In this post I want to take the following attitude. Although there are several promising approaches to solving EDP, I am going to concentrate just on the representation-of-diagonals idea and pretend that that is the problem. That is, I want to pretend that the main problem we are trying to solve is not a problem about discrepancy of 
Problem. Is it true that for every positive constant 
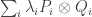



There are other equivalent ways of formulating this problem, but I’ll stick with this one for now. Incidentally, 

In this post I want to try to encourage a certain stepping back. Our general problem is to construct something with some rather delicate properties. We don’t really know how to go about it. In that kind of situation, what is one to do? Does one wait to be struck suddenly by a brilliant idea? Or is there a way of searching systematically? Of course, I very much hope it will be the latter, or at least nearer to the latter.
Here are a few very general (and overlapping) methods I can think of for finding delicate examples.
1. Try to find, out there in the literature already, a construction that has some delicate properties that are similar to the ones you are interested in, and then try to modify that known example.
2. Add some further properties that an example might have, in the hope that you can narrow down the search space.
3. Come up with a different problem and show that a solution to that problem has, or can be converted into something that has, the properties you want. (An example of this technique is the use of variational methods to solve differential equations.)
4. Successive approximation: make a guess, understand why your guess doesn’t work, make a guess about how to modify or replace your first guess, understand why that doesn’t work, and so on until you hit something that does work.
5. Indirect proofs of existence: prove that the constraints are mild enough that between them they do not wipe out the entire space of potential examples.
6. Recursion: instead of building what you want in one go, build it up in stages, in such a way that at the final stage you have the properties you wanted. (In Banach space theory there are examples where the building up process is infinite: you inductively define a sequence of norms and show that it converges to a limit with properties that you are looking for.)
This is unlikely to be a complete list. I would welcome further suggestions of very general example-finding strategies.
Let me briefly discuss the potential of each of the above strategies to solve our matrix problem.
1. Modifying a known example. I find this unpromising, largely because the properties we want are very closely tied to the particular nature of HAPs, and I don’t think HAPs figure much in the rest of mathematics.
2. Adding extra properties to narrow down the search. This, it seems to me, has the potential to help, though I doubt whether it will be sufficient on its own. One way we could narrow things down is to restrict the class of HAPs that we allow ourselves to use. We have already thought about this somewhat. For example, we do not know that we cannot get by just with HAPs whose common differences are either primes or powers of 2.
3. Devising another problem whose solution you can use. I think that this method could conceivably help. What is its advantage? Well, it comes in useful if you are trying to construct something and are not confident that there will be a nice formula for that thing. Another example is the use of fixed point theorems: sometimes we can cleverly devise a continuous function, show that it has a fixed point (which we cannot describe explicitly), and show that a fixed point can be translated into a solution of the original problem. For our matrix problem, we are not sure what the diagonal matrix should be, and no obvious formula jumps out of the experimental evidence. Perhaps it is something like a multiple of the stationary distribution of some random walk — since those often don’t have an obvious formula either.
4. Successive approximation. If all else fails, this, it seems to me, is the best method. Even understanding why a very bad guess is bad can make finding a good guess easier, and the more iterations one goes through of this procedure, the more deeply one understands the problem.
5. Indirect proofs of existence. This is initially tempting, but it seems to lead inexorably towards exploiting duality, and that takes us to a generalization of EDP that we have discussed in previous threads. In other words, it seems to be a backwards step. Nevertheless, it is always worth keeping this “predual” formulation in mind, as it helps us not to make guesses that are obviously wrong (such as taking the diagonal matrix to be a multiple of the identity). Another sort of indirectness is probabilistic methods: it is certainly conceivable that they could play a role.
6. I don’t find this very promising, but there is perhaps one possibility, which has already been discussed to some extent. That is to use linear and semidefinite programming techniques for improving guesses. If we do this infinitely often, we will converge to an optimal solution, which sounds great until one realizes that one has to be able to prove something about this optimal solution, and at each iteration the matrix gets harder and harder to describe.
I think we need to think very carefully about the following question. Suppose that there is no solution to the problem that can be described by a pretty formula. How in that case could we conceivably prove the existence of a decomposition with the desired properties? The only idea I have so far is 3, perhaps with a little help from the probabilistic method. (For instance, perhaps 3 would be used to come up with the diagonal matrix, and probabilistic methods for the decomposition.) But if that is genuinely the only way of going about it, then how do we come up with this other problem with a solution that magically transforms into a solution to our problem? I’m tempted to list potential sub-strategies. They might simply be a list of promising candidates for the class of “other problem”: eigenvectors, variational methods, fixed point theorems and the like. Or they might be more general advice about how to search for a proof of this kind.
