In this post I want to use my unfair advantage as host of this blog to push an approach that is the one that I am currently most interested in. So let me precede it with the qualification that although I shall present the approach as favourably as I can, it may well be that Moses’s SDP approach or Gil’s polynomial approach will in the end turn out to be more fruitful. I should also add that this new approach makes use of a crucial insight from the SDP approach, which is the idea that one can prove a result about all sequences 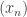 , including our troublesome friend 1, -1, 0, 1, -1, 0, … if we bound the discrepancy below by an expression of the form
, including our troublesome friend 1, -1, 0, 1, -1, 0, … if we bound the discrepancy below by an expression of the form  .
.
Lewis’s theorem
Before I explain the new result, I’d like to discuss a result from the geometry of Banach spaces. (I don’t need to do this, but it is a very nice result and this is a good excuse to write about it. If you just skim this section and take note of the definition of “well spread out” below, that will be enough to follow the rest of the post.) The result is a special case of an important theorem of Dan Lewis, though the proof that I shall sketch is a little different from Lewis’s.
Let  be a symmetric convex body in
be a symmetric convex body in  . The minimal volume ellipsoid of is, as its name suggests, the ellipsoid of minimal volume that contains . Now if
. The minimal volume ellipsoid of is, as its name suggests, the ellipsoid of minimal volume that contains . Now if  is this ellipsoid, then obviously the boundary of will touch the boundary of , or else we could just shrink by a small amount and have a new ellipsoid with smaller volume that still contains . (For what it’s worth, this argument relies on compactness, which guarantees that if the boundaries of and are disjoint, then there is a positive distance between them.)
is this ellipsoid, then obviously the boundary of will touch the boundary of , or else we could just shrink by a small amount and have a new ellipsoid with smaller volume that still contains . (For what it’s worth, this argument relies on compactness, which guarantees that if the boundaries of and are disjoint, then there is a positive distance between them.)
However, a moment’s thought suggests that we ought to be able to say more. Suppose, for instance, that is a sphere and that its boundary touches the boundary of only at two antipodal points. It feels as though we ought to be able to expand in the subspace orthogonal to those points and get a larger affine copy of inside . Note that the problem of finding the minimal volume ellipsoid that contains is equivalent to the problem of finding the maximum volume linear copy of contained in the unit sphere, where by “linear copy” I mean the image of under a linear map.
More generally, it ought to be the case that if we take the maximum volume linear copy of inside the unit sphere  , then the contact points (that is, the points where the boundary of touches the boundary of ) should be “well spread about”. The intuition would be that if the contact points are not well spread about, then we could find some big area of the sphere that is nowhere in contact with and expand into that area (perhaps very slightly contracting in other places in such a way as to increase the volume in total).
, then the contact points (that is, the points where the boundary of touches the boundary of ) should be “well spread about”. The intuition would be that if the contact points are not well spread about, then we could find some big area of the sphere that is nowhere in contact with and expand into that area (perhaps very slightly contracting in other places in such a way as to increase the volume in total).
To turn this intuition into a formal proof, we need to start with a formal definition. When do we count some unit vectors (the contact points) as being “well spread about”? There turns out to be a very nice answer to this: define the unit vectors 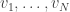 to be well spread about if there are positive scalars
to be well spread about if there are positive scalars 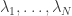 such that the identity matrix
such that the identity matrix  . Here, I write
. Here, I write  for the matrix
for the matrix  . One could alternatively think of the
. One could alternatively think of the  as column vectors and write
as column vectors and write  for the sum instead. Either way, if
for the sum instead. Either way, if  is any vector, then
is any vector, then  . Another small remark is that saying that
. Another small remark is that saying that 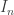 can be written as
can be written as 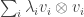 with positive
with positive  is equivalent to saying that
is equivalent to saying that  belongs to the convex hull of the
belongs to the convex hull of the  , since the trace of is
, since the trace of is  , and this implies that the have to add up to
, and this implies that the have to add up to  . A more geometrical way of expressing this condition is as follows. A well-known property of orthonormal bases
. A more geometrical way of expressing this condition is as follows. A well-known property of orthonormal bases 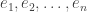 is that each vector is equal to the sum of its projections on to the 1-dimensional subspaces generated by the basis vectors: that is,
is that each vector is equal to the sum of its projections on to the 1-dimensional subspaces generated by the basis vectors: that is,  for every . The unit vectors are well spread about if we can find weights such that every is equal to the weighted sum of the “coordinate projections”: that is, we need positive constants such that every is equal to
for every . The unit vectors are well spread about if we can find weights such that every is equal to the weighted sum of the “coordinate projections”: that is, we need positive constants such that every is equal to  .
.
Lewis’s theorem is the statement that the contact points of and the maximal volume copy of inside are well spread about in this sense. (Or rather, Lewis’s theorem is a more general statement of which this is a special case.) Before I sketch the proof, let me point out that it implies Fritz John’s famous result that for any symmetric convex body  there is an ellipsoid such that
there is an ellipsoid such that  . To show this, let
. To show this, let  be the Euclidean norm and let
be the Euclidean norm and let 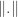 be the norm with unit ball . Since
be the norm with unit ball . Since  we know that
we know that  for every . If we can write as , where each is a contact point, then since each is a unit vector in both norms, we know that
for every . If we can write as , where each is a contact point, then since each is a unit vector in both norms, we know that  . By Cauchy-Schwarz, the square of this is at most the product of
. By Cauchy-Schwarz, the square of this is at most the product of 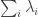 and
and  . But the latter expression is equal to
. But the latter expression is equal to  . Therefore,
. Therefore,  , so
, so  , which is equivalent to saying that
, which is equivalent to saying that  . And this obviously implies John’s theorem.
. And this obviously implies John’s theorem.
And now for the proof of the assertion about the contact points. Let us suppose that is not in the convex hull of the matrices  with
with  a contact point. Then by the Hahn-Banach separation theorem there exists a linear functional that separates from all such matrices. We can phrase this in terms of the matrix inner product
a contact point. Then by the Hahn-Banach separation theorem there exists a linear functional that separates from all such matrices. We can phrase this in terms of the matrix inner product  , which is the trace of
, which is the trace of 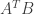 . Then the linear functional can be thought of as a matrix with the property that
. Then the linear functional can be thought of as a matrix with the property that  , which is
, which is  times the trace of , is 1, whereas there is some
times the trace of , is 1, whereas there is some 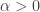 such that
such that  for every contact point . Now
for every contact point . Now  is equal to
is equal to  .
.
Now if is any  matrix, then the determinant of
matrix, then the determinant of  is
is  . It follows that if the trace of is , then the determinant of
. It follows that if the trace of is , then the determinant of  is
is  .
.
Next, we use the fact that  for every contact point . If
for every contact point . If  is another unit vector, then
is another unit vector, then

which is at most  If
If  , then this is at most
, then this is at most  . Thus, there is a positive constant
. Thus, there is a positive constant  , independent of
, independent of  , such that if is a contact point and
, such that if is a contact point and  then
then  . From this it follows that
. From this it follows that 
By compactness, there is some positive distance between the inner symmetric convex body and the set of all points on the surface of the sphere that are not within of a contact point. Therefore, if we perturb by a sufficiently small amount, we will not cause any point not within of a contact point to go inside . But the volume of  is equal to the volume of up to
is equal to the volume of up to  and every point within of a contact point maps to a point of norm at most
and every point within of a contact point maps to a point of norm at most  . Therefore, for sufficiently small , the body
. Therefore, for sufficiently small , the body  has volume greater than that of but still lies inside the unit sphere. The proof is complete.
has volume greater than that of but still lies inside the unit sphere. The proof is complete.
What has this to do with EDP?
The Erdős discrepancy problem asks us to prove that if is any  sequence of length , then there is some HAP with characteristic function
sequence of length , then there is some HAP with characteristic function  such that
such that  . Now one way one might imagine trying to show this would be by showing that these functions are so spread about that every sequence of
. Now one way one might imagine trying to show this would be by showing that these functions are so spread about that every sequence of 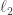 norm
norm  (that is, every sequence such that
(that is, every sequence such that  ) has inner product at least
) has inner product at least  with one of them. And that one could prove if one had a representation
with one of them. And that one could prove if one had a representation  with
with  , since
, since

Actually, there is an obvious problem with this idea, which is that if all the are positive, then unless all the  are singletons then there will be positive elements off the diagonal and therefore no hope of representing the identity. However, one can rescue the situation by considering slightly more general vectors such as convex combinations of the set of all s and their negatives. If is such a combination and
are singletons then there will be positive elements off the diagonal and therefore no hope of representing the identity. However, one can rescue the situation by considering slightly more general vectors such as convex combinations of the set of all s and their negatives. If is such a combination and  , then must have discrepancy at least in one of the HAPs that makes up . And the advantage of these vectors is that they are allowed to have negative coordinates.
, then must have discrepancy at least in one of the HAPs that makes up . And the advantage of these vectors is that they are allowed to have negative coordinates.
I had this thought a few years ago when attempting solve EDP and dismissed it once I spotted that the troublesome 1,-1,0,1,-1,0,… example kills the idea. It simply isn’t true that if is a sequence of length and  , then has unbounded discrepancy in some HAP, as the troublesome example (multiplied by
, then has unbounded discrepancy in some HAP, as the troublesome example (multiplied by  ) demonstrates.
) demonstrates.
However, an important lesson from the SDP approach is that this is a less serious problem than it at first appears, because we are not forced to use the norm as a lower bound for discrepancy. Instead, we can use a weighted norm. In the context of this proof, this suggestion becomes the idea that instead of trying to represent the identity, we could go for a diagonal matrix with large trace instead.
To spell this out, let us define a test vector to be any vector of the form  , where
, where  and the are characteristic functions of HAPs. Suppose that
and the are characteristic functions of HAPs. Suppose that  is a diagonal matrix with entries
is a diagonal matrix with entries 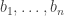 down the diagonal, and that we can write it as a convex combination , where the are test vectors. Then if is any sequence, we know that
down the diagonal, and that we can write it as a convex combination , where the are test vectors. Then if is any sequence, we know that  . But from the representation of we also know that
. But from the representation of we also know that

It follows that there exists  such that
such that  , and hence, since is a test vector, that the discrepancy of in some HAP is at least
, and hence, since is a test vector, that the discrepancy of in some HAP is at least  as well.
as well.
Thus, we can prove EDP if we can find a convex combination , where the are test vectors, that equals a diagonal matrix with unbounded trace.
Moses Charikar points out a modification of this requirement that is somewhat simpler. If  with
with  , then
, then  , which is a convex combination of matrices of the form
, which is a convex combination of matrices of the form  , where both and
, where both and  are characteristic functions of HAPs. Conversely, if we write a diagonal matrix as
are characteristic functions of HAPs. Conversely, if we write a diagonal matrix as  , where the and
, where the and  are HAPs and
are HAPs and  , then
, then

From this it follows, as before, that if is a sequence then there is some HAP on which the discrepancy of is at least  .
.
The non-symmetric vector-valued EDP.
Why should we believe that good representations of diagonal matrices exist?The best answer I can give to this is that it turns out to be equivalent to a strengthening of EDP that has (I think) no obvious counterexample. Let me give the strengthening and then prove the equivalence.
We have already met the vector-valued EDP: given any sequence  of unit vectors in a Euclidean space and any constant there exists some HAP such that
of unit vectors in a Euclidean space and any constant there exists some HAP such that  has norm at least . The problem that we shall now take is the “non-symmetric” vector-valued EDP: given any two sequences and
has norm at least . The problem that we shall now take is the “non-symmetric” vector-valued EDP: given any two sequences and  of vectors in a Euclidean space satisfying the condition
of vectors in a Euclidean space satisfying the condition  for every , there are HAPs and such that
for every , there are HAPs and such that  . If we insist that
. If we insist that  , then this reduces to the usual vector-valued EDP (for
, then this reduces to the usual vector-valued EDP (for  ).
).
The reason this looks as though it is probably true (or rather, that it and EDP are “equi-true”) is that if you try to make one of the sequences have small discrepancy by making it small on some HAP, then you have to make the other one large on that HAP. (This argument applies rather better to the real-valued case.) Also, the condition means that the directional bias of the 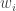 is somehow similar to that of the , which helps the discrepancies of the two sequences to align with each other.
is somehow similar to that of the , which helps the discrepancies of the two sequences to align with each other.
These are fairly feeble arguments, which reflects the fact that just at the moment I very much want to believe this statement and have not made a big effort to disprove it.
How about the equivalence? This again follows from the Hahn-Banach theorem. Let’s suppose that we cannot represent any diagonal matrix with trace greater than as a convex combination of s. Then the Hahn-Banach theorem implies that there is a separating functional, in this case a matrix such that  whenever is a diagonal matrix with trace at least , and
whenever is a diagonal matrix with trace at least , and  whenever and are characteristic functions of HAPs. Moreover, this is an equivalence: if such a matrix exists, then we trivially cannot represent as a convex combination of s.
whenever and are characteristic functions of HAPs. Moreover, this is an equivalence: if such a matrix exists, then we trivially cannot represent as a convex combination of s.
The first condition (that whenever is a diagonal matrix with trace at least ) is easily seen to fail if is not constant on the diagonal, and if it is constant then we see that its value on the diagonal must be at least  .
.
If such a matrix exists, then choose vectors 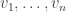 and
and  such that
such that  for every and
for every and  . (For instance, could be the rows of and could be the standard basis of .) Then
. (For instance, could be the rows of and could be the standard basis of .) Then  Therefore, the condition that
Therefore, the condition that  is always at most 1 is telling us that
is always at most 1 is telling us that  is always at most 1. If we now rescale by multiplying the by then we have a counterexample to the non-symmetric vector-valued EDP.
is always at most 1. If we now rescale by multiplying the by then we have a counterexample to the non-symmetric vector-valued EDP.
Conversely, if we have such a counterexample, then we can set  and we have a separating functional that proves that no diagonal matrix with trace greater than can be expressed as a convex combination of s.
and we have a separating functional that proves that no diagonal matrix with trace greater than can be expressed as a convex combination of s.
What are the difficulties in carrying out this programme?
The main problem we now face is this. If we want to write a matrix with unbounded trace as a convex combination of s, then we need to use fairly large HAPs. Indeed, the trace of 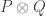 is
is  (if I may mix up sets and characteristic functions), so if our convex combination is then we need
(if I may mix up sets and characteristic functions), so if our convex combination is then we need  to be unbounded. This means more than merely the statement that the weighted average size of
to be unbounded. This means more than merely the statement that the weighted average size of  is unbounded, since some of the are of necessity negative.
is unbounded, since some of the are of necessity negative.
In particular, we need the sizes of the and to be unbounded. But if that is the case, then we are trying to write a diagonal matrix with a large trace as a convex combination of matrices that are very far from diagonal, which forces us to rely on clever cancellations.
