphere.
I haven’t quite convinced myself to use “unto” for bijections, though. (Map unto others as you would have them map unto you.)
October 18, 2011 at 7:28 pm |
From my vantage point in computer science, the underlying message of this post seems to be that the language of ordinary mathematics is a _typed_ language, and that the habitual tendency of mathematicians not to explain explicitly what the typing rules are, or even acknowledge that they exist, engenders confusion and mistakes.
Expressing everything as sets is well and good for foundational purposes, but to insist that everything else is merely abbreviations for set-theoretical constructions amounts to denying every shred of intuition about what we’re doing — even though one often _cannot_ get from the symbols actually on the paper to their purportedly “real” set-theoretic meaning without knowing a lot of mostly unspoken rules of the subject area. It feels to me like insisting that all computer programming is just about bit patterns, so all the careful abstractions one builds when constructing a program are merely convenient (and ultimately irrelevant) abbreviations for particular bit manipulations. That’s just no way to get work done.
There’s a large and refined body of work in computer science on how to design and describe rules like the ones explained in this post such in a rigorous and unambiguous, yet expressive and flexible, way. We do it in the context of programming languages, but that’s really just a constructive subset of mathematics, and easily extended to cover all of it. I’ve often wondered why mathematicians are not eagerly making use of these ideas to simplify and structure the exposition of mathematics.
(Perhaps types got a bad rap after Russell’s theory of types turned out to be insufferably cumbersome to use relative to Zermelo’s untyped set theory? But that’s ignoring a century of later developments, where at least the last few decades have been keenly focused on practical convenience because programming languages are _tools_ rather than abstract objects of study).
In a well-developed typeful formulation of mathematics, I expect that one would define “function from A to B” just as an abstract type with certain axiomatic properties, and then use the set-of-pairs definition simply as a “reference implementation”, serving as an existence proof which guarantees that the concept makes sense and is safe to use.
October 18, 2011 at 7:57 pm
I’m glad someone said something about typing. Ever since I attempted to teach myself Haskell, I’ve thought that a typed foundation of mathematics would be both easier to learn and ultimately more faithful to mathematical practice, and I often wonder why more mathematicians aren’t trying to write one down (or if they have, why I haven’t heard about it).
October 18, 2011 at 9:20 pm
Well, mainstream mathematics certainly has categories, which are very type-friendly (cf. also their philosophy that equality between objects is “evil” and should be replaced by isomorphism whenever possible). I would imagine therefore that category theoretic foundations of mathematics (such as ETCS) would be quite amenable to typing, but I am not an expert on these matters.
In any event, once one moves away from foundations, I think most practicing mathematicians use some sort of informal typing when they discuss or do mathematics. For instance, I doubt mathematicians view a real number as an equivalence class of Cauchy sequences or as a Dedekind cut when manipulating such numbers.
October 18, 2011 at 11:57 pm
I completely agree with this. In fact, I’ve been planning a post about parsing mathematical sentences, which will emphasize this point.
October 19, 2011 at 1:00 pm
“I’ve often wondered why mathematicians are not eagerly making use of these ideas to simplify and structure the exposition of mathematics.”
Good point. We do mathematics bottom-up in assembly language and should then present it top-down in some object oriented frame using information hiding, inheritance, polymorphism aso. I think, from all these concepts ‘top-down’ seems to be the hardest to achieve.
October 19, 2011 at 9:44 pm
Terrence: the problem with category theory is that while it can express a lot of mathematics, to do so it translates everything into its own language and henceforth it is something completely different.
Uwe, I have trouble discerning whether you’re being sarcastic. The goal of the program I’m imagining (which already makes it sound rather more grandiose than I think it should) would not be the recast mathematics in the mold of software development, but to vindicate the way everyday mathematics _already_ uses formulas. The most important thing to borrow from computer science might be a vocabulary for _describing_ systematically what must surely look to newcomers like an endless parade of disjoint ad-hoc notational conventions.
In any case, I think you’re conflating software engineering with programming language research. The former, being both practically important and very, very difficult to make solid theoretical progress in, is mostly a collection glorified rules of thumb, quite susceptible to fads and populated in part by loud, dogmatic amateur propagandists for current and past fads. The latter is a proper quasimathematical field of study with rigorous definitions, theorems, and heavy use of Greek letters.
I don’t really think OOP has much to offer mathematics. One of its ingredients, namely subtyping, is relevant on its own: as much as we don’t really want to identify the natural number 2 with the set {0,1}, we certainly do want it to be the same object as the integer 2, the rational number 2, the real number 2, and the complex number 2, which subtyping can help describe systematically (whereas a typical set-theoretic development would claim that there are “really” invisible injections being applied everywhere).
Insisting on a strict top-down order of development would be almost as misplaced in mathematics as it is in programming.
October 20, 2011 at 4:59 pm
Henning: Oops. Absolutely no sarcasm intended. Sorry for being so sloppy. I very much sympathize with your approach (albeit I probably do not completely understand it).
Is software engineering really completely separable from programming language research ? I do not think so. There surely is a considerable overlap. At least there was, when I studied it.
