This question arose in the discussion of my previous post, but deserves a place to itself because (in my opinion, which I shall try to justify) it involves different issues. For example, how does one explain the point of the abstract notion of finite-dimensional vector spaces when, unlike with groups, you don’t seem to have an interesting collection of different spaces? Why not just use  ? I addressed this point on my home page here, so won’t discuss it further on this post. But another point, which was raised in the previous discussion, concerns the relationship between theory and computation. I think it’s pretty uncontroversial to say that if you don’t know how to invert a matrix, or extend a linearly independent subset of to a basis, then you don’t truly understand linear algebra, even if you can state and prove conditions for a linear map to be invertible and can prove that every linearly independent set extends to a basis. Equally, as was pointed out, if you can multiply matrices but don’t understand their connection with linear maps, then you don’t truly understand matrix multiplication. (For example, it won’t be obvious to you that it is associative.) But how does one get people to understand the theory, be able to carry out computations, and see the links between the two? This is another situation where my own experience was not completely satisfactory: I’d be taught the theory in lectures and given computational questions to do, as though once I knew the theory I’d immediately see its relevance. But in fact I found the computational questions pretty hard, and some of the links to the theory were things I didn’t appreciate until years later and I found myself having to explain the subject to others.
? I addressed this point on my home page here, so won’t discuss it further on this post. But another point, which was raised in the previous discussion, concerns the relationship between theory and computation. I think it’s pretty uncontroversial to say that if you don’t know how to invert a matrix, or extend a linearly independent subset of to a basis, then you don’t truly understand linear algebra, even if you can state and prove conditions for a linear map to be invertible and can prove that every linearly independent set extends to a basis. Equally, as was pointed out, if you can multiply matrices but don’t understand their connection with linear maps, then you don’t truly understand matrix multiplication. (For example, it won’t be obvious to you that it is associative.) But how does one get people to understand the theory, be able to carry out computations, and see the links between the two? This is another situation where my own experience was not completely satisfactory: I’d be taught the theory in lectures and given computational questions to do, as though once I knew the theory I’d immediately see its relevance. But in fact I found the computational questions pretty hard, and some of the links to the theory were things I didn’t appreciate until years later and I found myself having to explain the subject to others.
This entry was posted on September 14, 2007 at 9:32 am and is filed under Mathematical pedagogy. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

September 14, 2007 at 12:59 pm |
But how does one get people to understand the theory, be able to carry out computations, and see the links between the two?
I think one should treat every computation as a mini-theoretical problem. In terms of the previous discussion, this would mean not writing down any expression without having some sort of mental model of what the expression represents (the models might be vague at first, but hopefully become more vivid as familiarity increases).
Teaching this way requires a good deal of effort and patience on the part of both student and teacher, but the payoff is worth it, in my opinion.
I’d be taught the theory in lectures and given computational questions to do, as though once I knew the theory I’d immediately see its relevance. ut in fact I found the computational questions pretty hard
My interpretation of this is that your instructors did not give you enough information about the theory! After all, if the solution to a problem is not obvious, then one is missing some important idea — in other words, some theoretical concept. (I’m assuming by “hard” you don’t just mean “labor-intensive” — although my remarks apply to some extent even in that case!)
September 14, 2007 at 1:51 pm |
I’m not sure about that last point. Let me give one example to illustrate why. Let’s take a simple fact like that any vectors in
vectors in  must be linearly dependent. One could approach that theoretically, using the Steinitz exchange lemma to prove that dimension is well-defined, and combining that with the easy fact that the standard basis of
must be linearly dependent. One could approach that theoretically, using the Steinitz exchange lemma to prove that dimension is well-defined, and combining that with the easy fact that the standard basis of  is indeed a basis. Alternatively, one could think about the result computationally, arranging the vectors into an
is indeed a basis. Alternatively, one could think about the result computationally, arranging the vectors into an  matrix and applying Gaussian elimination to that matrix until it has a row of zeros at the bottom, while at the same time applying the row operations to a column
matrix and applying Gaussian elimination to that matrix until it has a row of zeros at the bottom, while at the same time applying the row operations to a column  to keep track of the linear combination one had just discovered. It’s possible to understand both those arguments fully and not to see that they are intimately connected. In fact, I myself have meant for years to work out the precise sense in which they are essentially the same argument, but have never got round to it. But I don’t think that means that I’m missing some important idea from either argument.
to keep track of the linear combination one had just discovered. It’s possible to understand both those arguments fully and not to see that they are intimately connected. In fact, I myself have meant for years to work out the precise sense in which they are essentially the same argument, but have never got round to it. But I don’t think that means that I’m missing some important idea from either argument.
September 14, 2007 at 5:02 pm |
I am thinking this is an awesome post because at the moment I am doing both numerical linear algebra and linear algebra simultaneously. So hopefully I will learn something by participating. (Please feel free to correct anything I might get wrong!)
