This is the second part of a dialogue in which three characters, :), 8) and :|, discuss issues connected with the P versus NP problem. There are now nine parts: if this number continues to increase at a faster rate than I post them, then I may have to increase the rate of posting.
The story so far: 🙂 has put forward one or two ideas, and 8) has drawn attention to the work of Razborov and Rudich that places very serious constraints on what any proof that P
****************************************************************
🙂 Hi again.
8) Hello. Got anything for us today?
🙂 I’m not really sure. But I have had a few thoughts that I’d like to try out on you.
8) Fire away.
🙂 Well, the result of Razborov and Rudich tells us that if we want to define some notion of “structure” or “simplicity” that all functions of low complexity have and some function in NP does not have, then we have a choice. Either almost all functions must be simple, or it must not be possible to decide in polynomial time whether a function is simple. I have to say that I rebel against the first, so I’ve been trying to come up with properties that one might be able to prove something about, despite their not being in P.
If you take the attitude that any property not in P must be “weird” and “complex”, then this seems hopeless. But it’s gradually been dawning on me that there are plenty of properties that we understand perfectly easily even though we don’t have efficient algorithms for determining whether they hold. A pretty obvious class of such properties is NP!
For instance, if the property were “this graph on 

8) Yes, but if you allow properties in NP, then you allow the trivial universal properties such as “Has circuit complexity at most 
😐 Hang on just a moment. Can you explain why that’s in NP?
8) Certainly. If you want to convince me in polynomial time that a certain function 

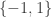



In short, if you tell me how
😐 OK, I get the general idea I think.
🙂 Hmm, so you’re saying that if I look at properties in NP then I run into the other difficulty—that I am allowing properties that lead to trivial reformulations of the original problem?
8) Well, it sort of looks that way.
🙂 Maybe. But it still doesn’t rule out that there might be some property in NP that does the job for us. For instance, perhaps for every polynomial-time computable function 

8) Well, in theory that might be possible I suppose. But the kind of thing you have just proposed won’t do as it stands, because if 

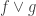
🙂 Hmm. But then if 


But wait. Is it as bad as all that? Let’s suppose that these collections 



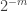
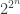
8) So, have you got any suggestion for a property along these lines. You appear to be wanting to say that 

🙂 I see what you mean. In particular, that last requirement is very strong indeed, since it implies that for every
That wouldn’t quite kill off the approach, because it might be that for a typical function, even if the restriction to almost every
8) OK, let’s hear it.
🙂 Well, I was trying to think of naturally occurring properties that are in NP and not obviously in P, and I suddenly realized that additive combinatorics can supply us with some.
8) Oh yes. Like what?
🙂 Well, an interesting phenomenon in additive combinatorics is that there are certain norms that can be computed in polynomial time, but that have dual norms that seem to be hard to think about except in an NP-ish way.
😐 Whoah, you’re losing me here. What is a dual norm, and what on earth has it got to do with NP?
🙂 Sorry, I keep forgetting that many people have an irrational dread of norms. I myself find that I can’t really understand anything until I’ve phrased it in terms of norms. (That’s an exaggeration of course, but it contains a kernel of truth.)
Anyhow, suppose we’ve got a finite set 
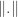


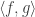



We now define the dual norm 

Note the trivial but useful inequality 
Now suppose that the norm of a function can be computed in polynomial time. It takes a little bit of effort to say precisely what that means, since we are dealing with real numbers here, but that’s a technicality I don’t want to get into. It’s sort of obvious in any individual case. For example, if I define 

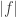
Next, suppose that we have a norm 


😐 That’s all very well, but for the examples I can think of, it seems to be possible to calculate the dual norm in polynomial time. For example, assuming this concept of duality is basically the same as a concept I was once taught about in a functional analysis course, isn’t the dual of 

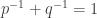
🙂 That’s what I thought as well to start with. Here’s a more sophisticated example. A well-known norm in additive combinatorics is the 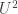


Now the direct definition of 

and if we define it that way then it looks like a function in NP that’s not obviously in P. However, it is an easy exercise to prove that 

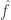


This shows that sometimes one can do a clever transformation, in this case the Fourier transform, that makes a dual norm easy to calculate, even if at first it appears to be hard to calculate.
8) OK then, what’s your point?
🙂 My point is that there are norms around where it’s nothing like so obvious how to do this. Here, for example is a problem that I don’t know the answer to. The 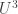


