This is the first of two posts about the difficulty of proving that P NP. The next post will contain yet another discussion (there are many of them online) of the famous paper Natural Proofs, by Razborov and Rudich. This one will set the scene by describing a couple of related but less rigorous arguments. I’m writing them because I’ve been fascinated by the natural proofs result ever since I heard about it on a car journey with Michael Saks about twelve years ago, but up to now I’ve been too lazy to follow its proof in detail. I’m now determined to put that right and writing a couple of blog posts seems a good way of forcing myself to read it properly. Although the proof is short, it has certain aspects that have made it hard for me to get my head round it, so I’ll try to write something considerably longer than what Razborov and Rudich write. I’ll assume knowledge of basic definitions such as Boolean functions, circuits, P, and NP. Also, throughout the posts I’ll write as though
NP. The next post will contain yet another discussion (there are many of them online) of the famous paper Natural Proofs, by Razborov and Rudich. This one will set the scene by describing a couple of related but less rigorous arguments. I’m writing them because I’ve been fascinated by the natural proofs result ever since I heard about it on a car journey with Michael Saks about twelve years ago, but up to now I’ve been too lazy to follow its proof in detail. I’m now determined to put that right and writing a couple of blog posts seems a good way of forcing myself to read it properly. Although the proof is short, it has certain aspects that have made it hard for me to get my head round it, so I’ll try to write something considerably longer than what Razborov and Rudich write. I’ll assume knowledge of basic definitions such as Boolean functions, circuits, P, and NP. Also, throughout the posts I’ll write as though  is a fixed large integer, when what I’m really talking about is a sequence of integers that tends to infinity. (For instance, I might say that a function
is a fixed large integer, when what I’m really talking about is a sequence of integers that tends to infinity. (For instance, I might say that a function  can be computed in polynomial time. If is a fixed integer, then that is a meaningless statement, but one can easily convert it into a meaningful statement about a sequence of Boolean functions on larger and larger domains.)
can be computed in polynomial time. If is a fixed integer, then that is a meaningless statement, but one can easily convert it into a meaningful statement about a sequence of Boolean functions on larger and larger domains.)
I have a secondary motivation for the posts, which is to discuss a way in which one might try to get round the natural-proofs barrier. Or rather, it’s to discuss a way in which one might initially think of trying to get round it, since what I shall actually do is explain why a rather similar barrier seems to apply to this proof attempt. It might be interesting to convert this part of the discussion into a rigorous argument similar to that of Razborov and Rudich, which is what prompts me to try to understand their paper properly.
But first let me take a little time to talk about what the result says. It concerns a very natural (hence the name of the paper) way that one might attempt to prove that P does not equal NP. Let 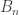 be the set of all Boolean functions . Then the strategy they discuss is to show on the one hand that all functions in that can be computed in fewer than
be the set of all Boolean functions . Then the strategy they discuss is to show on the one hand that all functions in that can be computed in fewer than 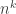 steps have some property of “simplicity”, and on the other hand that some particular function in NP does not have that simplicity property.
steps have some property of “simplicity”, and on the other hand that some particular function in NP does not have that simplicity property.
Now if one wants to design a proof along those lines, it is important that the simplicity property shouldn’t be trivial. By that I mean that it shouldn’t be a property such as “can be computed in fewer than steps”. The good news about that kind of property is that it is probably true that it distinguishes between your favourite NP-complete function and functions that can be computed in fewer than steps. But the obvious bad news is that proving that this is the case is trivially equivalent to the problem we are trying to solve.
The moral of that silly example is that we are looking for a property that is in some sense genuinely different from the property of being computable in at most steps. Without that, we’ve done nothing.
There are plenty of other silly examples, like “can be computed in fewer than  steps”, which are slightly less trivial but unsatisfactory in exactly the same way. So what we really want is some kind of simplicity property that isn’t obviously to do with how easy a function is to compute — it is that air of tautology that makes certain properties useless for our purposes.
steps”, which are slightly less trivial but unsatisfactory in exactly the same way. So what we really want is some kind of simplicity property that isn’t obviously to do with how easy a function is to compute — it is that air of tautology that makes certain properties useless for our purposes.
Now one way that we might hope to make the simplicity property non-trivial in this sense is if it is somehow simpler to deal with than the property of being computable in a certain number of steps.
Let me pause here to stress that there are two levels at which I am talking about simplicity here. One is the level of Boolean functions: we want to show that some Boolean functions are simple and some are not, according to some as yet unformulated definition of simplicity. The other is the level of properties of Boolean functions: we want our simplicity property to be in some sense simple itself, so that it doesn’t have the drawback of the tautologous examples. So one form of simplicity concerns subsets of  (which are equivalent to Boolean functions in ) and the other concerns subsets of , which can be identified with subsets of
(which are equivalent to Boolean functions in ) and the other concerns subsets of , which can be identified with subsets of  , a
, a  -dimensional discrete cube.
-dimensional discrete cube.
Why do we want the simplicity property to be itself simple? There are two potential advantages. One is that it will be easier to prove that some Boolean functions are simple and other Boolean functions are not simple if the simplicity property is not too strange and complicated. The other is that if the simplicity property is simple, then it will give us some confidence that it is not one of the semi-tautologous properties that get us nowhere.
The basic idea for the lazy
This second point isn’t obvious — how do we know that the property of being computable in at most steps corresponds to a very complicated subset of the -dimensional Boolean cube? The result of Razborov and Rudich gives a surprisingly precise answer to this question, but if you just want to convince yourself that it is probably true, then a short and easy nonrigorous argument is enough, and provides a good introduction to the slightly longer rigorous argument of Razborov and Rudich.
