The title of this post is a nod to Terry Tao’s four mini-polymath discussions, in which IMO questions were solved collaboratively online. As the beginning of what I hope will be a long exercise in gathering data about how humans solve these kinds of problems, I decided to have a go at one of this year’s IMO problems, with the idea of writing down my thoughts as I went along. Because I was doing that (and doing it directly into a LaTeX file rather than using paper and pen), I took quite a long time to solve the problem: it was the first question, and therefore intended to be one of the easier ones, so in a competition one would hope to solve it quickly and move on to the more challenging questions 2 and 3 (particularly 3). You get an average of an hour and a half per question, and I think I took at least that, though I didn’t actually time myself.
What I wrote gives some kind of illustration of the twists and turns, many of them fruitless, that people typically take when solving a problem. If I were to draw a moral from it, it would be this: when trying to solve a problem, it is a mistake to expect to take a direct route to the solution. Instead, one formulates subquestions and gradually builds up a useful bank of observations until the direct route becomes clear. Given that we’ve just had the football world cup, I’ll draw an analogy that I find not too bad (though not perfect either): a team plays better if it patiently builds up to an attack on goal than if it hoofs the ball up the pitch or takes shots from a distance. Germany gave an extraordinary illustration of this in their 7-1 defeat of Brazil.
I imagine that the rest of this post will be much more interesting if you yourself solve the problem before reading what I did. I in turn would be interested in hearing about other people’s experiences with the problem: were they similar to mine, or quite different? I would very much like to get a feel for how varied people’s experiences are. If you’re a competitor who solved the problem, feel free to join the discussion!
If I find myself with some spare time, I might have a go at doing the same with some of the other questions.
What follows is exactly what I wrote (or rather typed), with no editing at all, apart from changing the LaTeX so that it compiles in WordPress and adding two comments that are clearly marked in red.
Problem Let 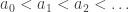

First thought.
Slight bafflement.
Observation.
The expression in the middle is not an average. If we were to replace it by an average we would have the second inequality automatically.
Proof discovery technique.
Try looking at simple cases. Here we could consider what happens when 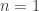

Here we automatically have the first inequality, but there is no reason for the second inequality to be true.
.
Putting those observations together, we see that the first inequality is true when 

If the inequality holds for a unique 

Question.
It is clear that WLOG 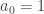

We get 

So 

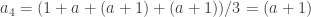

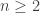
.
Out of interest, what happens to the inequalities when we (illegally) take the above sequence? We get 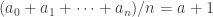

Proof discovery technique.
Try to disprove the result.
Proof discovery subtechnique.
Try to find the simplest counterexample you can.
An obvious thing to do is to try to make the inequality true when 
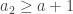
For 
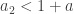
.
That doesn’t solve the problem but it looks interesting. In particular, it suggests rearranging the first inequality in the general case, to
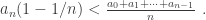
That’s quite nice because the right hand side is a genuine average this time.
Actually, if getting an average is what we care about, we could also rearrange the first inequality by simply multiplying through by 

.
I think it is time to revisit that guess, in order to try to prove at least that there exists a solution. So we know that the first inequality holds when 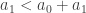
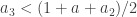
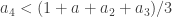
Let’s write 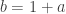
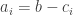
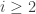
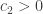
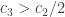

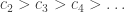
Let’s set 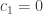
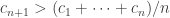
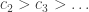
Is it possible with equality? WLOG 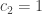

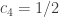
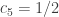
.
I’m starting to wonder whether the integer must be something like 1 or 2. Let’s think about it. We know that 
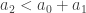

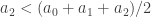
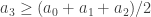
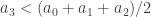
But since 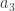
If 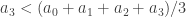

.
I seem to have disproved the result, so I’d better see where I’m going wrong. I’ll try to construct a sequence explicitly. I’ll take 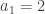
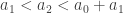
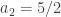
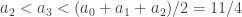
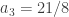

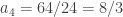
I don’t seem to be getting stuck, so let me try to prove that I can always continue. Suppose I’ve already chosen 

.
By induction we already have that 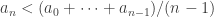
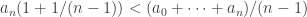
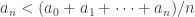
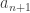
.
You idiot Gowers, read the question: the
Fortunately, the work I’ve done so far is not a complete waste of time. [The half-conscious thought in the back of my mind here, which is clearer in retrospect, was that the successive differences in the example I had just constructed were getting smaller and smaller. So it seemed highly likely that using the same general circle of thoughts I would be able to prove that I couldn’t take the 
.
Here’s a trivial observation: if the second inequality fails, then 


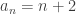
.
Never mind about that. I want to go back to an earlier idea. [It isn’t obvious what I mean by “earlier idea” here. Actually, I had earlier had the idea of defining the 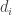
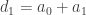
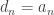
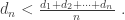
.
So each new 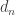
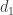
.
I’ve now shown that the first inequality must fail at some point. Suppose
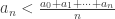
and

The second inequality tells us that 
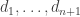
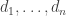

.
So now I’ve proved that there exists an integer 
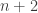
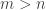

