It’s taken noticeably longer than usual for the number of comments on the previous EDP post to reach 100, so this is perhaps a good moment to think strategically about what we should do. Individual researchers continually have a choice — whether to take a break from the problem and work on other, possibly more fruitful, projects or to tackle that blank page head on and push towards a new level of understanding — and I see no difference with a Polymath project.
I would be interested in the views of others, but my own feeling is that there is still plenty to think about here. There has been a certain amount of talk about Fourier analysis, and that still feels like an insufficiently explored avenue. A good preliminary question, it seems to me, is this. Suppose that 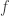





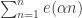
Even if we knew in advance that there was no hope of solving EDP, there are still some questions that deserve more attention. As far as I can tell, nobody has even attempted to explain why some of our greedy algorithms appear to give a growth rate of 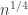
I am also interested in (without yet having thought much about) a class of examples introduced by Kevin O’Bryant. These are sequences of the form 


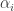
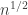
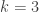



Another line of enquiry that Sune and Gil have thought about is to come up with toy problems that may be easier than EDP. One of Sune’s suggestions is interesting in that he has variants for which there appear to be counterexamples. This sheds light on EDP itself, because it shows that any proof of EDP would have to distinguish between the real problem and the variants.
I think it might be a good idea if we made a conscious decision that we would all focus on one aspect of the problem. For instance, we could choose a sub-problem with a nice statement and temporarily think of that as the “real” problem that we’re working on. But it might also be a bad idea: perhaps what we’ve done up to now, just letting people comment and others follow up on the comments if they find them sufficiently interesting, is the most efficient process. Incidentally, if you think you had a pretty good idea that got forgotten about, it’s not a bad idea to repeat it from time to time (as various people have done already, both in this project and in the DHJ project).
Anyhow, if anybody has thoughts about how we should proceed, then I’d be very pleased to hear them. In the absence of any suggestions to the contrary, I’ll think about the Fourier question and about trying to come up with interesting new multiplicative functions with low discrepancy.
While I’m at it, here’s a thought about such functions, which could turn out to be a special case of Kevin’s thought. (It might even be the basic idea that led him to his thought.) Our best examples so far (not including finite ones found by brute force) have been character-like functions, which are based on some prime number 

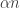

Another little thought, this time in the direction of toy problems, is this. (It may be a special case of one of Sune’s suggestions — I haven’t checked.) Let us say that an infinite discrete set 
![X\cap (0,n]](https://s0.wp.com/latex.php?latex=X%5Ccap+%280%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002)






I believe that something like this has been done for the Riemann hypothesis but I can’t remember the details. Terry, if you’re reading this, you were the one who told me about the RH example — it would be great if you or anyone else could remind me what the precise statement is and give me a reference so that I can add them to this post. [It has now been provided: see the first comment below.]

February 19, 2010 at 10:11 am |
Hi –
This is in answer to your request for a reference to work on the Riemann hypothesis for pseudointegers. You are referring to Beurling´s work.
See also
MR2208947 (2006j:11131)
Diamond, Harold G.(1-IL); Montgomery, Hugh L.(1-MI); Vorhauer, Ulrike M. A.(1-KNTS)
Beurling primes with large oscillation. (English summary)
Math. Ann. 334 (2006), no. 1, 1–36.
February 19, 2010 at 11:12 am
Thank you very much. Here is a link to the paper you mention, the introduction to which gives a useful summary of what is known.
February 19, 2010 at 12:47 pm |
Let me try to think about Kevin-style examples. I find it rather difficult to exact calculations straight on to the computer here, so to start with I’ll just describe the rough idea I have in mind.
We could look at in a different way as follows. We let
in a different way as follows. We let  and we start by taking the sequence
and we start by taking the sequence  . This goes 1, -1, 1, 1, -1, 1, 1, -1, 1, 1, -1, … We see that what is messing up the partial sums along HAPs is that this sequence is constantly 1 on multiples of 3, so we decide to correct that by using precisely the sequence we started with (or minus it) — and then we iterate.
. This goes 1, -1, 1, 1, -1, 1, 1, -1, 1, 1, -1, … We see that what is messing up the partial sums along HAPs is that this sequence is constantly 1 on multiples of 3, so we decide to correct that by using precisely the sequence we started with (or minus it) — and then we iterate.
What I’d like to know is whether we can do something similar for an irrational , and whether there is any chance that by some magic we would end up with a multiplicativity property.
, and whether there is any chance that by some magic we would end up with a multiplicativity property.
To make it easier to think about, perhaps one should go for a complex sequence. Here’s how one might define it. Start with a function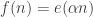 for some suitable irrational
for some suitable irrational  . The partial sum along the HAP with common difference
. The partial sum along the HAP with common difference  will be bounded, but the bound will depend on
will be bounded, but the bound will depend on  and will be worse, the closer
and will be worse, the closer  is to an integer. So we could pick the first
is to an integer. So we could pick the first  for which we find the bound to be unacceptably bad, choose an irrational
for which we find the bound to be unacceptably bad, choose an irrational  (perhaps even the same as
(perhaps even the same as  ), define a function
), define a function  to be
to be  , and replace
, and replace  by
by  . The vague thought behind this is that
. The vague thought behind this is that  is constant on intervals of length
is constant on intervals of length  , so with any luck
, so with any luck  doesn’t mess up the partial sums along HAPs with common difference less than
doesn’t mess up the partial sums along HAPs with common difference less than  (but this is far from a complete argument — it’s by no means clear that we do have this “luck”), but it corrects the problems when the common difference is
(but this is far from a complete argument — it’s by no means clear that we do have this “luck”), but it corrects the problems when the common difference is  .
.
Actually, perhaps this is more Morse-like than character-like. In fact, the Morse sequence can be expressed rather easily as a Kevin-type sequence: just take .
.
Just to finish these rambling thoughts, I wonder what happens if we express numbers in Fibonacci base and then take their parities. (I think this may be the same as taking , where
, where  .) I may as well give it a quick go. Here are the Fibonacci-base expressions of the first few integers. 1, 2, 3, 1+3, 5, 1+5, 2+5, 8, 1+8, 2+8, 3+8, 1+3+8, 13, 1+13, 2+13, 3+13, 1+3+13, 5+13, 1+5+13, 2+5+13, 21.
.) I may as well give it a quick go. Here are the Fibonacci-base expressions of the first few integers. 1, 2, 3, 1+3, 5, 1+5, 2+5, 8, 1+8, 2+8, 3+8, 1+3+8, 13, 1+13, 2+13, 3+13, 1+3+13, 5+13, 1+5+13, 2+5+13, 21.
The corresponding sequence is -1, -1, -1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, 1, 1, 1, -1, 1, -1, -1, -1. It seems to behave quite promisingly, but this is much too small a sample to be sure.
Actually, forget it. It’s obviously just as bad as the Morse sequence and for exactly the same reason, since if n is a large Fibonacci number then the HAP with common difference n+1 gives you a long sequence of 1s.
What this seems to suggest is that taking one of Kevin’s sequences with the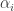 shrinking too geometrically is likely not to be all that good. But maybe there is a chance of something if the ratios of successive terms are not so regular.
shrinking too geometrically is likely not to be all that good. But maybe there is a chance of something if the ratios of successive terms are not so regular.
February 19, 2010 at 3:09 pm
“We could look at in a different way as follows. We let
in a different way as follows. We let  and we start by taking the sequence
and we start by taking the sequence  . This goes 1, -1, 1, 1, -1, 1, 1, -1, 1, 1, -1, …”
. This goes 1, -1, 1, 1, -1, 1, 1, -1, 1, 1, -1, …” or
or  ?
?
There is no n in your formula for f(n). Do you mean
February 19, 2010 at 3:20 pm
I meant the former and have now changed it. But the latter could work too perhaps.
February 19, 2010 at 4:11 pm
But that don’t give 1,-1,1,1,-1,1,…
February 19, 2010 at 4:14 pm
Damn, sorry — I meant and have now changed that too.
and have now changed that too.
February 21, 2010 at 10:13 pm
“if n is a large Fibonacci number then the HAP with common difference n+1 gives you a long sequence of 1s”
I don’t think this works. Eg. 2(n+1) and 3(n+1) will have an odd number of 1s in the Fibonacci base (dots means string of zeros):
n+1: 00100… 001
2(n+1): 01001… 010
3(n+1): 10001… 100
4(n+1): 10101… 101
However, if n and m are large Fibonacci-numbers with n much larger than m, then the HAP with difference n+m starts with a lot of 1s:
n+m: 00100…00100 … 00
2(n+m): 01001…01001 … 00
3(n+m): 10001…10001 … 00
4(n+m): 10101…10101 … 00
and so on.
February 19, 2010 at 1:54 pm |
Your pseudointeger suggestion is similar to the one I suggested, but it is not a special case. E.g. we could choose , but this is not possible in the model I suggested.
, but this is not possible in the model I suggested.
It might be, that if you require the set X to have unique factorization, your suggestion is a special case of mine. I want to break the specialization down to two steps (you can take any of the steps without taking the other):
First you want the pseudointegers to be reals numbers. This implies that if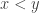 , there is a
, there is a 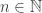 so that
so that  but this this not the case in the model I suggested (e.g. this is not the case in my "counterexample" where the sequence of primes grows fast). Your model is what I called "an ordering that can be defined by logarithms". If you want to make your model more general in this respect, you could use infinitesimals.
but this this not the case in the model I suggested (e.g. this is not the case in my "counterexample" where the sequence of primes grows fast). Your model is what I called "an ordering that can be defined by logarithms". If you want to make your model more general in this respect, you could use infinitesimals.
Secondly you wanted![|X\cap (0,n]|](https://s0.wp.com/latex.php?latex=%7CX%5Ccap+%280%2Cn%5D%7C&bg=ffffff&fg=333333&s=0&c=20201002) to be roughly n. I think this could be formulated in the model I suggested in this way: By
to be roughly n. I think this could be formulated in the model I suggested in this way: By 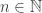 I mean the nth smallest element in
I mean the nth smallest element in 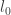 . Now for fixed k we want
. Now for fixed k we want  to be linear in n.
to be linear in n.
I'm almost sure that I have prove that the "counterexample" I gave here (the second example) has discrepancy 1, but I haven’t wrote down a proof yet. I might do that later this weekend.
February 19, 2010 at 4:25 pm |
Semi-meta (semi because this is not about polymath generally or the way the blog/wiki works, but about the “what next?” question)
Tim suggested that we discussed what to do now, so I will try to start this discussion.
I must admit that I’m not as optimistic about the project as I have been, but I was more pessimistic a couple of days ago. It seems that there have been more comments the last couple of day, and now we have something to think about again. (I can’t help noticing that posts asking “should we take a break from this problem” are unlikely to appear when the numbers of comments per day is low, as long as new posts are only made when the number of comments in the last post reach 100.)
I still think that there is good reason to continue working on this problem. Right now I’m interested in the different toy problems of EDP. In particular, it would be interesting to find a set of “psudointegers” (not necessarily in the way Tim defined them) where we can prove the EDP. As long a everyone has something to study, I think there is a reason to continue.
I’m not sure it is a good idea to decide that everyone should work on the same subproblem. It seems to me that these kind of decisions are impossible (like deciding that a polymath-project shouldn’t start yet. Sorry!) I think we should just let “evolution” make sure that the most interesting ideas and problems survive.
Before the project began 9 people said they would be “an active and enthusiastic participant with relevant knowlege”. I said I would be “an interested non-participant” and as I understand Tim didn’t vote. Who are the 9 people, and how many of them are participating/participated?
February 19, 2010 at 7:23 pm
I also had ticked the “interested non-participant” box, as I anticipated that many experts would contribute — it seems that polymath5 is perhaps not known widely enough (or not appealing enough, as in “it’s a well-known impossibly difficult problem” ?).