The basic philosophy behind the argument is this: a random efficiently computable function is almost impossible to distinguish from a random function. So if we let 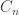 be the subset of that consists of all Boolean functions computable in at most steps, then looks very like a random subset of . (Recall that is the set of all Boolean functions on , so is a set of size
be the subset of that consists of all Boolean functions computable in at most steps, then looks very like a random subset of . (Recall that is the set of all Boolean functions on , so is a set of size 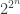 .)
.)
Let me briefly argue very nonrigorously (this is not the nonrigorous argument I was talking about two paragraphs ago, but an even vaguer one). A property of Boolean functions can be identified with a subset of . A simple property of Boolean functions can therefore be thought of as a simple subset of . A very general heuristic tells us that if  is a set,
is a set,  is a simple subset of of density
is a simple subset of of density  and
and  is a “random-like” subset of of density
is a “random-like” subset of of density  , then
, then  has density roughly
has density roughly  . That is, there is almost no correlation between a simple set and a random-like set. If we were to say “random” instead of “random-like”, then this kind of statement can often be proved using an easy counting argument: for each , the probability that has density significantly different from is very small. (I’m taking to be a random set of density .) Since there aren’t very many simple sets, most sets have the property that they do not correlate with any simple sets.
. That is, there is almost no correlation between a simple set and a random-like set. If we were to say “random” instead of “random-like”, then this kind of statement can often be proved using an easy counting argument: for each , the probability that has density significantly different from is very small. (I’m taking to be a random set of density .) Since there aren’t very many simple sets, most sets have the property that they do not correlate with any simple sets.
Suppose that that argument transferred from random sets to “random-like” sets and that the set of functions computable in at most steps is a “random-like” subset of . That will tell us that if is any simple simplicity property, then the probability that a random function in has property is almost the same as the probability that a random function in has property . It follows that if all functions in are simple (as we want for the proof strategy to get off the ground), then almost all functions in must be simple. But that’s saying that a random function should be simple (with high probability), which hardly sounds like the sort of simplicity property we know and love.
The statement of Razborov and Rudich’s main theorem is starting to take shape. What the above argument suggests is that if we want to use a simplicity property to show that 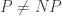 then we have an unwelcome choice: either has to be a strange and complicated property or almost all Boolean functions must have property . Razborov and Rudich formulate a precise version of this statement and prove it subject to the assumption that pseudorandom generators exist — an assumption that is widely believed to be true.
then we have an unwelcome choice: either has to be a strange and complicated property or almost all Boolean functions must have property . Razborov and Rudich formulate a precise version of this statement and prove it subject to the assumption that pseudorandom generators exist — an assumption that is widely believed to be true.
Why should we believe that the set of easily computable functions is a “random-like” set?
The previous section leaves a number of unjustified statements. Before I attempt to justify them, let me make two remarks. The first is that I haven’t said what I mean by the set of all functions computable in at most steps. Am I putting some bound on the size of the Turing machine that does the computation? If so, how?
The second remark is that for the general idea to be valid (that simple simplicity properties won’t distinguish between efficiently computable functions and arbitrary functions), it is enough if we can find some set of efficiently computable functions and convince ourselves that it looks like a random set. It doesn’t matter whether is the set of “all” efficiently computable functions, so we don’t have to decide what “all efficiently computable functions” even means. So that deals with the problem just mentioned.
I now want to describe a set of functions of low circuit complexity. This is not the same as low computational complexity, so the remarks I am about to make concern the question of how one might distinguish between NP and the class of functions of polynomial circuit complexity. Since functions computable in polynomial time can be computed with polynomial-sized circuits, this would be enough to show that ; indeed, it is one of the main strategies for showing it.
Let us define a 3-bit scrambler to be a function  of the following form. Let
of the following form. Let  be a subset of
be a subset of  of size 3, and assume for convenience that
of size 3, and assume for convenience that  . Let
. Let  be a permutation of
be a permutation of  . (That is, it takes the eight points in and permutes them in some way — it doesn’t matter how.) Then takes an -bit Boolean sequence
. (That is, it takes the eight points in and permutes them in some way — it doesn’t matter how.) Then takes an -bit Boolean sequence 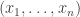 and “does to
and “does to 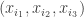 “. I hope that that informal definition will be enough for most people, but if you want a formal definition then here goes. Let’s define
“. I hope that that informal definition will be enough for most people, but if you want a formal definition then here goes. Let’s define  to be the projection that takes an -bit sequence to the sequence , and let’s define
to be the projection that takes an -bit sequence to the sequence , and let’s define  to be the “insertion” that takes a pair of sequences and
to be the “insertion” that takes a pair of sequences and  and replaces the bits
and replaces the bits  and
and  by
by 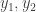 and
and  , respectively. Finally, if
, respectively. Finally, if  is an -bit sequence, define
is an -bit sequence, define 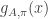 to be
to be 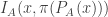 . In other words, we isolate the bits in
. In other words, we isolate the bits in  , apply the permutation
, apply the permutation  , and then stick the resulting three bits back into the slots where the original three bits came from.
, and then stick the resulting three bits back into the slots where the original three bits came from.
A simple example of a 3-bit scrambler is the map that takes an -bit sequence and performs the following operation. If the first three bits are 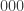 , then it replaces them by
, then it replaces them by 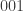 ; if the first three bits are , then it replaces them by ; otherwise it does nothing.