I am still rather busy with other things, but perhaps we could keep the project ticking along with a high-level strategic discussion about issues such as I have raised in this post. And then when people feel ready for it, we could start getting our hands dirty again.

April 26, 2010 at 5:04 am |
I might have missed one in the comments or on the wiki, but do we have a nontrivial example somewhere?
April 26, 2010 at 1:44 pm |
There’s another method which we have been making extensive use of already.
7. Pattern matching. Invent a finite version of the problem, compute optimal (or at least good) solutions to the finitized version, and try to recognize a pattern that could extend to the “real” problem.
Speaking of which, Is anybody still looking at the 1124 sequences, and their apparent structures? Where did that line of thought end off?
April 26, 2010 at 4:51 pm
I have also been busy with other things, but as I mentioned in on of my comments in EDP13 I think it could be interesting to see the Haar transforms of the long sequences. The thought being that the Haar wavelet could be suitable for catching the similarities between long and short HAP with small and large differences.
But I don’t have any ready made software for computing the transform myself.
April 27, 2010 at 8:53 pm
At this website:
http://www.cs.ucf.edu/~mali/haar/
There is an implementation of the one dimensional Haar transform in C++.
April 26, 2010 at 2:00 pm |
One kind of strategy that probably comes under 3 is to think about some natural generalization of the problem, in the hope of narrowing down the set of possible lines of enquiry. For example, what happens if we generalize the order of the tensor product? Can we express a ‘diagonal’ -tensor with unbounded ‘trace’ as
-tensor with unbounded ‘trace’ as  with each
with each  a HAP and
a HAP and  ? The quotation marks around ‘diagonal’ and ‘trace’ mean that I’m not sure of the best generalization of these ingredients. (But with the obvious specialization to
? The quotation marks around ‘diagonal’ and ‘trace’ mean that I’m not sure of the best generalization of these ingredients. (But with the obvious specialization to 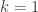 the answer is trivially ‘yes’: we can take
the answer is trivially ‘yes’: we can take 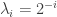 and
and  the HAP of length
the HAP of length 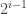 and common difference one.)
and common difference one.)
April 26, 2010 at 5:03 pm |
“Although there are several promising approaches to solving EDP, I am going to concentrate just on the representation-of-diagonals idea and pretend that that is the problem.”
Why?
April 26, 2010 at 5:39 pm
There are all sorts of reasons I could give. When I’m working on a problem, something I like doing is feeling that I’ve reduced everything to some smaller problem. Sometimes the “reduction” isn’t a formal implication but more like a feeling that if I could do A then I could probably do B, where B is what I ultimately want to do. Then it feels good to say, “Right, I’m going to forget about B and concentrate on A.” Here, things are even better, because we have a problem B that is in a certain sense easier than A (I think I can justify that statement) and does formally imply A.
Now Moses’s approach had the same property, so why choose the representation-of-diagonals approach? Well, the first thing to say is that I’m very much not trying to exclude any other approaches, and if someone were suddenly to make an observation that gave us a serious new hope about carrying out Moses’s approach, or some other approach again, then my inclination would probably be to abandon the representation-of-diagonals approach and go all out to try to push that new idea. But the reason I went for representation-of-diagonals is that I find it simpler to think about (because I find it hard to understand what makes a matrix positive definite) and it implies a stronger result (which makes me hope that solutions will be “more unique” and therefore easier to find).
Of course, this is Polymath. Shouldn’t we all be working in parallel? Well, perhaps. But I think that the number of people actively working on the theoretical side is small enough that there could also be some virtue in focusing the discussion (temporarily of course) on certain approaches, since if everybody spreads out then there will be less of the interaction that is the whole point of Polymath. If there were 45 people all devoting their whole time to the project, then the calculation would change completely.
Finally, I can’t force anyone to go with me on this. But if nobody wants to, I’m still interested enough in this approach that I’ll pursue it on my own (and report any thoughts that aren’t a complete waste of time to this blog as soon as I have them).
Sorry, that wasn’t final after all. I know that there are other interesting questions — computational ones for instance — that other people are still looking at. I certainly don’t suggest that they drop everything and concentrate just on this theoretical question. Basically, what I wrote was an invitation to have a certain mini-discussion. That’s all there was to it.