As for toy problems, I’m not sure I can contribute much theoretically, but for instance I’d be happy to explore the Liouville function more (there are relevant papers by Cassaigne et al in Acta Arithmetica) — although not until mid-march due to other commitments.
February 19, 2010 at 4:32 pm |
Here’s another vague thought that will probably come out hopelessly confused when I try to write it down. Let’s transform the multiplicative problem about pseudointegers into an additive problem (just for convenience). So now we have a set of non-negative real numbers that includes zero, is closed under addtion, and has the property that the size of
of non-negative real numbers that includes zero, is closed under addtion, and has the property that the size of ![X\cap [0,C]](https://s0.wp.com/latex.php?latex=X%5Ccap+%5B0%2CC%5D&bg=ffffff&fg=333333&s=0&c=20201002) is about
is about  for each
for each  . An additive function on
. An additive function on  is a function
is a function 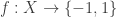 such that
such that  (so it’s an additive function from
(so it’s an additive function from  to the Abelian group of order 2). We now want to find
to the Abelian group of order 2). We now want to find  and
and  in such a way that
in such a way that  is a bounded function of
is a bounded function of  .
.
Without the growth condition on , this is trivial: we simply take
, this is trivial: we simply take  to be the set of all non-negative integers and we define
to be the set of all non-negative integers and we define  to be
to be  .
.
As I write, I see that I want to add an extra condition to the definition of : it should be generated by an additively independent set (of “pseudoprimes”). Otherwise we get strange multiplicities coming in.
: it should be generated by an additively independent set (of “pseudoprimes”). Otherwise we get strange multiplicities coming in.
So now a possibly nice preliminary question is whether we can build up a sequence of generators in such a way that the pseudo-Liouville function
of generators in such a way that the pseudo-Liouville function  has bounded partial sums. I have to go for a while but may return to this question unless someone has posted an answer to it by the time I get back.
has bounded partial sums. I have to go for a while but may return to this question unless someone has posted an answer to it by the time I get back.
February 19, 2010 at 5:26 pm
It seems that here we have another question that can be investigated algorithmically: we simply choose our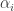 and hope to cancel out any largeness in the partial sums. (It might be necessary to make
and hope to cancel out any largeness in the partial sums. (It might be necessary to make  for some
for some  , however, unless one looks ahead.) But the big difference between this and the usual problem is that now we have complete control over where the primes fall: the only constraint is on how dense they are. So it’s reasonable to hope that we might be able to get better bounds for this problem than one can get for EDP itself.
, however, unless one looks ahead.) But the big difference between this and the usual problem is that now we have complete control over where the primes fall: the only constraint is on how dense they are. So it’s reasonable to hope that we might be able to get better bounds for this problem than one can get for EDP itself.
I don’t really mean “hope” exactly, because if we can find better bounds, then it seems to rule out various proof techniques for EDP (as Sune has already pointed out in a very similar context). But in another sense I do mean “hope” because it would be an interesting result in itself.
Just to add one remark about greedy algorithms here, one can clearly use a greedy algorithm to produce a sequence that keeps the partial sums small. The issue, however, is whether one can do so in a way that doesn’t cause the growth rate of the function![|X\cap [0,C]|](https://s0.wp.com/latex.php?latex=%7CX%5Ccap+%5B0%2CC%5D%7C&bg=ffffff&fg=333333&s=0&c=20201002) to be too large.
to be too large.
February 19, 2010 at 6:12 pm
I haven’t actually done it, but I think it ought to be possible to come up with an example where the growth rate of![|X\cap [0,C]|](https://s0.wp.com/latex.php?latex=%7CX%5Ccap+%5B0%2CC%5D%7C&bg=ffffff&fg=333333&s=0&c=20201002) is
is  to within a multiplicative constant (which is less accurate than one would like, but a start).
to within a multiplicative constant (which is less accurate than one would like, but a start).
The rough idea would be as follows. For convenience I’ll go for a growth rate of instead, as we can always rescale later. As our first generator we choose
instead, as we can always rescale later. As our first generator we choose  and set
and set  . By convention our sequence includes
. By convention our sequence includes 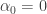 as well, so the growth rate is exactly what we want it to be at 0 and 1. At 2 we want to have had four numbers in
as well, so the growth rate is exactly what we want it to be at 0 and 1. At 2 we want to have had four numbers in  but so far all we have is three: 0, 1 and 2. So let’s choose
but so far all we have is three: 0, 1 and 2. So let’s choose 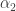 to be some real number that is very slightly smaller than 2 and irrational (so that there are no additive relationships between
to be some real number that is very slightly smaller than 2 and irrational (so that there are no additive relationships between 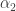 and
and 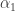 — I won’t keep mentioning this). Since
— I won’t keep mentioning this). Since  , we may as well let
, we may as well let  .
.
So the first few elements that we have so far put into are 0, 1,
are 0, 1, 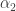 , 2, 3,
, 2, 3,  , 4, 5,
, 4, 5,  , and so on (though eventually the pattern will be broken because eventually
, and so on (though eventually the pattern will be broken because eventually  will be greater than 1). The partial sums therefore go 1, 0, -1, 0, -1, 0, 1, 0, -1, 0, -1, 0, 1, 0, -1, 0, -1, 0, … until the pattern breaks. (This is periodic with period 6 because when we get to 4 we have the same pattern of integers and multiples of
will be greater than 1). The partial sums therefore go 1, 0, -1, 0, -1, 0, 1, 0, -1, 0, -1, 0, 1, 0, -1, 0, -1, 0, … until the pattern breaks. (This is periodic with period 6 because when we get to 4 we have the same pattern of integers and multiples of 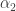 , including parity, and there are six numbers less than 4 in the sequence as it is so far.)
, including parity, and there are six numbers less than 4 in the sequence as it is so far.)
However, this is not good enough because we need to have eight numbers by the time we reach 3, and so far we have only five. The partial sum up to 3 is -1, so we should choose three numbers just below 3 and choose their values to be 1, -1 and 1, respectively.
just below 3 and choose their values to be 1, -1 and 1, respectively.
Now I claim that at least to start with we can keep the partial sums between -1 and 1 very easily. It will start to get more complicated when the next integer after is no longer
is no longer  , but if we make new terms of the sequence close enough to the ones they are trying to “correct”, then difficulties can be made to arise arbitrarily infrequently, which leads me to believe that a greedy algorithm along these lines might well be able to keep the partial sums bounded, and give a growth rate that at every
, but if we make new terms of the sequence close enough to the ones they are trying to “correct”, then difficulties can be made to arise arbitrarily infrequently, which leads me to believe that a greedy algorithm along these lines might well be able to keep the partial sums bounded, and give a growth rate that at every  is between
is between  and
and  . And if that is indeed possible, it can probably be refined quite a lot: perhaps even to give a growth rate of
. And if that is indeed possible, it can probably be refined quite a lot: perhaps even to give a growth rate of  .
.
February 19, 2010 at 6:55 pm |
I want to prove that the sequence I defined here over some “pseudointegers” has discrepancy 1. To recap, as pseudointegers I’m using , the set of sequences taking values in the non-negative integers that are 0 from some point, with the following ordering: Define
, the set of sequences taking values in the non-negative integers that are 0 from some point, with the following ordering: Define  . Now a>b if f(a)>f(b) and if f(a)=f(b) we use the lexicographical ordering. So the smallest elements is (dots means: the rest is 0):
. Now a>b if f(a)>f(b) and if f(a)=f(b) we use the lexicographical ordering. So the smallest elements is (dots means: the rest is 0): .
. . This is true for n=2 and 3, so lets assume that it is true for all k<n. We divide the set of
. This is true for n=2 and 3, so lets assume that it is true for all k<n. We divide the set of  into two set: The set with
into two set: The set with  (the parity of i_1 is the same as that of n) and the set with $i_1\geq 2$. But we take an i in
(the parity of i_1 is the same as that of n) and the set with $i_1\geq 2$. But we take an i in  , and subtract 2 from
, and subtract 2 from 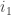 , and we get a element in
, and we get a element in  . This function is bijective and doesn't change the parity of the sum of the terms in i, so by induction hypotesis
. This function is bijective and doesn't change the parity of the sum of the terms in i, so by induction hypotesis  . We have
. We have  using a left shift. This gives
using a left shift. This gives  and by induction we get
and by induction we get 
(0,…), (1,…), (0,1,…), (2,…), (1,1,…), (3,…), (0,0,1,…), (0,2,…), (2,1,…), (4,…)
The sequence I define on these pseudointegers is simply the pseudo-Liouville function:
First of all, I want to show by induction that for all n>1,
This is not enough: We need to show that the partial sums are also bounded by 1. This can be done in exactly the same way.
are also bounded by 1. This can be done in exactly the same way.
February 19, 2010 at 10:10 pm
You should read my next comment and my reply to that, before you read this.
I will try to answer my first questions for this set of pseudointeger. The question is: For fixed what is the density of pseudointegers divisible by i?
what is the density of pseudointegers divisible by i?
Lets try to find the numbers . We have
. We have  and we can get the recursion formulas
and we can get the recursion formulas  and
and  . This gives us for n>1
. This gives us for n>1  , where
, where  is A033485 given by a(n) = a(n-1) + a([n/2]), a(1) = 1.
is A033485 given by a(n) = a(n-1) + a([n/2]), a(1) = 1.
Lets look at the subset of these pseudointegers that are not divisible by the first prime. We know that if i is not divisible by the first prime then is even. Furthermore we know that
is even. Furthermore we know that  (we get that by using a left shift). So if
(we get that by using a left shift). So if  as n go to infinity (this seems to be a reasonable assumption, I haven’t proved it) the density of pseudointegers divisible by the first prime is 1. From this comment we know (or at least think we know) that if this density of pseudointegers divisible by x is in
as n go to infinity (this seems to be a reasonable assumption, I haven’t proved it) the density of pseudointegers divisible by the first prime is 1. From this comment we know (or at least think we know) that if this density of pseudointegers divisible by x is in  for any x, then it will be in this set for all x. Since this is not the case for the first prime, this can’t be the case for any of the pseudointegers in this set. I think it is possible to show that the density is 1 for all
for any x, then it will be in this set for all x. Since this is not the case for the first prime, this can’t be the case for any of the pseudointegers in this set. I think it is possible to show that the density is 1 for all  .
.
February 19, 2010 at 7:58 pm |
Two questions I think are interesting for any set X of pseudointegers (again let n denote the nth lowest pseudointeger, and let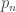 denote the nth lowest pseudoprime):
denote the nth lowest pseudoprime):
Fix . What is the density of the pseudointegers divisible by k? In particular, does it have a density and if so is it in
. What is the density of the pseudointegers divisible by k? In particular, does it have a density and if so is it in  or in {0,1}?
or in {0,1}? grow?
grow?
How fast does
It would also be interesting to find out how the two questions relate: If we know that the pseudointegers divisible by 2 have some density in (0,1), what can we say about the second question?
If is a set of pseudointegers as Tim defined them in the post, and it has a set of independent generators and
is a set of pseudointegers as Tim defined them in the post, and it has a set of independent generators and ![\lim_{n\to\infty}\frac{X\cap (0,n]}{n}\to 1](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Cto%5Cinfty%7D%5Cfrac%7BX%5Ccap+%280%2Cn%5D%7D%7Bn%7D%5Cto+1&bg=ffffff&fg=333333&s=0&c=20201002) we can solve the first question. The density of numbers divisible by
we can solve the first question. The density of numbers divisible by  is
is ![\lim_{n\to\infty}\frac{xX\cap (0,n]}{X\cap (0,n]}=\frac{1}{x}](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Cto%5Cinfty%7D%5Cfrac%7BxX%5Ccap+%280%2Cn%5D%7D%7BX%5Ccap+%280%2Cn%5D%7D%3D%5Cfrac%7B1%7D%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Here x means the real number, and not the integer that represents its position in
. Here x means the real number, and not the integer that represents its position in  . What can we say about the second question?