; if the first three bits are , then it replaces them by ; otherwise it does nothing.
It is easy to see that any 3-bit scrambler can be created using a circuit of bounded size. Therefore, a composition of  3-bit scramblers has circuit complexity at most
3-bit scramblers has circuit complexity at most  for some absolute constant
for some absolute constant  .
.
What’s nice about 3-bit scramblers is that they give us a big supply of pretty random looking functions of low circuit complexity: you just pick a random sequence of 3-bit scramblers and compose them. That gives you a function from to , but if you want a function from to  you can simply take the first digit.
you can simply take the first digit.
Now I would like to convince you, with a complete absence of anything so vulgar as an actual proof, that a random function created in this way is hard to distinguish from a genuinely random function. Let’s think about what a 3-bit scrambler looks like geometrically. If we have the function , then there is a sense in which what it does depends only on the bits in . But what is that sense, since the image depends on all the bits of  ? A nice way to look at it is this. The Boolean cube can be partitioned into eight parts according to the values at the three bits in . Each of these parts is a subcube of codimension 3. The effect of
? A nice way to look at it is this. The Boolean cube can be partitioned into eight parts according to the values at the three bits in . Each of these parts is a subcube of codimension 3. The effect of  is to apply a permutation to those eight parts, which it carries out in the simplest way possible. For example, if part X is to move to part Y, then it is simply translated there: the bits inside are changed but the bits outside are not changed. So you chop up the big cube into eight bits and swap those bits around without rotating them or altering their internal structure in any way.
is to apply a permutation to those eight parts, which it carries out in the simplest way possible. For example, if part X is to move to part Y, then it is simply translated there: the bits inside are changed but the bits outside are not changed. So you chop up the big cube into eight bits and swap those bits around without rotating them or altering their internal structure in any way.
I like to think of this as a sort of gigantic Rubik’s cube operation. The analogy is not perfect, since rotation does take place in a Rubik’s cube. However, what the two situations have in common is a set of fairly simple permutations that can combine to create much more complicated ones. In fact, the 3-bit scramblers generate every even permutation of the set . This isn’t obvious, but isn’t a massively hard result either. It is false for 2-bit scramblers, because those are all affine over 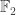 .
.
Consider now the following problem: you are given a scrambled Rubik’s cube and asked to unscramble it in at most 15 moves. The worst positions are known to need 20 moves. Of course, I’m assuming that at most 15 moves have been used for the scrambling — in fact, let’s assume that those 15 moves were selected randomly. As far as I know, finding an economical unscrambling is a hard problem, one that in general you shouldn’t expect to be able to solve except by brute force. A good reason for expecting it to be hard is that it’s very much in the territory of problems that are known to be not just hard but impossible, such as solving the word problem in groups.
And now consider a closely related problem: you are given a Rubik’s cube to which a random 15 moves have been applied, and another Rubik’s cube that is scrambled uniformly at random (that is, it is in a random position chosen uniformly from all positions reachable from the starting configuration), and are asked to guess which is which. Is there some quick way of making a guess that is significantly better than chance?
If you agree that the answer is probably no, then you should be even readier to agree that the answer is no for the corresponding problem concerning 3-bit scramblers, since those are all the more complicated. But I suppose I shouldn’t say that without providing a little bit of evidence that they really are complicated. For that I’ll refer to a paper of mine that was published in 1996, where I showed that if you compose a random sequence of  3-bit scramblers, then the resulting permutation of the Boolean cube is almost -wise independent for some that depends in a power-type way on and , meaning that if you choose any distinct sequences, then their images are approximately uniformly and independently distributed. This gives a reasonably strong sense in which a random composition of 3-bit scramblers looks like a random permutation of . Of course, it’s a long way from a proof that a random composition of 3-bit scramblers cannot be efficiently distinguished from a random permutation, but that’s not something we’re going to be able to prove any time soon, since it would imply that . However, it is a reassuring piece of evidence: although the idea that these random scramblings are hard to distinguish from genuinely random functions is quite plausible, it is good to have some reason to believe that this plausibility is not a mirage.
3-bit scramblers, then the resulting permutation of the Boolean cube is almost -wise independent for some that depends in a power-type way on and , meaning that if you choose any distinct sequences, then their images are approximately uniformly and independently distributed. This gives a reasonably strong sense in which a random composition of 3-bit scramblers looks like a random permutation of . Of course, it’s a long way from a proof that a random composition of 3-bit scramblers cannot be efficiently distinguished from a random permutation, but that’s not something we’re going to be able to prove any time soon, since it would imply that . However, it is a reassuring piece of evidence: although the idea that these random scramblings are hard to distinguish from genuinely random functions is quite plausible, it is good to have some reason to believe that this plausibility is not a mirage.
It is important be clear here what “hard to distinguish” means, so let’s pause for a moment and think how we could distinguish between random compositions of 3-bit scramblers and genuinely random even permutations of . (Again, if you want to talk about functions to instead, then take first digits. It doesn’t affect the discussion much.) To be precise about what the problem is asking, you are given two even permutations of , one a random composition of 3-bit scramblers and the other an even permutation chosen uniformly at random. Your task is to guess which is which with a probability significantly better than 1/2 of being correct. The question is how much computer power you need to do that.
The only obvious strategy is brute force: you look at every composition of 3-bit scramblers and see whether any of the resulting permutations is equal to one of the two permutations you’ve been given. If it is, then with very high probability that’s the one that was not chosen purely randomly. (It’s possible, but extraordinarily unlikely, that a purely random even permutation just happens to be a composition of 3-bit scramblers.)
