The post, A combinatorial approach to density Hales-Jewett, is about one specific idea for coming up with a new proof for the density Hales-Jewett theorem in the case of an alphabet of size 3. (That is, one is looking for a combinatorial line in a dense subset of ![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002)
![\null [n]^2](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002)

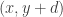
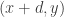
The purpose of this post is to summarize those parts of the ensuing discussion that are most directly related to this initial proposal. Two other posts, one hosted by Terence Tao on his blog, and the other here, take up alternative approaches that emerged during the discussion. (Terry’s one is about more combinatorial approaches, and the one here will be about obstructions to uniformity and density-increment strategies.) I would be very happy to add to this summary if anyone thinks there are important omissions (which there could well be — I have written it fast and from my own perspective). If you think there are, then either comment about it or send me an email.
Two suggestions, made by Terry in comment number 4 (the second originating with his student Le Thai Hoang), led to two of the main threads of the discussion relating to the triangle-removal approach. One was that since Sperner’s theorem is the density Hales-Jewett theorem for alphabets of size 2, and since there is no obvious way of generalizing the existing proofs of Sperner’s theorem to obtain the density Hales-Jewett theorem, then it would make sense to look for other proofs of Sperner’s theorem. The other was that the existing methods of tackling density theorems tend to prove not just that you get one configuration of a desired type but a positive proportion of the number of configurations in the whole set. One can usually obtain a seemingly stronger result of this type by an easy averaging argument (a prototype of which was proved by Varnavides in the 1950s), but in the case of the density Hales-Jewett theorem the stronger statement is false: one can easily come up with dense subsets of 
The Varnavides thread.
This led to a search for a suitable Varnavides-like statement, and that search seems to have been successful — though we have not checked this carefully. (See comments 61-64 and 66.)The basic idea is to restrict attention to the set 




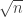

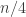
This seems to have cleared up the Varnavides problem, so it is something to hold in reserve and use if we get to the stage where we have a definite approach to try out on the problem. For now, one can either just pretend that the Varnavides problem doesn’t exist and think about
The Sperner thread.
Some definite progress has been made on trying to find alternative proofs of Sperner’s theorem. One approach was initiated in comments 21 and 22. The idea here was to try to find a statement that would have the same relationship to Sperner’s theorem as the hoped-for (but not yet even precisely formulated) triangle-removal lemma had to density Hales-Jewett. An argument was given in comments 21 and 22 that the statement, if it existed, should have the following form.
Let
and
be collections of subsets of
such that there are very few pairs
with
,
and
. Then it is possible to remove a small number of sets from
We have been calling statements like this pair-removal lemmas, even though we have not yet proved any useful ones. A statement like this implies a weak form of Sperner’s theorem as follows. Suppose you have a dense set system 






After some difficulty in formulating a precise pair-removal lemma that wasn’t either trivial or false, we have arrived at the following test problem. (It’s not actually the pair-removal lemma we’re going to want, but it is cleaner, looks both true and non-trivial, and seems to involve all the right difficulties.)
Tentative conjecture. Let
, where
tends slowly to infinity with
such that the number of pairs
. Then one can remove
sets from each of
Some promising suggestions have been made for how to go about proving this conjecture. Jozsef (in comment 124) has drawn attention to a theorem of Bollobás that implies that if each
A very quick word about what to expect of such a generalization. It would be “completing the square”, where vertex 00 is the trivial pair-removal lemma, vertex 01 is the pair-removal lemma in Kneser graphs, vertex 10 is the normal triangle-removal lemma (as described in the background-information post), and we are looking for vertex 11. Since getting from 00 to 10 is by no means a triviality, getting from 10 to 11 is unlikely to be a triviality either. But now we are in a stronger position than we were initially, because to get to 11 there are two potential routes. If we are really lucky, then we’ve got all the ingredients we need and just have to decide how to mix them together.
Other approaches to Sperner.
The above approach to re-proving Sperner has a certain naturalness to it, at least in the context of the main problem, but it is not the only one to have been discussed. If generalizing it runs into difficulties, then we have other ideas to explore that have definitely not yet been explored as far as they could have. They begin with Ryan’s comment 57 (in which he was responding to a related comment of Boris). This introduces the idea of what Boris calls “pushing shadows around”, which is apparently what Sperner himself did.
Other ideas that are still to be explored.
If we are going to follow the triangle-removal proof of the corners theorem quite closely, then at some point we will need to find an analogue of Szemerédi’s regularity lemma for subgraphs of the graph where you join two sets if they are disjoint. There are some obvious problems with doing this (discussed in the initial post in comment V, and comments EE to LL), and a very speculative suggestion for how a proof might look in comment 110. There would also be a need for a counting lemma: an offer to search for such a lemma in a systematic way has not yet been taken up.
[Remark added 7/2/09. It’s important to understand that this post is how the situation seemed to be when it was written yesterday. If you read the comments you will see that some of the assertions that looked plausible (such as the precise form of the tentative conjecture) have now been discovered to be wrong.]

February 6, 2009 at 11:16 am |
300. One of the main reasons for this comment is to establish the numbering. Comments on Terry’s post will be numbered 200-299 (with a convention that from now on if a post receives 100 comments then it must be summarized and restarted), comments on this post will be 300-399, and comments on the obstructions-to-uniformity post, when it is written, will be 400-499.
To get the ball rolling for this post, I’d like to write out Jozsef’s proof of pair removal in full detail, mainly for my own benefit so that I understand it properly, but also because if, as I hope, a major subproject for this thread will be to see if we can generalize Jozsef’s argument, it will be convenient to have that argument here for easy referral.
The first thing to note is that the result Jozsef proves is not quite as strong as the pair-removal lemma we originally asked for, because what he shows is not that you can remove a small number of sets and end up with no disjoint pairs, but rather that you can remove a small number of sets and end up with removing almost all the disjoint pairs you started with. This kind of weakening of a removal lemma is good enough for many applications. For instance, if we applied it to the corners problem we would find that we could remove a small number of edges and get rid of almost all the degenerate triangles, which is just as much of a contradiction as the usual one. (In fact, even if we could show that we could get rid of one percent of the degenerate triangles we would have a contradiction.)
I’ll get on to the actual proof in the next comment.
February 6, 2009 at 11:29 am |
301. Pair removal in Kneser graphs.
The Kneser graph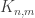 is the graph whose vertices are all subsets of
is the graph whose vertices are all subsets of ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) of size
of size  , with two sets
, with two sets  and
and  joined if and only if they are disjoint. We should think of
joined if and only if they are disjoint. We should think of  as being
as being  for some fairly small but nonconstant
for some fairly small but nonconstant  but for now I will avoid trying to specify them.
but for now I will avoid trying to specify them.
Let and
and  be collections of sets of size
be collections of sets of size  (i.e., subsets of the vertex set of
(i.e., subsets of the vertex set of 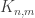 . We can form a bipartite graph by joining
. We can form a bipartite graph by joining  to
to 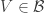 if and only if
if and only if 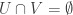 : this is not quite a bipartite subgraph of
: this is not quite a bipartite subgraph of 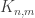 (since
(since  and
and  are not required to be disjoint), but it is an induced subgraph of what one might call the bipartite version of
are not required to be disjoint), but it is an induced subgraph of what one might call the bipartite version of 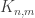 (where each vertex set contains all
(where each vertex set contains all  -element sets and you join two such sets if they are disjoint). From now on I will blur the distinction between this bipartite graph and
-element sets and you join two such sets if they are disjoint). From now on I will blur the distinction between this bipartite graph and 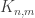 itself.
itself.
The maximum number of edges that could possibly join to
to  is the number of edges in
is the number of edges in 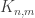 (bipartite version), which is
(bipartite version), which is  . So we shall assume that the total number of edges is at most
. So we shall assume that the total number of edges is at most  for some very small constant
for some very small constant  . Our aim is to remove at most
. Our aim is to remove at most  vertices and get rid of at least half these edges (or any other fixed fraction you might care to go for), where
vertices and get rid of at least half these edges (or any other fixed fraction you might care to go for), where  tends to zero as
tends to zero as  tends to zero.
tends to zero.
I’ll discuss how Jozsef does this in the next comment.
February 6, 2009 at 11:45 am |
302. Pair removal in Kneser graphs.
What Jozsef ends up showing is that there is a very simple way of deciding which vertices to remove: you just get rid of all vertices of large degree. It turns out that if you do this then you either get rid of a significant fraction of all the edges, or you had almost no vertices to start with (in which case you can just remove all of them).
Now all the time we are hoping to remove a number of edges that is large as a fraction of the total number of edges, so “large degree” means “significantly larger than the average degree”. Let us suppose, then, that the average degree in our graph is . (Here I am averaging over all vertices in
. (Here I am averaging over all vertices in 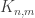 , including those that are not in
, including those that are not in  or
or  .) It follows from Markov’s inequality that for any
.) It follows from Markov’s inequality that for any  the number of vertices of degree at least
the number of vertices of degree at least  is at most
is at most  . So we will need to choose
. So we will need to choose  so that
so that  tends to zero as
tends to zero as  tends to zero.
tends to zero.
Suppose that removing these vertices doesn’t get rid of half the edges. That means that after the removal we have a bipartite induced subgraph of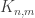 such that the average degree is at least
such that the average degree is at least 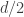 and the maximal degree is at most
and the maximal degree is at most  . In the next comment I’ll explain what Jozsef does in this case.
. In the next comment I’ll explain what Jozsef does in this case.
February 6, 2009 at 12:26 pm |
303. Pair removal in Kneser graphs.
What he does is to use what he calls “the permutation trick of Lubell” to get an upper bound on the number of vertices that there can be in a graph with average degree at least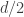 and maximal degree at most
and maximal degree at most  . Take a random permutation
. Take a random permutation  of
of ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Given two disjoint sets
. Given two disjoint sets  and
and  , we shall say that
, we shall say that  separates
separates  and
and  if every element of
if every element of  is less than every element of
is less than every element of  or vice versa. What is the expected number of separated pairs with
or vice versa. What is the expected number of separated pairs with  or
or 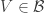 ?
?
