In my previous post, I suggested several possible Polymath projects. One of them, which initially seemed to be the favourite (and was my own favourite) was to have a look at an idea I had had for getting round the Razborov-Rudich obstacle to proving lower bounds in computational complexity. (This is closely related to the P versus NP problem, though my idea did not obviously apply to that problem itself.) However, now I am fairly sure I have understood why it cannot work: somehow, even if you come up with an idea for a proof that is not directly ruled out by their result, you find that slightly more complicated arguments, based on their idea, do eventually show that it doesn’t work.
While thinking about my approach, I wrote what was intended to be a series of five initial posts for the Polymath project if it happened. I thought I would experiment, so instead of explaining the basic concepts in the usual way I wrote a dialogue, which I hoped would be easier to read. It is between three characters, who are denoted by smileys (or is that smilies? no, perhaps not). The main character, :), is a mathematical optimist, continually becoming enthusiastic about ideas that have not been fully thought through. The next character, 8) , is much more sceptical, and also knows more about computational complexity (a lot less than an expert in the area, but enough to merit a “cool” smiley). Finally, 😐 is a neutral observer who occasionally asks for fuller explanations when 🙂 or 8) seem to be omitting them, and sometimes makes easy but useful mathematical observations.
To some extent these characters, particularly the first two, represent different sides of me as I think about the problem. However, I do not always agree with what they say (sometimes this is obvious, since they do not always agree with each other), and I sometimes allow them to get things wrong, or to think that they have had an idea when in fact that idea is already known. For example, towards the end of this first part of the conversation, 🙂 has the idea of applying the insights of Razborov and Rudich to other computational models. Not surprisingly, 🙂 was not the first to think of doing that, as an internet search later revealed.
Since I wrote the post about Polymath projects, the conversation has expanded and is now in seven parts of about 5000 words each. Be warned in advance that pretty well every idea that 🙂 has is eventually doomed to fail. But I hope that non-experts will find the failure instructive even if experts just find it wearily familiar.
I also hope that some of the later parts of the conversation might lead to fruitful exchanges of comments even if they don’t lead to a proper Polymath research project. For instance, at least at the time of writing, I don’t have completely satisfactory general explanations for why some of :)’s approaches fail. And some of the heuristic arguments (of which there are many) presented here are open to criticism. (Another warning: some of the early arguments are definitely wrong, even when the three characters appear to take them seriously, and their wrongness is pointed out only quite a bit later. It may be a little unconventional to explain mathematics by putting forward incorrect ideas and correcting them only after their consequences have been explored in detail, but there are plenty of conventional accounts of computational complexity for those who want them.)
For these kinds of reasons, it seems to me that I might as well post the dialogue rather than letting it go to waste. It’s even conceivable that somebody will be prompted by the ideas here to have better ideas, in which case maybe something serious could come out of it after all. I plan to post the seven parts (or more if I continue to add to them) of the dialogue at a rate of about one a week, to keep this blog ticking over until I am ready to start a Polymath project on something else. The first part is very much an introduction.
**************************************************************
🙂 Guess what I’ve been thinking about recently?
8) The Riemann hypothesis?
🙂 Very funny. But actually you’re not far off. I’ve been wondering about the P versus NP problem.
8) Wonderful. Join the club. But I should warn you that it drives people mad.
🙂 I can believe that, as it’s driving me a bit mad actually.
8) Well, it’s possible that I may be able to put you out of your misery by showing that whatever you are trying cannot work. That would replace madness by mere disappointment.
🙂 I suppose if I end up sadder but wiser, then at least I’m wiser.
8) Wow, you’re definitely a half-full type of person aren’t you?
🙂 I am actually, not just in real life but in mathematical research as well.
😐 Would someone mind explaining what the P versus NP problem is?
🙂 Oh, sorry. Well, P is the class of computational problems that can be solved in polynomial time. For example, multiplying two 



If you want to know more, I suggest looking at the Wikipedia article on the topic, which is OK. I don’t want to say too much more myself, other than that it is widely considered to be one of the most important problems in mathematics. That’s because what I’ve really been thinking about is a purely mathematical problem that is “morally equivalent” to the P versus NP problem.
8) Which formulation are you talking about?
🙂 I’m talking about finding superpolynomial lower bounds for the circuit complexity of an NP problem. In particular, I’m talking about the following formulation. Let’s define a Boolean function to be a function from 
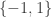

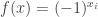

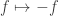



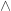


A straight-line computation of a Boolean function 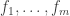

It is not too hard to show that if there exists a Boolean function 


8) Sounds OK to me.
😐 You may know all about that, but I find it an interesting formulation, since it makes no mention of non-mathematical concepts such as “algorithm”. Somehow, the problem feels more approachable when you put it like this.
8) It does until you try to solve the reformulated problem …
🙂 Well, let me tell you my idea for solving the reformulated problem. It’s an obvious idea really.
8) I’m suspicious already. If it’s an obvious idea, then it’s almost certainly known not to work.
🙂 Well can I try it out anyway? The thought was that one could try to define a function 

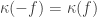

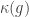
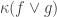

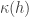

8) Have you actually got any candidates for such a function
🙂 Well, I haven’t yet thought of one that works, but the interesting thing is that my attempts so far have failed for two very different reasons.
8) This sounds familiar, but let’s hear what these attempts were.
🙂 Well, a thought that occurred to me was that maybe functions of low circuit complexity have some kind of structural property that shows that they are not truly random, whereas some function in NP might lack that property. So one would like to have some measure of pseudorandomness and show that the measure was small for functions of low circuit complexity but large for at least one function in NP. In additive combinatorics, there are many measures of pseudorandomness, but let me mention just one: we could define
But this doesn’t work. By Parseval’s identity, the 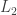
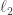