I read over the summer that matrices are operators.
I was extremely relieved to know that matrices weren’t the sum total of all
this because linear algebra for me represented, and I think this is probably common, “doing stuff with matrices” which didn’t strike me as all that interesting.
I am not sure if I’m typical and I’ve never taught anybody linear algebra and I’m only growing in my understanding of it even now, however, is it possible that linear algebra might be made more exciting by letting the cat out of the bag about the greater significance of it all even if people don’t completely get all the details of it right away? My own personal taste is that I prefer a clear division between computational details and the point of the computations.
I guess this sort of goes back to that paper Prof Gowers wrote on the two cultures of math which I read yesterday. I like a hint I think from the prof on what mode to see particular computations in. Depending on the stage of my understanding of mathematics I find one or the other way of looking at things more tractable.
For instance, if I understand very well the theoretical context of inverting matrices then I’d want to get insight into the theoretical underpinnings of the computations but if I don’t have that background then a comparison of several ways to invert a matrices and the trade offs can be interesting instead. I think the lectures that are halfway between both approaches can be very boring: a trudge through the theory but with examples which are mind-boggling computations too complex for any insight to be made.
September 14, 2007 at 5:32 pm |
Kay: If I were teaching matrices to somebody who had never seen them before, then I think I’d introduce them by the back door as follows. First I’d describe a geometrical transformation of the plane, such as a rotation through 45 degrees. Then I’d get people to work out where various points ended up after you’d done this transformation, until they got tired of that and simply wrote out a general formula for what the point maps to. (I’d try to choose the points so that this came out naturally. For instance, I’d start by doing it for
maps to. (I’d try to choose the points so that this came out naturally. For instance, I’d start by doing it for 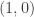 and
and  . Then maybe I’d do
. Then maybe I’d do 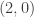 and see if they could work out how to do it for
and see if they could work out how to do it for  . If they got that then they should be able to do
. If they got that then they should be able to do  .)
.)
Having done that, I’d move on to a different transformation—a choice that springs to mind is a stretch by a factor of 2 in a direction parallel to the line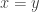 . (The thinking behind this choice is to have a geometrically and computationally simple transformation that does not have any zeros in the corresponding
. (The thinking behind this choice is to have a geometrically and computationally simple transformation that does not have any zeros in the corresponding  matrix.) It would then be fairly easy to do one operation followed by the other. The result would involve slightly complicated expressions involving the various coefficients, and would seem a bit ugly and unpleasant.
matrix.) It would then be fairly easy to do one operation followed by the other. The result would involve slightly complicated expressions involving the various coefficients, and would seem a bit ugly and unpleasant.
At that point I’d introduce the notation of column vectors and suggest that the numbers needed when you transform might be better organized in a
might be better organized in a  array. If that was done for the three geometric transformations, then one could see (even if one could not yet describe in full generality) how the matrix of the composition had been derived from the other two matrices.
array. If that was done for the three geometric transformations, then one could see (even if one could not yet describe in full generality) how the matrix of the composition had been derived from the other two matrices.
If I wanted to be very very gentle, I might not use the phrase “matrix multiplication” for a while, and refer to the product as a “composition matrix” or something like that. Then people would be less likely to have that feeling that it had no right to be so complicated. I’d then comment that what enabled us to work out where mapped to was the fact that the transformations were linear, so we just needed to know what happened to
mapped to was the fact that the transformations were linear, so we just needed to know what happened to 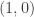 and
and  . Maybe then I’d look at linear transformations that were defined by matrices, rather than the other way round, and work out a few more composition matrices. Finally, I’d get to the general method for doing that. And if the class was reasonably sophisticated, I’d write down the product of two general
. Maybe then I’d look at linear transformations that were defined by matrices, rather than the other way round, and work out a few more composition matrices. Finally, I’d get to the general method for doing that. And if the class was reasonably sophisticated, I’d write down the product of two general  matrices.
matrices.
The result of all this (if it went according to plan) would be that the association between matrices and linear operators (in the form of geometrical transformations) would be established right at the beginning, that matrix multiplication would not be an absurd operation drawn out of a hat, and that matrices themselves would be seen as simplifying something complicated rather than making life complicated when it ought to be simple.
I’ve never gone through that process, however, since when I’ve taught linear algebra it has tended to be to people who have seen at least some of it before, and I’ve had a big syllabus to get through.