Having said that, I would also like to point out that the task is by no means hopeless. For example, if 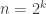 and are the Walsh functions (with respect to some bijection between
and are the Walsh functions (with respect to some bijection between  and
and  ), then
), then  equals the identity, even though each individual
equals the identity, even though each individual  is maximally far from being diagonal. Thus, there is nothing in principle to stop cancellations of the kind we want occurring. It is just a technical challenge to find them in the particular case of interest.
is maximally far from being diagonal. Thus, there is nothing in principle to stop cancellations of the kind we want occurring. It is just a technical challenge to find them in the particular case of interest.
Note that if we are looking for clever cancellations, then we are more likely to be able to find them if we deal as much as possible in points that belong to several HAPs. This suggests, and the suggestion is borne out by the experimental evidence we have so far, that the diagonal matrix we produce will probably be bigger at points with many factors. But one of the nice aspects of this approach is that one can concentrate on getting rid of the off-diagonal parts and not worry too much about which exact diagonal matrix results in the end. Making sure that its trace is big is a far easier task than guessing what it should be and then trying to produce it.
I will end this post by reiterating what I said after Moses first suggested using SDP: it seems to me that we have now “softened up” EDP. That is, it no longer feels like a super-hard problem with major obstacles in the way of a solution. Obviously I can’t be sure, but I feel optimistic that we are going to get there in the end.
This entry was posted on March 13, 2010 at 11:57 pm and is filed under polymath5. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

March 14, 2010 at 4:02 pm |
A question in trying to “push” EDP’s conclusion. Suppose we consider the
mean square weighted discrepencies, where HAP’s of period m have weights 1/d(m). ( d(m) is the number of divisors of m.) Can we expect this average is still unbounded?
March 15, 2010 at 8:03 am
Gil, what was your motivation in picking this particular weight function ? Did you mean to give weight 1/d(m) to each HAP of period m, or did you intend to give total weight 1/d(m) to all such HAPs ?
March 15, 2010 at 3:24 pm
Dear Moses
These weights came in the following way.
Let f be the function from the natural numbers to {+1,-1}
Let f_k be the restriction of f to integers on the HAP {ik}. and 0 for other integers.
Let X_k(n) be 0 if n is not of the form ik and otherwise if n=ik
X_k(n)=f(k)+f(2k)+…+f(ik)
Now, note that
(*) is a bounded function.
is a bounded function.
The hope was to play with Fourier expansions of the f_k and X_k to get some contradiction to (*). This did not went too far (I don’t see a nice fourier expansion for f_k and X_k) but it raised the question: Does (*) already leads to a contradiction.
In other words, is there a function f so that for every HAP of period k the discrepency divided by d(k) is bounded?
(Also here after giving this weight 1/d(k) for dicrepencies for HAP of period k you can take various l2 norms instead of infinity norm;)
d(k) is the number of dividors of k.
March 15, 2010 at 5:38 pm
By the way, pardon my ignorance but how does behaves?
behaves?
March 15, 2010 at 6:08 pm
If nobody knows the answer, maybe that’s one for Mathoverflow, where I imagine a few minutes would be enough. I can just make the simple observation that if you restrict the sum to primes you see that it grows at least as fast as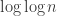 .
.
March 15, 2010 at 6:24 pm
March 17, 2010 at 6:32 pm
1. Well, It took 4 hours over Mathoverflow; (But that’s ok, of course, I see no advantage to a few minutes time-scale.)
2. Here is the link
http://mathoverflow.net/questions/18483/an-elementary-number-theoretic-infinite-series
3. The answer is
4. I liked especially the answer by David Hansen based on a beautiful formula by Ramanujan http://mathoverflow.net/questions/18483/an-elementary-number-theoretic-infinite-series/18501#18501
Maksym Radziwill asserted that the Selberg-Delange method gives the same answer.
5. I would still like to see an explanation that I can understand of the form: takes numbers which are product of m different primes where m = 1/2loglogn/logloglog n (say,say) and then you see how sqrt log n arises…
6. I think this answer makes these weights more appealing for the SDP approach. It may give the same answer as with 1 weights, and maybe maybe these weights will smooth the data so it will be easier to guess the pattern.
March 18, 2010 at 7:16 am
Wow! Hats off to Mathoverflow. I think insights into what weights to use for various HAPs in the SDP approach would be very valuable. Currently, I don’t have a good sense for what these weights should be.
Gil, I wanted to clarify some things what you wrote earlier.

 is exactly d(n); for all other k,
is exactly d(n); for all other k,  . If that is what you meant, then presumably the same
. If that is what you meant, then presumably the same

Presumably, here you meant to write d(n) in the denominator instead of 1+d(k) ?
The number of k such that
change should be made in the next expression too ?
March 18, 2010 at 10:15 am
Right, I forgot to count 1 as a divisor, so indeed it should be /d(k) in both formulas.
(I should also mention that Maxsym’s answer came first, about an hour before David’s.) I agree that this is a nice demonstration of MO’s usefullness.
Also if you give all HAP of period k a weight 1/d(k), what happens to the vector values EDP? can we still expect to be the answer or a smaller power.
to be the answer or a smaller power.
March 18, 2010 at 6:12 pm
Dear Gil, , the last element of the HAP, rather than
, the last element of the HAP, rather than  , the common difference. This suggests that we should compute average discrepancy by weighting the contribution of HAPs that end in
, the common difference. This suggests that we should compute average discrepancy by weighting the contribution of HAPs that end in  by
by  . This would not give a common weight for all HAPs with common difference
. This would not give a common weight for all HAPs with common difference  as a function of
as a function of  . Is this correct ?
. Is this correct ?
I don’t think I was very clear. It seems to me that in this argument, the denominator is a function of
March 20, 2010 at 11:14 pm
Right, I was confused it should be /d(n);
hmm, the rationale for the weights 1/d(k) for HAP with divisors k is now based on a typo. (Still the mathoverflow computation suggest that these weights may be useful.)
The corrected hope was to get a contradiction from (*) being bounded
being bounded
So this is a simple way of averaging the discrepencies…
Anyway, I suppose the interesting related conjecture would be that if the average square discrepencies for all HAPs ending with an integer m are below s for every m then s should already behave like .
.
(I think we suggested square-mean averaging over all HAPs of period k, and over all HAP’s altogether, so this one is a slightly different SDP.)
March 14, 2010 at 6:35 pm |
[…] By kristalcantwell There is a new thread for polymath5. The new thread is more of a place holder. It has material but that material is not yet applied to […]
March 15, 2010 at 9:35 am |
I wanted to mention some thoughts on the SDP approach. Recall that we are trying to prove that the quadratic form

 .
. , we get the following expression:
, we get the following expression:

is positive semidefinite. The lower bound established by this is
Under the assumption that the tails
Now let’s build in the assumption that fall off exponentially as well, in fact with the same decay parameter
fall off exponentially as well, in fact with the same decay parameter  . Suppose that
. Suppose that  and
and  , i.e.
, i.e.  . Writing the quadratic form in terms of $y_n$ and $b_n’$ we get:
. Writing the quadratic form in terms of $y_n$ and $b_n’$ we get:
 .
.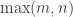 term in the exponent has been replaced by
term in the exponent has been replaced by  . Does this sort of quadratic form look familiar ? The lower bound established by this is
. Does this sort of quadratic form look familiar ? The lower bound established by this is  .
.
Notice that the
One could go further and assume that and now the goal is to determine a_d$. The quadratic form now is
and now the goal is to determine a_d$. The quadratic form now is
 .
.
The lower bound this proves is
So far, we haven’t really figured out what the unknown coefficients should be for this proof to work. Also, how should we show that the quadratic form obtained after subtracting the diagonal term is positive semidefinite ? Giving a sum of squares expression is one way to do it, but we should also consider other direct ways to argue that the remainder is psd. For example, given a matrix A, consider f(A), obtained by applying a function f() to each entry of A. Given that A is psd, f(A) is also psd if f() satisfies the following condition: all derivatives of f are non-negative and f(0) is non-negative. This gives a technique to prove that a matrix is psd without explicitly constructing a sum of squares representation. We have a whole slew of functions we could use, e.g.
should be for this proof to work. Also, how should we show that the quadratic form obtained after subtracting the diagonal term is positive semidefinite ? Giving a sum of squares expression is one way to do it, but we should also consider other direct ways to argue that the remainder is psd. For example, given a matrix A, consider f(A), obtained by applying a function f() to each entry of A. Given that A is psd, f(A) is also psd if f() satisfies the following condition: all derivatives of f are non-negative and f(0) is non-negative. This gives a technique to prove that a matrix is psd without explicitly constructing a sum of squares representation. We have a whole slew of functions we could use, e.g.  , any polynomial f(x) with non-negative coefficients. Is there a clever choice of
, any polynomial f(x) with non-negative coefficients. Is there a clever choice of  and a direct argument to show that the resulting quadratic form is psd ?
and a direct argument to show that the resulting quadratic form is psd ?
March 15, 2010 at 11:32 am |
Another point I’d like to make is this. We know that sequences do not have to have unbounded discrepancy on HAPs with common difference 1. We also know that they do not have to have unbounded discrepancy on HAPs of the form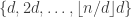 . This should imply that it is not possible to write a large-trace diagonal matrix as a convex combination of
. This should imply that it is not possible to write a large-trace diagonal matrix as a convex combination of  s if the HAPs
s if the HAPs  and
and  are restricted to one or other of these classes. This is indeed the case, and it is interesting to see why.
are restricted to one or other of these classes. This is indeed the case, and it is interesting to see why.
One way of seeing it is the obvious one of finding a separating matrix . In the common-difference-1 case we can take
. In the common-difference-1 case we can take  to be the matrix
to be the matrix  . Then any matrix of trace
. Then any matrix of trace  has inner product
has inner product  with
with  . But the inner product of
. But the inner product of  with any
with any 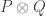 is 1 if
is 1 if 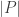 and
and  are both odd, and 0 otherwise. Therefore, we cannot get
are both odd, and 0 otherwise. Therefore, we cannot get  to be greater than 1. In the full-HAPs case, we can partition
to be greater than 1. In the full-HAPs case, we can partition  into the integers up to
into the integers up to  and the integers beyond
and the integers beyond  . And then we can define
. And then we can define 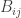 to be 1 if
to be 1 if  and
and  belong to the same class, and
belong to the same class, and  otherwise.
otherwise.
Going back to the difference-1 HAPs, the problem they have is that if and
and  are close, then for almost all HAPs
are close, then for almost all HAPs  with common difference 1, either both
with common difference 1, either both  and
and  belong to
belong to  or neither does. This means that a typical linear combination of products of HAPs with common difference 1 contains not just the diagonal but also much of the band of points close to the diagonal — unless, that is, one takes very very short HAPs.
or neither does. This means that a typical linear combination of products of HAPs with common difference 1 contains not just the diagonal but also much of the band of points close to the diagonal — unless, that is, one takes very very short HAPs.
Similarly, if we use HAPs with common difference , we will find it hard to separate two nearby multiples of
, we will find it hard to separate two nearby multiples of  .
.
With that thought in mind, let us informally think of two integers and
and  as “close” if
as “close” if 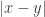 is a small multiple of the highest common factor
is a small multiple of the highest common factor  . This makes it difficult to find HAPs that contain one of
. This makes it difficult to find HAPs that contain one of  and
and  without the other.
without the other.
Having said that, if has plenty of small factors, then
has plenty of small factors, then 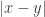 can be a largish multiple of some of these small factors, so there is still a chance of separating
can be a largish multiple of some of these small factors, so there is still a chance of separating  and
and  .
.
This suggests that in order to contribute to the diagonal and get plenty of cancellation off the diagonal, one should have plenty of products of short (but still of unbounded length) HAPs with small common differences.
Staring at the experimental evidence makes me despair slightly of finding any obvious pattern, so I am tempted by probabilistic methods: I would like to choose randomized combinations of products of shortish HAPs with small common differences, hoping to obtain enough cancellation that what remains off the diagonal can be tidied up in a more brutal way without destroying the benefit of what has been done already.
March 15, 2010 at 1:59 pm |
Here’s an example of the kind of method I had in mind for attempting to represent a diagonal map. First, let’s look at the matrix one obtains by adding together all such that
such that  is the intersection of an interval of length
is the intersection of an interval of length  with the set
with the set  . If this matrix is
. If this matrix is  , then
, then  equals
equals  . Note that it is concentrated around the diagonal, but also that we cannot make it diagonal unless we take
. Note that it is concentrated around the diagonal, but also that we cannot make it diagonal unless we take 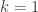 , which is not an economical representation.
, which is not an economical representation.
More generally, if we do the same but with progressions of the form (and shorter ones at the beginning and end) and multiply by an appropriate constant, then we can produce exactly the same function, but restricted to pairs
(and shorter ones at the beginning and end) and multiply by an appropriate constant, then we can produce exactly the same function, but restricted to pairs  such that
such that  . (Confession: I haven’t checked exactly what the effect is of taking those integer parts. In fact, I think what I’ve just written is wrong, but that by averaging over all pointwise products of real intervals of length
. (Confession: I haven’t checked exactly what the effect is of taking those integer parts. In fact, I think what I’ve just written is wrong, but that by averaging over all pointwise products of real intervals of length  with the set of multiples of
with the set of multiples of  between 1 and
between 1 and  we can indeed get the matrix I am claiming we can get.)
we can indeed get the matrix I am claiming we can get.)
Now let us add together all the matrices we have obtained. This gives us a new matrix whose entry is
entry is  .
.
I find this encouraging, because there ought to be a negative correlation between being large and
being large and  being large. Indeed,
being large. Indeed,  is large only if
is large only if  and
and  are close, and if two numbers are close (but not equal) then their highest common factor is necessarily fairly small.
are close, and if two numbers are close (but not equal) then their highest common factor is necessarily fairly small.
On the other hand, I’m not going to get too excited about it, because it somehow feels as though the cost of “localizing to distance ” is sufficiently high that having highest common factors of size at most
” is sufficiently high that having highest common factors of size at most  is no longer all that much of a gain.
is no longer all that much of a gain.
While I’m at it, another tiny observation is that if is the HAP
is the HAP 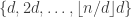 , then
, then  takes the value
takes the value  when
when  and
and  are coprime and
are coprime and  otherwise.
otherwise.
March 15, 2010 at 2:10 pm |
I’m intrigued by the generalized notion of multiplicativity that Tim mentioned at the end of EDP 11. To recap (and give it a name), call a sequence of unit vectors (
(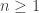 ) in
) in  -dimensional Euclidean space quasi-multiplicative if
-dimensional Euclidean space quasi-multiplicative if  for all
for all  .
.