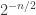
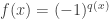
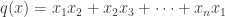
8) You said you ran into another difficulty. Can you explain what that was?
🙂 Well, many of my attempts failed for similar reasons to the attempt above. So then I started to wonder whether there existed a function 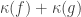
We can say a little bit about this function. Suppose that
8) Can I interrupt at this point?
🙂 OK.
8) You are defining something very similar to what is known as a formal complexity measure, and the correct version of what you are about to say is that
😐 What is formula-size complexity?
8) If I’m forced to explain it in :)’s terminology, then I define it as the number of basic functions (with multiplicity) you need in a formula that builds 
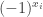
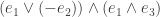
Anyhow, the formula-size complexity of a function can be bigger than its circuit complexity, and probably it can be much bigger. Therefore, using a formal complexity measure is not that great as a method for proving that P
🙂 Oh no. That’s stupid of me. But it’s still an interesting problem to prove lower bounds for formula-size complexity isn’t it?
8) Very much so. The best known lower bound for the formula-size complexity of a function in NP is 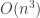
🙂 Yes, but not a million-dollar result.
8) I wouldn’t worry about that if I were you. Isn’t lasting fame in the theoretical computer science community good enough for you?
🙂 Er … well, it would be good, but if I could have a million dollars as well then I wouldn’t say no. But actually it’s not really that. It’s that showing that P
8) That’s true I suppose. But it’s still quite an easy problem to explain to non-specialists. Can we stop talking about this and get back to the mathematics?
🙂 All right, I’ll talk about formula size for now, and leave for later the question of whether any of this would apply to circuit complexity.
Let’s quickly prove that if we set 


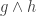


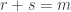
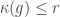
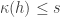
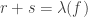
So, if some specific function
So the problem I have is this. All the formal complexity measures
8) Very succinctly put. Did you know that there are rigorous results that show that the kinds of difficulties you are encountering are not just due to your lack of imagination but are actually essential features of the problem?
🙂 I had heard something of the kind, but I’d love to hear more.
8) Well, the most famous result of this kind, and the one that best explains your particular difficulties (other people have had different difficulties that can be explained in other ways) is due to Razborov and Rudich. They defined a notion that they call a natural proof, and they showed that, subject to the truth of certain unproved conjectures that almost everybody believes, there cannot be a natural proof that P
To explain their idea, let me say first what a pseudorandom subset of 

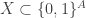


Since there are many levels of the set-theoretic hierarchy involved here, let me quickly clarify where 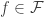

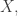
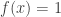




Anyhow, we shall say that 
![\displaystyle |\mathbb{P}[f(x)=1|x\in X]-\mathbb{P}[f(x)=1]|\leq\epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C%5Cmathbb%7BP%7D%5Bf%28x%29%3D1%7Cx%5Cin+X%5D-%5Cmathbb%7BP%7D%5Bf%28x%29%3D1%5D%7C%5Cleq%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
for every function 


😐 A small question. Couldn’t we just let 
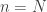
8) That’s a better question than you think. As it happens, I very deliberately didn’t do that, and I believe that by the end of my discussion you will be less confused than if I had.
In fact, let me tell you straight away why I went for a general set 


Now the thought that underlies the work of Razborov and Rudich is one that you have probably had yourself: it seems to be extraordinarily hard to tell the difference between a random Boolean function of low complexity and a purely random Boolean function. In fact, so much does this seem to be the case, that one might even hazard a guess that some theorem along the following lines is true: no polynomial-time algorithm can tell the difference between a random Boolean function of low complexity and a purely random Boolean function.
What does this mean? In order to stick to our resolution not to think about
Now it could be that the reason that the random low-complexity functions are hard to distinguish from purely random functions is that the random low-complexity functions form a pseudorandom subset of the set of all Boolean functions on
Here, it helps to visualize the 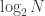


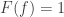
😐 One small remark. The function 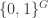
8) You’re right, and that’s an argument in favour of making all our Boolean functions take values in
🙂 Granted, but for the kinds of thoughts I was having it was more natural to have functions that typically averaged 
8) Let’s just all agree that we can switch from one notation to the other as we see fit. Anyhow, the point is that if you buy the assertion that a random low-complexity function is polynomially indistinguishable from a purely random Boolean function, then you can kiss goodbye to any thoughts of an easy proof that P
🙂 That sounds sort of plausible, but can you spell it out?
8) Certainly. Let me put the argument a bit loosely though. If you want to prove that P
Now that’s a bit strange, since the property was supposed to be one that applied to “simple” functions, and for any sensible definition of “simple” one would want a random function to be simple with only very tiny probability. But this argument shows that you can’t have that. If you define some notion of simplicity in the hope of proving that functions in P are simple and some function in NP is not simple, then either your notion of simple will not be computable in polynomial time (in the size of the group on which your functions are defined) or it will apply to almost all functions.
🙂 Wow. I can see that that rules out a lot of the ideas I had been having. For example, the Fourier transform of a function on the group 
8) Actually, I must admit that I oversimplified a bit. What Razborov and Rudich actually showed was not that the low-complexity functions form a pseudorandom subset of the set of all Boolean functions, but rather that it is possible to find a probability distribution that is concentrated on the low-complexity functions such that a random function chosen from this probability distribution cannot be distinguished by a polynomial-time algorithm from a purely random Boolean function. To oversimplify again, but much less, they found a clever subset of the set of all low-complexity functions rather than taking all of them. Also, and importantly, in order to show this they relied on an unproved hypothesis that asserts that certain kinds of pseudorandom generators exist. But this hypothesis, which is actually stronger than the hypothesis that P
🙂 I’m going to have to go away and think about this.
😐 Meanwhile, can this paper be found online?
8) Yes. Here is the paper of Razborov and Rudich, and here is a very nice discussion of natural proofs by Luca Trevisan.
😐 Thanks very much. I’ll go and have a look at those. By the way, where does the term “natural proof” come from?
8) Oh sorry, I forgot to say. Well, Razborov and Rudich call a proof that P
(i) all low-complexity functions are simple;
(ii) a random function is, with high probability (or even with non-tiny probability), not simple;
(iii) whether or not a function is simple can be determined in polynomial time (in
(iv) some function in NP fails to be simple.
The discussion above can be rephrased as saying that there is no property that satisfies (i) to (iii). In particular, if pseudorandom generators exist (which they do if, for instance, factorizing is hard), then there is no natural proof that P
🙂 Hmm. I’m not sure how to react to this. Initially I thought that perhaps I would be OK because, as you’ve pointed out to me, I was effectively thinking about formula size rather than circuit complexity. And the Razborov-Rudich result doesn’t tell us that there is no natural proof that some function in NP has large formula size.
But then it occurred to me that we could use their basic insight to give at least a heuristic argument that there is no natural proof that a function has large formula size either. Can I try it out on you?
8) Sure, go ahead.
🙂 Well, let me try to convince you that there is no natural proof that some specific function in NP has formula size greater than 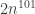