April 26, 2010 at 8:51 pm
Why not! we can have mini-discussion on the representation of diagonal approach which indeed looks very nice;
I am interested in the meta polymathing issue of how to proceed with such an open collaboration project. Which paths to take as a group? And also which paths to pursue individually; Naturally people like to pursue their own ideas, which is overall good, but it is also part of the business to think about ideas of others. (All these are interesting issues in ordinary collaborations but here they are more open.)
We started with being very careful (perhaps overly so) regarding collective choices and various matters of procedure in polymath1, and now perhaps we cut a few corners.
April 26, 2010 at 9:35 pm
I’m very open to other suggestions. There is of course an asymmetry about running this on my own blog, which is that I get to write the posts (as opposed to the comments). So I hereby make the following suggestion. If somebody would like to argue in an extended way for a different approach to the problem, then I’ll be happy to invite them to write a guest post.
April 29, 2010 at 2:44 am
Tim,
I came across these papers a few days ago (see below), and the more I work through them I think they may be useful to classify sequences in EDP.
The first paper explores the relation between the Kolmogorov-Sinai entropy, which describes the rate of increase of entropy in a chaotic system (here a measure preserving, recursive map over a real interval), and the Shannon-Khinchin entropy, S(t) = -k sum_i p_i \log p_i.
The second, more interesting paper studies the same type of problem at the “edge of chaos”, where S(t) is replaced by the Tsallis entropy, S_q(t), that tends to S(t) as q goes to 1 (at the edge of chaos, q is related to the characteristics of the mapping).
I think it may be better to see what you think of this than go into it further. I remember in one of the earlier posts someone had suggested applying entropy ideas to EDP but I don’t know if this went anywhere. Anyways, if it seems worthwhile, there is also a set of ‘mini-reviews’ on Tsallis’ web site.
The references are :
Latora et. al., Phys. Rev. Lett. 82, 520 (1999), Physics Letters A, 273, 97 (2000).
Tsallis’ site is at :
http://tsallis.cat.cbpf.br/biblio.htm
The PRL can be obtained from the arXiv site, but I think you may need to go to Physics Letters to get the second. The approach would apply to your heading (6) above.
April 26, 2010 at 11:48 pm |
[…] Density Hales-Jewett and Moser numbers By kristalcantwell The paper “Density Hales-Jewett and Moser numbers” has been accepted. I have just read a a post here in which this is discussed. Apparently a few minor changes are needed. That is good news. Also there is a new thread for the Polymath5 project here . […]
April 27, 2010 at 6:59 am |
A remark regarding the Linear Programming approach based on the “non symmetric vector valued EDP” (considered here) and the closely related SDP approach.
A successful “role model” in applying linear programming methods for assymptotic questions in for error-correcting-codes/spherical codes/packing questions. In these problems the linear program was related to properties of some familiar classes of orthogonal polynomials. The question is if something in this direction can be hoped for our problem.
April 27, 2010 at 8:03 am
That sounds interesting. Can you point us towards anywhere where it is possible to read about this? (An online reference would be ideal.) Or is it possible to describe the basic idea in a comment? At the moment, I don’t have a clear conception of where the orthogonal polynomials are coming in.
The reason I’m intrigued is that at least the words of what you say fit in with a possible approach to the diagonal decomposition problem. Suppose you’ve decided what you want the diagonal matrix to be. Then you could use that to define an inner product (in an obvious way — if the diagonal matrix has coefficients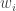 then the inner product is
then the inner product is  ) and apply Gram-Schmidt to that inner product, starting with some natural basis of
) and apply Gram-Schmidt to that inner product, starting with some natural basis of  . That gives you a decomposition of a diagonal matrix into matrices of the form
. That gives you a decomposition of a diagonal matrix into matrices of the form 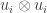 , where
, where  is the resulting orthonormal (with respect to the funny inner product) basis. Then you hope that your choices are such that each
is the resulting orthonormal (with respect to the funny inner product) basis. Then you hope that your choices are such that each  decomposes nicely into HAP products, and, better still, that there is cancellation in the coefficients used for different
decomposes nicely into HAP products, and, better still, that there is cancellation in the coefficients used for different  s.
s.
That proof strategy has a number of awkward “wild guess” steps at the moment, but if something similar already exists, then perhaps this unsatisfactory aspect could be reduced.