The number of compositions of 3-bit scramblers is 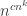 , which is bigger than exponential, so this strategy is very expensive indeed. In fact, it’s superpolynomial not just in but also in , which is a more appropriate measure, since to specify the problem we need to specify in the region of bits of information: the values taken by the two permutations. (It’s actually more like
, which is bigger than exponential, so this strategy is very expensive indeed. In fact, it’s superpolynomial not just in but also in , which is a more appropriate measure, since to specify the problem we need to specify in the region of bits of information: the values taken by the two permutations. (It’s actually more like 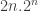 , though that’s a slight overestimate since we know that both functions are even permutations.)
, though that’s a slight overestimate since we know that both functions are even permutations.)
What is in terms of ? Well, let’s write  . Then
. Then  (here
(here  is a constant that can vary from expression to expression), so
is a constant that can vary from expression to expression), so  . A polynomial function of takes the form
. A polynomial function of takes the form 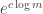 , so this is distinctly bigger.
, so this is distinctly bigger.
I said that this part of the post would not be rigorous, but that is slightly misleading, since I have just proved something rigorous: that if being able to detect the output of a 3-bit scrambler with probability better than chance is a hard problem, in the sense that the best algorithm is not much better than brute force, then the ugly choice described earlier really is necessary: if you want a property that distinguishes between functions computable by polynomial-sized circuits and arbitrary functions, then either that property will have to be one that cannot be computed in polynomial time (as a function of ) or it will have to apply to almost all functions.
The drawback with this argument is that its interest depends on the unsupported assertion that the 3-bit-scrambler problem is hard. What Razborov and Rudich did was similar, but they used a different assertion — also unproved, but more convincingly supported — namely that factorizing is hard.
Does it matter if almost all functions are “simple”?
Before I get on to how Razborov and Rudich did that, I want to discuss an approach to showing that that initially appears to get round the difficulty I’ve just described. Recall that the difficulty is this. If is a property of Boolean functions that applies to all functions of circuit complexity at most , then if certain problems that look very hard really are very hard, it follows that either is not computable in polynomial time (as a function of ) or applies to almost all functions.
In the latter case, it seems unreasonable to think of as a “simplicity” property. But so what? Do we need a simplicity property? Another idea is to have what one might think of as a “making-progress” property. Suppose, for example, that we are trying to prove that the problem of detecting whether a graph  has a clique of size is of superpolynomial circuit complexity. Perhaps we could define some kind of measure that we could apply to Boolean functions, such that the higher that measure was, the more information the Boolean functions would, in some sense, contain about which graphs contained cliques of size and which did not.
has a clique of size is of superpolynomial circuit complexity. Perhaps we could define some kind of measure that we could apply to Boolean functions, such that the higher that measure was, the more information the Boolean functions would, in some sense, contain about which graphs contained cliques of size and which did not.
There is a well-known argument that instantly kills this idea. Let’s suppose that our measure of progress towards detecting cliques is not completely stupid. In that case, a random function will, with very high probability, have made absolutely no progress towards detecting cliques. But now let  be the function that’s 1 if your graph contains a clique of size and 0 otherwise, and let be a Boolean function chosen uniformly at random. Then the function
be the function that’s 1 if your graph contains a clique of size and 0 otherwise, and let be a Boolean function chosen uniformly at random. Then the function  is also a Boolean function chosen uniformly at random. So and
is also a Boolean function chosen uniformly at random. So and  have, individually, made no progress whatever towards detecting cliques. However,
have, individually, made no progress whatever towards detecting cliques. However,  , so in one very simple operation — the exclusive OR, we get from no progress at all to the clique function itself.
, so in one very simple operation — the exclusive OR, we get from no progress at all to the clique function itself.
But does that really kill the idea? A natural response to this example is to think not about individual functions but about ensembles of functions. Is there a useful sense in which, while neither nor on its own carries any information about whether graphs contain cliques, the pair  does?
does?
There is obviously some sense in which the pair contains this information, since if you are given the functions and you can easily determine whether a graph contains a clique of size . However, we would like to generalize this very simple example. Here is a strategy one might try to adopt to prove that .
1. Choose your favourite NP-complete function, such as the clique function.
2. Define a “clique usefulness” property on ensembles of functions: roughly speaking this would tell you, given a set  of Boolean functions, whether it had any chance of helping you determine in a short time whether a graph contains a clique of size .
of Boolean functions, whether it had any chance of helping you determine in a short time whether a graph contains a clique of size .
3. Prove that the set  of coordinate functions (that is, the functions defined by
of coordinate functions (that is, the functions defined by  ) does not have the clique usefulness property.
) does not have the clique usefulness property.
Note that if we do things backwards like this, focusing very much on the target (to detect cliques) rather than the initial information (whether or not each edge belongs to the graph), then the property of “getting close to the target” is naturally small. So could we use this kind of idea to get round the difficulty that any reasonably simple simplicity property has to apply to almost all functions?
