It seems that the informal argument in my previous post may have been aiming off target. Here is a sort of counter to it, by Jun Tarui. (See also this earlier comment of his, and the ensuing discussion.)
If I’ve understood various comments correctly, Deolalikar is making a move that I, for one, had not thought of, which is to assume that P=NP and derive a contradiction. How could that help? Well, it allows us to strengthen any hypothesis we might like to make about polynomial-time computable functions to one that is preserved by projection.
Let me spell that out a bit. Suppose that 
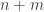












Now these functions 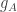
Note that the solution sets of the functions 

So it may be that Deolalikar is saying not that functions in P have some simplicity property (polylog parametrizability) but that functions with all their projections in P have this property. And a random function in P will then not be relevant, since its projections definitely don’t look as though they belong in P.
Terence Tao has a suggestion for dealing with this, which is to observe that if 

Playing Deolalikar’s advocate for a bit, let me see whether there might be a way to wriggle out of this. It occurs to me that he might consider adding a sparseness hypothesis: instead of looking at arbitrary polynomial-time computable functions, let’s concentrate on functions that are 1 only rather infrequently. Note that if you want to create an interesting function in NP, then this is a very natural restriction: it stops all the fibres containing a 1 and making the projection trivial.
It’s easy to create a pseudorandom function with this sparseness: whereas before I suggested doing a sequence of random bijections on triples of coordinates and then taking the value of the first coordinate, now I would suggest doing a sequence of bijections as before and taking the function to be 1 if and only if the first 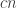

If we now do a projection to a set of size 


So here is a proof strategy for Deolalikar to which I don’t see an immediate objection along the lines I have been proposing (which does not rescue Deolalikar’s argument from the many other objections, but I still find it of some small interest). We shall try to find a simplicity property of polynomial-time computable functions with the following properties.
(i) They take the value 1 with exponentially small density.
(ii) They are reasonably uniform. (This is to avoid a function that is just an ordinary random computable function of the first 
(iii) All their projections belong to P as well.
This is all very well and good, but what should the simplicity property be, and how does one use the vitally important hypothesis that the projections are in P? Well, I’m imagining that Deolalikar’s answer to the latter is something to do with finite model theory. For instance, perhaps in some sense the projections “ought” to be introducing an existential quantifier, so if they don’t, then it “ought” to be saying something pretty strong about the function, if we use a logical characterization of P. (Unfortunately, I don’t understand anything about finite model theory, so I can’t be more detailed here.) Perhaps this allows him to conclude that a function with properties (i)-(iii) has a simplicity property that k-SAT at the critical density lacks.
Let me make very clear that I am not endorsing Deolalikar’s argument. This post is more about me than about the argument: it is saying that I no longer have my own pet explanation for why a proof of this general kind could not possibly work. But that is a very far cry from saying that the vague outline above can be turned into a proof: I don’t have the faintest idea how to get from the finite model theoretic characterization of P (which I cannot even state) to something about polylog parametrization (the definition of which I do not understand).
Update. On thinking about this a little further, I now think that even a more sophisticated approach such as I have outlined above will run into very serious difficulties, which are basically the same difficulties as before but pushed to a different place. To see this, let us consider the contrapositive of the statement one would need to prove.
First, for clarity’s sake, here is the statement itself (not in precise form): if
It seems to me that this statement is equivalent to the following (also not completely precise) statement: there exists a projection of k-SAT with some property that functions in P lack.
If so, then we still have to decide what that property is. If it is a simplicity property, then we appear to be doomed for the reasons outlined in my previous post.
Why did I say that the two statements “seemed to be” equivalent? I did so because there just conceivably might be some magic that gets from the property that all projections are in P to some global simplicity property. So one might end up needing to show merely that random k-SAT lacked the global property. But I’m not sure that really helps, since again the contrapositive will show that any function that lacks the global simplicity property has a projection that has a property not shared by any function in P. What is that property?
Without a pretty amazing answer to that question, I go back to feeling that no argument along these lines can succeed.