July 19, 2014 at 7:08 pm |
My experience was very different. Here is as much of it as I can remember:
First I have a mental image of the graph of two functions which intersect exactly once. It’s unclear what I can do with this.
Next, I don’t like the condition that the are increasing; in general I find this kind of condition hard to work with. I’d like to replace it with the equivalent condition that the differences
are increasing; in general I find this kind of condition hard to work with. I’d like to replace it with the equivalent condition that the differences 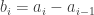 are positive. The desired inequality is now
are positive. The desired inequality is now
But this is something I can do stuff with because now I have a lot of subtractions available. Multiplying everything by and subtracting the middle term from the other two I get
and subtracting the middle term from the other two I get
But now the result is obvious: by hypothesis the are positive, so the sequence
are positive, so the sequence 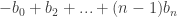 is increasing, starting from a negative value, so it crosses the x-axis exactly once. (That's sort of like my first mental image!)
is increasing, starting from a negative value, so it crosses the x-axis exactly once. (That's sort of like my first mental image!)
At this point I'm worried that this solution is too short so I'm looking over it for obvious mistakes. But everything looks fine to me.
July 20, 2014 at 6:34 am
The integer condition is never used. Whether it’s extra or there’s a fallacy this fact is noticeable.
July 20, 2014 at 9:25 am
It’s used implicitly in the deduction from the fact that the sequence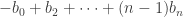 is increasing that it must cross the x-axis.
is increasing that it must cross the x-axis.
July 30, 2014 at 12:44 pm
The result is true if and only if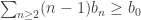 . The case of the $a_i$ integers is just an example.
. The case of the $a_i$ integers is just an example.
July 19, 2014 at 8:34 pm |
Here is how it went for me. I only mention what “occured” to me, since this is what you are probably most interested in, and leave out the computations.
First thought: this cannot be true. Second thought: ah, the middle expression is not an average. So I should make an average out of it. , I get that the conditions can be written
, I get that the conditions can be written 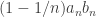 for small n? Yes, n=1 works. Do we have the reverse inequality for large n? Well, assume not (a computation follows). Ah, here we use the hypothesis that the sequence consists of integers (or rather that there is a lower bound on the spacing) to get a contradiction!
for small n? Yes, n=1 works. Do we have the reverse inequality for large n? Well, assume not (a computation follows). Ah, here we use the hypothesis that the sequence consists of integers (or rather that there is a lower bound on the spacing) to get a contradiction!
Thus, defining
July 19, 2014 at 9:13 pm
Many thanks for this. I think WordPress swallowed something between the and the
and the  . (It sometimes does this if you use a less-than symbol instead of writing an ampersand followed by lt; .)
. (It sometimes does this if you use a less-than symbol instead of writing an ampersand followed by lt; .)
July 20, 2014 at 12:40 am |
My process was something like this: (1) What? can’t be right. (2) Oh yes, the denominator is n but there are n+1 terms. (3) Still seems implausible; e.g., if an grows fast then it feels like the average should “always be too small”. (4) Write down the first few cases explicitly and try plugging in an = 2^n, for instance. Observe that then it fails very early; so that’s where my intuition was broken. (5) Notice that our condition is the same as P(n-1) & not P(n) where P(n) is n a_{n+1} < a0+…+an. (6) OK, so we’re saying there’s a unique point where P goes from true to false. (7) Check that not P(n) implies not P(n+1); easy. (8) Check that P(0); easy. (9) So we just have to show that eventually P(n) fails, which seems like it should be easy — a matter of the sequence having to grow more slowly than an integer sequence can. (10) Various bits of scribbling that happened to lead nowhere. (11) Rewrite in terms of the partial sums, whereupon not P(n) turns into something like S(n+1) < n/(n-1) S(n); apply for lots of n and telescope to get S(n+1) < n S(2). (12) This gives us an < (n-1)a0 + a1 easily enough, but where now? (13) Aha, if we take a little more care what we actually get is an < (n-1)a0 + a1 – (1+…+(n-2)) because these are supposed to be strictly increasing integers, and that's no good because the first bit increases linearly but the second decreases quadratically, so eventually an goes negative, contradiction.
I think the total elapsed time was something like 20 minutes or so, but it felt like a lot of it was spent floundering. (Though actually something like that much floundering is usually needed to get one's brain engaged with a problem.)
I had the same initial mental image as Qiaochu Yuan, though I didn't end up with a proof that really matched it. I had the feeling at the end that what I'd done was probably equivalent to something neater — rewriting it in terms of the differences would, I think, translate it into Qiaochu's proof, and I now feel bad for failing to apply the "increasing is awkward; work with differences and positivity" heuristic he did.
I like Qiaochu's proof a lot, but Tim's trick of combining the first two terms to repair the denominator is perhaps even nicer — to me, it seems to express the essence of why the key point (in my terminology, that P(n) ends up false) has to be so.
July 20, 2014 at 5:28 am |
I’m used to constructing a geometric picture in my mind before solving a problem. Then I plot the graph of both and
and 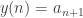 , followed by connecting near points by line segments. What I obtain is a small river flowing from the left-bottom side to right-top side because of monotone property of positive sequence. Now the problem becomes that if there’s a little frog on one side of the river following the route
, followed by connecting near points by line segments. What I obtain is a small river flowing from the left-bottom side to right-top side because of monotone property of positive sequence. Now the problem becomes that if there’s a little frog on one side of the river following the route 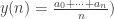 who wants to go across the river, only one rock inside the river (also possibly on the upper bank) is required, although the frog may jump onto that rock, find it boring the other side of the river, and jump back at last.
