After my tentative Polymath proposal, there definitely seems to be enough momentum to start a discussion “officially”, so let’s see where it goes. I’ve thought about the question of whether to call it Polymath11 (the first unclaimed number) or Polymath12 (regarding the polynomial-identities project as Polymath11). In the end I’ve gone for Polymath11, since the polynomial-identities project was listed on the Polymath blog as a proposal, and I think the right way of looking at things is that the problem got solved before the proposal became a fully-fledged project. But I still think that that project should be counted as a Polymathematical success story: it shows the potential benefits of opening up a problem for consideration by anybody who might be interested.
Something I like to think about with Polymath projects is the following question: if we end up not solving the problem, then what can we hope to achieve? The Erdős discrepancy problem project is a good example here. An obvious answer is that we can hope that enough people have been stimulated in enough ways that the probability of somebody solving the problem in the not too distant future increases (for example because we have identified more clearly the gap in our understanding). But I was thinking of something a little more concrete than that: I would like at the very least for this project to leave behind it an online resource that will be essential reading for anybody who wants to attack the problem in future. The blog comments themselves may achieve this to some extent, but it is not practical to wade through hundreds of comments in search of ideas that may or may not be useful. With past projects, we have developed Wiki pages where we have tried to organize the ideas we have had into a more browsable form. One thing we didn’t do with EDP, which in retrospect I think we should have, is have an official “closing” of the project marked by the writing of a formal article that included what we judged to be the main ideas we had had, with complete proofs when we had them. An advantage of doing that is that if somebody later solves the problem, it is more convenient to be able to refer to an article (or preprint) than to a combination of blog comments and Wiki pages.
With an eye to this, I thought I would make FUNC1 a data-gathering exercise of the following slightly unusual kind. For somebody working on the problem in the future, it would be very useful, I would have thought, to have a list of natural strengthenings of the conjecture, together with a list of “troublesome” examples. One could then produce a table with strengthenings down the side and examples along the top, with a tick in the table entry if the example disproves the strengthening, a cross if it doesn’t, and a question mark if we don’t yet know whether it does.
A first step towards drawing up such a table is of course to come up with a good supply of strengthenings and examples, and that is what I want to do in this post. I am mainly selecting them from the comments on the previous post. I shall present the strengthenings as statements rather than questions, so they are not necessarily true.
Strengthenings
1. A weighted version.
Let 

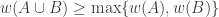



Note that if all weights take values 0 or 1, then this becomes the original conjecture. It is possible that the above statement follows from the original conjecture, but we do not know this (though it may be known).
This is not a good question after all, as the deleted statement above is false. When
2. Another weighted version.
Let 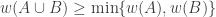
Again, if all weights take values 0 or 1, then the collection of sets of weight 1 is union closed and we obtain the original conjecture. It was suggested in this comment that one might perhaps be able to attack this strengthening using tropical geometry, since the operations it uses are addition and taking the minimum.
3. An “off-diagonal” version.
Tom Eccles suggests (in this comment) a generalization that concerns two set systems rather than one. Given set systems 

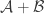
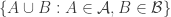
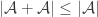

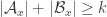

Simple examples show that 


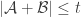
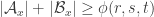
4. A first “averaged” version.
Let 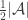
This is false, as the example 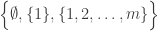
5. A second averaged version.
Let 

This again is false: see Example 2 below.
6. A better “averaged” version.
In this comment I had a rather amusing (and typically Polymathematical) experience of formulating a conjecture that I thought was obviously false in order to think about how it might be refined, and then discovering that I couldn’t disprove it (despite temporarily thinking I had a counterexample). So here it is.
As I have just noted (and also commented in the first post), very simple examples show that if we define the “abundance” 
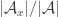



A short calculation reveals that the average abundance with this probability distribution is equal to the average overlap density, which we define to be
where the averages are over
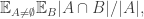
A not wholly pleasant feature of this conjecture is that the average overlap density is very far from being isomorphism invariant. (That is, if you duplicate elements of 
7. Compressing to an up-set.
This conjecture comes from a comment by Igor Balla. Let 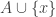
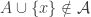

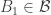
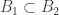
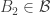
Note that each time we perform the “add
Suppose now that 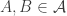

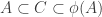
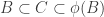
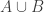
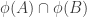
Now the fact that 
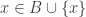
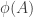

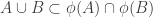
This leads to the conjecture that Balla makes. He is not at all confident that it is true, but has checked that there are no small counterexamples.
Conjecture. Let 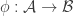
- For each
.
- For no distinct
Then there is an element
The following comment by Gil Kalai is worth quoting: “Years ago I remember that Jeff Kahn said that he bet he will find a counterexample to every meaningful strengthening of Frankl’s conjecture. And indeed he shot down many of those and a few I proposed, including weighted versions. I have to look in my old emails to see if this one too.” So it seems that even to find a conjecture that genuinely strenghtens FUNC without being obviously false (at least to Jeff Kahn) would be some sort of achievement. (Apparently the final conjecture above passes the Jeff-Kahn test in the following weak sense: he believes it to be false but has not managed to find a counterexample.)
Examples and counterexamples
1. Power sets.
If
Obviously this is not a counterexample to FUNC, but it was in fact a counterexample to an over-optimistic conjecture I very briefly made and then abandoned while writing it into a comment.
2. Almost power sets
This example was mentioned by Alec Edgington. Let 

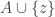
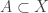
If 
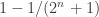
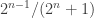
A slightly different example, also used by Alec Edgington, is to take all subsets of 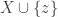

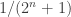
When 

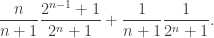
3. Empty set, singleton, big set.
Let 
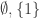


4. Using strong divisibility sequences.
I will not explain these in detail, but just point you to an interesting comment by Uwe Stroinski that suggests a number-theoretic way of constructing union-closed families.
I will continue with methods of building union-closed families out of other union-closed families.
5. Duplicating elements.
I’ll define this process formally first. Let 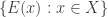
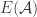
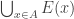
One can think of 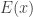
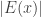
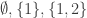
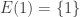
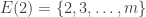
Let us say that 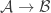
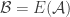

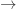

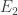
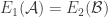
The effect of duplication is basically that we can convert the uniform measure on the ground set into any other probability measure (at least to an arbitrary approximation). What I mean by that is that the uniform measure on the ground set of 
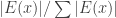
If one is looking for an averaging argument, then it would seem that a nice property that such an argument might have is (as I have already commented above) that the average should be with respect to a probability measure on
It is common in the literature to outlaw duplication by insisting that
6. Union-sets.
Tom Eccles, in his off-diagonal conjecture, considered the set system, which he denoted by 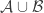
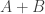
It’s trivial to see that if 
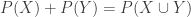

Another remark is that if 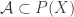
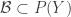
7. A less obvious construction method.
I got this from a comment by Thomas Bloom. Let 

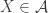
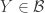
- sets
with
- sets
with
;
- sets
with
- sets
with
It can be checked quite easily (there are six cases to consider, all straightforward) that the resulting family is union closed.
Thomas Bloom remarks that if 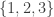

Thus, this construction method can be used to create interesting union-closed families out of boring ones.
Thomas discusses what happens to abundances when you do this construction, and the rough answer is that elements of
I feel as though there is much more I could say, but this post has got quite long, and has taken me quite a long time to write, so I think it is better if I just post it. If there are things I wish I had mentioned, I’ll put them in comments and possibly repeat them in my next post.
I’ll close by remarking that I have created a wiki page. At the time of writing it has almost nothing on it but I hope that will change before too long.

