Over at the Polymath blog, Gil Kalai recently proposed a discussion about possible future Polymath projects. This post is partly to direct you to that discussion in case you haven’t noticed it and might have ideas to contribute, and partly to start a specific Polymathematical conversation. I don’t call it a Polymath project, but rather an idea I’d like to discuss that might or might not become the basis for a nice project. One thing that Gil and others have said is that it would be a good idea to experiment with various different levels of difficulty and importance of problem. Perhaps one way of getting a Polymath project to take off is to tackle a problem that isn’t necessarily all that hard or important, but is nevertheless sufficiently interesting to appeal to a critical mass of people. That is very much the spirit of this post.
Before I go any further, I should say that the topic in question is one about which I am not an expert, so it may well be that the answer to the question I’m about to ask is already known. I could I suppose try to find out on Mathoverflow, but I’m not sure I can formulate the question precisely enough to make a suitable Mathoverflow question, so instead I’m doing it here. This has the added advantage that if the question does seem suitable, then any discussion of it that there might be will take place where I would want any continuation of the discussion to take place.
Fast parallel sorting.
I am in the middle of writing an article about Szemerédi’s mathematical work (for a book about Abel Prize winners), and one of his results that I am writing about is a famous parallel sorting network, discovered with Ajtai and Komlós, that sorts 
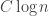


The thought I would like to explore is not a way of solving that problem — obtaining the AKS result with a reasonable constant — but it is closely related. I have a rough idea for a randomized method of sorting, and I’d like to know whether it can be made to work. If it gave a good constant that would be great, but I think even proving that it works with any constant would be nice, unless it has been done already — in which case congratulations to whoever did it and I very much like your result.
The rough idea is this. As with any fast parallel sorting method, the sorting should take place in rounds, where each round consists in partitioning all the pairs (or a constant fraction of them, but there isn’t much to be lost by doing extra comparisons) and swapping the objects round if the one that should come before the other in fact comes after it.
An obvious thing to try is a random partition. So you start with 
With this picture, the random method would be to partition the rocks randomly into pairs and do the corresponding 

What happens if we do 

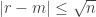

This suggests an adjustment to the naive random strategy, which is to have a succession of random rounds, but to make them gradually more and more “localized”. (Something like this is quite similar to what Ajtai, Komlós and Szemerédi do, so this idea doesn’t come out of nowhere. But it is also very natural.) That is, at each stage, we would choose a distance scale 
The thing that makes it a bit complicated (and again this has strong echoes in the AKS proof) is that if you just do a constant number of rounds at one distance scale, then a few points will get “left behind” — by sheer bad luck they just don’t get compared with anything useful. So the challenge is to prove that as the distance scale shrinks, the points that are far from where they should be get moved with such high probability that they “catch up” with the other points that they should be close to.
It seems to me at least possible that a purely random strategy with shrinking distance scales could sort
So my questions are these.
(i) Has something like this been done already?
(ii) If not, is anyone interested in exploring the possibility?
A final remark is that something that contributed a great deal to the health of the discussion about the Erdős discrepancy problem was the possibility of doing computer experiments. That would apply to some extent here too: one could devise an algorithm along the above lines and just observe experimentally how it does, whether points catch up after getting left behind, etc.

February 28, 2013 at 5:54 pm |
(i) I do not know. My knowledge about sorting does not go far beyond ‘quicksort’.
(ii) I would be interested.
February 28, 2013 at 10:11 pm |
This seems highly reminiscent of “Shell sort” — take a decreasing sequence a1,a2,…, ending in 1; for each k and each b mod ak, insertion-sort elements (t.ak+b); note that these “sub-sorts” can run in parallel — which has the following mildly discouraging features.
1. The (worst-case or average) execution time depends very strongly on the exact choice of gap sequence.
2. The way in which this dependence works is poorly understood.
3. No gap sequence produces a worst-case execution time that’s O(N log N). No gap sequence is known to produce an average execution time that’s O(N log N).
Now, maybe Shell sort is too rigid somehow, and the sort of randomized schedule you propose would somehow average things out in a helpful way. A bit of googling turns up a paper by Michael Goodrich describing what he calls “randomized Shellsort”, which allegedly runs in time O(N log N) and sorts correctly with very high probability. This looks really quite similar to what you propose here.