. What can we say about the second question?
February 19, 2010 at 8:02 pm
I forgot the “|”s around the sets in the limits.
February 19, 2010 at 9:32 pm
Lets say that a set X (actually an ordered set) is a set of pseudointegers if it is the set with an ordering such that
with an ordering such that  and for any a in X the set of elements less than a is finite. Here multiplication of sequences in X is just termwise addition.
and for any a in X the set of elements less than a is finite. Here multiplication of sequences in X is just termwise addition.
Suppose we have a pseudointeger such that the the density of pseudointegers divisible by x
such that the the density of pseudointegers divisible by x  is in
is in  . Lets define the logarithm in base x: For
. Lets define the logarithm in base x: For  we define
we define  . Now it should be possible to prove some basic formulas:
. Now it should be possible to prove some basic formulas:
I want to define the natural logarithm by: , where log(d) is the (good old) logarithm of the density of the pseudointegers that are divisible by x. All this gives us a map
, where log(d) is the (good old) logarithm of the density of the pseudointegers that are divisible by x. All this gives us a map  defined by
defined by  . This map should fulfill:
. This map should fulfill:
But in general this map is not injective, so we don’t have . Now I think it is possible to show that the density of pseudointegers divisible by y is given by
. Now I think it is possible to show that the density of pseudointegers divisible by y is given by  . In particular we have
. In particular we have  for all y in X and the functions
for all y in X and the functions 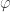 and
and  doesn't depend on the x we chose. Furthermore we get
doesn't depend on the x we chose. Furthermore we get 
Disclaimer: I haven't proved everything I claimed in this comment, but I think it should be easy.
February 19, 2010 at 11:07 pm
There is something wrong somewhere: I couldn’t make this work for the set of odd numbers. It should be possible to go though the “proof” with this example in mind and find the flaw, but I will go to bed now. I will look at it tomorrow, if no one else has found the flaw.
February 20, 2010 at 9:17 am
I think I have found the flaw. In general we don’t get but
but  for some real number d (can this be >1?). And now
for some real number d (can this be >1?). And now  . Of course the formula
. Of course the formula  doesn’t hold for y=1, but it should hold for all other y.
doesn’t hold for y=1, but it should hold for all other y.
If X is a set of pseudointegers as Tim defined them in the post, then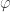 must be the inclusion map:
must be the inclusion map:  must be a monotone solution to Cauchy’s functional equation and if
must be a monotone solution to Cauchy’s functional equation and if ![X \cap(0,n]](https://s0.wp.com/latex.php?latex=X+%5Ccap%280%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) should be of almost the same size as
should be of almost the same size as ![\varphi(X)\cap (0,n]](https://s0.wp.com/latex.php?latex=%5Cvarphi%28X%29%5Ccap+%280%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , there is only one solution that works.
, there is only one solution that works.
I will try to state and proof all the remarks from these comments on the wiki later, and give a summary when I’m done.
February 19, 2010 at 8:28 pm |
I have been looking at the human proof that a multiplicative sequence with discrepancy less than or equal to 2 has length at most 246. In particular the case where f(2)=-1 and f(5)=1. The output from Uwe Stroinski prover is on the wiki and I think I can use it to deal with this case. f(2) = -1; f(3) = -1; f(5) = 1; f(7) = -1; f(11) = 1; f(13)= -1; f(17)= -1 and f(37) = 1.
From this we get that a f(220)=f(221)=f(222)=f(224)=f(225)=1. This means that there is a cut at 220 and the sum at 220 is zero and the sum at f(225) is at 3 or more which is greater than two thus the discrepancy is greater than 2 and we have dealt with this case. If this works there is still a lot of work to be done on the wiki in polishing the result but it looks like a human proof of this result is possible.
February 20, 2010 at 1:06 pm
That should be correct. The machine didn’t find this because I have excluded “long” partial sums like f[220,225] because of performance issues.
February 20, 2010 at 6:54 pm
A ‘polished’ version of case 1 in the Wiki.
Assume f(2)=1. We derive f(3)=f(5)=f(7)=f(19)=-1 e.g. like in the Wiki.
Assume f(11)=-1. We need 5 more values.
* f[12]=-2 implies f(13) = 1,
* f[32,35]=3+f(17) implies f(17) = -1,
* f[30,33]=3+f(31) implies f(31) = -1,
* f[132,135]=3+f(67) implies f(67) = -1;
* f[22]=-2 implies f(23) = 1
Since f(62)=f(63)=-1 we have a cut at 62. f(64)=1,f(65)=-1,f(66)=1. Thus f[66]=0. Furthermore f(67)=f(68)=f(69)=-1 implies f[69]=-3. Hence f(11) cannot be -1.
Assume f(11) = 1. We need 6 more values.
* f[74,77]=-3+f(37) implies f(37) = 1
* f[34,37]=3+f(17) implies f(17) = -1
* f[152,155]=-3-f(31) implies f(31) = 1
* f[184,187]=-3+f(23) implies f(23) = 1
* f[23]=2+f(13) implies f(13) = -1
* f[28]=-2 implies f(29) = 1;
Now f[37]=3 and thus f(11) cannot be 1. In conclusion: f(2) has to be -1.
February 19, 2010 at 8:40 pm |
[…] By kristalcantwell There is a new thread for Polymath5. The pace seems to be slowing down a […]
February 19, 2010 at 10:30 pm |
Although EDP is evidently very difficult, I feel that we haven’t yet discovered quite why it is so difficult — or at least, I haven’t. For this reason alone I feel like pushing on at least a bit longer, though I must admit that demands of work and family don’t leave me a great deal of time at the moment (I ticked the middle box in the poll, perhaps optimistically).
It seems that one reason for the difficulty of the problem is that it seeks to relate quite directly the additive and multiplicative structure of the integers; but this hardly feels like sufficient excuse for failure! Why should sums of multiplicative functions be so intractable? Is the difficulty on the level of the Riemann Hypothesis? If so, I’d like to see why, even if only roughly.
I’m not sure whether we have even come up with a heuristic reason, based on a plausible probabilistic model, why the conjecture should be true or false. I do feel this should be possible. The fact that any such argument would have to contend with the character-like examples seems to be part of the difficulty, however.
Another question that I think is worth exploring further experimentally is whether there is any non-trivially random way of generating multiplicative functions that exhibit logarithmic growth.
February 19, 2010 at 10:48 pm
For any random assignment of +-1 to a finite set of primes, can’t we get logarithmic growth by finding a large prime p such that all of the assigned -1s are quadratic nonresidues mod p and all of the assigned +1s are quadratic residues mod p and assigning the rest of the primes accordingly?
Or is it hard to find such a p.
February 20, 2010 at 12:54 am
One can do that with the help of quadratic reciprocity and the Chinese remainder theorem, but I think Alec would not want to count that as non-trivially random.
February 20, 2010 at 11:50 am
It is interesting that that can be done, but Tim is right, I wouldn’t count it as non-trivially random because it amounts to choosing a character-like function modulo a single random prime.
A less ambiguous question would be: are there uncountably many -valued multiplicative functions whose partial sums grow logarithmically? This isn’t quite what I had in mind (for instance, the answer is trivially ‘yes’ if we generalize to
-valued multiplicative functions whose partial sums grow logarithmically? This isn’t quite what I had in mind (for instance, the answer is trivially ‘yes’ if we generalize to 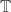 -valued sequences, whereas the question about randomly-generated sequences should apply there too), but it may be interesting in itself.
-valued sequences, whereas the question about randomly-generated sequences should apply there too), but it may be interesting in itself.
Here is another question in a similar vein. Imagine an infinite game where two players construct a multiplicative sequence by taking turns to assign values to primes. Good guy wants the final sequence to have logarithmic growth; bad guy wants to thwart him. Initially, all primes are assigned zero. Each player can, on his turn, assign to any prime that is still assigned zero. The final sequence is the pointwise limit of the sequences obtained after a finite number of turns. Is there a winning strategy for good guy? What if we allow good guy to assign
to any prime that is still assigned zero. The final sequence is the pointwise limit of the sequences obtained after a finite number of turns. Is there a winning strategy for good guy? What if we allow good guy to assign  primes on his turn (but bad guy only one)?
primes on his turn (but bad guy only one)?
February 20, 2010 at 12:14 pm
That’s a nice question. Here’s an idea that it might perhaps be possible to develop into a proof that bad guy wins. The strategy would be simply to pick the smallest prime that has not had a value assigned and choose a value randomly. Bad guy will then get to choose random values on a set of primes of density 1/2 (not true density, but something along those lines), which ought to be enough to produce square-root growth.
As it stands, this isn’t a proof, since good guy gets to choose values that depend on earlier values that bad guy has chosen. To understand this dependence, another question might be this: suppose bad guy chooses values at every other prime, and then good guy gets to choose the rest (knowing what bad guy has chosen). Can good guy get logarithmic growth? One could even ask this question in the case where bad guy chooses 1 every single time. What makes this hard for good guy is that the irregularities in the distribution of the primes will probably make it impossible to produce character-like functions. On the other hand, a free choice at every other prime feels as though it might be somehow comparable to a free choice at all primes.
February 20, 2010 at 11:42 am |
Here are a few thoughts about the Fourier question discussed in the post. We want to show that if is a function from
is a function from  to
to  satisfying certain conditions, the most important two of which are that
satisfying certain conditions, the most important two of which are that  and
and  (for some
(for some  that may turn out to have to depend on
that may turn out to have to depend on  ), then there exists a HAP
), then there exists a HAP  such that
such that  . This is provided that
. This is provided that  is sufficiently large.
is sufficiently large.
One way of proving such a result is to show that the sum in question is large on average. Since the extra generality could turn out to be helpful, let us consider a weighted average. For each and
and  such that
such that  , let
, let  be the HAP
be the HAP 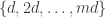 , let
, let  be a non-negative weight, and suppose that the weights sum to 1. Then it will be enough to show that
be a non-negative weight, and suppose that the weights sum to 1. Then it will be enough to show that  .
.
We can write as
as  (identifying
(identifying  with its own characteristic function). If we do this, then we see that by Parseval’s identity it is equal to
with its own characteristic function). If we do this, then we see that by Parseval’s identity it is equal to  . Therefore, the sum we are interested in is
. Therefore, the sum we are interested in is  , which is
, which is  . Interchanging summation and integration, we see that this is
. Interchanging summation and integration, we see that this is  , where the kernel
, where the kernel  is equal to
is equal to  .
.
So now we are trying to show that is unbounded, using certain properties of
is unbounded, using certain properties of 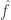 and
and  . What are these properties?
. What are these properties?
Well, we are assuming that and
and  . Since we are trying to find a lower bound for a quantity involving
. Since we are trying to find a lower bound for a quantity involving  , it might seem a bit peculiar to use an upper bound on the
, it might seem a bit peculiar to use an upper bound on the  norm of
norm of 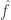 , but this is not completely ridiculous, since in conjunction with our knowledge of
, but this is not completely ridiculous, since in conjunction with our knowledge of  it gives us a lower bound for
it gives us a lower bound for  . So there is something to use here. (Roughly speaking, it tells us that
. So there is something to use here. (Roughly speaking, it tells us that 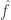 cannot be too concentrated.)
cannot be too concentrated.)