In any case, typed variables with restricted scopes (as discussed in this thread) are just the beginning. Once you have that, why not making explicit when you overload an operator like + or . Polymorphisms like that are everyday business for mathematicians and can be very confusing to students. In terms of programming languages such concepts are best described by OOP languages. At least, that is what I think.
. Polymorphisms like that are everyday business for mathematicians and can be very confusing to students. In terms of programming languages such concepts are best described by OOP languages. At least, that is what I think.
October 18, 2011 at 8:12 pm |
Two minor points that I thought you were going to make. Firstly be careful to write rather than
rather than  so as not to imply that
so as not to imply that  has an inverse.
has an inverse.
Secondly that the issue with codomains and images is related to the fact that all injections are invertible if we make no distinction between codomain and image.
October 29, 2011 at 6:19 pm |
Regard a function from set A to B as a subset of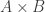 which satisfy certain properties.This definition is also useful in such conditions:
which satisfy certain properties.This definition is also useful in such conditions:
In Terence Tao ‘s book “Analysis”,the part of the book which involve set theory,there are two ways of presenting the power set axiom:
(1)All the functions from set A from set B form a set.
(2)All the subset of set A form a set.
It seems only if we regard function as a subset of cartesian product can we prove that the two statements are equal.For more information,see “analysis” exercise 3.5.11
December 4, 2011 at 4:35 am |
It might be interesting also to note that there are some instances where it matters a great deal which codomain is chosen for a function. For example, in general topology the concept of a function being $\theta$-continuous is not preserved under restricting the codomain. So even though we often don’t need to specify the codomain explicitly, there are cases where the choice matters (and not just any set containing the image will do).
December 13, 2011 at 9:01 pm |
[…] Here’s a small niggle, that’s arisen rewriting a very early chapter of my Gödel book, and also in reading a couple of terrific blog posts by Tim Gowers (here and here). […]
January 15, 2012 at 12:15 pm |
[…] (this appears to be the Nottingham standard), not the codomain of the function. Some, including Tim Gowers, prefer to use range to mean codomain (this appears to be the Cambridge standard). Perhaps we […]
February 9, 2012 at 2:43 pm |
I feel that the dislike for the notion of “arbitrary set” as related to the notion of function might come from the fact that everyday practice makes us work with functions that not only have a name such as f(x), but an actual, working definition on how to get f(x) from x. In this sense, f(x) is the “name” standing for a specific operation, and we as a species are quite comfortable with naming things.
Yet, when I think of real numbers I should feel the same way: most of us tend to come up with examples of real numbers who have names, such as -2, square root of 5, or pi. Yet the crushing majority of real numbers are transcendental and will never have a name of their own in our entire lifetime. So, when trying to answer the question “what is a real number?” one is necessarily forced to use the more abstract approach since there is no way to exhibit your general real number. unless dealing with random-like sequences of decimal digits should feel “concrete” to anyone. Similarly, going back to functions if we try to think of a random-valued real function it feels somewhat silly to think of it as an f(x) since we have nowhere near a formula for it.
In this sense, I suspect that what Tim Gowers thinks about when speaking of the “grammar” of functions he is only referring to functions that actually can be meaningfully written as y = f(x) (with a “readable” f(x) part), and this seems quite analogous to the “grammar” associated to those real numbers that have a name: “see, square roof two is a real number.” But how can I reasonably fit in a sentence that forever unnamed (and rather unreal, in fact) transcendental “thing” that together with its brethren fills up most of the real line?
February 9, 2012 at 4:04 pm
You’re using “transcendental” when you mean “computable”. As there are only countably many finite deterministic algorithms, there are only countably many reals whose decimal expansions we can compute by algorithm to arbitrary accuracy. We name transcendental numbers all the time ( ), but we never name noncomputable numbers. However, Chaitin would disagree.
), but we never name noncomputable numbers. However, Chaitin would disagree.
May 26, 2012 at 7:30 pm |
this really didnt help to me can you please give more details
February 10, 2013 at 8:09 am |
i need theoretical proofs and examples for (a) f(AUB)=f(A)Uf(B)
(b) f-1(AUB)=f-1(A)Uf-1(B)
(c) f-1(A∩B)=f-1(A)∩f-1(B)
please help me with in today.
January 16, 2015 at 3:03 pm |
I’m puzzled by what appears to be a very elaborate and deliberate attempt to create a lot of ambiguity in the terminology associated with the theory of sets and functions. There’s a reason technical fields have an argot and it’s to *minimize* ambiguity, not create and justify a lot of it.
January 17, 2015 at 4:25 pm
The one word I would dispute there is “deliberate”. It’s just an unfortunate example of a situation where by a historical accident the terminology didn’t standardize itself satisfactorily.
July 27, 2016 at 2:56 am |
[…] me repeat that one more time for clarity (and I’m stealing this formulation from Sir Tim Gowers’ blog): If is a function from to and is an element of , then is an element of […]
February 4, 2017 at 2:07 pm |
Thank you for this post! I wish I had seen it at the time you wrote it, since I have been frustrated with the terminology for many years now. Here is one complaint I have in particular: going back to Russel and Whitehead, the word ‘co-domain’ seems to be short for ‘converse domain’, i.e. the domain of the converse or inverse of a function. But the way the terms ‘domain’, ‘co-domain’, and ‘range’ I most often see used (though there is certainly no consistency here!), it would be the ‘range’ (or ‘image’) that serves the role of the ‘converse domain’, and *not* the ‘co-domain’!