January 29, 2016 at 3:59 pm |
Something I should have mentioned is methods of creating smaller union-closed families out of given ones. For example, one can remove an element from and identify sets that become identical. Or one can take an equivalence relation on
and identify sets that become identical. Or one can take an equivalence relation on  and restrict to just those sets that are unions of equivalence classes — this would be a “quotient” family.
and restrict to just those sets that are unions of equivalence classes — this would be a “quotient” family.
This sort of construction could conceivably be useful in an inductive proof. At any rate, in any proof we are free to assume that all such families contain elements with abundance at least 1/2, though that seems too weak to use as an inductive hypothesis — probably induction has more chance of working with attempted averaging arguments.
January 29, 2016 at 4:38 pm
That use of the word “quotient” wasn’t very intelligent. What I should have said is that a subset of gives rise to a quotient family (since you have to identify elements of
gives rise to a quotient family (since you have to identify elements of  ) while a quotient set of
) while a quotient set of  gives rise to a subfamily of
gives rise to a subfamily of  . So some sort of duality is operating.
. So some sort of duality is operating.
January 29, 2016 at 5:26 pm |
Logistical comment: have you considered getting a programmer (perhaps a volunteer) to write some more dedicated platform for hosting these discussions? The major weakness of having them in WordPress comments as I see it is that even when voting on comments is possible you can’t sort by votes (as you can on MathOverflow, say). Also there’s an annoying limit to how much you can nest comments, at least as far as I recall.
I think a platform something like Reddit but with LaTeX support would do a better job of bubbling up the best comments to everyone’s attention, to make it easier to follow the discussions casually.
January 29, 2016 at 10:03 pm
The r/math reddit [1] lists some scripts/extensions that one can use there to get the faux-TeX to display properly. I’ve not spent any appreciable time there or tried out the suggestions.
[1] https://www.reddit.com/r/math
January 31, 2016 at 4:20 pm
I made a polymath subreddit: https://www.reddit.com/r/polymathpoject/. I’m not sure I’m allowed to do this, but in the spirit of rapid prototyping I went ahead. I’m happy to hand it over to whoever wants to moderate it.
From what I understand, it might be best to have a subreddit for each polymath project or each “research community” (e.g. I have several email threads going with a bunch of collaborators, but we could use a private subreddit).
This bookmarklet will run mathjax on reddit: http://web.mit.edu/jcalz/Public/Reddit/mathjaxbookmarklet.html
February 4, 2016 at 2:48 pm
The discourse platform would already be a major step up: https://www.discourse.org/
January 29, 2016 at 6:17 pm |
Concerning the first weighted generalization “1.”, the assumption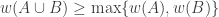 for all
for all 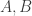 is equivalent to
is equivalent to 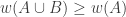 for all
for all 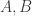 , which is simply monotonicity of
, which is simply monotonicity of  . So when
. So when  is the normalized counting measure of a set system, this assumption requires the set system to be upper closed! This is clearly not what we’re looking for, and therefore we might want to abandon the first weighted generalization in favour of the second, which indeed specializes to FUNC.
is the normalized counting measure of a set system, this assumption requires the set system to be upper closed! This is clearly not what we’re looking for, and therefore we might want to abandon the first weighted generalization in favour of the second, which indeed specializes to FUNC.
January 29, 2016 at 6:31 pm
Good point — I’ll edit the post later.
January 30, 2016 at 9:46 am |
Suppose we want to prove that the average overlap density of a union-closed family is always at least 1/2. An obvious idea is to try to use induction. That enables us to assume that the average overlap density of
is always at least 1/2. An obvious idea is to try to use induction. That enables us to assume that the average overlap density of  is at least 1/2 for every
is at least 1/2 for every  . But it actually allows us to assume more. We can define the average overlap density with respect to any probability measure we like on
. But it actually allows us to assume more. We can define the average overlap density with respect to any probability measure we like on  , and the duplication procedure shows that we are forced to prove the result for all such measures, so we end up with a stronger inductive hypothesis that does not come at the cost of a stronger result that needs to be proved with the help of that hypothesis.
, and the duplication procedure shows that we are forced to prove the result for all such measures, so we end up with a stronger inductive hypothesis that does not come at the cost of a stronger result that needs to be proved with the help of that hypothesis.
So the inductive hypothesis would be something like that for every and every probability measure
and every probability measure  on
on  that gives non-zero probability to all the elements of
that gives non-zero probability to all the elements of  , the average overlap density of
, the average overlap density of  with respect to
with respect to  is at least 1/2.
is at least 1/2.
So far so good. Where I don’t have an idea is in how to use the hypothesis that is union closed. It has to come in somewhere. But perhaps the right way to work that out is to try to carry out the above proof for an arbitrary set system
is union closed. It has to come in somewhere. But perhaps the right way to work that out is to try to carry out the above proof for an arbitrary set system  (which of course makes the result completely false) and then see what extra hypotheses are needed to make it work. Maybe one can identify some minimal hypotheses and the conjecture that those hold for union-closed families.
(which of course makes the result completely false) and then see what extra hypotheses are needed to make it work. Maybe one can identify some minimal hypotheses and the conjecture that those hold for union-closed families.
Of course, this average-overlap-density conjecture may very well be false, but in that case maybe pursuing an attempt like the above could lead to a way of constructing a counterexample.
January 30, 2016 at 11:23 am
Here’s a brief indication of why the average overlap density of might be hard to express in terms of the average overlap densities of the
might be hard to express in terms of the average overlap densities of the  . The average overlap density of
. The average overlap density of  is roughly speaking the average overlap of a random set
is roughly speaking the average overlap of a random set  with a random set
with a random set  given that both
given that both  and
and  contain
contain  . When we average that over
. When we average that over  (possibly with some weighted average) we are still calculating some kind of average overlap density but now we are conditioning on the event that
(possibly with some weighted average) we are still calculating some kind of average overlap density but now we are conditioning on the event that  and
and  both contain some random element
both contain some random element  . But one would expect this to increase the expected density of the overlap of
. But one would expect this to increase the expected density of the overlap of  and
and  . Thus, knowing that the average overlap densities of the
. Thus, knowing that the average overlap densities of the  are large does not seem sufficient to obtain that the average overlap density of
are large does not seem sufficient to obtain that the average overlap density of  is large.
is large.
It may be possible to get round this problem somehow. For example, the information that all the sets in contain
contain  should enable us to say something stronger about the average overlap density of
should enable us to say something stronger about the average overlap density of  than that it is at least 1/2. Indeed, there are two natural set systems to consider here: one is
than that it is at least 1/2. Indeed, there are two natural set systems to consider here: one is  and the other is
and the other is  . If
. If 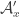 has average overlap density at least
has average overlap density at least  , then
, then  should have average overlap density a bit bigger than this.
should have average overlap density a bit bigger than this.
January 30, 2016 at 11:34 am |
I’ve done some more experimentation with Igor’s conjecture (7 above), this time following Tim’s suggestion of starting with a random upward-closed family and successively removing random abundant elements from random sets until one loses the desired property (or finds a counterexample). There are several tweakable parameters here, of course. But it seems difficult with this method to get the maximum abundance of the smaller set anywhere near while maintaining the property.
while maintaining the property.
January 30, 2016 at 5:15 pm
That’s not quite correct: it is easy to get the maximum abundance close to by taking
by taking 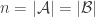 close to
close to 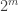 where
where  is the size of the ground set. Then
is the size of the ground set. Then  and
and  approach the power set, and the maximum abundance approaches
approach the power set, and the maximum abundance approaches  . But I’ve found no counterexamples to the conjecture.
. But I’ve found no counterexamples to the conjecture.
January 30, 2016 at 12:34 pm |
In the hunt for a strengthening amenable to induction, I really want to combine strengthenings 3 (off-diagonal) and 6 (average overlap density). It seems to me that there are two issues that immediately arise with an induction argument where we split the cube into the sets contain x and the sets not containing x:
1) The property of “having an abundant element” doesn’t play nicely with the split. If and
and 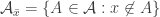 have an abundant element, we know little about abundance in
have an abundant element, we know little about abundance in  .
.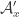 and
and 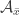 , the condition of “union-closed” becomes complicated – in fact, it becomes a few off-diagonal statements like
, the condition of “union-closed” becomes complicated – in fact, it becomes a few off-diagonal statements like 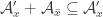 .
.
2) When we split into
2) is the problem that led me to want an off-diagonal conjecture. And 1) could be solved by a suitable averaging strengthening, like average overlap density.
January 30, 2016 at 9:22 pm
I had the same thought regarding problem 2) a while back, but I didn’t know how to deal with problem 1). It would indeed be interesting to engineer an “off-diagonal” and “averaged” conjecture that we could apply induction to.
January 31, 2016 at 10:16 am
Maybe a way to tackle the complication of the union-closed property when one splits is to do so head on. That is, perhaps one could take a subset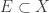 and for each
and for each 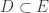 let
let 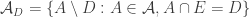 . Then we could try to work out what properties the set systems
. Then we could try to work out what properties the set systems 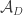 must have. Actually, maybe that’s not so hard: I think we get that
must have. Actually, maybe that’s not so hard: I think we get that 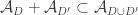 . That looks as though it might conceivably be a condition one could work with, perhaps by generalizing the original conjecture a lot. Note that if we set
. That looks as though it might conceivably be a condition one could work with, perhaps by generalizing the original conjecture a lot. Note that if we set 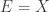 , then
, then 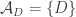 if
if 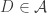 and
and  otherwise, so in that case the condition above is just the condition that
otherwise, so in that case the condition above is just the condition that  is union closed.
is union closed.
January 31, 2016 at 3:20 pm
One idea along these lines that doesn’t work out: I wondered whether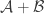 being small meant that one of the average overlap densities
being small meant that one of the average overlap densities 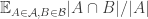 and
and 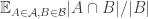 had to be large.
had to be large.
But that’s not true, even for and
and  union-closed. If
union-closed. If  and
and 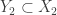 , we can take
, we can take 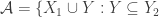 and
and 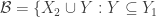 . The
. The  , but both the average overlap densities are very small if the
, but both the average overlap densities are very small if the 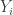 are much smaller than the
are much smaller than the  .
.
January 31, 2016 at 9:35 am |
I have now started to generate intersection closed set systems via strong divisibility sequences. While it was clear from the beginning that we cannot expect to get easy counter examples here I thought that the larger the sets get the closer to a counter example they go. This is false and the reason is quite obvious. I just do not have enough sets in my set system and thus run inside the regime where FUNC is known to be true.
To give you an idea of what is going on. If I take the sets of prime divisors of the first 10,000 numbers I get a system with 6,083 sets with 1,229 elements. Let denote the set system and
denote the set system and  the set of primes used. The concept of average overlap densitiy should translate like
the set of primes used. The concept of average overlap densitiy should translate like
If that is true the above set system has average overlap density > 99.8%.
How to proceed? Let me take out (from ) the sets that contain elements with the lowest frequency as long as this frequency is less or equal to 1/2. Then I check whether I get a counter example or the empty set. If this is not the case I repeat. Does such an (inductive) approach have a chance to achieve something? In our situation we are ultimately talking about taking numbers from sets and so there might be some (very small) chance that we can describe the algorithm by some sort of sifting procedure.
) the sets that contain elements with the lowest frequency as long as this frequency is less or equal to 1/2. Then I check whether I get a counter example or the empty set. If this is not the case I repeat. Does such an (inductive) approach have a chance to achieve something? In our situation we are ultimately talking about taking numbers from sets and so there might be some (very small) chance that we can describe the algorithm by some sort of sifting procedure.
January 31, 2016 at 3:36 pm |
[…] discuss together what directions to peruse. It is a pleasure to mention that in parallel Tim Gowers is running polymath11 aimed for resolving Frankl’s union closed conjecture. Both questions were offered along with […]
January 31, 2016 at 9:22 pm |
Another potential variant/weakening of FUNC:
Let be a union-closed family of
be a union-closed family of  sets, and define the abundancy of a set of elements to be the proportion of sets of
sets, and define the abundancy of a set of elements to be the proportion of sets of  which contain all elements of that set.
which contain all elements of that set.
FUNC says that some set of size has abundancy at least
has abundancy at least  , which trivially implies that, for every
, which trivially implies that, for every  , there exists some
, there exists some  -set which has abundancy at least
-set which has abundancy at least 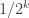 .
.
Let -FUNC be this generalised statement, so that regular FUNC is
-FUNC be this generalised statement, so that regular FUNC is  -FUNC, and we conjecture that
-FUNC, and we conjecture that  -FUNC holds for all union closed families with at least
-FUNC holds for all union closed families with at least  sets. Note that the other extremal case, when
sets. Note that the other extremal case, when 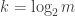 , is trivially true.
, is trivially true.
There are a number of possible ways to fiddle with this setup to produce weaker, more asymptotic, statements. For example, how about the following family of conjectures.
Fix a decreasing function![F:\mathbb{N}\to (0,1]](https://s0.wp.com/latex.php?latex=F%3A%5Cmathbb%7BN%7D%5Cto+%280%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . For every
. For every  and union-closed family of at least
and union-closed family of at least 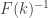 sets some
sets some  -set has abundancy at least
-set has abundancy at least 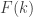 .
.
FUNC is then equivalent to this statement with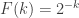 . As a weakening, can this conjecture be established with any function such that
. As a weakening, can this conjecture be established with any function such that 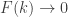 as
as 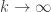 ?
?
February 1, 2016 at 8:46 pm
I like this -FUNC conjecture. It seems a natural generalization, and a little experimentation with random union-closed families suggests it stands a chance of being true.
-FUNC conjecture. It seems a natural generalization, and a little experimentation with random union-closed families suggests it stands a chance of being true.
February 2, 2016 at 8:11 am
Just as for strengthening 6 above, one could recklessly strengthen this further to the conjecture that if you choose a random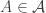 with
with  and a random
and a random  -element subset
-element subset 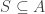 , the number of
, the number of 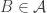 containing
containing  is at least
is at least  on average. This is equivalent to the statement that
on average. This is equivalent to the statement that 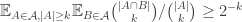 .
.
February 1, 2016 at 6:36 am |
Does anyone know where to find the article by Sarvate and Renaud on the conjecture? Or, more specifically, what is the counter-example they gave to 3 element ground set case?
February 1, 2016 at 8:05 am
I could not find it also but I believe the example you look for is also on Poonen’s paper in the non-theorems section
February 1, 2016 at 8:57 am
Tried to post the example but something went wrong. It is also quoted here: http://mathoverflow.net/q/228124
February 1, 2016 at 9:46 am
Since the ground set in this example has seven elements, it can’t be the set system that Thomas Bloom obtains by putting together two power sets using construction method 7. It would be good to have it clarified exactly what the relationship between these two examples is. In particular, is the exact example of Sarvate and Renaud (as listed on mathoverflow) obtainable by a nice construction method?
February 1, 2016 at 10:13 am
Which example do you mean when you say it has a ground set of 7 elements? Is this in Poonen’s paper?
The survey article (on p.15) describes a general construction for a UC family with a -element set none of whose elements are abundant. I haven’t checked whether this gives the Sarvate–Renaud example for
-element set none of whose elements are abundant. I haven’t checked whether this gives the Sarvate–Renaud example for  (but it does give an example with 9 elements).
(but it does give an example with 9 elements).
February 1, 2016 at 12:42 pm
Oops, sorry, I meant the one on Mathoverflow, which has nine elements in its ground set.
February 1, 2016 at 4:05 pm
Actually, never mind, I worked that one out. I’m now working on the idea of induction on the original problem. If we have a family of union closed sets F with one element x in at least half of them, we can extend this to a different set G such that if S is in F then either S or SU{y}, or both, are in G, and make sure that G is union closed. All that needs to be shown is that the number of sets in G containing both x and y is greater than the number of sets containing neither of them, and the induction will be complete. Unfortunately, I don’t think that last step will be that easy to prove (or even true).
February 1, 2016 at 1:29 pm |
Here’s another idea at a generalization that somebody else might be able to shoot down. As explained in the survey, one way to look for a proof of FUNC is to find and an injective map from
and an injective map from  to
to  .
.
Now I wonder whether it is always possible to find such an injection which in addition preserves unions, i.e. which satisfies
which in addition preserves unions, i.e. which satisfies 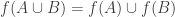 . It’s easy to see that this is indeed the case in the examples 1. to 3. of the original post, is unaffected by 5. (duplicating elements), and also invariant under the union-sets construction 6., at least in the case of disjoint ground sets.
. It’s easy to see that this is indeed the case in the examples 1. to 3. of the original post, is unaffected by 5. (duplicating elements), and also invariant under the union-sets construction 6., at least in the case of disjoint ground sets.
In terms of the lattice formulation of the survey, I’m asking whether one can always find a meet-preserving map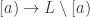 . The proof of Theorem 3, which shows that FUNC holds for all lower semimodular lattices, proceeds via constructing the injection
. The proof of Theorem 3, which shows that FUNC holds for all lower semimodular lattices, proceeds via constructing the injection 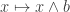 . This trivially preserves meets.
. This trivially preserves meets.
February 1, 2016 at 1:42 pm
Also the Sarvate-Renaud example has a union-preserving injection: the union-presering map injects
injects 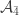 into
into  .
.
Inspired by this, here’s a further strengthening: does there always exist and
and  with
with  such that the map
such that the map