September 14, 2007 at 5:43 pm |
My own view is that most abstract structures are introduced in order to deal with or have a simpler way of thinking about “sub-objects.” I think this applies to most every object I can think of: vector spaces, manifolds, even groups (correct me if I’m wrong but historically mathematicians first dealt with permutation groups and it probably got too nasty to be always thinking about subgroups of permutation groups and instead think about the structure that unifies them). In a course I taught on beginning linear algebra, I found that the concept of a vector space was only useful when dealing with the various subspaces that appear in such a course like null spaces and ranges.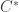 -algebras. One can introduce them in a completely abstract way or concretely as a closed *-subalgebra of the bounded operators on a Hilbert space (well maybe that’s not concrete to everybody). My favorite book on the subject (Mathematical Quantization by Weaver), uses the concrete definition and the only place the more concrete approach causes minor problems is in proving quotients of
-algebras. One can introduce them in a completely abstract way or concretely as a closed *-subalgebra of the bounded operators on a Hilbert space (well maybe that’s not concrete to everybody). My favorite book on the subject (Mathematical Quantization by Weaver), uses the concrete definition and the only place the more concrete approach causes minor problems is in proving quotients of 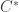 -algebras are also
-algebras are also 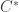 -algebras.
-algebras.
I think this is even true in
September 14, 2007 at 5:46 pm |
Hi Prof Gowers,
can you please recommend some nice books to self learn topics in linear algebra(both theory and computational aspects). i must confess that the only math i know is elementary calculus and a smattering of differential equations.
also can we self learn, just for fun, by reading books and doing problems on our own, the basic concepts in undergraduate and , if possible, graduate maths.
thanks,
shibi
September 14, 2007 at 6:08 pm |
What you say, that basically the only examples of vector spaces are , reminded me of something Joe Harris once said in a class shortly before introducing vector bundles: that he had always wondered the same thing until encountering bundles, when he realized that the infamous “non-canonical” isomorphism is precisely what allows you to have nontrivial bundles. Exploiting this feature, that vector spaces can arise which are naturally n-dimensional, but not given a natural basis, can make the theory seem more significant. This is what you address in the musings on your page. One doesn’t have to (shouldn’t?) say this in a first course, of course, but there are things you can do to imply it.
, reminded me of something Joe Harris once said in a class shortly before introducing vector bundles: that he had always wondered the same thing until encountering bundles, when he realized that the infamous “non-canonical” isomorphism is precisely what allows you to have nontrivial bundles. Exploiting this feature, that vector spaces can arise which are naturally n-dimensional, but not given a natural basis, can make the theory seem more significant. This is what you address in the musings on your page. One doesn’t have to (shouldn’t?) say this in a first course, of course, but there are things you can do to imply it.
One of those things I think you already had in mind when you wrote the post: “truly understanding” linear algebra means understanding the connection between linear operators and their matrices in a given basis. My personal experience is that the connection between the structure of the vector space and the structure of an operator’s matrix is not at all clear at first glance: for example, the various famous “shapes” of a matrix, such as upper-triangular, correspond to particular features of a vector space, for example a complete flag which the operator preserves. Then one sees that upper-triangularity isn’t just something fun that you come up with playing with arrays of numbers, but is actually an intrinsic property.
Basically, I’m advocating an explicit slant towards representation theory (or vector space as modules over, say![\mathbb{R}[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D&bg=ffffff&fg=333333&s=-1&c=20201002) , x acting as the operator in question). Every vector space, alone, is of course isomorphic to some
, x acting as the operator in question). Every vector space, alone, is of course isomorphic to some  , but a vector space with a linear transformation in hand has much more structure. Making this point in enough different ways, even if, for reasons of the students’ prior knowledge, you can’t follow it to its theoretical completion (for example, by making explicit that structure using the theory of modules over a PID), will plant the seeds of the correct understanding of what we mean when we say that a choice of basis is not “natural”.
, but a vector space with a linear transformation in hand has much more structure. Making this point in enough different ways, even if, for reasons of the students’ prior knowledge, you can’t follow it to its theoretical completion (for example, by making explicit that structure using the theory of modules over a PID), will plant the seeds of the correct understanding of what we mean when we say that a choice of basis is not “natural”.
This (to get to the point of your post) also allows you to gratify your students after they have suffered over some explicit computations without realizing the significance: a few days after teaching the coordinate-dependent concept, introduce the intrinsic one and show them how in their computations they were actually working out a particular structure (like a flag). This often seems to be done unintentionally (i.e. first courses which are all computation and no theory) or in reverse (like you had it: theory given, computation requested), but putting the theory close to, but right after the computation sounds like a better way to go. People learn mechanically first, after all: once they have a slight phenomenological understanding of the idea you can give them a conceptual one by tying it into their experiences, and even if there is no external reason for vector spaces to seem significant to them, the abstract concept will seem significant because it “explains” something they already “know”.
September 14, 2007 at 6:34 pm |
Prof Gowers,
The crux of your approach, if I understand it correctly, is to leave the student with the impression that matrices were making their life easier instead of harder. I think that emotional experience is probably pretty important and helpful. I think that’s sort of what keeping in mind a matrix is an operator does for me.
