Apologies for the attention-seeking title, but that really is the purpose of this post. I want to draw attention to some ideas that are buried in more comments that most people are likely to want to read, because I think there is a chance that all that stands between where we are now and a solution to EDP is a few soluble technical problems. It goes without saying that that chance is distinctly less than 100%, but I think it is high enough for it to be worth my going to some trouble to lay out as precisely as I can what the current approach is and what remains to be done. I’ll try to write it in such a way that it explains what is going on even to somebody who has not read any of the posts or comments so far. The exception to that is that I shall not repeat very basic things such as what the Erdős discrepancy problem is, what a homogeneous arithmetic progression is, etc. For that kind of information, I refer the reader to the front page of the Polymath5 wiki.
Representing the identity.
Let me now discuss an approach that doesn’t work. (If you have been keeping up with the discussion, then this will be familiar material explained in a slightly different way.) Let  be a large integer, and if
be a large integer, and if  and
and  are two HAPs contained in
are two HAPs contained in ![[N]=\{1,2,\dots,N\},](https://s0.wp.com/latex.php?latex=%5BN%5D%3D%5C%7B1%2C2%2C%5Cdots%2CN%5C%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002) then write
then write 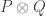 for the
for the 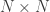 matrix that is 1 at
matrix that is 1 at  if
if  and
and  and 0 otherwise. In other words, it’s the characteristic function of
and 0 otherwise. In other words, it’s the characteristic function of  Note that if
Note that if  then
then  Let us write
Let us write  as
as  etc.
etc.
Suppose that we could find for every pair  of HAPs contained in
of HAPs contained in ![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=ffffff&fg=333333&s=0&c=20201002) a coefficient
a coefficient  in such a way that
in such a way that  and
and  Then for every real sequence
Then for every real sequence  we have
we have

It follows by averaging that there exist and such that

In particular, if each  then there must exist and such that
then there must exist and such that  from which it follows that either
from which it follows that either  or
or  is at least
is at least  So if we can get
So if we can get  to tend to zero as tends to infinity then we are done.
to tend to zero as tends to infinity then we are done.
Unfortunately, it is impossible to get to tend to zero. The reason is that the above argument would imply that if  when
when  mod 3, then for every
mod 3, then for every  there exists a HAP such that
there exists a HAP such that  But that is not true: it can never be greater than 1.
But that is not true: it can never be greater than 1.
Because of this example, we have been trying a different approach, which is to look for a more general diagonal matrix  and write that as a linear combination of matrices of the form
and write that as a linear combination of matrices of the form  If one generalizes the approach in this way, then it is no longer clear that it cannot work — indeed, it seems likely that it can. However, it also seems to be hard to find a suitable diagonal matrix, and hard to think how one might decompose it once it is found.
If one generalizes the approach in this way, then it is no longer clear that it cannot work — indeed, it seems likely that it can. However, it also seems to be hard to find a suitable diagonal matrix, and hard to think how one might decompose it once it is found.
Working over the rationals instead.
The single main point of this post is to suggest a way of overcoming this last difficulty. And that is to resurrect an idea that was first raised right near the beginning of this project, which is to look at the problem for functions defined on the positive rationals rather than the positive integers. (It is a straightforward exercise to show that the two problems are equivalent. For details go to the Polymath5 wiki and look at the section on the first page with simple observations about EDP.)
The point is that the counterexamples that show that the approach cannot work for the integers all make crucial use of the fact that some numbers are more divisible by small factors than others. But over the positive rationals all numbers are equally divisible. Or to put it another way, multiplying by a positive rational is an automorphism of 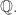 This suggests that perhaps over the rationals it would be possible to use the identity matrix.
This suggests that perhaps over the rationals it would be possible to use the identity matrix.
Dealing with infinite sets.
Now a problem arises if we try to do this, which is that the rationals are infinite. So what are we supposed to say about the sum of coefficients when we decompose the identity into a linear combination  ?
?
Let me answer this question in two stages. First I’ll say what happens if we decompose the identity when the ground set is  which shows a way of dealing with infinite sets, and then I’ll move on to
which shows a way of dealing with infinite sets, and then I’ll move on to  where some additional problems arise.
where some additional problems arise.
Suppose, then, that the infinite identity matrix (that is, the function  where
where  and
and  range over
range over  ) has been expressed as a linear combination
) has been expressed as a linear combination  Now let
Now let  be a
be a  sequence. We’d like to show that it has unbounded discrepancy: that is, we’d like to show that for every there exists a HAP such that
sequence. We’d like to show that it has unbounded discrepancy: that is, we’d like to show that for every there exists a HAP such that 
Our problem is that  is going to be infinite. We’d somehow like to show that it has “density” at most
is going to be infinite. We’d somehow like to show that it has “density” at most 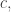 where is an arbitrary positive constant, or perhaps show that it has density zero. One way we might do this is as follows. For each positive integer
where is an arbitrary positive constant, or perhaps show that it has density zero. One way we might do this is as follows. For each positive integer 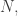 Let
Let 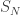 be the sum of the
be the sum of the  over all such that both and have non-empty intersection with
over all such that both and have non-empty intersection with ![[N].](https://s0.wp.com/latex.php?latex=%5BN%5D.&bg=ffffff&fg=333333&s=0&c=20201002) Then define the upper density of the coefficients to be
Then define the upper density of the coefficients to be  If this is zero we can say that the coefficients have density zero. And if it is at most then we can say that they have density at most
If this is zero we can say that the coefficients have density zero. And if it is at most then we can say that they have density at most 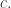 (In fact, even the
(In fact, even the  would be OK — we just want the density to be small infinitely often.)
would be OK — we just want the density to be small infinitely often.)
Let’s suppose that  is at most Then if we truncate the sequence
is at most Then if we truncate the sequence 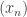 at , by changing all values after to zero, we find that
at , by changing all values after to zero, we find that

where I have written  for the set of all HAPs that have non-empty intersection with Since
for the set of all HAPs that have non-empty intersection with Since  the same averaging argument as before gives us a HAP (either or — WLOG ) such that
the same averaging argument as before gives us a HAP (either or — WLOG ) such that 
I fully admit that this is not very infinitary, but it is simple, and I’m not sure it matters too much that it is not infinitary. I’ll just briefly mention that one can use it to express the proof of Roth’s theorem (about AP discrepancy rather than HAP discrepancy). One expresses the infinite identity matrix as the following integral:

where  One then expresses each function
One then expresses each function  as a linear combination of HAPs of length (an arbitrary positive integer) and common difference at most
as a linear combination of HAPs of length (an arbitrary positive integer) and common difference at most  One then obtains some cancellation in the coefficients, and proves that the density of the coefficients is at most
One then obtains some cancellation in the coefficients, and proves that the density of the coefficients is at most  (up to a constant factor). For details of how this calculation works, see this write-up, and in particular the third section.
(up to a constant factor). For details of how this calculation works, see this write-up, and in particular the third section.
The importance of the restriction on the length and common difference is that the edge effects (that is, APs that intersect without being contained in ) are negligible for large 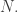 It is this feature that is slightly trickier to obtain for the rationals, to which I now turn.
It is this feature that is slightly trickier to obtain for the rationals, to which I now turn.
Transferring to HAPs and rationals.
One useful feature of the set of APs of length and common difference at most is that each number greater than or equal to  is contained in precisely such APs. A first question to ask ourselves is whether we can find a set of HAPs that covers the rationals in a similarly nice way. To start with, observe that if
is contained in precisely such APs. A first question to ask ourselves is whether we can find a set of HAPs that covers the rationals in a similarly nice way. To start with, observe that if  is a rational, then we can easily describe every HAP of length that contains
is a rational, then we can easily describe every HAP of length that contains  Indeed, for every
Indeed, for every  between
between  and
and 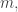 we have the HAP consisting of the first multiples of
we have the HAP consisting of the first multiples of  and that is all of them (since must be in the th place of the HAP for some
and that is all of them (since must be in the th place of the HAP for some 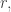 and that and the length determine the HAP). So we have the extremely undeep result that every is contained in precisely HAPs of length (Note, however, how untrue this is if we work in the positive integers rather than the positive rationals.)
and that and the length determine the HAP). So we have the extremely undeep result that every is contained in precisely HAPs of length (Note, however, how untrue this is if we work in the positive integers rather than the positive rationals.)
This looks promising, but we now need an analogue of the “increasing system of neighbourhoods” that was provided for us by the sets (It might have been more natural to work in  and take the sets
and take the sets ![[-N,N].](https://s0.wp.com/latex.php?latex=%5B-N%2CN%5D.&bg=ffffff&fg=333333&s=0&c=20201002) ) What is a sensible collection of finite sets with union equal to
) What is a sensible collection of finite sets with union equal to 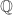 ?
?
One way of thinking about the sets is as follows. Using our system of APs, we can define a graph: we join to  if there is an AP of length and common difference at most that contains both and
if there is an AP of length and common difference at most that contains both and  The sets are quite close to increasing neighbourhoods in this graph: start with the number 1 and then take all points of distance at most from it. If we work with rather than then this graph is a Cayley graph, and after a while the neighbourhoods grow linearly with which is why the boundary effects are small.
The sets are quite close to increasing neighbourhoods in this graph: start with the number 1 and then take all points of distance at most from it. If we work with rather than then this graph is a Cayley graph, and after a while the neighbourhoods grow linearly with which is why the boundary effects are small.
What happens if we define a similar graph using HAPs in ? Now we are joining to if there exists  and
and  such that
such that  That is precisely the condition that there exists a HAP of length that contains both and In other words, we take the multiplicative group of and inside it we take the Cayley graph with generators all numbers
That is precisely the condition that there exists a HAP of length that contains both and In other words, we take the multiplicative group of and inside it we take the Cayley graph with generators all numbers 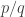 with
with 
This feels like the right graph to take, but it has the slight drawback that it is not connected: it is impossible to get from to if 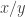 is a rational such that in its lowest terms either its numerator or denominator is divisible by a prime greater than The connected component of 1 in the graph is the set of all rationals
is a rational such that in its lowest terms either its numerator or denominator is divisible by a prime greater than The connected component of 1 in the graph is the set of all rationals  where both and
where both and  are products of primes less than or equal to But this is not really a problem: we’ll just work in that component of the graph.
are products of primes less than or equal to But this is not really a problem: we’ll just work in that component of the graph.
Let’s write  for the component of we are working in, and
for the component of we are working in, and  for the set of all points at distance at most from 1 in the graph. Now we can say how it would in principle be possible to prove EDP. We would like to find a way of writing the identity (this time thought of as the function
for the set of all points at distance at most from 1 in the graph. Now we can say how it would in principle be possible to prove EDP. We would like to find a way of writing the identity (this time thought of as the function  where and range over ) in the form
where and range over ) in the form

where and are HAPs of length at most that are contained in  For each let
For each let  be the set of all such HAPs that have non-empty intersection with the neighbourhood
be the set of all such HAPs that have non-empty intersection with the neighbourhood  Then we can define
Then we can define  to be
to be  and we can define the upper density of the coefficients to be
and we can define the upper density of the coefficients to be 
Now let me show that if  is at most for some sufficiently large then the HAP-discrepancy of every function
is at most for some sufficiently large then the HAP-discrepancy of every function  on is at least This is by almost exactly the same argument that worked in
on is at least This is by almost exactly the same argument that worked in 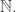 The first step is to consider the restriction of to Then we know that
The first step is to consider the restriction of to Then we know that

Now any HAP of length at most that intersects  is contained in
is contained in  from which it follows that any HAP of length at most that intersects but is not contained in must intersect
from which it follows that any HAP of length at most that intersects but is not contained in must intersect  Since is a finitely generated Abelian group, the sets grow polynomially, which implies that the ratio
Since is a finitely generated Abelian group, the sets grow polynomially, which implies that the ratio  tends to zero with
tends to zero with 
I’ll now be very slightly sketchy. We are supposing that is at most It follows that either  or
or  is noticeably smaller than
is noticeably smaller than  In the second case we can change to
In the second case we can change to  and start again — we won’t be able to do this too many times so eventually we’ll reach the first case, where
and start again — we won’t be able to do this too many times so eventually we’ll reach the first case, where 
In that case we have that

and that

After that, the argument really is the same as before (give or take the small approximations). [Remark: I have not checked the details of the above sketch, but I’m confident that something along these lines can be done if this doesn’t quite work. It’s slightly more difficult than in because it isn’t obvious that the intersection of a HAP with is a HAP, whereas the intersection of an AP with  is an AP.]
is an AP.]
Characters on the rationals.
Now we must think about how to express the identity as a linear combination of HAP products with coefficients of density at most where is some arbitrary positive constant. Taking our cue from the case, it would be natural to express the identity on in terms of characters, and then to decompose the characters. So a preliminary task is to work out what the characters are.
This is (not surprisingly) a piece of known mathematics. I shall discuss it in a completely bare-hands way, but readers who don’t like that kind of discussion may prefer to look at the comment by BCnrd to this Mathoverflow question.
First I’ll work out what the characters on are, and then I’ll look at Recall that a character is a function  from to the unit circle in
from to the unit circle in  such that
such that  for every
for every  That is, it is a homomorphism from
That is, it is a homomorphism from  to
to 
Suppose we know the value of at a rational That tells us what  is for every integer
is for every integer  However, it does not tell us what
However, it does not tell us what  is, say. All we know is that
is, say. All we know is that  which gives us two possibilities for
which gives us two possibilities for  So in order to specify
So in order to specify  we need to specify its values at enough rationals that we can write every other rational as a multiple of one of them. And the choices we make at those rationals have to be compatible with each other.
we need to specify its values at enough rationals that we can write every other rational as a multiple of one of them. And the choices we make at those rationals have to be compatible with each other.
A simple way of doing that is to choose the value of at 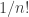 for every positive integer
for every positive integer 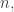 making sure that
making sure that  That is, we choose
That is, we choose  to be any point in
to be any point in  and then for each we have choices for
and then for each we have choices for  given our choices up to that point.
given our choices up to that point.
An equivalent way of thinking about this is that we choose a sequence of real numbers  satisfying the conditions that
satisfying the conditions that  and
and  is a multiple of
is a multiple of  Then the corresponding character is defined at
Then the corresponding character is defined at  to be
to be  for any
for any  Note that this is well-defined, since if and are both at least
Note that this is well-defined, since if and are both at least  then
then  so
so 
Now because we chose an element of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and then made a sequence of finite choices, it is easy to put a probability measure on the set of characters. We can therefore make sense of the expression
and then made a sequence of finite choices, it is easy to put a probability measure on the set of characters. We can therefore make sense of the expression