These sequences are potentially interesting to us because if a quasi-multiplicative sequence has bounded partial sums then it has bounded discrepancy (with respect to the Euclidean norm).
Can we characterize such sequences in some more arithmetic way? The simplest examples are those of the form where
where  is a
is a  -valued multiplicative sequence and
-valued multiplicative sequence and  is a unit vector; but there are plenty of others.
is a unit vector; but there are plenty of others.
For example, given a multiplicative -valued sequence
-valued sequence  , an additive function
, an additive function  (by which I mean
(by which I mean  ), an integer
), an integer  , and any two unit vectors
, and any two unit vectors  and
and  , we can define
, we can define  if
if  , and
, and  otherwise.
otherwise.
March 15, 2010 at 3:42 pm
Another source of examples is to take an orthonormal basis of Hilbert space and define a multiplication on it by
of Hilbert space and define a multiplication on it by  . Then for each prime you can choose a multiple
. Then for each prime you can choose a multiple  of some basis vector, where
of some basis vector, where  , and extend by multiplicativity (setting
, and extend by multiplicativity (setting  ). Moses’s modification of
). Moses’s modification of 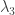 and
and  (which has discrepancy that grows like
(which has discrepancy that grows like  ) was of this type.
) was of this type.
March 15, 2010 at 6:15 pm
More generally, one can take any semigroup , index the orthonormal basis by elements of
, index the orthonormal basis by elements of  , and define
, and define  to be
to be  .
.
March 15, 2010 at 6:25 pm
I’m not sure how general this really is without thinking about it for a bit longer, but one could take a family of commuting orthogonal (or unitary in the complex case) transformations of a finite-dimensional space, map each to some unitary
to some unitary  in the family and extend by multiplicativity. The inner product would be the usual one
in the family and extend by multiplicativity. The inner product would be the usual one  .
.
As I write, I realize that we might as well look at the complex case and take the maps all to be diagonal. And then we can forget about the maps altogether and simply take vectors in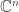 with each coordinate of modulus 1, with pointwise multiplication, and with inner product
with each coordinate of modulus 1, with pointwise multiplication, and with inner product  .
.
March 16, 2010 at 9:59 am
Ah yes — I hadn’t thought about the group or semigroup idea. (Actually, I don’t quite see how it works in a general semigroup — don’t we need cancellation, ?)
?)
The last example is nice, and suggests a general ‘direct sum’ construction: if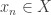 and
and  are quasi-multiplicative, then
are quasi-multiplicative, then  is quasi-multiplicative, if we define
is quasi-multiplicative, if we define
(and similarly for a general finite direct sum).
March 15, 2010 at 4:23 pm |
Following on from this comment, here is another speculation about how a proof might go that one can represent a diagonal matrix with unbounded trace as a convex combination of s.
s.
First, let us look at the sum of over all full HAPs
over all full HAPs  with prime power common difference. If
with prime power common difference. If  is this matrix, then
is this matrix, then  is the number of prime powers that divide
is the number of prime powers that divide  , which is the number of prime factors of
, which is the number of prime factors of  , with multiplicity.
, with multiplicity.
Now let me get a bit woolly. The Erdős-Kac theorem tells us that the number of prime factors of a random integer is pretty concentrated around its average
is pretty concentrated around its average 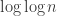 . So perhaps we can think of this matrix
. So perhaps we can think of this matrix  as behaving like
as behaving like  plus a small error. Is there any hope of producing
plus a small error. Is there any hope of producing  in an economical way?
in an economical way?
It seems to me that there might conceivably be. After all, I observed above that one can produce the matrix that is 1 when and 0 otherwise fairly easily. Unfortunately, that representation is not all that economical, but it suggests that there are ways of favouring pairs with fewer common factors. The idea here would be to add something to the matrix
and 0 otherwise fairly easily. Unfortunately, that representation is not all that economical, but it suggests that there are ways of favouring pairs with fewer common factors. The idea here would be to add something to the matrix  to make it roughly constant off the diagonal and end by subtracting a multiple of
to make it roughly constant off the diagonal and end by subtracting a multiple of  to obtain something that is very small off the diagonal.
to obtain something that is very small off the diagonal.
If this worked it would prove the yet stronger “prime-power-difference-non-symmetric-vector-valued EDP”, which would be like the normal non-symmetric vector-valued EDP except that the HAPs would have common differences equal to prime powers.
March 15, 2010 at 4:39 pm
Oops — I need to think more carefully about that, because so far all the HAPs mentioned are full ones, and we know that those are not enough.
March 15, 2010 at 6:04 pm |
Here’s another thought about how to get the decomposition to work. I think it may be more promising than my other recent ideas (which wouldn’t be hard).
Let’s choose a that tends to infinity very slowly with
that tends to infinity very slowly with  . Next, let us choose, by some random procedure, a collection
. Next, let us choose, by some random procedure, a collection  of HAPs of length
of HAPs of length  (here, by “length” I mean cardinality rather than diameter) and let us form the matrix
(here, by “length” I mean cardinality rather than diameter) and let us form the matrix  . This has trace
. This has trace  and on the diagonal it tends to favour numbers with more common factors. Also, the sum of the coefficients we have used so far is
and on the diagonal it tends to favour numbers with more common factors. Also, the sum of the coefficients we have used so far is  , so as things stand we have an unbounded ratio (namely
, so as things stand we have an unbounded ratio (namely  ) of trace to sum of coefficients. However, the matrix is not diagonal, so this is not very interesting.
) of trace to sum of coefficients. However, the matrix is not diagonal, so this is not very interesting.
Now let us try to remove everything that is not on the diagonal by subtracting matrices of the form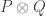 where
where  and
and  are disjoint HAPs. We will be done if we can achieve this using at most
are disjoint HAPs. We will be done if we can achieve this using at most  such matrices. Is there any chance that that can be managed?
such matrices. Is there any chance that that can be managed?
If is something like
is something like  , then
, then  will be fairly dense (though more so when
will be fairly dense (though more so when  has plenty of factors) and fairly random. So one might expect to be able to find reasonably large disjoint pairs
has plenty of factors) and fairly random. So one might expect to be able to find reasonably large disjoint pairs 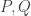 of HAPs such that
of HAPs such that  . Indeed, if
. Indeed, if  has density
has density  and
and  and
and  have length
have length  , then, very naively (and ignoring all sorts of important number-theoretic considerations) one might expect that the probability that
, then, very naively (and ignoring all sorts of important number-theoretic considerations) one might expect that the probability that  was around
was around  . And then we might hope that what is left after we have subtracted off
. And then we might hope that what is left after we have subtracted off 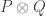 was still reasonably random-looking (perhaps we could do something like a Rödl nibble to ensure this) so that we could repeatedly remove fairly large HAP products.
was still reasonably random-looking (perhaps we could do something like a Rödl nibble to ensure this) so that we could repeatedly remove fairly large HAP products.
As we continued the process, the matrix that was left would become sparser and sparser and the pieces we subtracted would have to become smaller and smaller. There would therefore be a delicate balancing act: the hope is that even if some of the pieces had to be small, they would on average be large enough for the sum of coefficients to be at most .
.
After thinking about this proof strategy for all of a few seconds, I don’t see an obviously fatal flaw in it. However, it’s quite possible that one will emerge.
Incidentally, I do not at all imagine that the would be chosen uniformly from the set of all HAPs of length
would be chosen uniformly from the set of all HAPs of length  . My guess is that they would tend to have fairly small common differences and that larger differences would come into play when one began the nibbling process. I say that because of the fact that the diagonal seems to favour smooth numbers. (Note also that the above suggestion would lead to a non-negative diagonal, whereas the optimal solution has some negative coefficients on the diagonal. I suppose it isn’t crucial to choose
. My guess is that they would tend to have fairly small common differences and that larger differences would come into play when one began the nibbling process. I say that because of the fact that the diagonal seems to favour smooth numbers. (Note also that the above suggestion would lead to a non-negative diagonal, whereas the optimal solution has some negative coefficients on the diagonal. I suppose it isn’t crucial to choose 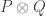 with
with  and
and  disjoint, as typically their intersections will be much smaller than the sets themselves.)
disjoint, as typically their intersections will be much smaller than the sets themselves.)
March 16, 2010 at 5:49 am |
I have implemented the suggestions about presenting the LP solutions. The solution is expressed as rational numbers for , and both
, and both  and
and  are explicitly written down. Look for the files *a.txt here:
are explicitly written down. Look for the files *a.txt here:
http://webspace.princeton.edu/users/moses/EDP/try-lp/
March 16, 2010 at 7:57 am |
In thinking about what the SDP approach and what choices of might be good, the following question comes to mind: What functions
might be good, the following question comes to mind: What functions  can be represented in the form
can be represented in the form  where the
where the  are non-negative ? Is there a well known characterization ? For example, all multiplicative functions that are non-decreasing on prime powers can be represented in this form. Let
are non-negative ? Is there a well known characterization ? For example, all multiplicative functions that are non-decreasing on prime powers can be represented in this form. Let  be such a function. Then we choose
be such a function. Then we choose  to be multiplicative and
to be multiplicative and  .
.
It seems to me that we can represent more complicated functions as well. e.g. I think we can represent where
where  is multiplicative and non-decreasing on prime powers. In order to do this, note that we can represent
is multiplicative and non-decreasing on prime powers. In order to do this, note that we can represent  (since it is multiplicative etc). Now
(since it is multiplicative etc). Now

 is the function
is the function  constructed above in representing a multiplicative function
constructed above in representing a multiplicative function  . Then consider
. Then consider

 .
.
Say that
Then
March 16, 2010 at 9:36 am
We can use Mobius inversion to get some kind of characterization. If , then
, then  . Therefore, if we know
. Therefore, if we know  ,
,  is constrained by:
is constrained by:
March 16, 2010 at 6:45 pm |
Continuing the line of enquiry from this comment, I want to consider in abstract terms what the obstacle might be to representing the off-diagonal part of as a sum
as a sum  with some given bound on
with some given bound on  .
.
By Hahn-Banach once again, we know that if is a matrix that cannot be represented as a sum of that kind with the moduli of the coefficients adding up to at most
is a matrix that cannot be represented as a sum of that kind with the moduli of the coefficients adding up to at most  , then there is a matrix
, then there is a matrix  such that
such that  and
and  for every pair
for every pair  of HAPs.
of HAPs.
In our situation, the assumption was that we had a matrix , where each
, where each  was a HAP of cardinality
was a HAP of cardinality  . This gave us a trace of
. This gave us a trace of  , so we needed to write the off-diagonal part as a linear combination of
, so we needed to write the off-diagonal part as a linear combination of  s with absolute values of coefficients adding up to
s with absolute values of coefficients adding up to  . To put this in perspective, if all coefficients were equal to
. To put this in perspective, if all coefficients were equal to  , then we would need the average cardinality of the sets
, then we would need the average cardinality of the sets  to be
to be  . So the typical size of each
. So the typical size of each  or
or  should be distinctly bigger than
should be distinctly bigger than  .
.
The Hahn-Banach argument tells us that we can do this if and only if the following statement holds: whenever is a matrix such that
is a matrix such that  , there exist HAPs
, there exist HAPs  and
and  such that
such that  . Note that if the sets
. Note that if the sets  are approximately disjoint, then the average value of
are approximately disjoint, then the average value of 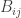 inside that set is about
inside that set is about  . Note also that
. Note also that  can be negative outside the support of
can be negative outside the support of  . So what we actually have is a new discrepancy problem. I haven’t yet thought about it properly, but a preliminary point to make is that a slight disadvantage of this perspective is that it is requiring us once again to make a big guess: namely, what the matrix should be. But I think that may be a necessary feature of this problem. Presumably it will be bigger at pairs
. So what we actually have is a new discrepancy problem. I haven’t yet thought about it properly, but a preliminary point to make is that a slight disadvantage of this perspective is that it is requiring us once again to make a big guess: namely, what the matrix should be. But I think that may be a necessary feature of this problem. Presumably it will be bigger at pairs  such that the highest common factor
such that the highest common factor  has many factors. So we could ask ourselves: why should such matrices be better candidates for ones that give a positive answer to the discrepancy problem just described.
has many factors. So we could ask ourselves: why should such matrices be better candidates for ones that give a positive answer to the discrepancy problem just described.
It would also be a useful (and presumably simple, but I have to stop for a bit) exercise to prove that something obvious like the matrix that is 1 everywhere cannot have its off-diagonal part decomposed. The matrix that shows this is probably
that shows this is probably 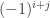 . I’ll check later.
. I’ll check later.
March 16, 2010 at 11:16 pm
That final sentence was, on reflection, ridiculous. Not only is it not true that is large, but it is easy to find
is large, but it is easy to find  s that correlate with it.
s that correlate with it.
A better example is this. Let be the matrix with
be the matrix with 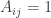 if
if  mod 3 and 0 otherwise. (This is not of the form
mod 3 and 0 otherwise. (This is not of the form  , but that’s the point.) Then let
, but that’s the point.) Then let  , where
, where  is our old friend that takes a number to 1 if it’s 1 mod 3, -1 if it’s 2 mod 3 and 0 if it’s 0 mod 3. Then
is our old friend that takes a number to 1 if it’s 1 mod 3, -1 if it’s 2 mod 3 and 0 if it’s 0 mod 3. Then  certainly correlates with products of progressions, but not with products of HAPs.
certainly correlates with products of progressions, but not with products of HAPs.
March 17, 2010 at 3:22 pm
Actually, a slight modification of that example illustrates better what is going on. Let us take to be the all-1s matrix (which equals
to be the all-1s matrix (which equals  , where
, where 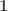 is the constant vector
is the constant vector 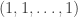 ). Now let
). Now let  be
be  as above. Then (assuming that
as above. Then (assuming that  is not 1 mod 3) we find that
is not 1 mod 3) we find that  . However, the off-diagonal part of
. However, the off-diagonal part of  correlates with
correlates with  : if we let
: if we let 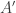 be the same as
be the same as  except with 0s down the diagonal, then
except with 0s down the diagonal, then  , since the diagonal of
, since the diagonal of  is 1,1,0,1,1,0,… . Now
is 1,1,0,1,1,0,… . Now  , which is at most 1 in modulus. Therefore, if we want to represent the off-diagonal part of
, which is at most 1 in modulus. Therefore, if we want to represent the off-diagonal part of  as a linear combination of
as a linear combination of  s, the sum of the absolute values of the coefficients has to be at least
s, the sum of the absolute values of the coefficients has to be at least  , rather than the
, rather than the 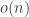 that we would need to prove EDP.
that we would need to prove EDP.
