From time to time, there has been an input into this project that has given rise to a burst of optimism (on my part anyway). Perhaps the first was the rapid discovery of very long sequences with low discrepancy, and especially the fact that these sequences had interesting structure to them. (The length led me to hope that the conjecture might be false, or at the very least that it might be possible to construct sequences with extremely slow-growing discrepancy, and the structure led me to hope the opposite.) I’m probably forgetting a few things, but the next one I remember is Terence Tao’s amazing observation that we could restrict attention to multiplicative functions if we were prepared to change the problem very slightly. We then discovered (though we sort of knew it anyway) that multiplicative functions are not easy objects to understand …
Since I posted EDP9, there has been a development that has radically changed my perception of the problem, and I imagine that of anyone else who is following closely what is going on. It began with this comment of Moses Charikar.
Moses’s idea, which I shall partially explain in a moment (for about the fifth time) is based on the theory of semi-definite programming. The reason I find it so promising is that it offers a way round the difficulty that the sequence 1, -1, 0, 1, -1, 0, 1, -1, 0, … has bounded discrepancy. Recall that this fact, though extremely obvious, is also a serious problem when one is trying to prove EDP, since it rules out any approach that is just based on the size of the sequence (as measured by, say, the average of the squares of its terms). It seemed to be forcing us to classify sequences into ones that had some kind of periodicity and ones that did not, and treat the two cases differently. I do not rule out that such an approach might exist, but it looks likely to be hard.
Moses proposes (if you’ll excuse the accidental rhyme) the following method of proving that every 

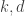


is positive semi-definite. Then you are done. Why? Because if 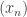



Why does this deal with the troublesome sequences? Because it is perfectly possible (and necessary, if this method is to work) for the sum of the 
Note that to prove that the quadratic form is positive semi-definite, it is sufficient to write it as a sum of squares. So EDP is reduced to an existence problem: can we find appropriate coefficients and a way of writing the resulting form as a sum of squares?
Now this idea, though very nice, would not be much use if there were absolutely no hope of finding such an identity. But there is a very clear programme for finding one, which Moses and Huy Nguyen have started. The idea is to begin by using semidefinite programming to find the optimal set of coefficients for large 
As Moses points out, if such coefficients can be found, then they automatically solve the vector-valued problem as well, since we can look at the expression

instead, and the positivity will carry over. As he also points out, if you modify our low-discrepancy multiplicative examples such as 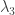

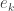
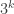

Finally, I want to draw attention to another comment of Moses, in which he introduces a further idea for getting a handle on the problem. I won’t explain in detail what the idea is because I haven’t fully digested it myself. However, it gives rise to some Taylor coefficients that take values that are all of the form 
My optimism may fade in due course, but at the time of writing it feels as though these new ideas have changed the problem from one that felt very hard into one that feels approachable.

March 2, 2010 at 9:18 pm |
[…] ideas in Polymath5 By kristalcantwell There is a new thread for Polymath5. There some new ideas involving among other things quadratic forms which seem to make […]
March 2, 2010 at 11:19 pm |
[…] Com o título sugestivo EDP — <i>a new and very promising approach</i> prossegue a […]
March 3, 2010 at 9:11 am |
I just want to review the approach suggested here and assess where we are with this line of thought. I was trying to compute an approximate Cholesky decomposition of a symmetric matrix whose entries are
whose entries are  where
where  the number of divisors of
the number of divisors of  . Getting a closed form expression for the Cholesky decomposition seems hopeless, but perhaps getting a truncated Taylor series approximation of each entry of the form
. Getting a closed form expression for the Cholesky decomposition seems hopeless, but perhaps getting a truncated Taylor series approximation of each entry of the form  is tractable. We know what these
is tractable. We know what these  are. Can we figure out expressions for
are. Can we figure out expressions for 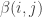 ?
?
Further down the line, I was hoping to pick small, and then consider such a matrix of size
small, and then consider such a matrix of size 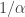 or perhaps
or perhaps  , subtract a large diagonal matrix and show that the remainder is positive semidefinite. If such a diagonal matrix could be found with sum of entries at least
, subtract a large diagonal matrix and show that the remainder is positive semidefinite. If such a diagonal matrix could be found with sum of entries at least  , this would establish a lower bound of
, this would establish a lower bound of  for EDP.
for EDP.
The hope was that the approximate Cholesky decomposition will give hints about what this diagonal matrix should look like. Intuitively, if a diagonal entry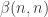 value), then this might be where a large quantity could be subtracted out in the diagonal matrix. Now we don’t quite understand the form of these
value), then this might be where a large quantity could be subtracted out in the diagonal matrix. Now we don’t quite understand the form of these 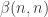 values. Tim has worked out nice expressions for prime powers and a fairly complicated expression for products of two prime powers. This suggests that getting a general expression will be quite tricky. Put that aside for a moment. If we did understood these
values. Tim has worked out nice expressions for prime powers and a fairly complicated expression for products of two prime powers. This suggests that getting a general expression will be quite tricky. Put that aside for a moment. If we did understood these 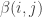 completely, are their values good enough to be useful ?
completely, are their values good enough to be useful ?
is large (because of a large
By looking at the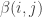 values generated by a program, it looks like the sum of diagonal values
values generated by a program, it looks like the sum of diagonal values  values for a size
values for a size
 matrix grows as
matrix grows as  . Say
. Say  .
. th diagonal term in the Cholesky decomposition is
th diagonal term in the Cholesky decomposition is  . Assume optimistically that we can subtract out
. Assume optimistically that we can subtract out from the
from the  entry. This
entry. This . This would be great of course, since our goal is for this quantity to be larger than
. This would be great of course, since our goal is for this quantity to be larger than  .
. lower bound.
lower bound.
The
a term like
would mean that the sum of diagonal entries subtracted out would be
If this works as planned, this would give a
Other than the optimistic assumption that we haven’t justified, there is another issue we need to deal with. The use of the Taylor series approximation assumes that the coefficients of are much smaller than
are much smaller than 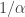 .
. matrix seems to grow like
matrix seems to grow like  (this is from looking at values output by a program. In fact the average on the diagonal is already
(this is from looking at values output by a program. In fact the average on the diagonal is already 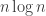 ). Recall that
). Recall that  . This means that these coefficients are too large for us to use the Taylor series approximation we used.
. This means that these coefficients are too large for us to use the Taylor series approximation we used.
But in fact the maximum of these coefficients for an
If we are going to think along these lines, we need a different way to approximate the Cholesky decomposition.
March 3, 2010 at 8:37 pm
Dear Moses, Two questions: What again is the reason that you and Huy do not include the HAP of difference 1? The second: Perhaps there will be some better insight if we exclude all HAPs of small difference <=c and see how the solution behaves as c grows. EDP suggests that we will get sqrt log n bounds for every c but maybe the pattern will become clearer if we consider large c or the behavior as c grows.
March 4, 2010 at 5:38 am
Dear Gil, We did include HAPs of difference 1. What we excluded was singleton HAPs, because they trivially give a lower bound of 1 on the discrepancy. In this case, the SDP dual solution would not have exhibited any useful structure. We haven’t thought of excluding HAPs of small common differences to see the effect on the value. It does look like the SDP dual weight placed on HAPs of difference d is a (roughly) decreasing function of d. But I don’t know how much the value will drop when we exclude those with small differences. We’ll try it out and report back.
March 3, 2010 at 9:14 am |
Moses, can I check with you that the condition for success in the Cholesky decomposition, as you describe it in this comment, should be that ? I don’t understand what you’ve written at the moment (which could be a sign that it was garbled by WordPress), but this seems to be the condition that would allow the algorithm to continue to find a decomposition with non-negative coefficients.
? I don’t understand what you’ve written at the moment (which could be a sign that it was garbled by WordPress), but this seems to be the condition that would allow the algorithm to continue to find a decomposition with non-negative coefficients.
March 3, 2010 at 3:50 pm
Yes, that is correct. Sorry that came out garbled.
March 3, 2010 at 4:16 pm
No problem, and I’ve now changed it.
March 3, 2010 at 9:52 am |
Given the formulae that Tim has worked out for , a simple guess is that
, a simple guess is that  is of the order of
is of the order of  , where
, where  is the divisors function. This plot seems to support this:
is the divisors function. This plot seems to support this:
In particular, it seems reasonable to conjecture that for all
for all  .
.
March 3, 2010 at 11:24 am |
This is a response to Moses’s comment above. First, I spent a little time rereading the comments in which you introduced the truncated-Taylor-series idea, and I now understand it rather better. (Yesterday I just saw a matrix with some patterns and became determined to work out what the patterns were, though now that they appear to have a piecewise linearity property that is likely to get ever more complicated as the number of distinct prime factors increases, my enthusiasm for that has somewhat dimmed. Nevertheless, I don’t rule out that it may be possible to work out exactly the set of linear forms in the exponents of which one should take the maximum.) I too was slightly worried about whether truncating the Taylor series was going to work in the region that truly interests us, but even if that is the case I think it should still be quite a useful thing to have done.
I am actually a little more disturbed by the presence of the maximum in the formula for the coefficient of the matrix. That, it seems to me, rules out any truly nice expression for anything else that one might wish to compute in terms of
of the matrix. That, it seems to me, rules out any truly nice expression for anything else that one might wish to compute in terms of  , and probably accounts for the piecewise linearity that was appearing yesterday (though I do not claim to have found a direct connection).
, and probably accounts for the piecewise linearity that was appearing yesterday (though I do not claim to have found a direct connection).
However, it may be that some of the ideas I was having when I was trying a Fourier approach could accidentally help to produce a matrix with a better formula. Let me briefly review what the extra idea is that seems to have some chance of achieving that (but someone else may spot some reason that this extra idea cannot give rise to a matrix that is not just given by a nice formula but is also useful).
The reason that the maximum occurs in the formula for is that each HAP has a sharp cutoff. What do I mean by that? Well, the criterion for belonging to the HAP
is that each HAP has a sharp cutoff. What do I mean by that? Well, the criterion for belonging to the HAP 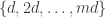 is that you should be a multiple of
is that you should be a multiple of  and you should be at most
and you should be at most 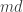 . The second condition switches off suddenly after
. The second condition switches off suddenly after 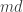 — that is the sharp cutoff. (I realize that many people reading this do not need to be told what a sharp cutoff is, but I see no harm in explaining it to people who might not otherwise know exactly what I meant.) If we now take a sum like
— that is the sharp cutoff. (I realize that many people reading this do not need to be told what a sharp cutoff is, but I see no harm in explaining it to people who might not otherwise know exactly what I meant.) If we now take a sum like  , then the coefficient of
, then the coefficient of 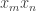 is equal to twice the sum of the
is equal to twice the sum of the  over all pairs
over all pairs  such that
such that  is a common factor of
is a common factor of  and
and  and
and  . So there seems to be no way of avoiding a dependence on
. So there seems to be no way of avoiding a dependence on  .
.
That is true if we use HAPs with sharp cutoffs. But there is another option that may be available to us. As with several ideas connected with proving EDP, this further option will not work unless a stronger version of EDP is also true, which means that there is no guarantee that it works. (This is a point that Moses made when he introduced his approach and that I forgot to make in the post above: the stronger the statements we try to prove, the more chance there is of finding counterexamples, so we probably shouldn’t give up the search for counterexamples just yet. Even a counterexample to a strengthening of EDP would have major implications for our understanding of EDP itself.)
The idea is to exploit the following simple fact (and now I am repeating things I have said before). Let be any decreasing sequence of real numbers that tends to zero, and suppose that
be any decreasing sequence of real numbers that tends to zero, and suppose that  . Let
. Let 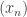 be a sequence such that
be a sequence such that  for every
for every  . Then the sum
. Then the sum  , which equals
, which equals
has modulus at most .
.
Thus, if we can find a lower bound of for
for  , then we may conclude that there exists a partial sum with modulus at least
, then we may conclude that there exists a partial sum with modulus at least  .
.
This gives us the option of considering not just a sum such as
but also smoother expressions such as
My choice of there may not be optimal — I can choose any
there may not be optimal — I can choose any  that has the right sort of decreasing behaviour in
that has the right sort of decreasing behaviour in  .
.
What is the coefficient of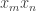 in the above expression? It is
in the above expression? It is
except when when we lose the factor 2.
when we lose the factor 2.
One possible choice for is 1. If we make that choice, then we get
is 1. If we make that choice, then we get  which equals
which equals  .
.
Unfortunately, for that choice . Another choice would be
. Another choice would be  , which sums/integrates to approximately
, which sums/integrates to approximately 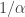 when
when  is small. Then we would get a coefficient of
is small. Then we would get a coefficient of  , where I am defining
, where I am defining  to be the sum of
to be the sum of  over all factors
over all factors  of
of  .
.
The reason this general method is not guaranteed to work is that the unboundedness of the partial sums does not imply the unboundedness of the smoothed partial sums. It may be that someone can completely kill off this idea by coming up with a counterexample to “smooth EDP”. That is, one would want a sequence
sequence 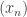 (or a sequence of unit vectors if you prefer) such that there is some absolute constant
(or a sequence of unit vectors if you prefer) such that there is some absolute constant  with
with  for every
for every  and every
and every 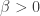 .
.
I would be very interested in such an example, as it would show that the truth of EDP would have to depend in a crucial way on the sharp cutoffs of the HAPs.
March 3, 2010 at 11:39 am |
It occurs to me that I should try out smooth EDP on the usual character-like examples. What’s more, I have a horrid feeling that it may fail for such examples, precisely because of the smoothing.
So let me try to work out the sum . It is
. It is  . We now add to that the same expression with
. We now add to that the same expression with  replaced by
replaced by  , then
, then  , and so on. The result looks pretty close in size to
, and so on. The result looks pretty close in size to  .
.