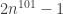

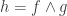

8) So what?
🙂 Well, unfortunately I don’t know how to prove anything about this random model. But it is at least plausible that a random function produced in this way is indistinguishable to any polynomial-time algorithm from a purely random Boolean function. And if that’s the case, then exactly the same argument goes through, and no natural proof could give lower bounds for formula size.
8) Yes, but what makes you say that that huge assumption of yours is even plausible, let alone true?
🙂 I don’t know. There just seems to be some kind of meta-principle that everything is either easy or impossible. So if there isn’t some obvious way to look at the values taken by a Boolean function defined by a smallish formula and work out what that formula is, then probably even telling the difference between a random function of low formula size and a purely random function is a problem that can’t be solved in polynomial time. And even if we merely suspect that that might be the case, then it should make us happier if our attempt to prove a lower bound for formula size was not an attempt to find a natural proof.
8) Hmm … that feels a bit circular to me. It’s a bit like saying, “If there’s no such thing as a natural proof then there’s no such thing as a natural proof.”
🙂 I don’t see it that way. The way I’d put it is, “My gut tells me that no polynomial-time algorithm can distinguish between a random low-formula-size function and a purely random function, so if I try to solve that problem by finding a suitable complexity measure, then I’m going to have to look for complexity measures that cannot be calculated in polynomial time.”
[In fact, this model of a random formula is flawed. See this comment of Luca Trevisan. And Ryan Williams suggests another reason that it may not work.]
While I’m at it, I’d like to mention another problem that I find very appealing. It’s sometimes thought of as a toy version of the P versus NP problem, in that the difficulties that arise feel quite similar.
The question is this: find an explicit non-singular 
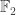
😐 Can you explain that in slightly more detail?
🙂 OK. Over any field, any non-singular 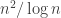
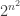
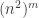
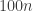
😐 Thanks, that was useful.
🙂 The point I wanted to make about this problem is that it too may be difficult for a formal reason. Suppose it is the case that there is no polynomial-time algorithm that can tell the difference between a purely random 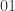
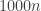
If it is true, then there is no natural proof that some specific matrix cannot be row-reduced using a linear number of operations. Here, a natural proof would be a polynomially computable property of matrices that all products of linearly many elementary matrices had, but that some explicit matrix lacked.
8) OK, thanks for that. You seem to have become a sort of optimistic pessimist.
🙂 I see what you mean. But actually I’m a bit depressed by all this.
8) Well, there are some people, including Razborov and Rudich in their original paper, who maintain that one shouldn’t necessarily react that way. If somebody shows you that a certain type of argument cannot work, then it should narrow down the search space and make finding a proof easier. So one can see the Razborov-Rudich argument as a very helpful hint rather than as a brick wall.
🙂 Yes, I like that. The trouble is that right now I can’t see how to get into this nice area that lies between natural proofs and useless universal proofs. I think we’d better stop this conversation for now, but I’ll be back.
8) I’m looking forward to it.

