Here is a simple but important fact about bipartite graphs. Let 



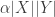
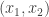
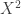
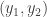
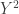
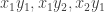


The proof is very simple. For each 
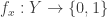






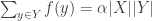
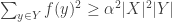
But by the Cauchy-Schwarz inequality again,
That last expression is 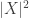
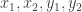
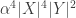


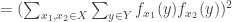
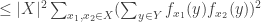
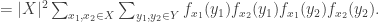
Essentially the same proof applies to a weighted bipartite graph. That is, if you have some real weights 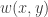
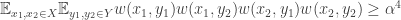
(One can also generalize this statement to complex weights if one puts in appropriate conjugates.) One way of thinking of this is that the sum on the left-hand side goes down if you apply an averaging projection to 
Thus, an appropriate weighted count of 4-cycles is minimized over all systems of weights with a given average when all the weights are equal.
Sidorenko’s conjecture is the statement that the same is true for any bipartite graph one might care to count. Or to be more precise, it is the statement that if you apply the averaging projection to a graph (rather than a weighted graph), then the count goes down: I haven’t checked whether the conjecture is still reasonable for weighted graphs, though standard arguments show that if it is true then it will still be true for weighted graphs if the weights are between 0 and 1, and hence (by rescaling) for all non-negative weights.
Here is a more formal statement of the conjecture.
Conjecture Let 
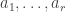
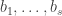



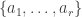


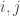


This feels like the kind of statement that is either false with a simple counterexample or true with a simple proof. But this impression is incorrect.
My interest in the problem was aroused when I taught a graduate-level course in additive combinatorics and related ideas last year, and set a question that I wrongly thought I had solved, which is Sidorenko’s conjecture in the case of a path of length 3. That is, I asked for a proof or disproof of the statement that if 

I also tried to prove the statement using the Cauchy-Schwarz inequality, but nothing I did seemed to work, and eventually I filed it away in my mind under the heading “unexpectedly hard problem”.
At some point around then I heard about a paper of Balázs Szegedy that used entropy to prove all (then) known cases of Sidorenko’s conjecture as well as a few more. I looked at the paper, but it was hard to extract from it a short easy proof for paths of length 3, because it is concerned with proving as general a result as possible, which necessitates setting up quite a lot of abstract language. If you’re like me, what you really need in order to understand a general result is (at least in complicated cases) not the actual proof of the result, but more like a proof of a special case that is general enough that once you’ve understood that you know that you could in principle think hard about what you used in order to extract from the argument as general a result as possible.
In order to get to that point, I set the paper as a mini-seminar topic for my research student Jason Long, and everything that follows is “joint work” in the sense that he gave a nice presentation of the paper, after which we had a discussion about what was actually going on in small cases, which led to a particularly simple proof for paths of length 3, which works just as well for all trees, as well as a somewhat more complicated proof for 4-cycles. (These proofs are entirely due to Szegedy, but we stripped them of all the abstract language, the result of which, to me at any rate, is to expose what is going on and what was presumably going on in Szegedy’s mind when he proved the more general result.) Actually, this doesn’t explain the whole paper, even in the sense just described, since we did not discuss a final section in which Szegedy deals with more complicated examples that don’t follow from his first approach, but it does at least show very clearly how entropy enters the picture.
I think it is possible to identify three ideas that drive the proof for paths of length 3. They are as follows.
- Recall that the entropy of a probability distribution
on a finite set
. By Jensen’s inequality, this is maximized for the uniform distribution, when it takes the value
. It follows that one way of proving that
is to identify a probability distribution
on
.
- That may look like a mad idea at first, since if anything is going to work, the uniform distribution will. However, it is not necessarily a mad idea, because there might in principle be a non-uniform distribution with entropy that was much easier to calculate than that of the uniform distribution.
- If
of vertices of
and
are all edges, that is not in general uniform and that has very nice properties.
The distribution mentioned in 3 is easy to describe. You first pick an edge 
Having picked the edge 