I think the answer is no, for reasons that are fairly similar to the reasons discussed in the previous section. Again I’ll use 3-bit scramblers to make my point. Let’s suppose that we have a property that applies to ensembles of functions, and that measures, in some sense, “how much information they contain about cliques”. Now let me define a collection of ensembles of functions using 3-bit scramblers. I’ll start with the clique function itself, which I’ll call 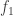 , and I’ll also take some random Boolean functions
, and I’ll also take some random Boolean functions 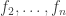 . (It isn’t actually important that there are functions, but there should be around .) Putting those functions together gives me a function
. (It isn’t actually important that there are functions, but there should be around .) Putting those functions together gives me a function 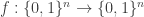 . Now I’ll simply compose with a random composition of 3-bit scramblers. That is, I’ll let
. Now I’ll simply compose with a random composition of 3-bit scramblers. That is, I’ll let  be random 3-bit scramblers (with
be random 3-bit scramblers (with  ) and I’ll define to be the Boolean function
) and I’ll define to be the Boolean function 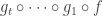 .
.
Suppose I know and the functions . Then it is easy to reconstruct , since I can just take the composition  . Thus, if I am given the Boolean functions
. Thus, if I am given the Boolean functions  , then with the help of a polynomial-sized circuit (to calculate the composition of the inverses of the 3-bit scramblers) I can reconstruct . Taking the first digit, I find out whether or not my graph contains a clique of size .
, then with the help of a polynomial-sized circuit (to calculate the composition of the inverses of the 3-bit scramblers) I can reconstruct . Taking the first digit, I find out whether or not my graph contains a clique of size .
Therefore, any “clique usefulness” property is going to have to do something that looks rather hard: it must distinguish between ensembles  produced in the manner just described, and genuinely random ensembles
produced in the manner just described, and genuinely random ensembles  of Boolean functions. Note that what is not random about the functions
of Boolean functions. Note that what is not random about the functions 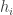 is not the functions themselves but the very subtle dependencies between them.
is not the functions themselves but the very subtle dependencies between them.
There is a slightly unsatisfactory feature of this problem, which is that it depends on a very specific function, namely the clique function. Also, when we create the function  , we don’t create a bijection, since it is not the case that exactly half of all graphs contain a clique of size . To deal with the latter criticism, let’s increase the number of random functions, so now we start with
, we don’t create a bijection, since it is not the case that exactly half of all graphs contain a clique of size . To deal with the latter criticism, let’s increase the number of random functions, so now we start with 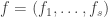 for some
for some  that’s large enough that is an injection. (It won’t have to be very large for this — linear in will be fine.) Now compose with
that’s large enough that is an injection. (It won’t have to be very large for this — linear in will be fine.) Now compose with  random 3-bit scramblers, where the sets are subsets of
random 3-bit scramblers, where the sets are subsets of 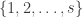 . The result of this is some functions
. The result of this is some functions  .
.
The problem we would now like to solve is this. Given the functions  , find a sequence of 3-bit scramblers defined on the Boolean cube
, find a sequence of 3-bit scramblers defined on the Boolean cube 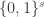 such that, writing for the composition
such that, writing for the composition  and for the function
and for the function 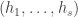 (so
(so 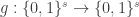 and
and 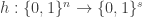 ), we have
), we have 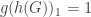 if and only if contains a clique of size .
if and only if contains a clique of size .
This is a special case of the following problem. Suppose you are given sequences of points  and
and  of . Does there exist a composition of 3-bit scramblers such that
of . Does there exist a composition of 3-bit scramblers such that  for every
for every  and
and  for every
for every  ?
?
Actually, that isn’t quite the problem that’s of interest, but it is very closely related. The real problem is more like this. Suppose you are given points and in and told that one of the following two situations holds. Either they have been chosen randomly or we have chosen 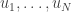 randomly with first coordinate 1 and
randomly with first coordinate 1 and  randomly with first coordinate 0, and taken a random composition of 3-bit scramblers, setting
randomly with first coordinate 0, and taken a random composition of 3-bit scramblers, setting  and
and  for each
for each 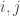 . Can you efficiently guess which is the case with a chance of being correct that is significantly different from 1/2 without using vast amounts of computer power?
. Can you efficiently guess which is the case with a chance of being correct that is significantly different from 1/2 without using vast amounts of computer power?
This doesn’t look at all easy, so it looks very much as though something rather similar to the natural-proofs statement holds in this reverse direction as well. It would say something like this. Suppose that you have some polynomially computable property  (for “informativeness”) of sets of functions
(for “informativeness”) of sets of functions  , such that has property whenever the clique function (or any other NP function of your choice) can be efficiently computed given the values of
, such that has property whenever the clique function (or any other NP function of your choice) can be efficiently computed given the values of 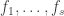 . Then almost every sequence of functions has property . The “proof” is similar to the earlier argument: a polynomially computable property can’t distinguish, even statistically, between genuinely random sets of functions and random sets of functions that have been cooked up to have just enough dependence to be informative about cliques. Since all the latter must have property , almost all the former must have property as well.
. Then almost every sequence of functions has property . The “proof” is similar to the earlier argument: a polynomially computable property can’t distinguish, even statistically, between genuinely random sets of functions and random sets of functions that have been cooked up to have just enough dependence to be informative about cliques. Since all the latter must have property , almost all the former must have property as well.
In the next post I’ll turn to the actual argument of Razborov and Rudich.
This entry was posted on October 3, 2013 at 2:36 pm and is filed under complexity. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

October 3, 2013 at 9:31 pm |
Some other intuition that these scramblers might be hard to distinguish from random is that they seem somewhat related to the designs of block ciphers, and these are actually conjectured by cryptographers to be indistinguishable from random. (And cryptanalysts spend significant time trying to attack these conjectures.)
Also, there is another way to view the argument above, and this is that the condition that properties S must apply to only a minority of the functions is useful to rule out a different kind of “semi-tautologies”.