is injective?
Now this certainly looks much too strong to be true, doesn’t it…?
February 1, 2016 at 3:14 pm
It certainly does. But it would be very nice to have a counterexample, given that the recipes in the post don’t work. (Of course, I’d settle for a proof …)
February 1, 2016 at 3:51 pm
Do we know a small example of a lattice that is not lower semimodular ?
February 1, 2016 at 4:12 pm
The smallest nonmodular lattice is : https://en.wikipedia.org/wiki/Lattice_%28order%29#/media/File:N_5_mit_Beschriftung.svg
: https://en.wikipedia.org/wiki/Lattice_%28order%29#/media/File:N_5_mit_Beschriftung.svg isn’t semimodular either. But it’s also not a counterexample to my strong conjecture. In its lattice version, the conjecture would state that there exists a join-irreducible element
isn’t semimodular either. But it’s also not a counterexample to my strong conjecture. In its lattice version, the conjecture would state that there exists a join-irreducible element  and a lattice element
and a lattice element  such that
such that 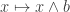 is an injection from
is an injection from 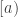 into
into 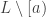 . To see this for
. To see this for  , just take
, just take  and
and  as labelled in the picture. (I’m using the notation from the survey, where
as labelled in the picture. (I’m using the notation from the survey, where  is the lattice and
is the lattice and 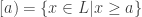 the upper set.)
the upper set.)
It’s easy to see
I don’t know any less trivial examples. As far as I understand, semimodularity of a lattice (very) roughly means that its Hasse diagram contains plenty of diamonds and that it permits a ‘dimension function’ stratifying the Hasse diagram into ‘levels’. So it might help to come up with lattices that don’t have these features.
February 1, 2016 at 5:17 pm
An attempt at a counterexample. In Polymath spirit I’ll start writing this comment before finding out whether it has any chance of working. Let’s just take all subsets of of size
of size 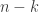 , where
, where  is some fairly small number like 2. Let’s try
is some fairly small number like 2. Let’s try 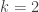 . Without loss of generality
. Without loss of generality 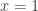 . Then there are
. Then there are  sets in
sets in  that do not contain
that do not contain  . Hmm, this fails miserably since we can take
. Hmm, this fails miserably since we can take 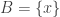 . What on earth made me think it could possibly work?
. What on earth made me think it could possibly work?
I wanted to exploit the fact that the union of two very large sets is almost always . Here’s a second attempt. Take a random bunch of quite a lot, but not too many, sets of size
. Here’s a second attempt. Take a random bunch of quite a lot, but not too many, sets of size  , and let
, and let  consist of their complements and all unions of their complements. Let
consist of their complements and all unions of their complements. Let 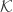 be the collection of
be the collection of  -sets.
-sets.
For a set to satisfy the conclusion of the strengthened conjecture, we need in particular that
to satisfy the conclusion of the strengthened conjecture, we need in particular that 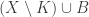 is a union of sets of the form
is a union of sets of the form  for every
for every 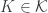 . That is, we need
. That is, we need 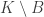 to be an intersection of sets in
to be an intersection of sets in 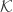 for each
for each 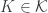 . For the injectivity property we need the sets
. For the injectivity property we need the sets 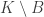 to be distinct.
to be distinct.
Suppose, in an attempt to make that hard to achieve, we take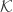 to be a Steiner triple system. That is, every pair of elements of
to be a Steiner triple system. That is, every pair of elements of  is contained in exactly one set in
is contained in exactly one set in 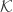 . If we take
. If we take  to be a singleton
to be a singleton  , then some of the sets
, then some of the sets 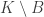 are pairs, and no pair is an intersection of sets in
are pairs, and no pair is an intersection of sets in 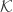 . If we take
. If we take  to be a pair
to be a pair 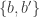 , then at most one set will contain
, then at most one set will contain  , so there will be many sets that contain
, so there will be many sets that contain  but not
but not 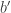 , so again there will be many sets
, so again there will be many sets 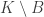 that are pairs, and so not intersections of sets in
that are pairs, and so not intersections of sets in 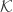 .
.
What if is quite a lot bigger? Then there is a significant danger that we will be able to find some
is quite a lot bigger? Then there is a significant danger that we will be able to find some  and elements
and elements 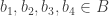 such that
such that 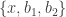 and
and 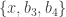 both belong to
both belong to 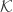 .
.
That’s not exactly a proof, but I think it might be an idea worth pursuing.
February 1, 2016 at 5:22 pm
Maybe it’s easier than I thought. We have problems if there is ever a set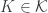 such that
such that 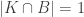 , since then
, since then 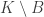 is a pair. But in that case if we look at all the sets that contain some element
is a pair. But in that case if we look at all the sets that contain some element  , we find that their union is all of
, we find that their union is all of  (since we must cover each pair
(since we must cover each pair  ) and they all intersect
) and they all intersect  either in a set of size 2 or an empty set. Also, they are disjoint apart from their intersection at
either in a set of size 2 or an empty set. Also, they are disjoint apart from their intersection at  . So we get exactly the situation I described when I asked about what happens when
. So we get exactly the situation I described when I asked about what happens when  is quite a lot bigger.
is quite a lot bigger.
So I think this is a counterexample to the ludicrously strong conjecture, but as always there’s at least a 40% chance that I’ve made a silly mistake, as I have not checked this argument carefully.
February 1, 2016 at 9:11 pm
I suppose I should also check whether this example disposes of the first conjecture. So let . Then looking at complements, we would like to find an injection from the sets in
. Then looking at complements, we would like to find an injection from the sets in  that contain
that contain  to the sets in
to the sets in  that don’t contain
that don’t contain  , and this injection needs to preserve intersections.
, and this injection needs to preserve intersections.
Now the intersection of two sets that contain is just
is just  , so if
, so if 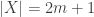 , then this says that we need to find
, then this says that we need to find  sets in
sets in 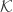 none of which contain
none of which contain  and all of which have the same intersection. That intersection can’t be
and all of which have the same intersection. That intersection can’t be  because we don’t have
because we don’t have  elements to play with. It can’t be a singleton because we don’t have
elements to play with. It can’t be a singleton because we don’t have  elements to play with. It can’t be a pair because no pairs occur as intersections. And it can’t be a triple because no triple occurs as an intersection (of distinct sets in
elements to play with. It can’t be a pair because no pairs occur as intersections. And it can’t be a triple because no triple occurs as an intersection (of distinct sets in  , that is).
, that is).
So I think this example shows that even the first conjecture is false, which suggests that finding a “structural” proof may be hard.
February 2, 2016 at 8:48 am
Wow! I’ve tried to walk through these arguments in the case of the Fano plane as the smallest nontrivial Steiner triple system. Confusingly, I seem to have found that the Fano plane *does* satisfy even the ludicrously strong conjecture. Following your idea, the intersection-closed set system consists of the 7 Fano lines, the 7 vertices and the empty set. When I say ‘set’ in the following paragraph, I’m referring to one of these.
In terms of the standard way of drawing the Fano plane, suppose that the rare element is the central vertex. Then there are four sets that contain
is the central vertex. Then there are four sets that contain  , namely the three interior lines and
, namely the three interior lines and  itself. By taking the intersection with the circular Fano line, we map these four sets to sets that don’t contain
itself. By taking the intersection with the circular Fano line, we map these four sets to sets that don’t contain  in an injective manner, namely to three vertices plus the empty set. This verifies the ludicrously strong conjecture. Or am I just being dense…?
in an injective manner, namely to three vertices plus the empty set. This verifies the ludicrously strong conjecture. Or am I just being dense…?
February 2, 2016 at 12:15 pm
The density was entirely mine. I was unthinkingly assuming that each triple in would have to map to a triple in
would have to map to a triple in  , but it can map to a singleton, as your counter-counterexample shows. However, I think my basic idea may not be completely dead. I’ll start a separate comment thread below and have another try.
, but it can map to a singleton, as your counter-counterexample shows. However, I think my basic idea may not be completely dead. I’ll start a separate comment thread below and have another try.
February 1, 2016 at 3:17 pm |
I agree that, put like that, your second conjecture seems too strong to be true, but I can’t find a counterexample.
if this strengthened version were true, however, it would fix the gap in the argument I had on the last blog post, so it would imply the strengthened FUNC with arbitrary weight functions (i.e. version 2 in this blog post).
February 1, 2016 at 4:27 pm
This was, of course, intended to be a reply to Tobias Fritz’s comment above.
February 2, 2016 at 12:45 pm |
Here is another attempt to disprove Tobias Fritz’s strengthenings of FUNC. I shall take complements and discuss the following equivalent problems.
1. Let be an intersection-closed set system. Then there exists
be an intersection-closed set system. Then there exists  and an intersection-preserving injection
and an intersection-preserving injection  from
from  to
to 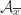 .
.
2. As 1 but with the added conclusion that is of the form
is of the form 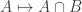 for some fixed
for some fixed  .
.
I thought I had shown that a Steiner triple system is a counterexample to 1 (and therefore 2), but my proof was wrong, because I accidentally assumed that triples had to map to triples. Now I want to explore what happens if I take a quadruple system — that is, a collection of 4-sets that covers each 2-set exactly once. (If this basic approach works, I think it should be possible to get a similar proof that doesn’t require results from design theory by taking suitable random collections of -sets and taking their intersections. But I may as well try to keep the proof simple by relying on whatever I want — even Keevash’s big theorem if necessary.)
-sets and taking their intersections. But I may as well try to keep the proof simple by relying on whatever I want — even Keevash’s big theorem if necessary.)
What does look like in this case? Well, we know that each pair that contains
look like in this case? Well, we know that each pair that contains  is in exactly one 4-set from
is in exactly one 4-set from  , so this tells us that the sets
, so this tells us that the sets 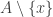 with
with 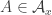 of size 4 form a partition of
of size 4 form a partition of 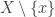 . Also,
. Also,  contains all sets of the form
contains all sets of the form 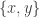 , and the singleton
, and the singleton  .
.
I would now like to argue that if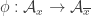 preserves intersections, then
preserves intersections, then  cannot map to the empty set. So let’s assume for a contradiction that it does.
cannot map to the empty set. So let’s assume for a contradiction that it does.
Observe first that if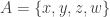 is a quadruple in
is a quadruple in  , then the pairs
, then the pairs 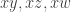 map to disjoint non-empty sets. Moreover, these sets must be subsets of
map to disjoint non-empty sets. Moreover, these sets must be subsets of 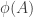 . Since
. Since 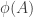 must be a quadruple if it has size at least 3, it must be a quadruple. (This is the key new ingredient to the argument.)
must be a quadruple if it has size at least 3, it must be a quadruple. (This is the key new ingredient to the argument.)
At this point, letting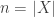 , we have
, we have 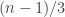 quadruples in
quadruples in  that must map to disjoint quadruples in
that must map to disjoint quadruples in 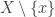 , which requires that
, which requires that 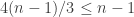 , which ain’t gonna happen. (I think we can allow ourselves not to worry about the case
, which ain’t gonna happen. (I think we can allow ourselves not to worry about the case 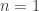 .)
.)
So I think we now have that must map to a non-empty set
must map to a non-empty set  . Again let’s think about what must happen to the quadruples in
. Again let’s think about what must happen to the quadruples in  . For any two of these, the intersection is
. For any two of these, the intersection is  , so we need to find
, so we need to find 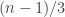 sets in
sets in 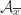 such that any two of them intersect in
such that any two of them intersect in  .
.
If is a singleton
is a singleton 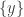 and all the sets we take are quadruples, then we don’t have enough elements (since we can’t use
and all the sets we take are quadruples, then we don’t have enough elements (since we can’t use  or
or  for the remaining three elements). What happens if some quadruple
for the remaining three elements). What happens if some quadruple  in
in  maps to a pair
maps to a pair  that contains
that contains  ? That looks to me like a problem because the three pairs in
? That looks to me like a problem because the three pairs in  that contain
that contain  must map to distinct subsets of
must map to distinct subsets of  that properly contain
that properly contain  , and we don’t have that. So I think quadruples have to go to quadruples still.
, and we don’t have that. So I think quadruples have to go to quadruples still.
Let me just check whether that is a general lemma. My claim is that (without assuming that goes to the empty set) quadruples have to go to quadruples. The idea is that if
goes to the empty set) quadruples have to go to quadruples. The idea is that if 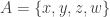 is a quadruple in
is a quadruple in  , then the images of the sets
, then the images of the sets 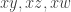 and
and  (omitting the set brackets because I’m getting tired of writing them) have to go to distinct subsets of
(omitting the set brackets because I’m getting tired of writing them) have to go to distinct subsets of 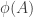 and if
and if 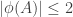 then we don’t have an intersection-preserving bijection that does the job.
then we don’t have an intersection-preserving bijection that does the job.
However, I’m not out of the woods quite yet. I think I’ve shown that can’t be empty or a singleton, but what if it is a pair? Ah, that is completely impossible, since I can find at most one quadruple in
can’t be empty or a singleton, but what if it is a pair? Ah, that is completely impossible, since I can find at most one quadruple in  that contains
that contains  .
.
OK, as cranks like to say, if you think this is wrong, then can you find a counter-counterexample? That is, can you exhibit a Steiner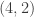 -system
-system  and an intersection-preserving injection from some
and an intersection-preserving injection from some  to
to 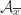 ?
?
February 2, 2016 at 2:39 pm
I would perfectly agree with this argument, if it wasn’t for the statement “Also, contains all sets of the form
contains all sets of the form 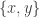 “. How is this compatible with working with a Steiner
“. How is this compatible with working with a Steiner 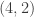 -system…?
-system…?
In fact, I suspect that the projective plane over the field with three elements is a counter-counterexample. It’s a Steiner
over the field with three elements is a counter-counterexample. It’s a Steiner 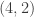 -system since any two points lie on a unique line, and all lines are
-system since any two points lie on a unique line, and all lines are 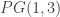 ‘s, so that they contain four points. Now for any point
‘s, so that they contain four points. Now for any point  , the resulting
, the resulting  is also a
is also a 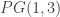 , meaning that it consists of four lines that only intersect in
, meaning that it consists of four lines that only intersect in  . Now choose any other line that doesn’t contain
. Now choose any other line that doesn’t contain  . Intersecting the sets in
. Intersecting the sets in  with this line results in the desired map
with this line results in the desired map 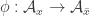 , which apparently verifies the ludicrously strong conjecture in this case.
, which apparently verifies the ludicrously strong conjecture in this case.
For what it’s worth, there’s an illustration of on p.42 of this beautiful book: http://www.uwyo.edu/moorhouse/handouts/incidence_geometry.pdf
on p.42 of this beautiful book: http://www.uwyo.edu/moorhouse/handouts/incidence_geometry.pdf
The gist of why this seems to work is probably that doesn’t have any interesting order structure: all the nontrivial sets in there are incomparable. In other words, the lattice for which we’re probing the conjecture has a height of only 4 (bottom, top, a level of atoms and a level of coatoms), and this seems to be too small.
doesn’t have any interesting order structure: all the nontrivial sets in there are incomparable. In other words, the lattice for which we’re probing the conjecture has a height of only 4 (bottom, top, a level of atoms and a level of coatoms), and this seems to be too small.
Thinking along these lines, it might be better to consider lattices of height 5, such as the face lattice of a 3-dimensional polytope. Consider e.g. the dodecahedron: simply by visual inspection, I have the impression that the ludicrously strong conjecture can’t possibly hold for its face lattice, but I haven’t yet found a rigorous and complete proof.
Of course, any pointers to errors in my reasoning will be very welcome.
February 2, 2016 at 2:41 pm
To clarify my question about the sets of the form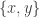 : I don’t understand how those are supposed to arise as intersections of blocks in the Steiner system.
: I don’t understand how those are supposed to arise as intersections of blocks in the Steiner system.
February 2, 2016 at 3:04 pm
Oh dear, I need to get my brain properly into gear before writing out long arguments. This time I somehow fooled myself into thinking that the pairs were all in because they are all covered, despite making crucial use of the fact that they were not intersections of sets in the system later on in the argument.
because they are all covered, despite making crucial use of the fact that they were not intersections of sets in the system later on in the argument.
I still feel that something along these lines ought to work though. Back to the drawing board.
February 2, 2016 at 3:26 pm |
I’m not necessarily going to finish this comment, but let me see whether I can prove that a Steiner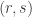 -system
