This post is intended as a launch of Polymath9. I have no idea how the project will go, but I think it may be rather short lived, since the difficulties I am having at the moment look as though they could turn out to be serious ones that rule out any approach along the lines I have been thinking about. However, it is difficult to say that with any certainty, because the approach is fairly flexible, so even if the precise statements I have been trying to prove are false, it might be possible to come up with variants that are true. In a way I find that a good state of affairs, because it increases the chances of proving something interesting. Obviously it increases the chances of proving that P
I’ve thought a little about what phrase to attach to the project (the equivalent of “density Hales-Jewett” or “Erdős discrepancy problem”). I don’t want to call it “P versus NP” because that is misleading: the project I have in mind is much more specific than that. It is to assess whether there is any possibility of proving complexity lower bounds by drawing inspiration from Martin’s proof of Borel determinacy. Only if the answer turned out to be yes, which for various reasons seems unlikely at the moment, would it be reasonable to think of this as a genuine attack on the P versus NP problem. So the phrase I’ve gone for is “discretized Borel determinacy”. That’s what DBD stands for above. It’s not a perfect description, but it will do.
For the rest of this post, I want to set out once again what the approach is, and then I want to explain where I am running into difficulties. I’m doing that to try to expose the soft underbelly of my proof attempt, in order to make it as easy as possible for somebody else to stick the knife in. (One could think of this as a kind of Popperian method of assessing the plausibility of the approach.) Another thing I’ll try to do is ask a number of precise questions that ought not to be impossible to solve and that can be thought about in isolation. Answers to any of these questions would, I think, be very helpful, either in demolishing the approach or in advancing it.
Reminder of basic definitions
This section is copied from my previous post.
I define a complexity structure to be a subset 







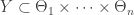
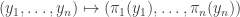
I call a subset of a complexity structure 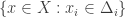
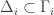
The non-trivial basic sets in the complexity structure 
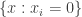


Given a complexity structure 
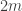
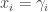
- Player I must specify coordinates from
to
- Player II must specify coordinates from
to
- At every stage of the game, there must be at least one
that satisfies all the specifications so far (so that the game can continue until all coordinates are specified).
Note that I do not insist that the coordinates are specified in any particular order: just that Player I’s specifications concern the first half and Player II’s the second.
To determine who wins the game, we need a payoff set, which is simply a subset 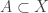


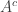
Because the game is finite, it is determined. Therefore, we have the following Ramseyish statement: given any 2-colouring of a complexity structure
Given a complexity structure 


This gives us a potential method for showing that a subset 

The definition of a Ramsey lift is closely modelled on Martin’s definition of a lift from one game to another.
What I would love to be able to show
Suppose that we have a suitable definition of “simple”. Then I would like to prove the following.
- If a set
has polynomial circuit complexity, then there exists a Ramsey lift
of
is much less than doubly exponential.
- If
- There exists an NP set
the smallest Ramsey lift that makes
Obviously, the first and third statements combined would show that P
Having the first and second statements would be a whole lot better than just having the first, since then we would have not just a property that follows non-trivially from low circuit complexity, but a property that distinguishes between functions of low circuit complexity and random functions. Even if we could not then go on to show that it distinguished between functions of low circuit complexity and some function in NP, we would at least have got round the natural-proofs barrier, which, given how hard that seems to be to do, would be worth doing for its own sake. (Again this is not quite guaranteed, since again one needs to be confident that the distinguishing property is interestingly different from the property of having low circuit complexity.)
As I said in my previous post, I think there are three reasons that, when combined, justify thinking about this potential distinguishing property, despite the small probability that it will work. The first is of course that the P versus NP problem is important and difficult enough that it is worth pursuing any approach that you don’t yet know to be hopeless. The second is that the property didn’t just come out of nowhere: it came from thinking about a possible analogy with an infinitary result (that in some rather strange sense it is harder to prove determinacy of analytic sets than it is to prove determinacy of Borel sets). And finally, the property appears not to be even close to a natural property in the Razborov-Rudich sense: for one thing it quantifies over all possible complexity structures that are not too much bigger than
It is conceivable that the property might turn out to be natural after all. For instance, maybe the property of preserving I-winning and II-winning sets is so hard to achieve (I have certainly found it hard to come up with examples) that all possible Ramsey lifts are of some very special type, and perhaps that makes checking whether there is a Ramsey lift that simplifies a given set possible with a polynomial-time algorithm (as always, polynomial in 
An approach that initially looked promising, but that ran up against a serious difficulty
Let 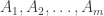





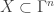

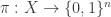

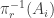
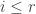
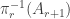
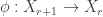
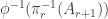



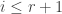
Thus, if we can find a very efficient Ramsey lift that turns a given intersection or union of two simple sets into a simple set, then we will be done. “Very efficient” means efficient enough that repeating the process
What might we take as our definition of “simple”? The idea I had that ran into trouble was the following. I defined “simple” to be “basic”. I then tried to find a very efficient lift — I was hoping to multiply the size of the alphabet by a constant — that would take the intersection of two basic sets to a basic set.
Let us very temporarily define a basic set to be 



Now let us apply that to the 
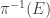
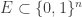
This is highly undesirable, because it means that we have shown that the property “Can be made simple by means of an efficient Ramsey lift” does not distinguish functions of low circuit complexity from arbitrary functions.
Because of that undesirability, I have not tried as hard as I might have to find such a lift. An initial attempt can be found in this tiddler. Note that the argument I have just given does not show that there cannot be a Ramsey lift that turns an 
Problem 1. Let 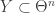