March 17, 2010 at 6:16 am |
Here is a question about the relationship of the representation-of-diagonals approach versus the SDP approach. We know that the best lower bound provable via the SDP approach is at least as large as the best bound provable via the representation-of-diagonals approach. One way to see this is the fact that a representation-of-diagonals proof proves a lower bound on the non-symmetric vector valued EDP, which is a stronger hypothesis than the vector valued EDP. A lower bound for the non-symmetric vector valued EDP applies to the vector valued EDP but not vice versa.
So, given a lower bound using the representation-of-diagonals approach, is there a direct way to construct an SDP proof that establishes the same (or higher) lower bound ? We know that such an SDP argument must exist.
March 17, 2010 at 8:24 am
That’s a good question. I think I have an answer for it. Let me sketch the answer. First, observe that
and
Therefore, if we have we have
we have
where the sign corresponds to the sign of .
.
Therefore, is written as the sum of a diagonal and a sum of squares. What’s more, the ratio of trace to sum of relevant coefficients is preserved.
is written as the sum of a diagonal and a sum of squares. What’s more, the ratio of trace to sum of relevant coefficients is preserved.
If this is correct, it might be interesting to try to understand what is special about this particular kind of SDP solution that does not have to happen in general.
March 17, 2010 at 2:15 pm
Very nice. This looks correct, except that you don’t need the 2’s everywhere. So does this suggest that we ought to look for differences of HAPs (or more generally, linear combinations of HAPs) in building a sum of squares expression in the SDP proof ?
Do you have a sense for what pairs of HAPs might be useful in getting a diagonal representation ? If we ignore the lengths of the HAPs for now, what pairs of common differences might make good combinations ?
March 17, 2010 at 3:11 pm
I’ve removed the 2s now.
March 17, 2010 at 3:58 pm
In answer to your last paragraph, at the moment I have absolutely no sense at all of how to get a good diagonal representation. The only thing I would say is that if we are trying to represent the same matrix in two different ways, then it will probably help if as much of that matrix as possible is concentrated at points with plenty of factors — to give us plenty of choice. So that would suggest taking pairs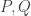 such that both
such that both  and
and  have plenty of factors.
have plenty of factors.
I find it quite hard to see what’s going on in the decompositions found by computer. However, it does seem that they have a number of “one-dimensional” parts: for example, things like , where
, where  is
is  without its last element and
without its last element and  is
is  with an extra element on the end.
with an extra element on the end.
With that thought in mind, is there an obvious counterexample to the following yet further strengthening of the non-symmetric version? It would say that for every , if
, if  and
and  are sequences of vectors with
are sequences of vectors with  for every
for every  , then either there exist
, then either there exist  and a HAP
and a HAP  such that
such that  or there exist
or there exist  and
and  such that
such that  .
.
March 17, 2010 at 4:09 pm
Oops, the answer to that last question is obvious. Just take to be an orthonormal basis.
to be an orthonormal basis.
I think that means we can’t do the decomposition into one-dimensional pieces.
March 17, 2010 at 6:55 am |
I have a question regarding greedy algorithms approach for multiplicative sequences.
Let’s assume we consider sequences in {1,2,…,N} when N is very large.
Did we try the following? we assign the value +1 or -1 for each prime one by one. When we assign the value for the (i+1)th prime we do it as to minimize the disrepancy.
By mimizing the discrepancy I mean that we compute the discrepancy for ALL intervals {1,..,t} where t is at most N under the two possible values for the (i+1)th prime where we assign value 0 to all larger primes. Then we take the possibility that gives smaller discrapancy.
March 17, 2010 at 7:37 am
My guess is that that would have some undesirable features. For instance, if an interval has lots of zeros in it (as the larger ones will) we should care less about its discrepancy because it will be much easier to correct. But some variant of a look-ahead greedy algorithm would definitely be interesting. I can’t remember what we’ve tried along those lines.
March 17, 2010 at 11:01 am
I dont think so; it is true that the first few prime assignmenets will be rather arbitrary but I think this very simple look-ahead greedy actually optimize the “right” thing.
So I would expect that the overall discrepency for my greedy proposal will behave more or less logarithmically. Even for problems we dont know such sequences at all (like EDP for square free numbers).
(I do agree that maybe by giving less weight to sequences with many zeroes you can “fine-tune” this suggestion and perhaps practically improve it somewhat. Also if you want a provably-low discrepency maybe you need to make the algorithm practically worse by introducing randomness. In any case, I propose trying this algorithm as is.)
March 17, 2010 at 12:10 pm
I definitely agree that that would be worth doing, and perhaps it is better to think about refinements only after looking at the simplest possibilities first.
I think part of my reason for being anxious about your suggestion is that it mininmizes only the maximum discrepancy at any one time, which leaves everything else free to misbehave. Another thing that I think could be very interesting, especially in the light of recent approaches to the problem, would be to minimize some kind of average discrepancy. If that led to an average discrepancy that grew very slowly, it would be pretty interesting, even if the maximum was somewhat bigger than the average. And this feels more likely to work, somehow.
Having said that, I see your point that once you start assigning values to slightly larger primes, my objections become weaker.
March 17, 2010 at 3:56 pm |
Here’s a question that might be helpful. We are aiming to find a sequence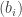 for which we can prove that the discrepancy of any sequence
for which we can prove that the discrepancy of any sequence 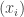 is at least
is at least  . Now if the
. Now if the  are non-negative, then
are non-negative, then  . Therefore, if we succeed in our goal, then for every sequence
. Therefore, if we succeed in our goal, then for every sequence 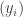 with
with  we will have proved that the discrepancy of
we will have proved that the discrepancy of 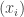 is at least
is at least  , which depends on a linear function of the
, which depends on a linear function of the  rather than a quadratic one. So it might be interesting to ask the following general question: for what sequences
rather than a quadratic one. So it might be interesting to ask the following general question: for what sequences  of non-negative weights can we prove that the discrepancy of every sequence
of non-negative weights can we prove that the discrepancy of every sequence 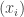 is at least
is at least  ? If
? If  is the set of all the sequences we manage to find, and
is the set of all the sequences we manage to find, and 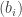 is a sequence of weights such that
is a sequence of weights such that  for every
for every  , then we have a lower bound of the kind we are looking for.
, then we have a lower bound of the kind we are looking for.
A trivial example of a sequence that belongs to
that belongs to  …
…
OK, this comment is slightly embarrassing because I’m going to end up with the triviality that consists of convex combinations of characteristic functions of HAPs, and I’ve ended up with almost exactly the question we started with. However, I had a different thought that led to this one, and I haven’t yet seen that the different thought is a waste of time. I’ll address it in a new comment.
consists of convex combinations of characteristic functions of HAPs, and I’ve ended up with almost exactly the question we started with. However, I had a different thought that led to this one, and I haven’t yet seen that the different thought is a waste of time. I’ll address it in a new comment.
March 17, 2010 at 7:17 pm |
I have been looking at the wiki. I think the possibility of some pages for some of the new approaches have been mentioned before. The last change seems to be February 20 so I think it has fallen behind some of what has been done for the last four threads.
March 17, 2010 at 11:06 pm |
A small observation, but unless it can be strengthened I don’t think it’s good for anything.
Let us define a graph on by joining
by joining  to
to  if and only if
if and only if 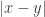 divides
divides  and
and  . The observation is that this graph contains arbitrarily large complete bipartite graphs.
. The observation is that this graph contains arbitrarily large complete bipartite graphs.
To see this, pick a sequence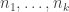 such that
such that  for every
for every  and
and  . For
. For  let
let  and let
and let  . Then
. Then  , which is at most
, which is at most 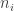 . It therefore divides
. It therefore divides  , and indeed it divides
, and indeed it divides  . And if
. And if  divides
divides  , then it must divide
, then it must divide 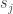 as well.
as well.
The motivation for this was to see whether the rather sparse graph where you join two numbers if they are consecutive in some HAP has dense bits. What I would prefer is something much stronger, where one had a multipartite graph in several layers. I tried something like this before, and I can’t remember whether I had a good reason for giving it up. I came back to it because I thought that maybe it would be a way of producing decompositions of diagonal maps.
March 18, 2010 at 8:08 am |
Here is a suggestion for an exercise to sharpen our understanding of diagonal representations: Can we give a proof of Roth’s theorem on the discrepancy of arithmetic progressions using diagonal representations ? If so, it would be a generalization of the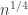 result for APs to the non-symmetric vector valued case. We know that the result is true in the vector valued case, e.g. via Lovasz’s SDP proof of Roth’s theorem. See Section 5.2, page 31-33 of these notes that were pointed out before:
result for APs to the non-symmetric vector valued case. We know that the result is true in the vector valued case, e.g. via Lovasz’s SDP proof of Roth’s theorem. See Section 5.2, page 31-33 of these notes that were pointed out before:
http://www.cs.elte.hu/~lovasz/semidef.ps
One caveat: We know that the answer for HAPs is very different from that for APs. Not only is the value of the lower bound different, the nature of the problem is very different too, since there are symmetries in the case of APs which don’t hold for the case of HAPs. One way this manifests itself is that for APs, in lower bounding the discrepancy by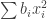 , you don’t need to use different
, you don’t need to use different  values because of symmetry. So perhaps this exercise will give no insights about constructing a proof for the HAP case. Nevertheless, it would be a good “proof of concept” and increase our understanding of diagonal representations.
values because of symmetry. So perhaps this exercise will give no insights about constructing a proof for the HAP case. Nevertheless, it would be a good “proof of concept” and increase our understanding of diagonal representations.
March 18, 2010 at 8:25 am
Moses, have you tried to solve the SDP corresponding to Roth’s theorem numerically? If one were to formulate an SDP for this problem along the same lines as the one we have solved for the EDP there might be some insight to be gained from comparing the numerical solutions for the two problems.
March 18, 2010 at 10:22 am
Another very good question, and again (after a failed attempt) I think I have found an answer. I have a train to catch, so for now I’ve got time only for a very brief sketch.
The idea is to start by representing the identity in terms of trigonometric functions. I’ll use complex ones for now, to save time, but in the end I’d do it with sines and cosines. Let and let
and let  . Then
. Then  (if this is interpreted appropriately with complex conjugates — again, it will work better with sines and cosines).
(if this is interpreted appropriately with complex conjugates — again, it will work better with sines and cosines).
We now pick, for each , some arithmetic progression
, some arithmetic progression  with common difference at most
with common difference at most  and length
and length 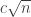 , such that
, such that  convolved with
convolved with  , which has to be a multiple of
, which has to be a multiple of  , is a reasonably big multiple. To do this we use the pigeonhole principle to find a common difference
, is a reasonably big multiple. To do this we use the pigeonhole principle to find a common difference  such that
such that  is very close to 1.
is very close to 1.
But is a linear combination of lots of translates of
is a linear combination of lots of translates of  . So this allows us to convert the trigonometric representation of the identity into one that involves APs that do not wrap around too much.
. So this allows us to convert the trigonometric representation of the identity into one that involves APs that do not wrap around too much.
I’ll check the details on the train, but I’m fairly confident that this is going to work. I’ll be able to report back in about four or five hours from now.
March 18, 2010 at 4:25 pm
I’m now back from my train journey and have realized that the question is subtler than I thought. I still think that a representation-of-identity proof is possible, however. Let me explain what was wrong with my suggestion above, and then why I think that the problem is not fatal.
Let be about
be about  and let
and let  be the interval
be the interval  and let
and let  be the characteristic function of
be the characteristic function of  . My previous idea was this. First, for each
. My previous idea was this. First, for each  we find some
we find some  such that
such that  is
is  for some real number
for some real number  . (Here I’m defining convolutions using sums rather than expectations.) Then we take the representation of the identity
. (Here I’m defining convolutions using sums rather than expectations.) Then we take the representation of the identity  and expand each
and expand each  into
into  , which represents
, which represents  as a sum of
as a sum of 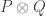 s with absolute values of coefficients adding up to
s with absolute values of coefficients adding up to  , which is proportional to
, which is proportional to  . Therefore, the average of the
. Therefore, the average of the  is represented with coefficients adding up to
is represented with coefficients adding up to 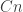 , and it gives us the identity, which has trace
, and it gives us the identity, which has trace  . So we get a ratio equal to a constant and have proved nothing at all.
. So we get a ratio equal to a constant and have proved nothing at all.
What, one might ask, is the weakness in the above argument? The answer, which is obvious in retrospect, is that we are missing the chance to exploit some cancellation. As soon as I can demonstrate that, I have already more or less proved that the discrepancy on arbitrary APs is unbounded. But I think that if the argument is pushed as far as it will go, then we will get the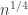 boud (though it looks as though a bit of effort would be needed to remove logarithmic factors).
boud (though it looks as though a bit of effort would be needed to remove logarithmic factors).
To see that there could be cancellation, let us go back to how we choose such that
such that  is a large multiple of
is a large multiple of  . The idea is to use the pigeonhole principle to show that for every
. The idea is to use the pigeonhole principle to show that for every  there exists
there exists  such that
such that  . But this means that each
. But this means that each  is used on average for about
is used on average for about  different values of
different values of  , and therefore we attach several different coefficients
, and therefore we attach several different coefficients  to
to  . Let
. Let  be the set of
be the set of  for which I chose
for which I chose  . (It will be something like an arithmetic progression with common difference
. (It will be something like an arithmetic progression with common difference  , all in a mod-
, all in a mod- sense.) Then the sum of
sense.) Then the sum of  over all
over all  is a geometric progression that the bad argument above bounds above with the trivial bound
is a geometric progression that the bad argument above bounds above with the trivial bound  . But of course for most
. But of course for most  a much better bound holds.
a much better bound holds.
I did a back-of-envelope calculation and convinced myself that this would lead to an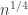 -type bound (give or take log factors, and I had ideas for what to do about those). I then tried it more carefully and got into some trouble. But I think I see where I was going wrong the second time. I will try to sort it out and write something rigorous.
-type bound (give or take log factors, and I had ideas for what to do about those). I then tried it more carefully and got into some trouble. But I think I see where I was going wrong the second time. I will try to sort it out and write something rigorous.
I think that this was, as Moses said, a valuable exercise. It suggests a general way of going about finding a diagonal representation for EDP that I had not previously thought of. The idea would be to start with a representation of a diagonal matrix as
as  , where the
, where the  are convex combinations of HAPs and
are convex combinations of HAPs and  equals the trace of
equals the trace of  . So far, that would prove nothing. But then one would look more closely at the representation and see that the coefficients it was attaching to individual
. So far, that would prove nothing. But then one would look more closely at the representation and see that the coefficients it was attaching to individual 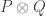 s involved a certain amount of cancellation, enabling us to rewrite the expression for
s involved a certain amount of cancellation, enabling us to rewrite the expression for  as
as  with
with  .
.