In a case like matrix multiplication, when I was taught this at first, I definitely had no idea why in the world people would do it this way other than my vague trust in the idea that it had been found more useful by people who knew more than me. I think I would definitely have appreciated the sequence as you describe it, where you implicitly show that the point of the multiplication is to compose the operation described by two matrices and not just the multiplying for the sake of having a multiplication operation.
September 14, 2007 at 7:34 pm |
i must add that the above questions are also directed at the commentators at this blog
thanks,
shibi
September 14, 2007 at 7:47 pm |
Here’s another example related to why we don’t just work in $R^n$, in the context of finite-dimensional Banach spaces. As I’m sure Tim knows well, people who work with such spaces have a habit of pretending they are the same as $R^n$. But consider the following vector space V: fourth-degree homogeneous polynomials in two variables, equipped with the supremum norm on the unit square. It’s easy to see that V is a 5-dimensional vector space, and there is even a fairly natural basis via which one can identify V with $R^5$. This identification gives a norm on $R^5$. Now try to express this norm in terms of the coordinates without just writing down where it came from.
September 14, 2007 at 9:13 pm |
As regards the identification between matrices and linear transformations: the latter are undoubtedly the best way to visualise matrix multiplication, but the former is more convenient for matrix addition. Similarly, with linear transformations, determinants are easy to understand, but traces are easier to understand using matrices (unless one takes a dynamical perspective and considers the matrix as an infinitesimal deformation of the identity; this gets back to the “near 1, multiplication is like addition” business from a few posts ago). So it’s important to understand both perspectives, and how to swap back and forth.
Regarding vector spaces that are not canonically identified with R^n, we have very familiar examples of this even in the one-dimensional case n=1; this is the whole business with units of measurement. For instance, your net mass is represented by a (positive) element of a one-dimensional space, but in order to express this mass as a number, you have to arbitrarily pick a unit, e.g. pounds or kilograms. But clearly the concept of mass makes sense even if you choose not to use pounds, kilograms, or any other unit; one can add two masses, and one can also scalar multiply a mass by a number.
One can view ratios, such as speeds, as examples of linear transformations from a one-dimensional space (e.g. time) to another (e.g. length). In order to convert this to a 1 x 1 matrix (i.e. a number), one needs to pick a basis (i.e. select a unit) for both the domain (e.g. seconds) and range (e.g. meters).
In my own classes, I’ve tried to emphasise the idea of a linear transformation (or matrix) as being the multidimensional generalisation of a ratio, see e.g.
Click to access week3.pdf
This seems to help some students but not others…
September 14, 2007 at 10:28 pm |
Prof Tao,
I was wondering what you throught of the critique that maybe the fact that matrix addition is so obvious in terms of matrices is what makes it so very confusing that multiplication is so complicated. But I think it makes sense when you know what the goal is, which isn’t just multiplying columns of numbers in arbitrary ways. I think from a novice perspective most of the convenience of linear algebra comes off as a coincidental to the complicated set up rather than as a result of the complicated set up. I think it’s sort of like the difference between foraging food from a wild landscape, where there is occasional useful things to eat but no overall design vs. a supermarket where it’s specifically organized for getting useful things to eat. I think a lot of students (and I think I am in the first category but slowly moving to the second category) don’t see the wisdom of the grand design of linear algebra and come away thinking of it as arbitrary number pushing.
September 14, 2007 at 10:41 pm |
Terry, for the second time in a few days you’ve sprung on me an idea that somehow manages to be at once incredibly simple and something I’d never thought of. I think the concept of the non-canonical nature of the vector space amongst all one-dimensional vector spaces could come into the category of concepts I mentioned earlier, where the phenomenon one describes is so easy to understand that it is difficult to get across why one is bothering to say it. I suppose you could give them a problem that involves adding two physical quantities, which you refer to by letters, and then get them to observe that what they were doing didn’t depend on their choice of units. And even if they didn’t immediately and fully appreciate the point, they might look back on it later.
amongst all one-dimensional vector spaces could come into the category of concepts I mentioned earlier, where the phenomenon one describes is so easy to understand that it is difficult to get across why one is bothering to say it. I suppose you could give them a problem that involves adding two physical quantities, which you refer to by letters, and then get them to observe that what they were doing didn’t depend on their choice of units. And even if they didn’t immediately and fully appreciate the point, they might look back on it later.
September 15, 2007 at 4:52 pm |
I could not agree more with Terry Tao when he says:
So it’s important to understand both perspectives [matrices and linear maps], and how to swap back and forth.
Nonetheless, it may still be the case that it’s better to start from one perspective and use it to reveal the other, rather than the reverse direction. Thus, to answer Tim’s point:
It’s possible to understand both those arguments [Stenitz exchange and Gaussian elimination, to show linear dependence] fully and not to see that they are intimately connected… But I don’t think that means that I’m missing some important idea from either argument.