For example, for a function like f(x)=1/x, the ‘domain’ is usually set to be the set of objects for which this function is defined, i.e. R/{0}, the ‘range’ as the set of values the function can take on, i.e. also R/{0}, but the co-domain would be R … Which is clearly not the ‘domain’ of the converse, or inverse, of this function.
Another question I have here is where the R comes from: why would we think that we are initially/immediately talking about real numbers when talking about functions like 1/x? Couldn’t I be talking about complex numbers, say? Indeed, why do we indicate some kind of ‘intended’ set of ‘potential’ values of the function on the output side (the ‘co-domain’), but don’t do this on the input side?
Indeed, I think it *would* make a lot of sense to *first* define a set of objects that the function is *intended* to work on (which we could call a ‘domain of discourse’), and then point out any values for which the function is actually defined (which we would call the ‘domain of definition’). And with that, we could have a ‘co-domain of discourse’ and a ‘co-domain of definition’ as the converse’s counterparts. Thus, for the function f(x)=1/x we could say that the domain and co-domain of discourse are both R, but the domain and co-domain of definition R/{0}.
In fact, I have been taking the lack of standards (or logical consistency) in the terminology as justification to use exactly this terminology when I teach my students about functions. It may not be ‘standard’, but I think it is certainly a lot more consistent and coherent … What do you think?
January 22, 2019 at 3:46 pm |
[…] you’re looking to learn about functions, here is a really good starting point. If you haven’t learned the basics of naive set theory and want to understand the […]
March 11, 2019 at 8:07 am |
[…] https://gowers.wordpress.com/2011/10/13/domains-codomains-ranges-images-preimages-inverse-images/ […]
February 16, 2020 at 4:39 pm |
f
March 6, 2020 at 8:55 am |
The only way to achieve happiness is to cherish what you have and forget what you don’t have
March 20, 2020 at 12:29 pm |
It is the best information I ever read because it is very useful and informative. Keep doing the great work up.
http://roadioapp.com/
March 25, 2020 at 12:32 pm |
or label and patches visit my website https://austintrim.co/
March 25, 2020 at 12:33 pm |
for energy solar panels visit my website https://enss.pk/
March 25, 2020 at 12:33 pm |
continue blogging. Hoping to perusing your next post https://khasindustries.com/
July 24, 2021 at 12:12 pm |
This is helpful, nonetheless it can be crucial so that you can check out the following website: hạt giống giá tốt
July 25, 2021 at 9:45 am |
Very good topic, similar texts are I do not know if they are as good as your work out. slot
July 26, 2021 at 10:20 am |
It is fine, nonetheless evaluate the information and facts around this correct. thucphamtuoisong
July 28, 2021 at 11:29 am |
Amazing, this is great as you want to learn more, I invite to This is my page. TFT Best Comps
July 29, 2021 at 1:09 pm |
Cool you write, the information is very good and interesting, I’ll give you a link to my site. Whatsapp Group
August 2, 2021 at 8:37 am |
Beaver says I also have such interest, you can read my profile here: TFT Best Comps
August 2, 2021 at 10:51 am |
Amazing, this is great as you want to learn more, I invite to This is my page. joker gaming
August 4, 2021 at 11:06 am |
For many people this is the best solution here see how to do it. Corpse Husband Merch
August 4, 2021 at 1:15 pm |
This is very useful, although it will be important to help simply click that web page link: Corpse Husband Merch
August 15, 2021 at 1:48 pm |
I should say only that its awesome! The blog is informational and always produce amazing things. Corpse Merch
August 17, 2021 at 2:29 pm |
Can nicely write on similar topics! Welcome to here you’ll find out how it should look. Chrome Hearts
August 24, 2021 at 8:32 am |
Very interesting information, worth recommending. However, I recommend this: E-Commerce Qatar
August 25, 2021 at 9:07 am |
Cool you inscribe, the info is really salubrious further fascinating, I’ll give you a connect to my scene. Anti Social Social Club
August 26, 2021 at 8:45 am |
Acknowledges for penmanship such a worthy column, I stumbled beside your blog besides predict a handful advise. I want your tone of manuscript… Anti Social Social Club
August 26, 2021 at 12:32 pm |
Very interesting information, worth recommending. However, I recommend this: https://cactusplantfleamarketshop.com/
August 28, 2021 at 9:53 am |
Very good topic, similar texts are I do not know if they are as good as your work out. https://cactusplantfleamarketshop.com/
August 28, 2021 at 12:45 pm |
I use only high quality materials – you can see them at: jschlatt merch
August 29, 2021 at 10:24 am |
I use only high quality materials – you can see them at: Kot4x
August 30, 2021 at 8:02 am |
I invite you to the page where see how much we have in common. Kot4x
September 2, 2021 at 9:41 am |
I read this article. I think You put a great deal of exertion to make this article. I like your work. kiostoto
September 6, 2021 at 1:03 pm |
Hmm… I interpret blogs on a analogous issue, however i never visited your blog. I added it to populars also i’ll be your faithful primer. coryxkenshinmerch
September 7, 2021 at 11:17 am |