Let’s suppose that the total number of vertices in the bipartite graph is . Then the total number of disjoint pairs is at least
. Then the total number of disjoint pairs is at least  . Each disjoint pair
. Each disjoint pair  has a probability of
has a probability of  of being separated (since there are
of being separated (since there are  ways of ordering
ways of ordering 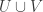 of which precisely two separate them), so the expected number of separated pairs is at least
of which precisely two separate them), so the expected number of separated pairs is at least  .
.
In particular, there exists a permutation that gives rise to at least
that gives rise to at least  separated pairs. But how many separated pairs can there be for a single permutation? Well, let’s suppose first that that permutation is the identity (without loss of generality) and that we have separated pairs
separated pairs. But how many separated pairs can there be for a single permutation? Well, let’s suppose first that that permutation is the identity (without loss of generality) and that we have separated pairs  , ordered in such a way that every element of
, ordered in such a way that every element of  is less than every element of
is less than every element of  . The crucial observation here is that if
. The crucial observation here is that if 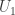 is a set with the smallest maximal element out of any of the
is a set with the smallest maximal element out of any of the  (again without loss of generality), then
(again without loss of generality), then  is a separated pair for all
is a separated pair for all  . Therefore, there can be at most
. Therefore, there can be at most  distinct sets
distinct sets  (since we know that
(since we know that 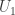 has degree at most
has degree at most  ). Similarly, there can be at most
). Similarly, there can be at most  distinct
distinct  , so the total number of separated pairs is at most
, so the total number of separated pairs is at most  .
.
It follows that , and hence that
, and hence that  . And having got to this point, I realize that I don’t understand why the right-hand side is small. Does anyone see it, or do we wait till Jozsef wakes up? (I also have trouble understanding the significance of the final inequality in his comment 155).
. And having got to this point, I realize that I don’t understand why the right-hand side is small. Does anyone see it, or do we wait till Jozsef wakes up? (I also have trouble understanding the significance of the final inequality in his comment 155).
February 6, 2009 at 12:36 pm |
304. Pair removal in Kneser graphs.
Maybe the point is that the right-hand side doesn’t have to be small if all we know about is that it’s a small multiple of
is that it’s a small multiple of  , but if we assume that
, but if we assume that  is much smaller (it’s possible that for applications to Sperner we may even be able to take
is much smaller (it’s possible that for applications to Sperner we may even be able to take 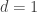 ) and
) and  is reasonably large, then the right-hand side is much smaller than
is reasonably large, then the right-hand side is much smaller than 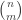 . So this would fit in with my comment 153 , where I suggested that using a stronger hypothesis might be helpful to prove a pair-removal lemma.
. So this would fit in with my comment 153 , where I suggested that using a stronger hypothesis might be helpful to prove a pair-removal lemma.
February 6, 2009 at 12:56 pm |
305. Triangle removal.
Here is a possible toy problem to think about, as an initial contribution to the project of generalizing Jozsef’s proof. This time we let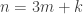 . Our basic objects will be pairs
. Our basic objects will be pairs  of disjoint sets. We are given three collections
of disjoint sets. We are given three collections  ,
,  and
and  of such pairs. A triangle is a triple of the form
of such pairs. A triangle is a triple of the form  with
with  ,
,  and
and  . We would like to prove that if for each pair
. We would like to prove that if for each pair  there is at most one
there is at most one  such that
such that  and
and  and similarly for the other two ways round, then it is possible to remove a small number of elements from
and similarly for the other two ways round, then it is possible to remove a small number of elements from  ,
,  and
and  and end up removing a significant fraction of all the triangles.
and end up removing a significant fraction of all the triangles.
There are no degenerate triangles here, so this wouldn’t do DHJ straight off, but I think it would be a good way of trying to understand whether Jozsef’s methods generalize. An alternative line of investigation would be to generalize Jozsef’s methods to a statement about several central layers of the cube rather than just one.
February 6, 2009 at 1:16 pm |
306. Triangle removal.
An optimistic guess about how it might go: we just routinely try to generalize Jozsef’s argument, and at a certain point a difficulty arises, which we turn out to be able to solve using the usual triangle-removal lemma.
February 6, 2009 at 1:38 pm |
307. Triangle removal.
At the very least, let’s try to do the routine generalization and see what happens. So without any serious thought about what is sensible and what is not, let us say that a permutation separates the three sets
separates the three sets 
 and
and  if every element of
if every element of  comes before every element of
comes before every element of  , which in turn comes before every element of
, which in turn comes before every element of  , or any one of the other five such statements you get by permuting the three sets. We’ll also say that
, or any one of the other five such statements you get by permuting the three sets. We’ll also say that  separates a triangle if it separates the three sets used to build it.
separates a triangle if it separates the three sets used to build it.
Given any two disjoint sets and
and  , let us define the
, let us define the  –degree of
–degree of  to be the number of
to be the number of  such that
such that  ,
,  and
and  . (In this case, we say that
. (In this case, we say that  form a triangle.) We have similar definitions for the other two possible degrees.
form a triangle.) We have similar definitions for the other two possible degrees.
Now let’s suppose that the average degree (over all three bipartite graphs) is and the maximal degree is
and the maximal degree is  . What can we say?
. What can we say?
Let’s think about the expected number of separated triangles. The total number of triangles is (up to some absolute constant depending on whether one orders the vertices etc.), and the probability that
(up to some absolute constant depending on whether one orders the vertices etc.), and the probability that  separates any given triangle is
separates any given triangle is  . So the expected number is
. So the expected number is  Therefore, there must be some permuation
Therefore, there must be some permuation  that separates at least this number of triangles.
that separates at least this number of triangles.
Now let’s think about how many triangles a permutation can separate. Our assumption is that no pair of sets forms a triangle with more than other sets. It’s at this point that, if our wildest dreams come true, we find that normal dense triangle removal is exactly what we need. But no reason to suppose that just yet. I’m going to continue in a new comment.
other sets. It’s at this point that, if our wildest dreams come true, we find that normal dense triangle removal is exactly what we need. But no reason to suppose that just yet. I’m going to continue in a new comment.
February 6, 2009 at 1:59 pm |
308. Triangle removal.
Let’s suppose that are separated triangles. We would like an upper bound on
are separated triangles. We would like an upper bound on  . If we choose
. If we choose  such that the maximal element of
such that the maximal element of  is minimized, we see that the number of distinct sets
is minimized, we see that the number of distinct sets  can be at most
can be at most  . Similarly, the number of distinct
. Similarly, the number of distinct  can be at most
can be at most  . But each pair
. But each pair  is allowed at most
is allowed at most  sets
sets  in the middle, so we seem to have at most
in the middle, so we seem to have at most  triangles separated by
triangles separated by  . This is slightly worrying as it came out a bit too simply for my liking.
. This is slightly worrying as it came out a bit too simply for my liking.
If it’s correct, it shows that , and therefore that
, and therefore that  , which is exponential in
, which is exponential in  . So for very small
. So for very small  , such as we might expect to have in DHJ, we get a contradiction.
, such as we might expect to have in DHJ, we get a contradiction.
I’ve got to go now, so all I’ll say at this point is that this argument feels too simple to be correct, but I can’t see what’s wrong with it. (If it’s right, then the explanation must simply be that it is not what we need.)
February 6, 2009 at 3:14 pm |
309. Pair removal in Kneser graphs.
Can someone help me with this dumb question?
Suppose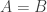 are the family of sets not including the last element
are the family of sets not including the last element  . Then
. Then  and
and  have density about
have density about  within
within  . (We’re thinking
. (We’re thinking  ,
,  here, right?) It seems that the fraction of Kneser graph edges which are in
here, right?) It seems that the fraction of Kneser graph edges which are in  is about
is about  , which is “negligible”. So we should be able to delete any small constant fraction of vertices from
, which is “negligible”. So we should be able to delete any small constant fraction of vertices from 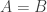 and make it an intersecting family. But
and make it an intersecting family. But  is
is  of the Kneser graph
of the Kneser graph  , and doesn’t the largest intersecting family inside such a Kneser graph have density only around
, and doesn’t the largest intersecting family inside such a Kneser graph have density only around  ?
?
February 6, 2009 at 4:49 pm |
310. Pair removal in Kneser graphs.
Ryan, all I can say is that I can’t see a flaw in your reasoning. If it’s correct, then it shows something rather interesting. I couldn’t get Jozsef’s argument to work unless I assumed that degrees were very small rather than just small, and your example suggests that it’s actually false when you merely assume that the degrees are a negligible fraction of the maximum possible. In your example, the degree of a vertex in is still large, even if it’s proportionately small, so there’s still some hope that Jozsef’s argument is correct and adaptable to DHJ.
is still large, even if it’s proportionately small, so there’s still some hope that Jozsef’s argument is correct and adaptable to DHJ.
Now I must stare at the argument that I produced in 308 and try to work out what’s going on.
February 6, 2009 at 5:10 pm |
311. I guess you can make the degree go down fairly rapidly compared to the density by requiring the last coordinates to be
coordinates to be  . (Density goes down like
. (Density goes down like  fraction of edges goes down like
fraction of edges goes down like  .)
.)
February 6, 2009 at 5:11 pm |
312. Counting lemma
This is idle wondering, but given a random (not quasi-random) tripartite graph, do we know the probability P of n triangles appearing given a density D? This seems like this sort of thing that ought to be just a textbook example.
February 6, 2009 at 5:13 pm |
313. Triangle removal.
I’m going to try to do two things at once. The first is express myself more clearly when it comes to arguments such as the one in 308, and the second is to try to develop an argument that involves more than one slice, in the hope that degenerate triangles will come into play somehow.
Let me begin by trying to define the nicest possible triangular grid of slices . I’ll define to be the union of all
to be the union of all  such that
such that 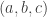 is a triple of integers that belongs to the convex hull of
is a triple of integers that belongs to the convex hull of  , … actually, cancel this. It seems to be more natural, if one is going for the nicest possible and most symmetrical set of slices, to go for a hexagon. So let’s take all
, … actually, cancel this. It seems to be more natural, if one is going for the nicest possible and most symmetrical set of slices, to go for a hexagon. So let’s take all 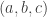 that sum to
that sum to  and that satisfy
and that satisfy  . Here I’m imagining that
. Here I’m imagining that  is a multiple of 3, not that it’s all that important. (This is a hexagon because there are six linear inequalities, and the symmetry of the situation makes it a regular hexagon.) Let’s write
is a multiple of 3, not that it’s all that important. (This is a hexagon because there are six linear inequalities, and the symmetry of the situation makes it a regular hexagon.) Let’s write  for the union of all these
for the union of all these  . We would like to prove that any dense subset
. We would like to prove that any dense subset  of
of  contains a combinatorial line.
contains a combinatorial line.