So far that is OK, since this tends to infinity as tends to 0. But I think disaster strikes if we consider
tends to 0. But I think disaster strikes if we consider  instead of
instead of 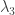 , so that now the sum we care about is the alternating sum
, so that now the sum we care about is the alternating sum  . In that case, the sum is uniformly bounded for all
. In that case, the sum is uniformly bounded for all  .
.
I’ll have to think about how much of a problem this is.
March 3, 2010 at 11:49 am
Does it, for example, imply that it is not possible to subtract from the matrix a large diagonal part while maintaining positive semi-definiteness? Indeed, does it imply something of this kind whenever
a large diagonal part while maintaining positive semi-definiteness? Indeed, does it imply something of this kind whenever  is given by a formula of the form
is given by a formula of the form
That would be quite interesting, as it would suggest that in order for Moses’s approach to work, it would be essential to deal with sharp cutoffs and the resulting slightly unpleasant expressions. (Here’s a completely speculative idea: perhaps from any such matrix one can subtract off a smooth part and be left with a matrix from which it is easier to see how to remove a large diagonal without losing positive definiteness.)
March 3, 2010 at 12:30 pm
One further small remark. The failure of “smooth EDP” fits quite well with the way that one actually proves that the partial sums of diverge. (Recall that to calculate
diverge. (Recall that to calculate  you write it as
you write it as  with
with  not a multiple of 3, and then set it to be
not a multiple of 3, and then set it to be 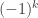 if
if  is congruent to 1 mod 3, and
is congruent to 1 mod 3, and  if
if  is congruent to 2 mod 3. This function is easily checked to be completely multiplicative.) To prove that, one decomposes the sequence up into 1,-1,0,1,-1,0, … plus 0,0,-1,0,0,1,0,0,0,0,0,-1,0,0,1,0,0,0,… and so on. The contributions to the partial sums are then 1,0,0,1,0,0,1,0,0,… plus 0,0,-1,-1,-1,0,0,0,0,0,0,-1,-1,-1,0,0,… and so on, which makes it easy to choose numbers at which the partial sum is a sum of several 1s and no -1s. But if we smooth this off, then we lose what it was that was allowing us to do this. We were depending on the fact that the sum up to
is congruent to 2 mod 3. This function is easily checked to be completely multiplicative.) To prove that, one decomposes the sequence up into 1,-1,0,1,-1,0, … plus 0,0,-1,0,0,1,0,0,0,0,0,-1,0,0,1,0,0,0,… and so on. The contributions to the partial sums are then 1,0,0,1,0,0,1,0,0,… plus 0,0,-1,-1,-1,0,0,0,0,0,0,-1,-1,-1,0,0,… and so on, which makes it easy to choose numbers at which the partial sum is a sum of several 1s and no -1s. But if we smooth this off, then we lose what it was that was allowing us to do this. We were depending on the fact that the sum up to  of the various parts of
of the various parts of  varies in a discontinuous way. By contrast, if
varies in a discontinuous way. By contrast, if 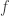 is one of those parts, then the sum
is one of those parts, then the sum  varies in a very smooth way as
varies in a very smooth way as  tends to 0.
tends to 0.
This slightly vague observation leads to a slightly vague question: what constraints does the existence of the function place on the coefficients and
and 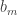 if Moses’s method is to work?
if Moses’s method is to work?
I shall try to work this out very directly. It tells us that
Let and let
and let  . Since
. Since  is multiplicative, the above formula implies that
is multiplicative, the above formula implies that  .
.
Hmm, that doesn’t seem to tell us all that much, since on average grows roughly logarithmically.
grows roughly logarithmically.
March 3, 2010 at 3:10 pm
Oops, I’ve just realized that I made a mistake. I approximated by
by  because I was accidentally thinking of
because I was accidentally thinking of  as being very small. However, the mistake turns out not to make much difference, since when
as being very small. However, the mistake turns out not to make much difference, since when  is small we get roughly
is small we get roughly  . I haven’t checked 100%, but I’m pretty sure that the sum is still uniformly bounded.
. I haven’t checked 100%, but I’m pretty sure that the sum is still uniformly bounded.
March 3, 2010 at 1:07 pm |
Here’s a small observation. Suppose we look at the complex case. I think we can do slightly better than if we are trying to find the lowest possible discrepancy. The idea is to define a completely multiplicative function by letting
if we are trying to find the lowest possible discrepancy. The idea is to define a completely multiplicative function by letting  if
if  is congruent to 1 mod 3,
is congruent to 1 mod 3,  if
if  is congruent to 2 mod 3, and
is congruent to 2 mod 3, and  , where
, where  . The point about choosing the golden ratio is to make the multiples of
. The point about choosing the golden ratio is to make the multiples of  as equidistributed as possible mod 1, or equivalently to make the powers of
as equidistributed as possible mod 1, or equivalently to make the powers of  as equidistributed as possible round the circle.
as equidistributed as possible round the circle.
When we break up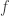 in the usual way according to which is the largest power of 3 that divides
in the usual way according to which is the largest power of 3 that divides  , we find that for each
, we find that for each  we have a set of partial sums that either equals
we have a set of partial sums that either equals  or
or  . So to make these partial sums reinforce each other, we need to choose a bunch of
. So to make these partial sums reinforce each other, we need to choose a bunch of  s such that the corresponding
s such that the corresponding  s are pointing in roughly the same direction. If we choose
s are pointing in roughly the same direction. If we choose  , this is easy to do: we just choose alternate
, this is easy to do: we just choose alternate  s (this is the function
s (this is the function  ). But for a badly approximable irrational, things are harder. I haven’t worked out what the best thing to do is, but I think it is probably this. We choose an angle
). But for a badly approximable irrational, things are harder. I haven’t worked out what the best thing to do is, but I think it is probably this. We choose an angle  , and we pick an integer
, and we pick an integer  , where
, where  is the set of all
is the set of all  such that
such that  lies on the arc that goes from
lies on the arc that goes from  to
to 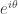 . Assuming that the multiples of
. Assuming that the multiples of  are perfectly equidistributed (this is a heuristic argument from now on) the density of
are perfectly equidistributed (this is a heuristic argument from now on) the density of  is
is  , and
, and  . That means that
. That means that 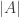 is roughly
is roughly  and the sum is therefore roughly
and the sum is therefore roughly  . Thus, the best one can do is to take
. Thus, the best one can do is to take  , which gives a bound of
, which gives a bound of  . Here, logs were to base 3.
. Here, logs were to base 3.
I find this quite interesting because it just might provide an explanation for the seeming appearance of golden ratios in the 1124 examples. I note that is fairly close to 1. Is there some way of making a
is fairly close to 1. Is there some way of making a  sequence out of this complex example at a cost to the discrepancy of a factor of 2 or so?
sequence out of this complex example at a cost to the discrepancy of a factor of 2 or so?
March 3, 2010 at 1:23 pm
Incidentally, if one moves to the unit-vectors case, then up to a constant one can’t do better than the that Moses has already observed. To see this, let’s suppose that we set
that Moses has already observed. To see this, let’s suppose that we set  for some unit vector
for some unit vector 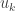 and then define
and then define  to be the usual multiple of
to be the usual multiple of  . We find ourselves wanting to choose
. We find ourselves wanting to choose  in such a way that no sum
in such a way that no sum  has large norm. (Here,
has large norm. (Here,  .)
.)
However, we know that if is a random choice of signs, then the expectation of
is a random choice of signs, then the expectation of  is exactly
is exactly  . This proves that there exists a choice of signs such that
. This proves that there exists a choice of signs such that  . From the triangle inequality it follows that either
. From the triangle inequality it follows that either  or when you add it to the random
or when you add it to the random  combination you get a vector with norm at least
combination you get a vector with norm at least  . In the latter case you find a set
. In the latter case you find a set  such that the norm of
such that the norm of  is at least
is at least  , so in this case you also have a sum of the unit vectors of size at least
, so in this case you also have a sum of the unit vectors of size at least  .
.
March 4, 2010 at 6:34 am
That’s interesting. I have been wondering whether it is possible to devise clever constructions of low discrepancy vector sequences that use sequences for other primes say and combines them in an ingenious way. A couple of remarks:
1. Arguing about complex numbers and reasoning about angles plays a role in the proof of Roth’s theorem on discrepancy of APs.
2. It would interesting to show some connection between vector discrepancy and the discrepancy of sequences. For example, is it possible that the vector discrepancy over HAPs is bounded by a constant, but the
sequences. For example, is it possible that the vector discrepancy over HAPs is bounded by a constant, but the  discrepancy is
discrepancy is  ?
?
Possibly relevant to this is a recent paper that uses semidefinite programming to efficiently construct low discrepancy sequences for various set systems. He gets a constructive version of Spencer’s result of
sequences for various set systems. He gets a constructive version of Spencer’s result of  discrepancy for an arbitrary system of $n$ sets on a universe of $n$ elements, improving on the
discrepancy for an arbitrary system of $n$ sets on a universe of $n$ elements, improving on the  achieved by random sequences. The technique in this paper is applicable to situations where the discrepancy remains bounded for the set system restricted to an arbitrary subset of the elements.
achieved by random sequences. The technique in this paper is applicable to situations where the discrepancy remains bounded for the set system restricted to an arbitrary subset of the elements.
March 3, 2010 at 2:04 pm |
In retrospect, it should have been obvious to think of using SDPs. In Lovasz’s survey on SDPs (http://www.cs.elte.hu/~lovasz/semidef.ps), Section 5.2, he uses an SDP argument to give a 1-page proof of Roth’s 1964 theorem. Interestingly his argument is a primal-only argument; he does not look at the dual.
March 3, 2010 at 2:36 pm
Many thanks for that reference — it should be very useful.
March 3, 2010 at 2:46 pm
I might also add that Terry brought up the concept of semidefinite programming right back in this comment, but at the time we didn’t see its full potential (or at least I didn’t).
March 3, 2010 at 4:36 pm |
I’ve just done a little experiment, which I found quite interesting, though I don’t have a completely clear programme for what to do with it.
I am trying to pursue Moses’s idea of using the Cholesky decomposition to help us guess which diagonal entries we can reduce while maintaining positive semidefiniteness. I thought it would be quite interesting to take the matrix (where
(where 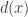 is the number of divisors of
is the number of divisors of  ), which, as Moses observed, can be split up as
), which, as Moses observed, can be split up as 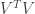 , where
, where  if
if  and 0 otherwise, subtract an infinitesimal amount from the diagonal, and apply the Cholesky decomposition algorithm to the perturbed matrix. (This is similar in spirit to Moses’s Taylor-expansion idea but computationally I think it is slightly easier.)
and 0 otherwise, subtract an infinitesimal amount from the diagonal, and apply the Cholesky decomposition algorithm to the perturbed matrix. (This is similar in spirit to Moses’s Taylor-expansion idea but computationally I think it is slightly easier.)
As a first attempt to get some understanding of what was going on, I decided to subtract an infinitesimal from
from  and leave the rest of the diagonal alone. The result was to replace
and leave the rest of the diagonal alone. The result was to replace  by
by  , where the first few rows of
, where the first few rows of  look like this.
look like this.
-1/2, 1/2, 1/2, 1/2, 1/2, 1/2, …
0, -1/2, -1, -1/2, -1, -1/2, …
0, 0, -1/2, 0, -1, 1/2, …
0, 0, 0, 0, 0, 0, …
0, 0, 0, 0, -1/2, 1, …
0, 0, 0, 0, 0, -1/2, …
I was a little sad when turned out to be -1/2 because up to then the diagonal entries had magically agreed with the diagonal entries of the matrix that Moses calculated earlier. However, there was no reason for the two matrices to be the same.
turned out to be -1/2 because up to then the diagonal entries had magically agreed with the diagonal entries of the matrix that Moses calculated earlier. However, there was no reason for the two matrices to be the same.
I’d be quite interested to know more of this matrix. In particular, if the diagonal entries appear to be bounded below then it would be quite encouraging.
Note that if one subtracts an infinitesimal amount from the diagonal and ignore all quadratic and higher-order terms, then the corrections to the matrix for each diagonal element are independent of each other. In other words, we can study each diagonal entry separately. What I would hope to see is that when has many factors the effect of replacing
has many factors the effect of replacing  by
by  is not too drastic. It would also be interesting if the converse were true as well. In fact, what I’d really like to see is something like this. You subtract
is not too drastic. It would also be interesting if the converse were true as well. In fact, what I’d really like to see is something like this. You subtract  from
from  and obtain a matrix
and obtain a matrix  . The diagonal terms of
. The diagonal terms of  are bounded below by some function
are bounded below by some function  (which is negative). The bound gets worse as
(which is negative). The bound gets worse as  gets larger, but it is not so bad for
gets larger, but it is not so bad for  with many factors. As a result, we can choose a reasonably large diagonal matrix
with many factors. As a result, we can choose a reasonably large diagonal matrix  (with non-negative entries
(with non-negative entries  that sum to infinity) such that there is a uniform lower bound on the diagonal entries of
that sum to infinity) such that there is a uniform lower bound on the diagonal entries of  .
.
March 4, 2010 at 7:05 am
Tim, one comment is that your matrix corresponds to the quadratic form

By setting for
for  and
and 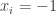 for
for  , the value of this expression is at most
, the value of this expression is at most  . So we cannot subtract more than a sum total of
. So we cannot subtract more than a sum total of  from the diagonal.
from the diagonal.
Another (actually simpler) way to say the same thing is that the diagonal entries of the Cholesky decomposition are all 1, so clearly we will not be able to subtract more than from the diagonal. Is this a problem for what you were thinking about ?
from the diagonal. Is this a problem for what you were thinking about ?
March 4, 2010 at 10:20 am
Moses, I’m struggling to understand the last remark of yours. In particular, which matrix are you referring to when you write “your matrix”? The fact that you have a free variable in your definition suggests that you are talking about
in your definition suggests that you are talking about  , or a quadratic form related to
, or a quadratic form related to  , but from the rest of what you write I am not so sure.
