This term I shall be giving Cambridge’s course Analysis I, a standard first course in analysis, covering convergence, infinite sums, continuity, differentiation and integration. This post is aimed at people attending that course. I plan to write a few posts as I go along, in which I will attempt to provide further explanations of the new concepts that will be covered, as well as giving advice about how to solve routine problems in the area. (This advice will be heavily influenced by my experience in attempting to teach a computer, about which I have reported elsewhere on this blog.)
I cannot promise to follow the amazing example of Vicky Neale, my predecessor on this course, who posted after every single lecture. However, her posts are still available online, so in some ways you are better off than the people who took Analysis I last year, since you will have her posts as well as mine. (I am making the assumption here that my posts will not contribute negatively to your understanding — I hope that proves to be correct.) Having said that, I probably won’t cover exactly the same material in each lecture as she did, so the correspondence between my lectures and her posts won’t be as good as the correspondence between her lectures and her posts. Nevertheless, I strongly recommend you look at her posts and see whether you find them helpful.
You will find this course much easier to understand if you are comfortable with basic logic. In particular, you should be clear about what “implies” means and should not be afraid of the quantifiers 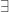 and
and  . You may find a series of posts I wrote a couple of years ago helpful, and in particular the ones where I wrote about logic (NB, as with Vicky Neale’s posts above, they appear in reverse order). I also have a few old posts that are directly relevant to the Analysis I course (since they are old posts you may have to click on “older entries” a couple of times to reach them), but they are detailed discussions of Tripos questions rather than accompaniments to lectures. You may find them useful in the summer, and you may even be curious to have a quick look at them straight away, but for now your job is to learn mathematics rather than trying to get good at one particular style of exam, so I would not recommend devoting much time to them yet.
. You may find a series of posts I wrote a couple of years ago helpful, and in particular the ones where I wrote about logic (NB, as with Vicky Neale’s posts above, they appear in reverse order). I also have a few old posts that are directly relevant to the Analysis I course (since they are old posts you may have to click on “older entries” a couple of times to reach them), but they are detailed discussions of Tripos questions rather than accompaniments to lectures. You may find them useful in the summer, and you may even be curious to have a quick look at them straight away, but for now your job is to learn mathematics rather than trying to get good at one particular style of exam, so I would not recommend devoting much time to them yet.
(more…)


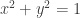 and
and  is the angle that the line from
is the angle that the line from 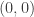 to
to  makes with the line from
makes with the line from 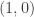 , then
, then  and
and  . So how does one establish that? How does one even define the angle? In this post, I will give one possible answer to these questions.
. So how does one establish that? How does one even define the angle? In this post, I will give one possible answer to these questions.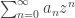 is differentiable inside its circle of convergence, and the derivative is given by the obvious formula
is differentiable inside its circle of convergence, and the derivative is given by the obvious formula  . In other words, inside the circle of convergence we can think of a power series as like a polynomial of degree
. In other words, inside the circle of convergence we can think of a power series as like a polynomial of degree  for the purposes of differentiation.
for the purposes of differentiation. , we have the following facts.
, we have the following facts. , we have that
, we have that  .
. ,
, 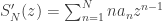 .
.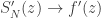 , then we would be done.
, then we would be done. converges? But it turns out that that is not the problem: it is reasonably straightforward to show that it converges. (Roughly speaking, inside the circle of convergence the series
converges? But it turns out that that is not the problem: it is reasonably straightforward to show that it converges. (Roughly speaking, inside the circle of convergence the series  converges at least as fast as a GP, and multiplying the
converges at least as fast as a GP, and multiplying the  th term by
th term by  for
for 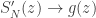
 ?
?![[x,x+h]](https://s0.wp.com/latex.php?latex=%5Bx%2Cx%2Bh%5D&bg=ffffff&fg=333333&s=0&c=20201002) tells us that there exists
tells us that there exists 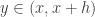 such that
such that 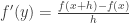 , and therefore that
, and therefore that  . Writing
. Writing  for some
for some  we obtain the statement
we obtain the statement  . This is the case
. This is the case  of Taylor’s theorem. So can’t we find some kind of “polynomial mean value theorem” that will do the same job for approximating
of Taylor’s theorem. So can’t we find some kind of “polynomial mean value theorem” that will do the same job for approximating  by polynomials of higher degree?
by polynomials of higher degree? of a group
of a group  , explain carefully how to make the set of (left) cosets of
, explain carefully how to make the set of (left) cosets of  and a homomorphism
and a homomorphism 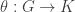 such that
such that  ). Show that if
). Show that if  , then
, then  be a finite set with
be a finite set with  on
on  , there exists at least one
, there exists at least one  with
with 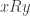 , is
, is  .
.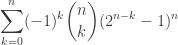 .
. is prime then
is prime then  (mod
(mod 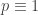 (mod 4) then
(mod 4) then (mod
(mod  . Show that if
. Show that if  (mod
(mod  (mod
(mod  (mod
(mod 