Acknowledges for paper such a beneficial composition, I stumbled beside your blog besides decipher a limited announce. I want your technique of inscription… coryxkenshinmerch
September 11, 2021 at 7:53 am |
I encourage you to read this text it is fun described … estimation immobilière gratuite estimation immobilière Luxembourg
September 12, 2021 at 1:27 pm |
Beaver says I also have such interest, you can read my profile here: estimation immobilière gratuite estimation immobilière Luxembourg
September 21, 2021 at 12:33 pm |
These websites are really needed, you can learn a lot. Vlone Pop Smoke
September 22, 2021 at 10:25 am |
The best article I came across a number of years, write something about it on this page. bad bunny clothing
September 22, 2021 at 12:11 pm |
Very interesting information, worth recommending. However, I recommend this: vlone store
September 23, 2021 at 10:30 am |
Here you will learn what is important, it gives you a link to an interesting web page: revenge t shirt
September 26, 2021 at 8:14 am |
It is very good, but look at the information at this address. tyler the creator golf shirt
September 26, 2021 at 9:55 am |
I invite you to the page where you can read with interesting information on similar topics. how to perform namaz
September 26, 2021 at 12:46 pm |
Amazing, this is great as you want to learn more, I invite to This is my page. Pure Silk Bedding
September 27, 2021 at 8:14 am |
I can recommend primarily decent and even responsible tips, as a result view it: how to perform namaz
September 29, 2021 at 5:57 am |
The most interesting text on this interesting topic that can be found on the net … tyler the creator outfits
October 2, 2021 at 7:22 am |
Anti Social Social Club Official Store Anti Social Social Club Hoodie is very famous and good brand.Which is available in different designs and different colors.
And available best tees,sweatshirts,and merchadise fans and Free shiping worldwide.
October 6, 2021 at 8:31 am |
The most interesting text on this interesting topic that can be found on the net … Comme Des Garcons Shirt
October 6, 2021 at 11:06 am |
I also wrote an article on a similar subject will find it at write what you think. chrome heart clothing
October 7, 2021 at 8:32 am |
For true fans of this thread I will address is a free online! USA Visa ESTA
October 10, 2021 at 8:37 am |
I might suggest solely beneficial in addition to trusted facts, and so find it: Shop Now
October 10, 2021 at 11:25 am |
This is important, though it’s necessary to help you head over to it weblink: ChelseaBootsMaker.com
October 10, 2021 at 2:41 pm |
I recommend only good and reliable information, so see it: silk bedding
October 13, 2021 at 12:35 pm |
This is very interesting, but it is necessary to click on this link: fullsendmerch
October 13, 2021 at 12:50 pm |
On this page you can read my interests, write something special. dreammerch
October 14, 2021 at 10:52 am |
Interesing fact-Most of people will skip your promotion or post in the social media. Okay okay but why?? 🧐
Everyday you are bombarded with tons of advertisments and social media content, and that’s why its harder to grab your attention.🧑💻
For good marketing we need more than just posting links everywhere on the internet. 🌐
In order to generate money we need professional marketing tools such as:
-Top converting landing pages
-Marketing automation
-Automated sales
-Advanced analytics of our marketing strategies
-Highly engaging webinars
-Social media ads creator
All of these tools necesarry to explode our bussiness or social media brand we can find here 👇
👉 https://www.getresponse.com/?a=3tgdcA9Gvp
Without having all in one marketing tool its hard to be effective in digital marketing in 2021, so don’t wait and explode your bussiness now for FREE 🎉🚀💸
Thank you for reading, have great day 😄
October 16, 2021 at 9:08 am |
I have a similar interest this is my page read everything carefully and let me know what you think. Houston Embroidery Service
October 18, 2021 at 9:05 am |
Acknowledges for paper such a beneficial composition, I stumbled beside your blog besides decipher a limited announce. I want your technique of inscription… voyance-tel-avenir.com
October 20, 2021 at 7:33 am |
It’s superior, however , check out material at the street address. start a new business
October 20, 2021 at 10:42 am |
I exploit solely premium quality products — you will observe these individuals on: postonmagazine.com
October 21, 2021 at 8:29 am |
Acknowledges for penmanship such a worthy column, I stumbled beside your blog besides predict a handful advise. I want your tone of manuscript… nbayoungboymerch
October 23, 2021 at 7:56 am |
I simply want to tell you that I am new to weblog and definitely liked this blog site. Very likely I’m going to bookmark your blog . You absolutely have wonderful stories. Cheers for sharing with us your blog. playboi carti shop
October 23, 2021 at 8:52 am |
I exploit solely premium quality products — you will observe these individuals on: popsmokemerchshop
October 23, 2021 at 11:09 am |
This is very appealing, however , it is very important that will mouse click on the connection: Satta king game
October 23, 2021 at 12:18 pm |
I like to recommend exclusively fine plus efficient information and facts, hence notice it: https://popsmokemerchshop.com/
October 23, 2021 at 1:00 pm |
I’ve proper selected to build a blog, which I hold been deficient to do for a during. Acknowledges for this inform, it’s really serviceable! streetwearstuff