February 28, 2013 at 10:13 pm |
Er, sorry, of course I should have given a link to Goodrich’s paper. It’s at https://www.siam.org/proceedings/soda/2010/SODA10_101_goodrichm.pdf .
February 28, 2013 at 11:06 pm |
Thanks for that interesting reference, which I didn’t know about. It does indeed look similar, though if I understand correctly the depth is greater than . Also, I was hoping for a sorting network that sorts every single permutation rather than just almost every permutation. But the complicated argument in this paper suggests that that may be hard to achieve.
. Also, I was hoping for a sorting network that sorts every single permutation rather than just almost every permutation. But the complicated argument in this paper suggests that that may be hard to achieve.
Having said that, I don’t want to rule out the possibility that one might be able to do things cleverly somehow and make the argument simpler.
March 1, 2013 at 6:25 am |
I was motivated to ask http://mathoverflow.net/questions/31364/inversion-density-have-you-seen-this-concept by a problem similar to yours, but without the random element. The references listed in the question may be of use; Poonen’s analysis is general enough that it might apply. However,
you or a student of yours might try an experiment comparing, say, combsort with a randomized version which changes the gap length by +- 1 each time a comparison is done.
March 1, 2013 at 2:50 pm |
At the time I felt that the best chances for a definite success in the various suggestions before agreeing on EDP was the first case of polynomial HJT. https://gowers.wordpress.com/2009/11/14/the-first-unknown-case-of-polynomial-dhj/
(Of course some propose projects were more “open ended”)
March 2, 2013 at 3:51 pm
I still very much like that question and would be interested in exploring it at some point.
March 2, 2013 at 8:54 am |
Sounds like a nice question: I’d be interested in exploring it.
March 2, 2013 at 3:26 pm |
From the response so far, it’s not clear whether a Polymath project based on this question would get off the ground (I mean that both positively and negatively), so let me try to be more specific about the question. The weakness in the proposed proof so far is that I don’t have a very precise idea about why it might be reasonable to hope that the elements that get “left behind” should eventually catch up. However, I do have a vague idea, and it might be interesting to try to turn that into a more precise heuristic argument, by which I mean turn it from a qualitative argument into a quantitative one, perhaps making some plausible assumptions along the way.
The vague idea is this. Suppose that we have a linearly ordered set and an initial permutation of that set. Let us write
and an initial permutation of that set. Let us write  for the place occupied by
for the place occupied by  after
after  rounds of sorting. And suppose that
rounds of sorting. And suppose that  is such that
is such that  for all but a small percentage of
for all but a small percentage of  . What we expect is that
. What we expect is that  should be
should be  for some positive constant
for some positive constant  , and indeed I think that something like that should be easy to prove, at least for small
, and indeed I think that something like that should be easy to prove, at least for small  .
.
That means that by the th stage, the algorithm should by and large be working at distance scale
th stage, the algorithm should by and large be working at distance scale  . Suppose now that the element
. Suppose now that the element  is one of the few that is way out of position: for convenience, let us assume that
is one of the few that is way out of position: for convenience, let us assume that  is much bigger than
is much bigger than  . Then at time
. Then at time  ,
,  will be surrounded (at a distance scale of
will be surrounded (at a distance scale of  ) by elements that are much larger, so practically all comparisons we ever make will result in
) by elements that are much larger, so practically all comparisons we ever make will result in  being moved closer to place
being moved closer to place  . (To be more precise, I would expect about half the comparisons to be with objects in later places, which would result in no movement at all, and half to be with objects in earlier places, which would result in significant movement towards
. (To be more precise, I would expect about half the comparisons to be with objects in later places, which would result in no movement at all, and half to be with objects in earlier places, which would result in significant movement towards  . Putting those two together should give significant movement towards
. Putting those two together should give significant movement towards  .)
.)
So the thing that gives me hope about this is that the elements that are far from their correct positions are much more likely to move towards their correct positions.