Now I’m going to do roughly the same thing as before. I’ll assume that there are no combinatorial lines in . For each sequence
. For each sequence  in
in  and each
and each 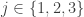 , let’s define the
, let’s define the  –set of
–set of  to be
to be  , and we’ll denote this by
, and we’ll denote this by  . As ever, we define
. As ever, we define  to be the set of all pairs
to be the set of all pairs  with
with  ,
,  to be the set of all
to be the set of all  and
and  to be the set of all
to be the set of all  (again, always with
(again, always with  ).
).
The assumption that there are no combinatorial lines tells us that there are no triples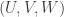 with
with  ,
,  and
and  , except in the degenerate case where
, except in the degenerate case where ![U\cup V\cup W=[n]](https://s0.wp.com/latex.php?latex=U%5Ccup+V%5Ccup+W%3D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . In the next comment I’ll try to hit this with Jozsef’s permutation argument.
. In the next comment I’ll try to hit this with Jozsef’s permutation argument.
February 6, 2009 at 5:15 pm |
(Meta-comment)
Ryan, like the brackets problem you should toss a {} before the 0 there if you want to render it in LaTeX in WordPress.
February 6, 2009 at 5:31 pm |
314. Triangle removal.
So now let’s choose a random permutation and see what we can say about the number of separated triangles. To do this, my first task is to say how many actual triangles there are. And the answer is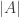 , one degenerate triangle for each element of
, one degenerate triangle for each element of  and no others.
and no others.
Next, I’d like some idea of the probability that a random permutation separates a given triangle. Let’s suppose that the point
separates a given triangle. Let’s suppose that the point  of
of  that gives rise to the triangle belongs to
that gives rise to the triangle belongs to  . Then the probability that
. Then the probability that  separates
separates  is
is  . So the expected number of separated triangles is
. So the expected number of separated triangles is  .
.
Now suppose I just choose an arbitrary permutation — without loss of generality the identity. How many separated triangles can there be? I think this may be where the problems arise, but let’s see. Suppose that are separated triangles. We know that for each
are separated triangles. We know that for each 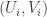 …
…
I may come back to this, but I’ve now seen where I went wrong in 308, so I should think about that first, as it’s a simpler problem.
February 6, 2009 at 5:49 pm |
315. Triangle removal: my mistake in 308.
I started 308 with the claim that if you choose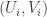 so as to minimize the maximum element of
so as to minimize the maximum element of  , then you could see immediately that there were at most
, then you could see immediately that there were at most  distinct
distinct  . The thinking behind this was that each
. The thinking behind this was that each  would form a triangle.
would form a triangle.
But that was wrong: there is no reason for to belong to
to belong to  or for
or for  to belong to
to belong to  . So it’s back to the drawing board here. (But this, I should stress, is good news as I wanted there to be a complication to give triangle-removal a chance to creep in.)
. So it’s back to the drawing board here. (But this, I should stress, is good news as I wanted there to be a complication to give triangle-removal a chance to creep in.)
Here is a new proof strategy. First I’ll copy the first part of Jozsef’s argument to get to the stage where each vertex is contained in roughly the same number of triangles. (If I can’t, I’ll remove a few vertices and get rid of a significant fraction of the triangles.) Next, I’ll argue as above that the expected number of separated triangles is reasonably large. Then I’ll try to bound the number of separated triangles if no vertex is in too many triangles and no edge is in more than one triangle. The first step of that will be to pick … actually, I still don’t see it.
I was going to say that one should pick the with smallest maximum, but I don’t see what that gives us.
with smallest maximum, but I don’t see what that gives us.
What we can say is this. For each there will be some system of sets
there will be some system of sets  such that
such that  forms a triangle. If in this set system we choose
forms a triangle. If in this set system we choose  such that the maximum of
such that the maximum of  is minimized, then we can deduce that there are not too many distinct
is minimized, then we can deduce that there are not too many distinct  . Except that I don’t know why I even say this so confidently: what makes me think that
. Except that I don’t know why I even say this so confidently: what makes me think that  should lie in
should lie in  ? OK I’m floundering around a bit here so I’d better stop. But I’ll leave these messy thoughts here in case anyone can get a clearer idea of what ought to be done. It feels as though it’s in promising territory somehow.
? OK I’m floundering around a bit here so I’d better stop. But I’ll leave these messy thoughts here in case anyone can get a clearer idea of what ought to be done. It feels as though it’s in promising territory somehow.
February 6, 2009 at 6:14 pm |
316. Triangle removal.
This is the kind of reason I find it promising. The graph where you join two sets if and only if one is completely to the left of the other is, under normal circumstances, much denser than the graph where you just join two sets if they are disjoint. So what Jozsef’s permutation argument is cleverly achieving seems to be to get us from a sparse context to a dense context. (I don’t yet have a fully precise formulation of this remark.)
Now let’s suppose we have our separated triangles above. Suppose also that we have managed to show somehow that many of the pairs
above. Suppose also that we have managed to show somehow that many of the pairs  belong to
belong to  , and so on. We know that there won’t be many triangles, so this will imply, by the usual triangle-removal lemma, that we can remove a small number of edges and end up with no triangles. Could there be an argument along these lines that allows us to prove density Hales-Jewett by hitting it permutation by permutation? We’re in that familiar state where there’s a small probability
, and so on. We know that there won’t be many triangles, so this will imply, by the usual triangle-removal lemma, that we can remove a small number of edges and end up with no triangles. Could there be an argument along these lines that allows us to prove density Hales-Jewett by hitting it permutation by permutation? We’re in that familiar state where there’s a small probability  of being close to a solution and a large probability
of being close to a solution and a large probability 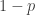 of having written a load of nonsense.
of having written a load of nonsense.
February 6, 2009 at 6:33 pm |
317. Pair removal in Kneser graphs.
Bad news – good news. Good morning! I hope that I didn’t derail the project with my last calculation yesterday – that the “removal lemma” works when . The main inequality is correct, and we see that it tells us something non-trivial if m is small compare to n. As I see now, the average degree, d, grows as
. The main inequality is correct, and we see that it tells us something non-trivial if m is small compare to n. As I see now, the average degree, d, grows as  . I think that this is the range where we have a removal lemma so far. This is a removal lemma we get by simple double-counting, so I’m afraid that we can’t expect too much out of it, but it supports Tim’s conjecture.
. I think that this is the range where we have a removal lemma so far. This is a removal lemma we get by simple double-counting, so I’m afraid that we can’t expect too much out of it, but it supports Tim’s conjecture.
February 6, 2009 at 7:15 pm |
318. Pair/triangle removal.
Hi Jozsef. Two remarks. It seems to me (but I’d be reassured if I knew you agreed about this) that we have a removal lemma if the average degree is very small. And in interesting contexts it is. For example, if is a counterexample to Sperner’s theorem and we let
is a counterexample to Sperner’s theorem and we let  consist of al complements of sets in
consist of al complements of sets in  , then each set in
, then each set in  is joined just to its complement, so the average degree is 1.
is joined just to its complement, so the average degree is 1.
The second remark is that it’s not impossible that a simple double counting gives us something good. The reason is that when going from 2 to 3 in the dense case you go from trivial to interesting, so when going from 2 to 3 here, perhaps you go from simple to very interesting.
February 6, 2009 at 7:25 pm |
319. Sperner.
Hi Jozsef, is that a typo? needs to be less than
needs to be less than  ; otherwise the
; otherwise the  Kneser graph is empty.
Kneser graph is empty.
I’m not sure the scenario we should consider now… we have counterexamples to the Tentative Conjecture for both constant and superconstant.
both constant and superconstant.
February 6, 2009 at 7:28 pm |
320 Pair removal lemma
Now I feel a bit dummy; I wanted to check where did the calculation go wrong yesterday in my last post, but I can’t see. Tim, in 304 you asked why is the right hand side small. By checking what I see – again – is that it should be around
what I see – again – is that it should be around  . I probably badly overlook the same thing again …
. I probably badly overlook the same thing again …
I’ll go to have a morning coffee.
February 6, 2009 at 7:34 pm |
321. Sperner
Ryan, you may be ahead of me here and already see why the suggestion I’ve been making is a bad one, but what about strengthening the hypothesis of the Tentative Conjecture from the number of disjoint pairs being to each set belonging to at most one disjoint pair? (With this second hypothesis one tries to prove that the sets must be small.)
to each set belonging to at most one disjoint pair? (With this second hypothesis one tries to prove that the sets must be small.)
Actually, isn’t that just Bollobás’s theorem? I think it is because if I take in 303 then I get the correct bound of
in 303 then I get the correct bound of  . Is that the standard proof of Bollobás’s theorem?
. Is that the standard proof of Bollobás’s theorem?
February 6, 2009 at 7:35 pm |
322. Pair removal in Kneser graphs.
Ok, I am trying to understand Jozsef’s proof (I notice it uses the greedy algorithm, interesting) and I must be missing something elementary at 303:
The crucial observation here is that if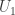 is a set with the smallest maximal element out of any of the
is a set with the smallest maximal element out of any of the  (again without loss of generality), then
(again without loss of generality), then  is a separated pair for all
is a separated pair for all  .
.
Could someone expand on this a little more? I’m not seeing why.
February 6, 2009 at 7:37 pm |
323. Pair removal in Kneser graphs.
Jason, if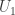 has the smallest maximal element and
has the smallest maximal element and 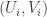 is separated, then the largest element of
is separated, then the largest element of 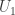 is at most the largest element of
is at most the largest element of  is less than the smallest element of
is less than the smallest element of  . If this doesn’t explain it then I don’t understand what you’re not understanding.
. If this doesn’t explain it then I don’t understand what you’re not understanding.