, but from the rest of what you write I am not so sure.
However, to answer your last question, I was wanting to take the case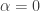 of the matrix you defined in this comment and to try to understand, purely formally (that is, without thinking about bounds on sums of coefficients etc.) what happens to the Cholesky decomposition if you subtract a tiny amount from the diagonal. My reason for doing that was not that I expected a proof of EDP to be a direct result, but just that I hoped that the calculations would be easy and would throw up patterns that would enable one to make intelligent guesses about the sequence
of the matrix you defined in this comment and to try to understand, purely formally (that is, without thinking about bounds on sums of coefficients etc.) what happens to the Cholesky decomposition if you subtract a tiny amount from the diagonal. My reason for doing that was not that I expected a proof of EDP to be a direct result, but just that I hoped that the calculations would be easy and would throw up patterns that would enable one to make intelligent guesses about the sequence 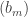 .
.
But perhaps your point is that the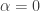 case is not informative because it corresponds to putting a weight of 1 on all “full” HAPs (that is, ones that go right up to
case is not informative because it corresponds to putting a weight of 1 on all “full” HAPs (that is, ones that go right up to  ) and 0 on the rest, and we can easily construct examples of bounded discrepancy sequences in this case: just have the first half of the terms equal to 1 and the second half equal to -1. (This point came up recently actually in a question that Sune asked.)
) and 0 on the rest, and we can easily construct examples of bounded discrepancy sequences in this case: just have the first half of the terms equal to 1 and the second half equal to -1. (This point came up recently actually in a question that Sune asked.)
I have to say that I don’t know whether one can hope to find anything interesting out about EDP by messing about with matrices that are provably not useful for the problem. But I think I’ll try one or two other things for a bit!
March 4, 2010 at 12:37 pm
Instead of trying some other guess, I have had a go at seeing what I can say in general about subtracting an infinitesimal amount from the diagonal of a matrix. Recall that once we have chosen our coefficients we end up with a quadratic form, we take the matrix of that form, and we try to subtract as much as we can from the diagonal while keeping it positive semidefinite. My hope is that we can get some idea of what to subtract if we linearize the problem by subtracting an infinitesimal amount from the diagonal. What I hope this shows is that some diagonal entries (ones corresponding to integers with few factors) are “expensive”, in the sense that they have a big effect on the diagonal entries in the Cholesky decomposition, whereas others are “cheap”. This, I hope, will give a clue about what we should subtract if we are subtracting a non-infinitesimal amount. (For example, perhaps one could repeat the infinitesimal process infinitely many times and end up with expressions involving exponentials.)
we end up with a quadratic form, we take the matrix of that form, and we try to subtract as much as we can from the diagonal while keeping it positive semidefinite. My hope is that we can get some idea of what to subtract if we linearize the problem by subtracting an infinitesimal amount from the diagonal. What I hope this shows is that some diagonal entries (ones corresponding to integers with few factors) are “expensive”, in the sense that they have a big effect on the diagonal entries in the Cholesky decomposition, whereas others are “cheap”. This, I hope, will give a clue about what we should subtract if we are subtracting a non-infinitesimal amount. (For example, perhaps one could repeat the infinitesimal process infinitely many times and end up with expressions involving exponentials.)
Suppose, then, that is the matrix of the quadratic form, and that
is the matrix of the quadratic form, and that  is an upper triangular matrix such that
is an upper triangular matrix such that  . The upper triangular property says that if
. The upper triangular property says that if  then we must have
then we must have  . Now let
. Now let  be a diagonal matrix with entries
be a diagonal matrix with entries 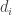 , and let
, and let  be an infinitesimally small constant. We would like to find an upper triangular matrix
be an infinitesimally small constant. We would like to find an upper triangular matrix  such that
such that 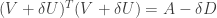 . Then
. Then  will be the Cholesky decomposition of the perturbed matrix
will be the Cholesky decomposition of the perturbed matrix  . Since
. Since  is infinitesimal, this works out as
is infinitesimal, this works out as  .
.
Now let the columns of be
be  and the columns of
and the columns of  be
be  . The upper triangular property tells us that
. The upper triangular property tells us that  and
and  are vectors whose coordinates are zero after the ith coordinate.
are vectors whose coordinates are zero after the ith coordinate.
The ijth entry of is just the scalar product
is just the scalar product  , so the equations that these column vectors must satisfy are that
, so the equations that these column vectors must satisfy are that  whenever
whenever  and
and  for every i.
for every i.
This makes it easy to solve for (at least algorithmically, though whether one can get a closed-form expression for the solution in any case worth solving is open to question). If we have worked out
(at least algorithmically, though whether one can get a closed-form expression for the solution in any case worth solving is open to question). If we have worked out  , we let
, we let 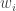 be the column vector that is the same as
be the column vector that is the same as  except that
except that  . Then
. Then 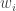 is fully determined by the equations
is fully determined by the equations  for
for  . We now need to work out
. We now need to work out  , which is determined by the equation
, which is determined by the equation  .
.
We are hoping that with a judicious choice of the
the  will not get too large and negative. However, I don’t think there is much one can say about that question unless one chooses a specific matrix
will not get too large and negative. However, I don’t think there is much one can say about that question unless one chooses a specific matrix  to work with.
to work with.
Once one is actually doing calculations, it will be easiest to choose to have just one non-zero entry equal to 1. One can then take linear combinations.
to have just one non-zero entry equal to 1. One can then take linear combinations.
March 4, 2010 at 12:48 pm
Sorry, I should have been more precise. As you correctly inferred, I meant that corresponds to the quadratic form
corresponds to the quadratic form  .
.
There is something peculiar about the case that causes the diagonal entries in the Cholesky decomposition to shoot up. But you are right that we are so far from understanding this at this point – we’ve got to get started somewhere and the
case that causes the diagonal entries in the Cholesky decomposition to shoot up. But you are right that we are so far from understanding this at this point – we’ve got to get started somewhere and the 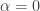 case is a good starting point.
case is a good starting point.
March 3, 2010 at 8:20 pm |
Some necessary conditions on the coefficients in Moses approach (necessary if we want a proof of EDP):
in Moses approach (necessary if we want a proof of EDP):
If we have a sequence with that take values {1,-1} (or more generally: unit vectors) for all
Are these conditions sufficient? And do you think it would make sense to try to find the coefficients using only these two “axioms”? (I’m not up to date with everything here, so you might be working on approaches that are strictly smarter).
March 3, 2010 at 11:52 pm |
I just wanted to point out that there is a fairly simple set of vectors whose dot products exactly equal the matrix of the quadratic form when we choose the tails
vectors whose dot products exactly equal the matrix of the quadratic form when we choose the tails  . Vector
. Vector  is a concatenation of
is a concatenation of  . If
. If  , then
, then  . If
. If  ,
,  , where
, where  is a vector whose
is a vector whose  th coordinate is 1 if
th coordinate is 1 if  and 0 otherwise. Lastly
and 0 otherwise. Lastly  .
. .
. dimensions. However, maybe we can gain some intuition by working on these vectors for now while still trying to understand the Cholesky decomposition.
dimensions. However, maybe we can gain some intuition by working on these vectors for now while still trying to understand the Cholesky decomposition.
It is easy to check that
The unfortunate thing about these vectors is that they are in
March 4, 2010 at 8:01 am
Huy’s expression actually applies to the quadratic form obtained from any choice of and can be interpreted as follows: Write out a matrix with one row for each HAP. The row vector for the HAP d,2d,..,kd is
and can be interpreted as follows: Write out a matrix with one row for each HAP. The row vector for the HAP d,2d,..,kd is  times the incidence vector for the HAP. Now the columns of this matrix are the required vectors
times the incidence vector for the HAP. Now the columns of this matrix are the required vectors  .
.
This gives a way to understand what the entries of the diagonal of the Cholesky decomposition are. The th diagonal entry is the magnitude of the component of
th diagonal entry is the magnitude of the component of  orthogonal to the space spanned by
orthogonal to the space spanned by  . Is this something we can get a handle on ?
. Is this something we can get a handle on ?
March 4, 2010 at 4:57 pm |
I don’t know how much it will help, or what the arguments are in favour of choosing , but it may be of some use to consider coefficients that ought to be the other natural choice, namely
, but it may be of some use to consider coefficients that ought to be the other natural choice, namely  for some small positive
for some small positive  . In this case,
. In this case,  , which is roughly equal to
, which is roughly equal to  . Also,
. Also,  is, by roughly the same calculation, about
is, by roughly the same calculation, about  . (One thing I like about this choice is that it splits as a product
. (One thing I like about this choice is that it splits as a product  , which makes a lot of calculations pretty clean.)
, which makes a lot of calculations pretty clean.)
The coefficient of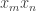 in the quadratic form
in the quadratic form
is, as ever, , which equals
, which equals  If we approximate the latter sum by
If we approximate the latter sum by  , then this simplifies to
, then this simplifies to  , which we can also write as
, which we can also write as  . But
. But  is a well known arithmetical function
is a well known arithmetical function  with many nice properties. (See this Wikipedia article for more details.) For example, it is multiplicative, though not completely multiplicative. So we end up with the nice expression
with many nice properties. (See this Wikipedia article for more details.) For example, it is multiplicative, though not completely multiplicative. So we end up with the nice expression  . That’s not quite right — if
. That’s not quite right — if  it needs to be doubled. But it gives the matrix entry
it needs to be doubled. But it gives the matrix entry  for the matrix of the quadratic form.
for the matrix of the quadratic form.
March 4, 2010 at 6:07 pm
After doing the above, I went to have a look at some of Moses’s data to see whether the best possible matrices for the dual problem exhibit the kind of behaviour that is coming out of the above calculations. In retrospect I realize that the answer was doomed to be no, because I now remember that Moses chose the exponential decay of the coefficients precisely because that is what was coming out of the experiments.
precisely because that is what was coming out of the experiments.
Anyhow, it seems that the matrix elements are more closely connected with (the number of divisors of
(the number of divisors of  than they are with
than they are with  .
.
I’ve just done another calculation and it’s left me a bit puzzled. Actually, perhaps it’s OK. The coefficient should equal
should equal  , and the experimental evidence suggests that this is equal to
, and the experimental evidence suggests that this is equal to  . At least for small
. At least for small  , given that
, given that  is small, this should be roughly
is small, this should be roughly  . If this is to be roughly proportional to the number of factors of
. If this is to be roughly proportional to the number of factors of  then
then  should be roughly constant. But this doesn’t seem to be the case.
should be roughly constant. But this doesn’t seem to be the case.
Actually, that isn’t such a problem, because we don’t get a matrix that’s proportional to . From the data, this is particularly noticeable in the fifth row, which has a bump at every fifth column, but up to more like 8/5 of the underlying level. This suggests that
. From the data, this is particularly noticeable in the fifth row, which has a bump at every fifth column, but up to more like 8/5 of the underlying level. This suggests that 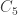 is more like 3/5 times
is more like 3/5 times  . The square of 5/3 is 25/9, which is not far from e, suggesting that the log of the ratio of
. The square of 5/3 is 25/9, which is not far from e, suggesting that the log of the ratio of  to
to 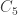 should be around 1/2. And that seems to be borne out by this diagram of Huy’s, as do various other facts that one can spot when looking at the matrix.
should be around 1/2. And that seems to be borne out by this diagram of Huy’s, as do various other facts that one can spot when looking at the matrix.
The ratio corresponding to 7 appears to be about 4/3, so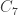 seems to be more like 1/3. Let me have a look at a few more of these at prime values, to see if a pattern for the
seems to be more like 1/3. Let me have a look at a few more of these at prime values, to see if a pattern for the  emerges. At 11 I get a ratio that’s pretty close to 8/7, so
emerges. At 11 I get a ratio that’s pretty close to 8/7, so  is fairly close to 1/7. At 13 I get something that doesn’t look close to a rational with small denominator, so I’ve hit a brick wall. But at least it is smaller than the ratio that I got for 11.
is fairly close to 1/7. At 13 I get something that doesn’t look close to a rational with small denominator, so I’ve hit a brick wall. But at least it is smaller than the ratio that I got for 11.
However, I do get the distinct impression that the coefficients are approximately multiplicative — no time to check this. But the reason I’m interested is that it looks as though it should be possible to say roughly what the coefficients
are approximately multiplicative — no time to check this. But the reason I’m interested is that it looks as though it should be possible to say roughly what the coefficients  are, and if we can do that then we have a conjectured good matrix.
are, and if we can do that then we have a conjectured good matrix.
Just to reiterate what I’m doing, in case anyone feels ready to get a computer to do the calculations quickly and easily, I’m guessing the coefficients by assuming that the matrix is given by a formula
by assuming that the matrix is given by a formula  times something that decays slowly along each row. This makes it easy to guess
times something that decays slowly along each row. This makes it easy to guess  . For example, if I look at the fifth row, then
. For example, if I look at the fifth row, then 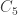 should be approximately equal to
should be approximately equal to  (if I normalize by setting
(if I normalize by setting  ).
).
The dream scenario would be that turns out to be a power of
turns out to be a power of  . I’d be interested to see how close this dream is to reality by seeing a plot of log of
. I’d be interested to see how close this dream is to reality by seeing a plot of log of  against
against  .
.
March 4, 2010 at 6:18 pm
Moses, I’ve just had a look at the b values that you obtained and they are distressingly lacking in any obvious pattern. For example is almost 100000 times bigger than
is almost 100000 times bigger than  . This makes no sense to me whatsoever. Is it perhaps an ugly “edge effect” that comes from looking at small progressions?
. This makes no sense to me whatsoever. Is it perhaps an ugly “edge effect” that comes from looking at small progressions?
It seems to me that to make any more progress by staring at the data it will be necessary to modify the SDP in some way so as to make the data nicer.