I would say that, at the stage where one is proving that n+1 vectors in are linearly dependent, one really ought not to have even mentioned matrices yet. By the time one gets to discussing matrices and Gaussian elimination, one should already be thinking automatically in the language of linear transformations, so that the “translation” is (ideally) readily apparent. In other words, the “precise sense in which they are the same argument” that Tim refers to, instead of being a mysterious undercurrent, should actually be the way that the Gaussian elimination argument is first conceived!
are linearly dependent, one really ought not to have even mentioned matrices yet. By the time one gets to discussing matrices and Gaussian elimination, one should already be thinking automatically in the language of linear transformations, so that the “translation” is (ideally) readily apparent. In other words, the “precise sense in which they are the same argument” that Tim refers to, instead of being a mysterious undercurrent, should actually be the way that the Gaussian elimination argument is first conceived!
The point is that by building up a theory systematically, in logical order, one should immediately see how different concepts relate to each other — because some are new, some are old, and the new are defined in terms of the old.
September 15, 2007 at 5:55 pm |
Funnily enough my feeling about that example is the exact opposite: that it’s better to see the Gaussian-elimination argument first and then be told (preferably in a detailed way) that the Steinitz exchange lemma is just a more abstract way of putting the same basic idea. Though when I say “better” I mean it in the subjective sense of “preferable to me” — clearly different mathematicians can legitimately disagree about this, and in other contexts, including some results in linear algebra, I myself would prefer to do things the other way round.
September 29, 2007 at 8:38 pm |
One answer to the question of how to introduce vector spaces is: “Don´t” . By simply never mentioning vector spaces (along with the Steinitz exchange lemma and similar paraphernalia) we can cut straight to the chase! The identification of matrices and linear transformations (and the accompanying row and column gymnastics) can be viewed as a necessary notational evil. For instance, when working with permutations of a finite set X, one writes 1,2,…n for the elements of X and then chooses a concise notation for permutations (the notation itself will inevitably depend on the chosen ordering 1,2,.. of X) Thus 53124 might denote the permutation which takes 1 to 5, 2 to 3, 3 to 1, 4 to 2, and 5 to 4. One must then work out how to calculate composition of permutations in the chosen notation e.g. 53124@21435 = 35214. Similarly, a linear transformation T will send each of 1,2,…,n to a linear combination of 1,2,..,n and so will be determined by the coefficients of 1,2,.. in T(1),T(2),..There are various ways the coefficients can be written down, e.g. as usual, in a rectangular array or listed in some definite order such as dictionary order. Then, of course, one has to work out the rules for calculating sum and composition and other operations. Basic properties and facts about linear transformations can be expressed and proved in matrix language e.g. “invertible matrices are square” and “square + injective iff square + surjective” all follow easily from invariance under PAQ equivalence (here P and Q are required to be square invertible matrices, although invertible is in fact enough as it turns out (using PAQ equivalence) that invertible implies square). Similarity of matrices can then introduced with the excuse that it expresses the important idea of two matrices “doing the same thing”. Next, polynomial matrices are introduced and the important criterion for similarity in terms of equivalence of polynomial matrices is proved and than used to get the cyclic decomposition and Jordan canonical form, an interesting case being GLn(2). The point is that all this and more (e.g. representations of finite groups) can all be done more easily without burdening oneself with abstractions, in particular vector spaces and modules . Of course, futher down the line, there will be no lack of abstractions ( e.g. schemes in algebraic geometry). Nevertheless there seems to be no harm in putting off the evil day for as long as possible.
September 29, 2007 at 10:39 pm |
Derek, I have to go the other way with it. What you’re asking is for the students to delay practice with abstraction, while admitting that they’re have to deal with it eventually. So suddenly that day comes and they’re totally unprepared for it.
The sooner we get students thinking independently of bases (for example), the easier they’ll pick up the ability to think of differential geometry independently of coordinates, or of the special linear group independently of its matrix representation.
September 30, 2007 at 9:17 am |
In France, at the time I was in school, we learnt of “vectors” very early on, at least in the setting of vectors in plane geometry (this was, if I remember right, in “3eme” or “4eme”, as school years are called here, which means roughly around 13 or 14 years old). The definition of what is a vector in a situation where affine geometry is what is naturally studied was so baroque that I remember it very well: a vector is “une classe d’équivalence de bipoints équipollents”. The first part is easy enough to translate, and it is interesting to see that we were supposed to be so well-versed in equivalence relations at that age that basic geometric notions could be built on this foundation. A bipoint is just an ordered pair of points (P,Q) in the plane. And two bipoints (P,Q) and (R,S) are “équipollent” if the quadrangle PQSR is a parallelogram. (Now everyone can see why French algebraists around this generation are never so happy than when cuddled-up with a good torsor of one kind or another…)
Having vectors, the basic properties of the corresponding space of vectors were derived from the definition: existence of the addition law, existence and properties of the origin of the vector space. I don’t remember how the scalar multiplication was done, however.