September 22, 2009 at 10:52 pm |
Tim: you appear to write “It is not too hard to show that if there exists a Boolean function f in NP … then P does not equal NP.” Is there something missing?
September 22, 2009 at 11:12 pm |
I second Michael’s question. It may not be too hard for you to show, but I’m pretty certain that 😐 (or however you “spell” your third character) should be screaming his head off at that point.
September 22, 2009 at 11:54 pm |
I assume the obvious bit is missing i.e.
“It is not too hard to show that if there exists a Boolean function in NP … THAT HAS SUPERPOLYNOMIAL CIRCUIT COMPLEXITY …then P does not equal NP.”
Thanks Tim, as a decided non-expert I found that informative. I look forward to parts 2 – 7.
September 23, 2009 at 12:07 am |
Thanks very much for pointing that out — I’ve corrected it now.
September 23, 2009 at 2:24 am |
After the comment about the statement not being directly connected to algorithms I (wrongly) assumed you must have meant something other than circuit complexity, thus my confusion. (Not to imply that non-uniform circuits are the same as algorithms, of course.) In any case, thanks for the clarification! I enjoyed this, and am looking forward to the other posts.
September 23, 2009 at 2:26 am |
Hi Tim,
A point that may be of interest to you: certain processes generating “random monotone formulas” will generate the MAJORITY function with high probability. See:
L. Valiant. Short monotone formulae for the majority function, Journal of Algorithms 5: 363–366, 1984.
I don’t know what happens when you throw in parity functions (i.e. the Rademacher functions). Maybe it would look something like what circuit complexity people would call a “MAJORITY of XORs”… or not.
September 23, 2009 at 10:18 am
That’s interesting. So maybe it’s harder than 🙂 thought (and, I have to admit, I thought) to create a good model of a random function of low formula complexity. The model suggested here was (as I think you are implicitly pointing out) a random monotone formula applied to basic functions and their negatives. It wouldn’t be a very good model if it was just applying the majority function from layer 1 onwards.
Fortunately, the general point—that the natural-proofs barrier applies to formula complexity as well—seems to be correct, as Luca points out below.
September 23, 2009 at 6:39 am |
The idea that a “random low complexity function is pseudorandom” is very appealing, but if it is true it is not going to be robust to the choice of basic functions and to the composition rules. In particular, I think that the example supplied by 🙂 does not work.
A necessary property of pseudorandom functions is to be approximately balanced (approximately half the inputs evaluate to 0, approximately half to 1) with high probability.
Consider the last step of the construction: with probability 1/2 you have h:= f OR g, with probability 1/2 you have h:= f AND g. Suppose you could prove that the construction gives an approximately balanced h with high probability; since f and g are coming from essentially the same construction (just fewer steps), then f and g are also approximately balanced with high probability, but this is a contradiction.
Other choices of bases could, however, work. As proved by one W.T. Gowers in 1996 (thanks to Omer Reingold for, coincidentally, showing me this paper yesterday), if one takes the basic functions to be permutations that operate on 3 bits and leave the other n-3 input bits unchanged, then the composition of poly(n,k) random basic permutations gives a family of almost k-wise independent permutations, and it is plausible that the resulting family of permutations is actually pseudorandom against polynomial-time algorithms, or maybe even sub-exponential size circuits:
W. T. Gowers:
An Almost m-wise Independed Random Permutation of the Cube. Combinatorics, Probability & Computing 5: 119-130 (1996)
Shlomo Hoory, Avner Magen, Steven Myers, Charles Rackoff:
Simple permutations mix well.
Theor. Comput. Sci. 348(2-3): 251-261 (2005)
In any case, if factoring is hard, then it is known that there are pseudorandom functions computable by polynomial size formulas, so as long as one uses the factoring assumption any instance of “circuit size” can be replaced by “formula size” in the Razborov-Rudich paper.
September 23, 2009 at 8:09 am
Many thanks for this interesting comment. Yes, I see your point about random formulae. I’ll try to think whether the “obstruction to randomness” that you point out is the only one. That is, is there any obvious way of telling the difference between the output of a random formula (as defined by 🙂 ) and a truly random function with the same density of 1s? I don’t immediately see one, but perhaps there is some other observation I haven’t made.
It’s tempting to rewrite the dialogue above to take into account your remark, but what I think I’ll do instead is get one of the characters to make this point much later on — there’s another thing I haven’t yet written where I was about to make the same mistake, but will now be able to avoid it.
The old paper of mine that you refer to has had a big influence on my private thoughts, and makes an appearance in some of the later instalments of this dialogue.
September 24, 2009 at 2:46 am
Interesting question. Rephrasing it to make sure I understand it in the right formulation: say that a distribution F over functions is random up to density if there is a distribution D over densities such that F is realized by first sampling a density d according to D, and then picking at random among all functions of density d. Then we say that a distribution F is pseudorandom up to density if there is a distribution F’ that is random up to density and such that no polynomial time tester can distinguish a function sampled from F from a function sampled from F’. The question is whether your process generates a function which is pseudorandom up to density.
A couple of remarks:
1) A “sanity check” question (although it is not clear that it is technically implied by the above question) is whether repeating the process an exponential (or even more) number of times eventually gives a function that is (close to) random up to density
2) If F and G are pseudorandom up to density, and we construct h by sampling f from F, g from G, and then with probability 1/2 defining h:= f AND g and with probability 1/2 h:= f OR g, then the resulting distribution H over functions h is also pseudorandom up to density. This means that if the answer to the question is NO, then it is not because of a “local argument.”
September 24, 2009 at 4:48 am
I think that the proposed model is very bad. Specifically, I suspect that, with probability approaching 1, it gives the constant function.
Here is a simpler model for which I can prove this is true. In this model, we have a sequence of probability distributions. Distribution A_0 always outputs a function of the form x_i or NOT(x_i), each one chosen with probability 1/2n. Distribution A_i takes two independent random samples from distribution A_{i-1}, and joins them with either an OR or an AND, each with probability 1/2.
