A few days ago I received an email from Brian Conrey, who has a suggestion for a possible Polymath project. The problem he wants to see solved is a little different from the problems in most previous projects, in that it is not a well known and long-standing question of acknowledged importance. However, that is not an argument against trying it out, since it is still far from clear what kinds of problems are best suited to the polymathematical approach, and it would be good to get more data. And this problem has other qualities that could make it very suitable indeed. First of all, it is quite new — it arises from a paper published last year, though it appeared on arXiv in 2013 — so we do not yet have a clear idea of how difficult it is, which should give us hope that it may turn out to be doable. Secondly, and more importantly, it is a very attractive question.
Suppose you have a pair of dice 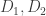 with different numbers painted on their sides. Let us say that
with different numbers painted on their sides. Let us say that 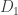 beats
beats 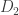 if, thinking of them as random variables, the probability that
if, thinking of them as random variables, the probability that 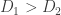 is greater than the probability that
is greater than the probability that 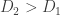 . (Here, the rolls are of course independent, and each face on each die comes up with equal probability.) It is a famous fact in elementary probability that this relation is not transitive. That is, you can have three dice
. (Here, the rolls are of course independent, and each face on each die comes up with equal probability.) It is a famous fact in elementary probability that this relation is not transitive. That is, you can have three dice  such that beats , beats
such that beats , beats 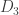 , and beats .
, and beats .
Brian Conrey, James Gabbard, Katie Grant, Andrew Liu and Kent E. Morrison became curious about this phenomenon and asked the kind of question that comes naturally to an experienced mathematician: to what extent is intransitivity “abnormal”? The way they made the question precise is also one that comes naturally to an experienced mathematician: they looked at  -sided dice for large and asked about limiting probabilities. (To give another example where one might do something like this, suppose one asked “How hard is Sudoku?” Well, any Sudoku puzzle can be solved in constant time by brute force, but if one generalizes the question to arbitrarily large Sudoku boards, then one can prove that the puzzle is NP-hard to solve, which gives a genuine insight into the usual situation with a
-sided dice for large and asked about limiting probabilities. (To give another example where one might do something like this, suppose one asked “How hard is Sudoku?” Well, any Sudoku puzzle can be solved in constant time by brute force, but if one generalizes the question to arbitrarily large Sudoku boards, then one can prove that the puzzle is NP-hard to solve, which gives a genuine insight into the usual situation with a 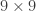 board.)
board.)
Let us see how they formulate the question. The “usual” -sided die can be thought of as a random variable that takes values in the set  , each with equal probability. A general -sided die is one where different probability distributions on
, each with equal probability. A general -sided die is one where different probability distributions on 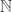 are allowed. There is some choice about which ones to go for, but Conrey et al go for the following natural conditions.
are allowed. There is some choice about which ones to go for, but Conrey et al go for the following natural conditions.
- For each integer
 , the probability
, the probability 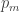 that it occurs is a multiple of
that it occurs is a multiple of  .
.
- If
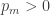 , then
, then  .
.
- The expectation
 is the same as it is for the usual die — namely
is the same as it is for the usual die — namely 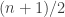 .
.
Equivalently, an -sided die is a multiset of size with elements in and sum  . For example, (2,2,3,3,5,6) and (1,2,3,3,6,6) are six-sided dice.
. For example, (2,2,3,3,5,6) and (1,2,3,3,6,6) are six-sided dice.
If we have two -sided dice  and
and  represented in this way as
represented in this way as 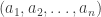 and
and 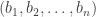 , then beats if the number of pairs
, then beats if the number of pairs 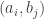 with
with 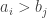 exceeds the number of pairs with
exceeds the number of pairs with 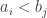 .
.
The question can be formulated a little over-precisely as follows.
Question. Let , and  be three -sided dice chosen uniformly at random. What is the probability that beats if you are given that beats and beats ?
be three -sided dice chosen uniformly at random. What is the probability that beats if you are given that beats and beats ?
I say “over-precisely” because there isn’t a serious hope of finding an exact formula for this conditional probability. However, it is certainly reasonable to ask about the limiting behaviour as tends to infinity.
It’s important to be clear what “uniformly at random” means in the question above. The authors consider two -sided dice to be the same if the probability distributions are the same, so in the sequence representation a random die is a random non-decreasing sequence of integers from that add up to — the important word there being “non-decreasing”. Another way of saying this is that, as indicated above, the distribution is uniform over multisets (with the usual notion of equality) rather than sequences.
What makes the question particularly nice is that there is strong evidence for what the answer ought to be, and the apparent answer is, at least initially, quite surprising. The authors make the following conjecture.
Conjecture. Let , and be three -sided dice chosen uniformly at random. Then the probability that beats if you are given that beats and beats tends to 1/2 as tends to infinity.
This is saying that if you know that beats and that beats , you basically have no information about whether beats .
They back up this conjecture with some experimental evidence. When 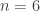 , there turn out to be 4417 triples of dice
, there turn out to be 4417 triples of dice 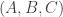 such that beats and beats . For 930 of these triples, and were tied, for 1756, beat , and for
such that beats and beats . For 930 of these triples, and were tied, for 1756, beat , and for 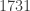 , beat .
, beat .
It seems obvious that as tends to infinity, the probability that two random -sided dice are tied tends to zero. Somewhat surprisingly, that is not known, and is also conjectured in the paper. It might make a good first target.
The reason these problems are hard is at least in part that the uniform distribution over non-decreasing sequences of length with entries in 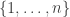 that add up to is hard to understand. In the light of that, it is tempting to formulate the original question — just how abnormal is transitivity? — using a different, more tractable distribution. However, experimental evidence presented by the authors in their paper indicates that the problem is quite sensitive to the distribution one chooses, so it is not completely obvious that a good reformulation of this kind exists. But it might still be worth thinking about.
that add up to is hard to understand. In the light of that, it is tempting to formulate the original question — just how abnormal is transitivity? — using a different, more tractable distribution. However, experimental evidence presented by the authors in their paper indicates that the problem is quite sensitive to the distribution one chooses, so it is not completely obvious that a good reformulation of this kind exists. But it might still be worth thinking about.
Assuming that the conjecture is true, I would imagine that the heuristic reason for its being true is that for large , two random dice will typically be “close” in the sense that although one beats the other, it does not do so by very much, and therefore we do not get significant information about what it looks like just from knowing that it beats the other one.
That sounds a bit vague, so let me give an analogy. Suppose we choose random unit vectors  in
in  and are given the additional information that
and are given the additional information that 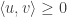 and
and 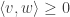 . What is the probability that
. What is the probability that  ? This is a simple exercise, and, unless I’ve messed up, the answer is 3/4. That is, knowing that in some sense
? This is a simple exercise, and, unless I’ve messed up, the answer is 3/4. That is, knowing that in some sense  is close to
is close to  and is close to
and is close to  makes it more likely that is close to .
makes it more likely that is close to .