Vector spaces in general where only properly introduced in axiomatic fashion in the first year of university (or Classes Préparatoires). I don’t remember if an arbitrary base-field was allowed in my class, but I wouldn’t be surprised if that had been the case in some places at least. In my class at least, the whole theory of finite-dimensional vector spaces was based on the lemma that if a family of $n$ vectors is generating, then any family with $n+1$ vectors is linearly dependent, proved using induction and some form of Gaussian elimination. But that might have been simply my teacher’s way of doing things.
I certainly don’t claim that this is (or was) the right way to do things. The proportion of students who felt comfortable with the abstraction of what is a “vector” according to the above was vanishingly small (this was supposed to be the universal curriculum in France for this age, not some specially selected groups of mathematically-inclined boys and girls).
All in all, at the right age, I think vector spaces is a pretty good first instance of mathematical abstraction, in that it comes usually as extending well-known things (plane and/or space geometry), and there are many examples to show the ubiquity and usefulness of the notion, including infinite-dimensional spaces — which I think should be introduced, as examples, quickly after the definition, because they provide one very solid reason for dispensing with coordinates-based presentation.
October 3, 2007 at 11:57 am |
[…] am choosing as my example of a statement to be proved the one I mentioned in this comment, namely the fact that vectors in cannot be linearly independent. Let me briefly sketch the two […]
October 13, 2007 at 12:24 am |
Prof Gowers,
I am a first year Maths students at Warwick Uni. I did A-Level Further Maths with CIE (Cambridge International Examinations). The syllabus is fairly similar to the other UK ones the only exception being that a large chunk of linear algebra is taught (and group theory is not even part of the syllabus!).
I remember doing things like linear independence, subsets, bases, spanning sets, linear transformation (and the use of matrices to represent them), rank-nullity theorem (without proof),…
A typical exam question was: a matrix representing a linear map from Rm to Rn (sorry I cannot use superscript) was given. We had to reduce it to row echelon form. Use the rank nullity theorem to get the rank or the nullity. Find a basis for the null space of M (the linear map which was given) and something else (like solving an equation of the form Mx=v, where M is the matrix representing the linear map).
The syllabus of the Further Maths exam (for linear algebra) looks quite similar to the brief outline of my term 2 course in Linear algebra at Warwick (although things are done much more rigorously there than at A-Level).
The way the questions and the syllabus (of the A-level course) was structured a greater emphasis was put on “learn the method and use it” rather than the theory behind it although, in theory, it had to be introduced. But in practise most exam centres teach it in a way so that the student learn the method (and get the grades) rather than the theory. Many Maths teacher do not even remember the linear algebra they did at uni so many years ago. The fact that students have no prior knowledge of group theory does not help. Also the only texts on the subjects are university ones and their level and assumed knowledge makes them not suitable for teaching the course.
The linear algebra question is generally the one in which the students perfom the less well. And from doing past papers I noticed that the level of the linear algebra question tends to be decreasing every year. Despite this fact the examiners still complain about the poor performance of students in the A-level exam.
CIE does not publish the mark schemes (not even to the teachers) which makes things even more difficult.
You might want to have a look at the syllabus: http://www.cie.org.uk/qualifications/academic/uppersec/alevel/subject?assdef_id=756
What are your views on teaching vector spaces at A-level?
October 14, 2007 at 12:20 pm |
If you get the grades by learning the method then learn the method and ignore the theory if that does not have any impact on the grade. Any time spent on theory is wasted if you could improve your grade by practicing the method more thoroughly. If you want to become a professional mathematician/scientist any time spent on doing things that don’t lead to the grade is wasted–until you have tenure. Then you can have fun! Of course if you are certain you will get A* then you can spend time reading some theory (although relaxing by watching a film might be more therapeutic!) Note that UG physics students have no time to learn theory. They follow ‘mathematical method’ courses that is all method. So ‘all method’ is OK, as is ‘all theory’. It depends on your circumstances. As an A level student your circumstance is passing the exam, not reading university texts on linear algebra (unless you are certain of A* and such an activity is more relaxing and fun for you than socialising and watching films).
October 14, 2007 at 4:32 pm |
This is exactly the sort of mindset that leads to the herd mentality and groupthink so prevalent in string theory. “Do what your superiors think is right, rather than what interests you.” Sometimes I think I’m the only mathematician my age left who has a passion for mathematics rather than just a profession for it. Don’t put the fun off until you’re one of those lucky few who manage to get tenure — do mathematics because it’s fun for you now.