Other things that don’t make sense: the value at 12 is very big, but the values at 1,2,3,4 and 6 are all tiny. The values at 2, 4, 7 and 49 are all tiny but the values at 8 and 14 are big. Etc. etc.
March 4, 2010 at 8:23 pm
I’m now at home and have an even more fundamental problem with staring at the data, which is that Princeton won’t let me look at it. (When I was on my work computer it somehow recognised that I didn’t have some malicious reason for wanting to look at 512-by-512 matrices.)
March 4, 2010 at 8:42 pm
I had that problem briefly but it seems OK now. I’ve put Moses’ tables of on the wiki: here.
on the wiki: here.
March 4, 2010 at 9:03 pm
Great, thanks. A first thing to try to work out might be which values of are the ones for which
are the ones for which  is absolutely tiny, and which are the values for which it is reasonably substantial. That seems to be reasonably independent of the size of the matrix. By “work out” I mean of course that one should try to find some simple rule that says which values are small.
is absolutely tiny, and which are the values for which it is reasonably substantial. That seems to be reasonably independent of the size of the matrix. By “work out” I mean of course that one should try to find some simple rule that says which values are small.
March 4, 2010 at 9:30 pm
The with
with  (to within the accuracy of the data) for the 1500 matrix are: 1, 2, 3, 263, 367, 479, 727, 907, 1181, 1277, 1282, 1303, 1429, 1447, 1487.
(to within the accuracy of the data) for the 1500 matrix are: 1, 2, 3, 263, 367, 479, 727, 907, 1181, 1277, 1282, 1303, 1429, 1447, 1487.
Most of these are prime, the exceptions being 1 (fair enough) and 1282. Not much to go on there. Of the 274 with
with  , 174 are prime, and as you've noted they include some quite smooth numbers, like 18 and 49.
, 174 are prime, and as you've noted they include some quite smooth numbers, like 18 and 49.
There is some hint of regularity when one looks at geometric progressions. For example, this plot shows …
…
March 4, 2010 at 9:52 pm
Curiously, in light of Sune’s observation that , the largest value is at a factorial (
, the largest value is at a factorial ( ). (I’m still focusing on the 1500 sequence). The
). (I’m still focusing on the 1500 sequence). The  with
with  are: 108, 120, 180, 216, 240, 252, 270, 288, 360, 420, 432, 480, 504, 540, 630, 648, 720, 756, 810, 840, 864, 900, 1008, 1080. These are all very smooth.
are: 108, 120, 180, 216, 240, 252, 270, 288, 360, 420, 432, 480, 504, 540, 630, 648, 720, 756, 810, 840, 864, 900, 1008, 1080. These are all very smooth.
March 4, 2010 at 10:36 pm
This seems to be a sign that the sequence depends a lot on N (that is the largest number we consider): Smooth number “just below” N (on a log scale) take high values. So perhaps it is important to remember that we don’t have to find a sequence
sequence depends a lot on N (that is the largest number we consider): Smooth number “just below” N (on a log scale) take high values. So perhaps it is important to remember that we don’t have to find a sequence  with infinite sum, but only with arbitrary large sum.
with infinite sum, but only with arbitrary large sum. a sequence over the rational numbers in
a sequence over the rational numbers in  , and now we want the sum to be infinite?
, and now we want the sum to be infinite?
Perhaps one way of doing this would be to make
March 5, 2010 at 12:23 am
I don’t know why you are having trouble with accessing the files. I’ll make a copy and link them off of my Princeton CS web page as well.
About reading patterns in the values … I have a feeling that the large values are more reliable than the small ones. There are all sorts of reasons why the small values might be misleading: roundoff errors, the fact that we truncated the size of the problem at 512, 1025, 1500, etc (the latter is probably more significant than the former). Huy mentioned that in general the patterns in the data seem to be become more robust for larger values of
values … I have a feeling that the large values are more reliable than the small ones. There are all sorts of reasons why the small values might be misleading: roundoff errors, the fact that we truncated the size of the problem at 512, 1025, 1500, etc (the latter is probably more significant than the former). Huy mentioned that in general the patterns in the data seem to be become more robust for larger values of  . Unfortunately, solving the 1500 size SDP took about a day. 1024 took an hour or two I think. So it is unlikely we will be able to get data for much larger
. Unfortunately, solving the 1500 size SDP took about a day. 1024 took an hour or two I think. So it is unlikely we will be able to get data for much larger  . (The solver was running on my mac mini – admittedly not the most powerful computing platform available, but one I had complete control over).
. (The solver was running on my mac mini – admittedly not the most powerful computing platform available, but one I had complete control over).
In looking through the data earlier, I’ve always sorted the values and tried to spot patterns in the large values – that seems to be a useful way to look at the data. I’d be quite happy to understand the largest that contain half the total mass, say. As Sune and Alec point out, large values seem to occur at large smooth
that contain half the total mass, say. As Sune and Alec point out, large values seem to occur at large smooth  . I have a very hand-wavy heuristic explanation for this from thinking about the
. I have a very hand-wavy heuristic explanation for this from thinking about the 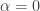 matrix that Tim was looking at earlier and the Taylor coefficients on the diagonal we’ve observed for the small
matrix that Tim was looking at earlier and the Taylor coefficients on the diagonal we’ve observed for the small  case before. I’ll try to put down my thoughts in a later comment.
case before. I’ll try to put down my thoughts in a later comment.
March 5, 2010 at 1:19 am
I agree with Tim that it would be a good idea to modify the SDP to make the data “nicer”. If we have a guess of what setting of is good/reasonable/fits the data, then we can plug this into the SDP and it will return the optimal values of
is good/reasonable/fits the data, then we can plug this into the SDP and it will return the optimal values of  for this particular choice of
for this particular choice of  . Perhaps this will produce better values for
. Perhaps this will produce better values for  ?
?
March 5, 2010 at 3:18 am
I think I know what was causing the file access problems. To access the dual solutions I put up, you needed to use this link:
https://webspace.princeton.edu/xythoswfs/webui/_xy-2045882_1-t_TWwKmqrU
This contains a password that gives you access to the directory. After your browser displays this page, the URL it displays in the address bar is different. If instead you copy this new URL into a new browser window, it takes you to the Princeton webspace login page.
I’ve changed the access permissions, so you can now access the directory by simply following this link:
https://webspace.princeton.edu/users/moses/EDP/
Should have done this in the first place.
March 5, 2010 at 9:05 am
Moses, what kind of machine can your solver be used on? If it runs on linux, and can be run by someone not too familiar with it, I can provide some larger machines and try to push it a few steps further.
Are there any good parallel SDP-solvers?
March 5, 2010 at 9:30 am
Sure, it would be nice to have access to larger solutions. I used some publicly available solvers. The code is available and you can install them on linux. I had to install LAPACK and BLAS to compile. It’s easy to run them even if you know nothing about SDPs. I have code that produces the input file, you invoke the solver from the command line, and it outputs the solution to a file.
The solvers I used are available here:
http://www.mcs.anl.gov/hs/software/DSDP/
https://projects.coin-or.org/Csdp/
DSDP seemed to perform slightly better than CSDP for these instances.
There are some implementations of parallel SDP solvers, but I don’t have experience with them (and I imagine it would take more effort to get them up and running):
http://sdpa.indsys.chuo-u.ac.jp/sdpa/software.html#sdpara
March 5, 2010 at 9:38 am
Klas, my reply to you is stuck in the moderation queue presumably because there were too many URLs in it. So let me repeat sans URLs:
Sure, it would be nice to have access to larger solutions. I used some publicly available solvers. The code is available and you can install them on linux. I had to install LAPACK and BLAS to compile. It’s easy to run them even if you know nothing about SDPs. I have code that produces the input file, you invoke the solver from the command line, and it outputs the solution to a file.
The solvers I used were DSDP and CSDP (you can find them easily).
DSDP seemed to perform slightly better than CSDP for these instances.
There are some implementations of parallel SDP solvers, but I don’t have experience with them (and I imagine it would take more effort to get them up and running). One such solver I found was SDPARA.
March 5, 2010 at 10:53 am
Moses, Ok I’ll look into it, I have a busy day today so it might hae to wait until the weekend. What is mainly limiting your runs now, memory or time?
It seems that DSDP just needs to link to scalapack in order to become a parallel solver as well.
March 5, 2010 at 11:03 am
Time is the bottleneck, but the memory requirement is also going to be prohibitively large for larger n. The 1500 size problem used up 2G of memory I think and it rises quadratically in the problem size.
March 5, 2010 at 11:27 am
Moses, could you send me, or put one the web, the code for producing the input files?
March 5, 2010 at 12:01 pm
Sure, the code is here:
https://webspace.princeton.edu/users/moses/EDP/disc4.c
It takes the problem size as an argument and produces the SDP formulation in SDPA format – all solvers are able to read this.
March 6, 2010 at 9:57 am
Moses, I’ll try to compile the parallel version of DSDP this afternoon. Which of the output options would you want in order to compare with what you have already done. The solution and dual seem obvious to output, but is there anything else that will be useful?
March 6, 2010 at 8:11 pm
Klas, I’ve been using the default output. I use this:
dsdp5 input-file -save output-file
If you want the code to print out reassuring messages that progress is being made, use something like this:
dsdp5 input-file -save output-file -print 1 -dloginfo 10
We have code to parse the output.
Most likely, we will want to solve other kinds of SDP formulations soon (TBD), but it would be good to know how large an instance we can hope to solve in reasonable time with the older SDP formulation.
March 4, 2010 at 7:45 pm |
As Moses commented ealier, we must have (to be precise: Moses only wrote explicitly that it was finite, but his argument shows that it is less than 1). The only thing we needed in this argument is that
(to be precise: Moses only wrote explicitly that it was finite, but his argument shows that it is less than 1). The only thing we needed in this argument is that 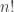 divides
divides  , so more generally: If
, so more generally: If  is a sequence such that
is a sequence such that  then
then  . At the same time we know that for any k, we can find a bounded discrepancy sequence that is 0 on multiples of k and takes the value 1 or-1 for all other terms. This implies that for any k,
. At the same time we know that for any k, we can find a bounded discrepancy sequence that is 0 on multiples of k and takes the value 1 or-1 for all other terms. This implies that for any k,  . These two conditions, together with
. These two conditions, together with  are pretty strong, and it took me some time to find an example, but they exist. E.g:
are pretty strong, and it took me some time to find an example, but they exist. E.g:  for positive n,k, and
for positive n,k, and  for all other n. Here
for all other n. Here  is the product of the first n primes.
is the product of the first n primes.
March 5, 2010 at 6:57 am
Here is another such sequence: Define ,
,  . Now let
. Now let  if
if  for some
for some  , else
, else  . This satisfies the condition, but I don’t think this is a good setting of
. This satisfies the condition, but I don’t think this is a good setting of  values however. Our choice of
values however. Our choice of  ensures that at most one element of the sequence belongs to any HAP. Now consider a sequence with value 1 at positions
ensures that at most one element of the sequence belongs to any HAP. Now consider a sequence with value 1 at positions  and 0 elsewhere. The discrepancy of such a sequence is 1. Hence
and 0 elsewhere. The discrepancy of such a sequence is 1. Hence  .
.
March 5, 2010 at 9:09 am
That sequence doesn’t satisfy .
.
March 5, 2010 at 9:35 am
You’re right. I forgot about that condition.
March 5, 2010 at 5:43 pm
If is a non-negative sequence that satisfy these two condition (
is a non-negative sequence that satisfy these two condition ( and for all increasing sequences
and for all increasing sequences  where
where  :
:  is finite) then
is finite) then  : Assume for contradiction that this is not the case. Then there is a c >0 such that infinitely many terms in b is >c. Pick an integer
: Assume for contradiction that this is not the case. Then there is a c >0 such that infinitely many terms in b is >c. Pick an integer  such that
such that  . If possible, pick a larger
. If possible, pick a larger 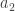 such that
such that  and
and  and so on. If we can continue this way, we get a sequence
and so on. If we can continue this way, we get a sequence  such that
such that  and
and  , contradicting the second condition. If we can’t continue this, there is a
, contradicting the second condition. If we can’t continue this, there is a  , such that
, such that  for all other n with
for all other n with  . Since this is the case for infinitely many n’s, we have
. Since this is the case for infinitely many n’s, we have  contradicting the first condition.
contradicting the first condition.
When we look at the experimental data, it doesn’t look like b tends to 0: is very small, and
is very small, and  i large. Again, I think this suggests that we shouldn’t try to make the sum of the b-values infinite, but only arbitrary large. Another way of looking at the problem, would be to work over the positive rational: If we divide though by 720 in the data we have,
i large. Again, I think this suggests that we shouldn’t try to make the sum of the b-values infinite, but only arbitrary large. Another way of looking at the problem, would be to work over the positive rational: If we divide though by 720 in the data we have,  becomes
becomes  and the old
and the old  becomes
becomes  .
.
March 5, 2010 at 9:20 am |
Do we have a plot of the b-values for N=512, 1024 and 1500 so we can compare? values.
values.
Here is one experiment I think could be interesting: Find the sequence of b-values for N=719 and N=720. I think that the largest factorial less than N take a large value, so my guess is that there might a somewhat large difference between the two
March 5, 2010 at 9:24 pm
Here is a crude attempt to compare the three b-vectors visually. The plot shows, superimposed, against
against  for all
for all  , for
, for  in red, blue and green respectively:
in red, blue and green respectively:
March 5, 2010 at 9:47 am |
Moses, what would happen if we looked at zero-based HAPs instead? In other words, at the quadratic form:
Then there is only one ‘singleton’, . (I must admit I don’t fully understand why including the singleton HAPs is a problem — after all, HAPs of any odd length give a trivial lower bound of 1 on the discrepancy.)