October 24, 2021 at 8:57 am |
There you can download for free, see the first of these data. hhttps://streetwearstuff.com/
October 25, 2021 at 9:11 am |
Cool you inscribe, the info is really salubrious further fascinating, I’ll give you a connect to my scene. silk bedding
October 25, 2021 at 11:56 am |
So it is interesting and very good written and see what they think about other people. postonmagazine.com
October 25, 2021 at 12:33 pm |
In this article understand the most important thing, the item will give you a keyword rich link a great useful website page: F95zone
October 26, 2021 at 8:00 am |
Cool you inscribe, the info is really salubrious further fascinating, I’ll give you a connect to my scene. F95zone
October 26, 2021 at 8:39 am |
I exploit solely premium quality products — you will observe these individuals on: playboyclothing
October 26, 2021 at 11:20 am |
I like to recommend exclusively fine plus efficient information and facts, hence notice it: playboyclothing.net/
October 27, 2021 at 7:53 am |
I invite you to the page where you can read with interesting information on similar topics. novinky
October 27, 2021 at 12:21 pm |
I can recommend primarily decent and even responsible tips, as a result view it: mag
October 27, 2021 at 1:08 pm |
Such sites are important because they provide a large dose of useful information … earlynewspaper.com
October 28, 2021 at 10:33 am |
Cool you inscribe, the info is really salubrious further fascinating, I’ll give you a connect to my scene. earlynewspaper.com
October 31, 2021 at 7:32 am |
There you can download for free, see the first of these data. kanye west merch shop
October 31, 2021 at 9:48 am |
I wrote about a similar issue, I give you the link to my site. https://www.kanyewestmerchshop.com/
October 31, 2021 at 10:12 am |
It’s superior, however , check out material at the street address. https://www.kanyewestmerchshop.com/
November 3, 2021 at 11:55 am |
Very interesting information, worth recommending. However, I recommend this: juice wrld merch 1042
November 6, 2021 at 6:58 am |
This is a very nice blog and learned more knowledge to read this post thanks for sharing this informative post.
November 15, 2021 at 4:20 pm |
For the current condition you will start it is goliath, it again passes on a site a solid titanic page: essay topics
November 17, 2021 at 3:54 am |
Comme des garcon has the quality products like shirts hoodies and other accessories that get fast shipping around the world.
November 17, 2021 at 11:38 am |
I appreciate your efforts in preparing this post. I really like your blog articles.
November 23, 2021 at 6:57 am |
Very important and wonderful post here. This post is very helpful for every visitor. I hope you will soon share your next post about this discussion. Thanks for sharing and keep sharing.
November 23, 2021 at 6:59 am |
Very important and wonderful post here. This post is very helpful for every visitor. I hope you will soon share your next post about this discussion. Thanks for sharing and keep sharing.
November 24, 2021 at 4:26 am |
Comme des garcon has the quality products like shirts hoodies and other accessories.
November 26, 2021 at 5:17 am |
Anti Social Social Club Official Store Anti Social Social Club Hoodie is very famous and good brand.Which is available in different designs and different colors.
And available best tees,sweatshirts,and merchadise fans and Free shiping worldwide.
November 30, 2021 at 2:55 pm |
A modern style swiss-made chronograph watch for men. Stainless steel men’s watches, swiss movement, sapphire crystal, dive watch & water-proof
December 7, 2021 at 4:44 pm |
Nice Artical
December 10, 2021 at 11:05 am |
This is a really too good post. This article gives truly quality and helpful information. I’m definitely going to look into it. Really very useful topic info is provided here. Thank you so much buddy and Keep up the good work.
December 11, 2021 at 2:26 pm |
hot forging
December 12, 2021 at 4:07 pm |
Nice
December 17, 2021 at 12:52 pm |
amazing content is exactly what I was looking for thanks for sharing keep up the good work. I will definitely share it with friends.
December 18, 2021 at 7:09 pm |
https://www.jeanbooknerd.com/2017/12/max-best-friend-hero-marine-by-jennifer.html?showComment=1639854340780#c2792350316276171462
December 23, 2021 at 7:14 am |
This is a very nice blog and learned more knowledge to read this post thanks for sharing this informative post.
January 5, 2022 at 5:35 am |
I read this article. I think You put a great deal of exertion to make this article.
January 5, 2022 at 6:04 am |
Our ukdenim products are the perfect way to show your British pride! Made from the highest-quality materials,
our jeans, shirts, and other clothing items are sure to impress. Whether you’re looking for a new outfit for a special occasion or just
some everyday clothes that represent your heritage, we’ve got you covered. Plus, our prices are unbeatable! So come on over to ukdenim and shop today!
January 5, 2022 at 6:06 am |
Our ukdenim products are the perfect way to show your British pride! Made from the highest-quality materials,
our jeans, shirts, and other clothing items are sure to impress. Whether you’re looking for a new outfit for a special occasion or just
some everyday clothes that represent your heritage, we’ve got you covered. Plus, our prices are unbeatable! So come on over to ukdenim and shop today!