April 27, 2010 at 5:16 pm
While I’m only familiar with the Gaussian elimination version of the algorithm, there’s a paper from 2008 about a variant of the LLL algorithm that uses orthogonal transformations (this paper, looks like). I don’t have Elsevier access so I don’t know if there’s anything salvagable from their approach.
April 27, 2010 at 8:27 pm |
Delsartes linear programming method is a way to find the maximum size of a code with minimal distance d inside various types of symmetric metric spaces. A code C of minimum distance d is a set of points so that the minimum distance between every pair of points is d. Here is a link to a paper of Barg and Nogin about this method http://www.springerlink.com/content/k30u412357230m88/fulltext.pdf (I dont think the link works universally) Some natural families of orthogonal polynomials appear in the solutions and the approach has also an appealing Fourier theoretic description. Here is a rekated paper by Navon and Samorodnitzky http://www.cs.huji.ac.il/~salex/papers/dels_ft.ps.
I will try to find further papers available online and perhaps web explanations. The problem is sufficiently remote from EDP for the connection to be concrete but this is a good stuff to know anyway.
If I remember right (from a remark of Moses) the LP required for the non symmetric vector valued problem (the one we consider) will require variables for pairs of HAP’s or something like that. So I cannot imagine what kind of polynomials might be relevant here (if any) and where do they live. Anyway, since the intention was to step back and try to discuss strategies, it worth mentioning that the Delsartes method is a very powerfull LP-based method.
April 28, 2010 at 6:00 am |
I only began following this blog a week or two ago, so please excuse me if I rediscover things which have already been mentioned.
I wrote a Mathematica program to examine +-1 sequences which are multiplicative, but not completely multiplicative. I found that such sequences of length greater than 260 must have discrepancy >2.
April 28, 2010 at 6:31 am
This hasn’t been mentioned; however, I thought I had found a (weakly) multiplcative length-344 sequence of discrepancy 2:
+-++–+–+-++–+-++-++–+–+-++–+–+-++–+-++-++–+-++-++–
+–+-++–+-++-++—-++-++–++-+-++–+-++-+—+–+-+++-+–+-+
+–+-+–+++-+-++-+—+–+-+++—++-+++-+–+-++–+–+-++—++
+-++–+–+++—+–+-++–++++-+—+-++-++–+—+++–+-++–+–
+-++-++–+–++++–+-+–++-++—-++–++-+-++–+-++-++–+-+–+
++-+–+–++—+-+++–+-++-++–+–+-+–++-++-
It is a little surprising that weakening the multiplicativity condition doesn’t get you very much further.
April 28, 2010 at 6:32 am
Try again:
April 28, 2010 at 9:21 am |
Indeed when I ran the multiplicative case I found 100.000ish sequences of length 100+ rather than 100ish in the completely multiplicative case. Maybe I should check the code and if its correct let it run a little further.
April 28, 2010 at 5:24 pm |
I’ve checked the weakly multiplicative sequence of length 344 and discripancy 2 given by Edgington, and there’s no problem with it. Clearly, my calculations, which led to my posting this morning, must be incorrect. I’ll go back and see if I can find my error (or errors.)
April 28, 2010 at 7:36 pm
Incidentally, that sequence is quite close to completely multiplicative: it satisfies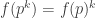 except for
except for  .
.
April 28, 2010 at 9:14 pm |
My exhaustive search has finished. There are 5.820 multiplicative sequences of length 344 and none of 345. Alec’s example is best possible.
April 29, 2010 at 6:59 pm |
Reading this blog has given me new ideas about a different problem which I’ve been thinking about, on and off, for a long time. So I feel justified in describing that problem up even though it’s somoewhat off topic.
Start with the generating function for unrestricted partitions:
(1+x+x^2+x^3+…) (1+x^2+x^4+x^6+…) (1+x^3+x^6+x^9+…)…
Now replace some of the plus signs with minus signs. The coefficient of x^n in the resulting series will, of course, be congruent (mod 2) to the number of unrestricted partitions of n. Is it possible to choose the signs so that the resulting series has coefficients which are all either +1, -1, or 0?
April 30, 2010 at 9:34 am
This is a very nice problem! What is known?
April 30, 2010 at 9:33 am |
Maybe It will be good to write down explicitly a few LP problems based on the representation-of-diagonal idea. (Preferably both the primal and dual versions.)
April 30, 2010 at 12:25 pm |
I didn’t see anything on the wiki explaining the representation-of-diagonals approach, so I’ve created a stub here (linked from the front page) for us to use as a repository of results and ideas related to it.