To be slightly more precise still, let’s say that an element is unlucky at stage if it doesn’t get moved significantly nearer to its correct position. At the beginning of the process, we would normally expect an element to be unlucky with constant positive probability. If that remained true, then even after logarithmically many steps we would expect at least some elements to be unlucky. But by then the distance scale would have contracted to
if it doesn’t get moved significantly nearer to its correct position. At the beginning of the process, we would normally expect an element to be unlucky with constant positive probability. If that remained true, then even after logarithmically many steps we would expect at least some elements to be unlucky. But by then the distance scale would have contracted to 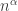 for some
for some 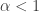 and it starts to look very difficult for that element to catch up. However, one of the assumptions I have just made is too pessimistic, since after a few steps the probability that an element is unlucky should no longer be a constant.
and it starts to look very difficult for that element to catch up. However, one of the assumptions I have just made is too pessimistic, since after a few steps the probability that an element is unlucky should no longer be a constant.
Having written that, I realize that it is not quite correct as I’ve stated it. Suppose that at each stage the probability that the element in place is compared with an element in place
is compared with an element in place  for some
for some 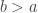 is
is  . Then if
. Then if 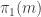 is significantly greater than
is significantly greater than  , there is a constant probability at each stage that
, there is a constant probability at each stage that  will be compared with an element in some place that is in a place that is greater than
will be compared with an element in some place that is in a place that is greater than 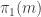 , in which case
, in which case  is unlucky. So for my vague argument to work, the random comparisons need to be organized in a way that guarantees that roughly half the comparisons should be with an element to the left and roughly half with an element to the right.
is unlucky. So for my vague argument to work, the random comparisons need to be organized in a way that guarantees that roughly half the comparisons should be with an element to the left and roughly half with an element to the right.
One possible way of doing that would be to pick at each stage a random number at the right distance scale, partition into residue classes mod
at the right distance scale, partition into residue classes mod  , and do two rounds, one where the pairs are
, and do two rounds, one where the pairs are  ,
, 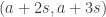 , etc. and the other where the pairs are
, etc. and the other where the pairs are 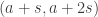 ,
, 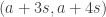 , etc.
, etc.
March 2, 2013 at 3:50 pm |
Here’s the kind of heuristic calculation I’d like to see done. First, we should work out what we expect the distribution of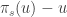 to look like. Next, suppose that an element
to look like. Next, suppose that an element  starts in a position that is
starts in a position that is 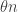 places to the right of
places to the right of  : that is,
: that is,  . Then we should work out the probability that
. Then we should work out the probability that  is large assuming that
is large assuming that 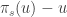 has roughly the expected distribution at all intermediate stages.
has roughly the expected distribution at all intermediate stages.
What makes it a bit tricky is that the probability in question affects the distribution: it looks as though the distribution is some kind of fixed point, and therefore quite hard to guess. The distribution itself depends on the distribution of the random comparisons, but that is less problematic — one could choose the comparisons in as nice a way as possible in the hope of simplifying the calculations. This could be a case where some computer experimentation would be interesting: if we choose some natural seeming collection of comparisons, such as the ones suggested at the end of the previous comment, with normally distributed with standard deviation
normally distributed with standard deviation 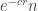 for some smallish constant
for some smallish constant  , what is the distribution of
, what is the distribution of 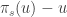 like?
like?
I’ve just seen an additional complication, which is that it is not clear what I mean by “the distribution”. In particular, am I talking about a random initial arrangement of the or the worst-case initial arrangement? It is the latter that I unconsciously had in mind. So I suppose that what I’m looking for is an “upper bound” for the distribution: that is, for each
or the worst-case initial arrangement? It is the latter that I unconsciously had in mind. So I suppose that what I’m looking for is an “upper bound” for the distribution: that is, for each  an upper bound for the proportion of
an upper bound for the proportion of  such that
such that  , the upper bound being valid whatever the initial sequence is.
, the upper bound being valid whatever the initial sequence is.
March 2, 2013 at 4:39 pm |
I’ve just realized that there is a problem with my suggested random scheme for sorting if we want to sort all sequences rather than just almost all. Given any place , the number of elements
, the number of elements  that can be at
that can be at  after
after  rounds of comparison is at most
rounds of comparison is at most  . So if
. So if  is less than logarithmic, then we can fix it so that the element initially in place
is less than logarithmic, then we can fix it so that the element initially in place  is much too large, and all the elements that could possibly end up at place
is much too large, and all the elements that could possibly end up at place  are even larger.
are even larger.
This implies that after, say, rounds, we may have some elements that are out of place by
rounds, we may have some elements that are out of place by  . But by that stage, the distance scale has dropped to
. But by that stage, the distance scale has dropped to 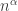 , which means that at least
, which means that at least  steps will need to be taken by those elements, which is impossible in only logarithmically many rounds.
steps will need to be taken by those elements, which is impossible in only logarithmically many rounds.