February 6, 2009 at 8:08 pm |
324. Triangle removal
A quick technical question: I think it should be reasonably straightforward to answer. Suppose we have a dense set in
in ![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . Suppose now that we take a random permutation
. Suppose now that we take a random permutation  and just take from
and just take from  the sequences that start with 1s, continue with 2s and finish with 3s (after you’ve used
the sequences that start with 1s, continue with 2s and finish with 3s (after you’ve used  to scramble the coordinates). And now suppose you form the tripartite graph from just those sequences. That is, you let
to scramble the coordinates). And now suppose you form the tripartite graph from just those sequences. That is, you let  consist of all pairs
consist of all pairs  that are equal to
that are equal to  for some
for some  , and so on. We can think of
, and so on. We can think of  as a bipartite graph, whose vertices are subsets of
as a bipartite graph, whose vertices are subsets of ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where we join
, where we join  to
to  if
if  finishes before
finishes before  starts. What I’d like to know is whether this graph tends to be dense. I think the straightforward answer is no, so what I really mean is whether it can be made dense if you remove a smallish number of vertices and edges, or something like that. The motivation for this question is that I’d very much like to be able to define a dense tripartite graph with few triangles and see what happens when we apply the usual triangle-removal lemma.
starts. What I’d like to know is whether this graph tends to be dense. I think the straightforward answer is no, so what I really mean is whether it can be made dense if you remove a smallish number of vertices and edges, or something like that. The motivation for this question is that I’d very much like to be able to define a dense tripartite graph with few triangles and see what happens when we apply the usual triangle-removal lemma.
February 6, 2009 at 8:30 pm |
325. Pair removals
Re: 319, yes there was a typo, I meant n/2 there, thanks. But I still don’t see if anything is bad with my calculation; Please help me, is it correct that if then d should be at least
then d should be at least  or we have a removal lemma? After this I will try to digest Tim’s triangle removal technique.
or we have a removal lemma? After this I will try to digest Tim’s triangle removal technique.
February 6, 2009 at 9:29 pm |
326. Kneser.
Hi Tim, in #321, if each set is involved in at most one Kneser edge, then I think the least number of sets you need to delete in order to eliminate all Kneser edges is with a factor of two of the number of sets (vertices), no?
February 6, 2009 at 9:37 pm |
327. Kneser
Yes, so if you can prove that you can remove a small number of sets then you’ve proved that there weren’t very many sets in the first place.
February 6, 2009 at 9:43 pm |
328. Pair removal
Jozsef in 325, my calculation (which I checked and I’m pretty sure it works out to be the same as yours) suggests that you get something interesting as long as is large and
is large and  is a lot smaller than
is a lot smaller than  . Since
. Since  is about
is about  , it follows that we need
, it follows that we need  to be small compared with
to be small compared with  in order to get a removal lemma. I think this agrees with you, since you are taking
in order to get a removal lemma. I think this agrees with you, since you are taking  and
and  . So it seems correct to you and it seems correct to me, which means that there’s an
. So it seems correct to you and it seems correct to me, which means that there’s an  chance that it’s incorrect.
chance that it’s incorrect.
February 6, 2009 at 9:53 pm |
329. Thank you Tim. I think I should apologize that, after reading 303, I didn’t pay much attention to later posts from where I could have learned that things were OK with the calculation. In the next post I will try to understand and extend your toy version of a triangle removal lemma. Unfortunately now I have to go to the university and probably I won’t read the posts in the next 5-6 hours.
February 6, 2009 at 11:11 pm |
330. Triangle removal
Jozsef, I should make it clear that I don’t yet have an interesting new triangle removal lemma proved, so if you prove anything at all it counts as an extension of what I’ve done. But I might think just a little bit further about the vague idea of 324.
Suppose then that we have a dense set of sequences in![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , and for simplicity let’s assume that they’re all reasonably well balanced (meaning that they all have roughly equal numbers of 1s, 2s and 3s). How many times do we expect a given set
, and for simplicity let’s assume that they’re all reasonably well balanced (meaning that they all have roughly equal numbers of 1s, 2s and 3s). How many times do we expect a given set  to occur as
to occur as  for some
for some  ? The very rough answer is
? The very rough answer is  . Let’s be even more rough and call that
. Let’s be even more rough and call that  . Now
. Now  has size around
has size around  .
.
I’m going to interrupt this comment because I’ve had a different idea that I want to pursue urgently.
February 6, 2009 at 11:52 pm |
331. Sperner and DHJ
The proof I know of Sperner goes like this. You take a random sequence of sets of the form![\emptyset=A_0\subset A_1\subset A_2\subset\dots\subset A_n=[n]](https://s0.wp.com/latex.php?latex=%5Cemptyset%3DA_0%5Csubset+A_1%5Csubset+A_2%5Csubset%5Cdots%5Csubset+A_n%3D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  has cardinality
has cardinality  . If
. If  is an antichain, then it intersects each such chain in at most one set.
is an antichain, then it intersects each such chain in at most one set.
Now let’s imagine we choose a set at random. What is the probability that it lies in ? Let’s write
? Let’s write 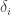 for the density of
for the density of  inside layer
inside layer  (that is, the number of sets in
(that is, the number of sets in  of size
of size  divided by
divided by  ). Then the expected size of the intersection of
). Then the expected size of the intersection of  with our random chain is
with our random chain is  . It follows that the
. It follows that the 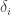 add up to at most 1 (since at least one random chain will have at least the expected number of elements of
add up to at most 1 (since at least one random chain will have at least the expected number of elements of  in it). Since the middle layer(s) is (are) biggest, it’s clear that we maximize the size of
in it). Since the middle layer(s) is (are) biggest, it’s clear that we maximize the size of  by choosing a middle layer.
by choosing a middle layer.
The idea that’s just occurred to me is that we’ve just deduced Sperner from the one-dimensional corners result (which states that if you have a dense subset of![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) then you must be able to find
then you must be able to find  and
and  in it with
in it with  ). What happens if we try to deduce density Hales-Jewett from 2-dimensional corners?
). What happens if we try to deduce density Hales-Jewett from 2-dimensional corners?
Well, first we need to decide what replaces a random chain. For reasons of symmetry I’d like to think of a random chain as follows: you pick a random permutation of![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and then once you’ve scrambled the set you take all partitions
and then once you’ve scrambled the set you take all partitions  of
of ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into two sets such that every element of
into two sets such that every element of  is less than every element of
is less than every element of  .
.
At this point I’m just going to guess that it might be reasonable to choose for DHJ purposes a random permutation of![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) followed by all partitions
followed by all partitions 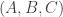 such that every element of
such that every element of  comes before every element of
comes before every element of  , which comes before every element of
, which comes before every element of  . This is at least a two-dimensional structure, since it’s determined by the end points of
. This is at least a two-dimensional structure, since it’s determined by the end points of  and
and  . I will also think of this as the set
. I will also think of this as the set  of all sequences in
of all sequences in ![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) that start with some 1s, continue with some 2s, and end with some 3s.
that start with some 1s, continue with some 2s, and end with some 3s.
Next question: if contains no combinatorial line, can we deduce that the intersection of
contains no combinatorial line, can we deduce that the intersection of  with
with  is small? What I’d like to do is prove that it has no corners, in some useful sense of the word “corners”.
is small? What I’d like to do is prove that it has no corners, in some useful sense of the word “corners”.
How would we get a combinatorial line in this set? We can of course encode each element of as a triple
as a triple 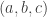 where
where  . And at this point we have a problem:
. And at this point we have a problem:  contains no combinatorial lines.
contains no combinatorial lines.
Well, I suppose if that had worked it would have been discovered by now. But it suggests an amusing problem. Let be the hexagonal portion of the triangular grid
be the hexagonal portion of the triangular grid 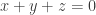 (a 2-dimensional subset of
(a 2-dimensional subset of  ) defined by
) defined by  . Let us call a function
. Let us call a function ![f:T_m\rightarrow [3]^n](https://s0.wp.com/latex.php?latex=f%3AT_m%5Crightarrow+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) a corner isomorphism if it is an injection such that every aligned equilateral triangle in
a corner isomorphism if it is an injection such that every aligned equilateral triangle in  maps to a combinatorial line. (An aligned equilateral triangle is a set of the form
maps to a combinatorial line. (An aligned equilateral triangle is a set of the form  .) If we could find a corner isomorphism for some fairly large
.) If we could find a corner isomorphism for some fairly large  , then we could probably move the image about and prove density Hales-Jewett using an averaging argument. So can anyone either find a big corner isomorphism or (more likely) prove that no such function exists? I don’t expect this problem to be very hard.
, then we could probably move the image about and prove density Hales-Jewett using an averaging argument. So can anyone either find a big corner isomorphism or (more likely) prove that no such function exists? I don’t expect this problem to be very hard.
February 7, 2009 at 1:48 am |
332. Sperner and DHJ
My last contribution for the day: I’ve just checked and there isn’t even a corner isomorphism from into
into ![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . The proof goes like this: you take an arithmetic progression of three points in a line and map them to
. The proof goes like this: you take an arithmetic progression of three points in a line and map them to  ,
,  and
and  . (I think I may also have wanted to insist that lines go to sets where the appropriate
. (I think I may also have wanted to insist that lines go to sets where the appropriate  -set is fixed.) Those three points determine a
-set is fixed.) Those three points determine a  and their images determine what the images of the other three points under a corner isomorphism would have to be, but those three images don’t lie in a combinatorial line. (For what it’s worth, they are
and their images determine what the images of the other three points under a corner isomorphism would have to be, but those three images don’t lie in a combinatorial line. (For what it’s worth, they are  ,
,  and
and  .)
.)