In fact, if all one wants to do is disprove the statement that for a random set there is a doubly exponential lower bound, it is enough to obtain a bound here of the form 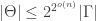
Another difficulty
The above observation tells us that we are in trouble if we have a definition of “simple” such that simple sets are closed under unions and intersections. More generally, we have a problem if we can modify our existing definition so that it becomes closed under unions and intersections. (What I have in mind when I write this is the example of basic sets. Those are not closed under intersections and unions, but if one could prove that every intersection of two basic sets can be lifted to a basic set, then, as I argued above, one could probably strengthen that result and show that every intersection of two basic sets can be lifted to a 1-basic set. And the 1-basic sets are closed under intersections and unions.)
Before I go on to discuss what other definitions of “simple” one might try, I want to discuss a second difficulty, because it gives rise to another statement that, if true, would deal a serious blow to this approach.
In the previous post, I gave an example of a lift that provides us with what I think of as the “trivial upper bound”: a Ramsey lift that turns every single subset of 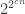


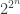
The reason this is troubling is that even if I forget all about simplifying any set
Maybe I can try to be slightly more precise about what I mean there. All the lifts I have considered (and I don’t think this is much of a restriction) take the form of sets 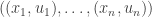

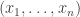
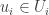
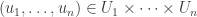
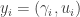
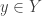


Suppose now that this extra information 
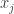
So it looks as though any “extra information” we declare has to be rather crude, in the sense that it does not cut down too drastically the set in which the game is played. But I have no example of a Ramsey lift with this property. What’s more, the kind of difficulty I run into makes me worry that such a lift may not exist. If it doesn’t, then that too will be a serious blow to the approach.
Let me ask a concrete problem, the answer to which would I think be very useful. It is a considerable weakening of Problem 1.
Problem 2. Let 
The main concern is that 
I have not sorted out completely what “non-trivial” means here, but let me give a class of examples that I consider trivial. Let 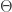


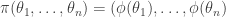

I claim that this is a Ramsey lift. Indeed, suppose that 


To put that more formally, if the specifications so far are 
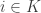


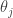
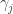
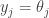
A similar argument works for winning sets for Player II.
It is the fact that this can always be done that makes the lift in some sense “trivial”. Another way of thinking about it is that there is an equivalence relation on
As far as I can tell at this stage, the problem is interesting if one takes “non-trivial” to mean not of the form I have just described. However, I reserve the right to respond to other examples by enlarging this definition of triviality. The real test of non-triviality is that an interesting Ramsey lift is one that has the potential to simplify sets.
A positive answer to the problem above will not help us if
A simple observation
I stopped writing for a few hours after that last paragraph, and during those few hours I realized that my definition of non-triviality was not wide enough. Before I explain why not, I want to discuss a worry I have had for a while, and a very simple observation that explains why I don’t have it any more.
Because the worry was unfounded, it is rather hard to explain it, but let me try. Let’s suppose that we are trying to find an interesting Ramsey lift 

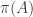
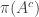

The observation I have now made is almost embarrassingly simple: if
It is worth drawing attention to the way that it seems to be most convenient to prove that a lift
Lemma. Suppose that
(i) The image of every winning subset of
(ii) The inverse image of every winning subset of
Proof. Suppose that the second condition holds and let 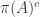
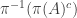
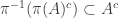
Conversely, suppose that the first condition holds and let 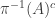
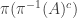
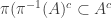
Another way of saying all this is that if we want to prove that a map 
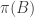
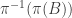
A slightly less trivial, but still uninteresting, class of Ramsey lifts
The quick description of these is as follows: take a trivial Ramsey lift of the kind I described earlier (one that duplicates each coordinate several times) and pass to a random subset of it.
Let me sketch an argument for why that, or something similar to it, works. The reason is basically the same as the reason that the trivial lift works. For the sake of clarity let me introduce a little notation. I’ll start with a complexity structure 

Now let 
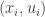

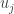

Typically, the proportion of 
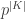
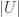
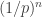
A wider definition of non-triviality
Let 
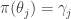
This is an attempt to describe the property that makes it very easy to lift strategies in
One thing that is probably true but that it would be good to confirm is that a Ramsey lift of this simple kind cannot be used to simplify sets. I’ll state this as a problem, but I’m expecting it to be an easy exercise.
Problem 3. Let
(A quick reminder: in a general complexity structure, I define the straight-line complexity of a set
Assuming that the answer to Problem 3 is yes, then the next obvious question is this. It’s the same as Problem 2 except that now we have a candidate definition of “non-trivial”.
Problem 4. Let
I very much hope that the answer is yes. I was beginning to worry that it was no, but after the simple observation above, my perception of how difficult it is to create Ramsey lifts has altered. In that direction, let me ask a slightly more specific problem.
Problem 5. Is there a “just-do-it” approach to creating Ramsey lifts?
What I mean there is a procedure for enumerating all the winning sets in
Let me also recall a problem from the previous post.
Problem 6. Let
I would also be interested in a Ramsey lift that made
Matters of procedure
Maybe that’s enough mathematics for one post. I’d like to finish by trying to clarify what I mean by “micro-publication” on the TiddlySpace document. I can’t do that completely, because I’m expecting to learn on the job to some extent.
I’ll begin by saying that Jason Dyer answered a question I asked in the previous post, and thereby became the first person to be micro-published. I don’t know whether it was his intention, but anyway I was pleased to have a contribution suitable for this purpose. He provided an example that showed that a certain lift that turns the parity function into a basic function was (as expected) not a Ramsey lift. It can be found here. There are several related lifts for which examples have not yet been found. See this tiddler for details.
Jason’s micro-publication should not be thought of as typical, however, since it just takes a question and answers it. Obviously it’s great if that can be done, but what I think of as the norm is not answering questions but more like this: you take a question, decide that it cannot be answered straight away, and instead generate new questions that should ideally have the following two properties.
- They are probably easier than the original question.
- If they can be answered, then the original question will probably become easier.
One could call questions of that kind “splitting questions”, because in a sense they split up the original task into smaller and simpler tasks — or at least there is some chance that they do so.
What I have not quite decided is what constitutes a micro-publication. Suppose, for example, somebody has a useful comment about a question, but does not generate any new questions. Does that count? And what if somebody else, motivated by the useful comment, comes up with a good question? I think what I’ll probably want to do in a case like that is write a tiddler with the useful comment and the splitting question or questions, carefully attributing each part to the person who contributed it, with links to the relevant blog comments.
Also, I think that when someone asks a good question, I will automatically create an empty tiddler for it. So one way of working out quickly where there are loose ends that need tying up is to look for empty tiddlers. (TiddlySpace makes this easy — their titles are in italics.)
Some people may be tempted to think hard about a question and then present a fairly highly developed answer to it. If you feel this temptation, then I’d be very grateful if you could do one of the following two things.
- Resist it.
- Keep a careful record of all the questions you ask in the process of answering the original question, so that your thought processes can be properly represented on the proof-discovery tree.
By “resist it”, what I mean is not that you should avoid thinking hard about a question, but merely that each time you generate new questions, you should write up your thoughts so far in the form of blog comments, so that we get the thought process and not just the answer. The main point is that if we end up proving something interesting, then I would like it to be as clear as possible how we did it. With this project, I am at least as interested in trying to improve my understanding of the research process as I am in trying to make progress on the P versus NP problem.