This seems to suggest that if the difference scales decrease in such a way that after a short time it becomes very unlikely that comparisons between distant places are ever made again, then we are in trouble. So for an approach like this to work, what seems to be required is for a typical comparison to become more and more focused on small distance scales without losing sight of the large distance scales. Exactly how this should be done is not clear to me, though it might be possible to get some insight into the problem by looking at the AKS scheme and seeing how they cope with elements that are left behind. Maybe some randomized version of what they do would work, though if it was too close to their approach then it wouldn’t be very interesting.
March 2, 2013 at 5:40 pm
A few remarks: 1) There is a simplification of AKS due to M. S. Paterson: Improved sorting networks with O(log N) depth, Algorithmica 5 (1990), no. 1, pp. 75–92. Perhaps there are further works.
2) There is a beautiful area of random sorting networks. See Random Sorting Networks by Omer Angel, Alexander E. Holroyd, Dan Romik, Balint Virag http://arxiv.org/abs/math/0609538
3) If you take a random sorting network of depth C log n (or more generally depth m) can we have a heuristic estimation for the probability p that this network will sort every n numbers? (Or perhaps simpler an expectation and variance for the number of orderings it will sort?) Then we can see when p is larger than 1/(n!)^m.
March 2, 2013 at 5:58 pm
A quick further remark. The following is a slightly daring conjecture, but I don’t see an obvious argument for its being false. One could simply do what I was suggesting and then do it again. My remark above shows that the first time round it can’t sort everything, but the second time round the initial ordering will on average be very close to correct, and then it isn’t clear that a second pass won’t tidy everything up.
March 3, 2013 at 10:58 am
Maybe it will be useful to to restate (glue and paste) or link to the explicit description of “what I was suggesting”. So we will be clear about your conjecture.
Let me remark that on thing that we can do is that anytime we compare 2 rocks we put them back in a random 1/2 1/2 position and then the quastion is how can we guarantee with such a small depth network, that the distribution is very close to uniform.
March 2, 2013 at 4:41 pm |
[…] sorting network for $n$ numbers of depth $O(log N)$. rounds where in each runs $n/2$. Tim Gowers proposes to find collectively a randomized sorting with the same […]
March 2, 2013 at 11:55 pm |
I want to see how your idea would work on a simple input, say [n,1,2,3,4,…,n-1]. My concern is that the sorting network will do a lot of unsorting (say [d,1,2,3,…,n,…]) and not make any provable progress in a logarithmic number of rounds.
March 3, 2013 at 12:25 am
That’s a nice example to think about. It’s not necessarily a major problem if d gets moved to the beginning, because it will have a strong tendency to move back. But of course, that will move other numbers out of place, and exactly how things pan out is not clear.
March 3, 2013 at 10:32 am |
I’ve thought about Gerhard’s example now and am in a position to explain why I don’t find it too threatening. What I’m going to do is consider a highly idealized and unrealistic model of what the randomized network would do, which to me makes it believable that a actual randomized network would have a chance of success.
To describe the idealized model, let’s assume that is a power of 2. For convenience I’ll call the numbers 1 to
is a power of 2. For convenience I’ll call the numbers 1 to  and the places 0 to
and the places 0 to  . The initial arrangement is
. The initial arrangement is  . The worry about this arrangement is that almost all the numbers are in order, so very few comparisons will actually change anything. Meanwhile, those few comparisons that do change anything seem to be messing things up.
. The worry about this arrangement is that almost all the numbers are in order, so very few comparisons will actually change anything. Meanwhile, those few comparisons that do change anything seem to be messing things up.
However, these two worries in a sense cancel each other out: the messing up is necessary to get all of to shift to the left.
to shift to the left.
Let’s now do the following sequence of rounds. We will begin by comparing place with place
with place  for each
for each  . Note that these are precisely those
. Note that these are precisely those  for which
for which 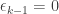 if we represent them as
if we represent them as  with each
with each  .
.
Next, we compare place with place
with place 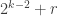 for each
for each  such that
such that 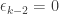 (that is, the first and third quarters of all the
(that is, the first and third quarters of all the  ). And we continue in this way.
). And we continue in this way.