The kernel is obviously positive definite (by which I really mean non-negative definite) since it is a sum of kernels that are trivially positive definite. It’s also Hermitian. So it can be “diagonalized”. We could either discretize everything and do a genuine diagonalization, or apply whatever spectral theorem is appropriate here. Instead of thinking about what that would be, let me simply assume that there is some orthonormal basis
is obviously positive definite (by which I really mean non-negative definite) since it is a sum of kernels that are trivially positive definite. It’s also Hermitian. So it can be “diagonalized”. We could either discretize everything and do a genuine diagonalization, or apply whatever spectral theorem is appropriate here. Instead of thinking about what that would be, let me simply assume that there is some orthonormal basis  of eigenvectors such that
of eigenvectors such that  , where
, where  .
.
So we would like to choose the weights (or just forget about the weights and give everything equal weight) in such a way that every function
(or just forget about the weights and give everything equal weight) in such a way that every function 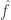 with the properties above has an expansion
with the properties above has an expansion  for which we can show that
for which we can show that  is at least
is at least  . This splits naturally into two problems: understand which kernels
. This splits naturally into two problems: understand which kernels  have this property, and try to produce such a kernel from the ingredients we have at our disposal.
have this property, and try to produce such a kernel from the ingredients we have at our disposal.
Is there some intuitive reason that one hopes would get this to work? Here is one small thought. Let us consider the difference between the sum and the sum
and the sum  for some
for some  . The first of these sums is
. The first of these sums is  , and the second is
, and the second is  . So the difference is
. So the difference is  . Actually, I’ll need to think about this. I was hoping that
. Actually, I’ll need to think about this. I was hoping that  wouldn’t be able to tell the difference between
wouldn’t be able to tell the difference between  and the shifted
and the shifted  , but I haven’t yet worked out what the right calculation is (if it is even correct at all).
, but I haven’t yet worked out what the right calculation is (if it is even correct at all).
February 20, 2010 at 1:19 pm
I forgot to make the point that one reason I am interested in this Fourier question is that it avoids the annoying difficulty of having to use the fact that the function is -valued. I am asking the question for a more general class of functions, and do not have to worry about 1, -1, 0, 1, -1, 0, … and functions like that, since they have large Fourier coefficients.
-valued. I am asking the question for a more general class of functions, and do not have to worry about 1, -1, 0, 1, -1, 0, … and functions like that, since they have large Fourier coefficients.
Arising from the discussion above is a question I find quite interesting, though at the moment I don’t even begin to see how to answer it. Consider the linear map defined on functions defined by the formula
defined by the formula  , where the sum is over all HAPs. I would like to know what the eigenvectors of this map are like. To make the question easier, I’m happy to allow any reasonable choice of weights
, where the sum is over all HAPs. I would like to know what the eigenvectors of this map are like. To make the question easier, I’m happy to allow any reasonable choice of weights  (I chose
(I chose  for all
for all  in the expression I wrote). I would also settle for an approximate eigenvector, by which I mean a function
in the expression I wrote). I would also settle for an approximate eigenvector, by which I mean a function  that is roughly proportional to its image. But I should also make clear that I want not just one eigenvector but the whole basis.
that is roughly proportional to its image. But I should also make clear that I want not just one eigenvector but the whole basis.
If we had that basis, then we would have an amazing handle on mean-square sums along HAPs. However, the eigenvectors look as though they may be quite strange, because a lot depends on how smooth a number is.
February 20, 2010 at 2:48 pm
That’s a very intersting question. It is still a bit vague for me. Just to make it entirely concrete here are some little questions:
1) What precisely do you mean by and what precisely is
and what precisely is  .
.
2) Do you need to consider all s or just those corresponding to small periods (= perhaps(??) the alphas which are rational number with small denominators).
s or just those corresponding to small periods (= perhaps(??) the alphas which are rational number with small denominators).
3) Does a positive answer (to the question in the first paragraph “we want to “…) even just to +1 -1 valued functions imply EDP?
February 20, 2010 at 4:28 pm
Here’s an attempt to answer your questions.
1) is a real number between 0 and 1 and
is a real number between 0 and 1 and 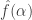 is
is  , where
, where 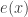 is shorthand for
is shorthand for 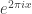 .
.
2) I don’t know the answer to this. I think it is convenient to consider all periods in calculations, so that one can use things like Parseval and the inversion formula, but it may be that the assumption about should be the weaker one that
should be the weaker one that 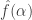 is small whenever
is small whenever  is close to a rational with small denominator (which would be nice because it would prove that if a sequence had bounded discrepancy then it would have to have bias on an AP with small common difference).
is close to a rational with small denominator (which would be nice because it would prove that if a sequence had bounded discrepancy then it would have to have bias on an AP with small common difference).
3) I’m not sure I fully understand this question, but I’ll answer what I think you are asking. If one could prove a very good result in the direction of what I am asking, then probably the best one could hope for is to show that if the discrepancy is at most then there is some Fourier coefficient of size at least
then there is some Fourier coefficient of size at least  . But I don’t see how to get from that to EDP. It seems like a step in the right direction, but it is a lot weaker than being character-like. But perhaps one could combine this with known results to get something stronger. For instance, if we now assume that the function is multiplicative, and if we got linear growth of partial sums along some AP, then we would perhaps be able to apply results of Granville and Soundararajan and somehow mimic the proof that works for character-like functions.
. But I don’t see how to get from that to EDP. It seems like a step in the right direction, but it is a lot weaker than being character-like. But perhaps one could combine this with known results to get something stronger. For instance, if we now assume that the function is multiplicative, and if we got linear growth of partial sums along some AP, then we would perhaps be able to apply results of Granville and Soundararajan and somehow mimic the proof that works for character-like functions.
February 20, 2010 at 4:47 pm
A reasonable reaction to my comment at the beginning of this thread would be “What is the point of the Fourier analysis?” I wasn’t very clear about that when I wrote the comment, but I think I have clarified it a bit in my mind now.
First of all, I’d say that the question about diagonalizing the linear map is the real question here. If we fully understood its eigenvectors and eigenvalues, then it should be possible to start thinking about why every function in the class we are interested in had to have a reasonable projection on to the subspace where the eigenvalues were not too tiny. Now it could be that looking at everything through the lens of the Fourier transform already takes us some way towards the diagonalization. That is, it could be (and there is some plausibility to what I am saying — it’s not just a wild hope) that the kernel
is the real question here. If we fully understood its eigenvectors and eigenvalues, then it should be possible to start thinking about why every function in the class we are interested in had to have a reasonable projection on to the subspace where the eigenvalues were not too tiny. Now it could be that looking at everything through the lens of the Fourier transform already takes us some way towards the diagonalization. That is, it could be (and there is some plausibility to what I am saying — it’s not just a wild hope) that the kernel  is already somewhat closer to being diagonal than the matrix we have in physical space. So it could be that finding the diagonalization would be easier if we started with
is already somewhat closer to being diagonal than the matrix we have in physical space. So it could be that finding the diagonalization would be easier if we started with  .
.
That said, in physical space we have the advantage of being able to write down an expression that’s easy to understand. Let me do that. The xy entry of the matrix is equal to the number of homogeneous arithmetic progressions that contain both and
and  . The common difference
. The common difference  of such a progression has to be a factor of
of such a progression has to be a factor of  , and the number of times
, and the number of times  counts is the number of multiples of
counts is the number of multiples of  that belong to the interval
that belong to the interval ![[\max\{x,y\},n]](https://s0.wp.com/latex.php?latex=%5B%5Cmax%5C%7Bx%2Cy%5C%7D%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . (Here is where allowing weights could be useful: it would allow one to smooth off the nasty boundary effects.)
. (Here is where allowing weights could be useful: it would allow one to smooth off the nasty boundary effects.)
That gives us a slightly unpleasant quantity to work with, but we can at least see that it is large when has plenty of small factors.
has plenty of small factors.
This seems to be inviting us to define everything in terms of prime factorizations. Perhaps with the right system of weights we could get a matrix that could be explicitly diagonalized.
February 20, 2010 at 7:13 pm
Something quite natural we may try is to try to represent the discrepency along each HAP by some new auxiliary function depending on the original function. For example, we can try the following.
Define and
and  if
if  is not of the form
is not of the form  . The functions
. The functions  reflext the discrepenct along HAP. The 2-norm of
reflext the discrepenct along HAP. The 2-norm of 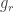 is a measure of the discrepency. If f is completely multiplicative then these functions (up tp spacing and a sign) are in some sense the same.
is a measure of the discrepency. If f is completely multiplicative then these functions (up tp spacing and a sign) are in some sense the same.
The question is: Is there a simple way to express the Fourier coefficients of and more generally of
and more generally of 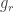 in terms of the Fourier coefficients of
in terms of the Fourier coefficients of  . (If we cannot find a useful expression perhaps we can at least give some bounds.)
. (If we cannot find a useful expression perhaps we can at least give some bounds.)
February 20, 2010 at 7:15 pm
And thanks for the answers, Tim.
February 20, 2010 at 9:42 pm
I don’t know if this is anything more than a curiosity, but if one uses the weight function (so allowing negative weights, which may defeat the whole point of the exercise), then the
(so allowing negative weights, which may defeat the whole point of the exercise), then the  entry of your matrix is approximately
entry of your matrix is approximately
when is large compared to
is large compared to  (one can write down a slightly more complicated exact formula), where
(one can write down a slightly more complicated exact formula), where  is the Euler totient function.
is the Euler totient function.
Perhaps we really want a weight function that decays with , so that the coefficients behave nicely as
, so that the coefficients behave nicely as  .
.
February 20, 2010 at 5:24 pm |
Here I want to try to pursue the thoughts from this comment.
First, let me make the observation (made in different guises several times already) that if the partial sums of are bounded, then
are bounded, then  is bounded by the same bound for every
is bounded by the same bound for every  . This follows easily from partial summation. So it would be enough to find some
. This follows easily from partial summation. So it would be enough to find some  such that that infinite sum is at least
such that that infinite sum is at least  .
.
Now in fact a more accurate bound that comes from partial summation is that the infinite sum is at most , so it would be sufficient to prove that
, so it would be sufficient to prove that
which equals .
.
Expanding out the modulus squared and interchanging summation and integration gives us which equals
which equals 
Now that was just looking at the partial sums of , but we also want to look at the partial sums along HAPs. The corresponding expression we get if we sum along multiples of
, but we also want to look at the partial sums along HAPs. The corresponding expression we get if we sum along multiples of  and take this particular weighted average is (obviously)
and take this particular weighted average is (obviously)  So we could throw in some weights
So we could throw in some weights  and obtain a sum, of which we want a lower bound, of
and obtain a sum, of which we want a lower bound, of  But now we want to express that in terms of x and y. That is, we change variables so that
But now we want to express that in terms of x and y. That is, we change variables so that  and
and  . For each x and y that gives us a term
. For each x and y that gives us a term  .
.
I find that an encouragingly pleasant expression. One possible option would be to take , in which case the xy entry of the matrix would be
, in which case the xy entry of the matrix would be  , where
, where  is the number of factors of
is the number of factors of  , or in other words the number of common factors of
, or in other words the number of common factors of  and
and  . Then the sum of the weights would be
. Then the sum of the weights would be  , so we’d need to beat that with our lower bound.
, so we’d need to beat that with our lower bound.
I’ve slightly glossed over a problem there, which is that this approach seems more naturally suited to functions defined on all positive integers, but if we do that then we end up with . I don’t immediately see what to do about this.
. I don’t immediately see what to do about this.
February 20, 2010 at 11:07 pm
I’ve been trying to decide whether it’s better to use the that I used above or whether
that I used above or whether  is better. It’s a difficult one because
is better. It’s a difficult one because  is more natural for additive problems and
is more natural for additive problems and  is more natural for multiplicative functions, but we have to deal with both. Anyhow, let me try to see how the discussion would have differed if I’d used
is more natural for multiplicative functions, but we have to deal with both. Anyhow, let me try to see how the discussion would have differed if I’d used  . Then the partial summation bound would have been
. Then the partial summation bound would have been  .
.
