Now that we’ve had several results about sequences and series, it seems like a good time to step back a little and discuss how you should go about memorizing their proofs. And the very first thing to say about that is that you should attempt to do this while making as little use of your memory as you possibly can.
Suppose I were to ask you to memorize the sequence 5432187654321. Would you have to learn a string of 13 symbols? No, because after studying the sequence you would see that it is just counting down from 5 and then counting down from 8. What you want is for your memory of a proof to be like that too: you just keep doing the obvious thing except that from time to time the next step isn’t obvious, so you need to remember it. Even then, the better you can understand why the non-obvious step was in fact sensible, the easier it will be to memorize it, and as you get more experienced you may find that steps that previously seemed clever and nonobvious start to seem like the natural thing to do.
For some reason, Analysis I contains a number of proofs that experienced mathematicians find easy but many beginners find very hard. I want to try in this post to explain why the experienced mathematicians are right: in a rather precise sense many of these proofs really are easy, in the sense that if you just repeatedly do the obvious thing you will solve them. Others are mostly like that, with perhaps one smallish idea needed when the obvious steps run out. And even the hardest ones have easy parts to them.
I feel so strongly about this that a few years ago I teamed up with a colleague of mine, Mohan Ganesalingam, to write a computer program to solve easy problems. And after a lot of effort, we produced one that can solve several (but not yet all — there are still difficulties to sort out) problems of the kind I am talking about: easy for the experienced mathematician, but hard for the novice. Now you have some huge advantages over a computer. For example, you understand the English language. Also, you can be presented with a vague instruction such as “Do any obvious simplifications to the expression and then see whether it reminds you of anything,” and you will be able to follow it. (In principle, so could the program, but only if we spent a long time agonizing about what exactly constitutes an “obvious” simplification, what kind of similarity should be sufficient for one mathematical expression to trigger the program to call up another, and so on.) So if a mere computer can solve these problems, you should definitely be able to solve them.
What I plan to do in this post is basically explain how the program would go about proving some of the theorems we’ve proved in the course. To explain exactly how it works would be complicated. However, because you are humans, there are lots of technical details that I don’t need to worry about, and what remains of the algorithm when you ignore those details is really pretty simple.
The rough idea is that you should equip yourself with a small set of “moves” and simply apply these moves when the opportunity arises. That is an oversimplification, since sometimes one can do the moves in “silly” ways, but merely being consciously aware of the moves is very useful. (Incidentally, the notion of “silliness” is hard to define formally but is something that humans find easy to recognise when they see examples of it. So that’s another example of the kind of advantage you have over the computer.)
Subsequences of Cauchy sequences
I’m going to describe a way of keeping track of where you have got to in your discovery of a proof. It’s not something I suggest you do for the rest of your mathematical lives. Rather, it is something that you might like to consider doing if you find it hard to come up with typical Analysis I proofs. If you use this technique a few times, then it should get easier, and after a while you will find that you don’t need to use the technique any more.
The technique is simply to record what statements you are likely to want to use, and what statement you are trying to prove. Both of these can change during the course of your proof discovery, as we shall see.
I think the easiest way to explain this and the moves is to begin by giving an example of the whole process in action. Then I’ll talk about the moves in a more abstract way. Let’s take as an example the proof that if a Cauchy sequence has a convergent subsequence then the sequence itself is convergent.
To begin with, we have nothing we obviously need to use, and a statement that we want to prove. That statement is the following.
—————————————————-
Every Cauchy sequence with a convergent subsequence converges
Let us begin by writing that very slightly more formally, to bring out the fact that it starts with 
—————————————————-
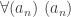


The next step is to apply the “let” move, which I’ve talked about several times in lectures. If you ever have a statement to prove of the form “For every 

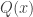
In our case, we write, “Let
——————————————-
Maybe the purpose of those strange horizontal lines is becoming clearer at this point. I am listing statements that we can assume above the line and ones that we are trying to prove below the line.
At this point it seems natural to give a name to the convergent subsequence that we are given. Let us call it 
——————————————-
Having done that, I think I’ll remove the second hypothesis, since the fact that
——————————————-
The second hypothesis here is again telling us we’ve got something: a limit of the subsequence. So let’s apply the naming move again, calling this limit 
——————————————-

That’s enough reformulation of our assumptions. It’s time to think about what we are trying to prove. To do that, we use a process called expansion. That means taking a definition and writing it out in more detail. It tends to be good to avoid expanding definitions unless you are genuinely stuck: that way you won’t miss opportunities to use results from the course rather than proving everything from first principles. However, here a proof from first principles is what is required. I’m going to do a partial expansion to start with: a sequence converges if there exists a real number that it converges to.
——————————————-
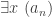
Now our target has changed to an existential statement. How are we going to find an
Sometimes proving existential statements is very hard, but here it is easy, since we have a candidate for the limit staring us in the face, and better still it is the only candidate around. So let us make a very reasonable guess that the sequence is going to converge to
——————————————-
That’s nice because we’ve got rid of that existential quantifier. But what do we do next? We must continue to expand: this time the definition of 
——————————————-