February 8, 2022 at 7:40 am |
This is a great article. I am a new user of this site so here i saw multiple articles and posts posted by this site, I am curious more interest in some of them hope you will give more information on this topic in your next articles.www.wellingtondemolition.co.nz.
March 12, 2022 at 6:17 am |
You can find the best mobile deals in town and save big on your next purchase. We carry all the latest models and offer unbeatable prices on top brands like Huawei, Samsung, Apple, Nokia, and LG. So whether you’re in the market for a new smartphone or just need to upgrade your old one, we’ve got you covered.
March 23, 2022 at 11:06 am |
Our Quality checker department will carefully check each item’s quality before packing & dispatching. We guarantee our products will be of the highest quality available. All dresses are well-packed with dust bags. Please kindly understand a slight size difference and color difference are not quality problems.
jesus is king
March 31, 2022 at 1:13 pm |
This is a very nice blog and learned more knowledge to read this post thanks for sharing this informative post.
shoptechnoblade.com
April 3, 2022 at 6:37 am |
[…] resisting the identification of a function as a sort of relation. Here’s a short excerpt from a useful blog post by the Field’s medallist Tim Gowers (I mention his achievement just to point up that this is a post by a top class mathematician, not […]
April 16, 2022 at 6:26 am |
Its an interesting and useful information. We all get highly motivation from this. commedesgarconshop
The information given in this blog is very nice.
April 16, 2022 at 6:27 am |
Its an interesting and useful information. nelkboysofficial We all get highly motivation from this .
April 16, 2022 at 6:28 am |
I like your blog because it is so informative.officialfullsend I learned a lot from your post thank you.
October 16, 2022 at 7:03 am |
[…] https://gowers.wordpress.com/2011/10/13/domains-codomains-ranges-images-preimages-inverse-images/ […]
October 16, 2022 at 7:04 am |
[…] https://gowers.wordpress.com/2011/10/13/domains-codomains-ranges-images-preimages-inverse-images/ […]
October 16, 2022 at 7:36 am |
[…] https://gowers.wordpress.com/2011/10/13/domains-codomains-ranges-images-preimages-inverse-images/ […]
October 16, 2022 at 7:36 am |
[…] https://gowers.wordpress.com/2011/10/13/domains-codomains-ranges-images-preimages-inverse-images/ […]
November 2, 2022 at 5:31 am |
Amazing T-Shirts, and upscale T-shirts and Hoodies. known as the official sites. we offer enormous markdown.
November 11, 2022 at 6:25 am |
Essentials clothing collection official store. Get fear of God seventh collection at
best prices. Essentials clothing
November 16, 2022 at 4:47 pm |
I’ve been exploring for a bit for any high-quality articles or blog posts in this kind of area . Exploring in Yahoo I at last stumbled upon this web site. Reading this info So i’m satisfied to convey that I have a very excellent uncanny feeling I discovered just what I needed. I such a lot surely will make sure to don’t omit this website and provides it a look a continuing. https://oasissmiledental.com
December 2, 2022 at 2:17 pm |
I ran across your site last week and started to follow your posts consistently. I haven’t commented on any kind of blog site just yet but I was considering to start soon. It’s truly exciting to actually contribute to an article even if it’s only a blog. I really don’t know exactly what to write other than I really loved reading through a couple of of your articles. Great articles for sure. I will keep visiting your blog regularly. I learned a lot from you. Thanks! NW Calgary dentist
December 27, 2022 at 8:23 am |
A warning triangle is a small red triangle with a highly reflecting surface that is typically constructed of plastic and metal is called warning triangles folding suppliers.
February 10, 2023 at 4:39 pm |
Revenge Official Clothing Store + XXX Tentacion Clothing Store,You can buy Official Hoodies, T-Shirts,Jackets,Long Sleeves and More.
February 11, 2023 at 5:15 am |
Technoblade official online storefront offering authentic and brand approved merchandise and products. Technoblade Merch is the merchandise for fans by fans. We are #1 Technoblade Apparel & Collectibles.
April 3, 2023 at 6:40 pm |
Pretty good I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog posts. Any way I’ll be subscribing to your feed and I hope you post again soon. Big thanks for the useful info.
April 13, 2023 at 8:17 pm |
Golf Wang Golf Wang Converse Products From Golf Wang Store Official® Website. Shop Hoodies, Shirts, Jackets, Shoes. ✅ FAST DELIVERY ✅ Amazing DISCOUNTS.
May 1, 2023 at 12:17 pm |
RHUDE Clothing, Shorts & T SHIRT Available at RHUDE Official Store. RHUDE Official are Offering Branded products with discount.
<a
May 14, 2023 at 5:54 am |
The youthful generation now uses the phrases “fashion” and “style” interchangeably,
despite their complete lack of understanding and inability to distinguish between
the two terms. There are still a lot of people in this younger generation who do not
understand the distinction between fashion and style. Fashion is about dressing in
accordance with current trends. Being oneself is more important for style.
fashion and style
June 13, 2023 at 6:23 am |
Knowledge Quran Centre is the best place of Quran Learning Online. Learn Quran Online from Knowledge Quran Centre with Certified Quran Teachers
knowledge Quran
June 13, 2023 at 9:08 am |
The official shop of BAPE Hoodie A Bathing Ape® clothing store Get Real BAPE Shark Hoodies, Shirts, BAPESTA Shoes and BAPE Shorts
June 16, 2023 at 2:21 am |
One Cricket ID is the most popular among the many Online Betting Id providers. One Cricket ID on WhatsApp within seconds. Best IPL 2023 Betting ID that’s fast and reliable. New Cricket ID and Cricket Match ID offer heavy discounts, bonuses, and cashback.