Now quite a lot is known about the 


8) Are you trying to suggest that the dual of the
🙂 Well, it seems like a long shot, since I thought of it just as an example of a fairly natural function that wasn’t obviously in P, and have no reason to suppose that it really is a formal complexity measure.
Maybe we should think about that. But first I want to tell you another reason that I can’t help being slightly excited about dual norms. Recall that we are trying to define a property of functions that we think of as “simplicity” or “structuredness”. A natural idea would be to define a notion of quasirandomness and say that a function is simple if it isn’t quasirandom. The
However, there is a problem, which is that if 
However, if we use dual norms, we are in much better shape. We say that 
😐 So you’re saying that it’s no good using “is not quasirandom” as a definition, but “does not correlate with a quasirandom function” might be OK.
🙂 That’s exactly what I’m saying.
😐 There’s something here that’s confusing me. Earlier, you mentioned what you called a trivial inequality, that
🙂 Yes I did.
😐 Well a special case of that is the statement that 
🙂 Yes.
😐 So if 

🙂 Oh. I think I see where this is going.
😐 So the only way
Thus, for
🙂 Damn. I was hoping to use some “magic power of duality”, but the observation you’ve just made shows that even the fact that the predual of some norm is in P causes problems for that norm.
That’s annoying, because dual norms had other virtues.
😐 What were those other virtues?
🙂 I just mean the things I’ve already mentioned: that the property of not even correlating with a quasirandom function seems much more likely to be closed under Boolean operations (in some useful sense that one would have to invent). I was also encouraged by the fact that the duals of the 

8) Perhaps we could formalize the difficulty and give a very slight (and very simple) extension of the Razborov-Rudich result. The reason your NP property (having a small dual norm) doesn’t work is that it implies a property in P (having a large norm) that holds for almost no functions. And that implies, by the work of Razborov and Rudich, that it cannot hold for all functions of low complexity. Therefore, your original property cannot hold for all functions of low complexity.
In fact, this is not an extension of the Razborov-Rudich result, since they have a notion of a naturalizable proof, which essentially means a proof that can easily be turned into a natural proof. And that is the case whenever the “simplicity” property you are considering implies another property that can be checked in polynomial time and does not hold for almost all functions.
🙂 That brings me to another point I wanted to make. It seems to me that coming up with an NP function that is quasirandom is not a particularly easy task, whereas coming up with an NP function that correlates with a quasirandom function ought to be significantly easier. I have examples up my sleeve to illustrate this, which perhaps I’ll talk about later. But for now I just wanted to point out that this was supposed to be another advantage of dual norms. The odd thing is that the failure of the proof seems to have nothing to do with the part of the argument where you show that some NP function is “complex”.
8) There. I told you you’d end up sadder but wiser.
🙂 I find that these feelings of sadness pass very quickly. I’ve just had another thought that might make things work.
8) I’m all ears.
🙂 Let me begin by saying what the 


Here, 



😐 By the way, is it supposed to be obvious that that formula really does define a norm?
🙂 Oh, sorry. No, it’s not obvious, but the proof is not too hard either. It’s a generalization of the proof that the 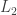
Anyhow, the thought that’s occurred to me is that perhaps we’d get something useful if we took 




8) You do realize, I suppose, that there is more to proving a complexity lower bound than just identifying a non-natural property. Do you have any reason to suppose that this one works, or are you just trying to find an approach that doesn’t trivially not work? Given the state of play with the problem, even the second aim has something to be said for it, but if you just make wild guesses like this, then the likelihood is that they won’t actually work.
🙂 You’re absolutely right. At this stage I just want to try to think about what a non-natural proof could conceivably look like. But now that I’ve got a candidate, why don’t we try to attack it and show that it doesn’t work?
8) Sounds good to me. And here’s my first attack. What makes you so confident that this norm does not belong to P?
🙂 I’ve just explained that. There are about 
8) Yes, but do we really have to look at all those configurations? Why couldn’t we take a much smaller random sample and get a good approximation to the norm with high probability? I’m pretty sure that would make the property naturalizable. (Here I’m using the general philosophy that all randomized algorithms can be derandomized — I could go into that, but suffice it to say that if we are assuming that strong pseudorandom generators exist then it shouldn’t be a problem to use randomized algorithms.)
🙂 I see. That’s a serious attack. So let’s think about how big the random sample needs to be.
Basically, it needs to be big enough that if there is some non-quasirandomness around, we will find it. So to make it as hard as possible to find, how about if we squash all the non-quasirandomness into a small space? For example, we could choose a function to be entirely random on the whole of 
I can’t be bothered to work out precisely what the 