April 30, 2010 at 5:28 pm |
Gil wrote: ” This is a very nice problem! What is known?”
There’s not much known. I did some computations years ago and found some series which answered the problem for coefficients up to about x^110.
Here is a comment from George Andrews:
“I doubt that what you want is possible in any way that would be useful. I.e. we know that it is a major unsolved problem to prove that p(n) is odd for half of the integers (Ken Ono has made major contributions to this problem but he is nowhere near solving it). Thus it is likely that the +/- 1’s appear at half the places with a seemingly random distribution that fits this probability of 1/2. Thus I doubt that there is any reasonable way of solving your problem.”
Here is a comment from Freeman Dyson:
” After a few minutes spent analyzing your problem, I think the answer is negative, no solution exists. Each of the factors in the product, considered as functions analytic in the unit circle, has to be large over some arcs of the circle and small over other arcs. The problem is to arrange the arcs so that the large factors are everywhere compensated by small factors. I conjecture that this is impossible, but I am not close to having a proof. Anyhow, it is a good problem.”
May 1, 2010 at 7:01 am |
One thing about this approach that I find both disturbing and interesting is that the proof that it implies EDP doesn’t make any use of the fact that we’re considering HAPs. In other words, it’s an approach that could be applied to any discrepancy problem. This leads me to wonder the following.
For a set system over
over  , let
, let  be the statement that all subsets of
be the statement that all subsets of  have bounded discrepancy with respect to
have bounded discrepancy with respect to  (so when
(so when  consists of all HAPs, this is EDP); and let
consists of all HAPs, this is EDP); and let  be the corresponding ‘diagonal representation’ statement: that there exists a diagonal matrix with unbounded trace expressible as a combination
be the corresponding ‘diagonal representation’ statement: that there exists a diagonal matrix with unbounded trace expressible as a combination  with
with  and
and  characteristic functions of sets in
characteristic functions of sets in  .
.
We always have . Can we find examples of set systems
. Can we find examples of set systems  such that
such that  is true but
is true but  is false? For example, is
is false? For example, is  true if we take
true if we take  to consist of all APs?
to consist of all APs?
May 1, 2010 at 7:06 am
In the second paragraph, when I said ‘bounded discrepancy’ I meant ‘unbounded discrepancy’.
May 2, 2010 at 9:25 am
As Tim points out below, his proof sketch of Roth’s theorem via diagonal representation implies that is true if we take
is true if we take  consisting of all APs. Your question is whether there exist set systems
consisting of all APs. Your question is whether there exist set systems  such that
such that  is true but
is true but  is false. I believe that such set systems do exist for the following reason:
is false. I believe that such set systems do exist for the following reason:
Alantha Newman, Aleksander Nikolov and I have the following (not yet written up) result: Consider a system of sets on
sets on  elements.
elements.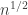 (roughly speaking). Now given such a set system, we can always compute the best lower bound on discrepancy that can be proved by the representation of diagonals approach in time polynomial in
(roughly speaking). Now given such a set system, we can always compute the best lower bound on discrepancy that can be proved by the representation of diagonals approach in time polynomial in  (this involves solving an LP). This bound should not be able to distinguish between the discrepancy 0 and discrepancy
(this involves solving an LP). This bound should not be able to distinguish between the discrepancy 0 and discrepancy  case. Hence, for some set systems in the class of instances constructed by the NP-hardness proof, the representation of diagonals approach ought to give a bound of 0, while the actual discrepancy is
case. Hence, for some set systems in the class of instances constructed by the NP-hardness proof, the representation of diagonals approach ought to give a bound of 0, while the actual discrepancy is  . In fact, this must be true of any polynomial time computable bound (if
. In fact, this must be true of any polynomial time computable bound (if  ).
).
Then it is NP-hard to distinguish between set systems with discrepancy 0 and those with discrepancy
May 2, 2010 at 7:41 am |
Here’s a simple sanity check on the method. Apologies if this has been answered already, or if I’m just being dim. Can we construct an diagonal matrix
diagonal matrix  such that
such that  where
where  are any subsets of
are any subsets of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 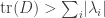 ?
?
May 2, 2010 at 8:01 am
Yes, just take .
.
May 2, 2010 at 8:08 am
Doesn’t that give equality?
May 2, 2010 at 8:54 am
Ok, I think this works. Take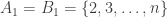 ,
,  for
for  , and
, and  .
.
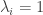 for
for 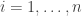 and
and  . Then
. Then  is a diagonal matrix
is a diagonal matrix  .