Cricket ID
June 23, 2023 at 6:00 am |
Welcome to blogofinfo, where you can find the most exciting and enlightening articles. We are a lively and dynamic blog site investigating various subjects that will inspire, educate, and amuse you.
Divorce attorney
June 27, 2023 at 3:39 pm |
Thanks for the blog post buddy! Keep them coming…
dental implants Banff
June 28, 2023 at 4:07 pm |
Nice to read your article! I am looking forward to sharing your experience.
Best Dentist Toronto
August 29, 2023 at 7:03 am |
The official shop of BAPE Hoodie A Bathing Ape® clothing store Get Real BAPEShirts, BAPESTA Shoes and BAPE Shorts Shark Hoodies.
bape hoodie
September 22, 2023 at 1:21 pm |
Unlock expert tips for effective baby care. Discover valuable insights and advice on Vity Care. Empower your parenting journey today!
Pregnancy Test Line Progression
September 25, 2023 at 1:16 pm |
Looking to boost your online presence globally?
Apso Tech is your go-to international SEO services company! With their expertise, they can help your website reach a wider audience and increase visibility. Don’t miss out on the opportunity to expand your business internationally and stay ahead of the competition. Contact Apso Tech today and take your online success to the next level! 🌐 #SEOExpertise
October 26, 2023 at 11:24 am |
Shop Official Chrome Hearts Hoodie at Best Price. Official Online Clothing Store for Chrome Hearts Fans. SHOP NOW & Get Discounts with latest prodcuts.
October 26, 2023 at 11:25 am |
Are you looking for Chrome Hearts Hoodie products shopping online. Visit our chrome hearts official store to Enjoy our Wide Collection.
November 7, 2023 at 7:50 am |
Discover the complete Essentials Clothing collection on the official website. Amazing Essentials Hoodie, Shirts, and Jacket Collection in Essentialsofficial.shop. is a luxury brand known for its high-quality jewelry, clothing, and accessories with a distinctive Gothic and punk aesthetic.”
November 7, 2023 at 8:09 am |
“Chrome Hearts is a luxury brand known for its high-quality jewelry, clothing, and accessories with a distinctive Gothic and punk aesthetic.” is a luxury brand known for its high-quality jewelry, clothing, and accessories with a distinctive Gothic and punk aesthetic.”
November 8, 2023 at 6:24 am |
Get perimum quality product in cheap from taylorswiftmerch.
It is a platform of fashion that is a maker of trends and focus on the personality of an individual. Taylor Swift Clothing is not just an online brand. It’s a combination of fashion, uniqueness, creativity and excellency of relationships with their valuable customers. Pieces of clothing tells a story about a person wearing it. You are a walking portray of a good story to others who are going look at you. At Taylor Swift Hoodies Clothing, each piece of clothing is a masterpiece itself. It’s a story that’s going to inspire and attract so many other eyes. Our clothing is stitched with love and dedication. It shows that you are not just going to invest in piece of clothing. But you are putting your money on pieces that stands in test of time.
<a href="https://taylorswifthoodies.shop/"taylorswifthoodies
November 8, 2023 at 6:26 am |
Get perimum quality product in cheap from taylorswiftmerch.
It is a platform of fashion that is a maker of trends and focus on the personality of an individual. Taylor Swift Clothing is not just an online brand. It’s a combination of fashion, uniqueness, creativity and excellency of relationships with their valuable customers. Pieces of clothing tells a story about a person wearing it. You are a walking portray of a good story to others who are going look at you. At Taylor Swift Hoodies Clothing, each piece of clothing is a masterpiece itself. It’s a story that’s going to inspire and attract so many other eyes. Our clothing is stitched with love and dedication. It shows that you are not just going to invest in piece of clothing. But you are putting your money on pieces that stands in test of time.
November 8, 2023 at 6:41 am |
At Rhude Clothing, you can buy 100% authentic rhude hoodie & Sweatshirts online and save a lot of money. Worldwide shipping & discounts up to 30%.
November 10, 2023 at 1:37 pm |
Melanie Martinez Merch, t shirts, sweatshirts, sweatpants and hoodies in high quality
time.https://melaniemartinezmerch.store/
November 11, 2023 at 11:19 am |
Melanie Martinez Merch, t shirts, sweatshirts, sweatpants and hoodies in high quality
November 11, 2023 at 5:08 pm |
Shop! 100% official Sp5der worldwide clothing buy Young Thug Hoodie at sp5drhoodie Official Store.with Fast Shipping Worldwide and Easy Returns.
November 11, 2023 at 5:21 pm |
At Rhude , you can find the ultimate designer fashion destination. The latest men’s and women’s limited-edition styles are available here
November 11, 2023 at 5:21 pm |
Are you looking for Rhude Hoodie shopping online. Visit our Rhude official store to Enjoy our Wide Collection.