November 3, 2013 at 5:55 pm |
A quick comment to say that I am thinking about Problem 3 above: that is, I am attempting to show that a trivial lift (according to the definition in the post) cannot reduce the circuit complexity of a set. The problem is set out in this tiddler here. It doesn’t seem completely straightforward, so I have come up with two splitting questions and am thinking about the first. I am writing up my thoughts about that first subquestion in this tiddler.
November 3, 2013 at 7:27 pm
The first subquestion turned out to be easy, so the next thing to do is decide whether it can be generalized to answer the question I was originally trying to answer.
November 5, 2013 at 10:39 pm
I have subsequently answered some more splitting questions. For instance, a trivial lift cannot turn a set that is not an intersection of two basic sets into a set that is an intersection of two basic sets. Unfortunately, the proof doesn’t seem general enough to yield the general case.
November 3, 2013 at 8:43 pm |
[…] Polymath 9 has started. See this post: https://gowers.wordpress.com/2013/11/03/dbd1-initial-post/ […]
November 4, 2013 at 4:01 am |
I’m fine with my micro-publishing page, except maybe at the end we should have the cases with Player II responding take the cases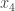 ,
,  , and
, and 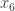 in order?
in order?
Going on; I’ve only started thinking about this, but trying to stick to your philosophical ideal:
Regarding the case where Player I always specifies the parity on the first move, it’s clear just by checking cases that Player I’s winning set is reduced to null when n = 2. I’m a little less clear on how to generalize this to larger n, but I imagine it can happen by doing parity locks across the sequence ( for odd i) making it so Player I has no control over parity and Player II has just enough control to foil the payoff set solely on that criterion.
for odd i) making it so Player I has no control over parity and Player II has just enough control to foil the payoff set solely on that criterion.
As far as new Ramsey lifts go, I was thinking about a variant where three versions of the game are played simultaneously, and a player needs to win two out of the three to win. This isn’t an obvious lift fail to me and it also doesn’t increase the alphabet much but it isn’t obvious what the lift would be, exactly. I’ll write it up more formally when I have time.
November 4, 2013 at 9:19 am
I’d be happy to change the order, but before I do, let me explain why I instinctively ordered the cases as I did. Its that I felt that the case where Player II responds by specifying first is in some sense the “real” case of interest, whereas the other two are cases where Player II does something a bit strange and it’s pretty obvious that he won’t win but you have to check.
first is in some sense the “real” case of interest, whereas the other two are cases where Player II does something a bit strange and it’s pretty obvious that he won’t win but you have to check.
Another possible reordering would be to pair coordinate with coordinate
with coordinate 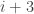 . In that case, the natural ordering of the cases would also be the ordering of the indices.
. In that case, the natural ordering of the cases would also be the ordering of the indices.
November 4, 2013 at 12:42 pm
Your second suggestion works for me.
For the game where Player I and Player II are forced to pick parity on their first move, let the payoff set be any sequence. Player I will clearly win the unmodified game, but in the parity-choice game Player II will have the last move and be able to choose so the parity opposes Player I. This will apply no matter the value of n.
November 4, 2013 at 3:32 pm
I’m afraid I don’t understand what you are saying about the game where Player I and Player II are forced to pick parities on their first move. Can you give more detail?
I’ve changed the indices in the “micro-publication”. I hope I have done so consistently.
November 4, 2013 at 2:08 pm |
[…] Gowers Proposed and launched a new polymath proposal aimed at a certain approach he has for proving that […]
November 5, 2013 at 12:12 am |
Sure:
Suppose the unmodified version of the game, and suppose is the null set. Clearly Player I will automatically win.
is the null set. Clearly Player I will automatically win.
Now suppose your variant where “both players commit themselves to their parities as soon as they make their first moves”. Player I plays and picks a parity ( ), Player II picks the opposite parity (
), Player II picks the opposite parity ( ). Play alternates until the last move, which is Player II’s. If the current parity is equal to
). Play alternates until the last move, which is Player II’s. If the current parity is equal to  , Player II puts a 0 in the last empty position and wins. If the current parity is equal to
, Player II puts a 0 in the last empty position and wins. If the current parity is equal to  , Player II puts a 1 in the last empty position and wins.
, Player II puts a 1 in the last empty position and wins.
November 5, 2013 at 9:18 am
But Player II doesn’t win because the eventual sequence belongs to .
.
November 5, 2013 at 2:19 pm
Doesn’t your revised version include the parities in ? Is it merely restricting the placement but doesn’t determine wins if a player picks a parity contradictory from the final sequence?
? Is it merely restricting the placement but doesn’t determine wins if a player picks a parity contradictory from the final sequence?
In any case, I’ve moved on to looking at the general case; I’m fairly certain at this point any sort of parity will cause the Ramsey lift to fail.
November 5, 2013 at 6:20 pm
I’m afraid I don’t understand your question. The modified game I had in mind is one where each player, when making their first move, promises that the parity of their moves will take a particular value. Their remaining moves have to keep that promise. The payoff set is still .
.
November 7, 2013 at 3:04 pm
I was implicitly making it so the meta-rule of parity was affecting the winning set in such a way that winning set + wrong parity still equaled a loss.
November 11, 2013 at 10:00 pm
I now have an example that shows that the modified version of the game where both players declare their parities at the beginning is not a Ramsey lift. The general idea behind the construction can probably be used to rule out a number of other over-simple candidates for Ramsey lifts but I haven’t looked into that yet.
November 5, 2013 at 1:38 am |