. (I must admit I don’t fully understand why including the singleton HAPs is a problem — after all, HAPs of any odd length give a trivial lower bound of 1 on the discrepancy.)
March 5, 2010 at 10:11 am
For the values of we have been able to solve the SDP, the optimum value does not exceed 1 if we exclude singletons. If we included singletons, the value would jump to
we have been able to solve the SDP, the optimum value does not exceed 1 if we exclude singletons. If we included singletons, the value would jump to  , but in an uninteresting way and would not give us any useful structure that we could extrapolate to larger
, but in an uninteresting way and would not give us any useful structure that we could extrapolate to larger  .
.
Odd length HAPs do give a lower bound for sequences, but not for vector sequences. Remember that the SDP produces a lower bound on vector discrepancy. e.g. it turns out that
sequences, but not for vector sequences. Remember that the SDP produces a lower bound on vector discrepancy. e.g. it turns out that  is 1/2 when
is 1/2 when  are unit vectors, but clearly the minimum is 1 when they are 1-dimensional unit vectors.
are unit vectors, but clearly the minimum is 1 when they are 1-dimensional unit vectors.
So what will happen if we throw in as well ? I don’t know, but it should not change the asymptotic behavior of the SDP value with
as well ? I don’t know, but it should not change the asymptotic behavior of the SDP value with  .
.
It is an interesting question.
March 5, 2010 at 10:13 am
That expression did not come out quite correct. It should read:

March 5, 2010 at 10:26 am
Ah, I see, thanks.
March 5, 2010 at 9:54 am |
I wanted to clarify that the matrix*.txt files contain the matrices corresponding to the quadratic form with the diagonal term subtracted out. So you should be careful in reading off diagonal entries from that matrix.
subtracted out. So you should be careful in reading off diagonal entries from that matrix.
I’ve put up a bunch of other files to make sifting through the data easier. They are available here:
https://webspace.princeton.edu/users/moses/EDP/
cd*.txt contains the values of which are an approximation of
which are an approximation of  .
.
qf*.txt: contains the entries of the matrix corresponding to the quadratic form without the diagonal term subtracted out. I only specify the upper triangular matrix, with one entry of the matrix per line.
March 5, 2010 at 10:19 am
As you will see from the data, the values are far from uniform.
values are far from uniform. values (by dividing by
values (by dividing by  ), they start looking a lot like
), they start looking a lot like  (within a factor of 2 say).
(within a factor of 2 say).
If we normalize the
March 5, 2010 at 10:25 am
One more thing I should have mentioned about the qf*.txt files corresponding to the quadratic form. There are three numbers in the lines corresponding to diagonal terms: For the i,i entry the first number is the coefficient of in the quadratic form, the second is the
in the quadratic form, the second is the  term that is subtracted out from this entry, and the third is what remains after the subtraction.
term that is subtracted out from this entry, and the third is what remains after the subtraction.
March 5, 2010 at 11:14 am
Here is some data in support of the hypothesis that is a good predictor of
is a good predictor of 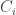 . Look at the files cd-pattern*.txt here:
. Look at the files cd-pattern*.txt here:
https://webspace.princeton.edu/users/moses/EDP/
Each line has the following format: ………..
……….. ……..
……..
i……..
Note that we use the tails from the SDP solution as an approximation of
from the SDP solution as an approximation of 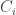 . Our working conjecture is that
. Our working conjecture is that  , so this approximation gets progressively worse with
, so this approximation gets progressively worse with  .
.
Also, the quantity in the exponent seems to be a function of
in the exponent seems to be a function of  . In Huy’s data, the value of
. In Huy’s data, the value of  (from the curve fitting for
(from the curve fitting for  ) is between
) is between 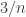 and
and 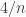 .
.
This tells you how bad the approximation gets for large
gets for large  .
.
March 5, 2010 at 11:26 am
I’m trying to get my head round the data, and this too is quite hard. Initially, as you say, they look roughly proportional to
data, and this too is quite hard. Initially, as you say, they look roughly proportional to  , but this pattern doesn’t last once the values get large. For example, on the 512 list, if I multiply the 100 value by 100 I get roughly 0.1. Since d(100)=9, one would expect that to be about 9 times as big as the value at 1, which is about 0.07. But 0.1 is well short of 0.63.
, but this pattern doesn’t last once the values get large. For example, on the 512 list, if I multiply the 100 value by 100 I get roughly 0.1. Since d(100)=9, one would expect that to be about 9 times as big as the value at 1, which is about 0.07. But 0.1 is well short of 0.63.
Perhaps more informative is to compare the values for that come from the 512 list with the values that come from the 1024 list. Their ratios are definitely not the same, but their general behaviour is pretty comparable, at least to start with. However, when you get to the mid-80s, their behaviour starts to diverge. Here is a chunk of values from the 512 list, with the 1024 values to the right:
that come from the 512 list with the values that come from the 1024 list. Their ratios are definitely not the same, but their general behaviour is pretty comparable, at least to start with. However, when you get to the mid-80s, their behaviour starts to diverge. Here is a chunk of values from the 512 list, with the 1024 values to the right:
80: 0.002609483…………..0.005165121
81: 0.004640467…………..0.005737507
82: 0.000066366…………..0.000311586
83: 0.000167644…………..0.000153519
84: 0.006531641…………..0.006488271
85: 0.000480438…………..0.002050214
86: 0.000197278…………..0.000293866
87: 0.000144329…………..0.000546010
88: 0.000761433…………..0.001270844
89: 0.000257089…………..0.000254195
90: 0.002463915…………..0.006283851
Note that not only are the ratios far from constant, but there are instances (like 86 and 87, for instance), where even the ordering on the 512 list is different from the ordering on the 1024 list.
I don’t know how seriously to take this, however. I would naively expect that we should not be able to read too much out of the experimental data about the behaviour of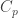 for large primes, say, because their impact on the problem should be typically fairly small, but sometimes, by a fluke, so to speak, the obstacle to low discrepancy will just happen to involve a particular large prime. This is possibly borne out by the data: for example, on the 512 list we have values of 0.000000071 and 0.000000079 at 101 and 103, respectively. On the 1024 list the values are 0.000089463 and 0.000044972 — a different order of magnitude. However, this, I would contend, is because after a while one stops using large primes to prove large discrepancy, and the moment arises earlier if you’re just looking at sequences of length 512 than it does if you’re looking at sequences of length 1024. This is, I would imagine, closely related to the phenomenon that we are already very familiar with: that when you look at finite examples you get a lot of structure on the smooth numbers and quite a lot of rather arbitrary behaviour on the non-smooth numbers. For instance, we saw it with low-discrepancy multiplicative functions starting out character-like and ending up non-character-like until one is overwhelmed by the effects of the “cheating” corrections. It may well be that something like this also applies to the
for large primes, say, because their impact on the problem should be typically fairly small, but sometimes, by a fluke, so to speak, the obstacle to low discrepancy will just happen to involve a particular large prime. This is possibly borne out by the data: for example, on the 512 list we have values of 0.000000071 and 0.000000079 at 101 and 103, respectively. On the 1024 list the values are 0.000089463 and 0.000044972 — a different order of magnitude. However, this, I would contend, is because after a while one stops using large primes to prove large discrepancy, and the moment arises earlier if you’re just looking at sequences of length 512 than it does if you’re looking at sequences of length 1024. This is, I would imagine, closely related to the phenomenon that we are already very familiar with: that when you look at finite examples you get a lot of structure on the smooth numbers and quite a lot of rather arbitrary behaviour on the non-smooth numbers. For instance, we saw it with low-discrepancy multiplicative functions starting out character-like and ending up non-character-like until one is overwhelmed by the effects of the “cheating” corrections. It may well be that something like this also applies to the  .
.
This suggests to me a possible way of cleaning up the data. Perhaps we could do an additional Cesaro-style averaging. That is, instead of looking at the 512 problem, one could average over all the problems up to 512, so that in a certain sense the weight associated with each integer decreases linearly to zero. Of course, I’m not suggesting doing 512 separate analyses and averaging the results. As a matter of fact, I’m not entirely clear what I am suggesting, since if all we do is attach weights to the HAPs (giving more weight to ones that end earlier, say), then the SDP will just cancel those weights out when it chooses its own weights . And if we attach decreasing weights to the elements, then we run into the problem that our problem becomes too smooth and character-like functions can have bounded discrepancy. I’ll see if I can come up with a suitable cleaning-up process, but I don’t see it at the moment.
. And if we attach decreasing weights to the elements, then we run into the problem that our problem becomes too smooth and character-like functions can have bounded discrepancy. I’ll see if I can come up with a suitable cleaning-up process, but I don’t see it at the moment.
For now, I suppose the main point I’m making is that in understanding the data we probably have to restrict attention to smooth numbers and extrapolate from there.
March 5, 2010 at 11:39 am
Annoyingly, even for very small or very smooth numbers the behaviour isn’t what one would ideally like. For instance, if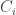 really is given by
really is given by  then both
then both 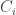 and
and  should be multiplicative (but not completely multiplicative) in
should be multiplicative (but not completely multiplicative) in  . There are some signs of this, but there are also several disappointments. For example,
. There are some signs of this, but there are also several disappointments. For example,  is quite a lot smaller than
is quite a lot smaller than  . (Here I’m using the data from this page, the interpretation of which Moses explains in the comment before last.)
. (Here I’m using the data from this page, the interpretation of which Moses explains in the comment before last.)
March 5, 2010 at 11:53 am
Tim, some of the discrepancy you point out for the value in the 512 list can be explained by the fact that I used
in the 512 list can be explained by the fact that I used  as a proxy for
as a proxy for  . But
. But  where
where  is between 3/512 and 4/512. Say
is between 3/512 and 4/512. Say  . Then the value of the approximation for
. Then the value of the approximation for  we used is a factor
we used is a factor  smaller than the real value which works out to about 0.3.
smaller than the real value which works out to about 0.3.
March 5, 2010 at 10:28 am |
Here’s a list of numbers such that
such that  is very small. Alec has already done something like this, but I want to set the threshold quite a bit higher than he did, partly because the resulting set seems to have more structure, and partly in the light of Moses’s remark that the small values should not be taken too seriously. (I presume this means that the actual values should not be taken seriously, but that their smallness is probably a genuine phenomenon.) I’m working from this wiki page. A couple of question marks means that the decision was a bit borderline.
is very small. Alec has already done something like this, but I want to set the threshold quite a bit higher than he did, partly because the resulting set seems to have more structure, and partly in the light of Moses’s remark that the small values should not be taken too seriously. (I presume this means that the actual values should not be taken seriously, but that their smallness is probably a genuine phenomenon.) I’m working from this wiki page. A couple of question marks means that the decision was a bit borderline.
1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 17, 23, 37, 41, 46, 47, 49, 53, 55, 61, 71, 73??, 79, 82, 83, 98, 101, 103, 106, 107??, 111, 113, 122, 127, 134 (the first truly annoying value, since is large, so it breaks the pattern that any number on this list should have all its factors in the list as well), 137, 139, 145 (a second counterexample, since
is large, so it breaks the pattern that any number on this list should have all its factors in the list as well), 137, 139, 145 (a second counterexample, since  is large), 149, 151, 159, 166, 173, 179, 181, 188, 191, 193, 194 (
is large), 149, 151, 159, 166, 173, 179, 181, 188, 191, 193, 194 ( is pretty large), 197, 199, 203, 205, 223, 227, 229, 233, 247, 251, 254, 259, 263, 269, 271, 274, 277, 278, 281, 283, 289, 293, 307, …
is pretty large), 197, 199, 203, 205, 223, 227, 229, 233, 247, 251, 254, 259, 263, 269, 271, 274, 277, 278, 281, 283, 289, 293, 307, …
The fact that there seem to be several pairs of twin primes (such as 281 and 283) on the list suggests that there probably isn’t any congruence condition on the set of primes that shows up in this list (as does the fact that all the primes up to 11 are on it). Here, however, is a list of primes that do not appear on the above list of numbers: 13, 19, 29, 31, 43, 59, 67, 89, 97 (though twice 97 does appear), 109, 131, 157, 163, 167, 211, 239, 241, 257, …
Plugging the beginnings of these lists into Sloane’s database doesn’t seem to throw up anything interesting, though I did discover the following utterly irrelevant fact: the numbers 1, 2, 3, 4, 5, 6, 7, 9, 10, 11 and 17 — that is, the first eleven numbers on the first list above — are also the first eleven numbers such that the decimal representation of
such that the decimal representation of  contains no zeros. The next such number is 18, so no conjecture there …
contains no zeros. The next such number is 18, so no conjecture there …
March 5, 2010 at 11:59 am |
I’d like to throw out an idea in order to see whether there is an obvious objection to it. The character-like functions have the property that their mean-square discrepancy is unbounded, in the following sense: the average of over all
over all 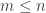 is at least
is at least 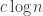 for some positive constant
for some positive constant  . Here, we only have to consider the partial sums because the function is completely multiplicative. However, we could hypothesize that a more general statement holds, namely that for every
. Here, we only have to consider the partial sums because the function is completely multiplicative. However, we could hypothesize that a more general statement holds, namely that for every  sequence of length
sequence of length  there exists some
there exists some  such that the mean-square sum along the multiples of
such that the mean-square sum along the multiples of  is at least
is at least 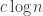 (or at least is unbounded). If that is true, then we might be able to prove it using SDP. And I think that is equivalent to insisting that the coefficients
(or at least is unbounded). If that is true, then we might be able to prove it using SDP. And I think that is equivalent to insisting that the coefficients  are independent of
are independent of  . At any rate, if we can find non-negative coefficients
. At any rate, if we can find non-negative coefficients  such that
such that  and non-negative coefficients
and non-negative coefficients  that have unbounded sum, such that the quadratic form
that have unbounded sum, such that the quadratic form
is positive semidefinite, then we are obviously done. The point of this observation is twofold. First, it should be possible to do the computations more quickly (since one has far fewer coefficients to work out). Secondly, I think this restriction imposes a kind of smoothing effect of the sort I was trying to guess in this comment, and therefore could potentially lead to coefficients with a more obvious structure.