But now let’s choose our random vectors from 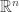 . The picture changes significantly. For fixed , the concentration of measure phenomenon tells us that for almost all the inner product
. The picture changes significantly. For fixed , the concentration of measure phenomenon tells us that for almost all the inner product 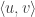 is close to zero, so we can think of as the North Pole and the unit sphere as being almost all contained in a thin strip around the equator. And if happens to be just in the northern hemisphere — well, it could just as easily have landed in the southern hemisphere. After a change of basis, we can assume that
is close to zero, so we can think of as the North Pole and the unit sphere as being almost all contained in a thin strip around the equator. And if happens to be just in the northern hemisphere — well, it could just as easily have landed in the southern hemisphere. After a change of basis, we can assume that 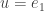 and is very close to
and is very close to 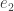 . So when we choose a third vector , we are asking whether the sign of its second coordinate is correlated with the sign of its first. And the answer is no — or rather, yes but only very weakly.
. So when we choose a third vector , we are asking whether the sign of its second coordinate is correlated with the sign of its first. And the answer is no — or rather, yes but only very weakly.
One can pursue that thought and show that the graph where one joins to if is, for large , quasirandom, which means, roughly speaking, that it has several equivalent properties that are shared by almost all random graphs. (For a more detailed description, Googling “quasirandom graphs” produces lots of hits.)
For the problem of Conrey et al, the combinatorial object being examined is not a graph but a tournament: that is, a complete graph with orientations on each of its edges. (The vertices are dice, and we draw an arrow from to if beats . Strictly speaking this is not a tournament, because of ties, but I am assuming that ties are rare enough for this to make no significant difference to the discussion that follows.) It is natural to speculate that the main conjecture is a consequence of a much more general statement, namely that this tournament is quasirandom in some suitable sense. In their paper, the authors do indeed make this speculation (it appears there as Conjecture 4).
It turns out that there is a theory of quasirandom tournaments, due to Fan Chung and Ron Graham. Chung and Graham showed that a number of properties that a tournament can have are asymptotically equivalent. It is possible that one of the properties they identified could be of use in proving the conjecture described in the previous paragraph, which, in the light of the Chung-Graham paper, is exactly saying that the tournament is quasirandom. I had hoped that there might be an analogue for tournaments of the spectral characterization of quasirandom graphs (which says that a graph is quasirandom if its second largest eigenvalue is small), since that could give a significantly new angle on the problem, but there is no such characterization in Chung and Graham’s list of properties. Perhaps it is worth looking for something of this kind.
Here, once again, is a link to the paper where the conjectures about dice are set out, and more detail is given. If there is enough appetite for a Polymath project on this problem, I am happy to host it on this blog. All I mean by this is that I am happy for the posts and comments to appear here — at this stage I am not sure what level of involvement I would expect to have with the project itself, but I shall certainly follow the discussion to start with and I hope I’ll be able to make useful contributions.
This entry was posted on April 28, 2017 at 2:39 pm and is filed under polymath13. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

April 28, 2017 at 7:45 pm |
Thanks, Tim, for posting this. The only thing I’d like to add is that of these and so about
of these and so about 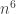 triples. Most of these triples
triples. Most of these triples of the triples have pairwise winners. When looking at these triples of one-step dice restricted to those triples which have pairwise winners we can prove that asymptotically 1/4 of the triples are intransitive, which is what our conjecture predicts. Our proof is very combinatorial; it considers 64 cases, and includes an interesting wrinkle having to do with triples that have special automorphisms. The details of the proof are in the first version of the paper we posted to the arxiv https://arxiv.org/pdf/1311.6511v1.pdf
of the triples have pairwise winners. When looking at these triples of one-step dice restricted to those triples which have pairwise winners we can prove that asymptotically 1/4 of the triples are intransitive, which is what our conjecture predicts. Our proof is very combinatorial; it considers 64 cases, and includes an interesting wrinkle having to do with triples that have special automorphisms. The details of the proof are in the first version of the paper we posted to the arxiv https://arxiv.org/pdf/1311.6511v1.pdf
we do have a small amount of theoretical evidence for our conjecture.
We call a die a “one-step” if it differs from the standard die only in
that one pip is removed from one face and placed on another. There are
about
have ties but around
April 28, 2017 at 9:38 pm |
Continuing the analogy with the angles-between-unit-vectors example, it is natural to ask the following question. Suppose we have two sets of -sided dice,
-sided dice,  and
and  , and suppose that every die in
, and suppose that every die in  beats every die in
beats every die in  . Must at least one of
. Must at least one of  and
and  have very small measure (where the measure is the uniform probability measure on the set of all
have very small measure (where the measure is the uniform probability measure on the set of all  -sided dice)? The analogy is that if you have two subsets
-sided dice)? The analogy is that if you have two subsets  and
and  of the
of the  -sphere and
-sphere and  for every
for every  and
and  , then at least one of
, then at least one of  and
and  has exponentially small measure.
has exponentially small measure.
This problem might be more tractable than the main one, but it is in the same ball park.
April 28, 2017 at 9:56 pm |
For the question of “How likely is it that two random dice are tied”…
The first natural thing you could hope for is “For any fixed die , the probability that
, the probability that  ties
ties  is small”. This is false — if
is small”. This is false — if  is the standard die, every die ties
is the standard die, every die ties  (due to the sum of the values on a die being fixed). But maybe somehow this is the only exception?
(due to the sum of the values on a die being fixed). But maybe somehow this is the only exception?
Suppose we fixed die to have values
to have values  . This naturally gives rise to a function
. This naturally gives rise to a function
The question of whether beats
beats  or not then comes down to whether the sum of this function over
or not then comes down to whether the sum of this function over  is positive, negative, or
is positive, negative, or  .
.
So you might hope that as long as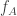 wasn’t somehow “too close” to the perfectly linear behavior for a standard die, a sum of
wasn’t somehow “too close” to the perfectly linear behavior for a standard die, a sum of  wouldn’t be too likely.
wouldn’t be too likely.
The complication here is that the are not quite independent, both because we’re considering multisets instead of sequences and because we’re requiring the sum of
are not quite independent, both because we’re considering multisets instead of sequences and because we’re requiring the sum of  to be a fixed value.
to be a fixed value.