who wants to go across the river, only one rock inside the river (also possibly on the upper bank) is required, although the frog may jump onto that rock, find it boring the other side of the river, and jump back at last.
Let as the vertical distance between the frog and the lower bank. Note that
as the vertical distance between the frog and the lower bank. Note that 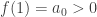 . Assume the frog never cross the river, i.e.
. Assume the frog never cross the river, i.e. 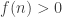 for all n. This is equivalent to
for all n. This is equivalent to  , or
, or 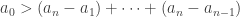 (*). But this is impossible since
(*). But this is impossible since 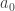 is finite and
is finite and  is increasing. Let $n$ be the time one step before the frog first time land the lower side of the river. Mathematically, we have
is increasing. Let $n$ be the time one step before the frog first time land the lower side of the river. Mathematically, we have 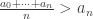 and
and 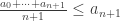 . We immediately obtain
. We immediately obtain 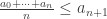 and prove the existence of n making the required inequality hold. To prove the uniqueness, observe from (*) that if
and prove the existence of n making the required inequality hold. To prove the uniqueness, observe from (*) that if  for some n,
for some n,  . That is, the frog will never go back.
. That is, the frog will never go back.
July 29, 2014 at 9:09 pm
Why does it immediately follow that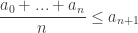 ???
???
We are at the last point before we cross the river but we do not know that do we?
do we?
Thank you
July 30, 2014 at 8:29 am
It follows from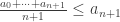 by simple algebraic deductions 🙂
by simple algebraic deductions 🙂
July 30, 2014 at 10:10 am
Oops, there now – thanks.
July 20, 2014 at 10:02 am |
I posted my brain-dump here: http://rgrig.blogspot.co.uk/2014/07/imo-problem-1.html
I must have made some mistake because I got that sometimes two $n$s are possible (see last example).
July 20, 2014 at 11:13 am
Thanks for all that! Your mistake was a transcription error: when you copied the question you didn’t notice that the first inequality had to be strict.
July 20, 2014 at 12:52 pm
Thanks!
July 21, 2014 at 1:10 pm |
An approximate post hoc recollection of my thought processes leading to a not necessarily correct solution (with shocking inconsistency of tense and doubtless many many typos, also I called the sequence elements x instead of a for some reason).
So this is saying that the mean of the first n terms is between the nth term and the (n+1)th term. Well that can’t be right, obviously the mean is smaller than the biggest term, hmm, must have missed something…
…
…Oh ok, there are actually n+1 terms in the sum so it’s not the mean, just something a bit like the mean… in fact I suppose it sort of tends towards the mean
Decided to call the mean-like term y_i. Did some vague thinking about what the y_is were for different sequences – 1,2,3…; 101,102,103… etc. Started thinking about the y_is in terms of whether they’re “too small” (y_i x_(i+1)) or ”just right” (between x_i and x_(i+1) as required). Imagined the sort of standard thing that might be possible where you start with an (in)equality and replace terms with things bigger/smaller to get a new more useful inequality. Thought about things like how a large x in the sequence makes the next y be large.
Now with pencil and paper, tried some of this, and in among some confusing myself, got that if y_i is too small, y_(i+1) is too small, and that if y_i is just right, y_(i+1) is to small (actually these were identical arguments but I did it twice). So there can’t be more than one just right y, and once it gets too small it stays there. But y starts too big (y_1 = x_0+x_1>x_1) so I’d better check it doesn’t stay too big forever.
Some more faffing and thinking, it seems to make sense the ys can’t stay too big, since that means the xs are all bounded by the ys, which are bearing down on the mean, so eventually the whole thing will get trapped. But the same sort of thing I was doing above isn’t yelling me anything (in retrospect for very obvious reasons). After a while I got my head around what needed doing and started doing the right things. It seemed that for y_2 to be too big then x_3 seemed to need to be less than y_1. Similarly then x_4 needed to be less than y_1. Okay, this seemed to be it. The xs increase so they can’t all be less than y_1. I formalised this into an induction argument, showing that the ys can’t stay too big forever. Done!
No wait, not done. The ys could go straight from too big to too small right. Hmm I could do with proving that if y_i is too big, y_(i+1) can’t be too small. Thankfully this worked as an easy argument along the same lines as the too-small-implies-too-small one. Done!
July 21, 2014 at 8:12 pm |
I think I must have got a bit lucky. I started by writing down the first few things we were trying to show to be mutually exclusive:
or else
or else
or else
It immediately jumped out at me that if the RHS of the first thing was false, then that automatically made the LHS of the next thing true, and similarly between the next pair in a way that would obviously extend inductively.
So I tried a couple of trivial rearrangements such as writing down the first differences of the sequence of not-quite-averages, and didn’t go far before I thought to multiply up all the statements to get rid of the denominators
or else
or else
or else
and then subtracted from all three sides of the first statement,
from all three sides of the first statement,  from all three sides of the second,
from all three sides of the second, 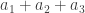 from the third and so on to get
from the third and so on to get
or else
or else
or else
and now it’s clear that what we’re really saying is that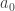 must lie between exactly one pair of terms of this secondary sequence, so if we can show the sequence is increasing then we’re done. And it obviously is: if you set
must lie between exactly one pair of terms of this secondary sequence, so if we can show the sequence is increasing then we’re done. And it obviously is: if you set 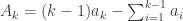 (for