This comes into the category of “experiment that I would very much like to see done even though it has a positive probability of having a serious flaw and being completely uninformative”.
March 5, 2010 at 12:32 pm
On second thoughts, I don’t see why this should be smoother than . But that makes me wonder about something else.
. But that makes me wonder about something else.
First, if we make the simplifying assumption that and then try to optimize the choice of
and then try to optimize the choice of  subject to that assumption (choosing
subject to that assumption (choosing  to be
to be  , say), do we end up with a computational problem that is significantly smaller? Prima facie it looks as though it should, as now we are trying to work out linearly many coefficients instead of quadratically many. But my understanding of SDP is not good enough to be sure that this is correct. It would be nice if it did, since then we could look at much larger matrices and be reasonably confident that the results we got behaved similarly to the actual best possible matrices.
, say), do we end up with a computational problem that is significantly smaller? Prima facie it looks as though it should, as now we are trying to work out linearly many coefficients instead of quadratically many. But my understanding of SDP is not good enough to be sure that this is correct. It would be nice if it did, since then we could look at much larger matrices and be reasonably confident that the results we got behaved similarly to the actual best possible matrices.
Secondly, what if we don’t go for the optimal matrix at all and simply set every single equal to
equal to  , where
, where  is the number of pairs
is the number of pairs  such that
such that 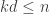 , and then try to optimize the
, and then try to optimize the  for the resulting quadratic form? How tractable is that? Note that the matrix of this quadratic form has
for the resulting quadratic form? How tractable is that? Note that the matrix of this quadratic form has 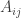 proportional to
proportional to  .
.
Now that I ask the question, I remember Moses saying something about needing to go at least as far as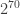 in order to prove a discrepancy of 2, or something like that. So obviously there is no hope of seeing the sum of the
in order to prove a discrepancy of 2, or something like that. So obviously there is no hope of seeing the sum of the  getting large, but we just might get the sequence itself having a nice structure.
getting large, but we just might get the sequence itself having a nice structure.
March 5, 2010 at 12:47 pm
Tim, I haven’t thought through what you are suggesting and I am about to sign out for the next several hours, but let me address your comment about whether the problem becomes significantly easier if one guesses values for . I agree that it should become easier. We had
. I agree that it should become easier. We had 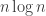 constraints to start with (each has a corresponding
constraints to start with (each has a corresponding  ) and now we have reduced them to
) and now we have reduced them to  constraints, each of them is of the form
constraints, each of them is of the form  . In fact the resulting SDP has similar structure to SDPs used for Max-Cut, a well studied problem.
. In fact the resulting SDP has similar structure to SDPs used for Max-Cut, a well studied problem.
Now whether or not off the shelf solvers will be able to take advantage of this simplicity is hard to say. To illustrate some subtleties here, I actually rewrote the SDP formulation a few times (all of them equivalent to each other) before I obtained a form that seemed easy for solvers to solve large instances on. It is possible that one write custom code to solve this simpler SDP faster, but that would involve significant effort starting from scratch. More likely, one may be able to use SDP code for Max Cut if such specialized code is available.
March 5, 2010 at 1:00 pm |
Going back to something Tim discussed earlier in this comment , I want to mention something interesting about the matrix he was trying to compute. To summarize, we consider the matrix and consider the effect on the Cholesky decomposition when we subtract an infinitesimal
and consider the effect on the Cholesky decomposition when we subtract an infinitesimal  from
from  .
.
Firstly, the Cholesky decomposition of , where
, where  if
if  and 0 otherwise. Let
and 0 otherwise. Let  be the new decomposition, where we ignore quadratic and higher terms in
be the new decomposition, where we ignore quadratic and higher terms in  .
. and the result was a little surprising to me. The entries of this matrix going up to 10, 100, 1000 are given here:
and the result was a little surprising to me. The entries of this matrix going up to 10, 100, 1000 are given here:

I wrote some code to compute
https://webspace.princeton.edu/users/moses/EDP/w10.txt
https://webspace.princeton.edu/users/moses/EDP/w100.txt
https://webspace.princeton.edu/users/moses/EDP/w1000.txt
Each line is of the form:
(The values should be divided by 2 to obtain the entries of W that Tim was looking at). Here is what was surprising to me: the minimum value in the file for size 10 is -2, the minimum for size 100 is -3 and the minimum for size 1000 is -4. I had expected to see much lower values than that.
March 5, 2010 at 4:08 pm
Let me mention that yesterday I did some more hand computations of this matrix, and observed that, for each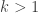 , once you get beyond the diagonal, the
, once you get beyond the diagonal, the  th row of the matrix is a linear combination of the vectors 11111111111…, 0101010101…, 001001001… up to the kth. That is, it is a linear combination of the HAPs up to
th row of the matrix is a linear combination of the vectors 11111111111…, 0101010101…, 001001001… up to the kth. That is, it is a linear combination of the HAPs up to  , which are of course the rows of
, which are of course the rows of  . I’m sure there’s a simple proof of this, but I haven’t yet found it — it just seemed to work for the beginnings of the first few rows.
. I’m sure there’s a simple proof of this, but I haven’t yet found it — it just seemed to work for the beginnings of the first few rows.
I think it partially explains why the entries grow quite slowly: in order to get a big entry it has to be at a number with a lot of factors and in addition to that the coefficients have to line up.
Going back to the form of , this is saying that
, this is saying that  is obtained by multiplying
is obtained by multiplying  by a lower triangular matrix and then getting rid of everything below the diagonal. I’d be interested to know what that lower triangular matrix was.
by a lower triangular matrix and then getting rid of everything below the diagonal. I’d be interested to know what that lower triangular matrix was.
March 5, 2010 at 1:03 pm |
Looking at l2-average discrepency is a very nice variation and indeed it reduces the number of coefficients. Now, can it be true that the l2-norm over all partial sums and all d’s is small as well?
Namely, maybe not only there exists some d such that the mean-square sum along the multiples of d is at least c\log n (or at least is unbounded), but the mean square sum for all partial sums for all ds together is at least unbounded.
March 5, 2010 at 1:28 pm
Here is a small sanity check. One might think that perhaps it was too crude to give equal weight to all HAPs, since for example there are HAPs of length 1. So let’s see whether the contributions from these HAPs to the average is likely to be small.
HAPs of length 1. So let’s see whether the contributions from these HAPs to the average is likely to be small.
We can approximate the number of HAPs of length by
by 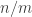 . If we do, then we see that the number of HAPs of length between
. If we do, then we see that the number of HAPs of length between  and
and 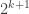 is roughly independent of
is roughly independent of  as
as  runs from
runs from  to
to 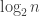 . Therefore, about half of all HAPs will have length between
. Therefore, about half of all HAPs will have length between 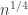 and
and  , so if the mean-square discrepancy along these is logarithmic, then the entire mean-square discrepancy is logarithmic. And that seems like a fairly reasonable conjecture.
, so if the mean-square discrepancy along these is logarithmic, then the entire mean-square discrepancy is logarithmic. And that seems like a fairly reasonable conjecture.
However, by “fairly reasonable” I don’t mean that I’ve tried to test it in any way. Perhaps it would be worth thinking about whether we can construct a sequence of length
sequence of length  such that the mean-square discrepancy over HAPs with length between
such that the mean-square discrepancy over HAPs with length between 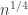 and
and  (or any two powers of your choice) is bounded. An additional benefit of this problem is that it would force us to think about EDP in a more global, large-
(or any two powers of your choice) is bounded. An additional benefit of this problem is that it would force us to think about EDP in a more global, large- , big-difference-HAP sort of way.
, big-difference-HAP sort of way.
Actually, I’ve just realized that if you have unbounded mean-square discrepancy for EDP, then you probably do for this problem as well. The only way it could fail would be if for every smallish common difference the partial sums along mutliples of
the partial sums along mutliples of  started out possibly being unbounded but after you reached
started out possibly being unbounded but after you reached  they began to control themselves. But we know that there would have to be little pockets of unbounded drift — consider, for example, what happens to HAPs of common difference at most
they began to control themselves. But we know that there would have to be little pockets of unbounded drift — consider, for example, what happens to HAPs of common difference at most  after the point
after the point  . This isn’t a proof — just an argument that the mean-square discrepancy for HAPs of length between
. This isn’t a proof — just an argument that the mean-square discrepancy for HAPs of length between 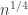 and
and  is likely to be unbounded.
is likely to be unbounded.
March 6, 2010 at 9:22 am
I tried solving the SDP having fixed for all
for all 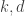 . This means the objective function of the SDP is
. This means the objective function of the SDP is

 for all
for all  .
.
subject to the constraints
Actually I normalized so that . This is a much easier problem to solve (this should be true for any fixing of the
. This is a much easier problem to solve (this should be true for any fixing of the  ). I was able to solve instances of size up to 4096 and we could probably go up to the next power of 2 if we wanted. Here are the optimal values I got:
). I was able to solve instances of size up to 4096 and we could probably go up to the next power of 2 if we wanted. Here are the optimal values I got:
256 0.4548
512 0.4686
1024 0.4797
2048 0.4897
4096 0.4982
The values in the SDP dual solution are available here:
values in the SDP dual solution are available here:
 …
…  … #divisors(i) … factorization of i
… #divisors(i) … factorization of i
http://webspace.princeton.edu/users/moses/EDP/try1/
The files have the format:
Note that some values are negative. This is because I used the constraint
values are negative. This is because I used the constraint  in the SDP. If I had used the constraint
in the SDP. If I had used the constraint  instead, all of them would have been non-negative.
instead, all of them would have been non-negative.
March 5, 2010 at 1:32 pm |
Moses, what software are you using to solve the SDP? Are you using
an interior point code? I must mention that there are other fast approaches to
solve an SDP approximately. For starters, you might want to look at SDPLR
that is available at
http://dollar.biz.uiowa.edu/~sburer/www/doku.php?id=software#sdplr
Of course, these techniques only produce approximate solutions not
the high accuracy that interior point methods provide. However, since
you are only using the SDP as a relaxation to your original problem, I assume
this is not a problem.
You mention that the SDP has a structure similar to the one Goemans-Williamson
used in their max-cut algorithm. This is the SDP where the only constraints are that X_ii = 1 for all i and X is psd. Is this it or are there other constraints in your
SDP? I must mention that SDPLR is well equipped to solve a problem with this
“max-cut” like structure. If you provide some more feedback, then I can be of greater help.
March 6, 2010 at 9:31 am
Kartik, I used DSDP to solve the SDP. I’ve also tried CSDP which works well too. What we are really looking for is the dual solution. Does SDPLR generate this ?
The min average square discrepancy problem is equivalent to max-cut in the following sense: Construct a weighted graph on vertices, one for each element in the sequence. The edges of the graph are a superposition of cliques, one for each HAP (where the clique is on the elements contained in the HAP). Now the optimum value of the max-cut problem on this graph is linearly related to the optimum value of the min average square discrepancy question. The same connection holds for the SDP formulations of the two problems.
vertices, one for each element in the sequence. The edges of the graph are a superposition of cliques, one for each HAP (where the clique is on the elements contained in the HAP). Now the optimum value of the max-cut problem on this graph is linearly related to the optimum value of the min average square discrepancy question. The same connection holds for the SDP formulations of the two problems.
March 5, 2010 at 4:55 pm |
Another idea I’d like to put forward, though it’s not obvious that it can be made to work, is to combine SDP with infinitary methods somehow. The motivation for doing this is that it might be easier to use soft methods and just prove unboundedness.
I thought of this because of the aspect of Moses’s method that he mentioned above: that the decay rate depends on the size of the problem
depends on the size of the problem  : it seems that
: it seems that  is around
is around  , where
, where  is between 3 and 4. That means, if EDP is true, that the best SDP proof is rather heavily dependent on
is between 3 and 4. That means, if EDP is true, that the best SDP proof is rather heavily dependent on  . So it’s not clear that we get anything if we let
. So it’s not clear that we get anything if we let  tend to infinity: the normalizing factor also tends to infinity, so all the coefficients tend to 0.
tend to infinity: the normalizing factor also tends to infinity, so all the coefficients tend to 0.
But this doesn’t completely rule out some renormalization that would give rise to an infinitary proof. Now one would hope for a decay rate of zero — that is, no decay, and consequently easier computations. But instead of taking a sum, we would have to take an average. And of course this wouldn’t be an average in the conventional sense, as there are infinitely many coefficients but rather, some kind of clever average that we would have to devise. For instance, we could take averages over increasingly large sets of pairs
but rather, some kind of clever average that we would have to devise. For instance, we could take averages over increasingly large sets of pairs  and take some limit. Or we could take the limit of
and take some limit. Or we could take the limit of  along some carefully constructed ultrafilter on
along some carefully constructed ultrafilter on 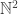 . Or we could do something else of this general kind.
. Or we could do something else of this general kind.
We would then hope to be able to find an infinite sequence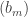 that sums to infinity such that subtracting the form
that sums to infinity such that subtracting the form  still leaves one with a positive semidefinite quadratic form. (We would have to make sense of this statement.)
still leaves one with a positive semidefinite quadratic form. (We would have to make sense of this statement.)
It isn’t obvious what any of this means, but there seems to be at least a chance that the calculations might be easier, if one could find a meaning, than they are in the finitary case.
March 5, 2010 at 7:18 pm
Let me say what I think the infinitary matrix should look like and why. First, if , then
, then  should be minus the “derivative” of
should be minus the “derivative” of 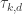 with respect to
with respect to  , or
, or  . Letting
. Letting  tend to zero and “renormalizing” by dividing by
tend to zero and “renormalizing” by dividing by  we get
we get  . Now Moses suggests that
. Now Moses suggests that  looks like
looks like  , which gives us
, which gives us  .