and prove that it is  Let me briefly sketch this. Suppose that
Let me briefly sketch this. Suppose that 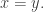 Then
Then  for every so we get 1. If
for every so we get 1. If  then let
then let  when written in its lowest terms. If is the (random) sequence that determines then each
when written in its lowest terms. If is the (random) sequence that determines then each 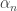 is uniformly distributed in the interval
is uniformly distributed in the interval  and
and  But
But  is uniformly distributed in the interval
is uniformly distributed in the interval  so this expectation is zero (as
so this expectation is zero (as  ).
).
We have therefore shown that

where  is the identity indexed by
is the identity indexed by
What do we do if we want to modify this to work for ? Well, an initial complication that (I hope) turns out not to be a serious complication is that is not an additive group: it contains 1 and it does not contain any prime greater than However, it generates a subgroup  of which consists of all rationals with denominators that are products of primes less than or equal to When I refer to “characters on ” I will really mean characters on
of which consists of all rationals with denominators that are products of primes less than or equal to When I refer to “characters on ” I will really mean characters on 
To describe these, we no longer need a sequence of reciprocals such that every rational is a multiple of one of them: we just want to capture all rationals in But that is straightforward: instead of taking the sequence  we could take the sequence
we could take the sequence  or we could replace
or we could replace 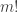 by the product of all the primes up to There are any number of things that we could do.
by the product of all the primes up to There are any number of things that we could do.
Decomposing a character into “non-local” HAPs.
The thing that seems to me to make this approach very promising is that for any character on it is possible to partition into long HAPs on each of which is approximately constant. As this result suggests, it is possible to decompose in an efficient way as a linear combination of HAPs, which is very much the kind of thing we need to do in order to imitate the Roth proof.
I should warn in advance that it is not quite good enough for our purposes, because the HAPs we use are not “local” enough: they are sets of the form  such that
such that 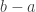 is small, but we do not also know that
is small, but we do not also know that  and
and  are small. Without that, each number is contained in infinitely many HAPs, so we no longer have the condition that enabled us to define the “density” of a set of coefficients. Later I shall present a different idea that does use “local” HAPs, but fails for a different reason. My gut instinct is that these difficulties are not fundamental to the approach, but whether that is mathematical intuition or wishful thinking is hard to say.
are small. Without that, each number is contained in infinitely many HAPs, so we no longer have the condition that enabled us to define the “density” of a set of coefficients. Later I shall present a different idea that does use “local” HAPs, but fails for a different reason. My gut instinct is that these difficulties are not fundamental to the approach, but whether that is mathematical intuition or wishful thinking is hard to say.
Before I go any further, here is an easy lemma.
Lemma. Let be a character on and let  Then there exists
Then there exists  such that for every there exists a positive integer
such that for every there exists a positive integer  such that
such that 
Proof. Without loss of generality  Let
Let  and let be the lowest common multiple of the numbers from 1 to
and let be the lowest common multiple of the numbers from 1 to 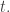 [Thanks to David Speyer for pointing out at Mathoverflow that the l.c.m. is around
[Thanks to David Speyer for pointing out at Mathoverflow that the l.c.m. is around  a non-negligible improvement over
a non-negligible improvement over  .] Then by the usual pigeonhole argument we can find a positive integer
.] Then by the usual pigeonhole argument we can find a positive integer 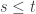 such that
such that  so we can take
so we can take 
For the next result we define a HAP to be a set of the form 
Corollary. Let be a character on let  and let be a positive integer. Then we can partition into HAPs of lengths between
and let be a positive integer. Then we can partition into HAPs of lengths between  and on each of which varies by at most
and on each of which varies by at most 
Proof. We begin by covering the integers. Find a positive integer such that  Then on any HAP with common difference
Then on any HAP with common difference  and length at most varies by at most We can partition the multiples of into HAPs of length and they will cover all the integers. (Indeed, they will cover all the multiples of
and length at most varies by at most We can partition the multiples of into HAPs of length and they will cover all the integers. (Indeed, they will cover all the multiples of  )
)
We now want to fill in some gaps. Let us write 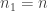 and let us pick an integer
and let us pick an integer 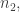 a multiple of
a multiple of 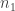 and greater than
and greater than  such that
such that  Between any two multiples of
Between any two multiples of  there are at least
there are at least  multiples of
multiples of  forming a HAP. This HAP can be partitioned into HAPs of common difference and lengths between and If we continue this process and make sure that every positive integer divides at least one
forming a HAP. This HAP can be partitioned into HAPs of common difference and lengths between and If we continue this process and make sure that every positive integer divides at least one 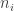 (which is easy to do), then we are done.
(which is easy to do), then we are done.
Now a character restricted to a HAP is just a trigonometric function. If the character varies very slowly as you progress along the HAP, then convolving it with an interval (as in the Roth argument, but now we are talking about a chunk with the same common difference as the HAP) we obtain a multiple very close to 1 of the character itself. With the help of this observation, we can actually decompose the character efficiently as a linear combination of HAPs. Since this does not obviously help us, I will leave the details as an exercise.
What can we do with local HAPs?
Let us fix a positive integer and define a HAP to be local if it is of the form  where
where  (Thus, the definition of “local” depends on ) What happens if we have a character and try to decompose its restriction to as a linear combination of local HAPs (of reasonable length) on each of which varies very little?
(Thus, the definition of “local” depends on ) What happens if we have a character and try to decompose its restriction to as a linear combination of local HAPs (of reasonable length) on each of which varies very little?
The short answer is that it is easy to cover with HAPs of this kind, but it doesn’t seem to be easy to partition into them. In order to achieve the partition into non-local HAPs in we helped ourselves to smaller and smaller common differences, and correspondingly larger and larger values of and 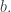 Another problem with that method was that what we are really searching for is a very nice and uniform way of decomposing characters, such as we had in the Roth proof. There the niceness was absolutely essential to getting enough cancellation for the proof to work, but it wasn’t essential to represent the identity — we could allow ourselves a bit extra as long as that extra was positive semidefinite.
Another problem with that method was that what we are really searching for is a very nice and uniform way of decomposing characters, such as we had in the Roth proof. There the niceness was absolutely essential to getting enough cancellation for the proof to work, but it wasn’t essential to represent the identity — we could allow ourselves a bit extra as long as that extra was positive semidefinite.
So let’s not even try to partition Instead, we could simply take our character and use it as a guide to the coefficients that we will give to our HAPs.
The rough idea would be something like this. Given a character and a HAP  we choose a coefficient
we choose a coefficient  in some nice way that makes it large when
in some nice way that makes it large when  is small. It could for example be
is small. It could for example be  for some suitable And then we could use convolution to represent times the restriction of to as a linear combination of sub-HAPs of of length smaller than but not too much smaller, and common difference
for some suitable And then we could use convolution to represent times the restriction of to as a linear combination of sub-HAPs of of length smaller than but not too much smaller, and common difference 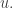
We would know from the lemma above that every would be contained in at least some HAPs with large coefficients, so the restriction of every would in some sense be catered for. I think there would be some that were catered for too much (the precise relationship between those and remains to be worked out, but I think this will be straightforward), but I hope that the whole decomposition can be defined in a nice enough way for the function  that results to be the pointwise product of the original character with a “nice” non-negative real function that’s bounded away from zero. More speculatively, one can hope that the coefficients have small density and that it is possible to subtract a not too small multiple of the identity from the matrix
that results to be the pointwise product of the original character with a “nice” non-negative real function that’s bounded away from zero. More speculatively, one can hope that the coefficients have small density and that it is possible to subtract a not too small multiple of the identity from the matrix  and still be left with something that’s non-negative definite.
and still be left with something that’s non-negative definite.
An attempt to be more precise.
In this final section I want simply to guess at a matrix decomposition that might potentially prove EDP. As I write this sentence I do not know what the result will be, but the two most likely outcomes are that it will fail for some easily identifiable reason or that the calculations will be such that I cannot tell whether it fails or succeeds.
Actually, to make the guess just a little bit more systematic, let’s suppose that for each HAP in the class of HAPs we are considering and for each character we have a coefficient  That is, corresponding to we are taking the function
That is, corresponding to we are taking the function  Given two HAPs and
Given two HAPs and 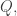 what will the coefficient of be in the decomposition
what will the coefficient of be in the decomposition  ?
?
Expanding this out gives us

