This is the final post in the series about complexity lower bounds. It ends not with any grand conclusion, but just with the three characters running out of steam. The main focus of this final instalment is the Gaussian-elimination problem mentioned in earlier instalments (find an explicit nonsingular matrix over 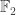 that needs a superlinear number of row operations to turn it into the identity). The discussion follows a familiar pattern, starting out with some ideas for solving the question, understanding why they are hopelessly over-optimistic, and ending with some speculations about why even this problem might be extremely hard.
that needs a superlinear number of row operations to turn it into the identity). The discussion follows a familiar pattern, starting out with some ideas for solving the question, understanding why they are hopelessly over-optimistic, and ending with some speculations about why even this problem might be extremely hard.
🙂 You know, since we started thinking about the Walsh matrix, I’ve begun to have my doubts about the burst of enthusiasm I had for the natural-proofs barrier when you first told me about it.
8) How do you mean?
🙂 Well, I started applying it to pretty well everything with no evidence to back up what I was doing. I gave a model for a random formula that turned out to be pretty hopeless, though it seems I was lucky and that pseudorandom generators with low formula complexity are known to exist (subject to the usual hypotheses). But I also said that it was plausible that no polynomial-time algorithm could distinguish between a random non-singular matrix over and a random matrix obtained from the identity by 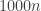 row operations. We’ve subsequently seen that that statement is false for an obvious reason: the second matrix will be sparse. It is possible to get round that problem, but I don’t see a strong argument for its being hard to give a superlinear lower bound, particularly given that the obvious way of producing a Walsh matrix takes time
row operations. We’ve subsequently seen that that statement is false for an obvious reason: the second matrix will be sparse. It is possible to get round that problem, but I don’t see a strong argument for its being hard to give a superlinear lower bound, particularly given that the obvious way of producing a Walsh matrix takes time 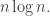 I think the point at which the problem becomes hard could just as easily be at around
I think the point at which the problem becomes hard could just as easily be at around  which is also the point at which a random sequence of row operations ought to produce a random-looking matrix.
which is also the point at which a random sequence of row operations ought to produce a random-looking matrix.
8) So do you have some idea of how you might go about proving a lower bound of  ?
?
🙂 I do actually. Not a properly thought through idea, so it’s very unlikely to work. But it’s just one of those ideas that you have to think about before dismissing it.
8) I think I know the kind you mean …
🙂 Ha ha. Anyhow, my thought was that when you build the Walsh matrix in the obvious way, you start with the  identity matrix. Then you make that into a block diagonal matrix with
identity matrix. Then you make that into a block diagonal matrix with  copies of
copies of 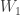 going down the diagonal. Then you pair those up to make
going down the diagonal. Then you pair those up to make 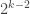 copies of
copies of  and so on. You have to do
and so on. You have to do  steps, and each step takes you
steps, and each step takes you  row operations.
row operations.
Now perhaps there is some parameter  that you can associate with matrices, with the following property. Let
that you can associate with matrices, with the following property. Let  be the block diagonal matrix that consists of
be the block diagonal matrix that consists of  copies of
copies of 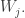 We would like to show that the number of row operations you need to apply to a matrix
We would like to show that the number of row operations you need to apply to a matrix  with
with  in order to obtain a matrix
in order to obtain a matrix  with
with  is at least
is at least 
I also have in mind an obvious parameter to try.
8) Oh yes?
🙂 Yes. It’s quite similar to the 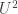 norm, and comes from the theory of quasirandom graphs. You take your
norm, and comes from the theory of quasirandom graphs. You take your 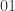 matrix, and convert it into a
matrix, and convert it into a  matrix in the usual way. If the converted matrix is
matrix in the usual way. If the converted matrix is 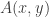 then the parameter is
then the parameter is

If is 1 everywhere, then you obviously get 1 for this expression. Also, since you can rewrite the expression as

and since  when
when 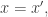 it follows that the value taken by the parameter is at least the probability that which is of course the reciprocal of the size of the set that
it follows that the value taken by the parameter is at least the probability that which is of course the reciprocal of the size of the set that  and
and 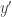 come from. In our case this size is
come from. In our case this size is 
Now what we are basically doing in calculating this parameter is taking the inner products of all pairs of rows, squaring them, and taking the average. Since the rows of a Walsh matrix (in its version) are orthogonal, we see that it has exactly the minimal value of the parameter I’ve just defined.