I don’t know whether that is a feasible approach, but I would believe in it more if we could find a rather general sufficient condition for a vector to be a convex combination of HAPs. This condition should say something like that
to be a convex combination of HAPs. This condition should say something like that  is not too big on APs that are not HAPs. The Hahn-Banach theorem says that if
is not too big on APs that are not HAPs. The Hahn-Banach theorem says that if  is not a convex combination of
is not a convex combination of 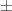 HAPs, then there is a function
HAPs, then there is a function  such that
such that  and
and  has discrepancy at most 1 on all HAPs. Can anyone think of a function
has discrepancy at most 1 on all HAPs. Can anyone think of a function  such that it is easier to prove that the HAP discrepancy of
such that it is easier to prove that the HAP discrepancy of  is always at least
is always at least  than it is to show that
than it is to show that  is a convex combination of HAPs and their negatives?
is a convex combination of HAPs and their negatives?
March 18, 2010 at 8:46 am |
No, I haven’t tried to solve the SDP corresponding to discrepancy of APs. Lovasz’s exposition describes a feasible solution to this SDP (not optimal, but good enough to prove the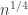 lower bound). This solution is as follows:
lower bound). This solution is as follows: . Consider all APs with common difference at most
. Consider all APs with common difference at most  and length exactly
and length exactly  . (One small technical detail is that he considers arithmetic progressions modulo
. (One small technical detail is that he considers arithmetic progressions modulo  , i.e. allows APs to wrap around.) There are
, i.e. allows APs to wrap around.) There are  such APs and in the SDP solution, he gives equal weight to all the APs in this set. The crux of the matter is to argue that the value of this solution is at least
such APs and in the SDP solution, he gives equal weight to all the APs in this set. The crux of the matter is to argue that the value of this solution is at least  . Here the proof exploits the symmetries of APs crucially.
. Here the proof exploits the symmetries of APs crucially.
Let
March 18, 2010 at 8:53 am
I thought it might be interesting to see the optimal solutions as well, as it is optimal solutions for the EDP-SDP we have been looking at. This might give some idea for how to good enough solutions to the EDP-SDP.
March 18, 2010 at 6:08 pm
I see … so you’re saying that we know there is a clean understandable SDP solution for the discrepancy problem for APs. If we weren’t aware of its existence, will looking at the optimal SDP solution for small give us any clues about how to construct an SDP solution for general
give us any clues about how to construct an SDP solution for general  ?
?
One issue with solving the discrepancy problem for general APs is that there are many more APs than HAPs. If we impose reasonable symmetry conditions on the SDP solution (i.e. by averaging discrepancy over all translations of an AP), the number of constraints is the same as the number of HAPs, but the constraints are a lot denser. So my sense is that the SDP solver will have a harder time solving these SDPs and we may only get solutions for smaller than we have got for the HAP case.
than we have got for the HAP case.
Nevertheless, it might be interesting to look at these solutions. Similarly, it might be interesting to look at the LP solution corresponding to the optimal diagonal representation to see if we would have had any hope of reverse engineering a solution for general by looking at such solutions.
by looking at such solutions.
March 18, 2010 at 10:12 pm |
A sort of a vague general question: Do Tim’s new approaches or some variant of the Moses SDP approaches allow us to give lower bounds for EDP (or some related problem) based on an LP problem rather than an SDP problem?
March 19, 2010 at 4:05 am
Dear Gil, and
and  (where
(where 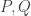 are characteristic vectors of HAPs, and the objective is to maximize the sum of the diagonal entries).
are characteristic vectors of HAPs, and the objective is to maximize the sum of the diagonal entries).
Yes, linear programming can be used to find the optimal solution to Tim’s approach of expressing a diagonal matrix as a convex combination of
In order to do this, you have two non-negative variables for every pair of HAPs: , the coefficient for
, the coefficient for  and
and  , the coefficient of
, the coefficient of  . You stipulate that
. You stipulate that  . The convex combination is an
. The convex combination is an  matrix; call it
matrix; call it  . Each entry of
. Each entry of  can be expressed as a linear function of the variables
can be expressed as a linear function of the variables  . We impose the condition that
. We impose the condition that  for
for  and the objective function is
and the objective function is  .
.
The SDP approaches do not directly lead to a linear programming problem,
although generally speaking, there are iterative methods to solve SDPs where each iteration requires the solution of a linear program. I don’t think this is what you were asking though.
March 19, 2010 at 4:46 pm
Thanks, Moses
One “role-model” case I have in mind is the LP approach for the maximum size of errore correcting codes and spherical codes. There, after moving to the dual description there is a way to analytically study the LP, which ties with certain hypergeometric functions and get good upper bounds which cannot be achieved by other methods. It is not known what the limits of the LP method is. There is a recent SDP approach which leads to better bounds in particular cases. For small cases the LP is much easier to compute than the SPD. It is not clear if the SDP can potentially lead to better asymptotic results and, in any case, it looks too difficult.
In our case since the LP talks about pairs of HAPs to start I dont think it is computationally better for small cases. As for theoretically studying it, I suppose trying to look at the dual is an instinct (probably it was already considered, was it?) and then the difficult part is trying to relate it to some familiar mathematics. This looks difficult.
March 18, 2010 at 10:37 pm |
In a somewhat similar spirit to Gil’s question, here is a question that I should have asked in this comment, but have only just thought of. The question is whether we can find interesting sequences of positive numbers such that the discrepancy of every sequence
of positive numbers such that the discrepancy of every sequence 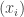 is bounded below by
is bounded below by  . We know that
. We know that  , so if the discrepancy is bounded below by
, so if the discrepancy is bounded below by  , then we can take
, then we can take  .
.
March 19, 2010 at 2:18 pm
If your question is about efficient computational methods to find such sequences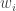 , then I don’t know of any other than the SDP approach and your diagonal-representation approach. If you think about how one might get such sequences via a convex programming approach, the
, then I don’t know of any other than the SDP approach and your diagonal-representation approach. If you think about how one might get such sequences via a convex programming approach, the 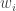 should correspond to constraints
should correspond to constraints  . But
. But  is not a convex constraint, i.e. the set of feasible vectors
is not a convex constraint, i.e. the set of feasible vectors  is not convex. Both the SDP and the diagonal-representation approach get around this problem in similar, but slightly different ways by solving an optimization problem on a different set of variables: In the SDP approach, the ‘variables’ are all products
is not convex. Both the SDP and the diagonal-representation approach get around this problem in similar, but slightly different ways by solving an optimization problem on a different set of variables: In the SDP approach, the ‘variables’ are all products 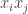 , and we place the constraint
, and we place the constraint  . In the representation of diagonals approach, we consider two sequences
. In the representation of diagonals approach, we consider two sequences  , the ‘variables’ are the products
, the ‘variables’ are the products  and we impose the constraint
and we impose the constraint  . As stated, the feasible set is still not convex, but actually, we allow convex combinations of matrices: convex combinations of
. As stated, the feasible set is still not convex, but actually, we allow convex combinations of matrices: convex combinations of  are simply the set of positive semidefinite matrices. In the diagonal-representation approach, convex combinations of
are simply the set of positive semidefinite matrices. In the diagonal-representation approach, convex combinations of  are arbitrary matrices.
are arbitrary matrices.
Ok … I think this comment went off on a little bit of a tangent. What you are really asking: is can we find interesting sequences by any means, not necessarily by convex programming. I don’t know the answer to that.
by any means, not necessarily by convex programming. I don’t know the answer to that.
March 19, 2010 at 3:49 pm
Yes, my thought was roughly this. If the SDP approach works, then there must exist a lower bound of the form for the discrepancy, with
for the discrepancy, with 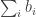 unbounded. But
unbounded. But  is at least as big as
is at least as big as  , so there must be a lower bound of the form
, so there must be a lower bound of the form  with
with  unbounded. Moreover, since we cannot reverse the implication, this should be a weaker statement.
unbounded. Moreover, since we cannot reverse the implication, this should be a weaker statement.
Looking at it now, I realize that it won’t be weak enough to be easy, since it clearly implies EDP.
March 19, 2010 at 9:12 am |
From computer experiments and various computer aided proofs we know that there is no completely multiplicative function with values in {-1,+1}, 2-bounded discrepancy and domain larger than {1,…,246}. Our human proofs are still inefficient in the sense that they contain a huge amount of cases and that they are not extendable to the general situation. This is maybe the case why we have lost interest in them. Let me just point out that we can reduce (or at least disguise) the number of cases to consider by exploiting properties of the set of all such partially defined completely multiplicative functions. Each of the following 6 facts is interesting in its own and comparatively easy to prove (at least compared to what we have so far). Let the functions be defined on {1,…,n}.
1. If n >= 123, then f(2)=-1.
2. If n >= 133, then f(3)=-1.
3. If n >= 215, then f(13)=-1.
4. If n >= 215, then f(19)=1 (the optimal bound is 123, but this is what we need, easier to prove and still the toughest case).
5. If n>= 225, then f(5)=-1.
6. If n>= 225, then f(41)=-1.
The final statement: let f:{1,…n}->{-1,+1} be a completely multiplicative function with discrepancy bounded by 2. Then n=247. Using the lemmas we get f(242)=f(2)f(11)^2=-1 and f(243)=f(3)^3=-1. This implies a cut at 242 and thus the partial sum f[242] is zero. Since f(245) = f(5)f(7)^2 = -1, f(246) = f(2)f(3)f(41) = -1 and f(247) = f(13)f(19) = -1 we have f[247]=-4+f(244) which is a contradiction.
March 21, 2010 at 10:00 pm
I’ve looked at these statements. They do seem to fit together to prove the theorem. I think the first two are proved in the wiki at http://michaelnielsen.org/polymath1/index.php?title=Human_proof_that_completely_multiplicative_sequences_have_discrepancy_at_least_2 but the proofs do not look particularly easy. The last 4 do not have easy proof as far as I know. If you have easy proofs for these six theorems I would like to see them as the would probably result in a proof of the overall result that is more simple than anything we have now.
March 22, 2010 at 7:48 am
What I meant to say, but probably didn’t was that with this 6 lemmas and one theorem approach we can reorganize the multitude of considered cases to reach subgoals which can be communicated on their own (as opposed to being subcases of some rather long proof).
That might motivate us to do the polishing (of the proof quoted by you), something so far nobody has done yet.
I have tex-ed the first lemma which is somewhere between 1 and 2 pages and let the prover work on the other cases. Its output makes me believe that we might need 20 (tex-)pages.
March 19, 2010 at 9:15 am |
In the proof of the final statement we have to assume n>=247. That got lost.
March 19, 2010 at 3:19 pm |
Here is an attempt to answer Moses’s exercise. That is, I shall try to be more precise about my earlier suggestion of how to produce a representation-of-diagonals approach to Roth’s theorem that the APs discrepancy of a sequence of length
sequence of length  is always at least
is always at least  .
.
I start with the well known lemma that for every real number and every
and every  there exists some
there exists some  such that
such that  . (Here,
. (Here,  is an absolute constant —
is an absolute constant — 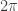 should do the job.)
should do the job.)
Now let . Then for every
. Then for every  we can find
we can find  such that
such that  .
.
Let for a sufficiently small absolute constant
for a sufficiently small absolute constant  . Let
. Let  be the interval
be the interval  . Let us estimate
. Let us estimate  . For every
. For every  we know that
we know that  . (This follows easily from the triangle inequality and the fact that
. (This follows easily from the triangle inequality and the fact that  .) We also know that
.) We also know that  is real. Hence,
is real. Hence,  is a real number that lies between
is a real number that lies between  and
and  .
.
Let us now define to be the characteristic measure of
to be the characteristic measure of  . (That is,
. (That is,  takes the value
takes the value  on
on  and 0 everywhere else.) Let
and 0 everywhere else.) Let  be the function
be the function  . Then the above calculation proves that
. Then the above calculation proves that  for some real constant
for some real constant  that lies between
that lies between  and 1.
and 1.
Now . (That is how I am going to define the convolution in this post.) Thus, if we define
. (That is how I am going to define the convolution in this post.) Thus, if we define  to be
to be  , then
, then  , from which it follows that
, from which it follows that  .
.
From this we deduce that .
.
We can use this to express as a linear combination of tensor products of HAPs. Note that
as a linear combination of tensor products of HAPs. Note that  is the characteristic measure of
is the characteristic measure of  , so associated with
, so associated with  are coefficients with absolute values adding up to
are coefficients with absolute values adding up to  , the order of magnitude of which is
, the order of magnitude of which is  (since
(since  is around
is around 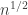 ). Adding this together for all
). Adding this together for all  takes us up to
takes us up to  , which is no good since the trace of
, which is no good since the trace of  is also
is also  .
.
Now let’s try to do better. For each let
let  be the set of all
be the set of all  such that we chose
such that we chose  for that
for that  . The above argument has a notable inefficiency in it, which is that attached to each
. The above argument has a notable inefficiency in it, which is that attached to each  is a sum of coefficients
is a sum of coefficients  , and we were bounding
, and we were bounding  above by
above by  , thereby ignoring a great deal of potential cancellation.
, thereby ignoring a great deal of potential cancellation.
What can we say about ? It is at most
? It is at most  , which after a small back-of-envelope calculation can be seen to equal
, which after a small back-of-envelope calculation can be seen to equal  . Now
. Now  is bounded above by some absolute constant and
is bounded above by some absolute constant and  has size at most
has size at most  , where
, where  is another absolute constant. Therefore, this is at most
is another absolute constant. Therefore, this is at most  .
.
The contribution to the sum of the coefficients from is therefore
is therefore  , which equals
, which equals  . There are
. There are  different values of
different values of  to consider, so the total sum of coefficients is at most
to consider, so the total sum of coefficients is at most  . Now recall that each
. Now recall that each  is itself around
is itself around 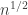 times the characteristic function of
times the characteristic function of  , so we have to multiply this by a further
, so we have to multiply this by a further  (because so far I’ve evaluated a sum of coefficients attached to functions of the form
(because so far I’ve evaluated a sum of coefficients attached to functions of the form  ). That gets us up to
). That gets us up to  . Since the trace of
. Since the trace of  is
is  , we have proved a lower bound for AP discrepancy of
, we have proved a lower bound for AP discrepancy of  , which is the square root of what I wanted.
, which is the square root of what I wanted.
Now I’m pretty sure I know why that happened. It’s because I used an inefficient method for estimating the amount of cancellation. The reason it was inefficient is that the sets are not just any old sets of size
are not just any old sets of size  but are more like dilations of arithmetic progressions. We were essentially working out
but are more like dilations of arithmetic progressions. We were essentially working out  norms of Fourier transforms of sets
norms of Fourier transforms of sets  , but using only their cardinalities and not their special structure.
, but using only their cardinalities and not their special structure.