February 7, 2009 at 6:49 am |
333. Triangle removal
To understand the notations and arguments below, one should read 305-307-308 first. Tim’s proof in 307-308 works nicely, if we change the initial conditions. Our base set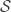 is now just a collection of m-element subsets (where n=3m+k) instead of
is now just a collection of m-element subsets (where n=3m+k) instead of 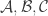 and we are considering now every triangle formed by any three pairwise disjoint elements of
and we are considering now every triangle formed by any three pairwise disjoint elements of 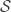 . For this set of triangles, we do have the removal lemma as Tim has calculated it. Let me add two technical remarks which might be needed for the complete proof. A triangle is called “normal” if none of its edges is edge of more than Cd other triangles. Then, the argument gives bound on the number of normal triangles. If most of the triangles aren’t normal, then we have a removal lemma. The conclusion is that if we have a small number of triangles in
. For this set of triangles, we do have the removal lemma as Tim has calculated it. Let me add two technical remarks which might be needed for the complete proof. A triangle is called “normal” if none of its edges is edge of more than Cd other triangles. Then, the argument gives bound on the number of normal triangles. If most of the triangles aren’t normal, then we have a removal lemma. The conclusion is that if we have a small number of triangles in 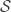 compare to the size of
compare to the size of 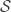 , then a small fraction of the edges covers most of the triangles. My second small remark is that when we bound the normal triangles separated by a permutation, then we consider the sets right from the leftmost (having the smallest last point) middle element and and the sets left from the rightmost (having the largest first point) element. These are both bounded by Cd and they span at most
, then a small fraction of the edges covers most of the triangles. My second small remark is that when we bound the normal triangles separated by a permutation, then we consider the sets right from the leftmost (having the smallest last point) middle element and and the sets left from the rightmost (having the largest first point) element. These are both bounded by Cd and they span at most  separated triples, as Tim said. I’m just emphasizing the selection of the left size here, only a technical detail.
separated triples, as Tim said. I’m just emphasizing the selection of the left size here, only a technical detail.
This theorem is more restricted than Tim’s original statement, but I think it might be useful. In DHJ the dense subset is given and we will work with the induced substructure.
February 7, 2009 at 7:01 am |
334. Sperner
I was wondering what would be the proper Sperner-type theorem in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) similarly useful as Sperner in
similarly useful as Sperner in ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . Is there something before DHJ?
. Is there something before DHJ?
February 7, 2009 at 10:22 am |
335. Sperner
Jozsef, I think I have the answer to your last question. Let’s define the Kneser product of two set systems and
and  to be the set of all pairs
to be the set of all pairs  such that
such that  ,
, 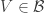 and
and 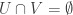 . Then the theorem would be that every Kneser product that is dense in the set of all disjoint pairs (of which there are
. Then the theorem would be that every Kneser product that is dense in the set of all disjoint pairs (of which there are  ) contains a corner: that is, a configuration of the form
) contains a corner: that is, a configuration of the form  ,
, 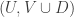 ,
, 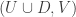 with all three of
with all three of  ,
,  and
and  disjoint.
disjoint.
I’ve stated it like that to make it as similar as I can to Sperner. But a more symmetrical version is this. Suppose that ,
, 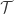 and
and  are set systems such that there are at least
are set systems such that there are at least  ways of partitioning
ways of partitioning ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) as
as  with
with  etc. Then the corresponding collection of sequences contains a combinatorial line.
etc. Then the corresponding collection of sequences contains a combinatorial line.
To see that this is a natural extension of Sperner, consider the following silly way of stating (weak) Sperner. If and
and  are two set systems such that there are at least
are two set systems such that there are at least  ways of partitioning
ways of partitioning ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) as
as 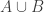 with
with  and
and  then the corresponding collection of 01-sequences contains a combinatorial line.
then the corresponding collection of 01-sequences contains a combinatorial line.
It looks to me as though there should be a two-dimensional family of density Hales-Jewett statements. That is, for each there should be a DHJ(j,k), where Sperner is DHJ(1,2), density Hales-Jewett in
there should be a DHJ(j,k), where Sperner is DHJ(1,2), density Hales-Jewett in ![\null [k]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) is DHJ(k-1,k), and the theorem just discussed (for which it looks as though we may have a proof) is DHJ(1,3). The idea would be that for DHJ(j,k), whether or not a sequence belongs to the set depends on a j-uniform hypergraph with
is DHJ(k-1,k), and the theorem just discussed (for which it looks as though we may have a proof) is DHJ(1,3). The idea would be that for DHJ(j,k), whether or not a sequence belongs to the set depends on a j-uniform hypergraph with ![2^{[n]}](https://s0.wp.com/latex.php?latex=2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) as its vertex set.
as its vertex set.
We should see if there is any relation between this and Terry’s DHJ(2.5) problem . I suspect there isn’t, in which case it’s amusing to have come up with a different way of “interpolating” between Sperner and DHJ.
February 7, 2009 at 2:32 pm |
336. Sperner and DHJ.
A small observation. One could regard the previous comment as showing that at least one natural generalization of Sperner to![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) turns out not to be the statement we want. That is unfortunate, though by no means catastrophic. In this comment I want to point out that there is a different way of generalizing Sperner that leads (I think) to a deeper theorem, though it still isn’t DHJ.
turns out not to be the statement we want. That is unfortunate, though by no means catastrophic. In this comment I want to point out that there is a different way of generalizing Sperner that leads (I think) to a deeper theorem, though it still isn’t DHJ.
Let’s go back to comment 331 and try to generalize the proof of Sperner and see what comes out, not worrying if it isn’t DHJ. To do this, we associate with any triple the three sets
the three sets  ,
,  and
and  . Let’s call this the triple
. Let’s call this the triple  . Now let’s suppose we have a corner, by which in this context I mean a triple of triples of the form
. Now let’s suppose we have a corner, by which in this context I mean a triple of triples of the form  ,
,  and
and  (with
(with  ). What combinatorial configuration do we get from the corresponding triples
). What combinatorial configuration do we get from the corresponding triples  ,
,  and
and  ? The answer is that we partition
? The answer is that we partition ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into sets
into sets  ,
,  ,
,  ,
,  and
and  . Then the sequence corresponding to
. Then the sequence corresponding to  is 1 on
is 1 on 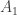 and
and 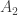 , 2 on
, 2 on 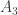 and
and 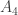 , and 3 on
, and 3 on 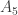 . The sequence corresponding to
. The sequence corresponding to  is 1 on
is 1 on 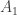 , 2 on
, 2 on 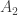 ,
, 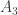 and
and 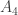 , and 3 on
, and 3 on 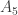 . Finally, the sequence corresponding to
. Finally, the sequence corresponding to  is 1 on
is 1 on 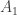 , 2 on
, 2 on 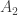 and
and 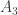 , and 3 on
, and 3 on 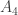 and
and 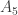 .
.
Thus, we have three fixed sets, namely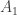 ,
, 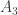 and
and 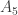 , and two variable sets, namely
, and two variable sets, namely 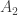 and
and 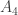 . If we identify each set to a point, we can think of the three sequences as
. If we identify each set to a point, we can think of the three sequences as 
 and
and  . If we forget about the fixed sets, the restrictions to the variable sets are going
. If we forget about the fixed sets, the restrictions to the variable sets are going  . Also, and this is important, the two variable sets have the same size. (If they didn’t, then the resulting theorem would be much easier.)
. Also, and this is important, the two variable sets have the same size. (If they didn’t, then the resulting theorem would be much easier.)
Given a dense set of triples that start with 1s, continue with 2s and end with 3s, then the corners theorem will tell you that you must have a configuration of the above kind. I haven’t checked this, but I’m about 99% certain that if you imitate the proof of Sperner by averaging over a random permutation, then you will be able to deduce that a dense subset of![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) will contain a “peculiar combinatorial line” of the above form. (Just to be clear, a peculiar combinatorial line is a triple of sequences that are fixed outside two sets
will contain a “peculiar combinatorial line” of the above form. (Just to be clear, a peculiar combinatorial line is a triple of sequences that are fixed outside two sets  and
and  that have the same size, and inside
that have the same size, and inside  and
and  they go
they go  .)
.)
The reason I call this a deeper theorem is that it relies on the corners theorem. Indeed, it implies the corners theorem if you restrict to sets that are unions of slices. (This is because we insist that and
and  have the same size.)
have the same size.)
Again, this is a slightly depressing observation because it shows that a reasonably natural generalization of the Sperner proof gives us the wrong theorem. However, again it doesn’t actually tell us that we can’t find a different way of generalizing Sperner that gives the right theorem.
February 7, 2009 at 4:05 pm |
337. Sperner and DHJ
A tiny observation, following on from 332. The main difficulty seems to be as follows. Let’s define the order profile of a sequence to be what you get when you collapse each block of equal coordinates to just one coordinate. For example, the order profile of is
is  . In
. In ![\null [2]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) you can have a combinatorial line where every element has the same order profile: e.g.
you can have a combinatorial line where every element has the same order profile: e.g.  and
and 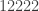 . But in
. But in ![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) that is impossible. (Proof: if the last fixed coordinate before a variable string starts is
that is impossible. (Proof: if the last fixed coordinate before a variable string starts is  and the first fixed coordinate after it finishes is
and the first fixed coordinate after it finishes is  , then the variable string can only take the values
, then the variable string can only take the values  and
and  .)
.)
I’ve vaguely wondered about having a two-dimensional ground set, so that it’s possible for three sets to meet at a point, but I haven’t managed to define a nice two-parameter family of sequences.
February 7, 2009 at 4:13 pm |
338. Sperner and DHJ
Actually, I can’t resist just slightly expanding on the last paragraph of 337. Let’s take not![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) but
but ![{}[3]^{n^2}](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E%7Bn%5E2%7D&bg=ffffff&fg=333333&s=0&c=20201002) , which we think of as the space of all functions from
, which we think of as the space of all functions from ![\null [n]^2](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) to
to 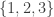 . I’d like to regard such a function as “simple” if you’ve basically got three big simply connected patches, of 1s, 2s and 3s, and if the boundaries between these patches are not too wiggly. A combinatorial line of functions like this would have the desirable property that it wouldn’t be obvious from just one of the functions what the variable set was: in some sense the “two-dimensional order profile” would be the same for all three points.
. I’d like to regard such a function as “simple” if you’ve basically got three big simply connected patches, of 1s, 2s and 3s, and if the boundaries between these patches are not too wiggly. A combinatorial line of functions like this would have the desirable property that it wouldn’t be obvious from just one of the functions what the variable set was: in some sense the “two-dimensional order profile” would be the same for all three points.
One could now ask whether the simpler structure here would make DHJ easier to prove. If so, then one could average up in the Sperner fashion. But it doesn’t look easy to say exactly what this simpler structure is.
February 7, 2009 at 4:58 pm |
339. Sperner and DHJ
I take that back. Here’s an actual conjecture.