If we reverse the order of expectation and summation then we see that the coefficient of is 
Now let us think what we are trying to achieve with the HAPs and 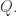 Given a HAP of the form
Given a HAP of the form  we want to use it to contribute to the representation of characters for which is small. If is such a character, then we know that the numbers
we want to use it to contribute to the representation of characters for which is small. If is such a character, then we know that the numbers  vary only slowly. Therefore, if we take short subprogressions of the form
vary only slowly. Therefore, if we take short subprogressions of the form  then on each one will be roughly constant. If we fix a length
then on each one will be roughly constant. If we fix a length 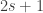 (which may have to be logarithmic in or something like that), then we can represent the restriction of to
(which may have to be logarithmic in or something like that), then we can represent the restriction of to  as a linear combination of the HAPs
as a linear combination of the HAPs  of length
of length  give or take some problems at the two ends.
give or take some problems at the two ends.
Roughly speaking, the coefficient of will be  That is, if we write
That is, if we write  for the HAP
for the HAP  then it is approximately true to say that the restriction of to is
then it is approximately true to say that the restriction of to is 
Now we want to do this only if  is close to 1. So the coefficient of in the decomposition of will in general be
is close to 1. So the coefficient of in the decomposition of will in general be  where
where  is some nice function (which, if the Roth proof is anything to go by, means that it has non-negative and nicely summable Fourier coefficients) that is zero except at points that are close to 1.
is some nice function (which, if the Roth proof is anything to go by, means that it has non-negative and nicely summable Fourier coefficients) that is zero except at points that are close to 1.
What would we expect  to be like? Is there any chance that it is close to a multiple of ?
to be like? Is there any chance that it is close to a multiple of ?
Since is roughly constant on whenever  is non-zero, the value of this function at is roughly the same as it is if we take just singletons — that is, if we set
is non-zero, the value of this function at is roughly the same as it is if we take just singletons — that is, if we set 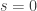 and define to be
and define to be  So the function we get should have a value at that is close to
So the function we get should have a value at that is close to 
In other words, we get something that has the same argument as but that has big modulus at a rational if it so happens that  is close to 1 for unexpectedly many positive integers
is close to 1 for unexpectedly many positive integers  Now this can happen, but I would think that for nearly all and
Now this can happen, but I would think that for nearly all and 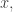 if is not too small, then
if is not too small, then  would be about its expected value of
would be about its expected value of  So I am hoping that we will have some kind of rough proportionality statement.
So I am hoping that we will have some kind of rough proportionality statement.
Going back to the coefficient of in the decomposition, let us take the two HAPs and  We have decided to define
We have decided to define  to be so
to be so  is equal to
is equal to

It is a significant problem that we are forced to consider the case where  in the Roth proof, we did not have to look at products of APs with different common differences. But if we are to have any chance of decomposing into “local” HAPs, then necessarily we must use completely different common differences to deal with rational numbers that are a long way apart in the graph. This is such a significant difference from the Roth proof that it may be a reason for this approach not working at all. However, it does look as though there is plenty of cancellation.
in the Roth proof, we did not have to look at products of APs with different common differences. But if we are to have any chance of decomposing into “local” HAPs, then necessarily we must use completely different common differences to deal with rational numbers that are a long way apart in the graph. This is such a significant difference from the Roth proof that it may be a reason for this approach not working at all. However, it does look as though there is plenty of cancellation.
I think the expression we would be trying to bound is

which is perhaps better thought of as

And our main strength would be that we would be free to choose as it suited us. There would be two challenges: to obtain a good bound on the above expression, and to prove that we could subtract a reasonable-sized multiple of the identity and still be left with a positive semi-definite matrix.
I think the above counts as a calculation for which I cannot tell whether it fails or succeeds. But I hope it may be enough to provoke a few thoughts.
This entry was posted on July 18, 2010 at 10:53 pm and is filed under polymath5. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