I am very happy to see such a different approach to this problem! I imagine that many theoretical computer scientists might be able to look at this more carefully and possibly contribute after Nov 11th (the STOC deadline). I definitely fall in that category…
It might be useful if there are concrete “morally related” technical problems (perhaps toy versions of the original problems) that could be stated concisely without requiring following all the definitions in this and the previous post. But perhaps once I really try to read it I’ll see these definitions are less scary than they look..
November 5, 2013 at 9:37 am
Ah — that’s good news that the silence so far from TCS experts has a possible explanation other than a general feeling that the approach is obviously doomed (which it may be, but if it is, then I think it would be useful to understand why).
Concerning the scariness of the definitions, I think it is important to distinguish between two types of scariness. One is to do with what they mean, and here I think they aren’t scary once one makes the effort to read them carefully. The definitions of a complexity structure and of maps between complexity structures are extremely elementary, the shrinking-neighbourhoods game is also easy to understand, and then the “Ramsey” maps are just maps that take sets that are a win for Player I/II to sets that are a win for Player I/II. I don’t think that’s scary at all.
However, there is another sense in which I myself find this definition scary even after thinking about it for some time, and that is that I have very little feel for how “flexible” it is. At the moment, I find it very hard to give interesting examples of these winning-set-preserving maps, but also very hard to think of any argument that would show that they are in any sense hard to come up with. So my general strategy at the moment is to forget all about P versus NP and just try to understand better this strange class of functions between complexity structures. Without that understanding, I think it will be difficult to say whether the approach has the slightest chance of working (unless it turns out to fall foul of some general barrier, but as said in the previous post, it doesn’t appear to me to be easy to naturalize).
November 5, 2013 at 2:27 pm
If there’s interest I might do another one of my “gentle introduction” posts like I did for Polymath 1 and 5, but I need a better feel for the problem first. (I’m still very shaky on the P vs NP connection because it looks nothing like the NP-related stuff I’ve seen before, but I suppose that’s part of the point.)
November 5, 2013 at 6:23 pm
I thought I didn’t have any toy problems, but I’ve now come up with a possibility, which is to look at the case . A complexity structure then becomes a bipartite graph. I think at least some of the problems may be non-trivial even in this very small case (since the alphabets can be large even if the dimension is small) and may shed useful light on some of the main problems, such as Problem 4.
. A complexity structure then becomes a bipartite graph. I think at least some of the problems may be non-trivial even in this very small case (since the alphabets can be large even if the dimension is small) and may shed useful light on some of the main problems, such as Problem 4.
November 7, 2013 at 3:12 pm
Regarding toy problems:
One problem that ought to be simple but I’m not sure the answer to — in the shrinking-neighbourhoods game, does converge, and if so, to what?
converge, and if so, to what?
November 7, 2013 at 4:54 pm
What’s here? I think I will be able to answer the question but I need more details to be sure of what you are asking.
here? I think I will be able to answer the question but I need more details to be sure of what you are asking.
November 7, 2013 at 5:31 pm
Let me rephrase and change letters so I don’t mix up with other uses:
Problem 1:
Let be the set of payoff sets that are I-winning.
be the set of payoff sets that are I-winning. be the set of all possible payoff sets.
be the set of all possible payoff sets.
Let
Does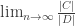 converge?
converge?
Problem 2:
Let be the set of payoff sets that are I-winning.
be the set of payoff sets that are I-winning. be the set of payoff sets that are II-winning.
be the set of payoff sets that are II-winning.
Let
Does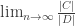 converge?
converge?
November 7, 2013 at 9:25 pm
Here’s a heuristic argument that both ratios tend to zero. If we choose a random set, then the advantage Player II gets from playing last means that it will almost certainly be a II-winning set. (That’s because Player I needs to get to the point where both Player II’s possible final moves result in points not in the random set.)
One can make this argument more precise if one insists that the players play their coordinates in a specific order. Then the critical probability for the game is the probability that satisfies the equation
that satisfies the equation  . The reason is that if you pick a random point, then its probability of being in the set is
. The reason is that if you pick a random point, then its probability of being in the set is  , so if you pick a random specification of all but the final coordinate of Player II, then the probability that Player II can’t go on and win after that specification is
, so if you pick a random specification of all but the final coordinate of Player II, then the probability that Player II can’t go on and win after that specification is 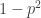 , so the probability that it is a winning position for Player I is
, so the probability that it is a winning position for Player I is 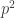 . If that equals
. If that equals 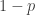 , then the probability that it is a winning position for Player II is
, then the probability that it is a winning position for Player II is  . Therefore, applying the same argument tells us that if we specify all but the final coordinate of each player, then the probability that we have a winning position for Player I is
. Therefore, applying the same argument tells us that if we specify all but the final coordinate of each player, then the probability that we have a winning position for Player I is  again, and back it goes.
again, and back it goes.
Thus, for that version of the game, the critical probability for the set to be I-winning is not 1/2 but something golden-ratio related (and greater than 1/2). Therefore, almost all sets are II-winning. (I’m relying on a general principle that there will almost certainly be an extremely sharp threshold here, so if is even a small amount less than the critical probability, then the chances of the set being I-winning ought to be absolutely tiny.)