What this seems to show is that, for this approach to have any chance of working, we would have to take 

8) Maybe not. Actually, I find your argument quite convincing. If all the non-quasirandomness of some function can be hidden in a very small subspace, it could well be quite hard to find that subspace.
😐 I’m not sure I’m quite as convinced. With your example, the function was constant on a subspace. Surely there must be ways of identifying large subspaces on which a function is constant if it is otherwise random. For instance, couldn’t one just take the Fourier transform?
🙂 Yes, but that was just one example. Having found that, one could disguise it a bit. For example, instead of making 
😐 OK, you’ve bludgeoned me into submission.
🙂 By the way, I should make clear that the complexity measure I would then go for is the dual norm of the
Having said all that, I still don’t really believe that I’ve just stumbled on a genuinely useful formal complexity measure. Here’s why.
We already more or less know that for bounded 
Suppose we were very lucky and could prove that 



😐 What do you mean by a degenerate configuration?
🙂 Well, with the 

Anyhow, I’m pretty sure that the largest possible 
8) I’d like to try out another demolition job if I could.
🙂 Fine by me, since I’m feeling less and less emotionally attached to this particular idea.
8) Well, if I understand correctly your definition of the
🙂 Yes, I’m pretty sure there is. But why don’t you explain it?
8) Well, let 

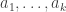




Thus, for a Boolean function to have a large
🙂 A simple argument shows that the expectation is non-negative, so if there is going to be any bias of this kind it will have to be towards even parity.
8) OK, forget the “or vice versa”.
Now the parity of the restriction of
🙂 Hmm … it sounds as though we’ve hit a fairly general obstacle here.
Oh, but hang on a moment. There’s a flaw in your argument. You correctly show that the expectation of the 
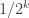



The point I’m making here is that if
8) Hmm, I’m going to come back to this point, because I’m still very suspicious of it. And there’s also your own objection to worry about — the one about 
🙂 Yes, but somehow that feels like an objection to one particular proposal for a complexity measure. And that proposal was, as you say, just a pure guess, with no thought for why low-complexity functions might turn out to have small dual norms. Perhaps some more carefully thought out quasirandomness norm might do better.
Also, I have to say that I don’t want to dismiss the dual of the