The beautiful property of this distribution is that the edges 
Now let us turn to point 2. The only conceivable advantage of using a non-uniform distribution and an entropy argument is that if we are lucky then the entropy will be easy to calculate and will give us a good enough bound to prove what we want. The reason this stands a chance of being true is that entropy has some very nice properties. Let me briefly review those.
It will be convenient to talk about entropy of random variables rather than probability distributions: if 
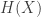

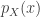
![\mathbb{P}[X=x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BX%3Dx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
We also need the notion of conditional entropy 

If you think of the entropy of 


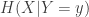
where 


Now let us calculate the entropy of the distribution we have defined on labelled paths of length 3. Let 

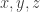

Now the nice properties of our distribution come into play. Note first that if you know that 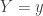
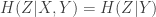

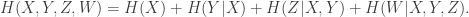
Now for each 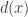

![\mathbb{P}[X=x]=d(x)/m](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D%5BX%3Dx%5D%3Dd%28x%29%2Fm&bg=ffffff&fg=333333&s=0&c=20201002)

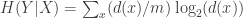
and because the edges all have the same distribution, we get the same answer for 

As for the entropy

Putting all this together, we get that

By Jensen’s inequality, the second term is minimized if 

If the average degree is 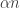
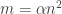

The moral here is that once one uses the nice distribution and calculates its entropy, the calculations follow very easily from the standard properties of conditional entropy, and they give exactly what we need — that the entropy must be at least 

Now I’ll prove the conjecture for 4-cycles. In a way this is a perverse thing to do, since as we have already seen, one can prove this case easily using Cauchy-Schwarz. However, the argument just given generalizes very straightforwardly to trees (and therefore forests), which makes the 4-cycle the simplest case that we have not yet covered, since it is the simplest bipartite graph that contains a cycle. Also, it is quite interesting that there should be a genuinely different proof for the 4-cycles case that is still natural.
What we would like for the proof to work is a distribution on the 4-cycles 




So now let us work out the entropy of this distribution. Again let 

From the second and third equations we get that

and substituting this into the first gives us




As before, we have that
and

Therefore,
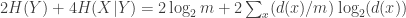
As for the term 


The remaining part is minimized when every 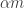


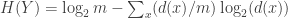
This kind of argument deals with a fairly large class of graphs — to get the argument to work it is necessary for the graph to be built up in a certain way, but that covers many cases of the conjecture.

