This instalment has a brief discussion of another barrier to proving that P
**************************************
🙂 I’m afraid I’m not yet ready to tell you what basic 3-bit operations do to quadratic phase functions.
8) In that case, can I instead mention something I read that looks relevant?
🙂 Sure, go ahead.
8) Well, you may remember my mentioning that Scott Aaronson and Avi Wigderson have a paper in which they introduce another barrier to lower bound proofs, which they call “algebrization”. If a proof can be algebrized, then it can’t prove that P
😐 What does “algebrized” mean?
8) Unfortunately, my understanding of it is rather hazy. But it refers to a technique where in order to prove complexity results, you try to approximate low-complexity functions by low-degree polynomials over 

A proof that P



😐 What’s an oracle?
8) I’m a bit hazy on oracles too. Basically, it means that you can take some fairly complicated function and assume that your computer takes only one step to calculate it. (The word “oracle” is used for obvious reasons: it’s as though when the computer wants to know the value of this very complicated function, it just goes and asks the oracle.) One then writes 
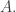



😐 Why would a proof remain valid for an arbitrary oracle?
8) The kinds of proofs we’ve been thinking about wouldn’t, but there is a very different class of techniques that would. The observation about oracles shows that you can’t hope to prove that P
😐 What do you mean by “diagonalization argument” in this context?
8) Well, one might try to run through all functions in P and construct a clever function in NP making sure that it disagrees with each function in P in at least one place. That’s the kind of thing you do to prove the insolubility of the halting problem. But for proving that P
😐 Why is that called “algebrization”?
8) It isn’t. That’s relativization. A proof that P
😐 I definitely would!
8) Anyhow, algebrization is a further twist, I think, where you have two oracles, and one is allowed to be a low-degree field extension of the other. Roughly, they show that you cannot prove that P
😐 But surely that’s already included in the relativization result? Just take

8) Hmm, that is quite confusing I agree. It may explain why I find this concept quite hard to grasp.
Aha, in the paper, which, incidentally, may be found here (or just Google “algebrization”), they say that they are referring to algebraic oracles, which they define as oracles that can work out not just the value of a function 

😐 But surely every Boolean function can be written as a polynomial.
8) Well, yes, but the polynomial will depend on 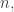
😐 What if you have two different polynomials that take equal values over one field but not over an extension?
8) I don’t think that’s a big problem. You’d just give some algebraic formula to the oracle and the oracle would be able to tell you the answer. It wouldn’t matter if some other algebraic formula happened to agree with it.
I’m sorry my understanding of this is less than perfect, but what I wanted to draw your attention to was the following few sentences from the Aaronson-Wigderson paper:
Can we pinpoint what it is about arithmetization that makes it incapable of solving these problems? In our view, arithmetization simply fails to “open the black box wide enough.” In a typical arithmetization proof, one starts with a polynomial-size Boolean formula
, and uses
But having done so, one then treats
as an arbitrary black-box function, subject only to the constraint that
is small. Nowhere does one exploit the small size of
except insofar as it lets one evaluate
🙂 Ah, I see why you’re saying that. Even if we don’t fully understand the algebrization barrier, we can still be a little sceptical of any proof attempt that makes use of polynomials without also making use of how those polynomials are put together. I think we’ve slightly run up against this thought in some of our earlier discussions actually. It seems to suggest that it is unlikely that we would be able to prove that applying 3-bit operations to arbitrary linear combinations of degree-
However, having said that I’d like to mention that the degree is by no means the only interesting parameter one can associate with a polynomial over
😐 Why, what else is there?
🙂 There’s also its rank.
😐 What does the rank of a polynomial mean? I thought ranks were things that linear maps had.
🙂 Well, let me first say what the rank of a quadratic is. Suppose you have a quadratic polynomial 

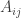




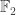
We can now define the rank of the original quadratic to be the rank of the associated bilinear form (or equivalently of the matrix). The rank has a direct impact on the 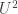




Using the fact that addition and subtraction are the same over 










😐 So if you’re talking about quadratics, then the rank is exactly what you are interested in, rather than the degree. Sorry, that was slightly silly—if the degree is fixed then obviously you aren’t interested in it.
🙂 But what you are saying is still basically right—it’s the rank that tells you all about the 
😐 So presumably for cubics you do the same thing, except that this time you get a trilinear map. Is that right?
🙂 Yes and no. Yes you do get a trilinear map, but now it isn’t obvious what you mean by the word “rank”.
😐 Why not?
🙂 Because there are several natural candidates for a definition, and they do not agree. The result is that there is no consensus about what the “right” definition should be for a multilinear map.
😐 What are some of these natural candidates?
🙂 Well, let 