(for  , so we include
, so we include 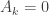 ),
), 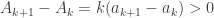 by increasingness of
by increasingness of 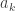 . So clearly there is a unique
. So clearly there is a unique 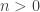 such that
such that 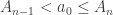 .
.
July 21, 2014 at 8:18 pm |
I only briefly thought about it, yet without attempting to solve it it led to the following (some existential) thoughts.
1) Is it a statement about averages?
2) Ohh, I see. Maybe it will be useful to write the left inequality as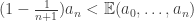 ?
?
3) is the last n to satisfies the left inequality the unique one to satisfy the right?
4) Could computer experimentation help here (and in other Olympiad problems)?
5) Can we automatize a proof. More generally, can we create a good computerized IMO participant?
6) Is it part of a more general interesting question? If yes what? If it is not interesting are the problems I study more interesting? Why?
7) Did I know this question? (Or a very similar one.)
8) Am I still interested in these kind of questions? Should I? I was quite interested when I was 16 years old, but should I be commited to such questions now? (along with others interests from that time)? Is keeping interested a way to keep one youth?
July 22, 2014 at 3:28 pm
I have a more existential question that is closely related to a couple of your questions above, namely this. Suppose one could design a good computerized IMO participant. In order to do that, would we have been forced to develop very general automatic theorem-proving techniques that would generalize to a much wider range of more “important” mathematics, or is it possible that something very fundamental about mathematical research would be missing? I suspect the answer is the latter, but I don’t think it is obvious.
July 22, 2014 at 9:26 pm
What would likely be missing in regard to mathematical research is the ability to deal with thought (6) of Gil Kalai. Can theorem proving software judge whether something is an interesting question or technique, and be able to generalize it to something we recognize as useful, interesting, or beautiful? Carrying this further, can the software itself generate interesting problems, not just interesting to itself, but interesting to people as well?
As an aside, who makes up all these problems anyway? I imagine that it is not an easy task. I recently found old problems of this sort, though probably not quite as hard, in a box in my attic that I had worked on at a math program for high school students at Berkeley about 45 years ago. I gave copies of the problems to UW Math because they deal with talented kids and I knew that creating new problems is not easy.
July 24, 2014 at 7:07 pm
Regarding automated IMO participation vs. automated theorem-proving, a good test case worth thinking about is automated chess playing. My impression is that in the old days it was thought that in order to design a chess AI that could compete with the best human players one would have to essentially create general human-level AI. Of course this turned out to not be the case in a very big way.
July 24, 2014 at 10:20 pm
How about the following revision of the question: to develop an automated chess-playing program that can make its moves instantly and use almost no storage, would one need to develop much more general AI capabilities?
July 22, 2014 at 3:09 pm |
I solved it in about ten minutes. My process was:
is almost an average. I want to work with averages, so I’ll replace it with
(Here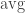 denotes the arithmetic mean.)
denotes the arithmetic mean.)
Actually I compressed it a little further and wrote
Then I wrote two columns, one containing the ‘s and one containing the
‘s and one containing the 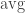 expressions. With a little inspection, it was clear what was going on: at the start, the first column is less than the second column. But the sequence is increasing, so eventually, the first column must grow bigger than the second column. And once it does, it will stay that way. The crossing-over point corresponds to the unique integer
expressions. With a little inspection, it was clear what was going on: at the start, the first column is less than the second column. But the sequence is increasing, so eventually, the first column must grow bigger than the second column. And once it does, it will stay that way. The crossing-over point corresponds to the unique integer  in the problem.
in the problem.
July 23, 2014 at 3:53 am |
This is the first time I’ve done an Olympiad problem, so it was fun. I can vaguely recreate my thought process, part of which was done when trying to sleep now I’m back in my home new time zone. Maybe half an hour to forty minutes of actual effort total over a couple of days.
First: try to get the left-hand inequality, but rewrite it as
i.e.
Rewrite this as
(Originally I made an indexing error here, and it held me up a little, later on, but the analysis continued as in the correct version) can be such that this is true (here I was thinking in terms of differences of terms, but didn’t notice that they formed a sequence of natural numbers just yet). That is, what is the largest number of terms on the LHS with this true? Namely when the gaps between the successive
can be such that this is true (here I was thinking in terms of differences of terms, but didn’t notice that they formed a sequence of natural numbers just yet). That is, what is the largest number of terms on the LHS with this true? Namely when the gaps between the successive 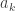 s are all 1, so we can solve for
s are all 1, so we can solve for  . This gives a finite bound on the possible solution
. This gives a finite bound on the possible solution  once we know
once we know 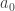 (this fact turned out not to be useful, but encouraging to know the search space was finite). At this point, might as well write this inequality as
(this fact turned out not to be useful, but encouraging to know the search space was finite). At this point, might as well write this inequality as
Now we can guess the maximum that
where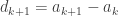 (except first time round, this expression was slightly different, due to the mistake above: the factor