-system  works for some
works for some 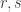 . For now I won’t specify the values of
. For now I won’t specify the values of  and
and  .
.
Since each -set is covered exactly once, the number of sets in
-set is covered exactly once, the number of sets in  is
is 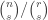 . Given any
. Given any 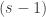 -set
-set  , let
, let 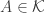 contain
contain  and let
and let  . Then
. Then 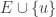 must be covered by some set
must be covered by some set 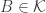 , which gives us two sets in
, which gives us two sets in  that intersect in
that intersect in  . So the intersection closure of
. So the intersection closure of  is, if I’m not much mistaken (a highly non-trivial assumption)
is, if I’m not much mistaken (a highly non-trivial assumption)  together with all sets of size at most
together with all sets of size at most 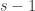 . Let this intersection closure be
. Let this intersection closure be  .
.
Now let be an intersection-preserving injection from
be an intersection-preserving injection from  to
to 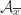 .
.
From my last, failed, attempt, it seems like a good idea to try to prove that the image of a set of size must have size
must have size  . So let
. So let 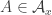 have size
have size  .
.
We know that if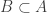 belongs to
belongs to  , then
, then 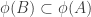 . Therefore, we have an injection from subsets of
. Therefore, we have an injection from subsets of  of size at most
of size at most 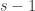 that contain
that contain  to proper subsets of
to proper subsets of 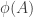 . There are at least
. There are at least 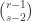 subsets of the first kind. If
subsets of the first kind. If 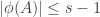 , then there are at most
, then there are at most 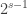 sets of the second kind. So this is impossible if
sets of the second kind. So this is impossible if 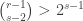 , something we can easily arrange to happen by choosing appropriate
, something we can easily arrange to happen by choosing appropriate  and
and  .
.
As a sanity check, let me see what happens with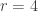 and
and  . There I get
. There I get  versus
versus 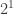 and the condition does not hold, which is reassuring …
and the condition does not hold, which is reassuring …
So now I know (in the “know until Tobias points out my stupid mistake” sense) that the -sets in
-sets in  have to map to
have to map to  -sets in
-sets in 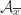 . Moreover, their images must all contain the set
. Moreover, their images must all contain the set 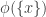 .
.
I’ll think for a moment and then continue.
February 2, 2016 at 3:56 pm
I’m now going to make an additional assumption about , which is that for each
, which is that for each  we can find sets in
we can find sets in  with union
with union  and with all intersections equal to
and with all intersections equal to  . This doesn’t follow from the definition of a design, but my guess is that it is achievable if one runs Keevash’s argument carefully or modifies it slightly.
. This doesn’t follow from the definition of a design, but my guess is that it is achievable if one runs Keevash’s argument carefully or modifies it slightly.
In that case, the arguments I gave in my wrong proof show that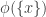 cannot be empty or a singleton, since in both cases one has a system of disjoint sets with cardinalities that add up to something too big. (In the first case we get
cannot be empty or a singleton, since in both cases one has a system of disjoint sets with cardinalities that add up to something too big. (In the first case we get 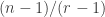 disjoint subsets of
disjoint subsets of 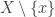 of size
of size  , and in the second case we get that number of disjoint subsets of a set
, and in the second case we get that number of disjoint subsets of a set 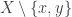 of size
of size  .)
.)
But I still need to rule out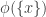 having cardinality greater than 1, which is no longer trivial since we have sets in the system of sizes up to
having cardinality greater than 1, which is no longer trivial since we have sets in the system of sizes up to 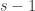 .
.
Let’s suppose that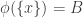 is a set of size 2. There are
is a set of size 2. There are 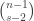 sets of size
sets of size 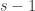 that contain
that contain  , and these must inject to sets in
, and these must inject to sets in 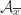 that contain
that contain  . If they map to sets of size
. If they map to sets of size 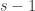 , then we have problems because
, then we have problems because 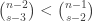 . They can’t map to sets of size less than
. They can’t map to sets of size less than 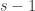 because all their subsets need to map nicely to subsets as well.
because all their subsets need to map nicely to subsets as well.
The one case I don’t yet see how to rule out is that some sets of size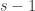 map to sets of size
map to sets of size  . But I think that should be impossible. I’ll post this comment and think further.
. But I think that should be impossible. I’ll post this comment and think further.
February 2, 2016 at 4:03 pm
Ah, that’s easily shown to be impossible. If a set of size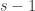 maps to a set of size
maps to a set of size  , then there is nowhere for any superset of size
, then there is nowhere for any superset of size  to map to.
to map to.
So I now have yet another argument that feels right but may well be wrong. In this case, I have made a further assumption about the Steiner system but (i) I think that systems satisfying this further assumption probably exist and (ii) if this proof is correct, then probably one can find another proof that avoids this extra assumption, which I made mainly out of laziness.
February 2, 2016 at 4:21 pm
I forgot to mention that if above has size bigger than 2, then things get even worse, so I think the argument is complete. However, I won’t feel happy about it unless someone OKs it.
above has size bigger than 2, then things get even worse, so I think the argument is complete. However, I won’t feel happy about it unless someone OKs it.
February 2, 2016 at 5:01 pm
Very nice! Now I don’t see anything wrong with the argument. As far as I can see, it should be possible to choose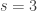 and
and 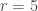 . So what is the smallest
. So what is the smallest  for which a
for which a  -Steiner system exists? The following webpage has examples with
-Steiner system exists? The following webpage has examples with  and
and 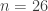 . Does anyone know interesting ways of constructing these?
. Does anyone know interesting ways of constructing these?
February 2, 2016 at 5:02 pm
Sorry, I forgot the link: https://www.ccrwest.org/cover/steiner.html
February 2, 2016 at 5:11 pm
Phew!
February 2, 2016 at 5:17 pm
I’ve just checked the example with and luckily it satisfies the extra condition, since it contains the sets {1,2,3,7,14}, {1,4,9,11,13}, {1,5,12,16,17} and {1,6,8,10,15} and is cyclically symmetric.
and luckily it satisfies the extra condition, since it contains the sets {1,2,3,7,14}, {1,4,9,11,13}, {1,5,12,16,17} and {1,6,8,10,15} and is cyclically symmetric.
February 2, 2016 at 5:27 pm
For another concrete example, projective 3-space over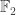 should work, with
should work, with 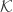 being the collection of projective planes (=Fano planes). I think that this would have parameters
being the collection of projective planes (=Fano planes). I think that this would have parameters 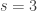 (three points determine a unique plane),
(three points determine a unique plane), 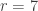 (size of the Fano plane), and
(size of the Fano plane), and 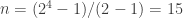 . Off the top of my head I’m not totally sure about the extra condition, though.
. Off the top of my head I’m not totally sure about the extra condition, though.
In any case, I’m glad that the conjecture seems to be resolved! But unfortunately, since the intersection-closed families constructed this way feel quite ‘bottom-heavy’, this doesn’t look like a good way to look for counterexamples to FUNC itself, or does it?
February 2, 2016 at 6:28 pm
I thought about that earlier today. I think it should probably be possible to prove that no Steiner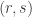 -system can work and have done a few calculations with that in mind. It would probably be a worthwhile thing to complete them, just to make sure. At some point soon I’ll try to say where I got to.
-system can work and have done a few calculations with that in mind. It would probably be a worthwhile thing to complete them, just to make sure. At some point soon I’ll try to say where I got to.
I also wonder whether it might be possible to prove a weakening of FUNC where one assumes that the set system has quite a lot of symmetry — an obvious hypothesis being that its symmetry group acts transitively on the ground set. Is there some easy argument that does this case?
The two questions are loosely related, since a design, though not necessarily symmetric, is at least highly balanced. Maybe one could prove a fairly general result that FUNC is true for sufficiently balanced systems, for some suitable notion of “balanced”.
February 3, 2016 at 6:49 am
Forget about projective 3-space (in my last comment): it’s not even a Steiner system! It’s true that every triple of points is contained in a plane, but this plane is not unique if the points are collinear…
February 3, 2016 at 12:35 pm
If we want to take this a bit further still, we could try to find examples in which not even an injective and /monotone/ map exists.
exists.
Tim’s argument already goes quite some way to proving this: the only case for which he actually needs the preservation of unions–as opposed to mere monotonicity–is in the paragraph where he shows that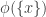 can’t be empty or a singleton.
can’t be empty or a singleton.
February 2, 2016 at 5:38 pm |
On sort of a whim, I decided to program a naive random union-closed family generator and see if it led me to anything interesting. My initial process is very simple, but it does work. I start by choosing a universe (i.e. choosing an , and having everything live in the integers from
, and having everything live in the integers from  to
to  ), a probability parameter
), a probability parameter  , and a number
, and a number  of sets. Then I create these
of sets. Then I create these  sets in the following (possibly too simple) way: each integer up to
sets in the following (possibly too simple) way: each integer up to  has probability
has probability  of being included. Finally, I take the closure under unions of the family.
of being included. Finally, I take the closure under unions of the family.
I’ve learned a few things, and some thoughts have jumped out at me. I think I’d like to carry on this experiment forward a bit and implement checkers on some of the proposed strengthenings mentioned above [if possible].
But one thing is very obvious to me — this is not a good way of generating “interesting” union-closed families, and almost always the resulting families have over half of the elements as being in at least half of the sets. I’m not quite sure what to change yet, but it’ll be hanging around my thoughts.
February 2, 2016 at 6:48 pm
I agree that it would be very interesting to try to come up with a random model that produces “promising” examples. One feature I would expect such a model to have is that if you take a minimal generating set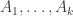 , then there are many coincidences amongst the unions of the
, then there are many coincidences amongst the unions of the  , so that in some sense we don’t get too many large sets. This seems unlikely to happen when the
, so that in some sense we don’t get too many large sets. This seems unlikely to happen when the  are chosen purely randomly, but perhaps there is some clever way of choosing a random object and then converting it deterministically into a “low-dimensional” system, or something like that.
are chosen purely randomly, but perhaps there is some clever way of choosing a random object and then converting it deterministically into a “low-dimensional” system, or something like that.
February 3, 2016 at 11:00 am
To be a little more explicit about this, let’s suppose that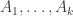 is a generating set for a set-system
is a generating set for a set-system  . That is,
. That is,  consists of all unions (including the empty union) that can be formed out of the
consists of all unions (including the empty union) that can be formed out of the  .
.
Suppose now that all those unions are distinct. In that case, it is trivial that has an element in half the sets. Indeed, we have
has an element in half the sets. Indeed, we have  different unions, and each
different unions, and each  is involved in half of them, so every element of every
is involved in half of them, so every element of every  is in at least half the unions.
is in at least half the unions.
So to have any hope of creating a counterexample to FUNC, one must find a generating set with the property that many unions coincide.
Can we be slightly more precise about this? For each set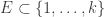 , write
, write 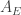 for the set
for the set 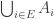 . And let’s say that
. And let’s say that 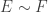 if
if 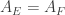 . Then the number of sets in
. Then the number of sets in  that contain
that contain  is the number of equivalence classes that contain a representative
is the number of equivalence classes that contain a representative  with
with 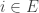 . And FUNC is satisfied if for some
. And FUNC is satisfied if for some  this is at least half the total number of equivalence classes.
this is at least half the total number of equivalence classes.
It’s worth making the trivial remark that there exist equivalence relations for which no such exists. For example, if each
exists. For example, if each  is the singleton
is the singleton 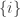 , we could define
, we could define  and
and  to be equivalent if they are either equal or both have size at least
to be equivalent if they are either equal or both have size at least  .
.
Actually, I’ve just noticed that this equivalence relation can occur. Let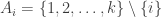 . Then any two distinct
. Then any two distinct  have union
have union 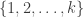 , so each
, so each  is contained in precisely two sets in
is contained in precisely two sets in  .
.
So what I needed to say earlier was not just that there should be many coincidences, but also that the sets should be small. To put it another way, I’ve just given a simple counterexample to the following strengthening of FUNC: every generating set of a union-closed family contains a set that is a subset of at least half the sets in .
.
So it seems as though what we’re looking for is lots of coincidences, but for those coincidences to occur for a “clever” reason, and not just because the sets we have taken are very large.
February 3, 2016 at 11:54 am
I’m not quite convinced that ‘to have any hope of creating a counterexample to FUNC, one must find a generating set with the property that many unions coincide’. In the extreme case where they’re all disjoint, we get (effectively) the power set, but is the power set a ‘worst case’ or a ‘best case’? In terms of minimizing the maximum abundance, it’s (conjecturally) optimal. It’s not clear (to me) whether counterexamples are more ‘likely’ in relatively small or large families (though there are results that rule out both very small and very large ones).
February 4, 2016 at 12:30 pm
In order to produce better random examples, how about starting with a fixed set of candidate generators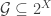 , and then choosing randomly for every
, and then choosing randomly for every 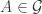 independently whether it will become an actual generator or not? For example, one could take
independently whether it will become an actual generator or not? For example, one could take 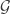 to consist of the 3-sets associated to a finite group as suggested in the other thread: https://gowers.wordpress.com/2016/01/29/func1-strengthenings-variants-potential-counterexamples/#comment-154131
to consist of the 3-sets associated to a finite group as suggested in the other thread: https://gowers.wordpress.com/2016/01/29/func1-strengthenings-variants-potential-counterexamples/#comment-154131 and randomly select a bunch of 3-sets
and randomly select a bunch of 3-sets 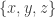 (with each element in the corresponding copy of
(with each element in the corresponding copy of  , and
, and 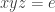 ). At the moment I find it hard to say whether this is likely to generate better examples or not.
). At the moment I find it hard to say whether this is likely to generate better examples or not.
Similarly, one could choose some finite group
It has also been suggested to me by Benjamin Matschke to look for counterexamples to FUNC in terms of the probabilistic method. Along these lines, I’ve been wondering whether something like the above prescription for generating union-closed families would let us apply the Lovász local lemma to the family of events “ has abundance at least 1/2″ in order to show that there is positive probability for all
has abundance at least 1/2″ in order to show that there is positive probability for all  to have abundance less than 1/2.
to have abundance less than 1/2.
So far, I don’t know of an interesting way to guarantee the necessary independence conditions on these events (or negative correlation conditions for the lopsided LLL).
February 4, 2016 at 1:00 pm
It might be interesting to explore generating random ‘normalized’ examples. These are discussed in section 3.5 of the survey article: a separating union-closed family is normalized if it contains the empty set and its size is one more than the size of its ground set; and FUNC is equivalent to the conjecture that every normalized family includes a basis set of at least half this size (a basis set being one that’s not a union of two other sets in the family). For example, one could generate random candidates by repeatedly adding sets that are just under half the target size and forming the union-closure until one either gets a family of the right size, or exceeds it (in which case start again).
February 4, 2016 at 4:47 pm
Interesting idea! I have implemented essentially this here:
https://cloud.sagemath.com/projects/da1aee8f-701b-4aa8-bc45-1a0a5e3f0d15/files/random_examples.sagews
Feel free to play with the program and improve the (very amateurish) code.
After a couple of runs, the smallest separating union-closed families with generators of size less than half of the ground set are as follows: for a ground set of size 15, the smallest family found has size 22; for a ground set of size 21, it’s 28. For all other sizes of the cardinalities the gaps are larger.
For a counterexample to the Salzborn formulation of FUNC, one would need a family whose cardinality is equal to the size of the ground set. My count is off by one with respect to the survey since my families don’t include the empty set.
I think that with a more intelligent selection of the generators these bounds will improve, but I have no good intuition for how low they can eventually get.
February 4, 2016 at 5:07 pm
For finding other ways to randomly generated union-closed families, it may be worth mentioning that every union-closed family has a ‘dual’ description, very much analogous to how every convex polytope has a description as the convex hull of its vertices, or dually as the intersection of a bunch of half-spaces.
Concretely, what I claim is that every union-closed family is equal to the solution set of a bunch of Horn clauses. Here, a Horn clause is an implication looking like this:

 that satisfy such a Horn clause is union-closed; more generally, the set of all
that satisfy such a Horn clause is union-closed; more generally, the set of all  ‘s that satisfy a bunch of Horn clauses is union-closed.
‘s that satisfy a bunch of Horn clauses is union-closed.
It’s easy to check that the set of all
The nontrivial part is to show that every union-closed family can be written in this form. If this turns out to be relevant, I can dig into some long forgotten memories and try to explain the details. There’s also these old notes of mine: http://personal-homepages.mis.mpg.de/fritz/2011/horn_formulas.pdf
The relevant part starts in the middle of p.5. The last page shows that I’ve already been obsessed with FUNC back then 😉
The reason that I’m mentioning this is that it provides another way to generate random union-closed families by randomly generating Horn clauses. However, whether this has the potential to result in more interesting union-closed families is totally unclear to me. Any thoughts?
February 2, 2016 at 6:44 pm |
One thought I had a little while ago was the following question. Suppose we could find a union-closed family with all abundances at most for some
for some 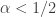 . Might there be some complicated product construction that would allow us to create for each
. Might there be some complicated product construction that would allow us to create for each  a new union-closed family with all abundances at most
a new union-closed family with all abundances at most  , and thus to show that if the conjecture itself is false, then so is the weaker conjecture that asks merely for an abundance of at least
, and thus to show that if the conjecture itself is false, then so is the weaker conjecture that asks merely for an abundance of at least  for some fixed positive
for some fixed positive  ? It would be nice if one could, because then it would be sufficient to prove the weaker conjecture.
? It would be nice if one could, because then it would be sufficient to prove the weaker conjecture.
An obvious product construction is to take two union-closed families and
and  defined on disjoint ground sets and take the union-closure of the collection of sets of the form
defined on disjoint ground sets and take the union-closure of the collection of sets of the form 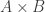 with
with 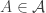 and
and 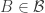 . But this feels far too naive to work. For obvious reasons, it isn’t easy to find a counterexample, but perhaps one can show that this naive product construction tends to behave in a way that makes it highly unlikely to work.
. But this feels far too naive to work. For obvious reasons, it isn’t easy to find a counterexample, but perhaps one can show that this naive product construction tends to behave in a way that makes it highly unlikely to work.
February 4, 2016 at 2:58 pm
I strongly suspect that if the conjecture is false and a construction method for generating a counterexample is found, then it could probably be used to generate union closed sets of arbitrarily small abundance, by continuing to use that construction. However, I don’t think your product construction would work, because just having a set of size x in A implies that one of the elements has abundance at least 1/2^x. So for this product to work, it would somehow have to go back and remove some of the elements.
February 4, 2016 at 4:41 pm
Ah, that’s a useful remark.
Actually, the most natural “product” of two families and
and  is probably the one where we make the ground sets disjoint and just take
is probably the one where we make the ground sets disjoint and just take 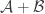 . This has size
. This has size 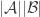 and is union closed, so the word “product” seems quite appropriate. Of course, it doesn’t change any abundances, so isn’t especially helpful for the conjecture or for the question of what one can deduce if the conjecture is false.
and is union closed, so the word “product” seems quite appropriate. Of course, it doesn’t change any abundances, so isn’t especially helpful for the conjecture or for the question of what one can deduce if the conjecture is false.
A more complicated version of the construction is to take union-closed families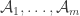 and a union-closed family
and a union-closed family  with ground set
with ground set  and then take all possible unions of the form
and then take all possible unions of the form 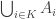 , where
, where 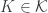 and
and  for each
for each  .
.
Suppose that the maximum abundance of an element of in
in  is
is  , and the maximum abundance in any of the
, and the maximum abundance in any of the 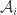 is
is  . Then if the ground set of
. Then if the ground set of 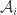 is
is  and
and 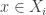 , we get that
, we get that  is involved in at most
is involved in at most 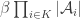 of the sets in
of the sets in  .
.
Unfortunately, this looks as though it is not going to give anything interesting, because if all the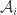 are fairly large, this set system hugely favours sets where
are fairly large, this set system hugely favours sets where  is large. I haven’t quite ruled out that it does something useful though. I’ll think a tiny bit and then write another comment.
is large. I haven’t quite ruled out that it does something useful though. I’ll think a tiny bit and then write another comment.
February 5, 2016 at 7:30 pm
Here’s an even more general ‘fibre bundle’ construction. Suppose that we have a union-closed family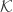 as well as a family of union-closed families
as well as a family of union-closed families  indexed by
indexed by 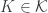 , and such that for every inclusion
, and such that for every inclusion  we have a homomorphism
we have a homomorphism 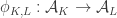 , such that
, such that 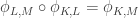 for every double inclusion
for every double inclusion 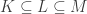 . The ground sets are irrelevant.
. The ground sets are irrelevant.
An element of the resulting combined family, denoted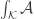 , is defined to be a pair
, is defined to be a pair 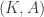 consisting of a
consisting of a 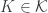 and an
and an 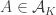 . The ‘union’ of a pair
. The ‘union’ of a pair 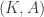 with another
with another  is defined to be
is defined to be 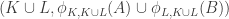 . In words: first transport both
. In words: first transport both  and
and  to their ‘common context’
to their ‘common context’  , and then take their union there. It may help to visualize all this in a bundle sort of way, especially since there’s a canonical homomorphism
, and then take their union there. It may help to visualize all this in a bundle sort of way, especially since there’s a canonical homomorphism 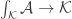 , which plays the role of the projection to the base space.
, which plays the role of the projection to the base space.
Tim’s previous construction is the special case of this where for all
for all  . Oh, and when I said ‘union’, I really meant ‘join’: since the ground sets have been abstracted away, this is really all about join-semilattices. Maybe there is a nice way to implement all this in terms of the ground sets, but I haven’t thought about it.
. Oh, and when I said ‘union’, I really meant ‘join’: since the ground sets have been abstracted away, this is really all about join-semilattices. Maybe there is a nice way to implement all this in terms of the ground sets, but I haven’t thought about it.
(Where did this come from? It’s secretly the Grothendieck construction from category theory, which turns a pseudofunctor into an opfibred category, specialized to the case of join-semilattices…)
I haven’t yet thought about what this does to abundances.
February 5, 2016 at 11:26 pm
I like this construction. It also seems to be closely related to a construction I gave in this comment, which I think makes it possible to carry out your implementation in a way that provides a ground set.
Given your construction above, let be the union of all the sets in
be the union of all the sets in  and let
and let  be the union of all the set systems
be the union of all the set systems 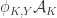 . We may take the ground set of
. We may take the ground set of  to be some set
to be some set  that is disjoint from
that is disjoint from  . Now take a set system
. Now take a set system  that consists of all sets of the form
that consists of all sets of the form  such that
such that  . This is union closed, and the map
. This is union closed, and the map  is a homomorphism from
is a homomorphism from  to
to  .
.
Conversely, given a union-closed family of subsets of
of subsets of  that projects to
that projects to  , let
, let 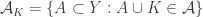 for each
for each 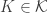 . Then … oh wait, this doesn’t seem to work. I don’t think we necessarily have a natural homomorphism from
. Then … oh wait, this doesn’t seem to work. I don’t think we necessarily have a natural homomorphism from  to
to  when
when  . For example, it could be that the only set that contains
. For example, it could be that the only set that contains  is
is 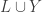 .
.
OK, so maybe this fibre bundle construction is more specific than just finding a homomorphism to .
.
February 6, 2016 at 11:01 am
Maybe I can get round the small difficulty I was having in the previous comment by insisting, in the converse direction, that each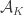 should contain the set
should contain the set  itself. Then we can define
itself. Then we can define 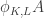 to be
to be 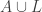 .
.
February 7, 2016 at 10:53 am
“let be the union of all the set systems
be the union of all the set systems 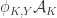 ”
”
Since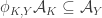 and the union includes the case
and the union includes the case 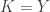 itself, I think that we get
itself, I think that we get 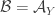 , no?
, no?
When all the ‘s are injective, then what you describe yields a nice concrete implementation of my abstract fibre bundle construction. But maybe it could also be interesting to consider some non-injective
‘s are injective, then what you describe yields a nice concrete implementation of my abstract fibre bundle construction. But maybe it could also be interesting to consider some non-injective  ?
?
Then you were asking what property characterizes those homomorphisms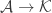 that arise from the fibre bundle construction, right? That’s an interesting question, and I think that the answer is: it’s precisely those for which for every double inclusion
that arise from the fibre bundle construction, right? That’s an interesting question, and I think that the answer is: it’s precisely those for which for every double inclusion 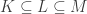 and every
and every 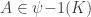 ,
,  with
with 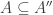 in
in  there is
there is 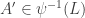 with
with  . (Think of ‘lifting’ the ‘path’
. (Think of ‘lifting’ the ‘path’ 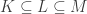 in the base space to the total space, given lifts of the endpoints.) In particular, this implies that
in the base space to the total space, given lifts of the endpoints.) In particular, this implies that  must preserve meets as well.
must preserve meets as well.
The condition is clearly necessary for a homomorphism to arise from the fibre bundle construction. Concerning sufficiency, I again only know how to show this in the abstract (without ground sets), as follows.
Given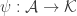 , let
, let 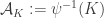 . For
. For 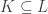 and
and 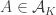 , let
, let 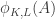 be given by the meet of all the
be given by the meet of all the 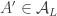 with
with 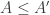 in
in  . (Recall that every finite semilattice is a lattice, so that this meet exists.) It’s straightforward to see that this preserves unions (by virtue of these being least upper bounds). It satisfies the required composition law
. (Recall that every finite semilattice is a lattice, so that this meet exists.) It’s straightforward to see that this preserves unions (by virtue of these being least upper bounds). It satisfies the required composition law 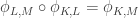 on double inclusions due to the assumption on
on double inclusions due to the assumption on  . Applying the fibre bundle construction to this recovers the original
. Applying the fibre bundle construction to this recovers the original 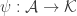 essentially by definition.
essentially by definition.
(As before, I’ve been abusing set-theoretic notation to talk about join-semilattices.)
I suspect that one can relax the assumed composition law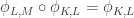 in the fibre bundle construction to
in the fibre bundle construction to  (understood pointwise), and then it’s conceivable that every (surjective) homomorphism
(understood pointwise), and then it’s conceivable that every (surjective) homomorphism 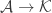 arises in this way.
arises in this way.
February 3, 2016 at 11:09 am |
Here is, if my calculations are correct, a simpler(?) counterexample to Tobias Fritz’s extreme strengthening, without using Steiner systems (or have I accidentally introduced them in disguise?)
Take the union-closed family generated by the sets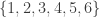 , all
, all  -subsets of
-subsets of 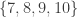 , and the 6 sets
, and the 6 sets  ,
, 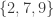 ,
, 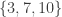 ,
,
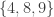 ,
, 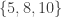 ,
, 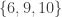 , which has (I think) 119 sets. The elements
, which has (I think) 119 sets. The elements 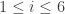 are in 52 sets each, and the elements
are in 52 sets each, and the elements  are in 100 sets each.
are in 100 sets each.
Suppose this strong form is true, so there is some and
and  such that
such that  is an injection over all
is an injection over all  . Without loss of generality,
. Without loss of generality, 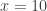 , say. Then
, say. Then 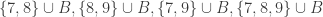 must all be distinct. It follows that
must all be distinct. It follows that 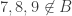 . But every set
. But every set  which contains
which contains 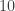 contains at least one of
contains at least one of  .
.
February 3, 2016 at 12:29 pm
Cool! Trying to take to be a set outside of the set system doesn’t work either: your argument shows
to be a set outside of the set system doesn’t work either: your argument shows 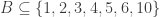 , which results in
, which results in 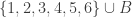 not belonging to the set system.
not belonging to the set system.
February 3, 2016 at 12:36 pm
I feel bound to ask whether it is possible to describe this example in a less rabbit-out-of-hat way …
February 3, 2016 at 2:10 pm
I think that the example’s structure is as follows: the elements 1 to 6 index the 2-subsets of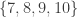 , and this is where the 3-sets come from.
, and this is where the 3-sets come from.
I’ve written some (extremely inefficient!) Sage code for forming the union closure of a given set system. It confirms that the union closure has cardinality 119. I’ll try to quote it below and now move on to drawing some Hasse diagrams for this example.
A = [{1,2,3,4,5,6},{7,8},{7,9},{7,10},{8,9},{8,10},{9,10},{1,7,8},{2,7,9},{3,7,10},{4,8,9},{5,8,10},{6,9,10}] done = False while done == False: newset_found = False for i in range(len(A)): for j in range(i+1,len(A)): candidate_union = A[i].union(A[j]) already_there = False for k in range(len(A)): if candidate_union == A[k]: already_there = True if already_there == False: A.append(candidate_union) newset_found = True if newset_found == False: done = True print len(A)February 3, 2016 at 2:38 pm
Ah of course.
February 3, 2016 at 4:14 pm
Here’s the complete (and absolutely horrible) Sage code for building union-closed families and drawing Hasse diagrams, applied to Thomas’s example:
https://cloud.sagemath.com/projects/da1aee8f-701b-4aa8-bc45-1a0a5e3f0d15/files/first%20experiments.sagews
The resulting Hasse diagrams are here:
http://personal-homepages.mis.mpg.de/fritz/A10bar.svg
http://personal-homepages.mis.mpg.de/fritz/A10.svg
Now I wonder: can the first diagram be made to fit into the second? This would check my earlier question whether one can at least find an order-preserving injection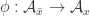 in the case of Thomas’s example.
in the case of Thomas’s example.
February 3, 2016 at 5:49 pm
Did my earlier comment with the link to the Hasse diagrams end up in the spam filter? (Feel free to delete this useless comment.)
February 5, 2016 at 9:25 am
A little late, but yes, I generated this example precisely as Tobias Fritz described.