Now, let u and v be two words in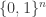 . I claim that the probability that
. I claim that the probability that 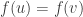 goes to 1, for f drawn from A_i, as i goes to infinity. Proof sketch: Fix u and v once and for all; let the probability we are interested in be p_i. I compute that
goes to 1, for f drawn from A_i, as i goes to infinity. Proof sketch: Fix u and v once and for all; let the probability we are interested in be p_i. I compute that
This recursion goes to 1.
Now, :D’s model is a little more complicated, and I am having trouble analyzing it. But I feel like the essence is the same.
We can add a little more randomness by, with some positive probability, aborting the whole process and going back to an atomic function. But this still has the fault that the probability of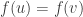 is bounded below by the probability that this be true for an atomic function. In particular, if u and v only differ in one bit, this probability is bounded below by
is bounded below by the probability that this be true for an atomic function. In particular, if u and v only differ in one bit, this probability is bounded below by  .
.
September 24, 2009 at 4:53 am
If we take MAJORITY as a primitive gate, this changes things. Here MAJORITY takes three binary inputs, and returns the more popular input. The recursion for MAJORITY is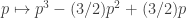 . This has a repelling fixed point at
. This has a repelling fixed point at  , and attracting fixed points at
, and attracting fixed points at  and
and  .
.
It would be interesting to find a set of primitive gates for which we could get random functions in the way you propose.
September 24, 2009 at 6:46 am
Very nice
September 24, 2009 at 2:34 pm
Luca: Shouldn’t there be some constraints on the density distribution D? Otherwise, it seems that the distribution that puts all its weight on the all 1’s function is random (and hence pseudorandom) up to density. Intuitively, for a definition of pseudorandomness to be useful in this context, it should at the very least imply circuit lower bounds.
The notion of pseudorandomness up to density for some fixed density (constant or 1/n, say) seems already interesting. But perhaps a pseudorandom function generator (PRFG)) for a density not too small or too large can be transformed into a PRFG for density approximately 1/2 by applying something like the von Neumann trick (sampling the original generator using several independent seeds and deciding the function value for the transformed generator based on the function values for all those seeds).
September 25, 2009 at 5:24 am
My reaction to David’s calculation was, “ah so the construction is pseudorandom up to density after all, except that the density is either 0 or 1.”
Indeed the definition is useful/non-trivial only if the density is noticeably bounded away from 0 and 1 with noticeable probability.
In such a case, there is another way to see that you can convert pseudorandom-up-to-density constructions into standard pseudorandom functions: the former imply one-way functions and from one-way functions you get pseudorandom functions in the standard sense.
If you let F be distribution of functions which is pseudorandom up to density, and A(.,.) be the evaluation algorithm that given randomness r and input x computes A(r,x) = f_r(x), then g(r):= (A(r,0),A(r,1),…,A(r,m)) must be a one-way function for large enough m=poly(n). (Here the number i is identified with the i-th binary string.) Otherwise, suppose you have an inverter I(.) that succeeds with noticeable probability; then, given an oracle function f(.) which might be either random up to density or coming from F, compute I(f(0),…,f(m)). If f is pseudorandom, then with noticeable probability the inverter finds an r such that f(.) = A(r,.); if f is random, then this happens with negligible probability (because the pseudorandom function has too much entropy to be well approximated by a short representation).
Once you have one-way functions, you can certainly construct standard pseudorandom functions.
September 23, 2009 at 7:23 am |
I can see how it might be hard to prove that a specific non-singular matrix needs more than 100n row operations to reduce it to the identity. But it also seems hard just to get to 10n. What candidate matrices were you thinking of, and can we prove any lower bounds of the form cn, for c>1?
September 23, 2009 at 8:10 am
I said 100n just to be safe. I think if you try to do things by hand then it probably gets hard before 10n. I’d guess you get up to something like 3n or 4n, but I’m not sure what the record is.
September 23, 2009 at 9:51 am |
Thanks very much for this, it’s great. Two small comments:
(1) Just before Shady uses the term “formal complexity measure”, in Smiley’s discussion about , there seems to be a superfluous phrase, “I choose a small
, there seems to be a superfluous phrase, “I choose a small  “.
“.
(2) In the definition of -pseudorandom, I had some confusion over whether
-pseudorandom, I had some confusion over whether  should be a function from
should be a function from  to
to  or was really from
or was really from 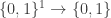 as stated, and spent a while staring at the definition rather than reading on. As it turned out, reading on cleared up the confusion, but it might have never appeared if there was a comment — just before or just after the offset formula — to the effect that we should think of
as stated, and spent a while staring at the definition rather than reading on. As it turned out, reading on cleared up the confusion, but it might have never appeared if there was a comment — just before or just after the offset formula — to the effect that we should think of  as a Boolean function and of
as a Boolean function and of  as a set of “candidate” complexity/simplicity measures for Boolean functions, or something like that.
as a set of “candidate” complexity/simplicity measures for Boolean functions, or something like that.
September 23, 2009 at 9:52 am
September 23, 2009 at 10:14 am
Thank you for that suggestion, which I have followed. I’m not sure even now that it’s as clear as it could be, but I think it is clearer than before.
As for the stray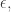 it was there because originally I had been going to construct a somewhat different function that needed a parameter. I’ve got rid of it now.
it was there because originally I had been going to construct a somewhat different function that needed a parameter. I’ve got rid of it now.
September 23, 2009 at 4:39 pm |
You seem to have created a polymathematical approach to the exposition problem …
September 23, 2009 at 5:38 pm |
One aspect for lower bounds which I find peculiar is that it’s not clear where NP itself is going to come in. Take a look at some of our best lower bounds for explicit functions:
The funny thing is, all of these lower bounds are for functions not just in NP but in P. (Andreev’s Function, some funny arithmetic function, Parity, and Matching, respectively.) Does anybody know any kind of lower bound where “NP-ness” was used essentially?
September 23, 2009 at 7:10 pm
I suppose you don’t count the use of the clique function to prove lower bounds for monotone circuit complexity on the grounds that it is possible to use perfect matchings instead. (Interestingly — or at least I find it interesting — the obvious infinite generalization of the perfect-matching problem is analytic but not Borel, so perhaps one could ask whether there is an exponential bound for monotone circuit complexity that comes from a function that doesn’t generalize to a non-Borel function.)
For my failed approach I was proposing to use a function that was not obviously in P (as will be clear in one of the later instalments of this dialogue), but it doesn’t really count as even a partial answer to your question to say that NP was fundamental to a lower-bound proof that doesn’t actually work …
September 23, 2009 at 7:31 pm
Ben Rossman’s recent lower bound for k-Clique against constant-depth circuits might be one example. He shows the lower bound for k constant, in which case k-Clique is in P, but I think it goes through also for slightly super-constant k. The proof seems to use specific properties of Clique, it’s not clear if the method works for an analogous problem in P…
September 23, 2009 at 11:07 pm
In the best results for monotone circuits (Razborov Alon-Boppana), isnt it the case that for cliques there was a exponential lower bound but for matchings only a superpolynomial (but not exponential something like n^logn ) lower bound?
September 24, 2009 at 2:18 am
Hi Gil. At first, yes, but E. Tardos improved the lower bound for Matching to or so. The best result in this area is Harnik-Raz, who get
or so. The best result in this area is Harnik-Raz, who get 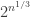 I believe for a function in P based on k-wise independent generators.
I believe for a function in P based on k-wise independent generators.
September 24, 2009 at 6:49 am
With all the natural proof attention and experts let me ask something (hope it is not too silly). Benjamini Schramm and me have a conjecture (which i think is reasonable albeit hard) that polynomial size bounded depth threshold circuit are stable against polylogarithmically-small noise. (log the size to the depth, or omega the depth). This will give a new proof (and strengthening) of results by Yau-Hastad-Goldman on bounded depth monotone circuits.
We also racklessly (and perhaps even very racklessly) conjectured (at least in our hearts) that this is true for monotone functions that can be described by arbitrary bounded depth polynomial size threshold threshold functions.
I think that Moni Naor and Omer Reingold showed that the natural proof disaster occurs already for bounded depth threshold circuits. Natural lower bounds there will give quick factoring.
So my question is if the seperation for bounded depth threshold circuits in my rackless conjecture with Itai and Oded is “natural proof” in the sense of Moni and Omer.
September 24, 2009 at 9:42 pm
Gil, I did not understand the difference between the first conjecture and the second conjecture.
If the second conjecture is “every monotone function in TC0 is stable against polylog noise,” then would it prove TC0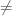 P? (because recursive majority-of-3 is monotone, in P, and noise sensitive?)
P? (because recursive majority-of-3 is monotone, in P, and noise sensitive?)
If so, your noise-related property would distinguish monotone easy (in TC0) functions from random monotone functions. Something like monotone pseudorandom functions (providing a natural-proof-type obstacle to your conjecture) might be constructed here:
Dana Dachman-Soled, Homin K. Lee, Tal Malkin, Rocco A. Servedio, Andrew Wan, Hoeteck Wee:
Optimal Cryptographic Hardness of Learning Monotone Functions.
ICALP (1) 2008: 36-47
September 25, 2009 at 3:23 am
Dear Luca, The first conjecture (which I still think is correct) talks about monotone TC_0 circuits. (Sorry I omitted the word monotone).
It will give that recursive majority of 3 is not expressible by (or very close to a function expressible by) a bounded depth monotone size threshold circuit.
The second conjecture is precisely as you stated. it would prove TC0 not equal P.
But I do not see why it distinguish easy function from a random monotone function because I do not thing a random monotone function is noise sensitive. Is it??? (Still I would not be surprised if the stronger conjecture may represent a natural proof of hardness somehow.)
September 25, 2009 at 5:04 am
Actually I don’t know if a random monotone function is noise sensitive, it just sounded like the kind of thing that should be true.
What is your intuition for thinking that a random monotone function is stable?
September 25, 2009 at 6:01 am
I would suppose a random monotone function looks a lot like a majority function.
September 25, 2009 at 5:00 pm
Sorry, I still can’t quite catch what the conjectures are 🙂
Let me try to restate them:
1. Monotone functions in AC0 are stable wrt 1/polylog(n) noise.
Comment: Isn’t this true even for nonmonotone functions, by LMN (Linial-Mansour-Nisan)?
2. Functions in monotone-TC0 are stable wrt 1/polylog(n) noise.
This is a very nice conjecture, and if I am thinking straight this morning I might guess that it’s true. Furthermore, it does not look impossibly scary.
This is in distinction with another conjecture (“Conjecture 3”?): Monotone functions in TC0 are stable wrt 1/polylog(n) noise. (There’s a distinction, right, between functions computable by bounded-depth polynomial-size circuits of monotone threshold gates — i.e. monotone-TC0 — and monotone functions computable by bounded-depth polynomial-size circuits of general threshold gates.)
Conjecture 3 looks too scary to try to prove, since as Luca points out the existence of Recursive-Majority-of-3 means this conjecture would imply TC0 differs from P.
But as I said, the conjecture that monotone-TC0 is noise stable for 1/polylog(n) noise looks nice, and not so bad given that (as Gil points out) Yao has a lower bound against monotone-TC0. Maybe the first step would be to look at depth 2?
September 27, 2009 at 4:33 pm
Dear Ryan,
Indeed the two conjectures I stated were your conjectures 2 and 3. The theorem of Linial Mansour and Nisan was an inspiration. It gives a much stronger property than noise stability for 1/polylog noise for AC0 functions.
Conjecture 2 will imply that recussive majority of 3 is not a or close to a function in monotone TC0. I agree that it is not that scary and that depth 2 is a place to start.
I agree that trying to prove conjecture 3 is scary as it will gives that reccursive-majority-of 3 is not in TC0 (which is widely believed) and not even very close to a function in TC0.
Seperating TC0 from P is a formidable task.
What I do not know is if Conjecture 3 being true is already scary.