April 29, 2017 at 9:56 am
I like this idea. To make a start on it, one could consider a few specific examples of dice . For example, the simplest one to analyse is probably
. For example, the simplest one to analyse is probably
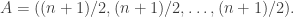
 from the given model, and define
from the given model, and define  to be the number of values of
to be the number of values of  that are less than
that are less than 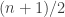 plus half the number that are equal to
plus half the number that are equal to 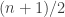 . It seems pretty plausible that the distribution of
. It seems pretty plausible that the distribution of  , which is something like a normal distribution with mean
, which is something like a normal distribution with mean  and variance tending to infinity (and quite possibly being of order
and variance tending to infinity (and quite possibly being of order 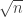 ), which would make the probability that it hits
), which would make the probability that it hits  on the nose be
on the nose be 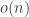 .
.
Now take a random multiset
April 29, 2017 at 10:10 am
Also, it looks to me as though the ties question becomes much easier if we use the alternative distribution mentioned in Kent Morrison’s comment below. That is (if I understand correctly) we take a random -sided die to be a random sequence
-sided die to be a random sequence 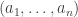 of integers between 1 and
of integers between 1 and  . Now for each fixed
. Now for each fixed  the analogues of the numbers
the analogues of the numbers 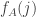 are independent. There are some extreme cases where ties are quite likely, such as when
are independent. There are some extreme cases where ties are quite likely, such as when  half the time and
half the time and  the other half of the time, in which case
the other half of the time, in which case 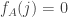 with probability close to 1 and there’s a good chance that every
with probability close to 1 and there’s a good chance that every 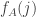 is zero. But for any reasonable
is zero. But for any reasonable  — perhaps one where the variance of a random
— perhaps one where the variance of a random  isn’t almost as big as it can be — it looks as though this won’t happen and that standard probabilistic techniques can be used to show that a tie happens with probability tending to zero.
isn’t almost as big as it can be — it looks as though this won’t happen and that standard probabilistic techniques can be used to show that a tie happens with probability tending to zero.
So unless I’ve misunderstood the model, it looks to me as though studying random sequences as above would be a good idea: it would be nice to prove that the tournament is quasirandom for some sensible model, even if it turns out to be hard for the original model.
April 28, 2017 at 10:32 pm |
Our dice are modeled as multi-sets of size with elements being integers from
with elements being integers from  to
to  and with the total being
and with the total being  . But we also looked at defining them to be ordered
. But we also looked at defining them to be ordered  -tuples with the uniform probability distribution. In this picture the induced probability on the multi-set model is no longer uniform. However, the computer simulations of random triples of these dice with
-tuples with the uniform probability distribution. In this picture the induced probability on the multi-set model is no longer uniform. However, the computer simulations of random triples of these dice with  sides (or so) showed the same results as for the multi-set model, and so we think that the conjectures hold for either of these two definitions of random dice.
sides (or so) showed the same results as for the multi-set model, and so we think that the conjectures hold for either of these two definitions of random dice.
On the other hand, the problem does show sensitivity to the choice of model. Suppose we define an -sided die to be a partition of
-sided die to be a partition of  with exactly
with exactly  parts. Now it is possible for sides to have values greater than
parts. Now it is possible for sides to have values greater than  . Put the uniform probability measure on the set of these partitions. Then the numerical simulations show that random triples are much less likely to form an intransitive cycle than they are to be a transitive chain. In this case the “typical” die is farther from the standard die than in the two models above.
. Put the uniform probability measure on the set of these partitions. Then the numerical simulations show that random triples are much less likely to form an intransitive cycle than they are to be a transitive chain. In this case the “typical” die is farther from the standard die than in the two models above.
There are a couple of other models that show different degrees of intransitivity that are described in our paper.
April 29, 2017 at 6:36 am |
[…] https://gowers.wordpress.com/2017/04/28/a-potential-new-poly… […]
April 29, 2017 at 11:41 am |
I’m beginning to think that the main conjecture should be true and not too hard to prove in the alternative model where a random -sided die is simply given by choosing each face independently and uniformly from
-sided die is simply given by choosing each face independently and uniformly from 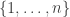 . I think it should be the case that for almost all pairs
. I think it should be the case that for almost all pairs  of random dice, if you choose a random die
of random dice, if you choose a random die  , then the four possibilities for which of
, then the four possibilities for which of 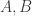 it beats all occur with probability roughly 1/4. The proof would come down to analysing two sums of i.i.d. random variables. The first ones would be distributed as
it beats all occur with probability roughly 1/4. The proof would come down to analysing two sums of i.i.d. random variables. The first ones would be distributed as 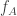 and the second ones as
and the second ones as 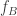 . The subtle point is that the two sums are not themselves independent: when we choose a random
. The subtle point is that the two sums are not themselves independent: when we choose a random  to go into
to go into  , each
, each 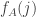 is quite strongly correlated with
is quite strongly correlated with  . But as long as
. But as long as  and
and  are not too similar, there should be plenty of
are not too similar, there should be plenty of  with
with 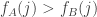 and plenty with
and plenty with  . So I feel optimistic that we should be able to identify a condition that is almost always satisfied that makes precise the idea that
. So I feel optimistic that we should be able to identify a condition that is almost always satisfied that makes precise the idea that  and
and  are not too similar.
are not too similar.
April 29, 2017 at 1:09 pm
Actually, the condition is not that mysterious. We need to look at the random variables . I.e., we care about the joint distribution of
. I.e., we care about the joint distribution of 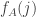 and
and  when a random
when a random  is chosen. This will give us a sum of 2D i.i.d. random variables and its distribution should be a 2D normal distribution. Then I think what matters is whether the corresponding ellipse is equally distributed in the four quadrants, or something like that.
is chosen. This will give us a sum of 2D i.i.d. random variables and its distribution should be a 2D normal distribution. Then I think what matters is whether the corresponding ellipse is equally distributed in the four quadrants, or something like that.
All this feels like the kind of thing that I or someone else should be able to work out given a quiet hour or two, which as it happens I don’t have for a little while …
April 29, 2017 at 5:16 pm
I still don’t have time to sit down with a piece of paper, but I can be slightly more specific about what I think needs to be worked out. Given two random dice and
and  , we will find that a typical
, we will find that a typical  will beat each of them with probability approximately 1/2. That’s because the probability is related to a sum of independent bounded random variables, and that sum is with high probability close to its mean.
will beat each of them with probability approximately 1/2. That’s because the probability is related to a sum of independent bounded random variables, and that sum is with high probability close to its mean.
To examine the correlation, we need to do something like this. We find that for some we have
we have 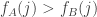 and for other
and for other  we have the reverse, and the average value of
we have the reverse, and the average value of  should I think be close to zero even if we condition on
should I think be close to zero even if we condition on  beating
beating  , because typically
, because typically  will only just beat
will only just beat  . I think it’s possible that one will be able to express all this rather neatly so that calculations become simple, but that I can’t see in my head.