😐 I think that means you want to take the reciprocal. Earlier you said you wanted it to take at least row operations to get the parameter to increase by a certain amount.
🙂 Yes, you’re right. Or we might find that we wanted to go for some kind of dual definition to this one, as we did when we were looking at  norms, in which case we’d have an increasing parameter.
norms, in which case we’d have an increasing parameter.
😐 Do you mind saying exactly what you mean?
🙂 Not at all. If and are two real matrices of the same size, define  to be
to be 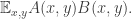 And then, if is the parameter I defined above, define a dual parameter
And then, if is the parameter I defined above, define a dual parameter  by
by

If is a matrix, then taking  gives us the inequality
gives us the inequality  So the Walsh matrix has parameter at least (and in fact equal to)
So the Walsh matrix has parameter at least (and in fact equal to) 
😐 So the fourth power that you put in there was just to make the maximum equal to  rather than
rather than 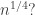
🙂 Sort of. Without the fourth power we get a norm, but the parameter was the fourth power of a norm and somehow it feels nicer to reflect that by making the fourth power of a norm as well.
Anyhow, what I’d very much like is for the value of the parameter at to double (or possibly halve if we decide to decrease) when  is replaced by
is replaced by  It seems that is not going to do that for us: the problem is that the identity matrix becomes a diagonal of
It seems that is not going to do that for us: the problem is that the identity matrix becomes a diagonal of  s in a sea of
s in a sea of  s, which is very unbalanced. Indeed, all the s in their versions are unbalanced.
s, which is very unbalanced. Indeed, all the s in their versions are unbalanced.
But being unbalanced is not so much of a defect when we take dual parameters, so perhaps we’ll have better luck there. What is of the identity?
Hmm …
😐 You’ve gone all quiet.
🙂 Sorry, I had to do some calculations. I’m coming to the conclusion that it is a nuisance to have matrices here. I want to define the parameter to be 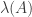 where is defined exactly as above but is a 01 matrix rather than a matrix. And now, if some hasty and unchecked guesses and calculations are to be believed, of the identity is something like
where is defined exactly as above but is a 01 matrix rather than a matrix. And now, if some hasty and unchecked guesses and calculations are to be believed, of the identity is something like 
8) Just as a matter of interest, how did you arrive at that figure?
🙂 I guessed that the Walsh matrix would be a good matrix for norming the identity. I suppose I should have tried the identity itself. What do we get there? Well, of the identity is  so
so  Since
Since 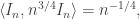 it follows that
it follows that 
I must apologize. That is now my revised guess. Indeed, I would guess that  is always worked out by hitting it with the appropriate multiple of
is always worked out by hitting it with the appropriate multiple of 
😐 Well it looks easy to work out 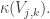 The probability that and all come from the same block is
The probability that and all come from the same block is  and the expectation of the thing you average over given that they do is
and the expectation of the thing you average over given that they do is 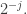 So you end up with
So you end up with  So the right multiple of should be
So the right multiple of should be  The inner product of with itself is, up to a constant factor,
The inner product of with itself is, up to a constant factor, 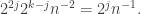 Putting in the normalizing factor we get
Putting in the normalizing factor we get  Finally, raising this to the power 4 gives us
Finally, raising this to the power 4 gives us  as the value, up to a constant, of
as the value, up to a constant, of  Note that this isn’t a proof, because we haven’t proved that is self-norming. But it seems to be at least potentially true.