.  and
and  .
.
May 4, 2010 at 12:52 pm
Yes, that works — as does Tim’s construction. And I think we can get an arbitrarily high ratio by letting run over all
run over all  -element subsets, with
-element subsets, with 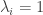 , and then subtracting
, and then subtracting 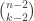 times
times ![\chi_{[n] \times [n]}](https://s0.wp.com/latex.php?latex=%5Cchi_%7B%5Bn%5D+%5Ctimes+%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) (this gives a ratio of about
(this gives a ratio of about  for
for  ).
).
I’m vaguely wondering about a type-6 approach where one starts with a solution in some larger set system and then tweaks the set system until one reaches a system of HAPs.
May 2, 2010 at 8:08 am |
Sorry, I misread the question. You are asking for strict inequality, so my naive solution does not answer your question.
May 2, 2010 at 8:58 am |
Here’s a simple example that solves the question Alec asks above. (As a matter of fact, it has been answered already if you buy my sketch a few weeks ago of a proof of Roth’s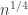 bound using the representation-of-diagonals approach.)
bound using the representation-of-diagonals approach.)
The simple example is as follows. First observe that if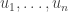 is any orthonormal basis of
is any orthonormal basis of  , then
, then  is the identity. Now apply that to the Walsh basis of
is the identity. Now apply that to the Walsh basis of 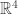 , which consists of the vectors (1,1,1,1), (1,1,-1,-1), (1,-1,1,-1) and (1,-1,-1,1), all divided by 2. Now
, which consists of the vectors (1,1,1,1), (1,1,-1,-1), (1,-1,1,-1) and (1,-1,-1,1), all divided by 2. Now  is half the characteristic function of a set, so
is half the characteristic function of a set, so  contributes 1/4 to the sum of the absolute values of the coefficients. Each other
contributes 1/4 to the sum of the absolute values of the coefficients. Each other  is half the difference of two sets, so it contributes 1 to the sum of the absolute values. So the sum of the absolute values is 3.25 and the trace is 4.
is half the difference of two sets, so it contributes 1 to the sum of the absolute values. So the sum of the absolute values is 3.25 and the trace is 4.
May 4, 2010 at 2:53 pm |
I don’t remember if this paper has been brought up earlier in the discussion. It show that for a larger family if sequences, including HAPs, the discrepancy is unbounded and grows at least as fast a power of
http://www.combinatorics.org/Volume_15/Abstracts/v15i1r104.html
May 4, 2010 at 4:16 pm
This looks very interesting and relevant. Interesting that we did not think about this variation of the problem…
May 4, 2010 at 7:22 pm
The problem is (and always has been) mentioned immediately following the statement of EDP on the wiki, but I don’t think we’ve discussed the techniques involved at all. There are some other related papers in wiki bibliography, too.
May 4, 2010 at 8:11 pm
It would be interesting to see whether the proof in the paper can be used to define a representation of a diagonal matrix by means of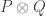 s, where now
s, where now  and
and  are allowed to be quasi-progressions.
are allowed to be quasi-progressions.
May 5, 2010 at 3:26 am
The relevant result is Theorem 1 of Vijay’s paper. He considers quasi-progressions (
( is a real number), and proves that the discrepancy of quasi-progressions contained in
is a real number), and proves that the discrepancy of quasi-progressions contained in  is at least
is at least  . (I’m dropping multiplicative constants for convenience).
. (I’m dropping multiplicative constants for convenience).
The proof of this makes crucial use of Roth’s theorem on the discrepancy of APs. can be realized as a quasi-progression. If the common difference of the AP is
can be realized as a quasi-progression. If the common difference of the AP is  , the proof shows one can pick a quasi-progression of difference
, the proof shows one can pick a quasi-progression of difference  that coincides with the AP on the interval
that coincides with the AP on the interval  . By Roth’s theorem, the discrepancy of APs on an interval of size
. By Roth’s theorem, the discrepancy of APs on an interval of size 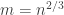 is
is  . QED.
. QED.
The main observation is that any AP on
So the proof can be expressed in the language of diagonal representations by appealing to Tim’s diagonal representation version of Roth’s result, but I think Tim was hoping to extract something more interesting than this.
May 5, 2010 at 9:38 am
Indeed, I was. However, perhaps for the kind of reason put forward by Alec in this comment, this could nevertheless be progress of a kind.