If Conjecture 3 amounts to a natural proof seperating TC0 from P then Conjecture 3 being true implies that factoring is easy (by Naor Reingold or perhaps the result Luca cited). This means that not only it will be very hard to prove Conjecture 3 but that we may expect that this conjecture is false.
If in order to present a natural proof we need that most monotone functions are not noise stable to polylogarithmically small noise than I suspect this is not true. (So maybe, in general, restricting to monotone functions is a way, in princi-le, to overcome the natural proof barrier.) Again I am not sure about it and I do not know if the statement of conjecture 3 will have unreasonable consequences that natural proofs give.
BTW You are right there is a distinction between monotone functions in TC0 and functions in monotone TC0. But I do not know of a function showing that. For AC0 this is a result by Ajtai and Gurevich; if you want a monotone function in *C0 that cannot be approximated by a function in *C0 I believe it is open for AC0 as well.
September 27, 2009 at 10:11 pm
The last sentence should be: if you want a monotone function in *C0 that cannot be approximated by a function in monotone *C0 I believe it is open for AC0 as well.
September 30, 2009 at 3:57 am
It now seems to me that if the strong conjecture (conjecture 3 in Ryan’s terms) then it would give a non-naturalizing circuit lower bound. Or, at least, I cannot see any natural proof obstacle to the strong conjecture.
– The paper I cite above does not construct a family of functions that are indistinguishable from random monotone functions: rather it considers (as a starting point for a more elaborate construction) a family of monotone functions which are indistinguishable from monotone functions where the “middle slice” of inputs of weights n/2 are mapped randomly, and the function is fixed to majority on the remaining inputs. (A family of pseudorandom functions is easily modified to be indistinguishable from this distribution of monotone functions.) Both random and pseudorandom families as above are noise-stable because they agree with majority almost everywhere
– Even if a family of functions in TC0 could be constructed to be indistinguishable from the uniform distribution over monotone functions, I find Gil’s claim convincing that both families would mostly contain functions close to majority and hence be mostly noise-stable
– More generally, I don’t see a way to exploit the ability to compute pseudorandom functions in TC0 in order to compute a monotone noise-sensitive function in TC0. In particular, the following super-strong conjecture seems plausible: “with probability 1, relative to a random oracle TC0 contains no monotone function which is noise-sensitive for 1/polylog n noise.” (And it better be, because if factoring is hard then the strong and the superstrong conjecture are equivalent.)
– Overall it seems entirely plausible that the hypothetical TC0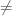 P proof given by the strong conjecture would be non-naturalizable. Interestingly, this would be so because the largeness condition would be violated. (Razborov and Rudich have a heuristic argument for why it would be strange to have a lower bound proof based on a property that fails the largeness condition, but the argument assumes that the property used to prove the lower bound is well defined for non-monotone functions.)
P proof given by the strong conjecture would be non-naturalizable. Interestingly, this would be so because the largeness condition would be violated. (Razborov and Rudich have a heuristic argument for why it would be strange to have a lower bound proof based on a property that fails the largeness condition, but the argument assumes that the property used to prove the lower bound is well defined for non-monotone functions.)
September 30, 2009 at 3:59 am
Sorry, the above anonymous comment was mine.
September 30, 2009 at 9:06 pm
I certainly support trying to separate P (or NP or NEXP or ) from TC0, and heartily recommend starting with depth-2 TC0. (I mean here general thresholds of thresholds, not just majority of majorities.) I feel the depth-2 case should be doable (even though I’ve worked on it unsuccessfully for a really long time).
) from TC0, and heartily recommend starting with depth-2 TC0. (I mean here general thresholds of thresholds, not just majority of majorities.) I feel the depth-2 case should be doable (even though I’ve worked on it unsuccessfully for a really long time).
September 30, 2009 at 10:13 pm
Maybe that could be a suitable Polymath project instead, though I’d want to think about it for a little while before getting started. Just to check, does depth-2 TC0 mean functions computable by a circuit of polynomial size, unbounded fanin, and threshold gates as well as AND and OR gates, where a threshold gate means “output 1 if at least r inputs are 1”? I had thought that it was at depth 3 that nothing was known.
October 1, 2009 at 4:23 am
That’s the correct definition of TC0; note that you don’t need to explicitly allow AND gates and OR gates, because they are just special types of threshold gates. You are allowed to use NOT gates as well.
October 1, 2009 at 8:43 pm
The problem I was suggesting is the following:
Let MAJ denote the class of functions of the form
of the form 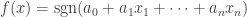 , where the
, where the  ‘s are integers with
‘s are integers with  .
.
Let THR denote the same class, except there is no upper bound on the magnitude of the ‘s. (Although it is known [Muroga-Toda-Takasu’61] that the
‘s. (Although it is known [Muroga-Toda-Takasu’61] that the  ‘s need not have more than
‘s need not have more than 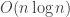 bits.) A function in THR is precisely the indicator of a halfspace in
bits.) A function in THR is precisely the indicator of a halfspace in  intersected with the discrete cube.
intersected with the discrete cube.
Let’s define circuit classes. Let MAJ o MAJ denote the class of functions computable as
computable as  , where
, where  are in MAJ and
are in MAJ and 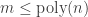 . Let THR o THR o THR denote the functions computable as a depth-3 poly-size circuit where the layers are functions from THR. Etc.
. Let THR o THR o THR denote the functions computable as a depth-3 poly-size circuit where the layers are functions from THR. Etc.
It is a theorem [Goldmann-Hastad-Razborov’92] that THR o THR o … o THR (d times) is contained in MAJ o MAJ o … o MAJ (d+1 times). So sometimes you see people defining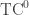 in terms of THR rather than MAJ, because it doesn’t really matter.
in terms of THR rather than MAJ, because it doesn’t really matter.
It *does* matter though if you’re being very careful about depth.
The original paper defining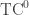 [Hajnal-Maass-Pudlak-Szegedy-Turan’87] gave an explicit function, IP2, which is not in MAJ o MAJ. This function IP2 = “Inner product mod 2” is nothing more than:
[Hajnal-Maass-Pudlak-Szegedy-Turan’87] gave an explicit function, IP2, which is not in MAJ o MAJ. This function IP2 = “Inner product mod 2” is nothing more than:
If you write bits as elements of the field of size 2, then IP2 is just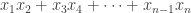 . This function is the canonical example of a function with a perfectly uniform Fourier spectrum; all coefficients are
. This function is the canonical example of a function with a perfectly uniform Fourier spectrum; all coefficients are 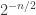 . Using this property is one of the several relatively easy ways to prove that IP2 is not in MAJ o MAJ. (Of course, IP2 is in P.)
. Using this property is one of the several relatively easy ways to prove that IP2 is not in MAJ o MAJ. (Of course, IP2 is in P.)
[Nisan’94] gave a nice proof (not very hard) that IP2 is not in MAJ o THR.
[Forster2000] gave a very beautiful (and a bit hard) proof that IP2 is not in THR o MAJ.
It is open whether IP2 is in THR o THR; I think it’s universally conjectured not to be. In fact, as I mentioned, there is no known explicit function not in THR o THR. For the complexity-theory lovers, I would add that as far as we know, not just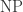 but indeed
but indeed  could be contained in uniform depth-2 arbitrary-threshold-gate circuit families. People often point to “bounded-depth AND-OR-NOT-Mod6-gate circuits” as the most ridiculously small class we can’t separate from NP, but I prefer the class THR o THR. It’s pretty galling that we can’t find an explicit function not in THR o THR.
could be contained in uniform depth-2 arbitrary-threshold-gate circuit families. People often point to “bounded-depth AND-OR-NOT-Mod6-gate circuits” as the most ridiculously small class we can’t separate from NP, but I prefer the class THR o THR. It’s pretty galling that we can’t find an explicit function not in THR o THR.
But I don’t feel too pessimistic about it (certainly I feel the AND-OR-NOT-Mod6 problem is much harder). I kind of feel like “IP2 not in THR o THR” should be doable; I mean, we managed MAJ o THR and THR o MAJ, so why not?
September 23, 2009 at 7:49 pm |
[…] https://gowers.wordpress.com/2009/09/22/a-conversation-about-complexity-lower-bounds/ […]
September 23, 2009 at 10:06 pm |
Ah, my old friends Simplicio, Salviati, and Sagredo!
September 24, 2009 at 3:00 am |
[…] first installment is out, and it already features a gentle and beautiful introduction to the models of boolean […]
September 24, 2009 at 8:08 am |
Ryan, I think that we end up applying arguments to simple functions because of the general approach to lower bounds, which are often designed by trying to understand precisely what makes a specific function hard. That precise understanding is easier if the function is not much more complicated than necessary. (Of course Razborov-Rudich points out that our typical methods are so sloppy that they apply to almost all functions.)
BTW: The improvement of E. Tardos to a truly exponential monotone circuit lower bounds for a polynomial-time computable function was not for Matching but rather for computing Lovasz’ Theta function (which was then improved by Harnik-Raz for a different function in P.) The best known monotone circuit size lower bound for Matching is still only quasipolynomial, though we know by Raz-Wigderson it has linear monotone circuit depth.
September 24, 2009 at 2:27 pm
Re the BTW: You’re right, thanks Paul! I misread Tardos.
September 24, 2009 at 9:45 am |
A non-mathematician’s (tiny) lament:
The smileys are a bit hard to distinguish between for me because the details that differ are buried within a big yellow blob. For me at least, it would be a lot easier to read if they were of different colours, even just different shades of yellow. Or if they were different shapes. Even bold single letters would work better for me: say O for the optimist, P for the pessimist, and N or L for the neutral “layman”. You might even call one of them S for Simplicio 😉
Another trick that could help: if they were placed with slightly different offsets from the left margin, they would also be easier to distinguish.
September 24, 2009 at 3:44 pm |
The natural proofs limit is truly brutal. I believe to make any further headway on P vs NP some new work down at the fundamental mathematical logic level is needed; something bizarre like one-and-a-half order logic (which doesn’t make any sense to me either, but is weird at the level I’m talking about).
However, I never would have expected forcing to work, so I’m not necessarily the smiley wearing the shades up there.
September 25, 2009 at 1:17 am |
[…] A conversation about complexity lower bounds In my previous post, I suggested several possible Polymath projects. One of them, which initially seemed to be the […] […]
October 7, 2009 at 2:44 am |
[…] parts are up so far. I will update readers as additional posts appear on Gower’s weblog. Part I here, part II here, and part III here. Submit this to Script & StyleShare this on FacebookShare this […]
October 8, 2009 at 7:22 am |
The initial part of the discussion might be easier to read if
* x_i is defined (that looks like the i’th “bit” of x?)
* “circuit complexity at most m” is defined, but then the existence of an NP problem with superpolynomial complexity is claimed to give P != NP. It may be clear to most readers that the latter definition of complexity is worst-case, but maybe it should be made explicit?
October 12, 2009 at 7:21 pm |
man i wish i was smart
October 21, 2009 at 12:36 am |
[…] think about problems (the other one I know is Terry Tao). In a recent series of posts (starting here), Gowers explains his attempts to attack the problem of finding lower bounds for circuit […]
October 27, 2009 at 5:01 pm |
[…] your earlier model of a random formula. I have to admit that I didn’t notice it myself, but was told about it by Luca Trevisan. He suggested using the basic operations from the Gowers model […]
November 6, 2009 at 10:47 am |
[…] If that’s not epic enough for you, Timothy Gowers has a (as of this writing) nine part series on the infamous P versus NP problem. This fascinating look into how a mathematician struggles with a problem starts here. […]
February 10, 2010 at 8:13 am |
[…] proofs” or the original paper or many other sources. (See also the series of posts by Gowers starting with this one. Our Conjectures 1 and 2 were briefly discussed there in the remarks […]
July 5, 2010 at 7:55 pm |
[…] fact, this model of a random formula is flawed. See this comment of Luca Trevisan. And Ryan Williams suggests another reason that it may not […]
November 1, 2012 at 9:47 pm |
[…] A conversation about complexity theory lower bounds by […]
February 28, 2017 at 6:03 am |
[…] It wasn’t intentional – I actually pinched the idea from a mathematics post about the P versus NP problem. […]
January 29, 2021 at 9:03 am |
[…] turned into a series of posts (first one here, whole “complexity category” here) where Tim tried to develop several ideas related to […]