. I think it’s possible that one will be able to express all this rather neatly so that calculations become simple, but that I can’t see in my head.
April 29, 2017 at 6:33 pm |
Regarding a spectral characterization for quasi-random tournaments, it seems that one does at least have a characterization in terms of counting a single tournament analogous to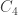 for graphs, namely the tournament with four vertices x,x’,y,y’ with both x vertices pointing at both y vertices.
for graphs, namely the tournament with four vertices x,x’,y,y’ with both x vertices pointing at both y vertices.
To see this, let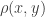 be the function which is 1 if x points to y and -1 if y points to x. Then we can consider the value
be the function which is 1 if x points to y and -1 if y points to x. Then we can consider the value 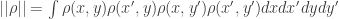 . Just like in the graph case, one can show that
. Just like in the graph case, one can show that  for any rectangle
for any rectangle 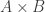 .
.
In particular, if is not quasi-random, we have
is not quasi-random, we have 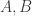 so that
so that 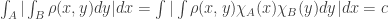 (in the notation of Chung-Graham, this is written
(in the notation of Chung-Graham, this is written  ), and therefore by Cauchy-Schwarz,
), and therefore by Cauchy-Schwarz, 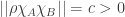 .
.
April 29, 2017 at 11:03 pm
This looks similar, but not identical, to the property P3 in Chung and Graham’s paper, which says that you have roughly the right number of “even 4-cycles” where that’s defined as a 4-cycle where the number of edges going in each direction is even.
April 29, 2017 at 11:28 pm
Ah, you’re right. I was expecting to see a characterization of this kind, and didn’t notice that P3 could be interpreted that way.
April 30, 2017 at 5:40 pm |
After thinking a bit more, I have realized that I have clearly misinterpreted Kent Morrison’s sentence “But we also looked at defining them to be ordered n-tuples with the uniform probability distribution.” I took it to mean that n-tuples were chosen uniformly from the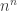 possible n-tuples of integers from
possible n-tuples of integers from  . It’s actually been quite instructive to think about this case and to see why one would not expect intransitivity to be common for it.
. It’s actually been quite instructive to think about this case and to see why one would not expect intransitivity to be common for it.
Let and
and  be two dice chosen from this model. As above, let
be two dice chosen from this model. As above, let 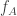 be the function defined by taking
be the function defined by taking 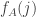 to be the number of
to be the number of  such that
such that  minus the number of
minus the number of  such that
such that 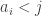 . (Actually, that’s minus what we had before, but it’s more convenient this way round for this comment.) Then
. (Actually, that’s minus what we had before, but it’s more convenient this way round for this comment.) Then  beats
beats  if
if 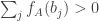 .
.
A key point with this model is that we are not assuming that the sum of the values of the faces is . That is what it will be on average, but there will be a standard deviation of order
. That is what it will be on average, but there will be a standard deviation of order 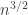 , and that turns out to make a big difference.
, and that turns out to make a big difference.
The reason it makes a difference is that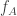 does not have to have average zero, so if we find that
does not have to have average zero, so if we find that  beats
beats  , that is quite strong evidence that for this particular
, that is quite strong evidence that for this particular  we have that
we have that 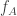 has an average somewhat greater than zero — perhaps some smallish multiple of
has an average somewhat greater than zero — perhaps some smallish multiple of 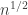 . And if that’s the case, then it makes
. And if that’s the case, then it makes  a whole lot more likely to beat some other
a whole lot more likely to beat some other  as well. So for this model, we certainly do not expect the tournament to be quasirandom.
as well. So for this model, we certainly do not expect the tournament to be quasirandom.
There will be a second part to this comment, but no time for that right now.
April 30, 2017 at 10:12 pm |
Another way of seeing that if you define a random -sided die to be a random element of
-sided die to be a random element of  then you shouldn’t get intransitivity that often is as follows. Let
then you shouldn’t get intransitivity that often is as follows. Let  and
and  be two such dice chosen randomly and then fixed. Then the random variables
be two such dice chosen randomly and then fixed. Then the random variables 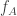 and
and 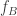 will have mean zero and variance of order
will have mean zero and variance of order  . Also, they will typically be fairly close to the uniform distribution on
. Also, they will typically be fairly close to the uniform distribution on ![[-n,n]](https://s0.wp.com/latex.php?latex=%5B-n%2Cn%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
The variance of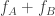 will therefore be of order
will therefore be of order  , but the variance of
, but the variance of  will be much smaller — I think a typical value will be of order
will be much smaller — I think a typical value will be of order 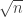 so the variance should be around
so the variance should be around  .
.
I’m not guaranteeing that everything I write is correct, but it seems to me, therefore, that if we take a sum of independent random variables distributed like
independent random variables distributed like 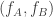 , we will get something close to a 2D normal distribution with major axis in the
, we will get something close to a 2D normal distribution with major axis in the 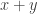 direction and minor axis in the
direction and minor axis in the  direction, with a hugely bigger variance in the
direction, with a hugely bigger variance in the 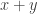 direction. But this means that it will almost always lie either in the positive quadrant or in the negative quadrant. That is, if
direction. But this means that it will almost always lie either in the positive quadrant or in the negative quadrant. That is, if  beats
beats  , then almost always
, then almost always  will beat
will beat  as well.
as well.
Now that I’ve written that, I don’t believe it, because it’s too extreme. It would seem to imply that if I choose two random dice and find that one beats the other, then almost all the remaining dice are in between, and that clearly can’t be true: beating another die can give some information, but surely not that much. I’ll have to try to work out where I’ve gone wrong.
May 1, 2017 at 10:31 am
I think my mistake was in accidentally assuming that will average zero. In this model, that may well not be the case, and if it isn’t, then a sum of random copies of
will average zero. In this model, that may well not be the case, and if it isn’t, then a sum of random copies of  will have a significant drift.
will have a significant drift.
April 30, 2017 at 10:45 pm |
$math$
April 30, 2017 at 10:56 pm
The answer to your implicit question is that if you want some mathematics to appear, you write it like TeX but with the word “latex” after the first dollar (with no space). For example, if you want to render the expression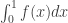 you write $laatex \int_0^1 f(x) dx$, except that there should be only one “a” in “latex”.
you write $laatex \int_0^1 f(x) dx$, except that there should be only one “a” in “latex”.
April 30, 2017 at 11:27 pm |
Despite my not yet resolved confusion in my 10:12pm comment above, let me mention something else that seems relevant.
Suppose now that we take as our model the uniform distribution over sequences of length with values in
with values in  that add up to
that add up to  . (I think perhaps this is the model Kent Morrison meant that gives behaviour similar to the random-multiset model. But I’m not sure.) If we fix
. (I think perhaps this is the model Kent Morrison meant that gives behaviour similar to the random-multiset model. But I’m not sure.) If we fix  and now take a random die
and now take a random die  , we are taking
, we are taking  random samples
random samples 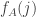 of the random variable
of the random variable 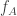 , except that this time we know that the sum of the
, except that this time we know that the sum of the  is
is  .