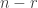






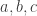


😐 That sounds a little tautological.
🙂 I know, but Gowers and Wolf observed that one could prove that this “analytic” rank had a number of useful properties. For example, they showed that if 


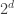

😐 So their result is weaker than what you’d get in the bilinear case from algebraic methods?
🙂 Yes, that’s odd. I expect it would be possible to improve the factor to 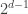


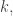
😐 Is there an algebraic interpretation of this notion of rank?
🙂 Sort of. In the trilinear case, for instance, 

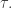


8) I’m not sure why you think that any notion of rank is going to be of any use in proving lower bound results.
🙂 Why not?
8) Because the rank is never going to be more than 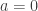
🙂 That does sound plausible, alas. I wonder if some principle like that follows from their results on algebrization. I feel like asking an expert about this.
8) Meanwhile, perhaps we should return to the question of what basic operations do to quadratic phase functions?
🙂 Oh yes, thanks for reminding me. But I’m afraid I still don’t have any progress to report. But I have had a little thought about it that I’d like to float past you.
8) OK.
🙂 I was a bit worried by your point that it is unlikely that a basic operation applied to a polynomial phase function of high degree will have 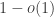
8) Ah, that sounds potentially interesting if you really can do it.
🙂 Well, the idea I had was this. If one is trying to prove that a function of low complexity is a linear combination, with coefficients that aren’t too big, of functions that are in some sense structured, such as low-degree polynomials and the like, then perhaps one can argue that the set of functions you use for 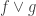


8) I sort of get the idea, and it sounds interesting in a way, but I worry that much of its interest may derive from its being rather vague and may vanish as soon as you try to express the idea more precisely. Can you give me a precise statement that says something like, “If there exists a set of functions 
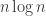
🙂 Let me tell you the kind of thing I had in mind. If you don’t mind I’ll call the set of functions 





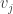

What can we then say about 
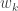


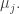
8) I can see a number of problems with this. To start with, if the coefficient sums go up by even a small constant factor each time you do a Boolean operation, then after a linear number of steps they will be exponentially large. But if your set 
But even if you can solve this problem (which is conceivable—for instance, there might be parameters other than the sum of the coefficients that could give you a measure of the “size” of the linear combination), there is another that seems to me to be more fundamental. Recall from an earlier conversation of ours that Boolean operations felt more like products than sums. Now what happens if you take the product of 





🙂 As ever, the water you pour over my ideas is well and truly cold. But there’s one point you made that I think needs to be thought about slightly harder.
8) As ever, you carry a little immersion heater around with you.
🙂 Something like that. What I wanted to say was that at a certain point you made the assumption that the cardinality of the set of functions 





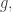
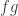

Now in general 


8) OK, but now you’ve introduced another idea into the picture. Your hypothesis would be not so much that you can write low-complexity functions as a linear combination of few structured functions, and more that you can write them as a linear combination of structured sets of structured functions. But where is your set-theoretic complexity measure now?
😐 I’ve thought of a question that might be worth considering. It just feels as though it could clarify the discussion a bit.
🙂 OK, what is it?
😐 Well, it seems to me that, motivated by the remarks of Aaronson and Wigderson, you are trying to distinguish between low-complexity and high-complexity polynomials, even when they have the same degree. This seems worth thinking about even for quadratics: a simple counting argument tells us that most quadratics have superlinear (in fact, almost quadratic) circuit complexity. So what is the difference between a high-complexity quadratic and a low-complexity quadratic? If you force yourself to think about just this question, then maybe you won’t keep coming up with properties that fail for known reasons.
🙂 That sounds like an excellent idea, but potentially also a very difficult one, because it might be possible to define “weird” quadratics by devising some clever low-complexity calculation that involves functions that are nothing like quadratics but that magically produce a quadratic at the end. But perhaps one could have a restricted model of computation that allowed more gates but insisted that all functions at every stage were quadratics.
8) That is sounding very like arithmetic complexity to me.
😐 What is arithmetic complexity?
8) It’s very like circuit complexity, but you replace the Boolean operations 
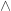

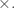


A very important fact in cryptography is that the arithmetic complexity of raising a number to a power modulo a large index 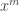