I’m not saying that I think that a homogeneous quasi-progression can be represented as a bounded combination of HAPs, but it might be worth understanding why it can’t. And even if we need too many HAPs to make a HQP, perhaps it can be done in such a way that the surplus HAPs cancel when you produce the representation.
Actually, while writing that I realize it’s got a serious problem to it, which is that presumably the HQP result produces a representation of the identity, and we know we can’t get that with HAPs.
May 5, 2010 at 10:35 am
The original version of this theorem is a result by Beck with a weaker lower bound for the discrepancy. Does anyone know if the original proof also reduces to Roth?
May 9, 2010 at 8:29 am |
During the night my program finished its work on N=2016 for C=2. It found no such sequences. So we now know that a sequence of discrepancy 2 must have length less than 2016.
This computation required a lot more CPU time than I had expected. It has been running on several different machines, in the gaps between other things I am working on. A while back Tim wrote that this would be a “the first rigorous (and very computer-assisted) proof “. I don’t have an exact number right now but an estimate is that “very computer-assisted” translates into about 30 CPU-core years of computer time.
May 9, 2010 at 11:47 pm
I’m curious. What does a sequence of length 2015 look like?
May 10, 2010 at 2:15 am
As I understand, the longest sequence with discrepancy 2 that we have has length 1124. Klas’ work shows that there are none with length 2016. Thus, the truth lies somewhere between 1124 and 2015, inclusive.
May 10, 2010 at 6:17 am
Kevin’s description is correct. I have only found an upper bound on the length of the longest sequence of discrepancy 2,
May 10, 2010 at 1:35 pm
The obvious way to bound the length of a discrepancy 2 sequence is a depth first search of the space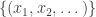 of
of  sequences. The only type of upper bound this could lead to would be the exact truth, though. Klas, I’m guessing that your code was looking at assignments of
sequences. The only type of upper bound this could lead to would be the exact truth, though. Klas, I’m guessing that your code was looking at assignments of  for highly composite
for highly composite  early, i.e., a depth first search through
early, i.e., a depth first search through  for some permutation
for some permutation 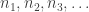 of the natural numbers. Is this correct? Is there someplace on the blog (or the wiki) where the algorithm is described?
of the natural numbers. Is this correct? Is there someplace on the blog (or the wiki) where the algorithm is described?
May 10, 2010 at 2:19 pm |
What I have done is to translate the problem into a boolean constraint satisfaction problem, using boolean clauses and cardinality constraints. So instead of +1 -1 I have True False, and there number of True and False variables in each HAP must be within the right bounds.
I picked a value for the length n which made sure that there are many different HAPs which include the value n, thereby restricting the value at n more.
Next I split the problem into subproblems by assigning valeus to the first few values. Each subproblem was then run for a fixed amount of time in an extended SAT-solver called Umsat, the source code for Umsat is available here http://abel.math.umu.se/~klasm/prog/Umsat/
The unsolved subcases were extended to include those forced variable assignment which the program had discovered during the run. Finally each remaining subcase was split into two subcases, by assigning the next unassigned variable.
Umsat, like most other modern SAT-solver uses non-chronological backtrack and clause learning. This means that it does not perform a simple depth first search, since the learning allows it to exclude large parts of the search space without explicitly searching through it. It also does not have a variable ordering which is constant during the search.
I should also mention that Daniel Andrén is working on a complete rewrite of Umsat which shoul make both faster and more flexible.
May 10, 2010 at 2:20 pm
Sorry, that should have been posted as a reply to Kevin’s question about the algorithm used.
May 10, 2010 at 9:21 pm |
[…] discrepancy 2. It must have length less than 2016. The longest such sequence we have is 1124. see here for more information. For more about the computation there is this post […]
May 11, 2010 at 6:17 pm |
I’ve rewritten my graph theory approach.
First, I dumped labelling the edges and just considered the edges to be from different sets. This allows me to clean up the terminology a little.
I added an acyclic condition because it is otherwise ambigious to find the discrepancy, and added the “paths only” condition because any trees can be simulated with multiple paths.
(General formulation)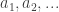 with k sets of directed edges
with k sets of directed edges 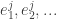 (for
(for 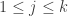 ) such that each set of edges (with corresponding nodes) forms an acyclic path.
) such that each set of edges (with corresponding nodes) forms an acyclic path.
Define a set of nodes
Give each node a value of 1 or -1. Consider any traversal corresponding to a set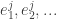 that starts at the root node; define the absolute value of the sum of the values of the nodes visited to be
that starts at the root node; define the absolute value of the sum of the values of the nodes visited to be  . The largest value of
. The largest value of  for all possible values of j is the discrepancy.
for all possible values of j is the discrepancy.