(except first time round, this expression was slightly different, due to the mistake above: the factor  was
was 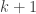 instead).
instead).
Now let’s try the second inequality. Again, change it to
Playing the same trick with the differences gets us the second inequality in the form
Now I thought to perhaps find some extremum for in this case as well, but it was quickly apparent that nothing would come of it. Then I fixed the first rewritten inequality to what is above, and put it together to get
in this case as well, but it was quickly apparent that nothing would come of it. Then I fixed the first rewritten inequality to what is above, and put it together to get
and it was clear I could reformulate the question as follows: given any sequence of natural numbers and any
of natural numbers and any 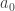 (chosen independently!), there must be a unique $n$ such that the inequalities hold. The previous inequality could be rewritten as
(chosen independently!), there must be a unique $n$ such that the inequalities hold. The previous inequality could be rewritten as ![a_0 \in (f(n-1),f(n)]](https://s0.wp.com/latex.php?latex=a_0+%5Cin+%28f%28n-1%29%2Cf%28n%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where 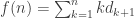 , whence, since
, whence, since  is an increasing unbounded function (and, now that I think of it,
is an increasing unbounded function (and, now that I think of it, 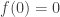 is the only sensible definition given the original statement of the problem), given any natural number
is the only sensible definition given the original statement of the problem), given any natural number 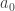 it must necessarily fall into precisely one such interval
it must necessarily fall into precisely one such interval ![(f(n-1),f(n)]](https://s0.wp.com/latex.php?latex=%28f%28n-1%29%2Cf%28n%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
July 24, 2014 at 10:22 pm |
One thing I didn’t mention in the post was that when I first read the problem, I had the strong feeling that there was no way that I wouldn’t be able to solve it reasonably quickly. I don’t have that feeling with all IMO problems. The same phenomenon occurs with problems that arise when I’m doing research. What is the difference between a problem one basically knows will yield after sufficient thought and one that one doesn’t know that about at all?
July 25, 2014 at 2:08 pm |
I am not sure that there is a deep reason behind the feeling that one can solve a problem quickly or not. Isn’t it just about a first impression of similarity to problems that one has solved before?
Something like: ah – the problem has to do with sums of arrays and some kind of average – seen that before … I have some techniques I could use,
It would be interesting to know if that intuition is 100% reliable (well I suppose Turing forbids 100% – 90% then).
I have an counter example of failing intuition: the problem is how many license plates numbered 000000-999999 can be used if each plate must differ from any other in at least 2 places (rather than 1)? Should be easy, right? But I got stuck. I guess I need a flash of inside like in the dominoes-on-a-chessboard problem.
PS I am not a mathematician, but an engineer who reads your blog with great interest.
July 26, 2014 at 12:39 pm |
My thought process:
0. The middle term looks sort of like average. Try multiplying both sides by n. Unclear what to do with that…
1. Hmm. We have two inequalities. Let’s figure out whether we can get at least one of them to hold for some n and then worry about getting both. [= start by proving a weaker statement]
2. A silly guess – maybe LHS simply implies RHS? Quick computation shows that not… but as a by-product of this computation, I got: if RHS hold for n, then LHS doesn’t hold for n+1 ! This sounds like progress.
3. Carrying this line of thought further, I immediately obtain that LHS and RHS are both “monotone” (hold up to some point and then don’t or vice versa).
4. By Observation 2, the only scenario we have to worry about is when neither LHS nor RHS hold. But then we immediately arrive at contradiction with the assumption that a_n is increasing!
July 27, 2014 at 6:20 pm |
You solve problems with LaTeX yet? There is a better (WYSIWYG) alternative: TeXmacs. It is much easier to write snippets of math with this software rather than with both LaTeX or pen/paper. LaTeX is from the previous century.
July 28, 2014 at 12:52 am |
I watched this great and inspiring talk a few weeks ago so it would be a pleasure to share my experience with the problem. Unfortunatley my approach is not to different to the ones alleady mentioned. But since i already wrote it down, i’ll post it anyway :-).
Here’s how i approached problem:
Insight 1: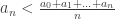 and trying to build the proof up from there. If you decompose the right side of the inequality into
and trying to build the proof up from there. If you decompose the right side of the inequality into 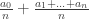 , you get
, you get 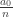 and the arithmetic mean of
and the arithmetic mean of  . I noticed that the inequality holds for
. I noticed that the inequality holds for  but has to break eventually as the arithmetic mean declines in proportion to
but has to break eventually as the arithmetic mean declines in proportion to 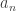 and you have
and you have 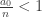 as
as  gets large.
gets large.
I started by focussing on the first inequality
This insight led me to propose a helping Lemma 1:
for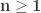 :
:  with
with  if
if  and
and 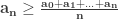 if
if 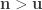
It’s relatively straightforward to see, that the proof of Lemma 1 can be divided into 3 parts:
(1) The first inequality holds for n = 1
obvious
(2) The first inequality breaks for some n
This can be seen by setting . For the arithmetic mean, you have:
. For the arithmetic mean, you have:
 as
as 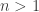 . As the inequality has integers on both sides and
. As the inequality has integers on both sides and 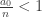 it follows that:
it follows that: 
(3)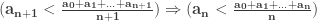
A simple transformation of the inequality is sufficient:
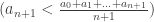