Note that this isn’t a proof, because we haven’t proved that is self-norming. But it seems to be at least potentially true.
🙂 Right, and if it is true, then we could hazard a guess of the following kind. Perhaps in order to double the value of you have to apply at least a linear number of row operations.
8) I’m afraid I’m starting to feel very suspicious again.
🙂 Why?
8) Because the matrices are very sparse when is small, and could therefore be giving you a misleading impression. If we go back to the idea of creating an upper triangular matrix and then randomly applying row operations, we might well find that we could get in linear time to a matrix with  In fact, I wouldn’t be surprised if you could go all the way.
In fact, I wouldn’t be surprised if you could go all the way.
I’m not saying that you can get the Walsh matrix this way: it seems quite plausible, as you say, that the obvious way of producing it is the best. However, I think the parameter you are looking at may be too close to natural to work.
🙂 Ah yes. If you think about eigenvalues, I think you find that of a random matrix will be within a constant of the maximum, so if the proof worked it would certainly distinguish between random matrices and matrices that can be produced in operations.
Maybe to get a handle on this we should consider the following model for a random low-complexity matrix. Given any  matrix and any permutation
matrix and any permutation  of the numbers from to
of the numbers from to 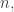 let
let  stand for the matrix you obtain from by adding row
stand for the matrix you obtain from by adding row  to row
to row  then row to row
then row to row  and so on all the way up to
and so on all the way up to  So row
So row  of is the sum of rows up to
of is the sum of rows up to 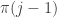 of
of 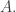
And now, to produce a matrix in linear time, choose  permutations
permutations 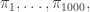 and take the matrix
and take the matrix
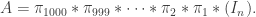
This can of course be thought of in another way: let  be the matrix that is 0 below the diagonal and 1 on and above it; then take matrices obtained by randomly and independently permuting the rows of ; then multiply them all together.
be the matrix that is 0 below the diagonal and 1 on and above it; then take matrices obtained by randomly and independently permuting the rows of ; then multiply them all together.
8) That’s more like it. Now we have a matrix that looks as though it could be hard to distinguish from a purely random (non-singular) matrix.
🙂 It seems to me that if this is a good model, then even  should be pretty scrambled. Indeed, without loss of generality,
should be pretty scrambled. Indeed, without loss of generality, 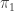 is the identity permutation. That means that
is the identity permutation. That means that 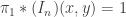 if
if  and
and  if
if  Writing for and writing for
Writing for and writing for  we then find that
we then find that 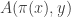 equals the parity of the set of all
equals the parity of the set of all  such that
such that 
If we now take 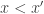 and add rows
and add rows 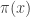 and
and  (mod 2), then we get the parity of the set of all
(mod 2), then we get the parity of the set of all  such that
such that 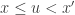 and This will be some random variable (depending on ), and as long as
and This will be some random variable (depending on ), and as long as  and are not too close to each other and
and are not too close to each other and  and
and 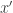 are also not too close to each other (a sufficient condition is that
are also not too close to each other (a sufficient condition is that  is significantly bigger than ) there will be very little correlation between the value we get at and the value we get at
is significantly bigger than ) there will be very little correlation between the value we get at and the value we get at 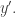 It would seem to follow that of this matrix will be very small, which does I think disprove the lemma that I hoped might show that you can’t get the Walsh matrix in linearly many operations. I’d have to check the details, but I definitely don’t believe in that approach any more. In fact, I think I’d now want to suggest that this new model of random low-complexity matrices could be polynomially indistinguishable from purely random matrices and go back to thinking that there cannot be a “natural” solution to the Gaussian-elimination problem.
It would seem to follow that of this matrix will be very small, which does I think disprove the lemma that I hoped might show that you can’t get the Walsh matrix in linearly many operations. I’d have to check the details, but I definitely don’t believe in that approach any more. In fact, I think I’d now want to suggest that this new model of random low-complexity matrices could be polynomially indistinguishable from purely random matrices and go back to thinking that there cannot be a “natural” solution to the Gaussian-elimination problem.