is even a small amount less than the critical probability, then the chances of the set being I-winning ought to be absolutely tiny.)
I’m pretty sure that something similar ought to hold for the version of the game where the coordinates can be chosen in any order as long as each player sticks to his/her half.
November 5, 2013 at 9:01 am |
“Obviously, the first and third statements combined would show that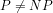 .”
.”
Without having quite grasped the subtlety of your approach and for what it is worth, here are two observations which suggest that set-theoretic formulations of the problem, as also those that involve ‘polynomial-time’, may not be well-defined from a computational perspective.
problem, as also those that involve ‘polynomial-time’, may not be well-defined from a computational perspective.
First: It is obscure why conventional wisdom treats it as self-evident that if we can define a polynomial-time checking relation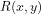 , which holds iff
, which holds iff  codes a propositional formula
codes a propositional formula  and
and  codes a truth assignment to the variables of
codes a truth assignment to the variables of  that makes
that makes  true, then
true, then  is necessarily algorithmically decidable.
is necessarily algorithmically decidable.
Reason: If is well-defined, we can always define a checking relation
is well-defined, we can always define a checking relation 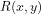 which holds iff
which holds iff  codes a propositional formula
codes a propositional formula  and
and  codes a truth assignment to the variables of
codes a truth assignment to the variables of  which makes
which makes  true, even when
true, even when  is not algorithmically decidable.
is not algorithmically decidable.
In other words, we first need to be able to logically prove that, as formulated currently, both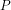 and
and 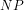 are well-defined algorithmically decidable classes.
are well-defined algorithmically decidable classes.
Second: The problem is formulated in terms of set-theoretically defined ‘languages’. However, in set theory the distinction between computable (recursive) sets and computably (recursively) enumerable sets may not be well-defined from a computational perspective.
problem is formulated in terms of set-theoretically defined ‘languages’. However, in set theory the distinction between computable (recursive) sets and computably (recursively) enumerable sets may not be well-defined from a computational perspective.
Reason: Since functions are defined extensionally in set theory, the theory cannot distinguish that two number-theoretic functions such as below—when defined set-theoretically by their extensions only—could be instantiationally equivalent but computationally distinct (i.e., they may be associated with distinctly different computational properties).
For instance, by Theorem VII of Gödel’s famous 1931 paper on undecidable arithmetical propositions, it can be shown (see Lemmas 8 and 9 of this paper) that every algorithmically computable (recursive) number-theoretic function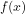 is instantiationally equivalent to an arithmetical function
is instantiationally equivalent to an arithmetical function 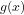 which is algorithmically verifiable but not algorithmically computable.
which is algorithmically verifiable but not algorithmically computable.
The distinction could be of significance in a game where Alice knows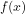 is algorithmically computable, but Bob only knows that
is algorithmically computable, but Bob only knows that 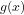 is algorithmically verifiable (but may not be computable).
is algorithmically verifiable (but may not be computable).
November 6, 2013 at 7:01 pm |
@Jason: I would love to see an introduction (by someone else then Gowers). I feel at the moment that there are too many things to cope with – learning tiddlyspace, following the stream of consciousness style ideas and the math.
Also, unrelated – two players game are usually PSPACE-complete, maybe a separation of P and PSPACE would come out, which would be also great.
November 7, 2013 at 10:49 am |
I’ve now looked more closely into the case and come to the conclusion that it is too simple to be truly informative about the general case. I’m considering going for the
case and come to the conclusion that it is too simple to be truly informative about the general case. I’m considering going for the  case instead, but it’s not clear that that will be easier to think about than the general case. See this page and this page for an analysis of the
case instead, but it’s not clear that that will be easier to think about than the general case. See this page and this page for an analysis of the  case.
case.
November 8, 2013 at 3:05 pm |
I think it would be useful to see some examples of Ramsey lifts for some very simple functions, much simpler than the parity function. For example, is there an efficient Ramsey lift for the -bit OR function that simplifies it to a basic set? By a lift for a function
-bit OR function that simplifies it to a basic set? By a lift for a function 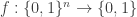 I mean a lift for its
I mean a lift for its  -set
-set 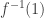 , so in this case for the set
, so in this case for the set 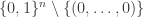 . We can ask the same question for a function whose
. We can ask the same question for a function whose  -set is almost basic itself: is there an efficient Ramsey lift for the function “
-set is almost basic itself: is there an efficient Ramsey lift for the function “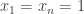 ” that simplifies it to a basic set? I was stuck for while even with the constant-
” that simplifies it to a basic set? I was stuck for while even with the constant- function, until I realized that its
function, until I realized that its  -set is already a basic set on
-set is already a basic set on  , namely the set
, namely the set 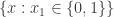 .
.
November 9, 2013 at 3:03 pm
I’d love to know whether such examples exist: some pages of the proof-discovery tree are devoted to precisely these questions (which is not meant as a way of saying that you should have read those pages — I’m glad you’re coming to similar conclusions independently). Let me explain why I hope that the answer to your question about simplifying the function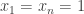 is that it cannot be done efficiently. It relates closely to a point in the post above. If one could do that, then probably one would simplify it to a basic set of the form