In polymath style: I was looking at the Renaud-Sarvate example, and was wondering how they came up with it. That example is generated by the family 123, 4567, 4589, 6789, 16789, 24589, 34567, 45678, 45689, 46789. Since 45, 67, and 89 are naturally paired, this seemed to come from starting with the family generated by 123, 45, 56, 46, 145, 256, 346. That is, take all 2-subsets of a 3-set, add in unique ‘indices’ for each 2-subset as well, and also throw in the set of all indices for good measure.
In general, we can try this for any combination – so doing this with all k-subsets of an l-set produces a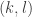 -family (say). The Renaud-Sarvate example is the
-family (say). The Renaud-Sarvate example is the 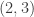 -family with an extra ‘splitting’ operation.
-family with an extra ‘splitting’ operation.
I tried plugging in a few different values, and in particular noticed that the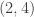 -family in my comment above provides the counterexample described.
-family in my comment above provides the counterexample described.
Given this success, and the relationship to the Renaud-Sarvate example, it looks like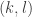 -families in general are a promising source of counterexamples to FUNC-like statements.
-families in general are a promising source of counterexamples to FUNC-like statements.
February 5, 2016 at 11:53 am
Thanks for that interesting answer! Let me try to make part of it more explicit (for my own benefit, but perhaps for someone else’s) by saying precisely what the extra “splitting” operation is. That is, how do we get from the set system 123, 45, 56, 46, 145, 256, 346 to the set system 123, 4567, 4589, 6789, 16789, 24589, 34567, 45678, 45689, 46789?
Note first that Renaud and Sarvate needed to do this because they wanted their set system to contain a unique set of size at most 3.
As a first step, let’s bracket together the pairs you draw attention to. So now the second system looks like this: 123, (45)(67), (45)(89), (67)(89), 1(67)(89), 2(45)(89), 3(45)(67), (45)(67)8, (45)6(89), 4(67)(89)
So it looks as though to get from the first system to the second we need 4 to correspond to 67, 5 to correspond to 89, and 6 to correspond to 45. If we just do that to the first system we get this: 123, (45)(67), (45)(89), (67)(89), 1(67)(89), 2(45)(89), 3(45)(67). The remaining three sets come (slightly puzzlingly to me) from taking the set (45)(67)(89) and for each pair in turn removing one element — by symmetry it doesn’t matter which. The thing I find puzzling is that one doesn’t produce six extra sets by taking all possible ways of removing one element from 456789, but presumably that tips the abundances of 1,2,3 over the edge for some reason.
February 5, 2016 at 1:29 pm
Actually, I forgot to check that, which is silly. If one does the more natural splitting (and adds six extra sets, rather than just 3, as you mention at the end of your comment), then this is still an example suitable for Renaud-Sarvate purposes – and the abundancies of 1,2,3 actually go down.
That is, it is a union-closed family (now with 36 sets), with a unique set of size 3, and every element in that set has abundancy 17/36<1/2.
So I suppose that your more natural splitting is the 'right' trick to use here (although, clearly, if one splits a little less naturally then you can get away with a slightly smaller family that still works).
Indeed, the three abundancies of the Renaud-Sarvate system are (roughly) 0.48, 0.74 and 0.85, while in your more natural construction they are 0.47 and 0.8 – so the abundancies of the 3-set actually becomes smaller in this second construction, but the less natural version manages to unbalance some of the higher abundancies as well (and the 'average higher abundancy' has gone down slightly in the less natural version).
February 5, 2016 at 1:43 pm
I should note that I haven’t been able to access the original paper of Renaud and Sarvate, so have no idea if this line of thinking is actually how they generated their example – it’d be great if someone with access could check if they remark in their paper how they came up with it.
February 7, 2016 at 4:53 pm
I’d like to explain how Thomas’s example can be obtained via the fibre bundle construction developed here: https://gowers.wordpress.com/2016/01/29/func1-strengthenings-variants-potential-counterexamples/#comment-154199
Take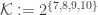 minus the singletons, or equivalently the family generated by the 2-subsets of
minus the singletons, or equivalently the family generated by the 2-subsets of 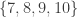 plus the empty set. In specifying the
plus the empty set. In specifying the  , I’ll restrict myself to only writing down a subset from which the others can be inferred by symmetry.
, I’ll restrict myself to only writing down a subset from which the others can be inferred by symmetry.
The maps are just those that take every element to itself.
are just those that take every element to itself.
I need to go now and haven’t checked this in as much detail as I’d like to. But even if some minor detail is off, it should be clear that Thomas’s example is an instance of the general construction.
February 3, 2016 at 12:49 pm |
Prompted by a remark of Alec Edgington’s just above I have thought of the following suggestion for a weaker result that it might be fruitful to try to prove.
I was about to write something that I then realized was known, but let me modify it. Can we prove FUNC for set systems that are generated by collections of sets of size 3? (I was going to write 2, but then would contain a set of size 2, and any such set has an element in at least half the sets.)
would contain a set of size 2, and any such set has an element in at least half the sets.)
The reason I quite like this is that it can be thought of as a question about 3-uniform hypergraphs. Indeed, let be a 3-uniform hypergraph with vertex set
be a 3-uniform hypergraph with vertex set  . Then unions of edges of
. Then unions of edges of  are subsets
are subsets  that induce subhypergraphs of
that induce subhypergraphs of  with no isolated vertices. (This condition means that every element of
with no isolated vertices. (This condition means that every element of  is contained in an edge of
is contained in an edge of  that is a subset of
that is a subset of  , which implies that
, which implies that  is a union of edges. And the converse is clear too.)
is a union of edges. And the converse is clear too.)
Let us call an induced subhypergraph “sociable” if it contains no isolated points.
So we can ask: given a 3-uniform hypergraph, must there be a vertex that belongs to at least half the sociable induced subhypergraphs?
Maybe experiments would be interesting here. What happens if we choose randomly? Of course, this is equivalent to using a random collection of 3-sets to generate a union-closed family. In particular, what happens if we make
randomly? Of course, this is equivalent to using a random collection of 3-sets to generate a union-closed family. In particular, what happens if we make  fairly sparse?
fairly sparse?
February 3, 2016 at 4:32 pm
In the paper “The 11-element case of Frankl’s conjecture”, by Ivica Bosnjak and Petar Markovic, they show that certain configurations of sets of size 3 imply FUNC, in particular, they show that if 3 sets of size 3 are in A and they are all subsets of the same 5 element set, then FUNC holds for A. This result can probably be extended to other configurations of sets of size 3.
February 3, 2016 at 6:04 pm
Here’s a reasonably nice example of a system of 3-sets such that no five elements span three sets in the system. (It may have other reasons for not working though.) Let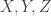 be disjoint copies of a finite group
be disjoint copies of a finite group  and take the set of all triples
and take the set of all triples 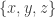 with
with 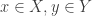 and
and 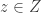 such that
such that 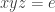 . To have three such triples all living in a 5-set, no two of them could be disjoint. But we also know that no two of them can intersect in more than one element. But it is impossible to have three 3-sets inside a 5-set without two of them intersecting in at least two elements.
. To have three such triples all living in a 5-set, no two of them could be disjoint. But we also know that no two of them can intersect in more than one element. But it is impossible to have three 3-sets inside a 5-set without two of them intersecting in at least two elements.
The obvious question in relation to this example is whether it gives a counterexample to Frankl’s conjecture. The set system we get is the collection of all subsets of that contain a triple that multiplies to the identity. By symmetry (since if
that contain a triple that multiplies to the identity. By symmetry (since if 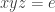 , then
, then 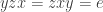 ), the question can be formulated as follows. Let
), the question can be formulated as follows. Let  be a random subset of
be a random subset of 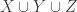 and let
and let 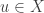 . Is the conditional probability that
. Is the conditional probability that 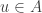 given that
given that  contains a triple
contains a triple  that multiplies to the identity at least 1/2?
that multiplies to the identity at least 1/2?
I think (but haven’t checked carefully) that a further symmetry argument can be used to show that it is enough to answer the problem in the case that is the identity element in
is the identity element in  .
.
I’m not sure how to go about answering this question in general, because random sets that contain triples that multiply to the identity seem like fairly hard things to handle. But probably it is easy to show for some small groups that this construction does not give rise to a counterexample to FUNC. Also, for large groups the construction seems to rule out small sets but keep big sets, so it doesn’t look a promising way of building a counterexample.
that this construction does not give rise to a counterexample to FUNC. Also, for large groups the construction seems to rule out small sets but keep big sets, so it doesn’t look a promising way of building a counterexample.
February 4, 2016 at 2:27 am
If G is a finite group, we need to prove that if G is a cyclic group of prime order, then if the triples are in A (even if they are not the full generating set), then FUNC holds. The simplest case is the cyclic group of order 2. I’m working on a proof along the lines of the paper to show that if {1, 2, 3}, {1, 4, 5}, {2, 4, 6}, {3, 5, 6} are in A, then FUNC holds for A.
February 4, 2016 at 3:57 am
I am able to show that FUNC holds for any union closed set containing {1, 2, 3}, {1, 4, 5}, (2, 4, 6}, and {3, 5, 6} (which are the triples you get from X={1, 6}, Y={2, 5}, Z={3, 4} and G is the cyclic group of order 2).
Let K be any set disjoint from {1, 2, 3, 4, 5, 6}, and let C be the set of all subsets s of {1, 2, 3, 4, 5, 6} such that KUs is in A. We need to show that for all K, the average size of the sets in C is at least 3 (then you can use the weight function that assigns 1 to all of 1, 2, 3, 4, 5, 6). The empty set {} may or may not be in C, but if C is nonempty (and there is no point in considering a K for which C is empty), then the full set {1, 2, 3, 4, 5, 6} is in C. We say that a set has deficit n if the set has n less elements than the target average (in this case 3), and surplus n if it has n elements more than the average. If for every K the total surplus is at least the total deficit, then FUNC holds for A.
Assume that FUNC does not hold for A, then for some K the total deficit of C is more than the total surplus of C.
Case 1: {} is in C: The surplus of {1, 2, 3, 4, 5, 6} cancels out the deficit of the empty set. Since {} is in C, then {1, 2, 3}, {1, 4, 5}, {2, 4, 6}, {3, 5, 6} are in C, along with all their unions, which together make up all the sets of size 5. The total surplus of these sets is 12 (there are 6 sets of size 5, and each has surplus 2, and we’re ignoring the full set), therefore the total deficit must be at least 13. However, for every set of size 1 in C, there are two sets of size 4 in C, as follows:
1: {1, 2, 4, 6}, {1, 3, 5, 6}
2: {1, 2, 4, 5}, {2, 3, 5, 6}
3: {1, 3, 4, 5}. {2, 3, 4, 6}
4: {1, 2, 3, 4}, {3, 4, 5, 6}
5: {1, 2, 3, 5}, {2, 4, 5, 6}
6: {1, 2, 3, 6}, {1, 4, 5, 6}
Therefore, the total deficit of the size two sets must make up the 13. But then there must be at least 13 sets of size 2 in C (since they only have deficit 1), and together, these 13 sets generate all of the sets of size 4 (since each set of size 4 can be generated in 3 ways, you need to remove 3 sets before you can’t generate a set of size 4). Therefore, the total surplus is 27, which is the maximum that the total deficit can be.
Case 2: {} is not in C. In this case, since {} is not in C, we consider the set {1, 2, 3, 4, 5, 6} as counting towards the total surplus (as the empty set isn’t there to cancel it out). Now, each set of size 1 in C means that two of {1, 2, 3}, {1, 4, 5}, {2, 4, 6}, {3, 5, 6} are in C, and the union of those is a size 5 set, so each size one set cancels out with a size 5 set. Now, every set of size 2 in C forces a set of size 4 to be in C, except {1, 6}, {2, 5}, {3, 4}. We just need a bijection from the sets of size 2 (excluding the above) to the sets of size 4 (excluding {1, 2, 5, 6}, {1, 3, 4, 6}, {2, 3, 4, 5}), such that if a set of size 2 is in C, then the associated set of size 4 is in C. Such a bijection is given below:
{1, 2}->{1, 2, 4, 5}
{1, 3}->{1, 3, 5, 6}
{1, 4}->{1, 2, 4, 6}
{1, 5}->{1, 2, 3, 5}
{2, 3}->{2, 3, 4, 6}
{2, 4}->{1, 2, 3, 4}
{2, 6}->{2, 3, 5, 6}
{3, 5}->{1, 3, 4, 5}
{3, 6}->{1, 2, 3, 6}
{4, 5}->{3, 4, 5, 6}
{4, 6}->{1, 4, 5, 6}
{5, 6}->{2, 4, 5, 6}
So, the surplus of {1, 2, 3, 4, 5, 6} cancels out the deficit of {1, 6}, {2, 5}, {3, 4}, and every other set of size 2 has an associated set of size 4. Therefore, the surplus is at least the deficit. Q.E.D.
So this proves that if your finite group G has a subgroup of order 2, then FUNC holds on the set generated by the triples. Sorry about the long post, if any of it is unclear, the paper I mentioned earlier should straighten things out.
February 4, 2016 at 4:29 am
Also, I would say that your intuition is right about the large groups (and probably all groups in general), that they have very large numbers of sets of size 3, more than I think could “fit”, in the sense that they’re very likely to contain a configuration that automatically implies Frankl’s conjecture. The number of sets of size 3 is the square of the order of the group (you can pick x and y, but then z is determined), which in my opinion is far too large.
This makes me think of Hamming codes and other error correcting codes, where the strings of 0’s and 1’s (which could be interpreted as which elements are in the set and which aren’t), could not be too close together (although I doubt it will work with the union closed condition).
February 4, 2016 at 7:40 am
With respect to the group example, I’m a bit puzzled by the statement “The set system we get is the collection of all subsets of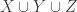 that contain a triple that multiplies to the identity”. Isn’t this suggesting that the set system is upper closed, so that FUNC holds trivially? Also, a 4-set of the form
that contain a triple that multiplies to the identity”. Isn’t this suggesting that the set system is upper closed, so that FUNC holds trivially? Also, a 4-set of the form 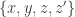 with
with 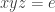 and
and 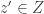 different from
different from  satisfies the condition, but can’t arise as a union of triples that multiply to the identity, no?
satisfies the condition, but can’t arise as a union of triples that multiply to the identity, no?
[Sorry for not having anything constructive to say at the moment…]
February 4, 2016 at 7:53 am
Ah yes, that statement is wrong. The system consists of all subsets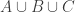 of
of 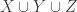 such that for every
such that for every  there exist
there exist 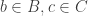 with
with  , and similarly for
, and similarly for  and
and  .
.
February 4, 2016 at 7:54 am
I assume that only the sets of size exactly 3 are included in the definition, because he is considering generating sets that contain only sets of order 3.
February 4, 2016 at 8:04 am
Never mind, I posted before I saw the previous comment. My above argument shows that no group of even order works, so the next case is the cyclic group of order 3. It may be possible (but beyond my ability) that given enough configurations of 3-sets that imply FUNC, we can find a sub-quadratic bound on the number of 3-sets that can occur for a given m.
February 4, 2016 at 8:05 pm |
Let be the probability that a random set
be the probability that a random set 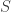 belongs to
belongs to  when
when  is chosen as follows: every element belongs to
is chosen as follows: every element belongs to  with probability
with probability  and these probabilities are statistically independent.
and these probabilities are statistically independent.
If is a symmtric union-closed family, namely if it is invariant under some transitive group of permutations on the elements then Frankl’s conjecture is equivalent to the statement that
is a symmtric union-closed family, namely if it is invariant under some transitive group of permutations on the elements then Frankl’s conjecture is equivalent to the statement that  has nonnegative derivative at
has nonnegative derivative at 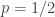 . We can extend it and ask if
. We can extend it and ask if  is monotone non-decreasing for every
is monotone non-decreasing for every  . Maybe we can juggle between different