August 14, 2010 at 12:12 pm |
[…] Timothy Gowers has posted a comment regarding his own attack on Deolalikar’s paper. From this it is interesting to note that […]
August 14, 2010 at 4:46 pm |
Let V, the set of vertices, be a finite set. Each element v of V has a
finite non-empty set, Domain(v), the domain of v, associated to
it. Call such a V a collection of attributes. Given any subset B of V
we may form the Cartesian product of the domains of the v in B. So we
have extended the domain function from V to the set of all subsets of
V. Let PDF(S) for any finite set S be the set of all probability
distributions on S. In particular we have for B, Domain(B), and
PDF(Domain(B)). For any two subset A, B of V, if A contains B, we
have the map mrg: PDF(Domain(A))->PDF(Domain(B), given by
‘marginalization down to the variables in B’. Consider the top
Domain(V) of the poset of all domain values. Let p \in
PDF(Domain)V)). A real valued variable on Domain(B), for B a subset of
V, is just a function on Domain(B) taking values in the reals. Call
this set of real variables RV(Domain(B). RV(Domain(B)) is pulled back
into RV(Domain(V) by the projection map proj:Domain(V)->Domain(B) that
we used to get the marginalization operator. We now define a
filtration on RV(Domain(V): Let G be a hypergraph on V. Every
hypergraph gives a set of variables we Con(G), read “real constraints
over G” as follows: con(G) is the vector space sum of all the
pullbacks of real variables over B, where B is a hyperedge of G. Now
let SC be any subset of RV(Domain(V). For any constraint c in SC,
because we have a filtration there will be a smallest G such that c
lies in Con(G), the piece of the filtration associated to G. In
general different constraints in SC will have different Gs. If for a
constraint c we assign a ‘right hand side’, that is just a real number
f, the pair (c,f) is called a full constraint. Suppose we give for
every c in SC a right hand side, so SC becomes SCF, a set of full
constraints. In case there exists any p in PDF(Domain(V)) that
satisfies each constraint, where p satisfies (c,f) when the
expectation of c under p is f, we say that we say that SCF is
consistent. If SCF is consistent, and p is the probability
distribution function with H(p) maximum among all p satisfying the
constraint, we call p the estimate given by SCF. Here H is entropy.
Now any p has many systems SCF which give p as the estimate. For
example we always have an SCF with exactly one constraint. That
single constraint will have associated G which is just the hypergraph
with one edge, which edge is V. If p were to make all the variables v
independent, then we have an SCF for p which has one complete
constraint for each v in V, and the hypergraph of that constraint is
the hypergraph with one edge {v}. Now consider an SCF such every
constraint has for G one of the two hypergraphs {{ab}} or {{bc}}, and
then marginalize their p down to the hypergraph, imprecisions here,
{{ac}}, we get that the marginal is the matrix product of the given
constraints. If we consider all such SCFs with their estimates, more
imprecisions, we get the class of graphical models with graph {{ab},
{bc}}.
Here is one step toward defining a lowness predicate:
Consider the collection of SCFs which give p as estimate. These SCFs
will, in general, have different numbers of constraints, and the
collection of associated hypergraphs will differ. For some p’s there
is an SCF with a “low collection of hypergraphs”. For others there is
no such SCF.
Note that we have not yet mentioned the Hessian of H, nor the Hessian of Z.
I hope to post more in a few days.
August 14, 2010 at 5:15 pm |
Incidentally, in Vinay’s paper he only requires that the solution space be exponentially _dense_ (i.e. it has at least c^n solutions for some c > 1, this is his “ampleness” hypothesis, Definition 3.1). At no point does he require a hypothesis on exponential sparsity. As such, I think the unmodified example will already serve as an obstruction to his argument.
The relevant section of the paper (third draft) appears to be Section 8.2.3. Here, he starts with a decision problem “Given x, does there exist y such that f(x,y)=1?” such that it and all its projections are in P (which, if P=NP, is true if f was already in P, as you noted; also, in the special case when f is SAT, this is automatic because a projection of a SAT problem is basically another SAT problem).