November 18, 2015 at 12:45 am |
There is an essentially equivalent approach to Sidorenko-for-paths that hides the entropy in the use of the tensor power trick, which I used in this paper with Nets Katz: http://arxiv.org/abs/math/9906097 . The key observation is that the vertices of degree at least in
in  capture at least half the edges of the graph. By restricting to this subgraph and using Sidorenko inductively on the length of the path, one can get the Sidorenko bound losing a multiplicative constant depending on the length of the path. But then one can recover this constant loss via the tensor power trick.
capture at least half the edges of the graph. By restricting to this subgraph and using Sidorenko inductively on the length of the path, one can get the Sidorenko bound losing a multiplicative constant depending on the length of the path. But then one can recover this constant loss via the tensor power trick.
November 18, 2015 at 10:12 am
How do you see that entropy is hidden in the tensor power trick? (I only have a rough intuition for entropy, but I am familiar with the tensor power trick.)
November 18, 2015 at 11:10 am
I may be wrong, but the entropy proof seems to me to be somehow genuinely different to the ‘induction to prove a weaker statement + tensor-power trick’ proof. I’m aware that entropy proofs can sometimes be used instead of inductive proofs, but what is the equivalence between these two proofs, exactly?
November 18, 2015 at 11:21 am
I don’t have a full answer to K’s question, but I do have an observation that is almost certainly relevant. It is a well-known fact that entropy is basically characterized by a few simple facts such as that the entropy of the uniform distribution on is 1 and that
is 1 and that  . The proof is reasonably straightforward once you manage to show that the entropy of the distribution on
. The proof is reasonably straightforward once you manage to show that the entropy of the distribution on  that takes the value
that takes the value  with probability
with probability  is
is
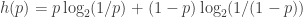 .
. independent Bernoulli variables (each with probability
independent Bernoulli variables (each with probability  of being 0) and exploit the fact that it looks somewhat like a uniform distribution on the subsets of size
of being 0) and exploit the fact that it looks somewhat like a uniform distribution on the subsets of size  from an
from an  -set. (This is an oversimplification.) Also, it is just
-set. (This is an oversimplification.) Also, it is just  times the entropy you’re trying to calculate. And the reason the calculations give you what you want is closely related to the fact that
times the entropy you’re trying to calculate. And the reason the calculations give you what you want is closely related to the fact that  .
.
And the natural way to show that seems to be (by which I mean it’s the proof I found when I worked it out for myself and I think there’s a good chance that it is the standard proof, but haven’t actually got round to looking it up) to use the tensor power trick. That is, you look at the distribution of
November 18, 2015 at 9:05 am |
See Lemma 3.8 here for a very short proof
Click to access ar2.pdf
November 18, 2015 at 9:25 am |
It’s the same as the one Terry just described.
November 18, 2015 at 4:00 pm |
This is absolutely fascinating for someone who comes from the information theory end of things. A couple of comments to translate things into information theorists’ language (apologies if these are completely obvious to you!):
1. I think the “deducing the value of entropy from the tensor power trick” you describe is based on the Asymptotic Equipartion Property (aka Shannon-McMillan-Breiman Theorem). That is, there is a “typical set” made up of about strings of
strings of  s and
s and  s, each with probability about
s, each with probability about  . You are essentially using that the size of the typical set is about
. You are essentially using that the size of the typical set is about 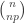 .
.
2. When you bound the size of using Jensen in the “3-cycle” case, this is really just maximum entropy again. That is, the
using Jensen in the “3-cycle” case, this is really just maximum entropy again. That is, the  gives a probability distribution (say
gives a probability distribution (say 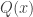 ) supported on
) supported on  values, and the term you want to minimise is
values, and the term you want to minimise is  , which is therefore greater than
, which is therefore greater than  . It may even be preferable to write this as relative entropy from a uniform distribution on