is that it cannot be done efficiently. It relates closely to a point in the post above. If one could do that, then probably one would simplify it to a basic set of the form 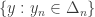 . But then we could do the same for the set
. But then we could do the same for the set 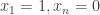 , and then, by taking unions, we would have converted the set
, and then, by taking unions, we would have converted the set 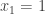 into a set of the form
into a set of the form 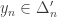 . Then we could do that for
. Then we could do that for 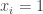 (
(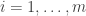 ), or rather we could compose
), or rather we could compose  efficient lifts, one for each
efficient lifts, one for each  , and we would have converted all the first
, and we would have converted all the first  coordinate functions into basic functions based on the
coordinate functions into basic functions based on the  th coordinate. But then all Boolean combinations of those basic functions — i.e., all functions that depend only on the first
th coordinate. But then all Boolean combinations of those basic functions — i.e., all functions that depend only on the first  coordinates — would be converted into basic functions, and that would be bad news as we are trying to discriminate between simple and complex functions.
coordinates — would be converted into basic functions, and that would be bad news as we are trying to discriminate between simple and complex functions.
So what I’d actually like is two things. One is a lower bound on the “lift complexity” of “shifting a basic set” from one coordinate to another. And the other is some notion of simplicity that’s a bit more complicated than that of being a basic set and that has the property that all sets of small circuit complexity can be made simple efficiently. It’s quite a lot to hope that both these can be done, but I don’t want to give up until I have a compelling reason (not necessarily 100% rigorous) that it can’t be done.
November 10, 2013 at 11:24 am
I see the point: basic sets are probably “too simple” so a lower bound would be good news and confirm the need to define simplicity a bit higher in the hierarchy. Even a lower bound showing that the alphabet must square would morally confirm this, since one expects an iterative construction, and squaring at each iteration is more than we can afford.
However, here is one question that arises (and I really hope it wasn’t asked in the proof-tree already and I missed it). Let’s look at the lift that provides the “trivial” doubly exponential upper bound on the alphabet size. That lift is built in one shot. Is there a way to think of that lift, or one that has the same effect of providing a doubly exponential upper bound, as being built iteratively, by an iteration step that, say, squares the alphabet at each step? Just to imagine how this could go, perhaps each iteration step would be designed to take care of one more move in the game, so the auxiliary information would not be based on a full strategy but just a strategy for the first few moves (I found in the pages something along the lines of considering a few moves only, but the goal looked different). If this iterative construction existed, the hope would be to exploit it as a skeleton on which to build other more efficient lifts by redesigning each step to fit whatever goal we are after (e.g. simplifying a set of low circuit complexity).
November 10, 2013 at 2:15 pm
I think you’re right that what I did in the pages was different: very roughly speaking, Player I declares a strategy for the first few moves and Player II declares an outcome for those moves that is consistent with Player I’s strategy. But that’s still a “one-shot” lift. The question of whether one could get from zero to simplifying all sets in a series of gradual steps is one that I don’t know the answer to and I agree that it would be well worth answering.
November 9, 2013 at 2:55 pm |
I have created my own TiddlySpace site: http://portonmath.tiddlyspace.com
I can’t get how to make the hierarchy/hierarchical presentation. Please help
November 9, 2013 at 3:14 pm
Oh, I see I just need to add “greater” signs to the main page
November 9, 2013 at 3:57 pm
LaTeX does not work for me: http://portonmath.tiddlyspace.com/#Test – what is my error?
November 9, 2013 at 4:22 pm
I did this. There was needed “Import/Export” “Import a TiddlyWiki” with http://math-template.tiddlyspace.com URL
November 9, 2013 at 8:57 pm |
wow 1st thought this is way over my head. think this is the 1st case of anyone thinking that borel sets have some major application in CS, right? skimming over your notes on the tiddly site, it seems highly tree-focused. agreed with your notes that there seems like a huge size gap between trees and DAGs although am not aware of thms that actually prove that. [some basic thms relating trees to DAGs would be a great start in this area]
just asked a similar question on stackexchange
P/Poly vs NP separation based on trees instead of DAGs
as for the idea of a circuit-related game relating to lower bounds, interesting idea. it would help just to establish any game that is closely connected to circuits. am not aware of such a result in CS theory. it did occur to me that circuit formulas do indeed bear a close resemblance to game trees. also note for monotone formulas you have OR,AND allowed only which are eerily similar to “min/max” approaches used in various game tree analysis strategies.
one idea, the so-called “pebble game” does show up in some key TCS complexity class type theorems. havent seen nice surveys on the subject, its more a sort of disconnected technique so far.
(wikipedia pebble game.) it does seem to relate closely to compressibility (a metaphor I use a lot to understand complexity class results & lower bounds).
ok, this is a left field/curve ball compared to your ideas, but have you ever looked into graph complexity eg stasys jukna notes? seems to me the community is relatively unaware of this very nice strategy/direction, have seen very few papers on the subject yet it seems to me to be in many ways quite promising.
also of course I sketched out an approach based on hypergraph decompositions, slice fns, monotone circuits in my blog which has still gotten no expert attn/feedback.
November 9, 2013 at 10:47 pm