After expanding out the modulus and interchanging summation and integration I would have got . The integral equals
. The integral equals  , so I’d have got
, so I’d have got  . Looking ahead, that means the matrix element at (x,y) would have been
. Looking ahead, that means the matrix element at (x,y) would have been  , which doesn’t simplify as nicely, though one can of course replace the denominator by
, which doesn’t simplify as nicely, though one can of course replace the denominator by  .
.
I have to go, but I think I may have more to say on this later.
February 20, 2010 at 11:44 pm |
“Even if we knew in advance that there was no hope of solving EDP, there are still some questions that deserve more attention. As far as I can tell, nobody has even
attempted to explain why some of our greedy algorithms appear to give a growth
rate of n^{1/4} for the partial sums. I would love to see just an informal
argument for this.”
If for the integers 1 to 2n a greedy algorithm is used to minimize the
discrepancy then in the region n to 2n the choice of sign of any prime has no effects because the next multiple of the prime is outside the region. So the primes in this region would have a damping effect. I am not sure what this effect would be but I wonder if it would account for the above phenomena or for that matter what numerically the damping effect of these primes would be.
February 21, 2010 at 4:05 pm |
Here’s a question that probably has an easy answer: what happens if we change EDP by requiring the common difference of the HAP to be a prime power?
We have already observed that we can find bounded discrepancy if we insist on a prime common difference: the sequence 1,1,-1,-1,1,1,-1,-1,… is an example with discrepancy 2. However, this is bad on multiples of 4. If we try to correct it on all powers of 2 in the most obvious way then we will end up with something like the Morse sequence, which will almost certainly fail to be an example. (A sufficient condition for it to fail is that there are infinitely many prime powers of the form , but that is far from necessary.)
, but that is far from necessary.)
It seems to me that there are unlikely to be enough constraints on a sequence to stop a greedy algorithm doing pretty well, but I’ve only just come up with the question so I’m not sure how to go about this. Note that going for a multiplicative function is not such a great idea because you need the partial sums to be bounded, just as before, and therefore you need a counterexample to the stronger EDP rather than this weak version.
The reason I thought of this question was that I was wondering about a good system of weights in the expression that occurs near the end of this comment. It occurred to me that taking
in the expression that occurs near the end of this comment. It occurred to me that taking  (where
(where  is the von Mangoldt function) would give rise to a nice expression, since
is the von Mangoldt function) would give rise to a nice expression, since  . However, if that turned out to be useful it would I think prove that one could get unbounded discrepancy with prime power differences (since
. However, if that turned out to be useful it would I think prove that one could get unbounded discrepancy with prime power differences (since  is zero except on prime powers) and there’s no point in trying to prove that if it is false.
is zero except on prime powers) and there’s no point in trying to prove that if it is false.
Alec, these thoughts were partly a response to your suggestion of taking — the fact that
— the fact that  is so often negative is indeed a problem for what I was trying to do, so this was an attempt to come up with the nicest non-negative arithmetical function I could think of. So I’m now quite interested in the matrix with xy entry equal to
is so often negative is indeed a problem for what I was trying to do, so this was an attempt to come up with the nicest non-negative arithmetical function I could think of. So I’m now quite interested in the matrix with xy entry equal to  .
.
February 21, 2010 at 9:07 pm
I don’t know if you can use this answer, but EDP fails over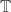 if we only look at HAPs with primepower difference. E.g. take
if we only look at HAPs with primepower difference. E.g. take  .
.
February 22, 2010 at 12:06 am
The Morse sequence is well investigated, but it struck me that the related sequence which allocates +1 to numbers with an even number of zeros in their binary representation, and -1 when the number of zeros is odd might have some interestingly different properties. It allocates the prime 2 the value -1, and 2 behaves multiplicatively (f(2n)=-f(n)).
This may have been explored already, but I was wondering how it performed on the prime power HAPs.
February 22, 2010 at 8:57 am
Sune, I don’t see how to convert your example into a example. Indeed, in the
example. Indeed, in the  case it is clear that no periodic example can work, because if
case it is clear that no periodic example can work, because if  is the period and
is the period and  is the largest power of 2 that divides
is the largest power of 2 that divides  , then the sequence along the HAP with common difference
, then the sequence along the HAP with common difference  is periodic with period
is periodic with period  , which is odd. This means that the growth rate of the partial sums along this HAP is linear (with gradient at least
, which is odd. This means that the growth rate of the partial sums along this HAP is linear (with gradient at least 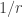 ).
).
February 22, 2010 at 11:02 am
Thinking about it further, I realize that I don’t have an answer to the even simpler question of whether EDP holds if you insist on a common difference that is either a prime or a power of 2. My instinct would definitely be to try to find a counterexample, but the proof that it cannot be periodic still works — indeed, it works just for powers of 2 — so it might be that while counterexamples exist, it is difficult to find an explicit one (as opposed to producing one using a greedy algorithm, say).
If by some miracle EDP were to hold for this smaller set of common differences, then it might turn out to be easier to prove the stronger result, since one would have much more control on how different HAPs intersected. Who knows, perhaps the best growth rate for EDP is and the best for this version is
and the best for this version is 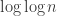 . If so, then it would be pretty hard to discover anything experimentally. I might see if I can work out by hand how long a sequence you can get with discrepancy at most 1 in this version.
. If so, then it would be pretty hard to discover anything experimentally. I might see if I can work out by hand how long a sequence you can get with discrepancy at most 1 in this version.
February 22, 2010 at 11:45 am
That last question turned out to have a boring answer: a discrepancy of at most 1 along HAPs with common difference a power of 2 forces the sequence to be the Morse sequence, which then goes wrong at 12 if you look at multiples of 3.
February 22, 2010 at 3:45 pm
If I vaguely understand you correctly then the weights will imply some result of the form:
For every sequence f(1),f(2),…f(N)
 is large (namely tending to infinity when N tends to infinity) where
is large (namely tending to infinity when N tends to infinity) where 
And you asked what can we say about the support of the weights. This would imply how much can restrict the differences in the HAP so that bounded discrepency is already impossible. (E.g., are prime powers suffice.)
Another related question is this: It looks that when we start with one sequence we can replace it by other sequence (based on blocks depending on the first sequence) so that the discrepency for HAP with “small periods” is forced to be small. So another question is what do such block constructions imply, or suggest, regarding the weights .
.
February 22, 2010 at 7:17 pm
An even weaker version of EDP: Use only HAPs where the difference is either 3 or a power of 2.
February 22, 2010 at 7:32 pm
This turned out to be easy: Let the even terms be the Morse-sequence. Now we know we have bounded discrepancy for the powers of 2 >1. We can choose value at an odd multiple of 3, 3(2n-1) to be minus the value at 3(2n). Now we also have bounded discrepancy for the HAP with difference 3. Since we have bounded discrepancy along 2,4,6,… and have only fixed the value at 1/3rd of the odd numbers, we can also keep the partial sums bounded.
February 22, 2010 at 7:35 pm
What happens if one takes the Morse sequence and repeats every term three times? Obviously the HAP with common difference 3 is OK. The HAP with common difference 2 goes 1 -1 -1 -1 1 1 -1 1 1 1 -1 -1 … In other words, it replaces each 1 in the Morse sequence by 1 -1 -1 and each -1 by -1 1 1. I haven’t checked, but my guess is that other powers of 2 behave similarly.
In fact, thinking about it for a few seconds longer, I’m pretty sure that it’s true in general that for each power of 2 you get a block x of length 3 such that the sequence along that HAP is x -x -x x -x x x -x -x x x -x etc.
So here’s a question in the opposite direction. Let’s suppose that is a sufficiently fast-growing sequence. Does it follow that we can find a sequence of
is a sufficiently fast-growing sequence. Does it follow that we can find a sequence of  with bounded discrepancy with respect to HAPs with common difference
with bounded discrepancy with respect to HAPs with common difference 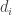 for some
for some  ?
?
A first case would be where for some
for some 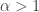 . A spirit-of-Erdős conjecture (with the difference that I haven’t thought about it enough to rule out that it is a stupid problem) could be that there is always a counterexample if
. A spirit-of-Erdős conjecture (with the difference that I haven’t thought about it enough to rule out that it is a stupid problem) could be that there is always a counterexample if  . That is carefully designed not to conflict with the
. That is carefully designed not to conflict with the  -or-prime question.
-or-prime question.
February 22, 2010 at 7:37 pm
Just seen your example after typing in mine. I prefer yours …
February 22, 2010 at 7:41 pm
Maybe your general technique does the -or-prime question as well. One could take the Morse sequence at multiples of 8, or something like that, and then … hmm, maybe I don’t see how to make this work. The rough idea was supposed to be that it would then be fairly easy to deal with HAPs with odd common difference. But I don’t actually see why that would be easy, because the example that works for odd HAPs, namely 1, -1, 1, -1, … would keep getting disrupted by the Morse bits.
-or-prime question as well. One could take the Morse sequence at multiples of 8, or something like that, and then … hmm, maybe I don’t see how to make this work. The rough idea was supposed to be that it would then be fairly easy to deal with HAPs with odd common difference. But I don’t actually see why that would be easy, because the example that works for odd HAPs, namely 1, -1, 1, -1, … would keep getting disrupted by the Morse bits.
February 22, 2010 at 8:20 pm
“A first case would be where for some
for some 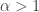 . A spirit-of-Erdős conjecture (with the difference that I haven’t thought about it enough to rule out that it is a stupid problem) could be that there is always a counterexample if
. A spirit-of-Erdős conjecture (with the difference that I haven’t thought about it enough to rule out that it is a stupid problem) could be that there is always a counterexample if  . That is carefully designed not to conflict with the
. That is carefully designed not to conflict with the  -or-prime question."
-or-prime question."
I think this is false if EDP is true. Notice that if we look at if we have a sequence with bounded discrepancy along the HAPs with difference resp. d, 2d, 3d, … nd, we can pass down to the HAP with difference d and get a sequence with bounded discrepancy along the HAPs with difference 1,2,3,…n. So assume that your conjecture is true. Choose a very fast growing sequences, . If the sequence grows fast enough, we should be able to find a sequence with bounded discrepancy along HAPs with difference
. If the sequence grows fast enough, we should be able to find a sequence with bounded discrepancy along HAPs with difference  . Passing down to the HAP with difference
. Passing down to the HAP with difference  gives you a sequence with bounded discrepancy along HAPs with difference
gives you a sequence with bounded discrepancy along HAPs with difference  . Compactness gives an counterexample to EDP.
. Compactness gives an counterexample to EDP.
February 21, 2010 at 6:06 pm |
To try to get some intuition about what the spectral decomposition of a matrix such as might conceivably be like, I’m going to imagine a more general situation. Just before I say what that is, let me point out what this matrix has going for it: it is positive definite, and pretty big on the diagonal (the latter because the highest common factor of x and x tends to be a lot bigger than the highest common factor of x and y).
might conceivably be like, I’m going to imagine a more general situation. Just before I say what that is, let me point out what this matrix has going for it: it is positive definite, and pretty big on the diagonal (the latter because the highest common factor of x and x tends to be a lot bigger than the highest common factor of x and y).
As I write, I suddenly realize that a cleverer choice of than
than 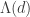 might have been
might have been  . That way we would get
. That way we would get  , which is rather nicer.
, which is rather nicer.
Anyhow, my model situation is this. We have a finite set and some subsets
and some subsets 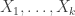 and we define
and we define  to be the number of
to be the number of  such that both
such that both  and
and  belong to
belong to  . I’d like to know what the eigenvectors of this linear map are like when there aren’t too many sets. (The rank of the matrix will be at most
. I’d like to know what the eigenvectors of this linear map are like when there aren’t too many sets. (The rank of the matrix will be at most  so there will be a big eigenspace with eigenvalue 0. I’m interested in the rest.)
so there will be a big eigenspace with eigenvalue 0. I’m interested in the rest.)