July 19, 2010 at 6:55 pm |
[…] By kristalcantwell There is a new thread for Polymath5 here. The main theme of the post is that the problem may be closed to being […]
July 20, 2010 at 10:01 am |
I have realized that the Roth proof can be simplified, and that the simplification has an analogue for rationals and HAPs that makes it much easier to think about.
In the Roth proof, a (small) technical complication came from the need to choose non-negative coefficients The three criteria that lay behind the choice of these coefficients were as follows.
The three criteria that lay behind the choice of these coefficients were as follows.
(i) For each the function
the function  should be “nice”, meaning that it has non-negative real Fourier coefficients that sum to 1.
should be “nice”, meaning that it has non-negative real Fourier coefficients that sum to 1.
(ii) should be non-zero only if
should be non-zero only if  is small.
is small.
(iii) For each there should exist
there should exist  such that
such that 
I realized last night (and checked this morning) that we can dispense with (ii). All we actually use in the proof is (i) and (iii). Intuitively, (ii) feels necessary, because every time is large, it is contributing to the sum of the coefficients that we are trying to make small. However, that intuitive argument is wrong: it is (iii) that controls the cancellation in the coefficients, and as long as they cancel, we don’t care how big the sum is that cancels.
is large, it is contributing to the sum of the coefficients that we are trying to make small. However, that intuitive argument is wrong: it is (iii) that controls the cancellation in the coefficients, and as long as they cancel, we don’t care how big the sum is that cancels.
The upshot of all that is that we can make the sort of simplification that usually sets alarm bells ringing: it is enough to take for every
for every  and
and 
Let me say what happens to the Roth write-up if you do that. Up to the end of page 8, the only change needed is to cross out wherever it appears. Also, Lemma 3.1 is no longer needed. Then at the top of page 9, the calculations now look like this. (Recall that
wherever it appears. Also, Lemma 3.1 is no longer needed. Then at the top of page 9, the calculations now look like this. (Recall that  is being summed from 1 to
is being summed from 1 to  )
)
In my next comment, I’ll say what the picture now looks like for rationals and HAPs.
July 20, 2010 at 10:49 am |
At the end of the post, I wrote that the expression we are trying to bound is
In this argument, was playing the role of
was playing the role of  So let’s set it to 1. Then we get
So let’s set it to 1. Then we get
But so this gives us
so this gives us  (That is because for each
(That is because for each  there is a unique
there is a unique  such that
such that  at least if we ignore edge effects, as we are allowed to do.)
at least if we ignore edge effects, as we are allowed to do.)
This looks a bit disastrous, given that we were hoping for a sum of coefficients that was small compared with However, I am not quite sure that it is disastrous. The first piece of potentially good news is that the decomposition we create could well be of a decent-sized multiple of the identity. Let me try to explain why.
However, I am not quite sure that it is disastrous. The first piece of potentially good news is that the decomposition we create could well be of a decent-sized multiple of the identity. Let me try to explain why.
We are in some sense approximating each character by the function
by the function
Setting to be identically 1, we get a function whose value at
to be identically 1, we get a function whose value at  is … actually, for technical reasons this doesn’t work — we need to do a double convolution as in the Roth proof. So let me try to reason informally. We are interested in the value of this function at
is … actually, for technical reasons this doesn’t work — we need to do a double convolution as in the Roth proof. So let me try to reason informally. We are interested in the value of this function at  The only
The only  for which
for which  belongs to some
belongs to some  are
are  If
If  is not within about
is not within about 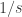 of
of  then the sum of
then the sum of  over all
over all  such that
such that  is small. Otherwise, it is about
is small. Otherwise, it is about 
We would ordinarily expect to be within
to be within 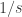 of 1 about
of 1 about 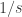 of the time. So we might expect to get a contribution of
of the time. So we might expect to get a contribution of  for about
for about  values of
values of 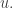 And this is them multiplied by
And this is them multiplied by  so the total contribution at
so the total contribution at  ought to be around $m\chi(x)/s,$ up to a constant. But that means that we ought to be approximating
ought to be around $m\chi(x)/s,$ up to a constant. But that means that we ought to be approximating  times the identity rather than the identity itself. Therefore, we want our sum of coefficients to be small compared with
times the identity rather than the identity itself. Therefore, we want our sum of coefficients to be small compared with 
Tantalizingly, what we actually have is equal to this, up to a constant.
What I hope this means is that any observation that gives even a tiny improvement to what is going on will solve EDP.
But what possible room is there for improvement? The one place I can see is this: I’ve been talking about representing the identity — indeed, the fact that one could talk about the identity was the whole reason for getting excited about the rationals — but we still have considerable flexibility in our choice of matrix. Indeed, it seems that we have not in fact represented the identity, and my impression is that what we have actually done is represent something slightly “larger” than the identity (because for some and some
and some  we have “too many”
we have “too many”  such that
such that  is close to 1, but I think we never have “too few”). Can we somehow squeeze out just the tiniest bit more from the argument?
is close to 1, but I think we never have “too few”). Can we somehow squeeze out just the tiniest bit more from the argument?
I have another idea for getting an improvement, but it is a bit harder to explain. I’ll save it for another comment.
July 20, 2010 at 11:58 am |
I think I have an explanation for why the Roth argument gives an improvement on the trivial bound, whereas the argument for HAPs and the rationals so far appears not to. If this explanation is correct, then it suggests a way of trying to improve the HAPs argument.
In the Roth argument, there are two things one might think of doing in order to approximate the rank-1 matrix where
where  is a character on
is a character on  At our disposal is the fact that for each
At our disposal is the fact that for each  the function
the function  is a non-negative real multiple of
is a non-negative real multiple of  and it is a linear combination of HAPs. Moreover, for some values of
and it is a linear combination of HAPs. Moreover, for some values of  it is quite a large multiple. So either we could take the function
it is quite a large multiple. So either we could take the function  (which will be a non-negative multiple of
(which will be a non-negative multiple of  ) and then tensor it with itself, or we could look at the function
) and then tensor it with itself, or we could look at the function  It turns out to be very important to do the latter. The reason it helps is that in the decomposition we only ever have products
It turns out to be very important to do the latter. The reason it helps is that in the decomposition we only ever have products 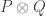 of APs with the same common difference.
of APs with the same common difference.
I haven’t checked, but I’m pretty sure that if we went down the first route, so that we would have to consider arbitrary pairs of common differences up to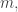 then we would lose a factor
then we would lose a factor  in the sum of the absolute values of the coefficients. This factor of
in the sum of the absolute values of the coefficients. This factor of  is precisely what gives us a non-trivial bound at the end of the proof.
is precisely what gives us a non-trivial bound at the end of the proof.
Now let’s switch to HAPs and the rationals. Here it is essential to consider products of HAPs with different common differences, or at least it is essential if we want a “local” argument. The reason is that if and
and  are far apart in the graph, then there just isn’t a common difference
are far apart in the graph, then there just isn’t a common difference  such that both
such that both  and
and  are contained in local HAPs of common difference
are contained in local HAPs of common difference 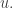 The result of this is that in the expression near the beginning of the previous comment, we ended up having to sum over all pairs
The result of this is that in the expression near the beginning of the previous comment, we ended up having to sum over all pairs 
But what if we could somehow get away with looking only at pairs? This is still a slightly vague thought, so let me say what I can and then stop. In the Roth case, we exploit the fact that if
pairs? This is still a slightly vague thought, so let me say what I can and then stop. In the Roth case, we exploit the fact that if  is roughly constant on a progression of common difference
is roughly constant on a progression of common difference 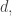 then it is roughly constant on any translate of that progression. That allows us to restrict attention to pairs of progressions with the same common difference.
then it is roughly constant on any translate of that progression. That allows us to restrict attention to pairs of progressions with the same common difference.
What I would like to have is something similar for HAPs and characters. It seems to be far too much to hope that if is roughly constant on a HAP that contains
is roughly constant on a HAP that contains  then we can deduce that it is roughly constant on some other HAP that contains
then we can deduce that it is roughly constant on some other HAP that contains  However, perhaps we can at least find a class of HAPs of size