Consider the following property that takes the idea of “CLIQUE usefulness” to the extreme: let S be the set of all functions except the CLIQUE function. Note that membership in S can be tested in time and so this S itself can be thought of as “simple”. If (as we all believe) NP does not have polynomial sized circuits, then all easily computable functions are in S but it is obviously not a very useful property for trying to prove this fact. The restriction to “small” properties S rules out such trivialities.
time and so this S itself can be thought of as “simple”. If (as we all believe) NP does not have polynomial sized circuits, then all easily computable functions are in S but it is obviously not a very useful property for trying to prove this fact. The restriction to “small” properties S rules out such trivialities.
October 6, 2013 at 3:59 am |
great to see people delving into this great proof/gem, but alas, its closing in on 2decades old, and is it still truly the most relevant to really attacking the problem? a very nice recent counterpoint, even near-rebuttal of this paper that has not gotten much attn, “almost natural proofs” by TChow.
to me people have gotten “wrapped around the axle” of this Natural Proofs paper that is focused on proving a barrier or a “no-go” theorem. while its useful to approach the problem from the “negative angle”, of course why not hedge bets, put objections on hold, and also pursue from a “optimistic angle”? have proposed an outline/blueprint for a NP vs P/poly proof closing in on 1yr old, no expert response so far. also proposed it as a polymath endeavor. hope to hear from anyone. oh! ps! its highly based on the pioneering directions of Razborov, when he himself was stil pursuing an “optimistic” rather than a “pessimistic” direction…
October 7, 2013 at 2:33 am |
I very much agree, re Timothy Chow’s paper. Especially once you see Salil Vadhan’s one-paragraph proof of his result (reproduced in Chow’s paper http://arxiv.org/pdf/0805.1385v3.pdf ).
October 7, 2013 at 7:58 am
Understanding Chow’s result properly has been on my to-do list for some time. I’ll have a look at it and look out for that paragraph.
October 7, 2013 at 3:15 pm
I like Chow’s paper quite a bit, but I don’t think it changes much the message of the natural proof paper. Rather it shows that quantitatively the Razborov-Rudich bound on the “largeness” condition is tight.
I don’t this makes such a difference, because a natural “simplicity” property ought to capture a vanishing fraction of all functions. However, RR actually proved a stronger result, ruling out even simplicity properties that capture a fraction of the inputs. (The way it’s usually described considers the complement of the “simplicity property”, which is called a “useful property”.) Chow’s paper shows that RR’s quantitative bound on the function
fraction of the inputs. (The way it’s usually described considers the complement of the “simplicity property”, which is called a “useful property”.) Chow’s paper shows that RR’s quantitative bound on the function 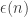 is essentially tight.
is essentially tight.
Salil’s proof basically uses the same trivial property I mentioned above – you consider the set H of all functions on bits that compute CLIQUE (or your other favorite NP-hard problem such as SAT) on the first
bits that compute CLIQUE (or your other favorite NP-hard problem such as SAT) on the first  bits of their input for some
bits of their input for some  . The measure of H is
. The measure of H is  but if, as we believe, there is no circuit computing CLIQUE on
but if, as we believe, there is no circuit computing CLIQUE on  -bit inputs with size smaller than, say,
-bit inputs with size smaller than, say, 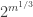 , then if we take
, then if we take  then no polynomial-time computable function is in H and so H is a useful property which is also constructive.
then no polynomial-time computable function is in H and so H is a useful property which is also constructive.
October 7, 2013 at 6:28 am |
“… we are looking for a property that is in some sense genuinely different from the property of being computable in at most steps.”
steps.”
The property is apparently obscured by an ambiguity that is implicit in the standard definitions of the Satisfiability problem (SAT), and of the classes P and NP.
These fail to either recognise or explicitly highlight that the assignment of satisfaction and truth values to number-theoretic formulas under an interpretation can be constructively defined in two distinctly different ways (with significant consequences for the foundations of mathematics, logic and computability):
(a) In terms of algorithmically verifiability:
A number-theoretical formula F is algorithmically verifiable under an interpretation (and is therefore in NP) if, and only if, we can define a polynomial-time checking relation R(x, y)—where x codes a propositional formula F and y codes a truth assignment to the variables of F—such that, for any given natural number values (m, n), there is an algorithm which will finitarily decide whether or not R(m, n) holds over the domain of the natural numbers.
(b) In terms of algorithmically computability:
A number-theoretical formula F is algorithmically computable under an interpretation (and is therefore in P) if, and only if, we can define a polynomial-time checking relation R(x, y)—where x codes a propositional formula F and y codes a truth assignment to the variables of F—such that there is an algorithm which, for any given natural number values (m, n), will finitarily decide whether or not R(m, n) holds over the domain of the natural numbers.
Of course we first need to argue that the two concepts are well-defined.
It is fairly straightforward to then argue that there are classically defined arithmetic formulas which are algorithmically verifiable but not algorithmically computable.
October 7, 2013 at 6:16 pm |
[…] However, if you disagree with me, then I don’t have much more I can say (though see Boaz Barak’s first comment on the previous post). What Razborov and Rudich did was to use a different set of random polynomial-time-computable […]
October 7, 2013 at 11:55 pm |
may write some more comments on this article after going thru it more carefully [have bookmarked it].
think there is some possibility that Razborov has already identified a mathematical “property” that may be sufficient to separate P from NP without realizing it…. further details on this idea to anyone who thinks its not outlandish enough to reply =)
thats quite a leap there. havent read your 3bit scrambler paper [could you put it on arxiv or online, or does a semievil scientific publishing corporation who shall remain nameless restrict that?], but what you have here is [something close to] a statement/assertion that you have found a different NP complete problem, albeit not really phrased exactly in the typical format. it needs to be quantified a bit better. in particular it appears one needs to bound the # of compositions of the scramblers.