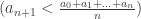

=
=
qed
Insight 2: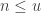 and fails otherwise. It would make sense to assume that the right inequality
and fails otherwise. It would make sense to assume that the right inequality 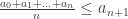 holds for all n above a certain bound
holds for all n above a certain bound 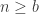 and fails otherwise. As the solution that satisfies both inequalities has to be unique, it also makes sense to assume
and fails otherwise. As the solution that satisfies both inequalities has to be unique, it also makes sense to assume 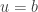 . These assumptions leads to the following case analysis:
. These assumptions leads to the following case analysis:
It’s now clear that the left inequality holds for all n below a certain bound
Case 1)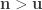 :
:
The left inequality fails.
Case 2) :
:
We know that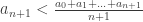 , therefore we can follow like in step (3) in Lemma 1 that:
, therefore we can follow like in step (3) in Lemma 1 that: 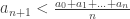 which violates the right inequality.
which violates the right inequality.
Case 3) :
:
The left inequality is guaranteed to be true, as for the right inequality we have:

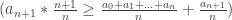
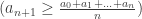
=
=
July 28, 2014 at 1:15 am |
Oh, there’s an error in Lemma 1 as n doesn’t have to be preselected.
It should be:
July 29, 2014 at 4:59 pm |
I believe that the moment when the problem was cracked open was after the second red comment in defining the d_i. It is very interesting that this “key trick” had occurred to you earlier, yet you did not record it despite this being an exercise in writing down as many relevant thoughts as possible. Perhaps somehow the subconscious retains and mulls over promising, (usually) simple insights, while we actively pursue “obvious things to try” (even if they may be sophisticated mathematical techniques). I think that this phenomenon arises in research but on a much greater scale.
Also, you were forced to record your thoughts to a linear transcript, whereas surely you are having multiple ideas interconnecting in various ways. This inadequacy of a linear medium is probably what led you to initially not record the idea that ended up playing a key role, as you yourself mention in the second red comment. This is not to say that everything else was a waste of time. There were many constructive insights before you chose to revisit the idea that on the surface appears only to be a slight notational change.
This dichotomy between linearity (of how we learn and communicate mathematics) and interconnection (of how we deeply understand areas of mathematics) plays a key role in the difficulty in teaching mathematics.
July 30, 2014 at 7:14 am
You are quite right to imply that my attempt to write down my thoughts was not a complete success, and unfortunately the point where I failed, thanks to a moment of laziness that I later regretted, was an important one.
I do, however, have some idea of the source of the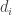 trick. It came in the section near the beginning labelled “Question”, where I took
trick. It came in the section near the beginning labelled “Question”, where I took 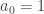 ,
,  and then found that everything else was
and then found that everything else was 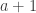 . That suggested that
. That suggested that 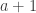 was more important than either
was more important than either  or
or  individually.
individually.
July 31, 2014 at 12:54 pm |
I solved it on a train to NYC with a friend in a sort of mini-mini-polymath. It took about 15 minutes or so. Basically the key insight was to notice that the problem does not change if we subtract 1 from $a_i$ for all $i \geq 1$. Thus, we may assume $a_1=0$ and the middle expression really is an average. I think this was basically isomorphic to Tim’s $d_i$ trick.
August 3, 2014 at 12:52 am |
I have either solved it or almost solved it, but first I want to understand your thoughts in detail. (FYI I participated in the 1979 IMO in London.)
I lose you at this point: why is the following obvious? Or more precisely, what thought did you have, but fail to record, which makes it obvious?
It is clear that WLOG a_0=1.
(I don’t see any obvious way to transform a vector of a’s to one with a_0 = 1 without changing the truth of any inequality in the problem, which is what I’d think you’d need to see to make this obvious.)
I have not read ahead in your answer or anyone else’s, or tried hard to answer this subquestion myself, since I want to help make your record of thoughts complete. In other words, I hope you will remember or somehow reconstruct what you thought then, rather than answering it anew.
August 3, 2014 at 6:22 pm
The answer to your question becomes clear if you read on, which you are deliberately not doing. But I don’t think it’s spoiling much if I tell you that at that point I had not noticed that the have to be positive integers, rather than positive real numbers. If they’re reals, then it really is obvious, since multiplying everything by a positive constant doesn’t affect the inequalities.
have to be positive integers, rather than positive real numbers. If they’re reals, then it really is obvious, since multiplying everything by a positive constant doesn’t affect the inequalities.
August 3, 2014 at 9:24 pm
I see, thanks. Your entire thought-flow is now clear, but I’ll point out two minor issues anyway:
> In particular, it suggests rearranging the first inequality in the general case, to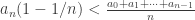 .
.
>
>
I think you meant, or should have meant,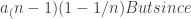 latex a_2<(a_0+a_1+a_2)/2$, we can simply insert