However, perhaps we can at least find a class of HAPs of size  and say that on at least one HAP in that class
and say that on at least one HAP in that class  must be roughly constant, or perhaps something weaker such as that that is true for almost all
must be roughly constant, or perhaps something weaker such as that that is true for almost all 
The trouble is that if and
and  are far apart in the graph, then it feels as though we don’t have any correlation at all. So I’m not altogether sure what it is that I am trying to say here. But the general point remains that we seem to have a non-trivial decomposition of something like the identity into HAPs, and if we can make it just the teeniest bit more efficient then we should be in extremely good shape.
are far apart in the graph, then it feels as though we don’t have any correlation at all. So I’m not altogether sure what it is that I am trying to say here. But the general point remains that we seem to have a non-trivial decomposition of something like the identity into HAPs, and if we can make it just the teeniest bit more efficient then we should be in extremely good shape.
July 20, 2010 at 8:26 pm |
“What I would like to have is something similar for HAPs and characters. It seems to be far too much to hope that if \chi is roughly constant on a HAP that contains x then we can deduce that it is roughly constant on some other HAP that contains y. ”
Could \chi be chosen so it satisfies \chi (x)\chi (y)=\chi (xy)? Then the above problem looks like it could be solved by multiplying by y/x.
July 20, 2010 at 9:45 pm
That’s certainly an interesting thought — to use characters on the multiplicative group of non-negative rationals instead. It wouldn’t instantly solve the problem, because writing a multiplicative character in terms of APs (let alone HAPs) is likely to be much more challenging than decomposing an additive character. But it may be that there is some way of doing it, and then the fact that the set of HAPs of length naturally gives rise to a multiplicative structure would fit in well with the decomposition.
naturally gives rise to a multiplicative structure would fit in well with the decomposition.
In a way, this illustrates the fundamental difficulty of EDP: that it mixes multiplication and addition in a strange way. Somehow we have to get from one to the other, and what you are suggesting could be thought of as trying to deal with the difficulty in a different place. Definitely worth thinking about.
July 20, 2010 at 10:17 pm
Are there any theorems saying that a -valued function on the positive integers must have large discrepancy either along HAPs or geometric progressions? That is certainly true for multiplicative functions.
-valued function on the positive integers must have large discrepancy either along HAPs or geometric progressions? That is certainly true for multiplicative functions.
Given that the multiplicative and additive groups are connected by the log-mapping we know what the characters of the multiplicative group are. But using that right seems to require quite a bit of untangling.
July 21, 2010 at 11:08 am
I’ve thought about Kristall’s suggestion a bit more and I now think that it cannot work. Or perhaps it is more accurate to say that it can work if and only if we manage to solve some problems that we are already stuck on.
Let me try to explain. The characters on the multiplicative group of are just the completely multiplicative functions from
are just the completely multiplicative functions from  to
to  (each of which is determined by its behaviour on
(each of which is determined by its behaviour on  ). To represent a completely multiplicative function
). To represent a completely multiplicative function  as a linear combination of HAPs, we would need at least some kind of correlation between
as a linear combination of HAPs, we would need at least some kind of correlation between  and some HAPs. But that requires one to solve EDP (positively) for completely multiplicative functions.
and some HAPs. But that requires one to solve EDP (positively) for completely multiplicative functions.
That does, however, suggest that if we knew a sufficiently strong statement about completely multiplicative functions, then we could use the Roth method to deduce EDP for general functions. It seems that for this to work we would need the partial sums of a completely multiplicative complex-valued function to be large on average. Does this ring any bells anyone? It seems that we are being inexorably drawn to Terry’s observation that EDP follows from a suitable statement about completely multiplicative functions taking values in My guess is that if we pushed this idea, we would end up with a proof that is essentially the same as the argument Terry gave.
My guess is that if we pushed this idea, we would end up with a proof that is essentially the same as the argument Terry gave.
July 23, 2010 at 9:22 pm
One idea I have is to assume the character function is completely multiplicative use that to get a result that implies that any completely multiplicative function is unbounded and then prove the result that any bounded EDP implies the existence of a bounded completely completely multiplicative function and thus get the desired result. I don’t know if assuming the character function is completely multiplicative improves the situation.
July 20, 2010 at 10:47 pm |
I had a thought in the negative direction concerning this approach — not negative enough to kill the approach but certainly negative enough to place quite strict limits on how well it could work.
The thought is that whereas Roth’s theorem gives you an AP of length on which the discrepancy is
on which the discrepancy is  we know that we cannot achieve that for HAPs and functions on the rationals. The reason is that we have our old friends, the completely multiplicative functions
we know that we cannot achieve that for HAPs and functions on the rationals. The reason is that we have our old friends, the completely multiplicative functions 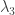 and
and  which extend easily to the rationals. As a reminder of how this is done, let me define the simpler of the two (I can’t remember whether this was
which extend easily to the rationals. As a reminder of how this is done, let me define the simpler of the two (I can’t remember whether this was  or
or 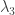 ). Given a rational $p/q,$ we can write it in the form
). Given a rational $p/q,$ we can write it in the form  where
where  and neither
and neither  nor
nor  is divisible by 3. We then define
is divisible by 3. We then define  to be 1 if
to be 1 if  mod 3 and -1 if
mod 3 and -1 if  mod 3.
mod 3.
This function is completely multiplicative, and as we have worked out many times, the sum along any HAP of length is at most
is at most  or thereabouts.
or thereabouts.
It follows that the best improvement we can hope for over the trivial bound is logarithmic in the lengths of the HAPs that are used in the decomposition.
July 21, 2010 at 9:49 am |
Formally, in the Roth case we get the group acting on by considering
by considering  with
with  being the rank one projections from the ROI approach and
being the rank one projections from the ROI approach and 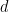 the period (the common difference of the AP). This is indeed a group homomorphism since
the period (the common difference of the AP). This is indeed a group homomorphism since  by orthogonality and
by orthogonality and  . Thus we have represented a (periodic) group acting on
. Thus we have represented a (periodic) group acting on  (the domain of the Fourier coefficients) as a sum of rank one operators. The same holds true for the corresponding Fourier series, at least if one interprets the representation correctly. Is it just a gut feeling or does ROI more than it claims? We represent the whole group and not just identity. If this is true we might get some information if we try to construct a group from
(the domain of the Fourier coefficients) as a sum of rank one operators. The same holds true for the corresponding Fourier series, at least if one interprets the representation correctly. Is it just a gut feeling or does ROI more than it claims? We represent the whole group and not just identity. If this is true we might get some information if we try to construct a group from  . The following guess
. The following guess  with
with 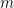 as in your introduction and
as in your introduction and 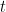 from
from  cannot be correct, since we do not have an m-periodic action. At least I do not see it.
cannot be correct, since we do not have an m-periodic action. At least I do not see it.
July 22, 2010 at 10:54 am |
I hoped I could have a precise thought here, but at the moment it’s a bit vague. If it is correct to say that we want to improve on a “trivial” bound (actually, not so trivial but that’s another story) and that there is no hope of improving on it by more than a logarithmic factor, then searching for any place where logs might come in seems to be a good idea. And there is one that I can think of. But at the moment I don’t see how to work it in.
The little observation is this. Suppose you have a rational and a character
and a character  and you know, for some integer
and you know, for some integer  that
that  is close to 1. What can you say about
is close to 1. What can you say about  ? You can’t say that it is close to 1, but you can say that it is close to 1 with probability 1/2 (if
? You can’t say that it is close to 1, but you can say that it is close to 1 with probability 1/2 (if  is chosen randomly), since it has to be close to a square root of 1. More generally,
is chosen randomly), since it has to be close to a square root of 1. More generally,  is close to 1 with probability
is close to 1 with probability  So the expected number of
So the expected number of  such that
such that  is close to 1 is about
is close to 1 is about 
The problem we were having earlier was that whereas we had “long-range correlations” in the Roth proof (if is roughly constant on
is roughly constant on  then it is roughly constant on all translates of
then it is roughly constant on all translates of  ) there seemed to be nothing comparable here. But perhaps the observation above is saying that there are some tiny correlations after all, and perhaps they can be exploited to get a correspondingly (and necessarily) tiny improvement on the trivial bound.