September 28, 2009 at 6:49 pm |
This might be a good time to point to the paper of Timothy Y. Chow, http://math.mit.edu/~tchow/almost.pdf. Therein he shows that the Razborov-Rudich result provably fails if you relax the “largeness” condition slightly; specifically, if you only insist that a random function have the property with probability at least rather than
rather than  .
.
He gives Salil Vadhan’s short proof of this statement at the top of page 10.
September 29, 2009 at 7:00 am |
Incidentally, 8) , the calculation of the U^k norm can be derandomized unconditionally using “epsilon-biased” spaces.
September 29, 2009 at 3:12 pm |
[…] emoticon’s converse … my guess this isn’t the conversation most people think they’re going to be […]
September 29, 2009 at 4:35 pm |
Thought-provoking post. Re. the “desperate idea”, it seems that niceness on X cannot be decidable in polynomial time (under a complexity hypothesis). Razborov and Rudich show that any formal complexity measure must be high for most Boolean functions. The same argument seems to carry through to say that if there is any function that is not nice on X, then it follows from the closure (or approximate closure) of niceness under Boolean operations that most functions on X are not nice on X. But then any criterion for niceness on X can be used to distinguish between random functions on X and pseudorandom functions (since pseudorandom functions ought to be nice on X), and hence cannot be decidable in polynomial time.
Perhaps a good test for a complexity measure in general is to check that it’s small for simple functions in NC^1, such as Recursive Majority. Indeed, if a measure is small for a complete function such as Boolean Formula Evaluation or iterated multiplication over S_5, and if it’s “closed under AC^0 reductions”, it’s small for all of NC^1. This would typically be the “easy” direction of a lower bound, the hard part being showing that there’s a function in NP for which the complexity measure is high. Maybe for “interesting” complexity measures, there would be a different tradeoff between these two parts of the argument, where it would now be non-trivial to show that the measure is small for functions with small formula size, but the proof that there’s a function in NP for which the measure is large would be simplified.
September 29, 2009 at 6:14 pm
The “desperate idea” took that point on board, and was proposing a definition that was something like this: a function f is “simple” if there is a “structured collection” A of “structured sets” X such that the restriction of f to any X in A is “nice”. If f is a typical low-complexity function, then for any individual X one would expect that the probability that f has a nice restriction to X is small (if niceness is in P), for the reason you give. The desperate idea was that for any low-complexity f there was nevertheless a structured collection A of exceptional sets X for which f did have a nice restriction, and that this property was preserved (in some sense) by Boolean operations. I think what I’m writing here is consistent with what you write, so apologies if this clarification is not needed.
I get the general gist of your second paragraph (after looking up what NC^1 is, but I haven’t yet got on to iterated multiplication over S_5 or closure under AC^0 reductions). I like the idea of trying to move the tradeoff.
September 30, 2009 at 4:43 pm |
Thanks for the explanation; I understand better now.
With regard to the second paragraph, the idea was that complexity measures which are proved to be useful by induction (i.e., by analyzing the effect of each individual AND and OR gate) might turn out to be just as hard to work with as formula size itself. A different way to show that a complexity measure is useful is to prove it’s small for a problem that is complete for NC^1, and then argue that it is small for all of NC^1 by using reductions. Typically, complete problems are complete under some simple form of reduction, such as AC^0 reductions. AC^0 reductions are reductions computable by a polynomial-size constant-depth family of circuits, where the circuits consist of AND and OR gates with arbitrary fan-in. The nice thing about AC^0 is that it’s fairly well-understood as a complexity class (relatively speaking!). Linial, Mansour and Nisan showed that any AC^0 Boolean function is well-approximated in L^2 norm by the Fourier spectrum restricted to co-efficients of weight at most polylog(n). As for completeness, there are some non-trivial (and simple) examples of problems that are complete for NC^1 – Barrington showed that multiplying a sequence of n elements of S_5 is complete, which is quite surprising since this can be done even by a finite automaton. An optimist might consider all this as evidence that NC^1 is a “simpler” and “easier to analyze” class than P.
September 30, 2009 at 5:09 pm
Exactly the same first sentence as yours!
Let me check that I really do understand what you’re saying—I’m fairly sure I do though. I haven’t checked, but I’m assuming that you focus on NC^1 because it is closely related to the set of functions of polynomial formula complexity, though if I’ve understood the definition correctly (bounded fanin, logarithmic depth, polynomial size circuits) then it doesn’t seem to be obviously identical. (In my head, it feels as though any NC^1 circuit can be expanded out into a polynomial-sized formula, but that some high-depth formulae cannot obviously be rewritten so as to have logarithmic depth.) But I’m also guessing that proving that some function is not in NC^1 would still be of major interest. So then you’re suggesting that to prove that using a complexity measure, it might be a good idea to do it in two stages. First, prove that some complete problem, such as multiplying permutations of a set of size 5 together (which can be done in NC^1 if you pair them up and multiply, then iterate that process until you’ve got a tree of permutations, each the product of the two before it) has low complexity according to that measure. Then prove that if you compose a low-complexity function with a function of bounded depth, you still have a low-complexity function. You suggest, but don’t quite say, that every function in NC^1 can be AC^0-reduced to the multiplying-permutations function. So then one would be done.