8) Of course, this suggestion is backed up by some serious hard thought, heuristic arguments, etc.?
🙂 No, I’m just making it off the top of my head, and am ready to abandon it if you can think of a clever way of working out what 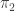 and
and  are if you are given the matrix
are if you are given the matrix 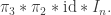 (Right at this moment I don’t even have a way of working out from
(Right at this moment I don’t even have a way of working out from 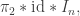 but I think there might be enough residual non-randomness to do that. But should clear that away I think.)
but I think there might be enough residual non-randomness to do that. But should clear that away I think.)
😐 Can I just share with you a thought that’s so naive-seeming that it really does seem as though it couldn’t possibly work?
8) Wow, that’s quite a plug. Let’s hear it!
😐 The thought I had was that the number of row operations you need to get from the identity to the Walsh matrix is the same as the number of row operations you need to get from the Walsh matrix to the identity.
8) Trivially. What good does that do?
😐 Well, as you pointed out, it is initially tempting to base arguments on the false assumption that the intermediate matrices have to be quite sparse. Unfortunately, 🙂 ‘s new model shows that no such argument can work. But what if we argued instead that when you work backwards from the Walsh matrix, it is very hard to get rid of all the 1s that you need to get rid of in order to end up with just of them down the diagonal? If you do some random scramblings, you certainly won’t make them any sparser.
8) There’s a pretty quick answer to that. If you’re trying to get from 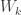 to the identity, why should you want to get rid of 1s as quickly as you can? Perhaps that greedy algorithm, so to speak, is far from optimal. Perhaps the best way to get the identity is to do some very clever sequence of operations that gives you a sequence of matrices that look pretty random but are secretly getting simpler (according to some complexity measure that we cannot calculate in polynomial time), and suddenly, ta da, we end up with a matrix that is 1 on and below the diagonal and 0 above it, which we can easily convert into the identity in a further
to the identity, why should you want to get rid of 1s as quickly as you can? Perhaps that greedy algorithm, so to speak, is far from optimal. Perhaps the best way to get the identity is to do some very clever sequence of operations that gives you a sequence of matrices that look pretty random but are secretly getting simpler (according to some complexity measure that we cannot calculate in polynomial time), and suddenly, ta da, we end up with a matrix that is 1 on and below the diagonal and 0 above it, which we can easily convert into the identity in a further  steps.
steps.
Basically, the property you were considering was “multiply by the Walsh matrix and see how many zeros you have,” which is far too natural a property to be likely to work.
😐 OK, I thought it was too much to hope for.
🙂 By the way, I think it’s easy to work out from  Indeed, let be the lower-triangular matrix that’s 1 everywhere on and below the diagonal. Then each row of the matrix
Indeed, let be the lower-triangular matrix that’s 1 everywhere on and below the diagonal. Then each row of the matrix 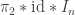 is a sum of rows of
is a sum of rows of  More precisely, the
More precisely, the  th row is a sum of the rows
th row is a sum of the rows 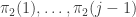 of But that means that the difference between rows
of But that means that the difference between rows 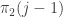 and of is the th row of I’m fairly sure all you have to do now is search for pairs of rows that have differences that look like this:
and of is the th row of I’m fairly sure all you have to do now is search for pairs of rows that have differences that look like this: 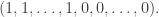 That will give you a directed graph, inside which you need a directed path of length
That will give you a directed graph, inside which you need a directed path of length  I think the graph will already be such a path, but haven’t checked this.
I think the graph will already be such a path, but haven’t checked this.
😐 What happens if you no longer assume that is the identity permutation?
🙂 Ah, perhaps for this algorithmic problem you do lose generality when you take  I see your point: it’s not that obvious what row-differences to look out for. But there are a few extremes. For example, you know that there will be a row difference that’s all 1s and another that has just one 1 in it. But I’m not sure that’s enough information to allow for an inductive proof or something like that.