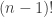

🙂 But I don’t see how this applies to quadratics, because they are not closed under taking products.
8) I agree that that’s a problem. But here’s the type of thing one could do. You’ll agree that the map 
🙂 Yes. I think it has rank either 
8) And it’s also computable in linear time, has linear arithmetic complexity, etc.
🙂 Yes, but its associated matrix is very sparse, since it has only 
😐 Sorry, but why
🙂 Because the bilinear form you get is symmetric: corresponding to each term 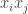

😐 Ah, I see.
8) The point I wanted to make is that you can produce less sparse matrices by producing some more interesting ensembles of linear forms than 




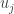
🙂 Ah, I like that. First of all, it really does seem a natural model for the computational complexity of quadratic forms over 

😐 Quick question: to what extent is the representation of a quadratic unique? In particular, might it have a “simple” representation and a “complex” one? Then in order to prove that a quadratic could not be computed in linear time (in this model) one would have to consider all possible representations rather than just one, which would be annoying.
🙂 I think uniqueness of any kind is too much to hope for. For example, if you work mod 3 instead and choose an arbitrary “orthonormal basis” (by which I mean a collection of binary sequences 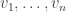

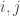




😐 Sorry, I got lost there—what is the general point?
8) It’s that one can probably find “weird” ensembles of linear forms that give you quadratics that can also be produced in non-weird ways. But now it’s my turn to be lost. What was the point you were making?
😐 I haven’t quite got it clear myself. But I liked this connection between the complexity of quadratic forms and the Gaussian-elimination problem and was trying to see how closely they were related. It seems that what you do here is a slightly generalized Gaussian-elimination procedure to produce two matrices (one with rows 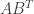
I suppose what I’m saying is that even if we could solve the Gaussian-elimination problem, we’d still have a long way to go.
🙂 I think that you are right, which is unfortunate.
😐 Thanks.
🙂 I don’t mean your correctness is unfortunate, but just that the correct fact you’ve identified (if it is correct) is a pity. But I still like your proposal that we should look at quadratics, because it still seems to be subject to the natural-proofs barrier, and we won’t be tempted to use crude parameters such as degree and rank because all our polynomials are quadratics and they can quite easily have maximal rank.
8) Yes, but now you haven’t the faintest idea how to prove anything.
🙂 That’s better than having lots of faint ideas that are guaranteed not to work. And in any case, now, despite what 😐 has pointed out, I want to think about the Gaussian-elimination problem. I have a simple question: how many Gaussian operations do you need in order to produce a quasirandom matrix?
😐 What do you mean by that?
🙂 I mean a matrix where the number of 1s is approximately 
8) That sounds like a very natural property to me.
🙂 Thank you.
8) I didn’t mean it as a compliment. It sounds easily computable, and hence very unlikely to be a good indication of complexity. I’m sure it will be possible to produce such matrices in a linear number of steps.
🙂 Oh yes. Well, perhaps we should just confirm that.
A random sequence of row operations doesn’t work I think, because each row ends up depending on only very few of the original rows. To put it another way, the matrix you end up with is far too sparse. But one can deal with that by first forming a triangular matrix with 0s on one side of the diagonal and 1s on the other side—it’s easy to see how to do that. Perhaps if one then applies a random sequence of Gaussian operations one reaches a quasirandom matrix in linear time.
8) Hmm, I’m not sure. For a start there will be a few rows that you will never touch again.
🙂 Yes, but all I need is for almost all rows to look random at the end of the process.
8) I think you need to be fussier than that. After all, the Paley matrix is very quasirandom according to your definition, so if you can’t produce extremely good quasirandomness in linear time then the Walsh matrix needs a superlinear number of row operations.
🙂 That was indeed an example I had in mind actually.
😐 What’s the Walsh matrix?
🙂 A quick definition is this: 
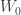


8) Right, how do you get that level of quasirandomness with linearly many row operations?
🙂 Hmm, we have an inductive construction, so presumably we can translate that into some inductively defined sequence of row operations. How do we produce 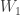



In general, if we’ve got the matrix 
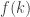



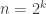
😐 It would be very surprising if that was not the quickest way of producing 
🙂 Maybe we should check. There’s obviously lots to think about here, but I’m getting tired. Shall we stop for now?
8) 😐 OK.