latex a_2<(a_0+a_1+a_2)/2$, we can simply insert 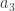 in between the two.
in between the two.
It took me awhile to understand what "two" you meant here — the two terms of that inequality.
August 3, 2014 at 9:32 pm |
I don’t understand what went wrong with the latex formatting I used above, but my reply came out mostly unintelligible, so here is “what I meant” in the messed-up part:
I think you meant, or should have meant, that first a_n to be a_(n-1).
> But since $ a_2<(a_0+a_1+a_2)/2$, we can simply insert $ a_3$ in between the two.
It took me awhile to understand what "two" you meant here — the two terms of that inequality.
August 3, 2014 at 10:41 pm |
As for my own thought-flow as I (partly) solved it, which I wrote down at the time (yesterday), I’ll just sketch it here so as not to be too redundant. (I have so far read yours but no one else’s.) I also was not trying as much as you were to record all informal aspects of it. (In retrospect I am unable to reconstruct some of my informal reasoning; if someone was serious about recording things like this in full detail, also making an audio recording of “thinking out loud” would probably be useful.)
I noticed the first inequality always holds for n = 1.
I worked on the uniqueness requirement for the special n (as opposed to its existence) first. (In retrospect, I’m not sure if that was because it seemed weirder, or seemed easier, or both.)
I multiplied each inequality through by n (just to make them easier to work with), and later noticed that the resulting second inequality for n, after adding a_(n+1) to both sides, becomes exactly inverse to the first inequality for n+1. I also noticed that (for any given n) if the first inequality is false, the 2nd one is true (due to ordering of the a’s). (This was natural to notice, since I was trying to understand all the ways those middle terms could insert themselves in between some pair of successive a_i’s.)
This proves uniqueness, since looking at the state of the two inequalities for successive n, “yes yes” must be followed by “no yes”, which must also be followed by “no yes”. (I think getting this far took 10-20 minutes.)
Then I worked on “existence of n” in some ways I won’t record here, except for what eventually either worked or almost worked. It’s clear from the info above that if the special n never exists, the inequality-pairs for successive n are all “yes no”. This means the almost-average (middle term) is bigger than the sequence itself (last term), which is weird given that the sequence is increasing. So let’s look at how fast the middle term might be increasing. Asymptotically, either the sequence of a’s is linear with some slope, or superlinear (this is the part of my solution I am only claiming “almost works” since I never did formalize it as much as I’d like to), and clearly a_n >= n + 1 (from original problem statement) so that slope is at least 1. But if it was actually linear, then for large enough n the average would be about 1/2 the last term, and the almost-average used here (which sets an upper limit for the new term under our assumptions) is only (n+1)/n times the average, a contradiction since (n+1)/n << 2.
I convinced myself "morally" that argument was valid (even for sequences a_i which go above some line infinitely often, but more and more rarely as n increases), but not formally enough to consider it solved. I also tried to come up with a non-asymptotic version, but I can't remember if I really did, or if I lost motivation to continue at some point. (I had stopped for dinner and then was no longer writing things down after that.)
August 9, 2014 at 10:27 am |
But everyone already knew this problem had an elementary solution, because otherwise it would not be a proposed problem in the olympiad.
What would happen if a professor gave as homework to his students some open problem without telling them it’s open? (and assuming they don’t know it, and a problem that doesn’t look hard) I think they would become frustrated for not being able to solve it much more than if they already knew it was a very hard problem.
Sorry for my bad English. I was never able to learn this crazy language.
August 9, 2014 at 11:02 am
The question of how it affects one’s approach to a problem if one knows that it has been set in an Olympiad is a very interesting one. It definitely gives a big clue about the nature of the solution, but making precise what the clue is is not easy. But it often seems to involve finding a “key” that suddenly unlocks the problem, whereas in a “real” problem there often isn’t such a key and what is required is more like hard grind. But of course, sometimes even research problems can be unlocked in a beautiful way: it’s just that that is not as common as it is in Olympiads.
May 10, 2015 at 7:17 am
Isn’t that basically what is said to have happened when George Dantzig arrived late for a lecture by Jerzy Neyman on mathematical statistics (see the Wikipedia page for George Dantzig, the Mathematical statistics subsection)?
August 12, 2014 at 7:52 pm |
[…] Tim Gowers walks through an IMO problem […]
April 22, 2016 at 3:14 pm |
[…] Tim Gowers walks through an IMO problem […]
June 10, 2016 at 3:02 pm |
Another data point. I was quite proficient with these contest problems in my youth, currently I can often solve them given some time and patience. I definitely lack the patience when the problems have no intrinsic appeal or connection to theory. In this case, the simple statement that looks like an average drew me in.
My process could be described as “micro-monomath” since it involves a step not in the ordinary rules.
– (1 minute) scan the post and comments quickly to see if there is a one-line “aha!” solution or keywords linking the problem to some more theoretical concepts beyond the IMO. No, the symbols and every-tenth-word look more like a bunch of algebra and calculation, so I decided to attempt to solve this myself.