After the first round, everything is as it was before, except that now we have in place
in place  and
and  in place 0. Now we have two copies of the original ordering, one in the left half and one in the right half. What’s more, in each half we do the sequence of rounds corresponding to
in place 0. Now we have two copies of the original ordering, one in the left half and one in the right half. What’s more, in each half we do the sequence of rounds corresponding to  . Therefore, by induction after
. Therefore, by induction after  rounds everything is sorted.
rounds everything is sorted.
What is happening here is that as we proceed, we replace one sequence that is messed up at a distance scale by a concatenation of two sequences that are messed up in precisely the same way at a distance scale
by a concatenation of two sequences that are messed up in precisely the same way at a distance scale 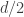 . In a sense, this concatenation is messier than the original sequence, but because we can operate on it in parallel, this does not matter.
. In a sense, this concatenation is messier than the original sequence, but because we can operate on it in parallel, this does not matter.
I think it would be very interesting to try to analyse what a more randomized set of rounds would do with this initial ordering.
March 3, 2013 at 3:04 pm |
Even if the goal is to find (or prove the existence of) small-depth circuits that sort all initial inputs (and not merely ‘almost all’), I wonder if it might be useful to think about the more general case. A proof that depended upon following some properties of the input distribution through the rounds might be easier to make work in that case. On the other hand, it might be possible to control some properties (e.g. some measure of sortedness) possessed by all potential inputs to each round.
I also wonder if we are after a (randomized construction of a) circuit that works with high probability, or just with positive probability? Or are these somehow equivalent?
March 3, 2013 at 4:36 pm |
As I heard from Michael Ben-Or, there is a randomized construction by Tom Leighton of a sorting network with 7.2log n rounds that sort all orderings except exponentially small fraction of them. (The problem with repeating is that it seems that a log number of repeats are needed.)
March 3, 2013 at 5:11 pm
The book by Leighton: :Introduction to Parallel Algorithms and Architectures Arrays, Trees, Hypercubes,” devotes a chapter to this construction. See also this paper by Leighton and Plaxton: http://epubs.siam.org/doi/pdf/10.1137/S0097539794268406
March 3, 2013 at 9:51 pm
Do you know why a log number of repeats is needed? One might think that if after a first round the number of elements that are out of place was (with similar statements at all distance scales), then at the next repetition the probability that tidying up fails becomes very small after only a constant number of rounds.
(with similar statements at all distance scales), then at the next repetition the probability that tidying up fails becomes very small after only a constant number of rounds.
Just to be clear, what I’m suggesting is that one does a randomized sorting procedure with the distance scales shrinking exponentially, and when one reaches a distance scale of 1, one repeats the entire process.
March 4, 2013 at 1:33 am |
I suppose roughly the reason is that for to be small you need t in the order of log n.
to be small you need t in the order of log n.
March 4, 2013 at 10:43 am
Hmm … it depends what we mean by small. I was thinking of “small” as meaning , so that for
, so that for  to be small we just need
to be small we just need  to be constant. But I can see that it isn’t obvious that that will work for all sequences rather than just almost all.
to be constant. But I can see that it isn’t obvious that that will work for all sequences rather than just almost all.
March 4, 2013 at 10:48 am |
It may not be feasible, but I quite like the idea of attempting something along the following lines. Given some kind of random comparator network, try to design a permutation, depending on the network, that will not be correctly sorted. With the help of this process, try to develop a sufficient condition for the permutation not to exist, and then try to show that that condition holds with positive probability.
To obtain the sufficient condition, what one might try to do is find a number of necessary conditions (saying things like that the network must “mix well” at every distance scale), and hope that eventually you have enough necessary conditions that taken together they are sufficient.
March 5, 2013 at 7:50 am
I wonder what lower bounds are known for the constant . There’s a trivial lower bound of
. There’s a trivial lower bound of  (from the fact that each round can have at most
(from the fact that each round can have at most  comparisons, and if
comparisons, and if  is the total number of comparisons then we must have
is the total number of comparisons then we must have  , and Stirling’s formula). Can anything more be said in this direction? What are the obstacles to creating such an efficient circuit?
, and Stirling’s formula). Can anything more be said in this direction? What are the obstacles to creating such an efficient circuit?
March 4, 2013 at 11:10 am |
Earlier, Gil asked for a precise statement of “what I am suggesting”. I’m not sure I can provide that yet, because there are a number of precise statements that I would be happy with. However, let me give a precise statement that I would be delighted to prove, but that might easily be false. If it is false, then I would want to find a modification of it that is true.