However, to exploit this structure, we have to choose the in a more careful way, probably with weights. The weights would be needed because the Fourier transform of the characteristic function of an arithmetic progression will introduce a logarithmic factor. So we want to apply the Fejer kernel trick, and we also want to make sure that the coefficients
in a more careful way, probably with weights. The weights would be needed because the Fourier transform of the characteristic function of an arithmetic progression will introduce a logarithmic factor. So we want to apply the Fejer kernel trick, and we also want to make sure that the coefficients  vary smoothly somehow.
vary smoothly somehow.
This I haven’t yet done. Let me state the problem more clearly. I would like to define for each a function
a function 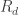 , and I would like these functions to have the following three properties. First, they sum to the constant function 1. Secondly,
, and I would like these functions to have the following three properties. First, they sum to the constant function 1. Secondly,  only if
only if  is at most
is at most  . Thirdly, each
. Thirdly, each 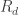 should vary smoothly enough for the
should vary smoothly enough for the  norm of its Fourier transform to be as small as it can reasonably be (which, if you normalize appropriately, is at most
norm of its Fourier transform to be as small as it can reasonably be (which, if you normalize appropriately, is at most  , because roughly
, because roughly 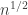 coefficients will take the value roughly
coefficients will take the value roughly  and the rest will be small).
and the rest will be small).
March 19, 2010 at 3:55 pm |
Something I’ve been meaning to think about properly for some time is whether the existence of character-like functions gives us some clues about what an SDP solution or a representation-of-diagonal solution could possibly look like. I plan to try to work out something more precise in due course, but for now let me merely point out the triviality that if you think you have an approach to writing a diagonal map with unbounded trace as a linear combination with
with  , then a good test is to see whether there is any chance that
, then a good test is to see whether there is any chance that  is unbounded, when
is unbounded, when  is a character-like function such as
is a character-like function such as  . For this to happen, it will be necessary for the
. For this to happen, it will be necessary for the  to attach plenty of weight to HAPs on which the sum of the
to attach plenty of weight to HAPs on which the sum of the  is unbounded.
is unbounded.
Having said that, maybe it isn’t such a huge constraint, since for a typical large integer the partial sum of up to that integer will be unbounded.
up to that integer will be unbounded.
March 19, 2010 at 10:42 pm |
This is not a new thought, but an old one that is perhaps due a revival. It’s been a while since we tried working on the rationals rather than the integers. Given that the rationals enjoy much better symmetry properties than the integers, and given that symmetry is very useful in the proof that the discrepancy for ordinary APs is unbounded, there is at least a chance that the SDP or ROD (= “representation of diagonal”) method could work more easily for the rationals.
For example, if we are working on the integers, then we find ourselves having to guess some strange diagonal map with coefficients that favour, in a way that we do not fully understand, numbers with more factors. If we were working over the rationals, then all numbers would have equal status (since the automorphisms of the additive group of act transitively), so the diagonal map we would be trying to work with would be the identity.
act transitively), so the diagonal map we would be trying to work with would be the identity.
Of course, that instantly raises a problem, which is that everything’s a bit too infinite. I think that means we’d have to resurrect some of the limiting techniques that Terry explained back in about EDP2 or something. Or perhaps we’d somehow be able to represent the identity using only a finite sum of coefficients of HAPs.
What, one might ask, about the usual example that shows that representing the identity efficiently is impossible? Well, over the rationals it is far less clear that that example exists, if I can put it that way. After all, what might it be? We could take the function that’s defined only on the positive integers that takes the value 1 when an integer is 1 mod 3, -1 when it is 2 mod 3, and 0 otherwise. If we call that function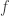 then we are not going to be able to prove that the square of the discrepancy of
then we are not going to be able to prove that the square of the discrepancy of 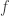 is at least
is at least  . But it’s not clear that that’s the right Hilbert space to be taking for our functions defined on the rationals. Maybe something that’s a bit more like an average (but infinite for functions that are
. But it’s not clear that that’s the right Hilbert space to be taking for our functions defined on the rationals. Maybe something that’s a bit more like an average (but infinite for functions that are  everywhere) could be defined that would do the job: it doesn’t seem unreasonable to suggest that the square of the function
everywhere) could be defined that would do the job: it doesn’t seem unreasonable to suggest that the square of the function 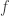 just defined has zero density, rather than the density 2/3 that it would have if it were just defined on
just defined has zero density, rather than the density 2/3 that it would have if it were just defined on  .
.
Just to get my head round this, I want to think about what the sum of over all HAPs
over all HAPs  of length
of length  would be. When do rational numbers
would be. When do rational numbers  and
and  both belong to the same HAP of length
both belong to the same HAP of length  ? Note that the notion of a highest common factor makes sense over the rationals. If
? Note that the notion of a highest common factor makes sense over the rationals. If  , then the number of HAPs of length
, then the number of HAPs of length  that contain both
that contain both  and
and  is the number of positive integers
is the number of positive integers  such that
such that  , which equals the integer part of
, which equals the integer part of  .
.
Here’s another idea. (For now I’m just going to play around a bit.) We can form out of HAPs a function that’s -1 at odd multiples of some rational and 1 at even multiples, simply by taking twice the characteristic function of the HAP with common difference 2d and subtracting the characteristic function of the HAP with common difference d. So let’s try summing all functions of the form
and 1 at even multiples, simply by taking twice the characteristic function of the HAP with common difference 2d and subtracting the characteristic function of the HAP with common difference d. So let’s try summing all functions of the form  , where
, where  alternates signs on a HAP of length
alternates signs on a HAP of length  .
.
Once again, let us pick rationals and
and  with
with  . Then the number of HAPs of length
. Then the number of HAPs of length  that contain both
that contain both  and
and  is, as we have seen, the integer part of
is, as we have seen, the integer part of  . The common differences of these HAPs are all of the form
. The common differences of these HAPs are all of the form  for some positive integer
for some positive integer  . If
. If 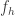 is the alternating signs function on the HAP of common difference
is the alternating signs function on the HAP of common difference  , then
, then  . Therefore, if
. Therefore, if  is odd, we get a lot of cancellation.
is odd, we get a lot of cancellation.
I’m not sure where to go with these observations, so instead let me discuss another idea. The ROD approach to Roth’s discrepancy theorem was to take a known representation of the identity and show that it can be rewritten in terms of characteristic functions of appropriately chosen APs (ones that do not wrap around too much). Can we argue that the known representation of the identity (in terms of trigonometric functions) is a natural one? Obviously yes, so I suppose what I mean is, can we argue that it is natural in a relevant way? I think the answer is still yes: the trigonometric functions are simultaneous eigenvectors of all shifts, and dilations move them from one to another. So they are very closely connected to the symmetries of the problem.
That makes me wonder whether we might be able to use some representation-theoretic thoughts to help us guess what to do in the HAPs case. The rough idea would be that we have a group of symmetries that take HAPs to HAPs (except that it’s only a group if we work on the rationals) and we’d like to find a nice basis of characters that will be eigenvectors for all these symmetries.
Actually, I think we’ve got those — aren’t they simply the completely multiplicative functions to the complex numbers?
So the next step might be to “integrate” over all and hope desperately that the result was a diagonal map (by which I mean a map from
and hope desperately that the result was a diagonal map (by which I mean a map from  to
to  — but in fact to
— but in fact to  — that is zero at
— that is zero at 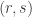 unless
unless  ).
).
And then it gets a bit less clear, but I think the idea would be to show that each multiplicative function can be decomposed in a fairly natural way as a linear combination of HAPs, and then to show that the same pairs of HAPs often get used for several different multiplicative functions, with coefficients that point in different directions and therefore cancel to a significant extent.
I’ve gone far enough into the realms of fantasy at this point, so will finish for the day.
March 19, 2010 at 11:25 pm
A small extra remark: decomposing a multiplicative function into HAPs might not be that easy, since to do it efficiently one would seem to want to use HAPs that have a reasonably large inner product with the function, but that seems to require showing that the function has large discrepancy. But perhaps we can do an inefficient decomposition and then gain on the cancellation later.
March 20, 2010 at 9:02 am |
Klas, re this comment: I’ve tried running my search program with these sets of constraints, but I doubt whether it will get anywhere (even as far as 1124). It might be possible to make better use of the structure of the constraints, but I can’t immediately see how to do so.
March 20, 2010 at 9:41 am
Alec, I have resumed that calculation as well. The program has eliminated several of the stubs and I think it will be able to eliminate one more in the next few days.
There is then one left which you could focus on, the last stub in the file. Right now my program is not working on that case at all, and has eliminated all but one of the others.
March 20, 2010 at 9:52 am
Do I understand correctly that if you can eliminate all stubs, then we will have for the first time ever a proof that for sufficiently large (in fact, for
(in fact, for  slightly bigger than 2000), every
slightly bigger than 2000), every  sequence of length
sequence of length  has HAP discrepancy at least 3?
has HAP discrepancy at least 3?
March 20, 2010 at 10:12 am
Yes, I believe so.
March 20, 2010 at 2:27 pm
Tim, that is correct.
March 23, 2010 at 12:34 pm
My program has now eliminated all stubs but one. The remaining case is the last stub in the file. This problem has required a surprisingly large amount of CPU time.
March 23, 2010 at 1:11 pm
Good progress! My program has been working on the last case for a few days now (on a single CPU) — but from its progress so far I’m not encouraged to believe it will finish any time soon, so if you’re working on it with multiple CPUs I’m inclined to abandon my attempt.
March 20, 2010 at 9:35 am |
Let be a
be a  matrix whose rows are characteristic functions of HAPs (
matrix whose rows are characteristic functions of HAPs ( is the number of HAPs on 1,2,…,n). Let
is the number of HAPs on 1,2,…,n). Let  be
be  matrices such that
matrices such that  for
for  where
where  denotes the
denotes the  th column of matrix
th column of matrix  . Note that
. Note that  , a diagonal matrix. We find
, a diagonal matrix. We find  matrices
matrices  , such that
, such that  and
and  . Then
. Then  . Now
. Now  , where
, where 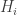 denotes the
denotes the  th row of
th row of  . Thus this gives a diagonal representation. The trace of the diagonal matrix
. Thus this gives a diagonal representation. The trace of the diagonal matrix  is
is  . On the other hand, the sum of the absolute values of the coefficients of
. On the other hand, the sum of the absolute values of the coefficients of  in the representation is
in the representation is  . The lower bound on discrepancy established by this diagonal representation is
. The lower bound on discrepancy established by this diagonal representation is  .
.
It is not clear that finding a diagonal representation of this form that yields a good lower bound is a simpler task in any way. There is considerable freedom in picking matrices and even after picking them, there is freedom in picking
and even after picking them, there is freedom in picking  and
and  . This ought to be connected to eigenvalues and eigenvectors, but I don’t know the connection yet.
. This ought to be connected to eigenvalues and eigenvectors, but I don’t know the connection yet.
Are the optimal diagonal representations constructed by the LP for small of this form ? … Actually, now that I think about it, perhaps any diagonal representation is of this form, because given the coefficients of
of this form ? … Actually, now that I think about it, perhaps any diagonal representation is of this form, because given the coefficients of  in the representation, we can always express the matrix of coefficients as
in the representation, we can always express the matrix of coefficients as  … ok, that’s not quite true because
… ok, that’s not quite true because  are supposed to be
are supposed to be  matrices and
matrices and  . For this to work, the rank of the matrix of coefficients should be at most
. For this to work, the rank of the matrix of coefficients should be at most  .
.
March 20, 2010 at 9:39 am
Oops … that previous comment started a little abruptly. In reading it, insert the following text at the beginning:
Here is one class of diagonal representations. (Although I haven’t fully understood Tim’s construction for proving Roth’s theorem, I believe it is of this form).
March 20, 2010 at 11:15 am |
Continuing for a moment the line of thought that can be found in this comment (and I think it is also closely related to Moses’s comment just above, but I haven’t yet got a computational feel for that one yet), let me make a couple of further observations.
Recall that a character of the multiplicative group is nothing other than a completely multiplicative function from
is nothing other than a completely multiplicative function from  to
to 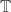 . It is determined by its values at primes, and that allows us to put a probability measure on the space of all characters: we just uniformly and independently choose the values at the primes. If
. It is determined by its values at primes, and that allows us to put a probability measure on the space of all characters: we just uniformly and independently choose the values at the primes. If  is a random character, then what can we say about the matrix
is a random character, then what can we say about the matrix  ? Its value at
? Its value at  is
is  , and its value at
, and its value at 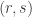 is
is  , which averages zero if
, which averages zero if  . Therefore,
. Therefore,  is the identity. (This is of course just a special case of a much more abstract result.)
is the identity. (This is of course just a special case of a much more abstract result.)
Now let us think about how we might try to decompose a multiplicative function into a linear combination of HAPs. The obvious way to do it, which we do not expect to be efficient, is to use a greedy algorithm that’s close to how one proves Möbius inversion. To illustrate it, let us take a function that might be regarded as the first non-trivial completely multiplicative function: it takes a rational in its lowest terms and returns 1 if the number of 2s in the prime factorization is even and -1 if the number of 2s is odd. For instance, and
and  .
.
Having written that, I suddenly realize that I was thinking about what to do when we are talking about integers rather than rationals. If we write for the characteristic function of
for the characteristic function of  then we would end up taking
then we would end up taking  . It’s not hard to check that that gives the right answer at every integer. As a matter of fact, so does
. It’s not hard to check that that gives the right answer at every integer. As a matter of fact, so does  , so maybe we could say that this function is, in some formal sense, equal to
, so maybe we could say that this function is, in some formal sense, equal to  . A formal sense that would work is to say that it’s the pointwise limit of those sums from
. A formal sense that would work is to say that it’s the pointwise limit of those sums from  to
to  as
as  tends to infinity.
tends to infinity.
By that kind of technique we can build multiplicative functions that take the value 1 at all primes except one, and by multiplying those together we can get all multiplicative functions. However, I’m a bit troubled by the fact that the coefficients look as though they are getting very large. For instance, if we took the Liouville function, then the coefficient of would be 4 (since
would be 4 (since  is the pointwise product of
is the pointwise product of  and
and  ), and more generally, the absolute value of the coefficient of
), and more generally, the absolute value of the coefficient of  would be 2 raised to the power the number of distinct prime factors of
would be 2 raised to the power the number of distinct prime factors of  . I suppose that usually isn’t too big.
. I suppose that usually isn’t too big.
I’m going to stop this comment before it gets too long and do a bit of work away from the computer. What I want to do is take an arbitrary completely multiplicative function and see what its decomposition of this kind is. Then for any pair
and see what its decomposition of this kind is. Then for any pair  of rationals I want to take the corresponding coefficient of
of rationals I want to take the corresponding coefficient of  in the expansion of
in the expansion of  . Finally, I want to average over all
. Finally, I want to average over all  . At this last stage I am hoping for a significant saving as a result of cancellation.
. At this last stage I am hoping for a significant saving as a result of cancellation.