I see your point: it’s not that obvious what row-differences to look out for. But there are a few extremes. For example, you know that there will be a row difference that’s all 1s and another that has just one 1 in it. But I’m not sure that’s enough information to allow for an inductive proof or something like that.
😐 Another question. Suppose it really is the case that no polynomial-time algorithm can distinguish between a random matrix of the form 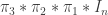 and a purely random matrix. (I’ve gone for three steps to be on the safe side.) What does that tell us about the Gaussian-elimination problem? Is there any conceivable argument that could solve it?
and a purely random matrix. (I’ve gone for three steps to be on the safe side.) What does that tell us about the Gaussian-elimination problem? Is there any conceivable argument that could solve it?
🙂 Well, we’d be in a similar situation to the one we are in for circuit complexity. We’d be wanting to find a property that is not given by a polynomial-time algorithm (and if we were being pessimistic we might even guess that the best algorithm took time  ), but that is somehow not “trivial”, so that it really does split the original hard problem into two easier parts.
), but that is somehow not “trivial”, so that it really does split the original hard problem into two easier parts.
😐 Can you say more precisely what you mean by a “trivial” property?
🙂 That is something I would very much like to be able to do. As things stand, I just feel as though I know one when I see it. For example, here the obvious “trivial” property is “Can be obtained using at most  row operations”. This distinguishes beautifully between matrices of the form and purely random matrices, but to prove that any given matrix does not have the property is trivially equivalent to the original problem.
row operations”. This distinguishes beautifully between matrices of the form and purely random matrices, but to prove that any given matrix does not have the property is trivially equivalent to the original problem.
😐 So perhaps we should focus on what would in principle count as a non-trivial property.
🙂 I have a necessary condition, but it’s very very far from sufficient.
😐 What’s that?
🙂 Simply that the property should be something that is shared not just by low-complexity functions but also by other functions as well.
8) Great!
🙂 OK, let me try to say something a tiny bit more interesting. I’d like to focus on properties in NP, since the contrast between “trivial” and “potentially useful” properties shows up already here.
Suppose, then, that we have a property in NP that we want to use to distinguish between low-complexity Boolean functions and random Boolean functions. We can obtain this as follows. Let  be a polynomially computable set of Boolean functions defined on
be a polynomially computable set of Boolean functions defined on  where
where  is the set of all Boolean functions defined on
is the set of all Boolean functions defined on  and
and  is the set of all Boolean functions defined on
is the set of all Boolean functions defined on  Then let
Then let  be the set of all Boolean functions
be the set of all Boolean functions 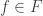 such that there exists
such that there exists 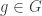 with
with  I want to distinguish between properties that say that
I want to distinguish between properties that say that  in some way includes a computation of
in some way includes a computation of  and more “natural” properties
and more “natural” properties 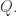
8) How do you propose to do that?
🙂 I don’t know, but I have a small idea about a possible way of getting started. It would be to use some logic. Roughly speaking, I’d want to introduce a language that allowed me various notions such as correlation between Boolean functions as primitives, and then I’d want to say that any formula that could be built in that language would give a property that could not give rise to an interesting lower bound.
For example, the property “correlates better with a quadratic than a typical random function does” would be something like “there exists such that is quadratic and  “.
“.
8) But how would you express “ is quadratic” in your language?
🙂 I’m not sure. Possibly I would allow all polynomially computable properties of and just place restrictions on how can relate to . But perhaps I’d insist on saying something like
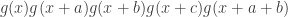
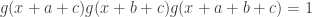
for every  which is a nice first-order formula concerning the values of
which is a nice first-order formula concerning the values of 
😐 But ultimately your property is second order because you say “there exists ” and is a function.