. It may even be preferable to write this as relative entropy from a uniform distribution on  values.
values.
November 18, 2015 at 6:50 pm |
Apologies if this is either old news or contained in what’s already been discussed, but a low-tech proof for length 3 appears to be given at http://mathoverflow.net/questions/189222/cauchy-schwarz-proof-of-sidorenko-for-3-edge-path-blakley-roy-inequality
November 18, 2015 at 9:54 pm
That was new to me, so thanks for the link. I’m not sure that the proof is lower tech than the entropy argument above, but it’s interesting. (I hope fedja was joking when he described the Cauchy-Schwarz inequality as a high-tech tool …)
November 18, 2015 at 10:47 pm |
I imagine he _was_ joking, since he has used rather more sophisticated technology when required ( https://en.wikipedia.org/wiki/Fedor_Nazarov ).
November 19, 2015 at 4:27 pm |
I should perhaps point out that results similar to Szegedy’s were also obtained by myself, Kim, Lee and Lee in the following paper:
Click to access 1510.06533v1.pdf
The approaches look quite different at the outset, Szegedy’s being procedural, determining general conditions under which two Sidorenko graphs may be glued together to give another Sidorenko graph, while our results yield a specific class of graphs built from trees in a certain tree-like way that satisfy the conjecture. However, the idea at the core of both results, which you describe so well here, is essentially the same. A lengthier discussion of the relationship between the results can be found in the conclusion to our paper.
November 19, 2015 at 4:40 pm
Many thanks for this link too — also something I was unaware of.
December 14, 2015 at 11:30 pm
I think this is a miss-understanding. My approach does not give a general condition under which Sidorenko graphs can be glued together to form another Sidorenko graph. I actually give a concrete family of graphs that are Sidorenko. (I call them thick graphs) It happens to be true that thick graphs contains all known exapmples for Sidorenko graphs.
November 20, 2015 at 4:48 am |
Such entropy inequalities are discussed in Friedgut’s beautiful
“Hypergraphs, Entropy, and Inequalities”
Click to access KKLBKKKL.pdf
This entropy argument for graph homomorphism inequalities also shows up in Kopparty and Rossman “Homomorphism Domination Exponent”
Click to access 1004.2485v1.pdf
November 24, 2015 at 1:03 am
Sigh! I thought that convexity played a central role in inequalities. Now Friedgut tells me that I only really need to worry about the convex function .
.
Thanks for the reference.
November 26, 2015 at 6:53 pm |
More precise formulas for the Sidorenko-for-trees in terms of the degree sequence were proved in
http://homepages.math.uic.edu/~mubayi/papers/tree-reg.pdf.
And a similar result for isomorphisms (not homomorphisms) of trees
was very recently proved by Verstraete and myself
http://arxiv.org/abs/1511.07274
I’m not sure if these are related to entropy.
December 7, 2015 at 2:20 pm
Hi Dhruv, I don’t know how to relate the second one to entropy, but something can be said for the first one: having a ‘right’ count for trees means the equality holds for entropy inequalities, and it happens if and only if the target graph is (almost) regular.
Tim’s note for a path of length 3 can be generalised to any trees, so it seems the first result of yours can be derived by carefully looking at equality conditions of the entropy analysis. The generalised analysis for trees can also be found in the paper of myself, David, Choongbum and Jeong Han, mentioned by David above. This philosophy of tracking on equality conditions also allows us to connect Sidorenko’s conjecture to forcing conjecture.
January 21, 2016 at 1:17 pm |
[…] Mathematics related discussions « Entropy and Sidorenko’s conjecture — after Szegedy […]
June 24, 2019 at 7:02 am |
Hi,
I’m currently teaching entropy techniques in my probabilistic-method course at Weizmann, and stumbled over this thread.
I want to point out that in the proof for the number of $C_4$’s there’s no need to do any calculations or considerations regarding the degree distribution. Here’s a proof for any complete bipartite graph that exemplifies this.
Claim: Let $G$ be a bipartite graph on two vertex sets $V_x,V_y$, each of size $n$, with $\alpha n^2$ edges. Then the number of homomorphisms of $K_{s,t}$ into $G$ (with the convention that the $s$ vertices belong to $V_x$ and the $t$ vertices belong to $V_y$ is at most $n^{s+t}\alpha^{st}$.