. Maybe we can juggle between different  s by modifyig the family
s by modifyig the family  e.g. by replacing every element by say
e.g. by replacing every element by say  elements and asking that a set in the new ground set in in the modified family if for some set in the original family it has at least one new element for every original element. (Or something like this.) So maybe a counterexample for
elements and asking that a set in the new ground set in in the modified family if for some set in the original family it has at least one new element for every original element. (Or something like this.) So maybe a counterexample for 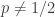 (say
(say  very close to 1) can be modified into a counterexample for
very close to 1) can be modified into a counterexample for 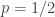 .
.
It will be interesting to looks at examples like “union of lines in projective spaces”. I dont know if for such examples is monotone increasing for
is monotone increasing for  for every
for every  .
.
February 5, 2016 at 4:00 am
For example, for the Fano plane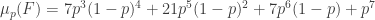 . Is it monotone with
. Is it monotone with  ?
?
Frankl’s conjecture says that every point is in more than half the sets which gives that the derivative of at 1/2 is positive. But it looks that having some
at 1/2 is positive. But it looks that having some  for which the derivative is negative will allow to replace the family with another and push the non-monotonicity to p=1/2. (Maybe such a reduction can work even for the non-symmetric case and even for different product measures based on diffrent
for which the derivative is negative will allow to replace the family with another and push the non-monotonicity to p=1/2. (Maybe such a reduction can work even for the non-symmetric case and even for different product measures based on diffrent  s.)
s.)
February 5, 2016 at 9:44 am
The function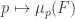 is monotonic with respect to
is monotonic with respect to  because its derivative is given by
because its derivative is given by ![\mu_p'(F)=\frac{7p^2(1-p)^2}{22}\left[41+(22p-5)^2\right]>0](https://s0.wp.com/latex.php?latex=%5Cmu_p%27%28F%29%3D%5Cfrac%7B7p%5E2%281-p%29%5E2%7D%7B22%7D%5Cleft%5B41%2B%2822p-5%29%5E2%5Cright%5D%3E0&bg=ffffff&fg=333333&s=0&c=20201002) .
.
February 7, 2016 at 2:24 am
Actually, we can add the empty set to and thus the additional term
and thus the additional term 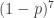 to
to  and then
and then 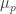 cannot be monotone so it will be decreasing for some
cannot be monotone so it will be decreasing for some  . (For this you can take the family with all sets of 0,2,3 elements from
. (For this you can take the family with all sets of 0,2,3 elements from 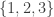 .) Now, it looks that the methods described above by replacing each element by a threshold on many elements so that the probability to reach the threshold is p, will transfer the non monotomicity from p to 1/2 as we want.
.) Now, it looks that the methods described above by replacing each element by a threshold on many elements so that the probability to reach the threshold is p, will transfer the non monotomicity from p to 1/2 as we want.
February 7, 2016 at 7:42 pm
Indeed, for union-closed families with transitive symmetry, monotonicity fails for general values of . (We can have the empty set and full set in the family giving
. (We can have the empty set and full set in the family giving 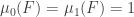 .) But I don’t see a reason that this will lead to examples that it fails for
.) But I don’t see a reason that this will lead to examples that it fails for 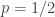 which is what Frankl’s conjecture gives. In particular, trying to augment the family with threshold families (as I suggested above) causes violation of the union-closed property. (Maybe, the conjecture extends to all
which is what Frankl’s conjecture gives. In particular, trying to augment the family with threshold families (as I suggested above) causes violation of the union-closed property. (Maybe, the conjecture extends to all 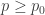 for some
for some 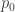 , perhaps $p_0=1/2$ but I am not sure it is “truer” for larger p. For the simple example of 0- 2-3- subsets of a 3-element set, monotonicity is violated when
, perhaps $p_0=1/2$ but I am not sure it is “truer” for larger p. For the simple example of 0- 2-3- subsets of a 3-element set, monotonicity is violated when 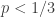 .)
.)
February 5, 2016 at 12:28 pm |
This is presumably a familiar concept to people who have thought about FUNC a lot, but it seems as though it should be mentioned here. Let’s define a homomorphism from a union-closed set system to a union-closed set system
to a union-closed set system  to be a function
to be a function  such that
such that 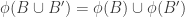 for every
for every 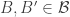 .
.
Given a union-closed family , it is quite interesting to think about what homomorphism exist to
, it is quite interesting to think about what homomorphism exist to  . An easy example is to let
. An easy example is to let 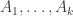 be a generating set for
be a generating set for  and to take
and to take  to be the power set of
to be the power set of 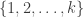 . Then we can map
. Then we can map  to
to 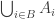 . Another obvious example is to duplicate elements of the ground set of
. Another obvious example is to duplicate elements of the ground set of  : then the resulting set system
: then the resulting set system  has an obvious homomorphism to
has an obvious homomorphism to  .
.
In general, suppose we have a union-closed system and it has a generating set
and it has a generating set  . Then we could try mapping
. Then we could try mapping 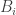 to
to  . This would force
. This would force 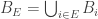 to map to
to map to 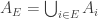 , which is fine provided we don’t find that there exist
, which is fine provided we don’t find that there exist  such that
such that 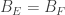 but
but 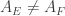 . So the condition we need is roughly that there are fewer set-theoretic relations amongst the
. So the condition we need is roughly that there are fewer set-theoretic relations amongst the 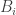 than there are amongst the
than there are amongst the  — which is why taking the
— which is why taking the 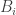 above to be (distinct) singletons works easily.
above to be (distinct) singletons works easily.
I thought about this while thinking about Thomas Bloom’s comment above. I haven’t checked, but it would be interesting to me to know whether the kinds of splitting operations he talks about are a special case of finding a new family and a homomorphism to the old family. I would also be interested to see whether anything interesting can be said about what homomorphisms do to abundances.
February 5, 2016 at 1:08 pm
A rather general way of constructing homomorphisms is as follows. Let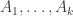 be a generating set for
be a generating set for  and let
and let  be some set disjoint from
be some set disjoint from  . Now let
. Now let 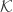 be an arbitrary family of subsets of
be an arbitrary family of subsets of  and let
and let 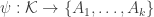 be an arbitrary function. Finally, let
be an arbitrary function. Finally, let  be generated by the sets
be generated by the sets 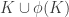 such that
such that 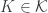 .
.
I claim that the map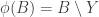 is a homomorphism from
is a homomorphism from  to
to  . It’s trivial that it preserves unions, but we need to be sure that
. It’s trivial that it preserves unions, but we need to be sure that 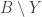 actually belongs to
actually belongs to  . But each
. But each 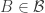 is the union of a union of subsets of
is the union of a union of subsets of  and a union of some of the sets
and a union of some of the sets  , so that is easy too.
, so that is easy too.
This construction is a way of “duplicating” sets in , by turning them into all their inverse images in
, by turning them into all their inverse images in  . Something reasonably promising about this is that it looks easy to do this in such a way that smaller sets in
. Something reasonably promising about this is that it looks easy to do this in such a way that smaller sets in  get duplicated more, since the more sets in
get duplicated more, since the more sets in  that you union together, the more chance (at least for certain choices of
that you union together, the more chance (at least for certain choices of  ) of coincidences. But this is presumably at the cost of introducing elements of
) of coincidences. But this is presumably at the cost of introducing elements of  that may have large abundances.
that may have large abundances.
This feels very similar to comments I have already seen, I think by Thomas Bloom. I hope it is a mild generalization, but apologies if it is in fact identical.
February 5, 2016 at 2:13 pm |
Inspired by the other thread on generating random examples, I’ve now written some code that computes the average overlap density:
http://personal-homepages.mis.mpg.de/fritz/overlap_density.sage
Upon downloading the file, you can run it in Sage using this command:
load("overlap_density.sage")The file’s header contains the three parameters that control the search for examples with low overlap density: size of the ground set, size of each generating set, and number of generating sets. There are no checks for the set system to cover the entire ground set or even to separate points.
The results are mildly encouraging: it’s easy to find examples with overlap density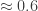 and lower, but no example with overlap density
and lower, but no example with overlap density 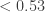 has been found so far. The smallest overlap densities of around
has been found so far. The smallest overlap densities of around 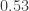 are observed in those examples in which the generating sets are pairwise disjoint, i.e. when the union-closed family is a Boolean algebra (and therefore very far from separating points). Using smaller generating sets typically results in smaller overlap densities.
are observed in those examples in which the generating sets are pairwise disjoint, i.e. when the union-closed family is a Boolean algebra (and therefore very far from separating points). Using smaller generating sets typically results in smaller overlap densities.
February 5, 2016 at 2:31 pm
Playing around with the overlap density and the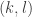 -families I described above in Python, it looks the following is true:
-families I described above in Python, it looks the following is true:
Let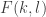 be the average overlap density of the
be the average overlap density of the 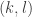 -family. Then, for
-family. Then, for  , we have
, we have 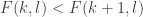 and
and 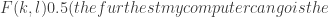 latex (1,7)$-family, which has average overlap density of 0.55514…
latex (1,7)$-family, which has average overlap density of 0.55514…
February 5, 2016 at 2:32 pm
Playing around with the overlap density and the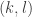 -families I described above in Python, it looks the following is true:
-families I described above in Python, it looks the following is true:
Let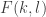 be the average overlap density of the
be the average overlap density of the 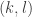 -family. Then, for
-family. Then, for 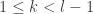 , we have
, we have 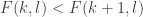 and
and 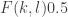 (the furthest my computer can go is the
(the furthest my computer can go is the  -family, which has average overlap density of 0.55514…
-family, which has average overlap density of 0.55514…
February 5, 2016 at 2:51 pm |
Can anyone explain why Frankl’s conjecture implies the Salzborn formulation? (Apparently the proof is in P. Wojcik, ‘Union-closed families of sets’, Disc. Math. 199 (1999), 173–182, but I can’t find that article.)
I’ve been playing with randomly-generated normalized families, with a view to looking for structure in the tightest examples, and observed that the mimimum maximum-basis-set-size as a function of the size of the ground set for normalized families seems to match the minimum maximum-abundance as a function of the size of the ground set for all union-closed families (the function called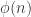 in the survey article, which starts uncannily like Sloane A004001). So I guess there must be an exact correspondence.
in the survey article, which starts uncannily like Sloane A004001). So I guess there must be an exact correspondence.
February 5, 2016 at 3:06 pm
You can find the paper here:
http://www.sciencedirect.com/science/article/pii/S0012365X98002088
There is also a way to do it using some dual families defined by Johnson and Vaughan. Let F be a normalized family and J(F) be the set of join-irreducible sets in the family F,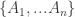 . For every x let J(x) be the set of the indexes of join-irreducible sets that have x and take D(F) the dual family of F as the family generated (so that it becomes union-closed) by {J(x): x in U}, where U is the ambient set. They prove this family has the same cardinality as F and it is clear that if this family has an element in at least half the sets that implies Salzburg holds for F.
. For every x let J(x) be the set of the indexes of join-irreducible sets that have x and take D(F) the dual family of F as the family generated (so that it becomes union-closed) by {J(x): x in U}, where U is the ambient set. They prove this family has the same cardinality as F and it is clear that if this family has an element in at least half the sets that implies Salzburg holds for F.
February 5, 2016 at 3:21 pm
Thanks!
February 5, 2016 at 4:06 pm |
No problem !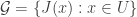 is already union-closed because if your initial family is normalized then
is already union-closed because if your initial family is normalized then 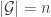 before (and after generating) and so it has a set {1,2,…,t}, where t is the number of join irreducible sets and another set
before (and after generating) and so it has a set {1,2,…,t}, where t is the number of join irreducible sets and another set 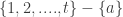 for some
for some ![a\in [t].](https://s0.wp.com/latex.php?latex=a%5Cin+%5Bt%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
Actually, I believe you can see that a normalized separating family has an universal element and an element in n-1 sets because the family
February 5, 2016 at 4:24 pm |
This may be a question that has already been answered, or has a trivial answer, but I’m curious enough to ask it anyway: what is known about Frankl’s conjecture if we assume the family is BOTH union-closed and intersection-closed (i.e. is isomorphic to a topology on some finite set)?
February 5, 2016 at 4:31 pm
If the family is both union closed and intersection closed, then the family either contains a set of size one, or it is not separable (in which case, you can combine elements in the set so that it is separable. Therefore, every union and intersection closed set satisfies FUNC.
February 5, 2016 at 4:33 pm
I guess that counts as a trivial answer. Thanks!
February 5, 2016 at 4:38 pm
If you’re interested, there is an equivalent conjecture (which you’ve probably heard of by now) about intersection closed sets, that there is always an element in at mot half of the sets. This equivalent conjecture might be easier to solve.
February 5, 2016 at 11:36 pm |
I have another question, this time not comparable to FUNC, in that proving it won’t prove FUNC and finding a counterexample won’t give a counterexample to FUNC. But I still find it interesting.
Suppose we take the conjecture about average overlap density. One way we might try to disprove it is to take an ordering on the elements of the ground set, and then duplicate the elements in such a way that each successive element of the ground set is duplicated far more times than its predecessor. Equivalently, let us weight the elements in such a way that the weights increase rapidly.
What will this do to the overlap densities? Well, if and
and  are sets in
are sets in  , then the weight of
, then the weight of  is almost entirely in its maximal element, so
is almost entirely in its maximal element, so 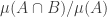 will be approximately 1 if
will be approximately 1 if  and approximately 0 otherwise.
and approximately 0 otherwise.
So let us define a new sort of overlap density. I’ll say that beats
beats  if
if  . I now want to know whether if you pick a random non-empty set
. I now want to know whether if you pick a random non-empty set 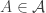 and independently a random set
and independently a random set  , the probability that
, the probability that  is always at least 1/2.
is always at least 1/2.