It’s not the first case of somebody trying to relate the theory of Borel sets to computational complexity. As far as I know, that was Michael Sipser. As I said elsewhere, there are worrying disanalogies between Borel sets and sets of low circuit complexity that suggest that this approach to the P versus NP problem is an extremely long shot.
November 9, 2013 at 9:04 pm |
another quick thought. wonder if there is a game where one side chooses the ANDs of the circuit, the adversary player chooses ORs, and one can have DAGs instead of game trees resulting, and the analogous P=?NP theorem for this would be something like, the game can conclude (ie can be won by either player) only after a large number of plays….. apparently the game is about computing an NP function and is won when the final player applies the last move equivalent to the NP function.
November 9, 2013 at 10:55 pm
Can you describe more precisely how this game works?
November 9, 2013 at 11:26 pm
its really quite simple =)
havent worked this all out, but something like the following. the goal is to compute the NP complete function for a specific number of input bits. the score of a player is how many “errors” remain (simple calculation using the hamming difference in the truth table, partially constructed function vs actual function). the “board” consists of the circuit constructed so far. each player adds one gate to the DAG constructed so far. the question is, are there any thms in game theory that describe that certain games must take a large amt of moves for either player to succeed, that would be key? (lower bound)… am not an expert on game theory….
November 10, 2013 at 9:13 am
Can you be more precise about what the payoff set is? That is, under what circumstances does the game stop and one of the players get declared as the winner?
November 10, 2013 at 5:32 pm
hmmm, ok, on further thought this may be related to some of your musings on xor of functions (have to go look at those again maybe). let $f_n(x)$ be a function that is meant to “approximate” a target function $g_n(x)$ where the latter is NP complete. then $f_n(x)$ Xor $g_n(x)$ is the number of “errors” in using $f_n(x)$ as an “approximation” of $g_n(x)$. the total error is the sum of all those bits. this is a common pattern in monotone circuit lower bounds proofs incl razborovs. but note this is also just the hamming distance between the output bit of the two function’s truth tables. (suspect something like this concept also shows up in natural proofs). figure it is in coding theory also somewhere.
similar to this question
cnf/dnf conversion to minimize errors
November 9, 2013 at 10:18 pm |
I have also created my TiddlySpace: http://portonmath.tiddlyspace.com/ – now it is about values of functions in singularity points (from a novel topological point of view). Please look to my space http://portonmath.tiddlyspace.com/#%5B%5BTheory%20of%20singularities%20using%20generalized%20limits%5D%5D and comment whether clarity of exposition is OK. Especially bad is http://portonmath.tiddlyspace.com/#%5B%5BMore%20on%20galufuncoids%5D%5D where my ideas are not properly exposed or sorted (they need to be precisely formulated and moved to other tiddlers). Is it overally OK? Should I organize it more before I “officially” announce my wiki about singularities?
November 9, 2013 at 10:37 pm
These questions are not relevant to this post. They would be better asked on your own blog.
November 11, 2013 at 6:08 pm |
Nice project!
I am reading your TiddlySpace description, looking to the first “open problem” I can contribute. In section “A more complicated class of games” you asked a question “Open Task: Analyse this (3_SAT) game for some very simple payoff sets, such as x_1=1”.
First, let us clarify the problem formulation. If you mean that 3-SAT clauses players can use are GIVEN AND LISTED, and there are m of them, then your statement “rules force the game to terminate: it terminates when there is just one sequence that satisfies all the clauses” would be wrong, if there are at least two sequences that satisfies all m clauses.
So, I conclude players can use ANY clauses they want subject to rules 1 and 2 in game description. Then, I claim player 1 wins your game in 4 moves:
Move 1. x_1=1 or x_2=1 or x_3=1
Move 2. x_1=1 or x_2=1 or x_3=0
Move 3. x_1=1 or x_2=0 or x_3=1
Move 4/ x_1=1 or x_2=0 or x_3=0
(no matter what player 2 does)
After move 4, all the remaining feasible sequences have x_1=1, and player 1 is guaranteed to win.
November 11, 2013 at 9:08 pm
You are of course right. When I wrote that, I must have been misremembering a question I had thought about that didn’t have a simple answer like that. In fact, in my notes (written before I wrote the TiddlySpace document) I made the observation you made above. I then commented that it didn’t seem obvious which player won the game defined by the parity function, so that may be a better question. I’ll change the “open task” to that.
November 13, 2013 at 6:13 pm |
Open task: think further about whether there might be some notion of “simple” strategy for which it can be shown that games with payoff sets of low circuit complexity have simple winning strategies.
I would call a winning strategy for player i is “simple” if there is an efficient algorithm (say, polynomial in 2^n), which, given payoff set A and a sequence of current moves, returns the next move for player i. I understand that the definition of simplicity invovling “efficient algorithm” is maybe not what you wanted, but this is exactly what I intuitively understand by “simple strategy”. For example, chess is determined, but there is no simple stragety in the sense above, and therefore the game is interesting to play. And if it would be, and I knew it, I could easily win against any opponent. So, for me this seems to be THE CORRECT definition of “simple strategy”. And, by the way, you question with this definition of simplicity seems to be interesting.
November 14, 2013 at 10:21 am
I’ve wondered about this definition of “simple”, but it has some problems. First, the whole point of any definition of simplicity is that it should be something we can use to prove results about computational complexity. If to prove a lower bound on circuit complexity we are required to show that there is no polynomially computable strategy of some kind, then the obvious question arises of how we are going to do that, given that proving superpolynomial lower bounds is more or less the problem we started with (but perhaps harder in this case, since strategies are complicated objects to analyse).