Possible conditions given a set of nodes :
:
No subsets (NS): No set of edges is a subset of another set.
Omega set (OS): One labelled set of edges connects to
to 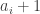 for all i from 1 to n-1.
for all i from 1 to n-1.
(Needs OS) Always increasing (AI): For any edge from to
to 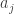 , i is less than j.
, i is less than j.
Isolated roots (IR): Each node can be the root node of only one labelled set of directed edges. [This condition is needed for the definition of completely multiplicative.]
It’d be best for conjectures to use a minimal number of conditions, but I don’t know which ones to choose yet.
Conjecture (I have a rough proof, but it needs checking):
Given only two sets of edges (and none of the extra conditions NS OS AI IR), with optimal placement of 1s and -1s the discrepancy can always be 1.
June 13, 2010 at 4:40 am
I have a proof to the conjecture now (using a combinatorial game theory trick) but I don’t have time for the writeup yet.
I am mainly posting because there’s been little activity and wondering what was going on with everyone. Is this still on?
June 13, 2010 at 12:41 pm
Speaking for myself, I have been busy with other things for a while. But by coincidence I found myself with a few hours to spare (on a plane) and had a few thoughts about EDP as a result. I think I’ll write a new post soon and see whether anybody takes the bait.
May 14, 2010 at 10:14 am |
In the completely multiplicative situation there might be some connection to sieves. Let me just sketch the idea. In my last comments I was considering completely multiplicative functions and the result after flipping
and the result after flipping  at some prime
at some prime  . Using inclusion-exclusion this can be extended to flipping at arbitrary (infinite) sets of primes. For this argument it suffices to consider
. Using inclusion-exclusion this can be extended to flipping at arbitrary (infinite) sets of primes. For this argument it suffices to consider  constant one. Let
constant one. Let  denote the set of primes
denote the set of primes 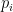 with
with  and let
and let 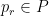 be the largest prime with
be the largest prime with  then
then
Define
Let us, just to get some confidence in the result, take our record holder
Assuming bounded discrepancy one would estimate the rhs. Control over the lhs is crucial to get a contradiction . The idea now is to observe the similarity of the lhs to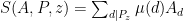 and use/extend sieves to estimate it. I have no reason to be overly optimistic that this works and even results for discrepancy
and use/extend sieves to estimate it. I have no reason to be overly optimistic that this works and even results for discrepancy  and special
and special  like
like  (to establish f(2)=-1) or
(to establish f(2)=-1) or 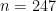 (to establish non-existence) would currently be a progress.
(to establish non-existence) would currently be a progress.
May 16, 2010 at 1:29 am |
I filled out Tim’s outline of a “representation of the diagonal” proof of Roth’s Theorem (concerning discrepancy on APs). It’s on the wiki.
I took out some of the motivation and put in too much detail.
Now I’m ready to think about the last 3 paragraphs of Tim’s comment on how to get from to
to 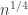 . Unfortunately, I think I may need a little more direction. Any hints?
. Unfortunately, I think I may need a little more direction. Any hints?
May 17, 2010 at 9:20 am
I’ll need to think more before being certain that this works, but it seems to me that some improvement could come from the following modification to the argument: instead of choosing one d for each r, one should instead choose all the d that work and take an average. I think that that ought to lead to a more explicit calculation and, if one is sufficiently careful, a better bound, but I can’t do it in my head so I’m definitely not sure about this yet.
June 19, 2010 at 9:52 am |
In the recent two related approaches of Mozes’ SPD and of Gowers’s repreentation of diagonal matrices we somehow hope that the SPD and LP problem “will do all the work”. However, in earlier discussions we gained some additional information on how an example of bounded discrepency should look like. In particular, Tao’s argument suggests that a counterexample will have diminishing correlation with every character on every HAP. (Terry proved it for multiplicative sequences but we can expect that this extends to general sequences.) Maybe it can be fruitful to add the condition of “small correlation with a caracter on every HAP” to Mozes’ SPD or Gowers’s LP, and hope to detect some pattern with such extra assumption. At the time, dealing with (say) multiplicative functions with diminishing correlation with every character lookes appealing.
June 21, 2010 at 12:09 pm |
[…] second remark is essentially the same as this recent comment of Gil’s. It’s that we already know that the extremal examples — by which I mean long sequences […]