November 3, 2009 at 1:35 am |
In the notion of algebrization, the function is a low-degree polynomial (of degree
is a low-degree polynomial (of degree  ) over a field
) over a field  of size
of size  with the property that for every
with the property that for every  we have
we have  , where we identify the
, where we identify the  of the field
of the field  with the
with the  of the field
of the field  .
.
(There are actually going to be different fields for different input lengths, so
for different input lengths, so  can be seen as a family of functions parameterized by
can be seen as a family of functions parameterized by  , and the
, and the  -th function has domain
-th function has domain  where the size of the field
where the size of the field 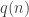 is polynomial in the dimension
is polynomial in the dimension  .)
.)
Having an algebrizing proof that means that for every
means that for every  and every
and every  that is in the above relation with
that is in the above relation with  we have
we have  .
.
In a relativizing proof, we would have that for every it holds
it holds  . This would imply that the proof also algebrizes, because for
. This would imply that the proof also algebrizes, because for  which is an “extension” of
which is an “extension” of  as defined above, we have
as defined above, we have  , simply because the oracle queries to
, simply because the oracle queries to  can be realized as oracle queries to
can be realized as oracle queries to  .
.
The converse, however, need not be true: it could be (and it is the case for certain complexity classes) that, even though there is an oracle such that
such that  , so that no relativizing proof that
, so that no relativizing proof that  is possible, for every
is possible, for every  and every extension
and every extension  we have
we have  , thanks to the extra power that we gain by evaluating
, thanks to the extra power that we gain by evaluating  at non-boolean points.
at non-boolean points.
November 3, 2009 at 1:43 am
Sorry for the mess: in the third paragraph, should be
should be  ; in the formula that does not parse a backslash is missing before ‘subseteq’, and later a backslash is missing before ’tilde.’ And ‘algebrization’ is misspelled in the first sentence.
; in the formula that does not parse a backslash is missing before ‘subseteq’, and later a backslash is missing before ’tilde.’ And ‘algebrization’ is misspelled in the first sentence.
[Thanks — I’ve edited out those typos now.]
November 3, 2009 at 4:57 pm |
I still find this concept weirdly difficult to understand. For example, you say that a proof that NP is not a subset of P algebrizes if for every and every
and every  that extends
that extends  we have
we have  . Later you say that
. Later you say that  . So surely the proof algebrizes if and only if
. So surely the proof algebrizes if and only if  . The proof would be that if you want to show that
. The proof would be that if you want to show that  for every
for every  that extends
that extends  it is enough to show it for the smallest such
it is enough to show it for the smallest such  , which is
, which is  .
.
I’m sure there’s something completely obviously wrong with what I’m writing, but I just don’t see it at the moment.
November 3, 2009 at 7:27 pm
Good point, evidently I too I was confused about the definition. I said that, in order to define an admissible , we choose a sequence of field sizes
, we choose a sequence of field sizes 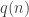 and then a sequence (indexed by
and then a sequence (indexed by  ) of polynomials over
) of polynomials over  which agree with
which agree with  on
on  . Then, as you say, one could take
. Then, as you say, one could take  and
and  .
.
Instead the definition of extension oracle (Def 2.2 in the paper) is as follows. To define an admissible , we pick for every
, we pick for every  and for every field
and for every field  a polynomial of low degree
a polynomial of low degree  over
over 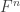 which agrees with
which agrees with  over
over 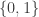 . Then the oracle
. Then the oracle  is the entire collection of polynomials.
is the entire collection of polynomials.
The definition tries to model the setting in which we have some kind of “interpolation formula” for , and hence we are able to evaluate the formula while doing operations over any field of our choice. No matter what field we choose, the invariant is maintained that over
, and hence we are able to evaluate the formula while doing operations over any field of our choice. No matter what field we choose, the invariant is maintained that over 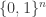 we recover
we recover  and that the polynomial degree of the function we compute is small. (The actual definition does not require that, for every
and that the polynomial degree of the function we compute is small. (The actual definition does not require that, for every  , there has to be a single algebraic formula from which all the
, there has to be a single algebraic formula from which all the  can be computed, and in fact it does not require any relationship between the
can be computed, and in fact it does not require any relationship between the  for different
for different  , other than agreeing over
, other than agreeing over 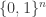 . This is just intuition for how an
. This is just intuition for how an  might actually look like.)
might actually look like.)
November 3, 2009 at 7:50 pm
Ah, I see now. So because you’re forced to choose an extension of to every field that extends
to every field that extends  , in a certain sense
, in a certain sense  is forced to be large and
is forced to be large and  is a correspondingly weaker statement than
is a correspondingly weaker statement than  , so saying that no proof that
, so saying that no proof that 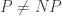 algebrizes is stronger than saying that no proof relativizes.
algebrizes is stronger than saying that no proof relativizes.