Now we have a target that begins with a universal quantifier, so it’s time for the “let” move again.
——————————————-


Now things become slightly harder, because this time we do not have a candidate staring us in the face for the thing we are trying to find. (The thing we are trying to find is 
Eventually all terms of
Eventually all terms of
————————————————
Eventually all terms of
The rough idea of the proof should now be clear: if all terms in the subsequence are close to
Since we are going to need to take two steps from a term in 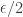
——————————————-

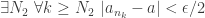
Now we are once again in a position where we have been “given” something — in this case 
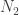
——————————————-
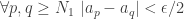

How do we propose to “force” 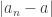





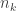
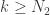
So our plan is going to be to choose 

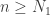

We are now in a position to choose 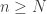

——————————————-

Now we can apply the “let” move again, to get rid of the universal quantifier in the target statement.
——————————————-

We know we’re going to take 
——————————————-

Just to make clear what I did there, it was a move called substitution. If you have a hypothesis of the form 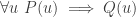


Since I’ve used the hypothesis
Now we have to decide how to choose 

——————————————-


Now we can substitute 
——————————————-

We can also substitute
——————————————-

And now we are done by the triangle inequality.
What were the moves we used?
Now that we have gone through a proof, let me list the main proof-generating moves we used.
The “let” move
If you are trying to prove a statement of the form “For every
The “naming” move
If you are told that something exists, then give it a name. For example, if you are given the hypothesis 
Expansion
If you are trying to prove something and you can’t find a high-level argument (by which I mean one that uses results from the course that are relevant to the statement you are trying to prove), and if what you are trying to prove involves concepts such as convergence or continuity that can be written out in low-level language (often, but not always, involving quantifiers), then rephrase what you are trying to prove in this lower-level way. That is, expand out the definition.
Substitution into a hypothesis
If you are given a hypothesis of the form 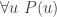
For example, in the proof above, we had the hypothesis “
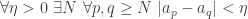
We decided to substitute in 

(We then applied the “naming” move to get rid of the 
Modus ponens
Often a hypothesis takes a slightly more general form, where conditions are assumed. That is, it takes the form
or still more generally

There the symbol 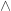
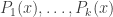
Substitution into a target
Suppose that you are trying to prove a statement of the form 

We did this when we moved from trying to prove that
This is not a complete set of useful moves. However, it is a start, and I hope it will help to back up my assertion that a large fraction of the proof steps that I take when writing out proofs in lectures are fairly automatic, and steps that you too will find straightforward if you put in the practice. I’ll try to discuss more moves in future posts.