permutations of a set of size 5 together (which can be done in NC^1 if you pair them up and multiply, then iterate that process until you’ve got a tree of permutations, each the product of the two before it) has low complexity according to that measure. Then prove that if you compose a low-complexity function with a function of bounded depth, you still have a low-complexity function. You suggest, but don’t quite say, that every function in NC^1 can be AC^0-reduced to the multiplying-permutations function. So then one would be done.
Even if that’s only approximately correct, what you say looks very interesting, and ties in a little bit with things that the characters say in later instalments of the dialogue. (What I mean here is that they consider computational models where you do one explicit function to scramble things up a bit and follow it by a random function from a rather simple model. The composition appears to end up looking a lot more random than either of the two ingredients that make it up.) And whether or not your approach could be made to work, it focuses the mind on a very interesting question: just what is it that is “simple” about iterated multiplication over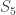 ?
?
September 30, 2009 at 5:39 pm
Actually, NC^1 is equivalent to having polynomial formula size, but there’s a (standard) trick required to see that. A formula can be thought of as a binary tree, and one can always find a node in this tree such that the size of the subtree rooted at that node is between n/3 and 2n/3 (where n is the size of the tree). This allows us to “re-balance” the formula to depth O(log(n)). And yes, you’re right, every function in NC^1 can be AC^0 reduced to the standard complete problems, such as Boolean formula evaluation or multiplication over S_5.
What makes me more hopeful about dealing with NC^1 rather than P is that regular languages are well understood, and AC^0 is somewhat well understood, so one might expect (naively) that it’s also possible to get a handle on functions that are AC^0-reducible to a regular language. In any case, I look forward to future instalments of the dialogue!
October 6, 2009 at 5:20 am |
This is somewhat tangential to the main post, but I wanted to mention a related open problem, which is to find faster ways to compute deterministically. For k=2, the FFT lets one compute this quantity in
deterministically. For k=2, the FFT lets one compute this quantity in  arithmetic operations. But for k=3, even with the FFT the fastest I can see is
arithmetic operations. But for k=3, even with the FFT the fastest I can see is  (by using the recursive formula for the uniformity norms); more generally, the fastest algorithm I know of for the U^k norm is
(by using the recursive formula for the uniformity norms); more generally, the fastest algorithm I know of for the U^k norm is  . It may be that an improvement on this could lead to some further understanding on these norms (historically, there has been a reasonable correlation between the ability to quickly compute an expression, and the ability to control that expression).
. It may be that an improvement on this could lead to some further understanding on these norms (historically, there has been a reasonable correlation between the ability to quickly compute an expression, and the ability to control that expression).
Of course, by random sampling (Monte Carlo integration, basically), one can quickly get the most significant digits of the U^k norm (assuming f bounded by 1, say), but this says nothing about the circuit complexity of these norms. I suspect though that the type bound for the U^k norm can be beaten.
type bound for the U^k norm can be beaten.
October 6, 2009 at 12:32 pm
A related question that I find interesting is to find a polynomial-time algorithm for the dual norm. I haven’t completely convinced myself that it’s hard, but I certainly don’t see how to do it. In fact, I don’t even see how to do the following (but again I haven’t sweated over it). If you have a function with
dual norm. I haven’t completely convinced myself that it’s hard, but I certainly don’t see how to do it. In fact, I don’t even see how to do the following (but again I haven’t sweated over it). If you have a function with 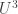 norm at least
norm at least  , then you know that it correlates with a quadratic phase function on a Bohr set (or a bracket polynomial, or whatever your favourite quadratic structure is — or look at the equivalent problem for
, then you know that it correlates with a quadratic phase function on a Bohr set (or a bracket polynomial, or whatever your favourite quadratic structure is — or look at the equivalent problem for 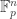 and take straight quadratics). There are superpolynomially many such structures, so one cannot find one in polynomial time by brute force. But can one do so by clever techniques?
and take straight quadratics). There are superpolynomially many such structures, so one cannot find one in polynomial time by brute force. But can one do so by clever techniques?
October 7, 2009 at 3:18 am
Tim’s question is answered in the case of for boolean functions in this paper:
for boolean functions in this paper:
Parikshit Gopalan, Adam R. Klivans, David Zuckerman: List-decoding reed-muller codes over small fields. STOC 2008: 265-274. (link)
They show that if agrees with a degree-2 polynomial
agrees with a degree-2 polynomial  on at least a
on at least a  fraction of inputs, then:
fraction of inputs, then:
1) There are at most polynomials
polynomials  having agreement at least
having agreement at least  with $f$ and
with $f$ and
2) They can all be found in time .
.
Even the first result is non-trivial because there are about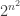 degree-2 polynomials.
degree-2 polynomials.
October 7, 2009 at 2:54 pm
I think Parikshit generalized some of these results to the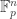 case, here:
case, here:
Click to access Quadratic.pdf
although I haven’t read his paper carefully yet…