You might object that it shouldn’t be possible to prove anything just using infinite HAPs. That objection has considerable force, but note that we do not have the usual “1 on first half, -1 on second half” counterexample at our disposal in the infinite case. So I’m going to pursue this thought for a bit longer and see where it gets me. The dream scenario would be to get a purely formal and nonrigorous argument that feels like a proof of EDP, and then to find some way of making it rigorous via a limiting argument.
March 20, 2010 at 12:08 pm |
For some reason I was blind in the previous comment and failed to notice that what I was doing was exactly Möbius inversion. In fact, it’s not even quite accurate to say that I didn’t notice — I noticed the possibility and then for some reason wrongly concluded that it wasn’t quite the same, even though in the past I have known perfectly well that it was.
So, here I am with sanity restored. Let me start with the integer case, and then I’ll try to move to the rationals. Let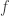 be an arbitrary completely multiplicative function from
be an arbitrary completely multiplicative function from  to
to 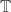 . We would like to write
. We would like to write 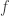 as
as  for some coefficients
for some coefficients  . But that is saying that we want
. But that is saying that we want  to equal
to equal  . But that’s saying
. But that’s saying  , where
, where  is the Dirichlet convolution and
is the Dirichlet convolution and  denotes the constant function 1. The Dirichlet inverse of
denotes the constant function 1. The Dirichlet inverse of  is the Möbius function
is the Möbius function  , so if we Dirichlet convolve on both sides by
, so if we Dirichlet convolve on both sides by  we get that
we get that  . That is,
. That is,  . Since
. Since  is multiplicative, we can write this as
is multiplicative, we can write this as  . Now let the primes that divide
. Now let the primes that divide  be
be  and write
and write ![[k]](https://s0.wp.com/latex.php?latex=%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) for the set
for the set 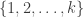 . Then this expression becomes
. Then this expression becomes ![f(m)\sum_{A\subset[k]}\prod_{i\in A}(-\overline{f(p_i)})](https://s0.wp.com/latex.php?latex=f%28m%29%5Csum_%7BA%5Csubset%5Bk%5D%7D%5Cprod_%7Bi%5Cin+A%7D%28-%5Coverline%7Bf%28p_i%29%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) , which equals
, which equals  .
.
Now I’m going to try to work out what Möbius inversion over the rationals is.
March 20, 2010 at 3:55 pm |
Actually, before I do that I’d like to think about the integer case. The coefficient attached to the HAP in the expansion of the multiplicative function
in the expansion of the multiplicative function 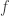 is, as we have seen,
is, as we have seen,  . It follows that the coefficient attached to
. It follows that the coefficient attached to  in
in  is
is  .
.
Now I need to think about what this works out to be. At first I thought it was going to be rather easy, since all one has to do is average over the possible values of the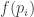 . But now I see that it’s more complicated because of the double appearance of
. But now I see that it’s more complicated because of the double appearance of  . So I’m going to do a calculation based on the formula in the previous comment, and I’ll come back with the answer.
. So I’m going to do a calculation based on the formula in the previous comment, and I’ll come back with the answer.
March 20, 2010 at 4:15 pm |
OK, let’s begin with the case . Then we’re just looking at
. Then we’re just looking at  . Expanding that back out, we get
. Expanding that back out, we get ![\sum_{A,B\subset[k]}(-1)^{|A|+|B|}\prod_{i\in A}f(p_i)\prod_{j\in B}\overline{f(p_j)}](https://s0.wp.com/latex.php?latex=%5Csum_%7BA%2CB%5Csubset%5Bk%5D%7D%28-1%29%5E%7B%7CA%7C%2B%7CB%7C%7D%5Cprod_%7Bi%5Cin+A%7Df%28p_i%29%5Cprod_%7Bj%5Cin+B%7D%5Coverline%7Bf%28p_j%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Now if
. Now if 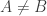 then there is at least one
then there is at least one  that occurs in exactly one of
that occurs in exactly one of  and
and  . Then for every choice of the
. Then for every choice of the  with
with  the average over the possible choices of
the average over the possible choices of 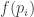 is zero. And if
is zero. And if 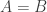 then obviously we get 1. So the whole thing works out to be
then obviously we get 1. So the whole thing works out to be ![\sum_{A\subset[k]}1=2^k](https://s0.wp.com/latex.php?latex=%5Csum_%7BA%5Csubset%5Bk%5D%7D1%3D2%5Ek&bg=ffffff&fg=333333&s=0&c=20201002) .
.
To summarize: the coefficient attached to in this expansion is
in this expansion is  , where
, where  is the number of distinct prime factors of
is the number of distinct prime factors of  . I’ll tackle the off-diagonal case in the next comment.
. I’ll tackle the off-diagonal case in the next comment.
March 20, 2010 at 4:45 pm |
This time let us write and
and  . Then we get
. Then we get  . Once again, the terms where
. Once again, the terms where  contribute zero on average, and when
contribute zero on average, and when 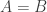 the two products multiply together to give 1. Therefore, in this case we get
the two products multiply together to give 1. Therefore, in this case we get  , where
, where  is the number of distinct primes in the prime factorization of
is the number of distinct primes in the prime factorization of  .
.
The next thing to think about is whether this observation counts as some kind of useful cancellation, along similar lines to what I was talking about in connection with Roth’s theorem. The answer is almost certainly no, since it looks as though we can simply truncate and fit everything into , and we know that the result is false for HAPs of the form
, and we know that the result is false for HAPs of the form 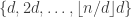 .
.
March 20, 2010 at 7:53 pm
The answer is that it certainly gives us a lot of cancellation, but the initial estimate (before the cancellation) is so bad that all the cancellation does is get us to something that is not quite so bad. But it’s pretty bad nonetheless — it proves a lower bound for EDP that tends to zero!
Another way of decomposing a multiplicative function into HAPs is to observe that each vector in the standard basis is the difference between the characteristic function of the first
in the standard basis is the difference between the characteristic function of the first  integers and the characteristic function of the first
integers and the characteristic function of the first  integers. If we then decompose a multiplicative function
integers. If we then decompose a multiplicative function  as
as  , we find when we expand out
, we find when we expand out  and average out, that all the off-diagonal terms cancel and we end up writing the identity as
and average out, that all the off-diagonal terms cancel and we end up writing the identity as  , which (since each
, which (since each  is made out of two HAPs) gives us the usual trivial lower bound of 1/4.
is made out of two HAPs) gives us the usual trivial lower bound of 1/4.
After all that, it’s not clear that the initial decomposition of the identity as (where
(where  ranges over all completely multiplicative functions) is especially helpful as a staging post to an efficient HAP decomposition.
ranges over all completely multiplicative functions) is especially helpful as a staging post to an efficient HAP decomposition.
March 20, 2010 at 10:08 pm |
Here is a half-baked idea following on from Tim’s remarks at the top about volumes of convex bodies, and probably not a new one, but it’s only just dawned on me. I wonder if we can say anything about the volume of the symmetric convex hull of the characteristic vectors of HAPs in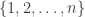 .
.
Let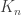 be that convex hull (so
be that convex hull (so 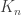 is the set of all
is the set of all  where
where  and
and  is the characteristic function of a HAP). And let
is the characteristic function of a HAP). And let 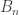 be the unit ball in
be the unit ball in  (so
(so  ). Since EDP would imply that every extreme point of
). Since EDP would imply that every extreme point of 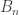 correlates well with a point of
correlates well with a point of 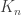 , we might hope that the volume of
, we might hope that the volume of 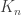 would be large (as a proportion of the volume of
would be large (as a proportion of the volume of 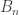 , which is
, which is  ).
).
March 22, 2010 at 7:08 am |
I wanted to think about diagonal representations where one constructs a linear combination of tensor products of characteristic vectors of HAPs with the same common difference. So for example, we are allowed to take tensor products of HAPs of common difference 1, and add them to tensor products of HAPs of common difference 2, and so on, but we cannot mix HAPs with two different common differences. Hopefully, this additional restriction makes it easier to think about possible diagonal representations, but it may be possible that the best bound achievable by imposing this restriction is bounded, even if the best bound achievable in general is unbounded.
Does anyone have a reason to believe that this restriction is too strong ? In order to show that the best bound achievable by this restriction is bounded, you need to devise a construction of matrices
matrices  such that for all d, for all HAPs P and Q of common difference d,
such that for all d, for all HAPs P and Q of common difference d,  , where C is a constant. (Here, I am using P to represent both the HAP and its characteristic vector, but the meaning should be clear from context).
, where C is a constant. (Here, I am using P to represent both the HAP and its characteristic vector, but the meaning should be clear from context).
March 22, 2010 at 7:46 am
Another way of thinking about what it would mean for the proof to work in principle (that is, for the best bound using just these matrices to be unbounded) is that the following strengthening of non-symmetric vector-valued EDP holds: given any two sequences of vectors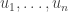 and
and 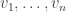 such that
such that  for every
for every  , there exist HAPs
, there exist HAPs  and
and  with the same common difference such that
with the same common difference such that  , where
, where  tends to infinity.
tends to infinity.
At the moment, I don’t have much feel for how far it is reasonable to expect to be able to strengthen EDP in this direction. For instance, it’s not obvious to me that one can’t go as far as insisting that . That would say that we can decompose a diagonal matrix with unbounded trace as a linear combination
. That would say that we can decompose a diagonal matrix with unbounded trace as a linear combination  with the absolute values of the coefficients summing to 1.
with the absolute values of the coefficients summing to 1.
March 22, 2010 at 8:10 am
I looked at some LP solutions for the optimal diagonal representation with this restriction. Inspired by them, here is a simple construction of a diagonal representation such that the ratio of the trace of
such that the ratio of the trace of  to
to  approaches 0.5 asymptotically. Admittedly not a great lower bound, but recall that so far, the best LP solution (without this restriction) we had been able to obtain earlier had a value of about 0.43178 (this was for
approaches 0.5 asymptotically. Admittedly not a great lower bound, but recall that so far, the best LP solution (without this restriction) we had been able to obtain earlier had a value of about 0.43178 (this was for  ). I will deliberately not use singleton HAPs in this construction since we get a bound of 1 in a trivial way by using them.
). I will deliberately not use singleton HAPs in this construction since we get a bound of 1 in a trivial way by using them.
In order to describe this family of solutions, I’ll introduce some notation. I use to denote the characteristic vector of the HAP of common difference
to denote the characteristic vector of the HAP of common difference  ending in
ending in  (this is only defined if
(this is only defined if  divides
divides  ). If
). If  is a linear combination of HAPs, I use
is a linear combination of HAPs, I use  to denote
to denote  . Let
. Let  be a large integer, and let
be a large integer, and let  . Now consider
. Now consider  . Note that
. Note that  is a matrix with 1s in locations (n,n), (n-i,n-i), (n-i,n), (n-i,n) and 0s elsewhere. Thus this summation has a total of 2k on the diagonal and the non-diagonal entries are of the form (n-i,n) and (n,n-i) for i=1,…,k. The sum of absolute values of coefficients used up in the summation is 4k. Now the non-diagonal entries are all in row n and column n. They can be easily killed off by subtracting
is a matrix with 1s in locations (n,n), (n-i,n-i), (n-i,n), (n-i,n) and 0s elsewhere. Thus this summation has a total of 2k on the diagonal and the non-diagonal entries are of the form (n-i,n) and (n,n-i) for i=1,…,k. The sum of absolute values of coefficients used up in the summation is 4k. Now the non-diagonal entries are all in row n and column n. They can be easily killed off by subtracting  and its transpose. (There may be a better way to do this, but it doesn’t matter). These additional terms add a total of 8 to the sum of coefficients. Thus the ratio of the trace to the sum of coefficients is
and its transpose. (There may be a better way to do this, but it doesn’t matter). These additional terms add a total of 8 to the sum of coefficients. Thus the ratio of the trace to the sum of coefficients is  which approaches 0.5 asymptotically.
which approaches 0.5 asymptotically.
Now it is clear that this solution was doomed to achieve no better than 0.5 because it built up the diagonal by using terms of the form . Each of these terms contributed 4 to the sum of coefficients, but only 2 to the diagonal. In order to do better, presumably, we should use terms of the form
. Each of these terms contributed 4 to the sum of coefficients, but only 2 to the diagonal. In order to do better, presumably, we should use terms of the form  where
where  is a large integer. This would contribute
is a large integer. This would contribute  to the diagonal, while the contribution to the sum of coefficients would still be 4. However, it is now much harder to subtract off the non-diagonal terms.
to the diagonal, while the contribution to the sum of coefficients would still be 4. However, it is now much harder to subtract off the non-diagonal terms.
One final comment: expressing such solutions may be easier if we include 0 in every HAP, and have 0 play the role of in the solutions above.
in the solutions above.
March 22, 2010 at 8:23 am
I thought the following argument should rule out the stronger restriction . I think one should be able to construct a matrix
. I think one should be able to construct a matrix  with 1s on the diagonal such that
with 1s on the diagonal such that  for all HAPs
for all HAPs  . We have
. We have  variables available to us (one for each of the non-diagonal entries), and only (about)
variables available to us (one for each of the non-diagonal entries), and only (about) 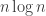 constraints. … not quite a proof, but it seems believable that such a matrix should exist for any
constraints. … not quite a proof, but it seems believable that such a matrix should exist for any  . If so, the stronger restriction will not yield any positive lower bound.
. If so, the stronger restriction will not yield any positive lower bound.
March 22, 2010 at 8:24 am
Another small comment, which follows on from my previous one, but is actually relevant to what you have just posted too. Observe first that if and
and  are (characteristic functions of) HAPs of the same common difference, then
are (characteristic functions of) HAPs of the same common difference, then  is plus or minus a segment of a HAP.
is plus or minus a segment of a HAP.
Since it follows that any (WLOG symmetric) decomposition into
it follows that any (WLOG symmetric) decomposition into 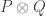 s where
s where  and
and  have the same common difference can be made into a decomposition of the form
have the same common difference can be made into a decomposition of the form  , except that now the
, except that now the  are sets of the form
are sets of the form  . In your construction you clearly did the reverse — starting with a decomposition of the latter type and translating it into one of the former type.
. In your construction you clearly did the reverse — starting with a decomposition of the latter type and translating it into one of the former type.
March 22, 2010 at 8:29 am
Your most recent comment came while I was writing mine. Yes, I think what you say sounds plausible. Actually, I had in mind the more general idea of a HAP, and then a decomposition of the desired kind is easily seen to be equivalent to what you were doing, as I have just pointed out. Even so, it would be quite interesting to try to make your argument rigorous.
March 22, 2010 at 8:31 am
Just to be clear — in your informal argument, you are presumably still insisting that your HAPs are not singletons.