October 8, 2013 at 10:19 am
I can get access to the paper by searching for the title (An almost m-wise independent random permutation of the cube), but, not too surprisingly, I can’t post a working link to it. At some point I’ll try to dig out the preprint from which that paper is derived, but it may take some searching to find it.
I don’t think the problem of distinguishing a random composition of say 3-bit scramblers from a truly random even permutation of the vertices of the cube is an NP-complete problem. Actually, the question there is whether it is a pseudorandom generator, but I don’t believe that the related problem of telling in polynomial time (in
3-bit scramblers from a truly random even permutation of the vertices of the cube is an NP-complete problem. Actually, the question there is whether it is a pseudorandom generator, but I don’t believe that the related problem of telling in polynomial time (in  ) whether a given even permutation is a composition of at most
) whether a given even permutation is a composition of at most  3-bit scramblers is NP-complete. However, it is certainly in NP, and I think it is at the hard end of NP. (The problem if you try to show that it is NP-complete is that because you are dealing with permutations, you somehow don’t have enough room to create gadgets. Or at least, that seems to be a problem.)
3-bit scramblers is NP-complete. However, it is certainly in NP, and I think it is at the hard end of NP. (The problem if you try to show that it is NP-complete is that because you are dealing with permutations, you somehow don’t have enough room to create gadgets. Or at least, that seems to be a problem.)
October 8, 2013 at 4:11 pm
hi wtg think that some near-variant of your bit scrambler problem is indeed NP complete. havent found nice formulations that show how distinguishing randomness or PRNGs from “truly random” is NP complete or related to complexity class separations, but have concluded after long study its basically the same phenomenon & the Natural Proofs paper certainly points in that direction. think part of the difficulty here is how you formulated this, what does it technically/formally mean to “distinguish a function from truly random”. how can that be defined mathematically? Razborov/Rudich paper has some ideas along these lines…. unfortunately some of the theory of PRNGs is more in the cryptography literature than the complexity theory literature, and this is a unnatural separation so to speak (in the sense of future hindsight)…. needs to be unified…. there is also an interesting sense in which monotone circuit (slice) functions compute a kind of permutation mapping…. have to write that up sometime…. deep connections….
October 8, 2013 at 4:23 pm
another interesting pov that shows how much a TM computation is like bit scrambling & shows ideas for a completeness construction. imagine the TM head moving over a binary tape and making changes as it passes left to right, back/forth, and the series of IDs, instantaneous descriptions aka computational tableau it generates. its similar to a “scrambling composition”, it is computing something very similar to your bit scrambler with somewhat more bits involved (roughly, enough to represent 3 tape squares/symbols)…. now, how to convert all this into a few problems, theorems and lemmas, esp linking up existing theory? there seem to be some key unknown or maybe now-obscure bridge thms waiting to be constructed or highlighted….
October 8, 2013 at 5:04 pm
It’s true that a slight variant of the problem is NP-complete. The basic reason for that is that if you allow some extra inputs and set them all to zero, then you can use 3-bit scramblers to simulate an arbitrary circuit.
October 8, 2013 at 10:24 pm
yeah re boaz’ 1st comment above, wonder if there are some proven NP complete problems in crypto wrt block ciphers & permutations/”scramblers” but havent noticed them myself yet over the yrs…. as for P=?NP, the question relating to circuits is stronger and is the P/poly=?NP question. the so called “uniform vs nonuniform” distinction.
here is a tcs.se question that has a formal mechanism for measuring “errors” which might be a way of measuring a “closeness” of functions re your idea of looking at “truly random” vs “pseudo random” cnf/dnf conversion to minimize errors
October 9, 2013 at 11:43 pm
fyi decided to ask a similar question on crypto.se, citing this pg: NP complete problems related to permutations of binary vectors or block ciphers
October 8, 2013 at 12:04 am |
here is another pov that few seem to realize & havent really seen explored much in the literature. what all this research is really saying as a bottom line, in some ways, is that another way of looking at randomness is that there are different “gradations” of randomness. a function running in can scramble/achieve a certain level of randomness,
can scramble/achieve a certain level of randomness, 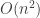 can achieve more randomness,
can achieve more randomness, 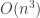 even more, etc, and subject to P≠NP, there are some “high levels of randomness” that no P algorithm can generate/accomplish. in a way, complexity theory is giving a very precise/fundamental new definition of information entropy where entropy is a measure of “disorder” or randomness. of course some of these ideas show up in kolmogorov complexity theory but are apparently unfinished. and razborovs natural proofs paper is examining/pointing out that a P≠NP proof must also inherently capture this complexity in its definition, in its separation method/function “machinery”.
even more, etc, and subject to P≠NP, there are some “high levels of randomness” that no P algorithm can generate/accomplish. in a way, complexity theory is giving a very precise/fundamental new definition of information entropy where entropy is a measure of “disorder” or randomness. of course some of these ideas show up in kolmogorov complexity theory but are apparently unfinished. and razborovs natural proofs paper is examining/pointing out that a P≠NP proof must also inherently capture this complexity in its definition, in its separation method/function “machinery”.
October 10, 2013 at 7:03 pm |
The “paper of mine” link about seems to be broken.