.
Now let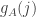 be the number of
be the number of 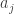 that are at most
that are at most  , and let
, and let 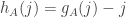 . Thus,
. Thus, 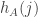 is the number of
is the number of 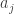 that are at most
that are at most  minus what we expect that to be. The order of magnitude of a typical
minus what we expect that to be. The order of magnitude of a typical 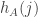 will be about
will be about 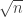 .
.
If we know that , then we know that
, then we know that 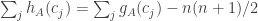 . I haven’t been careful enough about ties, but if I had, then I think this would be equal to
. I haven’t been careful enough about ties, but if I had, then I think this would be equal to 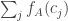 .
.
The basic point I want to make is that we seem, with this conditioning, to be able to write the quantity that determines whether beats
beats  as a sum of random variables that should have a much smaller variance than
as a sum of random variables that should have a much smaller variance than 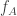 , namely the variables
, namely the variables 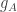 . Probably what was wrong with the earlier comment is that we can do something a bit like that there.
. Probably what was wrong with the earlier comment is that we can do something a bit like that there.
I still feel confused, but I think the random variables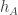 may be useful for showing that certain correlations are weak: I would expect
may be useful for showing that certain correlations are weak: I would expect 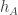 and
and 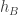 to be hardly correlated at all for most pairs
to be hardly correlated at all for most pairs  .
.
May 1, 2017 at 11:01 am
I think my confusion is now resolved (see May 1st 10:31am comment just above).
May 3, 2017 at 1:27 pm
Yes, that’s the model that I meant. The sums of the -tuples are
-tuples are  just as in the multiset model.
just as in the multiset model.
May 1, 2017 at 11:00 am |
OK, let me say a few things rigorously about the variables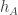 .
.
Let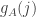 be
be 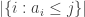 . Then
. Then
If we make the assumption that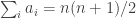 , then this equals
, then this equals  . Therefore, if we set
. Therefore, if we set 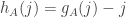 , then we get that
, then we get that 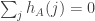 .
.
Now let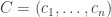 and suppose that
and suppose that 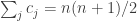 . Then
. Then
Actually, this is still unsatisfactory from the point of view of ties. I’ll write another comment soon with a better choice. But the above is coming close to showing that the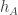 average zero and that to determine whether
average zero and that to determine whether  beats a randomly chosen
beats a randomly chosen  we take the almost independent sum
we take the almost independent sum 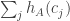 and look at its sign.
and look at its sign.
What I am now hoping is that for almost all pairs the random variables
the random variables 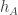 and
and 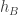 are of mean zero (that bit is OK) and are uncorrelated. That is, I want
are of mean zero (that bit is OK) and are uncorrelated. That is, I want 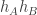 to have mean close to zero as well. That should I think be enough to allow us to argue that if
to have mean close to zero as well. That should I think be enough to allow us to argue that if  beats
beats  it gives us very little clue about whether
it gives us very little clue about whether  beats
beats  .
.
May 1, 2017 at 11:45 am |
Here’s a cleaner choice of random variables to use. Again I’ll just do a few simple calculations.
I’ll return to Kevin Costello’s random variables
On average, we expect that to be . So we now create some new variables that we expect to be a lot smaller, namely
. So we now create some new variables that we expect to be a lot smaller, namely
The main calculation I want to do is to show that if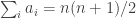 , then
, then 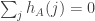 . Here it is.
. Here it is.
May 1, 2017 at 11:51 am
And another calculation is the following. Let be another die, again with faces adding up to
be another die, again with faces adding up to  . Then
. Then
The last two terms cancel, so the sign of this sum tells us whether beats
beats  or
or  beats
beats  or it’s a tie.
or it’s a tie.
May 1, 2017 at 3:24 pm |
I’ve done another calculation, which I won’t present here, but I’ll give the result. (Maybe I’ll give the full calculation in a second post at some point.) It’s an expression for , where
, where 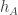 and
and 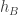 are defined as in the previous comment. I end up with
are defined as in the previous comment. I end up with
I’ve written it in that not quite fully simplified form to make it more transparent where the terms come from if anyone else feels like doing the calculation too.
What I’d like is to be able to show that for a typical pair this is a lot smaller than
this is a lot smaller than 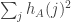 or
or 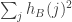 . However, I don’t see how to do that at the moment. But intuitively I’d expect
. However, I don’t see how to do that at the moment. But intuitively I’d expect  to be around
to be around  on average, and I’d expect
on average, and I’d expect  to be around 0 on average.
to be around 0 on average.
May 2, 2017 at 10:51 am |
A couple of suggestions/ questions / reformulations.
The question is whether tournament G with vertices dices and arrows “who beats who” is quasi-random. A necessary (not sufficient) condition for this is that, for almost every vertex/dice A, |Out(A)-Int(A)|=o(|G|), where Out(A) and Int(A) are the number of dices beaten by A and which beats A, respectively. More precisely, for every e>0, there is N, such that if |G|>N, then |Out(A)-Int(A)| < e|G| holds for all except e fraction of A.
I would start with investigating for which distributions this holds. For example, if we do not require the sum to be fixed, then it obviously fails for A which happened to have a sum much higher/lower than average.
On a different note, it seems convenient to subtract (n+1)/2 from values (1,2,…,n), and assume that n=2k+1 is odd, so that possible values are (-k,-k+1,…,k-1,k) and the sum is required to be 0. More generally, why not allow arbitrary distributions, including continuous ones? A nice special case when dice values are taken from standard normal distribution, subject to condition that the sum is 0. Due to rotation invariant property of normal distribution, this may be equivalent (?) to selecting dices uniformly at random from n-dimensional unit sphere intersected with plane x1+…+xn=0. This distribution looks "nicer" than suggested by authors. At least, in this setting, the ties question trivially holds. Now, the question is, is (almost) every point A on the sphere beats area which is about half of the sphere?
May 2, 2017 at 11:03 am
That sounds like a nice question at the end there.
Maybe it will be helpful (for others) if I mention an example that demonstrates that the condition you discuss is indeed not sufficient. Take the cyclic group of order and put an arrow from
and put an arrow from  to
to  if
if 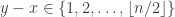 . Then each vertex is joined to almost exactly half the other vertices, but the out-neighbourhoods of vertices that are close to each other are strongly correlated, so the tournament is far from quasirandom.
. Then each vertex is joined to almost exactly half the other vertices, but the out-neighbourhoods of vertices that are close to each other are strongly correlated, so the tournament is far from quasirandom.