March 22, 2010 at 8:44 am
Good point (about using the more general notion of HAPs). So perhaps decompositions of the form , where
, where  are sets of the form
are sets of the form  are worth thinking about. Now the informal argument about the existence of a matrix
are worth thinking about. Now the informal argument about the existence of a matrix  such that
such that  for all
for all  breaks down. We have about
breaks down. We have about  constraints now. And yes, the informal argument assumes that singleton HAPs are excluded.
constraints now. And yes, the informal argument assumes that singleton HAPs are excluded.
In order to make the informal argument precise, I think something like this may suffice: for any subset of variables , let
, let 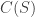 be the constraints that involve only variables in
be the constraints that involve only variables in  . Then for all
. Then for all  ,
,  . Alternately, one can simply give an explicit construction of such matrices.
. Alternately, one can simply give an explicit construction of such matrices.
March 22, 2010 at 12:01 pm
I haven’t checked exactly what matrix this gives, but I think we can easily construct such a matrix step by step, by imposing the constraints (in addition to ):
):
Then, once we’ve got for all
for all  and
and  for
for  (
( ), we can calculate
), we can calculate  from the single linear equation
from the single linear equation
which we can solve because the coefficient of is
is  and the other terms are all known.
and the other terms are all known.
March 22, 2010 at 9:01 pm
Actually, I have found the formula for this matrix. It is given by for
for 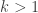 , and
, and  . Here
. Here  is the Mobius function at integers and zero at non-integers. For
is the Mobius function at integers and zero at non-integers. For 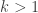 this is Sloane’s A092673. It’s straightforward to prove by direct calculation that this works.
this is Sloane’s A092673. It’s straightforward to prove by direct calculation that this works.
In the course of finding this I’ve stumbled upon a fact that has (I assume) nothing to do with EDP, but which is rather odd. Consider
This seems to be precisely this sequence from Sloane’s database. I’m rather confused by the definition of that sequence, however…
March 22, 2010 at 9:25 pm
I am confused both by that definition and yours. Actually, no I’m not. Your set consists of all multiples of 8, and all numbers that are multiples of an odd perfect square. Equivalently, its complement consists of all square-free numbers and all numbers that are twice a square-free number. But the definition on Sloane’s database seems to be circular — or at least the principal definition does.
March 23, 2010 at 7:05 am
For what it’s worth, I now see that one can just take the (non-symmetric) matrix defined for all
defined for all  by
by  (where by convention
(where by convention  is zero at non-integers). This satisfies
is zero at non-integers). This satisfies  for all HAPs
for all HAPs  (excluding singletons), and has ones on the diagonal.
(excluding singletons), and has ones on the diagonal.
March 22, 2010 at 10:19 pm |
This is not a new point, but I want to articulate it clearly for my own benefit, and perhaps for that of some others. In a sense, what we are trying to do is “quantitative linear algebra”. Given a bunch of HAPs used to form a quadratic form
used to form a quadratic form  , we know that this form is positive semidefinite, and it is positive definite if the
, we know that this form is positive semidefinite, and it is positive definite if the  span. (Proof: then the only way for the sum to be zero — I’m assuming the
span. (Proof: then the only way for the sum to be zero — I’m assuming the 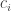 are positive — is for every
are positive — is for every  to be zero, which implies that
to be zero, which implies that  is zero.) But we want to show that the
is zero.) But we want to show that the  are not just a spanning set but “well spread about”, to enable us to prove not just the qualitative fact that that quadratic form is positive definite, but the quantitative fact that it is bounded below by a diagonal quadratic form with unbounded trace.
are not just a spanning set but “well spread about”, to enable us to prove not just the qualitative fact that that quadratic form is positive definite, but the quantitative fact that it is bounded below by a diagonal quadratic form with unbounded trace.
Now it still seems worthwhile to investigate aspects of the purely qualitative question. For example, we could look, and indeed to some extent have looked, at small sets of HAPs where we know that they are not spanning sets, and we could think about what subspaces they annihilate. If we could show that the subspace annihilated by one set of HAPs is very different from the subspace annihilated by some disjoint set of HAPs, it might help us quite a bit.
The idea of this vague proposal would be to identify sets of HAPs (such as the ones of the form “all multiples of d up to n”) where we can explicitly calculate the annihilated subspace. Well, those ones span, but we could remove one of them, say.
I admit that I don’t have a clear view of how this might work, so I’ll leave this comment here for now.
March 23, 2010 at 6:00 am |
I explored this strengthened diagonal-representation question that we discussed recently: Can we construct diagonal matrices of the form
diagonal matrices of the form  , where
, where  are sets of the form
are sets of the form  and the ratio of the trace of
and the ratio of the trace of  to
to  is larger than any fixed constant for
is larger than any fixed constant for  large enough ?
large enough ?
I looked at LP solutions that construct the best such representation for a given . One change from before was that I looked at HAPs over {0,1,2,…n}. The experience with the LP solutions before indicated that the LP benefits from having n be a highly divisible number. However, this requires very large n (I chose n=lcm(1,2,…,k) earlier). Including 0 gets around this since 0 plays the role of the highly divisible number and you might get a good solution for much smaller n.
. One change from before was that I looked at HAPs over {0,1,2,…n}. The experience with the LP solutions before indicated that the LP benefits from having n be a highly divisible number. However, this requires very large n (I chose n=lcm(1,2,…,k) earlier). Including 0 gets around this since 0 plays the role of the highly divisible number and you might get a good solution for much smaller n.
Note that allowing sets of the form can potentially lead to solutions that are better by a factor of 4, since representing
can potentially lead to solutions that are better by a factor of 4, since representing  can be done using a single term instead of 4. Indeed the optimal LP values that I got seem to approach 2 (instead of 0.5 earlier). Moreover, the optimal solutions were exactly of the form
can be done using a single term instead of 4. Indeed the optimal LP values that I got seem to approach 2 (instead of 0.5 earlier). Moreover, the optimal solutions were exactly of the form  where
where  are the sets
are the sets  . This gives a sum of 2d on the diagonal and off-diagonal terms in the 0 row and column. As before, these off-diagonal terms can easily be cancelled off by using a constant number of additional terms.
. This gives a sum of 2d on the diagonal and off-diagonal terms in the 0 row and column. As before, these off-diagonal terms can easily be cancelled off by using a constant number of additional terms.
I had hoped to see more complex LP solutions but the fact that the optimal solutions are of this form (for n upto 100) leads me to conjecture that perhaps 2 is the best bound we can prove using these restricted diagonal representations.
To confirm this, we need to construct matrices
matrices  such that the absolute value
such that the absolute value  is at most 2. (Again, $P$ is a set of the form
is at most 2. (Again, $P$ is a set of the form  . The LP actually constructs such matrices (in fact this is the dual solution). Having looked at them briefly, I didn’t see any obvious pattern. I believe the LP may have a lot of flexibility in constructing such a matrix, so the LP solution may be a result of some arbitrary choices made by the LP solver. We may get some clues from these LP solutions if we suitably constrain them.
. The LP actually constructs such matrices (in fact this is the dual solution). Having looked at them briefly, I didn’t see any obvious pattern. I believe the LP may have a lot of flexibility in constructing such a matrix, so the LP solution may be a result of some arbitrary choices made by the LP solver. We may get some clues from these LP solutions if we suitably constrain them.
March 23, 2010 at 8:21 am
Here is a small thought in that direction. Let and
and  be two coprime integers, both with plenty of factors, such that
be two coprime integers, both with plenty of factors, such that  , and consider the matrix
, and consider the matrix  , where
, where  stands for the set (or its characteristic function) of multiples of
stands for the set (or its characteristic function) of multiples of  .
.
The value of is
is  , which is zero.
, which is zero.
OK I made some mistake in my mind before I started this comment — I was hoping to use as a building block but I don’t see what use it is. (The idea in the back of my mind was that we are trying to find matrices that have a different effect on
as a building block but I don’t see what use it is. (The idea in the back of my mind was that we are trying to find matrices that have a different effect on  s from the effect they have on
s from the effect they have on 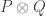 s.)
s.)
March 23, 2010 at 11:32 am
Along those lines, here is a half baked idea: Is it possible to construct such a matrix where the the coordinates of the vectors
where the the coordinates of the vectors  are cosine (or sine) functions ? Then
are cosine (or sine) functions ? Then  and hopefully the dot products
and hopefully the dot products  have small magnitude.
have small magnitude.
March 23, 2010 at 3:22 pm
Here are some difficulties with that idea, though I don’t have a proof that it cannot work.
Obviously just taking one sine or cosine function won’t work. This is partly for the trivial reason that you won’t get 1s down the diagonal. And in fact, that is the only thing wrong with taking . But for a sine with irrational period we can also pick a HAP along which it varies slowly and then pick a segment of that HAP where it is persistently close to 1.
. But for a sine with irrational period we can also pick a HAP along which it varies slowly and then pick a segment of that HAP where it is persistently close to 1.
These simple thoughts push us towards some kind of average. But the average over all trigonometric functions gives us the identity, which is no good to us.
Maybe another point I’d make is that I don’t understand why if is a sum of trigonometric functions then
is a sum of trigonometric functions then  might always be small even though
might always be small even though  could be large.
could be large.
While I’m at it, doesn’t Cauchy-Schwarz imply that whatever symmetric matrix you take, it will not be able to positive semidefinite (at least if this method of proof has any chance of working)? After all, if
you take, it will not be able to positive semidefinite (at least if this method of proof has any chance of working)? After all, if  can be written in the form
can be written in the form 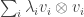 with all the
with all the  positive, then by Cauchy-Schwarz we have
positive, then by Cauchy-Schwarz we have
I haven’t thought that through to the point of seeing whether it is a sensible thing to say, and I’m not claiming to be certain that trigonometric functions won’t help.
March 23, 2010 at 6:27 pm
Yes, if we have a construction of arbitrarily large matrices
matrices  such that
such that  is bounded, then I would hope that this is not possible with all
is bounded, then I would hope that this is not possible with all  positive. If they were all positive,
positive. If they were all positive,  would be positive semidefinite, and then
would be positive semidefinite, and then  would be a counterexample to the SDP approach as well. What you point out above is that a counterexample to the SDP approach automatically is a counterexample to the representation of diagonals approach, since
would be a counterexample to the SDP approach as well. What you point out above is that a counterexample to the SDP approach automatically is a counterexample to the representation of diagonals approach, since 
Any matrix has a representation of the form
has a representation of the form  where
where  are eigenvalues and corresponding eigenvectors. If we know that
are eigenvalues and corresponding eigenvectors. If we know that  is small for all HAPs (over intervals), what does that tell us about good choices for
is small for all HAPs (over intervals), what does that tell us about good choices for  ? (Here I’m thinking of
? (Here I’m thinking of  as being the characteristic vector of a set of the form
as being the characteristic vector of a set of the form  , so we don’t need to think about expressions of the form
, so we don’t need to think about expressions of the form  for HAPs
for HAPs 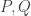 .) Somehow, choosing the coordinates of
.) Somehow, choosing the coordinates of  to be a periodic function with alternating signs seems to be a natural choice to try.
to be a periodic function with alternating signs seems to be a natural choice to try.
March 23, 2010 at 3:39 pm |
Some time ago we had a discussion of how much it might be possible to strengthen EDP by reducing the set of HAPs against which you test the discrepancy. The smallest one that we couldn’t give an answer to consisted of all HAPs with common difference either a prime or a power of 2. (If you just go for primes then the sequence 1,1,-1,-1,1,1,-1,-1,… is a counterexample.) Sune asked whether one could take only HAPs that are of the form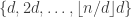 , but the sequence that’s 1 for the first
, but the sequence that’s 1 for the first  terms and
terms and  for the rest is a counterexample to that. However, I don’t immediately see a counterexample if we enlarge this set slightly by allowing all HAPs with common difference 1, while continuing to insist that all other HAPs are “full”. In other words, we would insist that the partial sums are bounded.
for the rest is a counterexample to that. However, I don’t immediately see a counterexample if we enlarge this set slightly by allowing all HAPs with common difference 1, while continuing to insist that all other HAPs are “full”. In other words, we would insist that the partial sums are bounded.
As I was writing that, I suddenly wondered about a trigonometric function (in the complex case) such as , where
, where  is a badly approximable real. But this doesn’t work: we just pick a pretty large
is a badly approximable real. But this doesn’t work: we just pick a pretty large  such that
such that 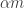 is very close to an integer and let that be the common difference.
is very close to an integer and let that be the common difference.
It seems a bit too much to hope that EDP could be true for this restricted set of HAPs, but if it is, then it might be slightly easier to think about because it would divide the “reason for the high discrepancy” up more clearly into what I think of as the number-theoretic part (to do with divisibility and so on) and the metric part (to do with lengths of HAPs).
One reason to think that it’s false is that the number of HAPs we would be considering is only 2n-1. That is at least more constraints than we have variables, but it still feels like a dangerously small number. Also, we know that a lot of the constraints play no serious role. The number of HAPs we’d be taking with length greater than would be down to
would be down to  or so.
or so.
So let me go the whole hog and ask this. Is it true that for every there exists
there exists  such that for every
such that for every  if you take all HAPs with common difference 1 and all full HAPs with common difference at most
if you take all HAPs with common difference 1 and all full HAPs with common difference at most  you get discrepancy at least
you get discrepancy at least  ? Or, more realisitically, can anyone think of a counterexample?
? Or, more realisitically, can anyone think of a counterexample?
If not, then the next question would be whether we can represent a diagonal matrix if we restrict to just this class of HAPs …
March 23, 2010 at 4:32 pm
Well, the probabilistic heuristics (in its more reliable direction) suggests that this is NOT true; that the number of such sequences when C is large should be larger than 2^{0.999}n.
March 23, 2010 at 5:00 pm
Sorry I got the computation wrong (I considered only divisors d of n.) The PH (in its less reliable direction) indicates that this may well be correct (and also for the original version which we know fails).
March 23, 2010 at 8:09 pm
On the subject of strengthening EDP by reducing the set of HAPs under consideration, I have done some experiments restricting the difference to approximately the square root of the maximum of each HAP. To be precise, I considered the discrepancy with respect to HAPs where
where  . It may be that even this restricted set of HAPs suffices to guarantee unbounded discrepancy (for any
. It may be that even this restricted set of HAPs suffices to guarantee unbounded discrepancy (for any 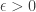 ).
).
March 25, 2010 at 6:17 am
Actually I think I have to retrect the retraction. The probability for the full HAP with period d (If d is not too large) to sum up to a number below x is up to a multiplicative constant . So for large x multiplying all these numbers gives which is not exponentially small. Adding a condition that the partial sums for period 1 are below x or that all bounded sums of HAP with periods at most t are beloe x will still leave us with probability above 2^{0.999}n.
. So for large x multiplying all these numbers gives which is not exponentially small. Adding a condition that the partial sums for period 1 are below x or that all bounded sums of HAP with periods at most t are beloe x will still leave us with probability above 2^{0.999}n.