We know that this matrix will have a non-negative eigenvector. It may not be easy to say exactly what it is, but perhaps we can say something about its properties. For instance, we know that it will be a linear combination of the characteristic functions of the . If it is
. If it is  , then its image is
, then its image is  , so we know that
, so we know that  is proportional to
is proportional to  . In other words, we are interested in the matrix
. In other words, we are interested in the matrix  and its eigenvectors.
and its eigenvectors.
To try to understand this better, let’s consider a very simple case, where ,
,  and
and  for some
for some  . Then we are looking at the matrix with entries
. Then we are looking at the matrix with entries  . The characteristic polynomial is
. The characteristic polynomial is  , which has roots
, which has roots  . If we choose a convenient value of
. If we choose a convenient value of  such as 5/16, then we have
such as 5/16, then we have  and
and  , so the two roots are 25/16 and 1/16. The eigenvector with eigenvalue 25/16 has entries 1 and u such that
, so the two roots are 25/16 and 1/16. The eigenvector with eigenvalue 25/16 has entries 1 and u such that  , so
, so  and
and  . I feel far from confident that this is correct, and I’ve lost track of what I was hoping to get out of it.
. I feel far from confident that this is correct, and I’ve lost track of what I was hoping to get out of it.
The basic thing I’d like to do is try to understand how the ways that the intersect affects the shape of the eigenvectors. Does anyone know anything about this?
intersect affects the shape of the eigenvectors. Does anyone know anything about this?
February 21, 2010 at 7:25 pm
Probably this subproblem would make a good question for mathoverflow and its large algebro-geometric readership, it might even be a classical subject for them.
February 21, 2010 at 9:35 pm
In case it helps, here is a picture of the elements of the positive eigenvector of the matrix whose elements are
whose elements are  , plotted on a log-log scale.
, plotted on a log-log scale.
February 21, 2010 at 11:50 pm
Another gorgeous diagram! I think it would be very useful also to have a few values tabulated — up to 200, say — so one could get an idea of how the value of the eigenfunction depends on the prime factorization of the number itself.
February 22, 2010 at 11:36 am
In haste… as can be seen in the previous picture, the elements of the eigenvector decay at rate . This picture shows what happens if you scale up the nth element by
. This picture shows what happens if you scale up the nth element by  . Points on the lower boundary occur at primes. Points on the upper boundary occur at highly composite numbers, though the precise pattern is not clear.
. Points on the lower boundary occur at primes. Points on the upper boundary occur at highly composite numbers, though the precise pattern is not clear.
February 22, 2010 at 11:53 am
Incidentally, when I say that the elements of the eigenvector decay at rate , I’m speaking very loosely: it looks as though the running minimum decays at roughly
, I’m speaking very loosely: it looks as though the running minimum decays at roughly  , but it’s hard to say exactly what’s going on with the running max.
, but it’s hard to say exactly what’s going on with the running max.
February 22, 2010 at 1:28 pm
Perhaps it would be better to plot only the points and don’t connect them with lines?
February 22, 2010 at 8:21 pm
Here you are, Sune.
February 22, 2010 at 8:45 pm
It’s very clear that there is some partitioning of the integers going on here. Are you able to present it to us in some easily digestible form so we can try to work out the pattern? Then it might be possible to make a guess about what the eigenvector actually is (or perhaps just to guess an approximation to it).
Another thing that would be very interesting indeed would be to work out what the eigenvector with the next largest eigenvalue is. I don’t know if you’re using a package that can do that quickly and easily.
February 22, 2010 at 9:15 pm
I’m using Mathematica. I’m wiki-literate, otherwise I’d create a page and put the first few thousands entries there. Let me try to put the first 100 entries here–I hope it won’t look too bad:
{1., 2.11102, 2.81802, 3.8597, 3.61534, 5.75823, 4.00197, 6.35191, \
6.03905, 7.26692, 4.32967, 10.1464, 4.39645, 7.9459, 9.39487, \
9.59086, 4.46601, 11.859, 4.49177, 12.5566, 10.1864, 8.44294, \
4.50222, 16.0052, 8.32411, 8.50826, 10.6031, 13.529, 4.50517, \
18.0482, 4.51182, 13.4171, 10.6934, 8.53287, 12.3541, 19.9551, \
4.50549, 8.5356, 10.7248, 19.353, 4.49567, 19.2631, 4.48884, 14.0761, \
18.173, 8.4719, 4.48422, 23.0056, 9.0444, 15.624, 10.6619, 14.0592, \
4.46045, 19.8037, 12.7455, 20.489, 10.6336, 8.36961, 4.43931, \
29.6064, 4.43621, 8.3527, 19.1655, 17.4809, 12.6807, 19.7686, \
4.40838, 13.8927, 10.4793, 22.7692, 4.41709, 29.8178, 4.40162, \
8.25771, 19.2753, 13.8107, 13.3357, 19.6322, 4.38885, 27.0662, \
15.6337, 8.18873, 4.38498, 30.9959, 12.4535, 8.14757, 10.2706, \
20.783, 4.35536, 32.9945, 13.2172, 13.5572, 10.231, 8.10037, 12.3841, \
30.3699, 4.32922, 16.3485, 19.3677, 24.9019}
February 22, 2010 at 9:24 pm
Ouch – that wasn’t great. And, obviously, I meant I’m *not* wiki-literate above. I’ve put the Mathematica notebook here if anyone else wants to have a look.
Regarding the various strata that are visible in the picture:
The bottom one is the primes
The next up is 2 x primes
The next one up, which is sparser, is the primes squared
The next up is 3 x primes
The next up is 5 x primes
…
Then there is some bunching up
…
Then the primes cubed (very sparse)
Then 2 x primes squared
….
I should reiterate for the benefit of people reading these comments rapidly that what I’m plotting here is not the elements of the eigenvector, but these elements scaled up at rate . (Here’s what the unscaled picture looks like.)
. (Here’s what the unscaled picture looks like.)
February 22, 2010 at 9:25 pm
I may be able to work it out from what you’ve given, but what I was really hoping for was this. Looking at your diagram with the points, they seem to belong to very nice curves (or at least many of them do). I’d be particularly curious to know which integers belong to which curves. Precisely what the value of the function is interests me less (for now, though eventually I’d be very interested to know what the curves are too). When I get time, I’ll have a look at the 100 values you’ve provided and see if I can extract a small set of “continuous” functions from it.
February 22, 2010 at 9:26 pm
Ah, while I was writing that comment you gave me just what I wanted to know.
February 22, 2010 at 10:14 pm
Here’s a plot of the second eigenvector of , with no
, with no  scaling and on a log-vs-linear scale for obvious reasons.
scaling and on a log-vs-linear scale for obvious reasons.
No time to investigate what’s going on here further, unfortunately, but I’ve updated the Mathematica notebook in case anyone wants to play around with it.
February 22, 2010 at 10:23 pm
It occurs to me that perhaps the second eigenvector plot is harder to interpret than the first eigenvector plot: I think some of its qualitative features may be more sensitively dependent on the cutoff (ie, on the dimension of the matrix: 3000 in these examples).
February 23, 2010 at 12:25 am |
Let me try to think about the first eigenvector by trying to think what happens if we start with the constant function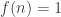 and repeatedly apply
and repeatedly apply  to it. So at the first stage we have
to it. So at the first stage we have  . Already I’m not quite sure what’s happening. In fact, I’m worse than not quite sure, since if we sum to infinity then this diverges (since
. Already I’m not quite sure what’s happening. In fact, I’m worse than not quite sure, since if we sum to infinity then this diverges (since  is always at least 1).
is always at least 1).
Obviously, one could try to deal with this by summing to some large instead. But that feels as though it would introduce ugly cutoff effects. (On the other hand, I think that’s what Ian has been doing and his pictures look as though they may have quite pleasant descriptions.) So instead I want to think about whether one can make sense of the ratio of
instead. But that feels as though it would introduce ugly cutoff effects. (On the other hand, I think that’s what Ian has been doing and his pictures look as though they may have quite pleasant descriptions.) So instead I want to think about whether one can make sense of the ratio of 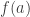 and
and 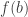 . I’ll start with the case where
. I’ll start with the case where  is a prime. Then
is a prime. Then  goes to infinity like
goes to infinity like  . The way I worked that out was to say that if we pick a random integer
. The way I worked that out was to say that if we pick a random integer  then we add roughly
then we add roughly  (when
(when  is large and therefore roughly equal to
is large and therefore roughly equal to  , multiplicatively speaking) and with probability
, multiplicatively speaking) and with probability  we add a further
we add a further  .
.
So the rate of growth associated with is
is  . So I’m going to deal with this by just dividing through by
. So I’m going to deal with this by just dividing through by  at the end.
at the end.
That was just for prime. What if
prime. What if  is twice a prime? Let’s write
is twice a prime? Let’s write  . This time our growth rate will be
. This time our growth rate will be  , which, after we divide by
, which, after we divide by  , gives us
, gives us  .
.
At this point I want to approximate, by taking to be fairly large. So if
to be fairly large. So if  is a prime I map it to 1, and if
is a prime I map it to 1, and if  is twice a prime I map it to
is twice a prime I map it to 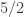 .
.
And what is happening in general? For this I’ll do the calculation differently. For every factor of
of  I’ll get a contribution of
I’ll get a contribution of  with probability
with probability  . (Check: when
. (Check: when  we get
we get  which is approximately 3. (Honesty compels me to say that I had in fact made a mistake earlier and got 5/2, so that check was worthwhile.) And what is
which is approximately 3. (Honesty compels me to say that I had in fact made a mistake earlier and got 5/2, so that check was worthwhile.) And what is  ?
?
I don’t know whether that has a nice interpretation, so instead I’ll try applying the matrix again. So now we obtain a function . Following what I did last time I’ll just forget about dividing by
. Following what I did last time I’ll just forget about dividing by 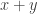 and I’ll take an average over all
and I’ll take an average over all  . But I don’t see anything nice coming out of this.
. But I don’t see anything nice coming out of this.
What about a qualitative description? It definitely seems that the smoother a number is the better it is going to do. So one might guess that there is some measure of smoothness and that
and that  is proportional to
is proportional to  . This would be saying something like that you can get a reasonable idea of how smooth a number
. This would be saying something like that you can get a reasonable idea of how smooth a number  is by seeing how smooth other numbers are that have big common factors with
is by seeing how smooth other numbers are that have big common factors with  .
.
February 23, 2010 at 1:15 am
In view of this picture, how about starting with the function , and applying
, and applying  to that?
to that?
Then , so the sum converges. If
, so the sum converges. If  is a prime, then
is a prime, then  .
.
Cleaning this up a bit, . Approximating this by an integral from
. Approximating this by an integral from  to
to  ,
,  .
.
February 23, 2010 at 1:19 am
Er,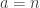 in the above.
in the above.
February 23, 2010 at 1:59 am |
Let me correct the small typo in my post above: if is a prime, then
is a prime, then  .
.
If is twice a prime, then following the same approach gives
is twice a prime, then following the same approach gives  . And if
. And if  is a prime squared, then
is a prime squared, then  .
.
February 23, 2010 at 4:03 am |
D’oh! I think I made the same mistake you made earlier, which caused me to get a 5/2 when I should have had a 3 in the case . The corrected version for this case is
. The corrected version for this case is  .
.
In general, if for distinct primes
for distinct primes 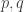 , we have
, we have  , assuming I haven’t made any more silly mistakes.
, assuming I haven’t made any more silly mistakes.
So if is the product of twin primes
is the product of twin primes  ,
,  can be as large as about
can be as large as about  ; in the typical case in which
; in the typical case in which  ,
,  is quite a bit smaller.
is quite a bit smaller.