May 3, 2017 at 12:06 am |
Possible typo (unless I’m being dim): in your list of Conrey’s 3 conditions in the fourth para of your post, shouldn’t the formula for the expectation be the sum over m of [m.p subscript m] rather than the sum over m of [p subscript m]?
Thanks, it was indeed a typo — now corrected.
May 4, 2017 at 1:47 pm |
It seems it might be easier, or anyway neater, if the probabilities don’t have to be multiples of . So a die is a vector
. So a die is a vector 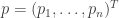 with
with 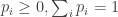 , and
, and  . According to my calculations, which need to be checked…
. According to my calculations, which need to be checked…
Let be a
be a  matrix with 1s on the diagonal, 0s above the diagonal and 2s below. Let
matrix with 1s on the diagonal, 0s above the diagonal and 2s below. Let  be the standard die. Then
be the standard die. Then  beats
beats  iff
iff 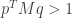 . Also
. Also 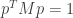 for any allowed
for any allowed  , and the condition
, and the condition  is equivalent to
is equivalent to 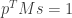 .
.
In the case the allowed
case the allowed  s lie in a 2D kite shape, with corners at (1/2,0,0,1/2), (0,3/4,0,1/4), (0,1/2,1/2,0), and (1/4,0,3/4,0). If you draw line through
s lie in a 2D kite shape, with corners at (1/2,0,0,1/2), (0,3/4,0,1/4), (0,1/2,1/2,0), and (1/4,0,3/4,0). If you draw line through  and
and  , it divides the kite into dice that
, it divides the kite into dice that  beats and those that beat it.
beats and those that beat it.
May 5, 2017 at 10:00 pm
This is an attractive model that should show the same behavior as the multiset dice model and the ordered tuple dice model (both with sums constrained to be . There is the advantage that ties obviously have probability zero, and I think that you see the probabilities of the tournament graphs converging faster to the equally likely probability as
. There is the advantage that ties obviously have probability zero, and I think that you see the probabilities of the tournament graphs converging faster to the equally likely probability as  grows.
grows.
I’ve just done some random sampling of three distribution vectors for , and for each
, and for each  the 8 different tournament graphs all occur with about the same frequency for a few thousand samples.
the 8 different tournament graphs all occur with about the same frequency for a few thousand samples.
Rather than the using , one could use the skew-symmetric matrix
, one could use the skew-symmetric matrix  with
with  ’s below the diagonal, and then, necessarily,
’s below the diagonal, and then, necessarily,  ’s on the diagonal and
’s on the diagonal and  ’s above the diagonal. Then
’s above the diagonal. Then  beats
beats  iff
iff  , and the condition that
, and the condition that  is equivalent to
is equivalent to  .
.
May 5, 2017 at 11:59 pm |
Suppose that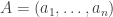 is a random
is a random  -tuple of integers from
-tuple of integers from  , chosen uniformly from all such triples subject to the condition that
, chosen uniformly from all such triples subject to the condition that 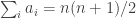 . Now let
. Now let  be the number of
be the number of  such that
such that 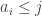 , and let
, and let 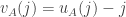 . Given
. Given  and
and 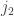 , I would like to understand how the random variables
, I would like to understand how the random variables  and
and 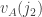 depend on each other, and roughly how they are distributed.
depend on each other, and roughly how they are distributed.
I would expect that if is not too close to 1 or
is not too close to 1 or  , then
, then 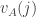 is approximately normally distributed with mean zero. (The mean zero part is OK.) But while that’s easy to prove without the conditioning on the sum, it is less clear with that conditioning.
is approximately normally distributed with mean zero. (The mean zero part is OK.) But while that’s easy to prove without the conditioning on the sum, it is less clear with that conditioning.
Also, if and
and 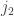 are very close, then obviously
are very close, then obviously  and
and 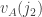 will be positively correlated. But what about, say,
will be positively correlated. But what about, say,  and
and 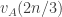 ?
?
If is a purely uniform
is a purely uniform  -tuple of elements of
-tuple of elements of  , then these two random variables are correlated. Indeed, if
, then these two random variables are correlated. Indeed, if  , then there are
, then there are 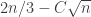 more numbers, all in the range from
more numbers, all in the range from  to
to  , to be chosen randomly. On average, half of these will be less than or equal to
, to be chosen randomly. On average, half of these will be less than or equal to  , so on average
, so on average  will be
will be
 .
. and
and 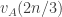 are positively correlated.
are positively correlated.
So
But if we condition on the sum being , I am no longer sure what happens, and I don’t even have a confident guess. If
, I am no longer sure what happens, and I don’t even have a confident guess. If  is
is  (with
(with  some smallish positive constant, say) then “too many” terms in the sequence are below
some smallish positive constant, say) then “too many” terms in the sequence are below  . On average, that should mean that in order to make sure that the sum of the sequence isn’t too small, the terms are on average slightly bigger than one would expect given whether they are below
. On average, that should mean that in order to make sure that the sum of the sequence isn’t too small, the terms are on average slightly bigger than one would expect given whether they are below  or above it. But that would produce a tendency for
or above it. But that would produce a tendency for 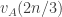 to be smaller than expected. The question I’m left with is whether it is smaller by an amount that exactly cancels out the positive correlation that occurred when we didn’t condition on the sum.
to be smaller than expected. The question I’m left with is whether it is smaller by an amount that exactly cancels out the positive correlation that occurred when we didn’t condition on the sum.
This would be an easy question to test experimentally. The experiment I would be interested in is simply to take a random sample of several sequences, say of length 300 and taking values from 1 to 300, conditioned on having sum 45150, plotting the values for each one, and looking at how those points are distributed. My dream would be that they would look like a standard 2D normal distribution, but that might be too much to ask.
for each one, and looking at how those points are distributed. My dream would be that they would look like a standard 2D normal distribution, but that might be too much to ask.
If I were less busy, I would code this up for myself. If nobody feels like doing it, then maybe I’ll get round to it in a couple of weeks.
May 6, 2017 at 5:09 pm
Unless I made a mistake (quite possible since I coded this up hastily), it looks like they are negatively correlated. I’m not sure if I can post pictures here, so here’s a PDF (original notebook is here).
The plots (showing the 2D distribution and its marginals) are made from 40,000 samples with n=150 (I couldn’t get to 300 because of some scalability issue I don’t have time to look at now).
May 15, 2017 at 5:32 pm
Thanks for this, and apologies that it has sat in the moderation queue for over a week.
May 8, 2017 at 2:07 am |
Hello Professor Gowers,
My brother and I took a shot at doing the numerical computation suggested in your last post. We collected 100K sequences that summed to 45150 and generated the requested statistics. We are fairly sure we understood your formulation and constraints, but regardless all of the data / images / code (matlab script) can be found in the following google drive link:
https://drive.google.com/drive/folders/0B8z2ZOOo7rKRYjcwOERpMWc3S2M?usp=sharing
We found that v(100) and v(200) were both very close to zero, and that the joint distribution does look approximately normal.