Secondly, if you take any monotone game, then there is a very simple optimal strategy (at least in the version of the game where each player has their own set of coordinates to play): Player I always plays 1 and Player II always plays 0. Since there are plenty of NP-complete monotone functions, this is fairly worrying.
November 14, 2013 at 12:01 pm
Completely agree that proving the statement S: “every set A of low circuit complexity have an efficiently computable strategy” would not directly solve P vs NP problem for the reasons you described. However, it would be at least a good starting point, because, with any definition of simplicity I can imagine, a simple strategy is efficiently computable, therefore the statement T: “every set A of low circuit complexity have a simple strategy” is much stronger than S, therefore we cannot hope proving T before we even know how to prove S.
I do not completely agree with second worry: Having T, be will only need to show that ONE (not any) NP-complete function does not have a simple strategy. Ok, so we would need to choose a non-monotone example at this stage.
November 14, 2013 at 12:38 pm
I agree that the second worry doesn’t rule out an approach along these lines, but I still find it a worrying sign that some of the hardest NP functions, such as the clique function, are not hard from this point of view.
However, your first point is one that I agree with: it would be interesting to know whether functions of low circuit complexity have efficient strategies (either for the 0-set or for the 1-set). My instinct is that they don’t. If, for example, one creates a highly pseudorandom function, then it seems to me to be very unlikely that there would be a polynomial-computable function (incidentally, I think it should be polynomial in rather than
rather than  because the payoff set is not part of the input) for deciding how to play optimally.
because the payoff set is not part of the input) for deciding how to play optimally.
However, that is not a very good argument, since the weirdness of a computable function could be matched by the weirdness of a computable strategy. For example, it might be that one could build up a circuit for the strategy in terms of a circuit for the function. So it would be good to try to find either a proof that efficient strategies exist, which would be a very interesting result I think, or a convincing heuristic argument that they don’t.
When I get time, I think I’ll add a page suggesting this question (including your thoughts above and crediting it and them to you).
November 14, 2013 at 2:01 pm
“My instinct is that they don’t.”
If they don’t, thet you current open task
“think further about whether there might be some notion of “simple” strategy for which it can be shown that games with payoff sets of low circuit complexity have simple winning strategies.”
may be solved only with “simple” strategy witch is not efficiently computable…
On the other hand, if they are, it would be a very interesting result indeed.
November 19, 2013 at 6:05 pm
Hm… In the obvious game, by setting the winning set A to contain all sequences with x_2=1, we can force the second player to choose a specific move (x_2=0 in our case), and thus allow the first player to move twice. Thus, we can assume that each player has k consecutive moves.
Now, take any P-space complete game, for example Node Kayles game (where players mark vertices in an undirected graph, and you cannot choose a marked vertex or any of its neighbours, and loses a player who cannot make a legitimate move), and let G be any hard instance of this game with m vertices. Let all vertices in G are marked as 0-1 sequences of length k. Let n=mk, and consider the following obvious game. If the first k moves of player 1 do not describe a vertex of G, then the sequence does not belong to A. Otherwise, if the next k moves of player 2 do not describe a legitimate move in a Node Kayles game, then the sequence belongs to A, and so on. As a result, the first player wins this “obvious” game if and only the first player wins the corresponding Node Kayles game. For every given sequence it is easy to say if it belongs to A or not, therefore A has low circuit complexity. However, there is no “simple” winning strategy unless either P=PSPACE or we define simplicity such that “simple” does not imply “efficiently computable”…
Does it make sense?
November 13, 2013 at 10:05 pm |
TiddlySpace seems to have a deficiency: It is not convenient to track changes in somebody’s tiddly space. For example in Mediawiki/Wikipedia there is tracking for latest changes (an one if he wants may see all changes by others but not by himself). It is very sad for such mathematical projects. Can more convenient tracking changes be added? (Yes, I’ve noticed “Recent” in the right sidebar, but that is just not convenient enough.)
November 13, 2013 at 11:53 pm
Perhaps you should raise that through https://github.com/TiddlySpace/tiddlyspace, rather than here.
November 20, 2013 at 8:46 pm |
There’s a small omission here: in the definition of the complexity class NP, the function g must be computable in a time that is at most polynomial in n.
Thanks — corrected.
November 25, 2013 at 7:13 pm |
This is just a minor point regarding step (3) of what you would like to prove. Would it be any easier to establish (3) with NEXP in place of NP? If one of your goals is to show that some class is not contained in P/poly via a combination of (1) and (3), why not start with an (ostensibly) weakened version of (3)? (which would still be very interesting)
November 27, 2013 at 9:20 am
I don’t know whether it would be easier, but that’s an interesting suggestion. A related suggestion is to try to establish (1) with formula complexity replacing circuit complexity. That again would potentially lead to very interesting results that fell short of solving the P vs NP problem.
November 29, 2013 at 4:07 am |
Sorry if there’s a better place than this for naive questions, but I’m confused about what it means to say a set $A \in {0,1}^n$ has polynomial (circuit) complexity, as opposed to a sequence of sets $A_n \in {0,1}^n$ for all $n$.
November 29, 2013 at 8:12 am
Strictly speaking it doesn’t make sense for a single . But non-strictly speaking I mean that
. But non-strictly speaking I mean that  is arbitrary and the bound one can prove for the circuit complexity is a polynomial that does not depend on
is arbitrary and the bound one can prove for the circuit complexity is a polynomial that does not depend on  .
.
August 18, 2014 at 2:00 pm |
[…] has recently outlined a problem, which he calls “discretized Borel determinacy,” whose solution is related to […]
May 17, 2016 at 7:05 am |
Hi everybody, just to know, is there any news about this approach, it looks like very interesting. Any results since 2014 ? Thanks !