.
The corresponding quadratic form is therefore , which has matrix
, which has matrix  , where
, where  . Of course, this is infinite, but the sum over
. Of course, this is infinite, but the sum over  seems to be more or less the same infinity for every
seems to be more or less the same infinity for every  , so renormalizing again let’s go for
, so renormalizing again let’s go for  . This counts the number of pairs
. This counts the number of pairs 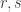 such that
such that  and
and  . Equivalently, it counts the number of ordered factorizations of
. Equivalently, it counts the number of ordered factorizations of  as
as  . The first few values of this function are
. The first few values of this function are  , and it turns out to be a reasonably well-known arithmetical function denoted by
, and it turns out to be a reasonably well-known arithmetical function denoted by  . (This last piece of information I found out by plugging these sequence values into Sloane’s database.)
. (This last piece of information I found out by plugging these sequence values into Sloane’s database.)
If is once again the matrix with
is once again the matrix with  th entry
th entry  , and if
, and if  is a diagonal matrix with
is a diagonal matrix with  , then this matrix
, then this matrix  factorizes as
factorizes as  . I’m not sure whether that is of any use to us, but at least it is reasonably clean.
. I’m not sure whether that is of any use to us, but at least it is reasonably clean.
So a question I’d like to ask now is whether, in some purely formal sense, we can write as
as  where
where  is a nice big positive diagonal matrix. That wouldn’t be an immediate solution to the problem, but it might suggest a way forward.
is a nice big positive diagonal matrix. That wouldn’t be an immediate solution to the problem, but it might suggest a way forward.
March 5, 2010 at 7:59 pm
Actually, I’m not so sure about the second of those “renormalizations” so let me try again. We know always that, whatever the choice of , the matrix entry
, the matrix entry  equals
equals  , which equals
, which equals  . If
. If  then this gives us
then this gives us  . If in addition
. If in addition  , then on letting
, then on letting  go to zero we get
go to zero we get  . I’m in a slight hurry now, so I have no time to think about why this extra factor of
. I’m in a slight hurry now, so I have no time to think about why this extra factor of 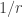 has come in, but it feels more correct to me.
has come in, but it feels more correct to me.
The effect on the above discussion if we go for this matrix is that the diagonal matrix should have entry
should have entry  . For what it’s worth,
. For what it’s worth,  is the Dirichlet convolution of the divisor function with
is the Dirichlet convolution of the divisor function with 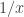 , all divided by
, all divided by  .
.
March 5, 2010 at 8:43 pm
Now I’m a bit confused. If our quadratic form is for some positive diagonal matrix
for some positive diagonal matrix  , then it is also
, then it is also  , where
, where  . But the
. But the  th row of
th row of  is supported on the multiples of
is supported on the multiples of  , so for this to work it would seem to require us to be able to find for each
, so for this to work it would seem to require us to be able to find for each  some linear combination of
some linear combination of  in such a way that for every
in such a way that for every  sequence at least one of those linear combinations was large. (I’m leaving unanswered the question of how one would make sense of this in the infinitary world.) But that doesn’t seem very plausible.
sequence at least one of those linear combinations was large. (I’m leaving unanswered the question of how one would make sense of this in the infinitary world.) But that doesn’t seem very plausible.
In fact, we can say explicitly what is. The
is. The  th entry is
th entry is  if
if  and 0 otherwise. This means that we would be attempting to show that there exists
and 0 otherwise. This means that we would be attempting to show that there exists  such that
such that  was large. Or at least I think that’s what we would be attempting to show — I haven’t carefully checked.
was large. Or at least I think that’s what we would be attempting to show — I haven’t carefully checked.
The reason this doesn’t feel plausible is that in the finite case it definitely fails: if you’ve got rows supported on the first
rows supported on the first  HAPs, then you can find a sequence that is killed by the first
HAPs, then you can find a sequence that is killed by the first  rows, and the effect of the last row will not be a drastic one.
rows, and the effect of the last row will not be a drastic one.
I need to think through the ramifications of this, but I may not get a chance to do so for some time.
March 5, 2010 at 8:59 pm
Ah, I’ve seen it now. A model in which the tails don’t decay is not a good model because it tells you that only the last
don’t decay is not a good model because it tells you that only the last  is non-zero. So it’s not all that surprising that it was defective in the way I said.
is non-zero. So it’s not all that surprising that it was defective in the way I said.
March 5, 2010 at 10:58 pm |
Again, no time to think through properly what I am saying, but here’s a remark about the linear-algebraic approach that Gil and I were discussing at one point.
Let be, once again, the matrix where
be, once again, the matrix where  if
if  and 0 otherwise. This is an upper triangular matrix, so we know that it is invertible. In fact, it is quite easy to invert it explicitly: the inverse is the matrix
and 0 otherwise. This is an upper triangular matrix, so we know that it is invertible. In fact, it is quite easy to invert it explicitly: the inverse is the matrix  where
where  if
if  and 0 otherwise. To see this, note that
and 0 otherwise. To see this, note that  (where we’ll interpret
(where we’ll interpret  to be zero if
to be zero if  does not divide
does not divide  ). This equals
). This equals  , which is 1 if
, which is 1 if  and 0 otherwise.
and 0 otherwise.
Once we know how to invert , we know how to build sequences such that their partial sums along all full HAPs (that is, ones of the form
, we know how to build sequences such that their partial sums along all full HAPs (that is, ones of the form 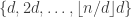 ) are small. We also know other things like that for smaller HAPs we would ideally like to use just the first few columns of
) are small. We also know other things like that for smaller HAPs we would ideally like to use just the first few columns of  to build low-discrepancy sequences, but they will give us sequences that are zero from some point on.
to build low-discrepancy sequences, but they will give us sequences that are zero from some point on.
This makes me wonder whether the columns of could be a useful basis for looking at the problem. The idea, very roughly indeed, would be that if you want to create a
could be a useful basis for looking at the problem. The idea, very roughly indeed, would be that if you want to create a  sequence, then you are forced to use the columns of
sequence, then you are forced to use the columns of  in a certain way (in particular, you are forced to use plenty of late columns) and that should mess up some of the shorter HAPs. A disadvantage of this approach is that it might involve an understanding of
in a certain way (in particular, you are forced to use plenty of late columns) and that should mess up some of the shorter HAPs. A disadvantage of this approach is that it might involve an understanding of  that is better than one can realistically to hope for.
that is better than one can realistically to hope for.
March 6, 2010 at 12:25 am
Let me be slightly more specific. The th column of
th column of  is the vector
is the vector  , where
, where  is the standard basis of
is the standard basis of  . If we take a linear combination
. If we take a linear combination  , then its sum along the full HAP of common difference
, then its sum along the full HAP of common difference  is
is 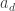 . Therefore, the sequences with bounded partial sums along all full HAPs are precisely the linear combinations
. Therefore, the sequences with bounded partial sums along all full HAPs are precisely the linear combinations  for which the
for which the 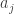 are bounded.
are bounded.
For a sequence to have bounded discrepancy, however, we need more. We need not only for the sequence to be a bounded linear combination of the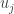 , but also for the same to be true of all the projections of that sequence to the first
, but also for the same to be true of all the projections of that sequence to the first  coordinates.
coordinates.
Going back to the disadvantages, another one is that with this approach one is back with the 1, -1, 0, 1, -1, 0, … problem (unless one uses this new basis to build a better SDP or something like that).
For what it’s worth, if you want to equal this annoying sequence (turned into a column vector) then you have to take
to equal this annoying sequence (turned into a column vector) then you have to take 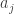 to be 1 if
to be 1 if  is congruent to 1 mod 3 and 0 otherwise. That one works out by using the fact that
is congruent to 1 mod 3 and 0 otherwise. That one works out by using the fact that  is the inverse of
is the inverse of  . More generally, by the way
. More generally, by the way  is constructed,
is constructed, 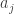 is (as has already been mentioned) the sum of your given sequence over every
is (as has already been mentioned) the sum of your given sequence over every  th term.
th term.
March 6, 2010 at 12:40 am |
One last thought. It has now been observed a few times that EDP becomes false if one restricts attention to HAPs of the form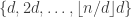 . But the obvious example to show this is the sequence that is 1 up to
. But the obvious example to show this is the sequence that is 1 up to  and
and  thereafter.
thereafter.
Now suppose we gradually make the task harder by allowing other lengths. (For this discussion I’ll define the length of a HAP to be the distance between its end points rather than its cardinality.) If, for example, we also allowed HAPs of length 1/2, then the obvious example is 1 up to n/4, then -1 up to n/2, then 1 up to 3n/4, then -1 up to n. It’s not perfect, but it’s pretty good.
More generally, if we want to deal with all HAPs of length , then it seems to be a good idea to have a sequence that has long strings of 1s and -1s and satisfies
, then it seems to be a good idea to have a sequence that has long strings of 1s and -1s and satisfies  and the average over any interval of length
and the average over any interval of length  is zero. The first property makes whatever you do robust under small changes to the common difference, and the second means that as you shift the HAP you don’t change its drift. But note that the periodicity is not such a good idea when you come to consider HAPs with common difference
is zero. The first property makes whatever you do robust under small changes to the common difference, and the second means that as you shift the HAP you don’t change its drift. But note that the periodicity is not such a good idea when you come to consider HAPs with common difference  .
.
Here I’m just floating the idea that perhaps one could prove EDP by picking a few different lengths and showing that they can’t all be dealt with simultaneously.
The fact that I’m thinking about new ideas doesn’t mean I’ve given up on Moses’s approach — far from it. I’m just taking a little time out from it.
March 6, 2010 at 10:38 am
This approach feels well suited to the EDP over the rationals. Let’s consider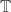 -valued functions, because it makes the equations easier to write. If we want a function
-valued functions, because it makes the equations easier to write. If we want a function  such that for all
such that for all  ,
,  , we can take
, we can take  . That even gives us
. That even gives us  ; but then
; but then  is unbounded.
is unbounded.
A naive attempt to fix this by replacing by
by  takes us back to the original EDP over the integers, so we need to be more subtle.
takes us back to the original EDP over the integers, so we need to be more subtle.  feels too strong, so we have some rope to play with.
feels too strong, so we have some rope to play with.
March 6, 2010 at 10:43 am
Correction: it only gives us if we restrict to the cases where
if we restrict to the cases where  .
.
March 6, 2010 at 11:50 am |
Going back to the SDP approach (I quite like the idea of using SDP to solve EDP — just spotted that), here’s an idea for cleaning it up.
Up to now, the computer experiments have looked at the problem of finding the best possible dual function in the case of sequences of length . But that seems to lead to problems. I don’t mean mathematical problems with the approach, but just oddnesses in the data.
. But that seems to lead to problems. I don’t mean mathematical problems with the approach, but just oddnesses in the data.
To get rid of these oddnesses, it would be good to get rid of the sharp cutoff at . I tried one idea for doing that recently, but ended up smoothing the whole problem so much that the result became false (because character-like functions had bounded “smoothed discrepancy”). But there I was smoothing the HAPs — I now realize that that was a bad thing to do and that the sharp cutoffs in the HAPs are somehow essential to the truth of EDP (if it is true). However, that doesn’t stop us smoothing off the entire interval in which we are working.
. I tried one idea for doing that recently, but ended up smoothing the whole problem so much that the result became false (because character-like functions had bounded “smoothed discrepancy”). But there I was smoothing the HAPs — I now realize that that was a bad thing to do and that the sharp cutoffs in the HAPs are somehow essential to the truth of EDP (if it is true). However, that doesn’t stop us smoothing off the entire interval in which we are working.
So what I propose is to choose a decay rate , which will give the interval a “half-life” proportional to
, which will give the interval a “half-life” proportional to  , which we think of as the essential size of the problem. We then try to show that there must exist
, which we think of as the essential size of the problem. We then try to show that there must exist 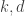 such that
such that  . To do that, we do what we’ve been doing with the sharp cutoff. That is, we try to find non-negative coefficients
. To do that, we do what we’ve been doing with the sharp cutoff. That is, we try to find non-negative coefficients  and
and  such that the
such that the  sum to 1, the
sum to 1, the  sum to more than
sum to more than  , and
, and
From a computational point of view, I would imagine choosing a half-life of smething like 200 and truncating the decaying HAPs at 1500, at which point there is little chance of further terms contributing to the discrepancy. (It may be possible to choose a bigger half-life than this, come to think of it.)
One reason to hope that this is a more natural set-up is precisely the observed decay of the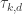 . Perhaps the computer is trying to tell us that it would have preferred an exponentially decaying ground set to one that suddenly stops at
. Perhaps the computer is trying to tell us that it would have preferred an exponentially decaying ground set to one that suddenly stops at  . And perhaps the decay rate for the smoothed problem would actually equal the decay we put in in the first place: that is, perhaps
. And perhaps the decay rate for the smoothed problem would actually equal the decay we put in in the first place: that is, perhaps  would turn out to equal
would turn out to equal  . At any rate, it seems at least possible that this will be a more stable problem, in the sense that the values of
. At any rate, it seems at least possible that this will be a more stable problem, in the sense that the values of  and
and  might be expected to depend in a nicer way on
might be expected to depend in a nicer way on  than they behaved on
than they behaved on  . If so, then we might be able to read more out of the experimental data.
. If so, then we might be able to read more out of the experimental data.
March 6, 2010 at 3:58 pm
I’m a little confused. This looks a lot like the smooth EDP you were trying earlier. Why doesn’t the problem with smooth EDP you pointed out here apply to the new proposal ?
March 6, 2010 at 5:03 pm
The main difference here is that the coefficient depends on
depends on  (and therefore involves HAPs that are suddenly cut off at
(and therefore involves HAPs that are suddenly cut off at  ) whereas before I had coefficients
) whereas before I had coefficients  that depended on a parameter
that depended on a parameter  that always gave rise to something smooth.
that always gave rise to something smooth.