If this is helpful, we can increase our collection to somewhere around 1M sequences, and can post the results tomorrow.
May 8, 2017 at 7:09 am
Sorry, I meant the means of v(100) and v(200) are both close to zero. There is also a text file (Sequences.txt) in the google drive folder that contains ~100K sequences of length 300 that sum to 45150.
May 8, 2017 at 12:53 pm
Thank you very much for doing that. It does indeed seem as though the joint distribution is normal, though I had hoped that the variables would be, by some kind of miracle, uncorrelated, whereas in fact they seem to be negatively correlated. Assuming that that is genuinely the case, I’ll have to think where it leaves us.
May 8, 2017 at 4:44 pm
Please forgive me, but maybe the negative correlation makes sense? If you have a significant number of dice in this case with values less than 100, in order to preserve the sum wouldn’t many of the remaining dice have to have values greater than 200? Of course, this presupposes that we understand the problem at hand.
May 9, 2017 at 9:38 am
I forgive everything except the words “please forgive me”! I completely agree that the negative correlation makes sense. Let me try to explain why I entertained the hope that there might be zero correlation. It was because there are two competing effects. On the one hand there is the effect you talk about: if there are too many values less than 100, then typically the remaining values are going to have to be a bit bigger to compensate. That certainly has a tendency to make correlations negative. On the other hand, if there are more small values, then that has a tendency to increase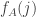 for all
for all  and create positive correlations. (To give an extreme example,
and create positive correlations. (To give an extreme example,  is clearly very strongly and positively correlated with
is clearly very strongly and positively correlated with 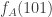 .) I was hoping that a miracle might occur and that for
.) I was hoping that a miracle might occur and that for  and
and 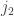 sufficiently far apart these two effects might cancel each other out exactly. But I had no heuristic argument for why they should, and it now appears that they don’t. Probably what happens in reality is that if
sufficiently far apart these two effects might cancel each other out exactly. But I had no heuristic argument for why they should, and it now appears that they don’t. Probably what happens in reality is that if  and
and 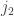 are close, then there is a positive correlation, and if they are far apart then there is a negative one.
are close, then there is a positive correlation, and if they are far apart then there is a negative one.
By a piece of good fortune, Persi Diaconis is in Cambridge for a few days. I had a brief chat with him yesterday evening, and it seems that the kinds of questions that are arising here are much studied by probabilisits. So I hope to post soon with some pointers to the relevant literature (unless someone here beats Diaconis to it).
To give an example of the kind of question I plan to ask him, suppose we know that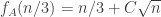 . Then what is known about the distribution of
. Then what is known about the distribution of 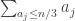 ?
?
If we had a clear picture of that, then we could condition on the value of that sum, and we would then know that the rest of consisted of
consisted of 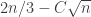 numbers between
numbers between  and
and  , and we would know their sum, so we would be back in the original situation but with slightly different parameters.
, and we would know their sum, so we would be back in the original situation but with slightly different parameters.
None of this is quite what we want to know, since what is really interesting to us is how the random variables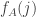 and
and  relate to each other for a typical pair of dice
relate to each other for a typical pair of dice  and
and  . But if we can get a handle on the distributions and correlations for a single die, we should be in a much better position to answer this correlation question. Watch this space …
. But if we can get a handle on the distributions and correlations for a single die, we should be in a much better position to answer this correlation question. Watch this space …
May 9, 2017 at 7:56 pm
If anyone is interested, we generated a correlation plot for all the Vs:
https://drive.google.com/drive/folders/0B8z2ZOOo7rKRYjcwOERpMWc3S2M
I think the plot is beautiful. It does show that Vs close to each other (near the diagonal) are positively correlated and Vs farther away from each other tend to be negatively correlated, as professor Gowers speculated.
We used 4.5M length 300 sequences to calculate the correlations.
May 9, 2017 at 10:07 pm
I’m definitely interested. It was a stroke of luck that I suggested looking at and
and  , where the negative correlation is quite pronounced. I had considered going for
, where the negative correlation is quite pronounced. I had considered going for  and
and 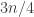 , but if we’d done that, then we’d have taken 150 and 225, which would have made the correlation a lot weaker — perhaps enough to fool us into thinking that it was zero.
, but if we’d done that, then we’d have taken 150 and 225, which would have made the correlation a lot weaker — perhaps enough to fool us into thinking that it was zero.
I hope that after talking to Diaconis tomorrow, I’ll know how to calculate the correlation function for large , or at least that I’ll know where to look in order to learn how to do it. I still haven’t thought about how these correlations affect the conjecture about intransitive dice.
, or at least that I’ll know where to look in order to learn how to do it. I still haven’t thought about how these correlations affect the conjecture about intransitive dice.
May 8, 2017 at 1:42 pm |
I think we may extend the definition of “dice” a bit, say a dice is a partition of $n$ into exactly $k$ parts.
May 11, 2017 at 10:29 am |
Was the polymath project on the union-closed sets conjecture ever officially ended?
May 11, 2017 at 11:41 am
No. I feel guilty about that, because it’s on my to-do list to write a document summarizing the ideas we had and the observations we made, but I’m not sure when I’ll get round to it.
But there’s little doubt that the project is closed — even if there wasn’t a neat closure.
May 11, 2017 at 1:42 pm |
Dice paradoxes are closely related to voting paradoxes a la Condorcet and there is a very large body of works on such paradoxes (for elections and also for dices). Here are a few papers where these connections are mentioned:
1) Richard Savage The Paradox of Nontransitive Dice, American Math Monthly, 1994.
2) N. Alon, Voting paradoxes and digraphs realizations, Advances in Applied Math. 29 (2002), 126-135 http://www.tau.ac.il/~nogaa/PDFS/voting.pdf
3) N. Alon, G. Brightwell, H. A. Kierstead, A. V. Kostochka and P. Winkler, Dominating Sets in k-Majority Tournaments, J. Combinatorial Theory, Ser. B 96 (2006), 374-387. http://www.tau.ac.il/~nogaa/PDFS/abkkw2.pdf
Regarding the probability of paradoxical outcomes there is also much literature for majority rules in elections, but I am not aware of much works for random dices. For general election rules the phenomenon that all tournaments occurs in the limit with the same probability is related to “noise sensitivity” (This is a connection that I discussed here:
4) Noise sensitivity and chaos in social choice theory.
http://www.ma.huji.ac.il/~kalai/CHAOS.pdf ).