The precise statement is as follows. Let me define an –round of type 0 to be a set of comparisons of the following kind. First, partition
–round of type 0 to be a set of comparisons of the following kind. First, partition  into intervals of the form
into intervals of the form ![[2m(r-1), 2mr-1]](https://s0.wp.com/latex.php?latex=%5B2m%28r-1%29%2C+2mr-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , then partition each such interval into pairs
, then partition each such interval into pairs  (which can be done in exactly one way), and finally, do a comparison for all such pairs for which both
(which can be done in exactly one way), and finally, do a comparison for all such pairs for which both  and
and 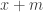 are between 1 and
are between 1 and  . Define an
. Define an  –round of type 1 to be the same except that the initial partition is into intervals of the form
–round of type 1 to be the same except that the initial partition is into intervals of the form ![[2m(r-1)+m,2mr-1+m]](https://s0.wp.com/latex.php?latex=%5B2m%28r-1%29%2Bm%2C2mr-1%2Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) . If we do an
. If we do an  -round of both types, then every place
-round of both types, then every place  between 1 and
between 1 and  will be compared with both place
will be compared with both place  and place
and place 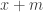 , provided both those places are between 1 and
, provided both those places are between 1 and  .
.
Now I propose the following comparator network. We choose a random sequence of integers , where
, where  is uniformly distributed in the interval (of integers)
is uniformly distributed in the interval (of integers) ![[1,ne^{-cs}]](https://s0.wp.com/latex.php?latex=%5B1%2Cne%5E%7B-cs%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and  is maximal such that
is maximal such that  . Then at step
. Then at step  we do an
we do an  round of type 0 followed by an
round of type 0 followed by an  round of type 1.
round of type 1.
When we have finished this, we repeat the process once.
My probably false suggestion is that for some fixed and with reasonable probability this defines a sorting network.
and with reasonable probability this defines a sorting network.
Incidentally, there is a detail in the above suggestion that reflects a point I have only recently realized, which is that if one is devising a random sorting network of roughly this kind — that is, with increasingly local comparisons — then it is important that there should be correlations between what happens in two different places at the same small distance scale. If not, then when we get to small distance scales, there are many opportunities for something bad to happen. That is, it might be that each little piece of network has a quite high probability of behaving well, but that if you choose many little pieces independently, then some of them will misbehave. The use of -rounds above is an attempt to get round this problem by making the network do essentially the same thing everywhere at each distance scale. (It doesn’t do this exactly, because of the ends of the intervals of length
-rounds above is an attempt to get round this problem by making the network do essentially the same thing everywhere at each distance scale. (It doesn’t do this exactly, because of the ends of the intervals of length 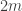 , but I’m hoping that that minor variation is not too damaging.)
, but I’m hoping that that minor variation is not too damaging.)
March 4, 2013 at 3:41 pm |
I now think that the suggestion in the previous comment is unlikely to give a depth better than . Here is why. The sum of the GP
. Here is why. The sum of the GP 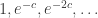 is approximately
is approximately 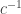 . So if an element starts out at a distance
. So if an element starts out at a distance 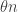 from where it should be and is not moved at any time during the first approximately
from where it should be and is not moved at any time during the first approximately  rounds, then at the end of all rounds it will still be at a distance proportional to
rounds, then at the end of all rounds it will still be at a distance proportional to  from where it should be. If we start with a random permutation, then the chances of this happening look to me like at least
from where it should be. If we start with a random permutation, then the chances of this happening look to me like at least 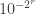 , since we only care about the values in at most
, since we only care about the values in at most  places.
places.
So I would expect that after the first round, the proportion of points that are a long way from where they should be will be at least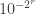 , which is an absolute constant (depending on the absolute constant
, which is an absolute constant (depending on the absolute constant  that we choose at the beginning).
that we choose at the beginning).
After the next round, something similar can be said, except that this time the probability that a point in one of the places is a bad point has gone down to more like
places is a bad point has gone down to more like 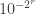 . But that still gives us a probability of
. But that still gives us a probability of  that the point will end up way out of place. And after
that the point will end up way out of place. And after  repetitions, we get to
repetitions, we get to  . For that to be smaller than
. For that to be smaller than  we need
we need  .
.