A nice thing about this is that we can fix the order to be just the usual order on and then choose the set system to try to make it as unlikely as possible that the maximal element of one set is contained in another set. The relationship between this and FUNC is that both statements follow from the conjecture that the average overlap density is always at least 1/2. So it is a special case of a fairly natural strengthening. I think it’s a special case worth considering, because it looks fairly clean to investigate computationally, so there’s a chance that we may be able to use it to dispose of the average-overlap-density strengthening. Perhaps one can even find an example by hand.
and then choose the set system to try to make it as unlikely as possible that the maximal element of one set is contained in another set. The relationship between this and FUNC is that both statements follow from the conjecture that the average overlap density is always at least 1/2. So it is a special case of a fairly natural strengthening. I think it’s a special case worth considering, because it looks fairly clean to investigate computationally, so there’s a chance that we may be able to use it to dispose of the average-overlap-density strengthening. Perhaps one can even find an example by hand.
February 6, 2016 at 8:55 am
If I’ve understood correctly, I think this is a counterexample with : take the 6-set family
: take the 6-set family 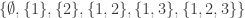 . The number of pairs
. The number of pairs 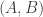 where
where 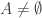 and
and 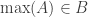 is 14, which is less than half of
is 14, which is less than half of 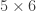 .
.
February 6, 2016 at 10:00 am
That looks right. So it should convert into a counterexample to the average-overlap-density “conjecture” (the inverted commas because it always seemed a bit unlikely to be true). Let be disjoint sets with
be disjoint sets with  a singleton,
a singleton,  a set of size
a set of size  and
and  a set of size
a set of size  . Then the counterexample should be
. Then the counterexample should be
for sufficiently large .
.
February 6, 2016 at 10:39 am
Yes, that works.
February 6, 2016 at 10:44 am
I suppose an obvious challenge at this point is to try to find a counterexample that separates points. However, what I would prefer to try to find is a general method for converting set systems that don’t separate points into set systems that do separate points, while keeping the abundances approximately the same (in some sense). I may well be wrong, but it feels to me as though it ought to be possible somehow. A slightly weaker requirement that would still do fine would be to find a way of achieving what can be achieved with duplication but with just a few more sets thrown in so that points are separated.
February 6, 2016 at 2:47 pm |
Advance warning: this comment and the first two replies to it give a detailed description of a construction that ends up not working.
Here’s a rough proposal for a method of construction that is aimed at showing, roughly speaking, that adding the condition that a set system should separate points doesn’t help, in the sense that it won’t magically make false conjectures true. (Obviously it makes some statements true — e.g. the statement that your family separates points. I haven’t thought about how to characterize the statements that I’m talking about.)
Let be a set system that does not necessarily separate points. Let
be a set system that does not necessarily separate points. Let  be the ground set of
be the ground set of  . Now let
. Now let  be the cyclic group of order
be the cyclic group of order  and form a new set system
and form a new set system 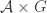 that consists of all sets of the form
that consists of all sets of the form  with
with 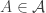 . I am assuming that
. I am assuming that  is much bigger than
is much bigger than  .
.
Now choose two random functions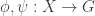 . For each
. For each 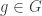 and each
and each  , let
, let 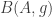 be the set
be the set
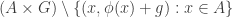
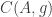 be the set
be the set
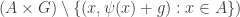 .
. be the set system generated by the sets
be the set system generated by the sets 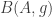 and
and 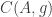 .
.
and let
I now want to let
The two things I want to prove about are as follows.
are as follows.
1. It separates points.
2. The abundance of any element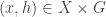 in
in  is approximately the same as the abundance of
is approximately the same as the abundance of  in
in  .
.
I will post this comment to make it easier to look at what I’ve just defined and what I want to prove. Of course, this risks that I will find that I’ve got it wrong. (I haven’t written this out in advance.)
February 6, 2016 at 3:00 pm
Let me start with 1. Let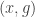 and
and 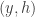 be distinct elements of
be distinct elements of 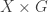 . (I’m assuming that
. (I’m assuming that 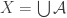 of course.) If
of course.) If 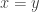 , then choose
, then choose  such that
such that 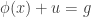 . Then
. Then 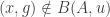 , but since
, but since 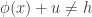 ,
,  .
.
If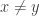 , then this does not work because we might find that
, then this does not work because we might find that 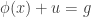 and
and  . That would imply that
. That would imply that  . But then we can use the set
. But then we can use the set 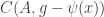 instead. The only thing that can go wrong is if there exist
instead. The only thing that can go wrong is if there exist  and
and  with
with 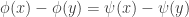 . But if
. But if  is much larger than
is much larger than 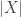 , then this happens with very low probability. (All I need for this argument is that there exist functions
, then this happens with very low probability. (All I need for this argument is that there exist functions  and
and  such that it doesn’t happen.)
such that it doesn’t happen.)
The above argument, I forgot to say, was dealing with the case where there is some set that contains both
that contains both  and
and  . If no such
. If no such  exists, then
exists, then  and
and  are already separated.
are already separated.
I’ll deal with abundances in a separate comment.
February 6, 2016 at 3:26 pm
OK, let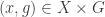 . I want to estimate its abundance.
. I want to estimate its abundance.
First let’s see how many sets in are subsets of a given set
are subsets of a given set  but not of any set
but not of any set 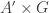 with
with 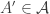 a proper subset of
a proper subset of  . What I need for this construction to work is that I should get roughly the same answer for all
. What I need for this construction to work is that I should get roughly the same answer for all  .
.
Unfortunately, I realize as I write this that it doesn’t work. My basic problem is that if and
and  are disjoint sets in
are disjoint sets in  , then if I do a construction that creates, in some sense, approximately
, then if I do a construction that creates, in some sense, approximately  copies of
copies of  and another
and another  copies of
copies of  , then when I take their unions I will have to create
, then when I take their unions I will have to create  copies of
copies of 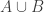 . I thought I could somehow “couple” the copies of
. I thought I could somehow “couple” the copies of  with the copies of
with the copies of  , but I can’t.
, but I can’t.
February 6, 2016 at 4:13 pm
I think I can convert that failure into a lemma. Let be a union-closed set system. I claim that if
be a union-closed set system. I claim that if  contains two disjoint non-empty sets, then it is not possible to find a union-closed set system
contains two disjoint non-empty sets, then it is not possible to find a union-closed set system  and a surjective homomorphism
and a surjective homomorphism  such that every
such that every 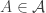 has approximately the same number of preimages — except if that number is 1.
has approximately the same number of preimages — except if that number is 1.
The proof is trivial. If and
and  are disjoint elements of
are disjoint elements of  and
and  and
and  are preimages, then
are preimages, then 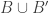 is a preimage of
is a preimage of 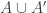 . Actually, for this argument to be properly trivial I need to assume that
. Actually, for this argument to be properly trivial I need to assume that  and
and  are disjoint, which they don’t have to be, so it’s back to the drawing board yet again — maybe there is some clever way of getting sets to overlap in order to compensate for this effect.
are disjoint, which they don’t have to be, so it’s back to the drawing board yet again — maybe there is some clever way of getting sets to overlap in order to compensate for this effect.
February 6, 2016 at 7:33 pm |
Here’s a ludicrously optimistic strengthening of FUNC. Normally I’d try a little bit to find a counterexample before posting it, but I’m otherwise occupied this evening. The strengthening is the claim that if is a surjective homomorphism (meaning that it preserves unions), then the maximum abundance of an element with respect to
is a surjective homomorphism (meaning that it preserves unions), then the maximum abundance of an element with respect to  is at least as big as the maximum abundance of an element with respect to
is at least as big as the maximum abundance of an element with respect to  . This would imply FUNC, because we could just take a generating set
. This would imply FUNC, because we could just take a generating set 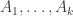 for
for  and take
and take  to be the power set of
to be the power set of 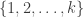 and map
and map  to
to 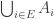 .
.
Why is this “conjecture” even slightly plausible? Well, if we try to disprove it by taking to consist of large sets, then we are likely to find coincidences amongst the unions of sets in
to consist of large sets, then we are likely to find coincidences amongst the unions of sets in  that do not correspond to coincidences in
that do not correspond to coincidences in  .
.
Actually, writing that sentence has made me realize just how false this “conjecture” is. We can take to be generated by random subsets
to be generated by random subsets  of
of  for some very large
for some very large  , each of density
, each of density  for some
for some 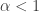 . (The closer
. (The closer  is to 1, the larger we need to take
is to 1, the larger we need to take  .) Then as long as
.) Then as long as  is large enough, all unions of the
is large enough, all unions of the 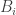 will be distinct, so the map that takes
will be distinct, so the map that takes 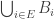 to
to 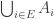 will be a homomorphism, and we can make the average abundance in
will be a homomorphism, and we can make the average abundance in  as large as we like.
as large as we like.
February 7, 2016 at 8:37 am
That is arguably not a very good counterexample, since all abundances are 0, 1/2 or 1 (again just because there are no coincidences among the unions of the generators). The average abundance becomes large only due to the large number of elements with abundance 1. I want to argue that we shouldn’t really count elements with abundance 1: one reason is that the lattice formulation of FUNC doesn’t even ‘see’ them and would consider your
is arguably not a very good counterexample, since all abundances are 0, 1/2 or 1 (again just because there are no coincidences among the unions of the generators). The average abundance becomes large only due to the large number of elements with abundance 1. I want to argue that we shouldn’t really count elements with abundance 1: one reason is that the lattice formulation of FUNC doesn’t even ‘see’ them and would consider your  to have a maximal abundance of 1/2. So if one excludes elements of abundance 1 from the strengthened conjecture, then that counterexample doesn’t work.
to have a maximal abundance of 1/2. So if one excludes elements of abundance 1 from the strengthened conjecture, then that counterexample doesn’t work.
For a different family of counterexamples that still work, take to be any union-closed family containing the empty set and with maximal abundance greater than 1/2. Take
to be any union-closed family containing the empty set and with maximal abundance greater than 1/2. Take 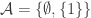 , and
, and  to be given by the empty set mapping to the empty set and everything else mapping to
to be given by the empty set mapping to the empty set and everything else mapping to 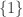 . Then
. Then  is surjective, but decreases maximal abundance.
is surjective, but decreases maximal abundance.
February 7, 2016 at 12:47 pm
Ah yes, that’s a good point (and one that I had to think about for a while before understanding why it was correct).
Although I still very much doubt whether any conjecture like this can be true, let me try to refine the conjecture slightly to rule out the two examples so far but to leave something that still implies FUNC.
The refined conjecture says the following. Let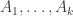 be a minimal generating set for a union-closed system
be a minimal generating set for a union-closed system  (which by convention I will take to include the empty set). Let
(which by convention I will take to include the empty set). Let  be some other sets and suppose that the following two statements hold.
be some other sets and suppose that the following two statements hold.
(i) The map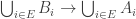 is a homomorphism.
is a homomorphism.
(ii) If any element is removed from any of the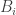 , then the map ceases to be a homomorphism.
, then the map ceases to be a homomorphism.
Then the maximum abundance of is at most the maximum abundance of
is at most the maximum abundance of  .
.
February 8, 2016 at 9:14 am
I must be missing something – isn’t a map of the form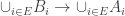 always a homomorphism, whatever we do to the the
always a homomorphism, whatever we do to the the 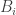 , so the second condition is never satisfied? Also, presumably this is intended to rule out Tobias’ example with
, so the second condition is never satisfied? Also, presumably this is intended to rule out Tobias’ example with  and
and 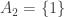 , but I’m afraid I don’t see how?
, but I’m afraid I don’t see how?
February 8, 2016 at 10:28 am
It’s always a homomorphism if it’s well-defined, but it may not be well-defined. I should have made it clearer that that was the main constraint on .
.
As for ruling out Tobias’s example, the unique minimal generating set of in his example is
in his example is  , which forces
, which forces  to equal 1, which forces
to equal 1, which forces  to be a very boring set system — it has to consist of just one set and the empty set, and then by minimality that set has to be a singleton.
to be a very boring set system — it has to consist of just one set and the empty set, and then by minimality that set has to be a singleton.
February 8, 2016 at 10:32 am
Having said that, the second condition doesn’t feel right, since removing elements from some of the can sometimes turn a homomorphism into a non-homomorphism, but it can also sometimes turn a non-homomorphism into a homomorphism. So it doesn’t seem to capture the idea of minimality that I was trying to capture.
can sometimes turn a homomorphism into a non-homomorphism, but it can also sometimes turn a non-homomorphism into a homomorphism. So it doesn’t seem to capture the idea of minimality that I was trying to capture.
Maybe I should have stuck with something simpler like removing all elements with abundance 1.
February 7, 2016 at 3:45 am |
[…] element that belongs to at lease half the sets in the family. Here are links to Post number 0 and Post number 1. (Meanwhile polymath10 continues to run on “Combinatorics and […]
February 24, 2016 at 3:50 pm |
I wonder if something like this might lead to interesting questions: http://brunni.de/ucf/stats.cgi (abundance statistics for randomly generated and breeded families).
February 29, 2016 at 6:02 am |
[…] discuss together what directions to peruse. It is a pleasure to mention that in parallel Tim Gowers is running polymath11 aimed for resolving Frankl’s union closed conjecture. Both questions were offered along with the […]
April 22, 2016 at 9:49 am |
A possible construction is using independent finite sets. Lets say of m independent sets. Now for union over any r of these must belong to the family.
so we have a total of 2^m sets in total
now assume x belongs to one of the sets then there are 1+2^(m-1)
sets to which x belongs
which is clearly greater than 1/2
this can generalized for overlaping sets by removing all the independent sets from the family
the family is still union closed
in this case the total number of sets become (2^m) – m
but now x belongs 2^(m-1)
which is still greater than 1/2.
clearly, the new family is conformable to any union closed family
August 13, 2016 at 8:23 pm |
[…] 14) Frankl’s union closed set conjecture (Proposed by Dominic van der Zypen; Also one of the proposals by Gowers in this post). (Launched) […]
March 8, 2018 at 9:33 pm |
[…] the problem in our very first post, and Tim Gowers ran polymath 11 in attempt to solve it (first post, wikipage). See also this post over GLL and this […]