Proof: Let (X,Y) be a random variable taking values in $V_x \times V_y$, distributed uniformly on the edges of $G$. It has entropy $\log(\alpha n^2)$. It can be sampled by sampling $X=x_1$ from the marginal distribution of $X$ and then sampling $Y=y_1$ from the conditional marginal of $Y|X=x_1$. Next, consider the random variable $(X_1,Y_1,….Y_t)$ with $X_1=x_1$ sampled as before, and $Y_1=y_1,….Y_n=y_n$ sampled as before, conditioned on $X_1=x_1$, but independently. Since the $Y$’s are chosen independently we have
$H(X_1,Y_1,….Y_n) = H(X_1) + \sum H(Y_i |X_1) = tH(X,Y) – (t-1)H(X) \ge \log (\alpha^t n^{t+1})$, where I’ve used the trivial bound $H(X) \le \log(n)$.
Next, swap and repeat; consider the random variable $((Y_1,….Y_t),X_1)$, with the above distribution. It can be sampled by taking $(Y_1,….Y_t)$ from its marginal (I’m referring to the joint marginal of the $Y$’s), and then choosing $X_1$ from the conditional marginal. So do this, but choose $X_1,….X_s$ from the conditional marginal independently.
We now get, similarly to before,
$H(Y_1,…Y_t,X_1,….X_n)= H(Y_1,…Y_t) + \sum H(X_j| Y_1,…Y_t)=
sH(Y_1,….,Y_t,X_1) – (s-1)H(Y_1,….Y_t) \ge \log (\alpha^{st} n^{s+t}$, where I’ve used what seems like an incredibly wasteful bound $H(Y_1,…Y_t) \le \log(n^t)$.
To summarize: the random variable $(X_1,…X_s,Y_1,…Y_t)$ is supported on vertex sets which support a homomorphism of $K_s,t$ into $G$, but not necessarily uniformly. Denoting the set of all homomorphisms by $\Sigma$ this gives
$ \log (\alpha^{st} n^{s+t} \le H(X_1,….X_s,Y_1,…,Y_t) \le \log (|\Sigma)$ as required.
June 24, 2019 at 10:34 pm
Dear Prof. Friedgut,
Your swap-and-repeat technique is very close to our information-theoretic approach (https://arxiv.org/abs/1510.06533v2). In particular, once you observe further that $(Y_1,\cdots,Y_t,X_1)$ is ‘well-projected’ onto $(Y_i)_{i\in I}, X_1)$ for any subset $I\subset [t]$, then the result by Conlon-Fox-Sudakov follows. A further generalisation led us to Section 2 in our paper.
There are more applications of an analogous approach, for example, my paper with David (Section 5.3 in https://arxiv.org/pdf/1611.05784.pdf) and my own paper (https://arxiv.org/abs/1707.02916).
Best,
Joonkyung
August 13, 2019 at 5:49 pm
Nice! Thanks for sharing. Ehud
June 24, 2019 at 8:12 am |
Here’s a (hopefully) better latexed version:
Claim: Let be a bipartite graph on two vertex sets
be a bipartite graph on two vertex sets 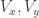 , each of size
, each of size  , with
, with  edges. Then the number of homomorphisms of
edges. Then the number of homomorphisms of  into
into  (with the convention that the
(with the convention that the  vertices belong to
vertices belong to 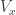 and the
and the  vertices belong to
vertices belong to  is at most
is at most  .
.
Proof: Let be a random variable taking values in
be a random variable taking values in  , distributed uniformly on the edges of
, distributed uniformly on the edges of  . It has entropy
. It has entropy  . It can be sampled by sampling
. It can be sampled by sampling  from the marginal distribution of
from the marginal distribution of  and then sampling
and then sampling  from the conditional marginal of
from the conditional marginal of  . Next, consider the random variable
. Next, consider the random variable  with
with  sampled as before, and
sampled as before, and  sampled as before, conditioned on
sampled as before, conditioned on  , but independently. Since the
, but independently. Since the  ‘s are chosen independently we have
‘s are chosen independently we have

 .
.
where I’ve used the trivial bound
Next, swap and repeat; consider the random variable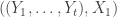 , with the above distribution. It can be sampled by taking
, with the above distribution. It can be sampled by taking  from its marginal (I’m referring to the joint marginal of the
from its marginal (I’m referring to the joint marginal of the  ‘s), and then choosing
‘s), and then choosing  from the conditional marginal. So do this, but choose
from the conditional marginal. So do this, but choose 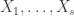 from the conditional marginal independently.
from the conditional marginal independently.



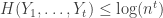 .
.
We now get, similarly to before,
where I’ve used what seems like an incredibly wasteful bound
To summarize: the random variable is supported on vertex sets which support a homomorphism of
is supported on vertex sets which support a homomorphism of  into
into  , but not necessarily uniformly. Denoting the set of all homomorphisms by
, but not necessarily uniformly. Denoting the set of all homomorphisms by  this gives
this gives
 as required.
as required.