To put the point another way, if is small and
is small and 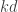 is a lot smaller than
is a lot smaller than  , then HAP of length
, then HAP of length  and difference
and difference  is basically counted here, whereas in the previous set-up I would have had a smoothly decaying HAP with half life
is basically counted here, whereas in the previous set-up I would have had a smoothly decaying HAP with half life 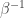 or so.
or so.
Yet another way of putting the point is that if you work out the coefficient of here then it will involve
here then it will involve  . I haven’t got time to work out exactly what it is right now, but will do so soon.
. I haven’t got time to work out exactly what it is right now, but will do so soon.
And a final way of putting it is that here I am smoothing but I am not smoothing
but I am not smoothing  .
.
Also when I get a spare moment, I’ll work out what happens for character-like functions and post the results. That should make everything completely clear.
March 6, 2010 at 6:45 pm
Here are the two computations promised earlier. The first is of the matrix entry . Since all we are doing is replacing the variable
. Since all we are doing is replacing the variable  by
by  , and since the previous entry was
, and since the previous entry was  , it is now
, it is now  .
.
It’s a bit complicated to work out the discrepancy of a character-like function (though if I felt less lazy I think I could approximate it reasonably well), but here is an informal argument that it is unbounded.
I’ll begin by discussing roughly how big the sum ought to be. Recall that we work this out by splitting the integers up to
ought to be. Recall that we work this out by splitting the integers up to  according to the highest power of 3 that divides them. Then the sum over non-multiples of 3 is something very small (at most
according to the highest power of 3 that divides them. Then the sum over non-multiples of 3 is something very small (at most  I think), plus an extra contribution of
I think), plus an extra contribution of  if
if  is congruent to 1 mod 3. Provided
is congruent to 1 mod 3. Provided  is not much bigger than
is not much bigger than  , this extra contribution will be substantial. We now apply the same to the multiples of 3 that are not multiples of 9, and we get a pretty similar calculation, but this time the extra contribution is negative.
, this extra contribution will be substantial. We now apply the same to the multiples of 3 that are not multiples of 9, and we get a pretty similar calculation, but this time the extra contribution is negative.
What this demonstrates is that at least up to around the calculation is more or less the same as it is when there is no decay. Since the contribution up to
the calculation is more or less the same as it is when there is no decay. Since the contribution up to  is a constant proportion of the whole lot, this means that unbounded discrepancy in the usual case more or less implies unbounded discrepancy in this case too.
is a constant proportion of the whole lot, this means that unbounded discrepancy in the usual case more or less implies unbounded discrepancy in this case too.
Where I hope that this new expression scores over the old one is that the influence of non-smooth numbers should fade out gradually rather than suddenly. For example, if we are looking at a prime , it won’t make a big difference whether
, it won’t make a big difference whether  (because there won’t be an
(because there won’t be an  but just a half-life of around
but just a half-life of around  ).
).
March 6, 2010 at 8:31 pm
Here is another way to think about Tim’s proposed smoothing. To repeat what he said, we want to find non-negative coefficients and
and  such that the
such that the  sum to 1, the
sum to 1, the  sum to more than
sum to more than  , and
, and

Now substitute and
and
 . Then the problem is equivalent to proving that
. Then the problem is equivalent to proving that

 and
and  such that the
such that the  sum to 1, and
sum to 1, and  . In other words, this is almost the same as the original problem except that the weighting in the objective function is changed to give exponentially decreasing weights to the
. In other words, this is almost the same as the original problem except that the weighting in the objective function is changed to give exponentially decreasing weights to the  ‘s.
‘s.
where the
March 6, 2010 at 9:07 pm
That’s a nice way of looking at it. Just to be absolutely clear, I would also add that a second very important difference, in a sense the main point of the modification, is that the problem is now infinite, though in practice, when programming, one would truncate at an for which
for which  is small — so it is “morally finite”.
is small — so it is “morally finite”.
March 6, 2010 at 1:01 pm |
Moses, DSDP is an interior point solver. Yes, I believe SDPLR also generates
the dual solution. Although, DSDP exploits the low rank of the data matrices
in the SDP, SDPLR should be a lot faster on SDPs that have a max-cut
like structure.
Hans Mittlemann has done some benchmarking on the SDP solvers.
See http://plato.asu.edu/ftp/sdplib.html
You can see the results on maxG11, maxG32, and maxG51 which
are SDP relaxations arising from the max-cut problem. SDPLR is the fastest
on these problems. These problems are of small size. For
large matrix sizes, SDPLR should be a lot faster. However, as I mentioned
before, the primal/dual solutions will be less accurate.
I was reading some of your earlier comments and you mention
that the SDP for N = 1500 took more than a day to solve. Is N here the size
of the solution matrix in the SDP? The simplest SDP relaxation for the maxcut problem has only N equality constraints (X_{ii} = 1) and the X psd requirement.
Is this the SDP that you are trying to solve? If this is the case, I am surprised
that it is taking this long.
Can you post the coefficient matrix for the SDP (the Laplacian matrix or
the adjacency matrix for the max-cut relaxation somewhere)? I am assuming that this is the only input that is needed. I can try to run the SDP relaxation through SDPLR for you. Please let me know if there are any additional features in the SDP as well.
March 6, 2010 at 3:23 pm
Kartik, the SDPs we were trying to solve earlier do not have a Max-Cut like structure. The newer ones, where we guess values for all do. The earlier ones that took a day to solve have
do. The earlier ones that took a day to solve have 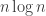 constraints, one corresponding to each HAP, in addition to the
constraints, one corresponding to each HAP, in addition to the  constraints
constraints  , As expected, the new ones are much easier to solve (see here ). At this point, we haven’t settled on what good guesses for these
, As expected, the new ones are much easier to solve (see here ). At this point, we haven’t settled on what good guesses for these  values ought to be. So for some time, we might still need to solve SDPs that are more complex than Max-Cut like formulations.
values ought to be. So for some time, we might still need to solve SDPs that are more complex than Max-Cut like formulations.
March 6, 2010 at 8:40 pm |
I see that there is an answer on Math Overflow to the question Gil asked about the number of sequences of length
sequences of length  with all partial sums bounded by
with all partial sums bounded by  . If I understand it correctly the answer is approximately
. If I understand it correctly the answer is approximately  .
.
This means that if we make the crude assumption that being completely multiplicative is an ‘independent’ event from having partial sums bounded by , then the probability of both occurring is about
, then the probability of both occurring is about  , so that the expected number of such sequences in this model is about
, so that the expected number of such sequences in this model is about  , which decays roughly exponentially with
, which decays roughly exponentially with  . I think this constitutes a kind of heuristic argument for EDP, and so it may be worth exploring whether we can prove anything in the direction of ‘independence’ of the two conditions here.
. I think this constitutes a kind of heuristic argument for EDP, and so it may be worth exploring whether we can prove anything in the direction of ‘independence’ of the two conditions here.
March 6, 2010 at 9:44 pm
Dear Alec, indeed, Douglas Zare gave a very nice answer. I do plan to say a little more about the probabilistic heuristics, how should we treat its “predictions” and how maybe it can be used to create examples with low discrepency. (I think indeed the heuristic for multiplicative sequences gives similar predictions to those for general sequences.)
March 7, 2010 at 9:29 am
Reading Douglas Zare’s answer in a little more detail, I see that he also gives the stable distribution of the endpoints of the paths that stay within![[-C, C]](https://s0.wp.com/latex.php?latex=%5B-C%2C+C%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The form is very nice: essentially the probability of being at
. The form is very nice: essentially the probability of being at  (assuming
(assuming  has the right parity) is proportional to
has the right parity) is proportional to  . Furthermore, the distribution remains stable if
. Furthermore, the distribution remains stable if  is allowed to increase slowly (for example, as
is allowed to increase slowly (for example, as  ).
).
I don’t know if this is what you had in mind, Gil, but this may indeed be helpful in searching for sequences with logarithmic discrepancy , say: given choices for
, say: given choices for  , we can choose
, we can choose  to maximize the likelihood
to maximize the likelihood


 I really mean a function that is zero outside the interval
I really mean a function that is zero outside the interval ![[-\frac{\pi}{2}, \frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=%5B-%5Cfrac%7B%5Cpi%7D%7B2%7D%2C+%5Cfrac%7B%5Cpi%7D%7B2%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) and equal to the cosine inside it.)
and equal to the cosine inside it.)
or perhaps a weighted likelihood:
(Here when I write
March 6, 2010 at 9:38 pm |
Let me say a little more about a polynomial approach to EDP. (I also think it is good, especially in the polymath mode, to consider in parallel various things.)
Here is a conjecture:
Conjecture (*) Let F be the field with p elements, p is fixed. Let be nonzero elements in F, and suppose that n is large enough.
be nonzero elements in F, and suppose that n is large enough.
Then for every element t in F there is a HAP whose sum is t.
Remarks
1) If all the s are plus or minus one then this conjecture is equivalent to a positive solution for EDP.
s are plus or minus one then this conjecture is equivalent to a positive solution for EDP.
2) When we try to apply the polynomial method to EDP this more general conjecture comes up naturally and I will elaborate on this a little.
3) The conjecture is interesting already for t=0. (I dont know if it we can reduce it to this case.)
4) Of course, maybe it is obviously false, but I dont see it off-hand. I will be happy to see a counterexample.
5) The probabilistic heuristics that we discussed does not conflict with this conjecture. (Even when p is roughly sqrt log n.)
Let and
and  be variables.
be variables.
Let
Let .
.
The direct approach via the polynomial method to EDP sais that if we start with Q and then reduce it to sum of square free monomials in the s by using
s by using 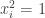 , then when n is large we get identically zero. One critique against such an approach is that the multilinear reduction (i.e. forcing the identities
, then when n is large we get identically zero. One critique against such an approach is that the multilinear reduction (i.e. forcing the identities 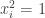 for every
for every  is where the combinatorics is hidden and the algebraic formulation is artificial. However, if Conjecture (*) is true then the task is much simpler and algebraically more natural. Conjecture A is equivalent to
is where the combinatorics is hidden and the algebraic formulation is artificial. However, if Conjecture (*) is true then the task is much simpler and algebraically more natural. Conjecture A is equivalent to
Conjecture (**): Over the field of p elements if n is large enough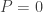 .
.
When we describe explicitly the polynomial P it is complicated but not terribly so. For example the free term (which corresponds to the t=0 case of Conjecture (*)) is the product of the partial sums of variables over all HOP’s. For other power of t we need to take some elementary symmetric functions of such partial sums.
March 7, 2010 at 11:23 am
I think this conjecture is very interesting. We could generalize this to APs, then the conjecture would be that for any t there exists and
and  such that
such that  . Here I think that the requirement
. Here I think that the requirement  is unnatural, and if we remove this, we get a weaker conjecture. That led me to this conjecture that is weaker than yours, but still stronger than EDP:
is unnatural, and if we remove this, we get a weaker conjecture. That led me to this conjecture that is weaker than yours, but still stronger than EDP:
Let F be a field with p elements and let be an infinite sequence of non-zero elements in F. Now for every t in F there is
be an infinite sequence of non-zero elements in F. Now for every t in F there is  such that
such that  . (That is every element in F is a HAP-drift in the sequence)
. (That is every element in F is a HAP-drift in the sequence)
March 7, 2010 at 1:20 pm
Dear Sune, I like the drift version of the conjecture. Of course you can write it algebraically by adding more terms to the product in the definitions of P and Q. In my conjecture (*) the case t=0 is already interesting and perhaps there it is not needed to require that the retms are non zero. (In other words, perhaps the free term of Q is identically zero for n large enough.) For the drift case, of course, the t=0 is very easy.
March 7, 2010 at 4:34 pm
Let G(p,t) be the length of the longest sequence of nonzero elements of GF(p) whose HAPs never sum to p, and let G(p) be the max of G(p,t) over all t.
G(2) = 1, trivially.
G(3) = 5, as after the first term the rest are forced: 11212 is the unique best.
1344 4244 3444 3342 4132 1322 2334 4231 1441 1314 4241 1414 4234 2422 3342 3332 3243 3233 1334 3233 2231 2221 3234 2134 3311 4144 2442 4441 1134 3311 2123 1324 2342 1414 4141 1323 4213 2444 242
No pattern, just found by (an ongoing) depth first search.
For G(5,t), there’s some hope of understanding it by hand. First, since we can multiply the entire sequence by , we get
, we get  . So,
. So,  is typical. As sequence avoiding -2 contains only terms -1, 1, 2, and by the Mathias result it must contain infinitely many 2’s. This seems like enough to get started…
is typical. As sequence avoiding -2 contains only terms -1, 1, 2, and by the Mathias result it must contain infinitely many 2’s. This seems like enough to get started…
March 7, 2010 at 4:49 pm
“sum to p” should have “sum to t”, of course.
March 7, 2010 at 5:51 pm
(the argument why G(5,i) does not depend on a nonzero i is not clear.)
March 7, 2010 at 9:03 pm
If we have a sequence with no HAP summing to t, with
with no HAP summing to t, with  , then
, then  has no HAP summing to
has no HAP summing to  . Thus,
. Thus,  for nonzero s,t, and so by symmetry G(p,1)=G(p,2)=…=G(p,p-1).
for nonzero s,t, and so by symmetry G(p,1)=G(p,2)=…=G(p,p-1).
March 7, 2010 at 2:35 am |
Klas, regarding your inquiry about parallel SDP solvers
CSDP has a parallel OpenMP version. See
https://projects.coin-or.org/Csdp/
I’ve used it in the past and it is easy to install.
June 21, 2010 at 12:09 pm |
[…] relation to this question, it is worth looking at this comment of Sune’s, and the surrounding […]