October 10, 2013 at 8:35 pm
Sorry about that. I think I was fooled by being able to get access to it from a university computer. I’ll try to find a preprint and change the link to that.
October 18, 2013 at 12:33 pm |
[…] to *: I am not alone! See for instance this blogpost of Timothy Gower’s representing one extreme; and this plaintive appeal representing the […]
October 22, 2013 at 5:53 pm |
[…] How not to prove that P is not equal to NP (gowers.wordpress.com) […]
October 28, 2013 at 1:07 pm |
[…] via Hacker News https://gowers.wordpress.com/2013/10/03/how-not-to-prove-that-p-is-not-equal-to-np/#comments […]
October 28, 2013 at 1:21 pm |
[…] How not to prove that P is not equal to NP Source: https://gowers.wordpress.com/2013/10/03/how-not-to-prove-that-p-is-not-equal-to-np/#comments 0 … […]
October 28, 2013 at 3:24 pm |
P = NP? P = 0. Solved. You’re welcome. Timmy Daniels PhD Age 46
October 28, 2013 at 5:20 pm |
[…] How not to prove that P is not equal to NP Source: https://gowers.wordpress.com/2013/10/03/how-not-to-prove-that-p-is-not-equal-to-np 0 […]
October 28, 2013 at 5:30 pm |
[…] via Hacker News https://gowers.wordpress.com/2013/10/03/how-not-to-prove-that-p-is-not-equal-to-np […]
May 5, 2014 at 9:23 am |
@ Gowers
The definition of the problem P=NP is I believe below:
“If a solution to a problem can be verified as the right solution in polynomial time, the problem can also be solved in polynomial time”
Before going to P & NP, I want to understand the basis for these levels/classes of complexities well. I convey my understanding below and that I do because from that I want to question the question itself.
Assume that there is this hypothetical problem solver program which will try to solve a given problem and find an answer. This program typically takes greater number of machine head moves and tape space in a turing machine to solve a problem if it is given a tougher problem. The length of the time (number of head moves) to solve a problem partly depends on the length of the variables in the problem – number of digits in a number in case of factorization problem or the number of cities in case of travelling salesman problem. For each problem if we come up with an optimal method (program) to solve the problem, still the number of machine head moves and tape space consumed in reaching the solution is a function of the length of the variables – f(lv). The rate at which the value of this function f(lv) increases with the increase in the length of the variables depends on the inherent hardness of the problem. As the length of the variables tend towards infinity almost all the f(lv)s will tend towards infinity. But some tend to infinity faster than the rest or one could reword it as some tend to a bigger infinity than the rest. If we do not accept the different cardinalities in infinities, does this differentiation between the hardness of two problems still hold good?
In other words, consider Limit of (x power n)/ (e power x) as x tends to infinity and n is finite – is it really zero or undefined?
In a stronger version of the above statement consider Limit of (x power n)/ (x power n+1) as x tends to infinity and n is finite – is it really zero or undefined?
In other words, consider two cars, one travelling in uniform velocity and the other with uniform acceleration – would both given infinite time to travel, travel different infinite distances (assuming there is no speed limit like c)?
If say there are three cars covering distances as a function of t (the time taken) – t, t-squared and (e power t). Given infinite time, would they cover markedly different infinite distances?
There is something troubling about these limits when x tends to infinity or zero, cardinalities of infinities, infinity, infinitesimal, the assumption of continuum of the number line itself. Dont you think?
I am not able to convince myself that everything is clear and lucid and “comfortably acceptable” to one’s mind when we deal with these mathematical things. It seems like there is a certain sense of mental delusion and some hacking happening to justify say the continuum of the number line.
Why dont we just be content with those algebraic numbers which involve non infinite process, lets not even include 10/3 in the domain of numbers, definitely not root of 2 and transcendentals like pi and e. For pi and e, its definition depends on I believe on geometry and calculus, both apriori assume continuum and infinite processes. I feel our minds deludes itself that it can hold infinity and infinitesimal in it but it cannot – it truly cannot conceive of an infinite process of continuously reducing epsilon for to do that you will take a lifetime but after a point we just mentally say to ourselves “…” and resort to a delusional induction that enables us to come to terms with infinitesimal and the continuum.
Isnt there something deeply troubling in doing that?
Can we not create an alternate version of maths which doesnt need the continuum. You dont need continuum for calculus or geometry. For all you know space and time might not be continuous. We can create virtual reality mimicking real world geometry and motion (speed & acceleration) using discrete computers. For all you know the physical laws of our world arent based on the continuous. May be a computer can create a reality using quantum mathematics where when you combine laws of gravitation and quantum theory it doesnt result in singularities and infinities as quantum mathematics doesnt include infinity as a valid concept to start with. Somehow I feel the problem of unification of laws of physics doesnt lie in physics but in mathematics, in its assumption of a continuum. Energy is not continuous but comes in quantum packets not because of the laws of nature but the laws of underlying mathematics of nature. The only thing which blocks our understanding of that mathematics is the ability of our mind to conjure up an infinite process but in actuality it doesnt – it thinks it does through induction but it doesnt. I somehow think if we dont get mathematics in order, and cure ourselves of that delusion of infinite induction, we will never be able to unify. I am strongly doubt space-time which surround us is also quantum and discrete and we cannot model it with our mathematics of continuum.
July 10, 2015 at 4:36 pm |
[…] 10. How not to prove that P is not equal to NP | Gowers’s Weblog […]
August 15, 2017 at 5:40 am |
[…] Timothy Gowers, How not to prove that P is not equal to NP, 3 October […]