March 4, 2013 at 3:44 pm
To be clear, when I say that the suggestion in the above comment is unlikely to give a depth better than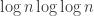 , what I actually mean is that the suggestion itself looks false, and to rescue it I think one would need to repeat at least
, what I actually mean is that the suggestion itself looks false, and to rescue it I think one would need to repeat at least 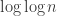 times rather than just once.
times rather than just once.
March 5, 2013 at 2:46 am |
[…] Gowers suggests a polymath project based on parallel sorting; Alexander Holroyd has a gallery of pictures of sorting […]
March 19, 2013 at 10:04 am |
I’m a bit late to this post, but the question sounds interesting and I would support it as well. Unfortunately, I don’t know much about it either.
– David Lowry-Duda
March 19, 2013 at 10:17 am |
I’d just like to throw something out there, so I beg forgiveness if this is a bit nonsensical. But I was reading up on the AKS network sort, and I read that a key idea in the method is to construct an expander graph. As a student of modular forms, I’ve heard that there is a way to construct expander graphs that is intimately connected to modular forms (somehow). While I don’t know much about this yet, I wonder if there is something to be gained from examining that connection a bit more closely.
March 24, 2013 at 7:35 pm |
Here is a test comment on another post, as requested.
March 26, 2013 at 1:52 pm |
I am definitely interested in thinking more about this problem.
March 31, 2013 at 6:07 pm |
“A final remark is that something that contributed a great deal to the health of the discussion about the Erdős discrepancy problem was the possibility of doing computer experiments. That would apply to some extent here too: one could devise an algorithm along the above lines and just observe experimentally how it does, whether points catch up after getting left behind, etc.”
huge fan of empirical/experimental approaches here too & think they are too much underutilized. an interesting strategy along these lines is something like what is called a “magnification lemma” seen in jukna’s new book on circuit theory. basically it is a way of translating or scaling problems of size N to size log(N) which might it more accessible to computer experiments of the results.
have recently collected various refs on experimental math on my blog home page links & am planning to do a post on the subject. theres also an excellent article on simons web site profiling zeilberger.
suggest that future polymath projects be launched with an eye toward supporting empirical attacks to support building technical intuition.
also, have been thinking that nobody has addressed this issue much, but basically polymath is an attempt to find “viral-like” projects which have high popularity. but there is currently no good way to sort out this popularity. so, suggest a voting system be built up so that projects can gain “critical mass” through measuring interest via votes. [similar to stackexchange mechanisms].
think that this difficulty in achieving “critical mass” is one of the key issues facing further polymath success. which by the way to my eye, speaking honestly/critically but hopefully also constructively, does not seem to be “clicking” so much since the original/initial gowers project.
March 31, 2013 at 6:17 pm |
one other point. it would be helpful if someone put together a survey of the status of polymath problems launched since the original gowers Hales-Jewett DHJ problem—its hard to keep track of them all. analyzing in particular not so much the results but the crowd level of participation and enthusiasm for each, which imho is a key ulterior factor of project success, a social-cultural aspect which is so far seems largely not addressed by any participants.
April 17, 2013 at 3:59 pm |
I’d like to say something else about expander graphs and that approach. I recently heard a talk by Dr. Cristina Ballantine at ICERM where she explained that she could construct expander bigraphs, i.e. low degree highly connected biregular bipartite graphs.
April 17, 2013 at 4:04 pm
I did not mean to end that post already – so I continue in a comment to myself.
From my (somewhat limited) experience with computer science algorithms, bigraphs made things much better than just highly connected graphs. Here, having a graph be biregularly bipartite (meaning that the vertices are of two families; in each, all the vertices have the same degree – but the two families can have different degrees from each other – and are directly connected only to the other family) seems like it might behave well with parallelizing the work, maybe.
Maybe this is something to consider?
May 29, 2013 at 5:00 am |
Sorry to diverge the thread, but based purely on heuristics, if you would like to have an $O(\log n)$ random parallel sorting algorithm I would think it would be hard to beat Markov chain monte carlo with an appropriate score to optimize the ordering.
July 3, 2015 at 7:14 am |
I know that over two years have passed, so I’m not sure how relevant the topic still is, but there is a newer (March 2014) interesting result from Goodrich:
Click to access 1403.2777.pdf
July 12, 2015 at 9:58 pm
Thanks for that reference!