🙂 Yes. But I just do that once to make a property in NP. Perhaps then one could go further than NP and quantify more than once, obtaining a whole class of properties that cannot work. So in one sense they would be more general than NP, but in another sense they would form a smaller class, because we would be replacing “polynomially computable” by something much more restricted — but perhaps still general enough to be interesting and rule out all the attempts I have made so far. I would find this interesting even if I couldn’t actually prove it rigorously, as long as I could come up with a formulation that was not obviously false. I’d be even happier if I could show that the property in some sense had to involve encoding a computation of , but I don’t know how to make that idea precise.
😐 But if you could do that, wouldn’t you have shown that there was no proof that P NP?
NP?
🙂 Probably not. I agree that it sounds a bit like that — as though the only property that can distinguish between low-complexity functions and random functions is a property that essentially says “ has low complexity” — but that still leaves open the possibility of a property that fails the largeness condition. In other words, there might still be a property that holds for random functions but is carefully designed to fail for some specific function in NP.
😐 So where do all these conversations leave us?
🙂 Sadder but wiser, just as 8) predicted.
This entry was posted on November 10, 2009 at 12:57 pm and is filed under Uncategorized. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

November 10, 2009 at 3:10 pm |
I just wanted to thank you for a wonderful series.
(Also, I find it interesting that this last post is much less technical — at least to me — than many of the other ones.)
Is this problem still a potential polymath, or is it out?
November 10, 2009 at 4:06 pm |
The problem of trying to find circuit lower bounds for pretty much anything is pretty much out in my view. I just don’t have any feeling that I had with DHJ(3) that there was an approach that deserved to be investigated. In a sense you could say that these dialogues were a sort of pseudo-Polymath that went nowhere very much.
Having said that, I don’t completely rule out the idea of having a complexity-related Polymath project. There were some interesting questions about Boolean polynomials a few posts back, and one or two questions I quite like in this most recent instalment about trying to formulate more precisely the difference between an NP property that trivially reformulates the problem and one that doesn’t. (The motivation for that would be to have a more general natural-proofs barrier that rules out “potentially fruitful” NP properties and just leaves you with the useless ones.) I also had one or two thoughts about how one might go about trying to find a new public-key cryptosystem, though I was slightly thrown when Richard Lipton recently described this as a mathematical disease. Anyhow, I might ignore that, think a little bit more about my idea, and if I can get it to stop looking hopeless then I might try to turn it into a proposal.
Another idea might be if any experts in theoretical computer science had a good idea for a complexity-type project that is hard enough to be interesting but not super-hard in the way that many of the notorious problems are. (There were one or two suggestions early on — it might be a good idea to discuss them a little further.)
November 10, 2009 at 5:56 pm |
Here are 54 attempts to resolve P vs NP:
http://www.win.tue.nl/~gwoegi/P-versus-NP.htm
November 10, 2009 at 6:30 pm |
There is a closely related norm which I find it easier to think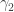 norm, also known as the Schur product operator
norm, also known as the Schur product operator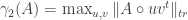
 . From this expression you can
. From this expression you can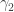 norm of the
norm of the  -by-
-by- Walsh
Walsh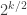 , taking
, taking  to be uniform unit
to be uniform unit
about, the
norm. This is defined as
where the max is over unit vectors, and you take the trace norm of A entrywise
product with the rank one matrix
see that the
matrix is at least
vectors. In fact, this is the exact value.
An equivalent formulation is
 is the largest
is the largest 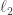 norm of a row of
norm of a row of  .
.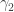 of the identity
of the identity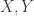 to be identities). Again this is
to be identities). Again this is
where
From this formulation you can see that
matrix is at most one (taking
the exact value.
Using both of these formulations, one can show
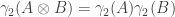 , which can give
, which can give matrices you talk about.
matrices you talk about.
the norm for the intermediate
It is somewhat disheartening that the obvious bound here, that
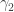 can increase by at most one with each row operation, seems
can increase by at most one with each row operation, seems operations to transform the
operations to transform the
 -by-
-by- Walsh matrix to identity.
Walsh matrix to identity.
to just give a lower bound of