) there seemed to be nothing comparable here. But perhaps the observation above is saying that there are some tiny correlations after all, and perhaps they can be exploited to get a correspondingly (and necessarily) tiny improvement on the trivial bound.
July 22, 2010 at 12:14 pm |
Here’s a different but related thought. What I talked about in the previous comment is not really “long-range” correlations after all, since we are talking about correlations between values of at points that are close to each other in the graph. (And it is fairly easy to see that those are the only pairwise correlations that exist, so to make use of them one would perhaps have to consider correlations between values at more points.)
at points that are close to each other in the graph. (And it is fairly easy to see that those are the only pairwise correlations that exist, so to make use of them one would perhaps have to consider correlations between values at more points.)
But if we were dealing with completely multiplicative functions, then the functions themselves would have long-range correlations all over the place. So couldn’t we get rid of our difficulties by looking at the multiplicative case? And since that is morally equivalent to the whole problem (in the sense that any proof is likely to give not just a single HAP with big discrepancy, but unbounded discrepancy on average, and that would imply EDP), isn’t it worth thinking rather hard about that case, and in particular about whether it is possible to get the ROI (on the rationals) approach to work for it?
The question is, how would one exploit the fact that we only cared about completely multiplicative functions? I think the answer would be something like this. When we express the identity as we do so because we need a matrix
we do so because we need a matrix  for which we can argue that
for which we can argue that  is large for every
is large for every  function
function 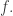 But what if we just wanted a statement like that for completely multiplicative functions
But what if we just wanted a statement like that for completely multiplicative functions  ? It seems that we could then afford to throw away a lot of (additive) characters
? It seems that we could then afford to throw away a lot of (additive) characters  because we would know that they couldn’t correlate with a completely multiplicative function.
because we would know that they couldn’t correlate with a completely multiplicative function.
Let me be a bit speculative. Suppose we identify a class of characters
of characters  that have “multiplicative structure” and that we can show that any
that have “multiplicative structure” and that we can show that any  that does not belong to
that does not belong to  has only a tiny correlation with any completely multiplicative function. Then the matrix
has only a tiny correlation with any completely multiplicative function. Then the matrix  would appear to be almost indistinguishable from the identity as long as one applied it only to completely multiplicative functions.
would appear to be almost indistinguishable from the identity as long as one applied it only to completely multiplicative functions.
Now we do have some examples of characters that correlate with completely multiplicative functions. For instance, the …
… actually, I’m not sure I like what I was about to write there. The example I had in mind ( and the function $x\mapsto e(x/3)$) is too much of an integers example as opposed to a rationals example. Also, I’m a bit worried that when we express a function as an integral combination of characters, we may have to use lots of characters that don’t correlate well with the function (just as the point
and the function $x\mapsto e(x/3)$) is too much of an integers example as opposed to a rationals example. Also, I’m a bit worried that when we express a function as an integral combination of characters, we may have to use lots of characters that don’t correlate well with the function (just as the point  has norm 1 despite having only small correlation with any vector from the standard basis). It seems that we would have to show that the correlation between a non-special additive character and a completely multiplicative function was not just small but very small.
has norm 1 despite having only small correlation with any vector from the standard basis). It seems that we would have to show that the correlation between a non-special additive character and a completely multiplicative function was not just small but very small.
Suppose we could somehow do that. The hope would be that special additive characters had long-range correlations for HAPs — not as strong as the perfect correlations you get with completely multiplicative functions, but good enough to be exploited.
Here’s a very brief thought about what would count as “very small” correlation. Suppose we have a function that takes values of modulus 1 everywhere on
that takes values of modulus 1 everywhere on  Then its
Then its 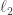 norm (on that set) is
norm (on that set) is  So if we are representing
So if we are representing  as
as  then we can afford to disregard all
then we can afford to disregard all  for which
for which  is substantially smaller than
is substantially smaller than 
So a preliminary question is this. Suppose you have an additive character on the rationals and you know that its correlation with some completely multiplicative function is at least
on the rationals and you know that its correlation with some completely multiplicative function is at least  on the set
on the set  . What can you say about
. What can you say about  ? I have an unpleasant feeling that the answer may be nothing at all: if you look at the mean square over all completely multiplicative functions, then I think you will get
? I have an unpleasant feeling that the answer may be nothing at all: if you look at the mean square over all completely multiplicative functions, then I think you will get  (by representing the identity in terms of multiplicative characters).
(by representing the identity in terms of multiplicative characters).
I’m not sure this line of thought is going anywhere.
July 23, 2010 at 7:52 am |
[…] finished and with bearable temperatures returning I plan to spend some free time to think about the Erdös Discrepancy Conjecture. Is it wise to post this plan? I think so. It puts some pressure on me and this is […]
August 4, 2010 at 2:55 pm |
Can we learn anything useful by considering EDP for the cyclic group instead of
instead of  ?
?
For , define the (zero-based) discrepancy
, define the (zero-based) discrepancy
and let
A couple of observations:
(1) If , then
, then  is a power of 2.
is a power of 2.
(Suppose is not a power of 2. Write
is not a power of 2. Write  where
where 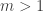 is odd. Then
is odd. Then  has an odd number of terms, so is non-zero, so the discrepancy with respect to the difference
has an odd number of terms, so is non-zero, so the discrepancy with respect to the difference  is unbounded.)
is unbounded.)
(2) .
.
To show this, first define the function by
by  ,
,  ,
,  , and
, and  (for
(for 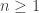 ). Then define
). Then define  by
by  if
if  is even, and
is even, and  if
if  is odd. Then
is odd. Then  . This follows from the observations: that
. This follows from the observations: that  is completely multiplicative (on the positive integers); that
is completely multiplicative (on the positive integers); that  is equal to
is equal to  except when
except when 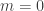 (when it equals
(when it equals  ) or
) or  (when it equals
(when it equals  ); and that
); and that  .
.
It would be interesting to know whether this bound is best possible. In other words, is it true that for every function ,
,  ? If it is true, this seems like a simple enough problem to be tractable, and I wonder if the proof could shed some light on EDP for
? If it is true, this seems like a simple enough problem to be tractable, and I wonder if the proof could shed some light on EDP for  when we let
when we let 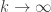 .
.
In particular, I wonder if a ‘representation of the diagonal’ proof might work over , which is isomorphic to its own character group. I haven’t yet thought about this in any detail.
, which is isomorphic to its own character group. I haven’t yet thought about this in any detail.
August 12, 2010 at 9:44 am
Alec, I find this thought interesting (despite taking ages to respond to it). But at the moment I’m being slow to understand your point (1). Would it be possible to make both the statement and its proof more precise?
A slight variant of what you suggest could also fit in rather well with what I was trying to do over while avoiding some of the technical problems. That would be to work in
while avoiding some of the technical problems. That would be to work in 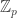 for some very large prime
for some very large prime 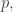 but to restrict the lengths of the HAPs to at most
but to restrict the lengths of the HAPs to at most 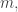 for some much smaller, but unbounded,
for some much smaller, but unbounded,  Basically,
Basically,  would be thought of as a fixed, but large, constant, while
would be thought of as a fixed, but large, constant, while  tended to infinity. I don’t instantly see how a lower bound for this problem would give a lower bound for EDP, but the converse clearly holds, and it’s hard to believe that a non-trivial lower bound for this problem wouldn’t shed light on EDP.
tended to infinity. I don’t instantly see how a lower bound for this problem would give a lower bound for EDP, but the converse clearly holds, and it’s hard to believe that a non-trivial lower bound for this problem wouldn’t shed light on EDP.
August 12, 2010 at 12:35 pm
Here’s another way to think about it which may be clearer. Consider functions that are periodic with period
that are periodic with period  . Obviously the discrepancy of such a function with respect to HAPs of common difference
. Obviously the discrepancy of such a function with respect to HAPs of common difference  is unbounded if