To the contrary of what Paul says. Forget the grade. As a student, do whatever it takes for you to learn the material. As a teacher, do whatever it takes for your students to learn the material. There is no one approach that works for everyone, but comprehension is far more important than a grade on this exam or that.
Try a bit of theory and a bit of method, and you’ll be able to tell when you’re understanding the concepts. And you’ll know it without the carrot/stick mentality of a grade-grubber.
October 14, 2007 at 8:19 pm |
I strongly disagree with the sentiments expressed in John’s remark. When we depend on a brain surgeon or a jet pilot or a taxi driver or the person who prepare for us cappuccino, the professionalism and technical skills of these people (which can reflect a blessed “group-think”) are far more important to us than their passion and sense of fun. To a large extent (even if not to full extent) this applies also to mathematicians and other scientists.
Forgetting the grades is far worse advice for students than caring only about grades (which is also a rather bad advice.)
October 15, 2007 at 12:00 am |
So, Dr. Kalai, are you opposed to the policy of many mathematics departments (including, Yale’s, where I know you like to spend a fair amount of time) of not grading upper-level graduate courses?
Clearly undergraduate study needs to be graded, but just as clearly there is no such thing as a grading rubric after some point. Maybe I’m engaging in some hyperbole, but it’s only in response to the statement that you should be completely obedient to those who have gone before until you get tenure. The very existence of grades disappears long before the tenure level, and all you’re left with is following a select inner circle simply for the sake of their approval.
That’s a great way to be a graphic designer, but a horrible way to be an artist. Personally, I’d rather be an artist.
October 15, 2007 at 1:20 am |
Dear John, right right I think we met in Yale quite often; I did not recognize you with the hat. I am sure we agree that students should take seriously their grades and other obligations, as we faculty members (before or after tenure) should take seriously our obligations. (“Complete obedience” does not seem relevant in both cases.) best regards –Gil
October 15, 2007 at 2:50 am |
Paul said:
So how do you read “grade”? Who’s “grading” after the undergraduate level? Of course you have to do good work, but who’s there to “grade” you but existing research programmes?
Undergraduate study consists of doing what your professors think is good for you to do, and submitting to their judgement through the mechanism of grading. By the graduate level — and certainly before “you have tenure” — you need to learn to think for yourself, and to decide for yourself what needs to be done and where you can most productively contribute. Paul’s extremist viewpoint needs counterbalancing.
October 15, 2007 at 2:01 pm |
There is an important point for many of us as instructors to take from Paul’s post. His attitude is quite common among undergraduates, and not only in lower-level courses. Paul’s post contains several conditional phrases like “ignore the theory IF that does not have any impact on the grade” (my emphasis). If you believe that understanding the theory is a vital part of a class you’re teaching, then your testing and grading should reflect that. Of course, the same goes for any other aspect of the class as well.
October 15, 2007 at 3:06 pm |
John’s approach might be “fun” but if you end up with a C in ‘A’ level mathematics through “having fun” then you end up at Bournemouth University instead of Cambridge. Then you can “have fun” all the way to stacking shelves at LIDL. Of course, you can then do “fun maths” in the evening, like Ramanujan. So, who knows, you might get to “do something” via that route.
Lecturers tend to avoid testing for theory, unless absolutely necessary, because half the class would fail.
Of course, lecturers have multiple personality disorder when it comes to this issue. Glancing at Anton’s calculus text he has four introductory sections on limits – intuitive, computational, rigorous (optional) and ‘very’ rigorous (optional and in an appendix). Solution – find out which disorder(s) your lecturer has by asking him explicitly for page references and past (still valid) exam papers — and attending lectures and taking notes of those ultra-important ‘this might be on the exam’ side hints.
October 15, 2007 at 6:37 pm |
I think the discussion contained in the last few comments needs to be a bit more focused on examples, because the benefits of learning theory vary from example to example. For instance, if you are taking an exam in which a typical question is to solve three simultaneous equations, then knowing an algorithm is going to be enough. If you have to consider the cases where solutions may not exist or may exist without being unique, then an algorithm is still enough, but it certainly helps to see what is going on if one has a mental picture of what, say, a linear map from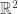 to
to 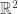 does. In such situations, a bit of theory could be very useful, even for exam purposes, as a protection against making silly mistakes without realizing it. Once you look at
does. In such situations, a bit of theory could be very useful, even for exam purposes, as a protection against making silly mistakes without realizing it. Once you look at  -dimensional systems of equations and discuss general phenomena then theory becomes very useful as a way of avoiding the unpleasant task of describing algorithms clearly and unambiguously.
-dimensional systems of equations and discuss general phenomena then theory becomes very useful as a way of avoiding the unpleasant task of describing algorithms clearly and unambiguously.