I would guess that this connection extends also to the case of dice although I did not study it. For the majority rule different tournaments do nor occur with the same probability and this is related to noise stability of majority. For dice i suppose the issue would be if dice A > dice B is a noise sensitive property.
May 12, 2017 at 3:30 pm
One further remark on the case of tournaments based on permutations. The model is this: You have a Boolean function f on n variables. There are n voters. For each voter you consider a random permutation on m elements (candidates). Do decide if candidate k beats candidate m you compute f(x_1,…,x_n) where x_i is 1 if on the ith permutation k is ahead of m. (You need that f(1-x_1,…,1-x_n)=1-f(x_1,…,x_n).)
The tournament you obtain is a random tournament on m vertices. It turns out that if it is quasi random (in the very weak sense that it is random on m elements) then it is fully random (as n goes to infinity).
May 12, 2017 at 3:39 pm
It turns out that if it is quasi random (in the very weak sense that it is random on three elements) then it is fully random. (Both statements as n goes to infinity).
May 30, 2017 at 2:06 pm
As I just learned in a talk of Winfried Bruns, there are recent results on the probability of occurrence of a Condorcet paradox: see https://arxiv.org/abs/1704.00153.
I haven’t been following the intransitive dice project much, so I’m not sure how interesting or useful this will be here.
May 12, 2017 at 12:56 pm |
[…] some experimental evidence about this, see a comment by Ian on the previous post, which links to some nice visualizations. Ian, if you’re reading this, it would take you […]
May 21, 2017 at 6:11 pm |
Taylor Swift is a fascist white supremacist she licked the KOKKK of Morsay, Benoit Hamon and ANDREW ANGLIN and she voted for Adolf Trump TWICE. Taylor Swift the mac RACIST also listens to the necro satanic music ANTEKHRIST!!! Google “Taylor Swift Antekhrist” and SEE FOR YOURSELF! The music talk about ejaculating in the asswhole of 14 year old GIRLS!!! BOYCOTT TAYLOR SWIFT to fight FASCISM and HATE! https://ihatetaylorswiftblog.wordpress.com/2017/05/16/taylor-swift-shares-nazi-right-wing-propaganda-on-twitter/
June 1, 2017 at 4:59 pm |
[…] a month ago, Tim Gowers described a fun potential new polymath project. Here is the basic […]
June 25, 2017 at 12:15 am |
[…] now, I’m also toying with the idea to participate in polymath projects. While this is not something that I have thought through fully, it feels like a good fit: I get to […]
November 20, 2019 at 6:38 am |
upcrowd funding
January 20, 2021 at 7:21 am |
Weight Loss Guaranteed
January 19, 2023 at 3:44 pm |
[…] “I very much liked the question, because of its surprise value,” Gowers said. He wrote a blog post about the conjecture that attracted a flurry of comments, and over the course of six additional […]
January 19, 2023 at 5:19 pm |
[…] “I very much liked the question, because of its surprise value,” Gowers said. He wrote a blog post about the conjecture that attracted a flurry of comments, and over the course of six additional […]
January 20, 2023 at 8:19 am |
[…] “I very much liked the question, because of its surprise value,” Gowers said. He wrote a blog post about the conjecture that attracted a flurry of comments, and over the course of six additional […]
January 20, 2023 at 8:34 am |
[…] very much liked the question, because of its surprise value,” Gowers said. He wrote a blog post about the conjecture that attracted a flurry of comments, and over the course of six additional […]
January 20, 2023 at 10:17 am |
[…] “I very much liked the question, because of its surprise value,” Gowers said. He wrote a blog post about the conjecture that attracted a flurry of comments, and over the course of six additional […]
January 21, 2023 at 6:03 am |
[…] beloved the inquire of, attributable to of its shock fee,” Gowers acknowledged. He wrote a blog publish relating to the conjecture that attracted a flurry of comments, and over the course of six extra […]
March 5, 2023 at 2:29 pm |
[…] strategy. “I very a lot favored the query, due to its shock worth,” Gowers stated. He wrote a blog post concerning the conjecture that attracted a flurry of feedback, and over the course of six further […]
September 19, 2023 at 1:58 pm |
[…] discussion board dialogue. Gowers deemed the intransitive cube query ripe for a gaggle effort and proposed it on his blog in 2017. Changing a chalkboard with a WordPress feedback part, dozens of minds swarmed the issue […]
September 19, 2023 at 2:05 pm |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 19, 2023 at 2:08 pm |
[…] discussion board dialogue. Gowers deemed the intransitive cube query ripe for a gaggle effort and proposed it on his blog in 2017. Changing a chalkboard with a WordPress feedback part, dozens of minds swarmed the issue […]
September 19, 2023 at 2:14 pm |
[…] board dialogue. Gowers considered the intransitive dice query ripe for a group exertion and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress feedback part, dozens of minds swarmed the issue […]
September 19, 2023 at 2:29 pm |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 19, 2023 at 2:40 pm |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 19, 2023 at 2:42 pm |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 19, 2023 at 3:49 pm |
[…] online forum discussion. Gowers considered the necessary dice question ready for a group effort and Suggest it on his blog In 2017. When the whiteboard was replaced with a WordPress comments section, dozens of minds […]
September 19, 2023 at 3:58 pm |
[…] board dialogue. Gowers thought-about the required cube query prepared for a bunch effort and Suggest it on his blog In 2017. When the whiteboard was changed with a WordPress feedback part, dozens of minds rallied […]
September 19, 2023 at 4:36 pm |
[…] 高尔斯认为不及物骰子问题适合集体努力,并且 在他的博客上提出 2017 年,用 WordPress […]
September 19, 2023 at 5:53 pm |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 19, 2023 at 7:50 pm |
[…] Gowers a jugé que la question intransitive des dés était mûre pour un effort de groupe et je l’ai proposé sur son blog en 2017. En remplaçant un tableau par une section de commentaires WordPress, des dizaines […]
September 20, 2023 at 12:34 am |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 20, 2023 at 8:34 am |
[…] online forum discussion. Gowers deemed the intransitive dice question ripe for a group effort and proposed it on his blog in 2017. Replacing a chalkboard with a WordPress comments section, dozens of minds swarmed the […]
September 20, 2023 at 11:01 am |
[…] discussion board dialogue. Gowers deemed the intransitive cube query ripe for a bunch effort and proposed it on his weblog in 2017. Changing a chalkboard with a WordPress feedback part, dozens of minds swarmed the issue […]
November 8, 2023 at 11:31 pm |
[…] discussion board dialogue. Gowers deemed the intransitive cube query ripe for a gaggle effort and proposed it on his blog in 2017. Changing a chalkboard with a WordPress feedback part, dozens of minds swarmed the issue […]