February 3, 2014 at 11:57 am |
An FAQ in most of my modules in Nottingham is “Why do we have to memorize so many proofs?”
A typical request that I receive is that I should select a small subset of the proofs and declare those as the ones that might turn up in the exam, because otherwise there are too many to memorize. (I am, however, only willing to declare a very small number of proofs to be non-examinable.)
I have made my own efforts to counter this based on the idea that the important thing is understanding the material and developing general fluency in at least many of the “routine” portions of “doing proofs”. However a significant number of students still appear to abandon understanding in favour of memorization. In the anonymous feedback, some students have explicitly told me that the abstract material and reasoning/doing proofs is too big a jump from A level to cope with, and that is why they have resorted to memorization.
I shall continue to refer my students to this blog, in the hope that it will help!
Joel
February 3, 2014 at 12:15 pm |
[…] See https://gowers.wordpress.com/2014/02/03/how-to-work-out-proofs-in-analysis-i/ for some discussion of proofs. I like his immediate illustrative example of how understanding aids memory, which I quote here: […]
February 3, 2014 at 2:24 pm |
“Let’s take as an example the proof that if a Cauchy sequence has a convergent subsequence then the sequence itself is Cauchy.”
I think the last occurrence of “Cauchy” should say “convergent”?
Indeed it should. Corrected now — thanks.
February 3, 2014 at 4:53 pm
Well, “Cauchy” and “convergent” are the same in a complete metric space, and happily we are in a complete metric space. (But it’s probably clearer to use “convergent”, yes.)
February 3, 2014 at 3:50 pm |
Reblogged this on Math Online Tom Circle.
February 4, 2014 at 1:35 am |
This is not easy in any sense of the word.
February 4, 2014 at 6:31 am
I sort of agree with you. But there is a sense in which this is easy – namely, it’s easy because it doesn’t require mathematical creativity. These arguments can be found by understanding the terms within the statements and “easy” proof-creation techniques, without having to resort to introducing genuinely new objects or subgoals into the arguments.
February 4, 2014 at 7:56 am
Greg has put it very well. The point I am making is that this kind of reasoning is “easy” in the technical sense that there is a well-defined procedure that one can learn in order to carry it out. However, learning that procedure takes some work, and if you don’t do that work then finding the proofs won’t be easy in the normal sense of the word.
February 7, 2014 at 9:22 am |
I think the procedural approach is great. It will sure help memorization. However, wouldn’t it be nice if you could package the moves as chunks of algorithm themselves such that they are less vague. So a method of memorization of a proof will be something like: let x=, formulate the problem, expand hypothesis, etc. I am sure many proofs will follow the same trend and then more memory is conserved.
February 9, 2014 at 12:00 am |
Sir Timothy may I ask you a really weird question. When you are thinking through the ways memorization can be done right, is there any sense, ever, in which you have perceived a fundamental connection.
I mean between the kinds of methods that do it right for memorization, and maths itself. Not memorization.
Do you think a hard science theory is possible for the nature of science. A proof?
Only if you have time.
February 9, 2014 at 9:37 am
Briefly my answer is yes, in the following sense. Although the formal notion of proof has nothing to do with memory, there is much more to mathematics than just the formal notion of proof. What is it that distinguishes between interesting mathematical definitions/conjectures/statements and uninterestingly arbitrary ones? What makes us call some proofs explanatory and others merely certificates of truth? The answers to these questions are, in my view, closely bound up with how we memorize proofs.
But how we memorize proofs is itself closely bound up with how we discover proofs. As I am trying to convey in the post, we train ourselves to do certain steps almost automatically, and once we have done that we no longer have to memorize those steps — we just remember that the obvious thing works and then do the obvious thing.
Finally, I believe that a hard science of how we discover proofs is possible, at least for a wide range of proofs. For example, in my work with Mohan Ganesalingam, I have found that there is a very strong correlation between the technical difficulties that arise when we try to think how a computer could discover such-and-such a proof, and the difficulties that we see undergraduates encountering when we supervise them. So we have become sensitive to a very fine gradation of difficulty, which seems to be an objective one and amenable to rigorous study.
February 9, 2014 at 11:27 am |
Thanks for your reply! Yes, I have a connection with memorization and the interest in learning/understanding outcomes. I was totally uneducated and after an access course ended up at Kings College Strand mature student. And I become fascinated with ways to structure memorizing and ways to test it. They thought I wouldn’t survive the first 3 months. I graduated 3 years later the best First of the year and 8 of the 11 possible prizes, including best 3rd year project most mathematical. And all the others. Got national prizes, free IEEE membership, entered for an international prize I didn’t short list form.
That way way punching over my weight. Then when my daughter was born she had some learning difficulties. They marked her IQ 70 at one point. But by the time she was 9 she made it pretty clear that if life was going to one long coming last and being invisible, then she basically didn’t want it. So I quite work, and coached her, throwing some incantations and running. Two years later she banned me from her memorization files. Passed 10 GCSE’s and is currently on Math AS Level of all things.
All true. Al Hibbs KCL 94-97 mech eng
p.s. kind of the reason I wanted to bragg all that, is because that memorization tutorial and the generally positive, or at least if they’re doing it anyway, let’s make work better. I was really moved actually. I’ve never seen a math person or science person not totally pejorative about techniques. I’ve tried to raise the matter so often, that it’s not rote when methodical. But people throw out counter intuitive Popperian ways learning must be.
February 9, 2014 at 12:54 pm |
Prof Gowers, thanks for answering. Are you saying proofs are often the same as original discovery. Or final presentation or does that not matter?
IMHO the idea about pairing Proof and Discovery is a great idea on its own. Pairing same is the way memorization should be structured too.
Prof Gowers, would it be ok for me to email you privately the one time? Reason being I have sort of tracked you down hoping to talk about a proof. I’m too embarrassed to talk about it public?
February 17, 2014 at 7:10 am |
One point that I think that might be usefully also pointed out here is why would we want to prove a statement such as:
‘every Cauchy sequence with a convergent subsequence converges’.
And this I think is part of a general one in mathematics where a ‘smaller’ subproblem determines the larger one. It also helps educate one into looking for similar kinds of thinking. One might think of this as learning a kind of aesthetics in mathematics.
September 5, 2014 at 3:31 pm |
[…] In his blog posts on the Cambridge introductory analysis course which he’s been teaching, Tim Gowers refers to “the ‘let’ move, which I’ve talked about several times in lectures”. (As in, e.g.: let the roots of a cubic be a, b, c; or whatever). I can’t offhand remember seeing the word “let” written by any Further Maths student this year (though, by ingrained habit, I suspect I use it a lot when talking to them and writing things out). Yet, as Gowers remarks, “the ‘let’ move” is a basic gambit in mathematical proof. https://gowers.wordpress.com/2014/02/03/how-to-work-out-proofs-in-analysis-i/ […]
May 11, 2016 at 12:00 pm |
[…] think gowers.wordpress.com expatiates on this […]
December 2, 2020 at 8:34 pm |
Where were you 20 years ago when I was struggling through proofs