is unbounded if  is a multiple of
is a multiple of  . But we can ask whether it is possible for the discrepancy to be bounded with respect to all other
. But we can ask whether it is possible for the discrepancy to be bounded with respect to all other  .
.
This is only possible if is a power of 2. For if
is a power of 2. For if  where
where 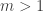 is odd, then
is odd, then  has unbounded discrepancy with respect to HAPs with common difference
has unbounded discrepancy with respect to HAPs with common difference  (since
(since  , which tends to
, which tends to 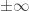 as
as 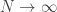 because the factored-out sum is the sum of an odd number of
because the factored-out sum is the sum of an odd number of  terms and so non-zero).
terms and so non-zero).
The second observation is that it is possible when is a power of 2 — and that we can get the discrepancy as low as
is a power of 2 — and that we can get the discrepancy as low as  if
if  , by simply repeating the first
, by simply repeating the first  terms of the function
terms of the function 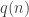 (if
(if  is even) or of the function
is even) or of the function  (if
(if  is odd).
is odd).
It may be more interesting to consider functions . Then of course the first observation is no longer valid.
. Then of course the first observation is no longer valid.
August 12, 2010 at 12:48 pm
I see. It didn’t occur to me that you were allowing your HAPs to have length greater than so that they could actually repeat themselves. It seems to me that asking exactly the same question but restricting the length of the HAP to be at most
so that they could actually repeat themselves. It seems to me that asking exactly the same question but restricting the length of the HAP to be at most  leads to a more natural question.
leads to a more natural question.
Actually, I take that back. In we can express any AP with common difference coprime to
we can express any AP with common difference coprime to  as a difference of two HAPs, so if e.g.
as a difference of two HAPs, so if e.g.  is prime then the question becomes equivalent to Roth’s theorem.
is prime then the question becomes equivalent to Roth’s theorem.
August 12, 2010 at 9:34 am |
I’d like to make it clear that even though this project is moving at a snail’s pace compared with how it was moving before, I do not regard it as closed. I am not thinking about it continuously, but I do intend to return to it from time to time and I hope others will too. I’m writing this now because I had a little session with the problem a couple of hours ago and I’d like to report on my (far from conclusive) thoughts.
A quick reminder of what I was trying to do in some of the comments above. I wanted to find a representation-of-diagonal approach, and had noted an idea that potentially made the task much easier. That idea was that working over the rationals could eliminate one of the main difficulties of the approach — understanding what the diagonal matrix should be. The point is that if one works with the integers up to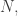 then there is a hugely important distinction between smooth integers and non-smooth ones. But in
then there is a hugely important distinction between smooth integers and non-smooth ones. But in  all numbers are equal, so it becomes reasonable to search for a representation of the \textit{identity}.
all numbers are equal, so it becomes reasonable to search for a representation of the \textit{identity}.
I was trying to do this by using what we had learned from the representation-of-identity proof of Roth’s theorem about AP-discrepancy. The basic idea there is to start by decomposing the identity using characters and then decomposing the characters. This seemed reasonably promising, but eventually I got a bit stuck. But it now occurs to me that we could attack the problem from the other end. We could ask ourselves a question of the following kind: if the approach works, what properties will the resulting decomposition have, and does there actually exist a decomposition with those properties?
The real question there is the second one. We could use the previous ideas as a guide to tell us, non-rigorously, what sort of decomposition we might expect, and then we could search directly for a decomposition that is much less general than an arbitrary decomposition, or else try to prove that the much more specific decomposition cannot exist (which would then inform all subsequent efforts to find a decomposition).
In order to keep my comments bite-sized, I’ll stop this one here, and make a more technical comment on this theme separately.
August 12, 2010 at 11:07 am |
Right, here is a more technical expression of what I was saying in my previous comment.
Let’s suppose we want to write the identity on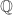 as a linear combination of products of HAPs. What I want to think about here is whether there is some “beautiful formula” that “magically works”. I’ll ignore, for the moment, any concerns about the fact that
as a linear combination of products of HAPs. What I want to think about here is whether there is some “beautiful formula” that “magically works”. I’ll ignore, for the moment, any concerns about the fact that 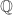 is infinite and that certain sums might not converge.
is infinite and that certain sums might not converge.
First of all, here is a very quick argument that we cannot get away with HAPs that are all of the form for some fixed
for some fixed  To see this, note that we could find a multiplicative function that happens to have a small partial sum at
To see this, note that we could find a multiplicative function that happens to have a small partial sum at 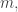 and it will not correlate with any such HAP. But a representation-of-diagonals proof shows that every
and it will not correlate with any such HAP. But a representation-of-diagonals proof shows that every  function correlates with an HAP that is used in the decomposition.
function correlates with an HAP that is used in the decomposition.
The next simplest thing one could hope for is to use HAPs that are of length bounded above by Since one can subtract one HAP from another, it seems nice to allow HAPs of the form
Since one can subtract one HAP from another, it seems nice to allow HAPs of the form  where both
where both  and
and  are at most
are at most  However, choosing coefficients that depend on
However, choosing coefficients that depend on 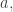
 and
and  seems nasty.
seems nasty.
It can be made a bit nicer if we consider functions of the form which I define to take
which I define to take  to
to  if
if  and to 0 otherwise. That is,
and to 0 otherwise. That is,  is the pointwise product of the HAP
is the pointwise product of the HAP 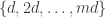 with a trigonometric function. If we do this, it is important to restrict
with a trigonometric function. If we do this, it is important to restrict  in such a way that this function can be efficiently decomposed into HAPs. A sufficient condition for this is that
in such a way that this function can be efficiently decomposed into HAPs. A sufficient condition for this is that  should be bounded above by a constant that tends to zero (so that
should be bounded above by a constant that tends to zero (so that  is approximately constant on intervals of unbounded length).
is approximately constant on intervals of unbounded length).
So let’s ask the following question. Can we find a decomposition of the form
The value of the right-hand side at then works out to be
then works out to be
where is the set of all
is the set of all  such that both
such that both  and
and  are of the form
are of the form 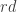 for some
for some  So we would like this to be 1 if
So we would like this to be 1 if 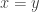 and 0 otherwise.
and 0 otherwise.
I’ll say more about this later, but have to go now.
August 12, 2010 at 3:10 pm |
I haven’t yet explained the main point of the calculations in the previous comment. They are that if we are searching for a pretty formula, then it makes sense to give some symmetry to the coefficients And the most obvious way of doing that is to make them independent of
And the most obvious way of doing that is to make them independent of  That is, we could search for a decomposition of the more specific kind
That is, we could search for a decomposition of the more specific kind
Also, we might, in order to give ourselves a bit more flexibility, the opportunity for smooth cutoffs, etc., like to replace the sum over by a sum with weights. That is, we might like to consider an expression of the form
by a sum with weights. That is, we might like to consider an expression of the form
Again, if we are searching for coefficients that are independent of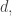 we might like to place restrictions on
we might like to place restrictions on 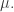 Note that we are already hoping that
Note that we are already hoping that  will be concentrated in the set of
will be concentrated in the set of  such that
such that  , which is the set of
, which is the set of  such that
such that  and
and  are small multiples of
are small multiples of  So it feels natural to make
So it feels natural to make  a function of
a function of  and
and  A nice aspect of that is that the integral is also a function of
A nice aspect of that is that the integral is also a function of  and
and 
If we do this, then I think the entire expression depends on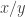 only. Let me just check that. Yes, it’s clear, since if we multiply
only. Let me just check that. Yes, it’s clear, since if we multiply  and
and  by
by 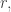 we can just substitute
we can just substitute 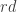 for
for  and end up with the original expression.
and end up with the original expression.
I now need to do a little bit of paper calculation in order to work out a nice way of expressing the matrix as a function of Then one can think about how to make that function 1 at 1 and 0 everywhere else.
Then one can think about how to make that function 1 at 1 and 0 everywhere else.