As an example of where a bit of theory can be a huge help, when I was first taught quadratic equations I was told different methods for how to solve them, according to the signs of the coefficients. If I was solving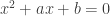 with
with  and
and  positive, then I was told to look for two numbers that added up to
positive, then I was told to look for two numbers that added up to  and multiplied together to give
and multiplied together to give  . But if the equation was
. But if the equation was  then I had to find two numbers whose difference was
then I had to find two numbers whose difference was  and that multiplied to
and that multiplied to  and make the smaller one negative … and so on. One day my father pointed out to me that in all cases you just take two numbers that add up to the second coefficient and multiply together to give the constant term. What’s more, if you just multiplied out
and make the smaller one negative … and so on. One day my father pointed out to me that in all cases you just take two numbers that add up to the second coefficient and multiply together to give the constant term. What’s more, if you just multiplied out  it was obvious why this should be. So a tiny amount of theory (how to add and multiply negative numbers) was enough to make a method that was unpleasant and difficult to remember into one that was attractive and easy. I could make similar remarks about the benefits of knowing how to complete the square rather than blindly applying the quadratic formula: at the very beginning it may be enough to apply the formula but pretty soon if that is all you know how to do it will be a handicap.
it was obvious why this should be. So a tiny amount of theory (how to add and multiply negative numbers) was enough to make a method that was unpleasant and difficult to remember into one that was attractive and easy. I could make similar remarks about the benefits of knowing how to complete the square rather than blindly applying the quadratic formula: at the very beginning it may be enough to apply the formula but pretty soon if that is all you know how to do it will be a handicap.
I think in most cases you can get a reasonable distance just with the methods, but learning the theory will often have two practical benefits: it will make the methods easier to remember and it will help you in the next exam but one. Since mathematics takes time to digest, it’s worth worrying now about the next exam but one rather than waiting until it gets close.
There are some cases where a gamble is involved: the theory is difficult to understand and you may spend a lot of time trying to understand it and end up not succeeding; however, if you do succeed then everything becomes easier. Whether or not you want to take that gamble depends on your ability and on what you want out of mathematics.
October 15, 2007 at 8:23 pm |
A side conversation with Dr. Kalai and reading the new comments reveals that I should possibly clarify a bit.
My position is that a student should do whatever it takes to master the tools at hand, and it is the student’s job to learn how best to learn for himself. At the undergraduate level this does consist of submitting oneself to a grading mechanism, but that mechanism drops out far before the tenure level. If one is still focussing on grades and not on comprehension by graduate school, I see that as a problem.
In short: Paul’s comments are appropriate, but only in a greatly restricted scale to that in which he originally expressed them.
October 16, 2007 at 2:44 pm |
Some professors are famous for taking a sink or swim approach. They give their students hard, interesting problems and the students sinks (fails PhD) or swims (gains PhD). Others give their students an easy problem and hand hold them through the methods that will get them the PhD — an approach more conducive to swimming. Some students insist on pursuing their own research interests. Others take on a research project specified by their professor. Suggestion: to succeed find a ‘hand holding’ professor, take on a project of his suggestion, and follow his advice to the letter. If he says ‘learn theory’ then learn theory. If he says ‘pursue this method’ then purse this method. Do the same as research assistant/research fellow. Then get tenure — now pursue your interests, and do your own thing while being paid for it (unless you want loadsa money/promotion, in which case, swim to the dictates of the head of department). John appears to be a ‘sink or swim’ professor (‘learn how best to learn for himself’). You might be lucky enough, or talented enough, to swim if thrown in the deep end. But why take that chance?
October 16, 2007 at 3:34 pm |
The problem with that approach, Paul, is that you’re assuming people will have the time or the energy to go back and learn all the basics of a new field they’re really interested in once they’ve achieved tenure. Why not instead find an advisor who will help you find your own problems to work on from the beginning of your research career?
Oh, and let’s cut out the ad hominem, shall we? You have no idea how I implement my pedagogical philosophies.
October 16, 2007 at 5:03 pm |
Through undergraduate studies people should be able to pursue certain things they are interested in. This doesn’t always apply, of course. Cambridge seem to be severely limiting the number of people able to study theoretical physics in their final year — on recommendation of tutors. Also, to find supervisors in the most interesting areas you better be high up on the wrangler list. Maybe you could, say, find someone to supervise you in ‘easy to get job’ areas like ‘quantum computing’, then slip into doing (say) quantum gravity when you get tenure?
On the ad hominem, I have a certain (very outline) impression of your pedagogical philosophy from your posting and was hoping to draw it out a bit more. Anyway, as per request, I will cut this approach…
December 8, 2007 at 11:20 am |
[…] to Space, the issue of Vector Space has undergone a good treatment recently, in Prof Gowers weblog. Do pay attention to Terence Tao’s comment and his linked notes. I […]
August 26, 2015 at 2:24 pm |
Self Help books should be available for those who are not students and are old who study for the fun and as aid to understanding quantum physics etc.