February 23, 2010 at 8:40 am
Follow-up question: is there an obvious function such that (i)
such that (i)  simplifies somehow and (ii)
simplifies somehow and (ii)  is constant over primes
is constant over primes  , constant over twice-primes
, constant over twice-primes 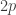 , … , over squared primes
, … , over squared primes  , … in such a way that it replicates the layers visible in the plot, which also seem to be coming out of these calculations?
, … in such a way that it replicates the layers visible in the plot, which also seem to be coming out of these calculations?
February 23, 2010 at 10:08 am
That does look like a good question. I’m going to add the condition that it is smallest for primes, next smallest for twice-primes, and so on, and have a look at the Wikipedia page on arithmetic functions to see if anything jumps out at me.
February 23, 2010 at 10:28 am
Nothing did, but an idea occurred to me, which was that perhaps is of the form
is of the form  for some function
for some function  . If so, then we’d be able to find
. If so, then we’d be able to find  by Möbius inverting
by Möbius inverting  : that is,
: that is,  . It’s a stab in the dark, but do we get anything interesting if we Möbius invert the function
. It’s a stab in the dark, but do we get anything interesting if we Möbius invert the function  that we’re given experimentally?
that we’re given experimentally?
February 23, 2010 at 11:06 am
Here’s a plot of the Mobius inversion of the experimental using the 2000×2000 matrix
using the 2000×2000 matrix  .
.
There are some visible patterns: for example, the clearly defined upper stripe is the primes, and the most obvious stripe below is the twice-primes.
February 23, 2010 at 4:41 am |
I haven’t read this for a while, and I’m sure this has already been mentioned, but the sequence is made out of 14 letter alphabet with distinct combination rules. Each letter represents a 4 digit sequence that contains no more than three 1’s or three -1’s.
I’ll think about this some more, as I am sure the algorithm’s that people are running are probably already doing something similar, and I saw someone had already done some analysis using 4 digit binaries. What I am thinking though is that one could determine whether or not the there is a rate of growth in the number of permissible letter combinations. If there isn’t and it only goes to extinction (or one unique solution) that would be an interesting result itself I think.
February 23, 2010 at 11:47 am |
One could also view the problem as reducing to a sequence of movements on a unit hypercube. It would be interesting to see whether the movements take on any patterns, or rather if the movements are restricted to edge, face or volume movements.
February 23, 2010 at 12:02 pm |
I suppose one could also ask in terms of the rotations and reflections.
February 23, 2010 at 12:30 pm |
I’m still trying to make a decent guess in response to Ian’s question. I’ve tried several things and not got very far yet. But maybe some useful clues could come from the ratios that are there in the data. For instance, it looks as though tends to a limit as
tends to a limit as  tends to infinity (along the primes). So this gives us some number
tends to infinity (along the primes). So this gives us some number  to think about.
to think about.
I’m still puzzled about why squares of primes should behave as they do. It seems that being a square of a prime is worse than being three times a prime, and much worse than being a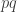 for primes
for primes  and
and  of comparable size.
of comparable size.
One thing I’m about to look at, without much hope of a miracle: is the eigenvector a multiplicative (as opposed to completely multiplicative) function?
February 23, 2010 at 3:31 pm
Answer: it seems not.
A few experimental questions that interest me are as follows.
(i) What does the restriction of the graph of to numbers of the form
to numbers of the form  look like?
look like?
(ii) More generally, if you pick a large prime and look at the ratios
and look at the ratios  for small values of
for small values of  , then what does that look like as a function of
, then what does that look like as a function of  ?
?
(iii) Does that function have more or less the same shape as itself?
itself?
(iv) What does look like at integers of the form
look like at integers of the form 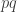 with
with  and
and  primes of roughly the same size?
primes of roughly the same size?
February 23, 2010 at 7:01 pm
I’m entering a busy phase but will try to have a look at these at some point. (Given the addictiveness of this, I’ll probably get round to it fairly soon…)
Regarding the experimental evidence on prime squares vs thrice primes: isn’t this what we see happening based on the approximations here and here? For example, if
if  is a thrice prime and
is a thrice prime and  if
if  is a prime squared.
is a prime squared.
Admittedly, these approximations are (i) upper bounds and (ii) upper bounds on the behaviour of the first iterate of , rather than the eigenvector/fixed-point, but it seems an encouraging sign.
, rather than the eigenvector/fixed-point, but it seems an encouraging sign.
Incidentally, I think it’s also possible to provide lower bounds for this first iterate. For example if a prime, then
a prime, then ![[(n-1)\pi+4n \arctan \sqrt{n}]/(2n^{3/2}) \leq Af(n) \leq (2n-1)\pi/n^{3/2}](https://s0.wp.com/latex.php?latex=%5B%28n-1%29%5Cpi%2B4n+%5Carctan+%5Csqrt%7Bn%7D%5D%2F%282n%5E%7B3%2F2%7D%29+%5Cleq+Af%28n%29+%5Cleq+%282n-1%29%5Cpi%2Fn%5E%7B3%2F2%7D&bg=ffffff&fg=333333&s=0&c=20201002) , which looks like
, which looks like  if
if  is large. I haven’t yet done this in the cases
is large. I haven’t yet done this in the cases  or
or  , but will try to do this at some stage soon unless you think this is a dead end?
, but will try to do this at some stage soon unless you think this is a dead end?
Finally, another experimental observation: it also looks as though the primes cubed are worse than being twice a prime squared.
February 23, 2010 at 3:53 pm |
I’ve been thinking about a graph-theoretical generalization of the problem, which unfortunately doesn’t include the multiplicative feature.
Define an infinite set of nodes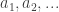 such that given a node
such that given a node  there is a directed edge labelled
there is a directed edge labelled  from
from  to
to  for all
for all  .
.
Give each node a value 1 or -1. Consider a traversal starting at a node moving along edges with the same label a finite number of times; then the discrepancy of a given traversal is the absolute value of the sum of all nodes visited. Asking if it is possible for the discrepancy to be bounded is equivalent to our problem.
What’s interesting is the graph doesn’t have to follow the number system. Have a set of nodes (finite or infinite) such that there are labelled directed edges, but allow the edges to be arbitrary. Then there are interesting questions like; given a discrepancy d, what is a minimal graph (in terms of nodes and/or edges) where the discrepancy is greater than d? What conditions cause the discrepancy to “break”? My hope is we can isolate certain graph theoretic properties which cause the logic to break and translate those into number theoretic properties we can search for (perhaps very rare ones, but ones we can prove exist nonetheless).
such that there are labelled directed edges, but allow the edges to be arbitrary. Then there are interesting questions like; given a discrepancy d, what is a minimal graph (in terms of nodes and/or edges) where the discrepancy is greater than d? What conditions cause the discrepancy to “break”? My hope is we can isolate certain graph theoretic properties which cause the logic to break and translate those into number theoretic properties we can search for (perhaps very rare ones, but ones we can prove exist nonetheless).
February 23, 2010 at 3:56 pm
Sorry, I should add it’s only equivalent to our problem if we only allow traversals to start at the root node of a particular set of labelled edges.
February 23, 2010 at 4:50 pm
Your generalization is in a similar spirit to a generalization that Terry suggested a few weeks ago, but it seems to be more general still. It would be very nice if one could come up with a graph-theoretic conjecture that was significantly more combinatorial than EDP but still hard.
February 23, 2010 at 5:42 pm
While it’s fun to think about the completely general version of the structure (for example, cycles of odd degree cause unbounded discrepancy), for the sake of the original problem it might be useful to set some conditions:
Given a set of nodes :
:
1. One labelled set of edges connects to
to 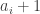 for all i from 1 to n-1.
for all i from 1 to n-1.
2. For any edge from to
to 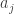 , i is less than j.
, i is less than j.
3. Given a set consisting of all labelled edges of a given label, any traversal starting from the root node of the set can traverse the entire set of edges.
4. No set of edges is a subset of another set (this prevents having arbitrary start points).
Given these conditions, the minimal set of nodes where the discrepancy must be greater than 1 is 4.
Proof: Consider every possible set of edges using 3 nodes.
set A: 1->2->3
set B: 1->3
Then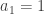 ,
,  ,
,  has a discrepancy of 1.
has a discrepancy of 1.
However, consider these sets with 4 nodes:
set A: 1->2->3->4
set B: 1->3
set C: 1->4
Then no combinations of +1 and -1 (set A constrains the possibilities to + – + -, – + + -, + – – +, and – + – +) avoids having a discrepancy of 2 in some set of edges.
February 23, 2010 at 4:35 pm |
I want to try once more to explain why I’m interested in the eigenvalues and eigenvectors of the matrix , partly for my own benefit.
, partly for my own benefit.
The starting point is a wish to prove EDP by means of a suitable averaging argument. That is, instead of proving that there exists a HAP such that
such that  , one attempts to prove that the sum is large on average.
, one attempts to prove that the sum is large on average.
There is a great deal of flexibility in how one interprets this, since we can apply a monotonic function to the sum before taking the average, and we can also introduce weights. To be more explicit, suppose that is some strictly increasing function. Then
is some strictly increasing function. Then  if and only if
if and only if  . Therefore, if
. Therefore, if  is a set of HAPs, and to each
is a set of HAPs, and to each  we assign a weight
we assign a weight  in such a way that
in such a way that  , then a sufficient condition for there to exist a HAP with
, then a sufficient condition for there to exist a HAP with  is that
is that  .
.
The most obvious choice of function is
is  , since this is gives us a positive-definite quadratic form in
, since this is gives us a positive-definite quadratic form in  and potentially makes available to us the tools of linear algebra.
and potentially makes available to us the tools of linear algebra.
We can think of this quadratic form as follows. Let be the linear map from
be the linear map from  to
to  that’s defined by
that’s defined by  , and let
, and let  be the diagonal map from
be the diagonal map from  to itself that has matrix
to itself that has matrix  . Then the quadratic form takes the column vector
. Then the quadratic form takes the column vector  to
to  . It ought to be useful if we could diagonalize this quadratic form, which is equivalent to finding
. It ought to be useful if we could diagonalize this quadratic form, which is equivalent to finding  functions
functions  such that
such that  . The most obvious way to try to do that is to take the symmetric
. The most obvious way to try to do that is to take the symmetric  matrix
matrix  and find an orthonormal basis of eigenvectors. But it occurs to me while writing this that there might be other useful ways of diagonalizing the quadratic form. Or maybe one would be happy to settle for more than
and find an orthonormal basis of eigenvectors. But it occurs to me while writing this that there might be other useful ways of diagonalizing the quadratic form. Or maybe one would be happy to settle for more than  functions
functions 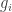 , as long as they were somehow “nice”. It is of course always open to us to choose the weights to try to make them nice.
, as long as they were somehow “nice”. It is of course always open to us to choose the weights to try to make them nice.
February 23, 2010 at 6:19 pm |
This might be a stupid question, but I’ll ask it anyway: Does there exist a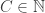 such that for any
such that for any 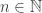 there is a finite {1,-1}-sequence
there is a finite {1,-1}-sequence 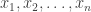 such that for any
such that for any  :
:
That is, we don’t care for partial sums, but only for HAPs that goes all the way to n.
February 23, 2010 at 6:20 pm
How about making the first half of the equal to 1 and the second half equal to -1?
equal to 1 and the second half equal to -1?
February 23, 2010 at 8:11 pm |
Something else that would help a lot in the process of seeing whether any diagonalizing-of-matrices approach could work is to think about what any proof that is large could possibly look like. For example, it is obvious that if the smallest eigenvalue of
is large could possibly look like. For example, it is obvious that if the smallest eigenvalue of  is
is  , then
, then  , since the best you can do is choose an eigenvector with eigenvalue
, since the best you can do is choose an eigenvector with eigenvalue  . However, we also know that that is not how a proof of EDP could look, since there are functions
. However, we also know that that is not how a proof of EDP could look, since there are functions  such that
such that  is large and the discrepancy is small, such as our old friend 1, -1, 0, 1, -1, 0, 1, -1, 0, …
is large and the discrepancy is small, such as our old friend 1, -1, 0, 1, -1, 0, 1, -1, 0, …
What I have been suggesting is an intermediate result, in which we assume not just a lower bound on but also an upper bound on
but also an upper bound on  . How might that help?