Let’s take as our basic object the kind of thing one talks about in Sperner’s proof of the Brouwer fixed point theorem (surely a coincidence though). Chop out a large hexagonal piece from a tiling of the plane by hexagons and colour two of its edges (next to each other) red, two green and two blue, and extend these colourings from the boundary into the inside of the hexagon until you’ve coloured it all, and do so in such a way that you have three simply connected regions that meet at some point. Colourings of this kind are the basic objects that we’ll consider. Of course, “red”, “green” and “blue” is another way of saying 1, 2 and 3.
The question is, if you have a dense set of such colourings, must you have a combinatorial line? A combinatorial line in this context will be like what I described except that the three regions meet not at a point but round the boundary of a fourth region, which is the set of variable coordinates.
At the moment I know pretty well nothing about this question. I don’t know whether there’s an easy counterexample, I don’t know how to think about the measure on all those colourings (which feels like a fairly nasty object of a kind that the late and much lamented Oded Schramm would have been able to tell us about), and I don’t know whether a positive answer follows from density Hales-Jewett. The one thing I feel fairly confident of is that this, if true would imply DHJ. Oh, and one other thing is that I don’t have any feel for whether this is more or less equal to DHJ in difficulty, or whether there is a chance that it is easier.
Actually, there’s another thing that I’m confident of — in fact, certain of — which is that it is a natural generalization of the trivial fact that underlies Sperner. (That is the fact that if you have a dense set of 2-colourings of a line of points, then two of those 2-colourings will form a combinatorial line.)
This conjecture is probably not to be taken too seriously, but I quite like the fact that it doesn’t follow easily from DHJ.
February 7, 2009 at 7:09 pm |
340. Variant of Sperner
First I must admit, that I haven’t read much in this thread, so I don’t know if this has been said before. I got this idea while I tried to find some low values of .
. is a antichain, $\sum_{A\in\mathcal{A}}\frac{1}{\binom n{|A|}}\leq 1$. Using the same idea it is possible to show that if
is a antichain, $\sum_{A\in\mathcal{A}}\frac{1}{\binom n{|A|}}\leq 1$. Using the same idea it is possible to show that if  is a family, that intersects every chain
is a family, that intersects every chain ![\emptyset=A_0\subset A_1\subset A_2\subset\dots\subset A_n=[n]](https://s0.wp.com/latex.php?latex=%5Cemptyset%3DA_0%5Csubset+A_1%5Csubset+A_2%5Csubset%5Cdots%5Csubset+A_n%3D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , then $\sum_{A\in\mathcal{A}}\frac{1}{\binom n{|A|}}\geq 1$. Notice that when the elements of
, then $\sum_{A\in\mathcal{A}}\frac{1}{\binom n{|A|}}\geq 1$. Notice that when the elements of  is only allowed to have one of two given sizes, these two theorems are equivalent. The later theorem seems to be easier to generalize to the k=3 case, and it might be useful, at least in the 200-thread.
is only allowed to have one of two given sizes, these two theorems are equivalent. The later theorem seems to be easier to generalize to the k=3 case, and it might be useful, at least in the 200-thread.
In 331 Gowers gives a proof that if
February 7, 2009 at 9:56 pm |
341. Sperner
I’m reading 335, and I’m trying to understand the conjecture. First, there is a coloring theorem for subsets that says that one can find three disjoint sets in the same colour class that their unions are also in that colour class. It is a special case of the Finite Union Theorem (Folkman’s Theorem) which is equivalent to the finite sums theorem. It states that any finite colouring of the natural numbers contains arbitrary large monochromatic IP sets. The density statement is clearly false without extra conditions on the dense subset. It is obvious that the finite union theorem implies the finite sum theorem, however the other direction is difficult; one can use Van der Waerden for the reduction. Maybe we can also prove some density theorem for disjoint set unions using Szemeredi’s thm. It is still not Tim’s cross-product conjecture, but it seems to be quite promising. Let me also mention that the other proof of finite union theorem uses HJ! About the details: a possible reference is Graham, Rothschild, Spencer, “Ramsey Theory”. Now it’s family lunch-time, so I will be away for a while, but I’m quite excited about this possible “density finite union theorem” so I will come back a.s.a.p.
February 7, 2009 at 10:42 pm |
342. Sperner
Jozsef, What I wrote in 335 was meant to be more or less the same as what you suggested in 333 — a very slight generalization perhaps, but you can make it the same if you look at the special case . And I think that, as you say, it can be proved by the argument of 308. Or are we talking about different things?
. And I think that, as you say, it can be proved by the argument of 308. Or are we talking about different things?
February 7, 2009 at 11:37 pm |
343. In comment 335 what is meant in general by DHJ(j,k)?
February 8, 2009 at 12:02 am |
344. Sperner/DHJ
Boris, I hadn’t actually worked it out, but I think I can. Basically, DHJ(j,k) is density Hales-Jewett in![\null [k]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) but with
but with  placing a restriction on the complexity of the dense set
placing a restriction on the complexity of the dense set 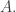 Let me give the case
Let me give the case  first. This is equivalent to the normal density Hales-Jewett theorem, but I’ll state it slightly differently.
first. This is equivalent to the normal density Hales-Jewett theorem, but I’ll state it slightly differently.
Actually, I think I may as well go for the whole thing right from the start.
Suppose that for each subset of
of ![\null [k]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) of size
of size  you have a set
you have a set 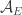 of functions from
of functions from  to the power set of
to the power set of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that the images of all the points in
such that the images of all the points in  are disjoint sets. Let’s write
are disjoint sets. Let’s write  for a typical element of
for a typical element of 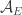 . I now define a set
. I now define a set  of (ordered) partitions of
of (ordered) partitions of ![\null [n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into
into  sets
sets  by taking all partitions
by taking all partitions  such that for every
such that for every  of size
of size  we have that
we have that  belongs to
belongs to 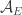 . Thus, in a certain sense the set of partitions (which are of course in one-to-one correspondence with sequences in
. Thus, in a certain sense the set of partitions (which are of course in one-to-one correspondence with sequences in ![\null [k]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) ) depends only on what collections of
) depends only on what collections of  sets there are in the partition. Then DHJ(j,k) is the claim that if your dense set
sets there are in the partition. Then DHJ(j,k) is the claim that if your dense set  has this special form, then it must contain a combinatorial line.
has this special form, then it must contain a combinatorial line.
My suggestion, which I think I could justify completely if pushed to do so, is that if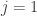 then one can prove DHJ(j,k) by a fairly simple adaptation of the proof of Sperner as given by Jozsef. Sperner, by the way, is DHJ(1,2), and the problem we have been considering is DHJ(2,3). In general, I suspect that DHJ(j,k) is of roughly equal difficulty to DHJ(j,j+1). It might be interesting to see if we can deduce DHJ(j,k) from DHJ(j,j+1), though at the moment my feeling is that we can prove DHJ(1,k) not by deducing it from DHJ(1,2) but by imitating the proof of DHJ(1,2), which is not quite the same thing.
then one can prove DHJ(j,k) by a fairly simple adaptation of the proof of Sperner as given by Jozsef. Sperner, by the way, is DHJ(1,2), and the problem we have been considering is DHJ(2,3). In general, I suspect that DHJ(j,k) is of roughly equal difficulty to DHJ(j,j+1). It might be interesting to see if we can deduce DHJ(j,k) from DHJ(j,j+1), though at the moment my feeling is that we can prove DHJ(1,k) not by deducing it from DHJ(1,2) but by imitating the proof of DHJ(1,2), which is not quite the same thing.
February 8, 2009 at 12:03 am |
345. Triangle Removal in Kneser Graphs
I will go back to the “density finite union theorem” soon as I think it is relevant to our project, but first here is a general remark about the removal lemma. I just want to make it clear that in a certain range we have a real removal lemma. Given three families of sets A,B, and C. If the number of disjoint triples (one element from each) is smaller than X (something depending on the sizes |A|,|B|, and |C|) then a small fraction of the disjoint pairs covers EVERY triangle. To see that, we just have to iterate the counting of “normal” triangles. (post 333.)
February 8, 2009 at 12:17 am |
346. I think I misunderstand comment 344. Consider DHJ(k-1,k). We have sets
sets  each of which gives a rise to a subset of
each of which gives a rise to a subset of ![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) which I call
which I call  . Then the subset
. Then the subset  of
of ![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) that corresponds to
that corresponds to  that is the intersection
that is the intersection  . However, nothing stops us from make
. However, nothing stops us from make  large, and their intersection empty.
large, and their intersection empty.
February 8, 2009 at 12:33 am |
347. Boris, I wasn’t clear enough in what I meant. Of course, you are right in what you say, but the statement is that if the intersection is dense then you get a combinatorial line, and not the weaker assumption that each individual is dense. Of course, in the case
is dense. Of course, in the case  you can consider just a set system
you can consider just a set system ![B_{[k-1]}](https://s0.wp.com/latex.php?latex=B_%7B%5Bk-1%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , just as in Sperner you can consider just the set of points where your sequence is 0.
, just as in Sperner you can consider just the set of points where your sequence is 0.
February 8, 2009 at 1:22 am |
348. Density Finite Union (DFU) Theorem
My previous remark was about a possible DFU thm. Let us see the simplest version. What would be a necessary density condition to guarantee a pair of disjoint sets A and B that A,B, and are in this “dense” set? Considering the arithmetic analogue, if we have a set
are in this “dense” set? Considering the arithmetic analogue, if we have a set ![S\subset [n]](https://s0.wp.com/latex.php?latex=S%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) with cn elements a that 2a is also in S, then there is a nontrivial solution for x+y=z.
with cn elements a that 2a is also in S, then there is a nontrivial solution for x+y=z.
February 8, 2009 at 1:37 am |
349. DFU contd.
The first density condition would be that the number of disjoint pairs is at least .The second condition should be something related to sets having 2/3n+-k elements. I’m still not sure what could be a meaningful notation for density here.
.The second condition should be something related to sets having 2/3n+-k elements. I’m still not sure what could be a meaningful notation for density here.