– (8 minutes) look for a formulation with averages. This didn’t work, these are not quite averages. Had the indexing started at a_1 instead of a_0 this would have been easier to notice, but I slowly came around to it.
– (5 minutes) Forget about averages and work with integers, since the statement looks suspicious in the generality of real numbers. We need an increasing integer function g(n) that starts negative and therefore crosses 0 at a unique point. The first candidate that comes to mind is g(n)= n a(n) – (a(0) + a(1) + … + a(n) ) and this works.
Writing everything up might have doubled or tripled the time. I used pencil and paper only at the last step, to verify that g(n) works after having decided to try it.
The key heuristic guiding the failed first step and the successful last step was that there should be a statement that (except for the sign of the inequality) is the same for a_n and a_(n+1). For example the same function g(n) is used at points n and (n+1). And in the averaging formulation, the idea was that a_n should be below average for the first n or n+1 terms or something, and a_(n+1) should be above average in the exact same sense. Although averages seemed more intuitive at first, that path runs in circles and it was easier to junk it and switch to “multiplying out” everything so as to work with integers.
November 16, 2018 at 3:50 pm |
I was thinking about this :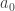 then everything would appear like an arithmetic mean and that would have been pleasant (so far no words about how the result would have appeared). But life is not so pleasant as we have a
then everything would appear like an arithmetic mean and that would have been pleasant (so far no words about how the result would have appeared). But life is not so pleasant as we have a 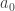 and that can’t be $0$. Now, note that
and that can’t be $0$. Now, note that 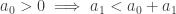 . So, if we can show the existence of some unique integer
. So, if we can show the existence of some unique integer  satisfying the given inequality, we are done (in simple words, we don't have to make our hands dirty to show that such a integer must positive). Now, can the left most inequality be true for every positive integer
satisfying the given inequality, we are done (in simple words, we don't have to make our hands dirty to show that such a integer must positive). Now, can the left most inequality be true for every positive integer  . Let's see : multiplying out both sides of the leftmost inequality by
. Let's see : multiplying out both sides of the leftmost inequality by  and then subtracting what remains on the left side from what remains on the right side gives us the equivalent inequality
and then subtracting what remains on the left side from what remains on the right side gives us the equivalent inequality  and a quick observation is that this is
and a quick observation is that this is 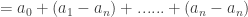 and since we know that the sequence is increasing so life's good as the above quantity can't always be positive (since everything is an integer and after subtraction things are decreasing). At some point it has to hit some non negative number and that point will be determined by what $a_0$ is. Then immediately everything in the remaining solution was quite visible. We will take the largest such
and since we know that the sequence is increasing so life's good as the above quantity can't always be positive (since everything is an integer and after subtraction things are decreasing). At some point it has to hit some non negative number and that point will be determined by what $a_0$ is. Then immediately everything in the remaining solution was quite visible. We will take the largest such  for which the above inequality holds. And then all that remains to be seen is that once it hits a non negative number, it can't become positive anymore, as after the subtraction everything was decreasing here. So we get a largest
for which the above inequality holds. And then all that remains to be seen is that once it hits a non negative number, it can't become positive anymore, as after the subtraction everything was decreasing here. So we get a largest  for which the Left inequality holds. And if there is any truth in the world, then the right inequality must hold for some $k \le n$. And this largest
for which the Left inequality holds. And if there is any truth in the world, then the right inequality must hold for some $k \le n$. And this largest  gives everything that we want, because the right inequality is no different than what we were trying to avoid while ensuring that the left inequality gets satisfied. Clear denominators and add and subtract
gives everything that we want, because the right inequality is no different than what we were trying to avoid while ensuring that the left inequality gets satisfied. Clear denominators and add and subtract 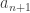 and the RHS of the right inequality from the LHS of the right inequality and we will get everything we want.
and the RHS of the right inequality from the LHS of the right inequality and we will get everything we want.
If we could get rid of
If I am not wrong then this was also one of the official solutions (but I had no connections with the jury, and obviously didn't know about the official solution or any other solution at the time of solving)……
Actually I believe that my solution was along these lines mainly for two reasons : first, my brain somehow always thinks of trading terms (like you give one value to one side and you have to compensate it with adding another value and so on……) and secondly because at that time I was probably very obsessed with the Well Ordering principle and so somehow something along the lines of finding the first point where something goes wrong or where something is satisfied was occupying my thinking procedure and fortunately it worked.
(PS : I did not know about the existence of this topic until today and so I am sorry if I am bumping an old topic).