. How might that help?
Well, if we knew that the only eigenvectors with very small eigenvalues were very trigonometric in shape, then we might be getting somewhere, since then the only way for to be large without
to be large without  correlating with a trigonometric function would be for
correlating with a trigonometric function would be for  to have a reasonable projection on to the space generated by eigenvectors with larger eigenvalues.
to have a reasonable projection on to the space generated by eigenvectors with larger eigenvalues.
It’s quite plausible that low-eigenvalue eigenvectors are trigonometric in nature, since periodic examples seem to give us a rich supply of low-discrepancy sequences (and hence sequences that are mapped to something small by our matrix). So this might be something that’s not too hard to investigate.
Why isn’t this just restating the problem? I think it’s because I’d hope that we could find such a big supply of functions that are mapped to small things that we would “run out of the small part” of the spectral decomposition. It might not be necessary to find the eigenvectors. Sorry to be a bit vague here. I think the next thing to do is see what the matrix does to trigonometric functions.
February 23, 2010 at 8:12 pm
Hmm … immediately after submitting that I realized it was very close to what I was trying to do earlier with the continuous kernel. But that doesn’t stop me wanting to think about it.
February 23, 2010 at 8:26 pm |
I promised that I would write something about pseudointegers on the wiki and give a summary. I have written the page now, but I haven’t proved as much as I had hoped. Here is what I have found out:
For a pseudointeger we look at the density of pseudointegers that are divisible by x. In one of the models where EDP fails this is 0 for all
we look at the density of pseudointegers that are divisible by x. In one of the models where EDP fails this is 0 for all  and in another this is 1 for all x. I have proved, that if it is 0 for one x, it is 0 for all
and in another this is 1 for all x. I have proved, that if it is 0 for one x, it is 0 for all  . If it is 1 for a
. If it is 1 for a  , it must be 1 for all x.
, it must be 1 for all x.
It turns out, that for a set X of “pseudointegers” as I defined it here (@Tim: sorry for stealing the word) you can find a (non necessarily injective, but non-trivial) function with
with  and
and  . It is defined such that if the density of integers divisible by x is
. It is defined such that if the density of integers divisible by x is  , then
, then  . If furthermore the limit
. If furthermore the limit
exists and we know that the density
we know that the density  must exists.
must exists.
I think it is a good idea to think of pseudointegers as subsets of R, but as Tim noticed here it gives some difficulties (if there exists n such that
there exists n such that  ), so it might still make sense to use the more general definition.
), so it might still make sense to use the more general definition.
February 24, 2010 at 8:16 am |
I thought that maybe it will be a good idea to try even superficially some orthogonal ideas (at least to my own, it is so not easy keeping track).
First, a remark: It looks that the only definite result in the positive direction is about functions correlated with a character and I would be happy if somebody can explain informally, “why” this result is true, and does it “explain” the observed log-n discrepency.
So I thought about probabilistic heuristical ideas towards sequences with low discrepency.
How to construct prove using a random method that sequences with low discrepency exist? or even to estimate roughly the number of such sequences? Heuristically, if we want to keep the discrepency on a AP below K we need to impose conditions on intervals of length about or a little less. (If we assume that
or a little less. (If we assume that  then we can be pretty sure that the partial sums are below
then we can be pretty sure that the partial sums are below 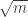 or so.)
or so.)
Altogether on all HAP we have nlogn/(K^2) conditions; and each one represents an event whose probability is roughly 1/K, so a rough estimate of the overall probability for a sequence to satisfy all these conditions is (1/K)^nlogn/K^2 which should be larger than 2^-n.
So if K is little more than sqrt log n it looks good.
There are now good news and bad news:
The bad news is that we do not have independence. There are methods to prove the existence of rare events even if there is some slight dependencies (e.g., Lovasz Local Lemma) but you still need much more independence.
The good news is that it seems that the correlation is positive. So if you already assume that sums of s is zero (or close to zero) for certain entervals in some HAP then it is more likely that such sums are zero when you take sums along intervals in other HAP.
s is zero (or close to zero) for certain entervals in some HAP then it is more likely that such sums are zero when you take sums along intervals in other HAP.
But the good news are not that good in the sense that I see no (even heuristically) reason to believe that this positive correlation will replace the 1/K with something larger than 1/2 and this will not make a big difference. (But this deserves more thinking.)
What about general AP (just as a sanity test). Here, the n log n is replaced by n^2 so K indeed is expected to be larger. It would be interesting to compare the discrepency results for AP (Roth?) with what the probabilistic heuristic gives to get some intuition.
If such a heuristic can show that the probability for a sequence with low discrepency (say polylog n) is sufficiently large, I see no reason why such low discrepency will force some periodic behavior.
February 24, 2010 at 9:32 am
How was the -bound for general APs proved?
-bound for general APs proved?
February 24, 2010 at 9:46 am
I find this line of thought interesting, and I would certainly be very interested indeed in a proof that there were many examples with logarithmic discrepancy.
One thing I didn’t understand was your assertion that the correlations were positive. For example, it looks as though by far the easiest way to make the discrepancy small along all HAPs with odd common difference is to take a periodic sequence such as 1, -1, 1, -1, … or 1, 1, -1, -1, 1, 1, -1, -1, … which suggests a negative correlation with low discrepancy along HAPs with common difference a power of 2.
It could be that this heuristic argument breaks down if one looks only at logarithmic discrepancy, but I still don’t see any evidence for positive correlation. Indeed, the rough picture I had in mind was that there was negative correlation, in that in general it seems that periodicity tends to help a lot with some common differences and be a big problem for others. Or perhaps I mean something a bit more complicated, like positive pairwise correlation but with negative correlations coming in when one tries to ensure many events all at once. (If EDP is true then something like this seems to be the case, since we probably do have reasonable pairwise correlations but we know that we can’t get all the events to hold simultaneously. But again I’m talking about bounded discrepancy rather than logarithmic discrepancy here.)
February 24, 2010 at 9:47 am
Sune’s question is one I want to know the answer to as well, but I’ve been too lazy to get hold of the paper.
February 24, 2010 at 10:23 am
Well, if one drunk person goes at each time-period left and right with probability 1/2 and his lazy twin brother makes precisely the same moves on odd time-periods and stays still on even times periods, then the probabilities for them to end very near to the origin are positively correlated. So I think positive correlation for the kind of events I considered is roughly the “first order” behavior. (I think you are right that there may be subtle negative correlations floating around.)
If my heuristic idea is roughly ok (and it is quite possible I made a serious mistake there), then I would expect that log n discrepency sequences (perhaos even logn^{1/2+epsilon)) will be a rare but positive-probability events, (the number of such sequences will still be exponential), so I would not believe some subtle negative correlation will interfere (of course, proving this is a different matter).
There is some little hope that positive correlations will somehow allow constant-discrepency sequences.
This also suggests that finding in an arbitrary +-1 sequence an interval in an HOP with large discrepency using a pobabilistic argument is something worth trying. But the big obstacle here (as before) would be how to distinguish a +-1 sequence from a 0 +1 -1 sequence.
February 24, 2010 at 10:57 am
A general question that occurred to me was this. Suppose you have a finite set and a collection
and a collection  of subsets of
of subsets of  of even cardinality. Under what conditions can you find a function
of even cardinality. Under what conditions can you find a function 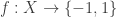 such that
such that  for every
for every  ?
?
My guess is that this problem would be NP-complete in general, so the best one could hope for is a sufficient condition for such a function to exist. The motivation for the question is that one way of restricting the growth along a HAP is to insist, fairly frequently, that the sum is zero. This gives us a collection as above, and the question is how “dense” we can make it.
as above, and the question is how “dense” we can make it.
A small remark is that if we take the linear relaxation (that is, we allow to take arbitrary real values) then we always have the trivial solution of setting
to take arbitrary real values) then we always have the trivial solution of setting  to be identically zero, and we have non-trivial solutions only if the characteristic functions of the sets
to be identically zero, and we have non-trivial solutions only if the characteristic functions of the sets  are linearly independent. If we decide that the sum should be zero at every
are linearly independent. If we decide that the sum should be zero at every  th number along each HAP, then the HAP with common difference
th number along each HAP, then the HAP with common difference  gives rise to around
gives rise to around  linear conditions, so the total number of conditions we need is
linear conditions, so the total number of conditions we need is  , which (for smallish
, which (for smallish  ) is around
) is around  . This suggests that there is something natural about the
. This suggests that there is something natural about the  bound. (Of course, it is possible that there will be dependencies amongst the various conditions, but at first glance they look fairly independent to me.)
bound. (Of course, it is possible that there will be dependencies amongst the various conditions, but at first glance they look fairly independent to me.)
February 25, 2010 at 6:38 pm
That’s quite interesting! I like this linear algebra idea.
A few remarks:
1) Actually we do not have to determine in advance: we only need to assume we can partition the HAP to intervals of length proportional to k (say between k/100 and 100k) so that the equations will be satisfied. (We have a considerable freedom to chose the equations that will still to the discrepency being likely small.)
in advance: we only need to assume we can partition the HAP to intervals of length proportional to k (say between k/100 and 100k) so that the equations will be satisfied. (We have a considerable freedom to chose the equations that will still to the discrepency being likely small.)
2) The linear algebra consideration can go both ways. If you can show using linear algebra that you cannot have the zeros of the sums on all HAP being too “close by” (say uniformly below some constant) this will come close of proving EDP.
(And as a meta comment: trying other techniques like linear algebra methods or polynomial methods or probabilistic methods seem quite reasonable for EDP. unlike DHJ i dont think we have a propri much knowledge which tricks will be relevant.)
3) Strangely we need to understand how such conditions on HAP with large periods depend on conditions for HAP with small periods; Both in terms of “statistical dependence” (my heuristic comment) and in terms of “linear algebra dependence” (your comment).
4) Also the problem of trying to get by stochastic methods low discrepency sequence has a feeling like random walks with various stochastic tools to make the walks frequently return to zero. (Simultaniously for all HAP). It seems we discussed such “biased” random walks before but I dont remember when.
5) Anyway these heuristics taking also with the linear algebra concerns still suggest that discrepency sqrt log n might be possible.
February 26, 2010 at 11:05 am
One further remark. It is initially tempting (or at least it was for me) to conjecture that if you choose many intervals along many HAPs, then you are forced to choose a linearly independent set of intervals. However, I have just realized that the usual example, 1, -1, 0, 1, -1, 0, … shows that that cannot be true, since along every HAP it has a zero sum either always or every third term. The conclusion is that if we take all sets of the form then they (or rather their characteristic functions) are not linearly independent (because they all live in the subspace orthogonal to 1, -1, 0, 1, -1, 0, …).
then they (or rather their characteristic functions) are not linearly independent (because they all live in the subspace orthogonal to 1, -1, 0, 1, -1, 0, …).
But I think that raises an interesting question. If we choose a large set of small segments of HAPs, then must the annihilator of that set consist of very structured functions (e.g. functions that are periodic with period for some small
for some small  and zero at all multiples of
and zero at all multiples of  )? Since this is a linear algebra question, it might be more approachable that EDP itself, but it also seems close enough that an answer to it could be helpful. Even if that is not the case, I like the question.
)? Since this is a linear algebra question, it might be more approachable that EDP itself, but it also seems close enough that an answer to it could be helpful. Even if that is not the case, I like the question.