February 8, 2009 at 2:03 am |
350. DFU
A possible statement could be the following; Given a family F of subsets of [n]. Let us suppose that the number of disjoint pairs in F is at least We are going to define a graph on F. The verices are the sets in F and two are connected iff they are disjoint and their union is also in F. Then, either one can remove
We are going to define a graph on F. The verices are the sets in F and two are connected iff they are disjoint and their union is also in F. Then, either one can remove  vertices to destroy all edges, or there are
vertices to destroy all edges, or there are  edges where c’ depends on c only. I’m not sure that the statement is true, but something like this should be true.
edges where c’ depends on c only. I’m not sure that the statement is true, but something like this should be true.
February 8, 2009 at 2:14 am |
351. DFU (Density Finite Union) theorem.
Well, now I see that is way too ambitious; let me change it to f(n)|F| where f(n) goes to infinity.
is way too ambitious; let me change it to f(n)|F| where f(n) goes to infinity.
February 8, 2009 at 2:30 am |
352. DFU
I’ve got to go to bed, but as a last comment, let me ask whether 350 is intended as a set-theoretic analogue of Ben Green’s theorem that if you have a set with few solutions of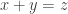 then you can remove a small number of elements and end up with no solutions of
then you can remove a small number of elements and end up with no solutions of 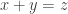 . It would be very nice to be able to prove something like that (and a generalization to larger finite unions).
. It would be very nice to be able to prove something like that (and a generalization to larger finite unions).
If one were going to try to find a counterexample, one would have a large collection of sets of size around , and one would partition them into disjoint pairs, and one would add to the collection the set of unions of these pairs, which would turn them into a matching in your graph. The question would then be whether one could do this without creating
, and one would partition them into disjoint pairs, and one would add to the collection the set of unions of these pairs, which would turn them into a matching in your graph. The question would then be whether one could do this without creating  further edges.
further edges.
Here’s an attempt to do so. First we choose a random collection of sets of size
of sets of size  , big enough that its
, big enough that its  lower shadow is all of
lower shadow is all of ![\binom{[n]}{n/3}](https://s0.wp.com/latex.php?latex=%5Cbinom%7B%5Bn%5D%7D%7Bn%2F3%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Next, we choose all sets of size at most
. Next, we choose all sets of size at most  . Then the number of disjoint pairs is certainly at least
. Then the number of disjoint pairs is certainly at least  . Also, the number of edges is at most
. Also, the number of edges is at most  . Next, it seems to me that it will be very hard to remove all edges: the fact that
. Next, it seems to me that it will be very hard to remove all edges: the fact that  is random and that every vertex is contained in an edge (and we could make
is random and that every vertex is contained in an edge (and we could make  slightly bigger so that each vertex is in several edges) ought to mean that we can choose a large matching. How big is
slightly bigger so that each vertex is in several edges) ought to mean that we can choose a large matching. How big is  ? Well, each set in
? Well, each set in  covers
covers  small sets, so by my calculations the number of edges is
small sets, so by my calculations the number of edges is  , which is a lot smaller than
, which is a lot smaller than  . Sorry if some of this turns out to be nonsense — I must must sleep now.
. Sorry if some of this turns out to be nonsense — I must must sleep now.
February 8, 2009 at 2:32 am |
353. DFU
Just to say that I wrote 352 before seeing your 351.
February 8, 2009 at 8:36 am |
354. DFU (Density Finite Union conjecture)
Let me state here a conjecture. It might not be directly connected to our project, however I’ve been looking for the right formulation for a while and I think that this is the right one; First we have to find the proper notation of density since simple density wouldn’t guarantee the result we are looking for. The “weighted density” of a set![S\subset [n]](https://s0.wp.com/latex.php?latex=S%5Csubset+%5Bn%5D+&bg=ffffff&fg=333333&s=0&c=20201002) is given by the sum of the (normalized) number of pairwise disjoint k-tuples in S for all 1<kc>0 there are m pairwise disjoint sets,
is given by the sum of the (normalized) number of pairwise disjoint k-tuples in S for all 1<kc>0 there are m pairwise disjoint sets,  that
that  for any nonempty
for any nonempty ![I\subset [m]](https://s0.wp.com/latex.php?latex=I%5Csubset+%5Bm%5D+&bg=ffffff&fg=333333&s=0&c=20201002) . This form is clearly a density version of Folkman’s theorem; If we colour the subsets of [n] by K colours, then at least one class has density > 1/K.
. This form is clearly a density version of Folkman’s theorem; If we colour the subsets of [n] by K colours, then at least one class has density > 1/K.
February 8, 2009 at 8:45 am |
Somehow I lost the middle of the text between 10
355. DFU (Density Finite Union conjecture)
Let me state here a conjecture. It might not be directly connected to our project, however I’ve been looking for the right formulation for a while and I think that this is the right one; First we have to find the proper notation of density since simple density wouldn’t guarantee the result we are looking for. The “weighted density” of a set![S\subset 2^{[n]}](https://s0.wp.com/latex.php?latex=S%5Csubset+2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) is given by the sum of the (normalized) number of pairwise disjoint k-tuples in S.
is given by the sum of the (normalized) number of pairwise disjoint k-tuples in S.  . The maximum number of pairwise disjoint k-tuples is
. The maximum number of pairwise disjoint k-tuples is  so D(S) is a number between 0 and 1. The conjecture is that for any number m, if S contains no m pairwise disjoint elements with all
so D(S) is a number between 0 and 1. The conjecture is that for any number m, if S contains no m pairwise disjoint elements with all  possible nonempty unions, then it is sparse. D(S) goes to 0 as n goes to infinity.
possible nonempty unions, then it is sparse. D(S) goes to 0 as n goes to infinity.
With different words, if S is dense (and large enough) then there are m pairwise disjoint sets, that
that  for any nonempty index set
for any nonempty index set ![I\subset [m]](https://s0.wp.com/latex.php?latex=I%5Csubset+%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002)
February 8, 2009 at 11:51 am |
356. DFU
Dear Jozsef, I’ve edited your last comment so that the formulae show up, and made a couple of other tiny changes (such as changing![S\subset [n]](https://s0.wp.com/latex.php?latex=S%5Csubset+%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) to
to ![S\subset 2^{[n]}](https://s0.wp.com/latex.php?latex=S%5Csubset+2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) ). Please check that I haven’t introduced any errors.
). Please check that I haven’t introduced any errors.
As it stands, I don’t understand your conjecture. A typical disjoint -tuple has all its sets of size around
-tuple has all its sets of size around  , so it seems to me that the set of all sets of size around
, so it seems to me that the set of all sets of size around  is dense in your sense. And there is of course no hope of getting finite unions in this set. Am I misunderstanding something?
is dense in your sense. And there is of course no hope of getting finite unions in this set. Am I misunderstanding something?
February 8, 2009 at 5:43 pm |
[…] and lower bounds for the density Hales-Jewett problem , hosted by Terence Tao on his blog, and DHJ — the triangle-removal approach, which is on this blog. These three threads are exploring different facets of the problem, though […]
February 8, 2009 at 6:22 pm |
357. DFU
Tim, there is a 1/(n-1) multiplier, so I thought that one layer (k) will contribute a small fraction only. In particular, I think that rich layers form arithmetic progressions and it might be useful in a possible proof.
February 8, 2009 at 6:37 pm |
358. DFU
Ah — I hadn’t spotted that you were averaging over lots of layers. Now it starts to make more sense to me.
February 8, 2009 at 7:25 pm |
359. Averaging over multiple layers does not seem to help in comment 355. Consider the family of all sets of odd size. It contains no disjoint
of all sets of odd size. It contains no disjoint  such that
such that  .
.
February 8, 2009 at 7:30 pm |
Oops… for the example I gave.
for the example I gave.
February 8, 2009 at 8:05 pm |
361. I think Jozsef’s conjecture is true, but not for an interesting reasons. I claim that for every fixed positive integer the condition
the condition  implies that
implies that ![|S\cap \binom{[n]}{t}|\geq (1-o(1))\binom{n}{t}](https://s0.wp.com/latex.php?latex=%7CS%5Ccap+%5Cbinom%7B%5Bn%5D%7D%7Bt%7D%7C%5Cgeq+%281-o%281%29%29%5Cbinom%7Bn%7D%7Bt%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Suppose not, let
. Suppose not, let ![T=\binom{[n]}{t}\setminus S](https://s0.wp.com/latex.php?latex=T%3D%5Cbinom%7B%5Bn%5D%7D%7Bt%7D%5Csetminus+S&bg=ffffff&fg=333333&s=0&c=20201002) . Now let us generate the partition of
. Now let us generate the partition of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into
into  parts as follows. Let
parts as follows. Let  be the partition of
be the partition of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into
into  random parts. If
random parts. If  with
with  , then
, then ![Pr[P_i\in T]=p](https://s0.wp.com/latex.php?latex=Pr%5BP_i%5Cin+T%5D%3Dp&bg=ffffff&fg=333333&s=0&c=20201002) is positive, and is independent of
is positive, and is independent of  . Had
. Had  been independent, it would have implied that
been independent, it would have implied that ![Pr[\exists i\ P_i\in T]=p^k](https://s0.wp.com/latex.php?latex=Pr%5B%5Cexists+i%5C+P_i%5Cin+T%5D%3Dp%5Ek&bg=ffffff&fg=333333&s=0&c=20201002) is exponentially small. Clearly,
is exponentially small. Clearly,  ‘s are not independent, but they are nearly independent. More precisely, let
‘s are not independent, but they are nearly independent. More precisely, let 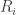 be the event that
be the event that  . Then
. Then ![Pr[ P_i\cap P_j\neq \emptyset |R_i\wedge R_j]=1-O(n^{-1/2})](https://s0.wp.com/latex.php?latex=Pr%5B+P_i%5Ccap+P_j%5Cneq+%5Cemptyset+%7CR_i%5Cwedge+R_j%5D%3D1-O%28n%5E%7B-1%2F2%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) . Hence, sampling
. Hence, sampling  random sets by choosing each element with probability
random sets by choosing each element with probability 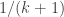 is virtually indistinguishable from choosing a random
is virtually indistinguishable from choosing a random  -tuple of disjoint sets, and then looking at first
-tuple of disjoint sets, and then looking at first  of them. I believe I can write the appropriate string of inequalities to show that if asked.
of them. I believe I can write the appropriate string of inequalities to show that if asked.