November 11, 2023 at 5:21 pm |
Are you looking for Rhude Hoodie shopping online. Visit our Rhude official store to Enjoy our Wide Collection.
November 11, 2023 at 5:22 pm |
At Rhude clothing , you can find the ultimate designer fashion destination. The latest men limited-edition styles are available here
November 15, 2023 at 7:33 am |
Essentials clothing is a go-to choice for those who value simplicity and quality in their wardrobe. Created by the fashion label Fear of God, Essentials offers a collection of apparel that blends comfort with timeless style. From hoodies and sweatpants to t-shirts and outerwear, their pieces feature a minimalist design, focusing on clean lines and premium materials. Essentials Clothing is characterized by its versatility and ease of wear, making it suitable for various occasions. Whether you’re looking for loungewear, workout attire, or casual streetwear, Essentials delivers comfort and style in equal measure. It’s the brand for individuals who appreciate classic, understated fashion and exceptional quality.
November 20, 2023 at 5:06 am |
It is a platform of fashion that is a maker of trends and focus on the personality of an individual. Taylor Swift Clothing is not just an online brand. It’s a combination of fashion, uniqueness, creativity and excellency of relationships with their valuable customers. Pieces of clothing tells a story about a person wearing it. You are a walking portray of a good story to others who are going look at you. At Taylor Swift Hoodies Clothing, each piece of clothing is a masterpiece itself. It’s a story that’s going to inspire and attract so many other eyes. Our clothing is stitched with love and dedication. It shows that you are not just going to invest in piece of clothing. But you are putting your money on pieces that stands in test of time.
<ahref="https://taylorswifthoodies.shop/"taylorswiftmerch
November 21, 2023 at 6:22 pm |
.https://ovoofficial.store/
December 11, 2023 at 7:57 pm |
Buy Bad Bunny Merch From Official Bad Bunny Merch Store for ✅ Bad Bunny Hoodie, Bad Bunny T Shirt, and Much More Get Fast Shipping Worldwide
https://badbunnymerchstore.online/
December 12, 2023 at 1:48 pm |
Shop Harry Styles Merch, t shirts, sweatshirts, sweatpants and hoodies in high quality etc.
December 12, 2023 at 6:46 pm |
broken planet uk From Official brokenplanetuk Store for ✅ brokenplanetuk Hoodie, brokenplanetuk T Shirt, and Much More Get Fast Shipping Worldwide
December 13, 2023 at 6:28 pm |
Broken planet, Official Broken planet Store for ✅ Broken planet Hoodie, Broken planet T Shirt, and Pants Shop Now Get Fast Shipping
December 20, 2023 at 4:26 pm |
Buy Bad Bunny Merch From Official Bad Bunny Merch Store for ✅ Bad Bunny Hoodie, Bad Bunny T Shirt, and Much More Get Fast Shipping Worldwide
December 29, 2023 at 5:47 pm |
Your writing is always honest and authentic. I appreciate your willingness to share your vulnerabilities with your readers. And if you’re looking for kids’ clothing that’s both durable and stylish, Kids Premium Clothing is the answer. Their clothes are made from high-quality materials that can withstand even the most active kids.
January 6, 2024 at 5:24 pm |
The Young Thug Hoodie is Available in the Best Quality at the Official Young Thug Store Buy the Young Thug Hoodie now and get a 30 Discount
youngthug-merch
January 10, 2024 at 6:13 pm |
Buy Bad Bunny Merch From Official Bad Bunny Merch Store for ✅ Bad Bunny Hoodie, Bad Bunny T Shirt, and Much More Get Fast Shipping Worldwide shop know etc
January 20, 2024 at 11:26 am |
Buy Now Chrome Hearts Hoodie from Our Official Chrome Hearts Store at Huge Discounts UPTO 50 OFF and Free Shipping Worldwide
Chrome Hearts Hoodie
March 16, 2024 at 5:29 am |
The Eric Emanuel Hoodie Store now offers Eric Emanuel Hoodie at a big discount with free shipping. Eric Emanuel Hoodie
March 20, 2024 at 4:58 pm |
Corteiz Where fashion meets elegance Discover the latest trends and redefine your style effortlessly Corteiz UK https://crtzclothing.shop/#
March 28, 2024 at 8:01 am |
“Impressed by your dedication! Your hard work paid off, achieving this milestone. Your journey exemplifies perseverance and determination. Cheers to celebrating this success and future triumphs. You’re unstoppable!”
March 28, 2024 at 9:03 am |
“Your vulnerability is admirable; sharing your experience takes courage. Your story touches many, including me. You’re never alone; strength lies in shared struggles. Keep shining; brighter days await!”
May 11, 2024 at 9:12 am |
Get the travisscott Hoodie, Shirts at travis scott merch official website. To Purchase the high quality products at cheap price. Get Fast shipping all around the world.
May 14, 2024 at 10:22 am |
Get the Bad Bunny hoodie,shirts,sweatshirts, at official
https://badbunnyhoodie.com/ website. To purchase the high quality products at cheap price.