Since density of is nearly
is nearly  on each
on each ![\binom{[n]}{t}](https://s0.wp.com/latex.php?latex=%5Cbinom%7B%5Bn%5D%7D%7Bt%7D&bg=ffffff&fg=333333&s=0&c=20201002) the existence of any given configuration follows by simple averaging.
the existence of any given configuration follows by simple averaging.
February 8, 2009 at 9:18 pm |
362.
Thanks Boris! It seems that this is still not the right formulation for a DFU conjecture. Actually, I should have noticed that a random selection of sets with probability 1/2 already gives density zero. So, I’m still looking for the right density definition. Boris, do you have any suggestion?
February 9, 2009 at 12:03 am |
363. DHJ(j,k)
I had to struggle a bit to understand what DHJ(j,k) meant – I had not followed this thread for a while – but when I finally got it, I can see how it fits nicely with the whole hypergraph regularity/hypergraph removal story, and so does look quite promising. Anyway, I thought I’d try to restate it here in case anyone else also wants to know about it…
In![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , we can define the notion of a “(basic) complexity 1 set” to be a set
, we can define the notion of a “(basic) complexity 1 set” to be a set ![A \subset [3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) of strings whose 1-set lies in some fixed class
of strings whose 1-set lies in some fixed class ![{\mathcal A}_1 \subset 2^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_1+%5Csubset+2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , whose 2-set lies in some fixed class
, whose 2-set lies in some fixed class ![{\mathcal A}_2 \subset 2^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_2+%5Csubset+2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , and whose 3-set lies in some fixed class
, and whose 3-set lies in some fixed class ![{\mathcal A}_3 \subset 2^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_3+%5Csubset+2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) . A simple example here is
. A simple example here is  ; in this case
; in this case  is the set of subsets of
is the set of subsets of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) of size a, and so forth. As I just recently understood over at the obstructions to uniformity thread, basic complexity 1-sets are obstructions to uniformity, and so we definitely need to figure out how to find lines in these sets.
of size a, and so forth. As I just recently understood over at the obstructions to uniformity thread, basic complexity 1-sets are obstructions to uniformity, and so we definitely need to figure out how to find lines in these sets.
In analogy with hypergraph regularity (and also with ergodic theory), the next more complicated type of set might be “non-basic complexity 1 sets” – sets which are unions of a bounded number of basic complexity 1 sets. (In graph theory, basic complexity 1 corresponds to a complete bipartite weighted graph between two cells with some constant weight, and non-basic complexity 1 corresponds to a Szemeredi-type weighted graph between a bounded number of cells, with any pair of cells having a constant weight
having a constant weight  on the edges connecting them.) But it seems fairly obvious that if dense basic complexity 1 sets have lines, then so do dense non-basic complexity 1 sets (though one may have to be careful with quantifiers, and use the usual Szemeredi double induction to organise the epsilons properly).
on the edges connecting them.) But it seems fairly obvious that if dense basic complexity 1 sets have lines, then so do dense non-basic complexity 1 sets (though one may have to be careful with quantifiers, and use the usual Szemeredi double induction to organise the epsilons properly).
Then we have the basic complexity 2 sets in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , which are those sets A in which the 12-profile of A (i.e. the pair consisting of the 1-set and 2-set of A; one can also identify this with an element of
, which are those sets A in which the 12-profile of A (i.e. the pair consisting of the 1-set and 2-set of A; one can also identify this with an element of ![3^{[n]}](https://s0.wp.com/latex.php?latex=3%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) ) lies in some fixed class
) lies in some fixed class ![{\mathcal A}_{12} \subset 3^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_%7B12%7D+%5Csubset+3%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , the 23-profile of A lies in some fixed class
, the 23-profile of A lies in some fixed class ![{\mathcal A}_{23} \subset 3^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_%7B23%7D+%5Csubset+3%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , and the 31-profile of $A$ lies in some fixed class
, and the 31-profile of $A$ lies in some fixed class ![{\mathcal A}_{31} \subset 3^{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D_%7B31%7D+%5Csubset+3%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) . But of course when k=3, any one of these complexity 2 profiles determine the entire set A, so every set A is complexity 2, which is why DHJ(2,3) is the same as DHJ(3). [Incidentally, to answer a previous question, this hierarchy seems to be unrelated to my DHJ(2.5) – I was simplifying the lines rather than the sets.]
. But of course when k=3, any one of these complexity 2 profiles determine the entire set A, so every set A is complexity 2, which is why DHJ(2,3) is the same as DHJ(3). [Incidentally, to answer a previous question, this hierarchy seems to be unrelated to my DHJ(2.5) – I was simplifying the lines rather than the sets.]
If we knew that sets A which were uniformly distributed wrt complexity 1 sets were quasirandom (a “counting lemma”), then we would be well on our way to reducing DHJ(2,3) to DHJ(1,3) by the usual regularity type arguments. (I’m sure Tim and the others here already know this, this is just me trying to get up to speed.)
February 9, 2009 at 12:24 am |
364. Big picture
There is now a definite convergence of this thread and the obstructions-to-uniformity thread, which perhaps illustrates the advantages of not splitting the discussion up. At any rate, this last comment of Terry’s is closely related to comment 411, and also to earlier comments on the 400-499 thread that attempt to establish some sort of counting lemma. I now get the feeling that the problem has been softened up, and that it is not ridiculous to hope that we might actually solve it. But it could be that certain difficulties that feel technical will turn out to be fundamental.
Unfortunately, I’ve got two big teaching days coming up, so my input is going to go right down for a while. But perhaps that’s in the spirit of polymath — we get involved, then we go off and do other things, then we come back and catch up with what’s going on, but all the while polymath continues churning away at the problem.
February 9, 2009 at 2:36 am |
Metacomment: Ideally, I suppose we should be working in an environment in which comments from different threads can somehow overlap, coalesce, or otherwise interlink to each other. But, failing that, I think this division into subthreads has been the least worst solution (e.g. the for small n thread seems to have taken off once it was separated from the “mainstream” threads of the project). And revisiting the threads every 100 comments or so seems to be just about the right tempo, I think.
for small n thread seems to have taken off once it was separated from the “mainstream” threads of the project). And revisiting the threads every 100 comments or so seems to be just about the right tempo, I think.
February 9, 2009 at 10:49 am |
365. Technical clean-up idea
This is another comment that could go either here or on the obstructions-to-uniformity thread, but I think it is slightly more appropriate here. Terry, that’s a good point about the 100-comments-per-post rule, and if the 300s and 400s threads really do seem to be converging, then they can merge into the 500s thread.
My comment is that I have a variant of DHJ that ought to be equivalent to DHJ itself but has the potential to tidy up a lot of the annoying technicalities to do with slices being of different sizes. (I don’t know for certain that it will work, however.) It’s motivated by the proof of Sperner that I gave in 331. There one shows the stronger result that if the slice densities add up to more than 1 then there is a “combinatorial line”. What should the analogue be for DHJ?
My contention is the following: define the slice density to be
to be  . Then I claim that if
. Then I claim that if  (for fixed positive
(for fixed positive  and sufficiently large
and sufficiently large  ), then
), then  contains a combinatorial line. This conjecture bears the same relation to corners that the strong form of Sperner bears to the trivial fact that if you have at least two points in
contains a combinatorial line. This conjecture bears the same relation to corners that the strong form of Sperner bears to the trivial fact that if you have at least two points in ![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) then you get a configuration of the form
then you get a configuration of the form  with
with  . Given that the averaging argument for Sperner naturally proves this stronger result, I think there is reason to hope that the numbers will all work out miraculously better if we go for this revised version of DHJ. I hope that way we can avoid boring details about being near the middle.
. Given that the averaging argument for Sperner naturally proves this stronger result, I think there is reason to hope that the numbers will all work out miraculously better if we go for this revised version of DHJ. I hope that way we can avoid boring details about being near the middle.
I haven’t begun to check whether this miracle really does happen, but I think it’s definitely worth investigating.
February 9, 2009 at 11:07 am |
366. Technical clean-up idea.
Another way of looking at 365. All we’re doing is choosing a random point of![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) not with the uniform measure but by first choosing a slice and then choosing a random point in that slice. It seems to me that this should have huge advantages. For instance, and most notably, the distribution of a random point used to be radically different if you conditioned on it belonging to a typical combinatorial line. Now it’s different but not that different. (With the new measure the situation is on a par with the situation for corners, where the difference between the distributions of random point and random vertex of a random corner is not a serious problem.) But I think there may be all sorts of arguments that will now work out exactly. Perhaps even the quasirandomness calculations I was trying to do will become clean and nice. No time to check though!
not with the uniform measure but by first choosing a slice and then choosing a random point in that slice. It seems to me that this should have huge advantages. For instance, and most notably, the distribution of a random point used to be radically different if you conditioned on it belonging to a typical combinatorial line. Now it’s different but not that different. (With the new measure the situation is on a par with the situation for corners, where the difference between the distributions of random point and random vertex of a random corner is not a serious problem.) But I think there may be all sorts of arguments that will now work out exactly. Perhaps even the quasirandomness calculations I was trying to do will become clean and nice. No time to check though!
November 4, 2011 at 12:35 am |
Hi everyone. While the Hales-Jewett theorem may be a little beyond my current level of mathematics, I did put something together that I believe the mathematicians that solved this problem would have interest in.
I created a fully playable 12 dimensional tic-tac-toe iPhone game.
It is available for free download on the app store.
http://itunes.apple.com/us/app/twelvetacto/id457438285?mt=8
My calculation gives 121,804,592 possible solutions for an unaltered playing space via the self-discovered formula:
s(d) = (1/2) * ( (k +2)^d – k^d )
where d = # of dimensions
and k = length of side
I’ve also defined it recursively as:
s(d) = (k+2)*s(d-1) + k^(d-1)
In my game, d = 12 and k = 3.
Using the basic framework of the game, I do believe a computer-assisted proof would be possible. I do know that computer proofs are generally considered less elegant in the world of higher mathematics, but if anyone is interested, I would be willing to share my source code and collaborate on such a proof.