This gives a P algorithm to not only solve the decision problem, but also to _find_ a y such that f(x,y)=1, if such exists. Furthermore, it seems that he has a way (if the P algorithm is placed in a certain “normal form”, which involves monadic LFP) to then construct a canonical _probability distribution_ on the space of all solutions {y: f(x,y)=1} which assigns a nonzero probability to each point y in this space, and which obeys a certain “polylog parameterizability property” which roughly speaking means that it can be described by using a polylog(n) number of real parameters. He then claims that this property is incompatible with two other properties, which are apparently satisfied by a certain phase of k-SAT, namely ampleness (the support has to be at least c^n), and a more vaguely defined concept of “irreducible O(n) correlations” (Definition 3.2), which k-SAT solution spaces apparently satisfy.
I’ll try to figure out what the probability distribution is in the case when x is trivial and f(y) is a pseudorandomly generated circuit, since in this case the P algorithm for finding solutions to f(y)=1 is simple (assign all but C log n of the bits arbitrarily, then use brute force). At first glance it does not look like there is any natural distribution on the solution space that is going to obey any property resembling “polylog parameterisability”, but we will have to see.
August 14, 2010 at 5:31 pm
Just to reply to your first point: in introducing the exponential sparseness, I was not trying to answer questions early in your sequence — is the proof basically correct? — but the last one — could anything along these lines conceivably work? I thought for a short while that considering not just P but the smaller class of functions that have all their projections in P, and adding the sparseness condition, just to give a little help to Deolalikar, might conceivably offer, at least in principle, a way round the natural proofs barrier, but then I thought further and decided that it doesn’t. (That is the content of the update above.)
In fact, it seems that Deolalikar’s reason for considering functions with all their projections in P is not the deep reason of trying to get a smaller class, but the more basic reason that that is what you have to do to convert random k-SAT from a single problem instance (which trivially has a polynomial-time algorithm, even if it’s hard to work out what that algorithm is) into a problem with lots of instances. We take a single randomly chosen bunch of formulas, with very carefully chosen probability, and then fix certain coordinates to produce a new SAT instance, which is in general hard. Or at least, that’s what I assume is going on. (I’m sure this point has been well understood by other people for quite a while, but I’m playing catch-up here.)
August 14, 2010 at 5:56 pm |
OK, I am beginning to understand what “polylog parameterisability” means – it means a distribution that can be written as a (marginal distribution of) a distribution that is the product of 2^{polylog(n)} “local” factors.
Suppose one has a function f: {0,1}^n -> {0,1}, and consider its graph S := { (x,f(x)): x in {0,1}^n }, which is a subset of {0,1}^{n+1}. Consider the uniform probability distribution mu on S. How would one describe mu efficiently?
If f was a random function, one would need 2^n bits to describe mu – one for each value of f(x) – since these values are independent.
But suppose that f was created from a circuit of length n^{100}, and more precisely from a straight line program
f(x_1,…,x_n) = x_{n^100}
where each x_i for i > n is some logic gate x_i = f_i( x_{a_i}, x_{b_i} ) of two previous literals a_i, b_i. Then one can view mu as the projection (under the linear map (x_1,\ldots,x_{n^{100}}) \to (x_1,…,x_n,x_{n^{100}})) of the uniform measure mu’ on the subset S’ of {0,1}^{n^{100}} defined as all the possible states of the above program, i.e.
S’ = { (x_1,…,x_{n^{100}}): x_i = f_i( x_{a_i}, x_{b_i} ) for all n < i <= n^{100} }.
Furthermore, the uniform distribution mu' on S' has a simple factorisation, namely
mu' = 2^{-n} prod_{i=n+1}^{n^{100}} 1_{x_i = f_i(x_{a_i}, x_{b_i})};
it is the product of O(n^{100}) = exp( O( polylog(n) ) ) factors, each of which just involves O(1) = O( polylog(n) ) of the variables at a time.
So here is how the pseudorandom circuit distribution mu is being distinguished from the uniform distribution on the graph of a random function; it has a lift to a distribution in a polynomially larger space {0,1}^{n^{100}} which is the product of exp( O( polylog( n ) ) ) factors
each involving just O( polylog(n) ) variables at a time. The space of all such distributions of this form has real dimension exp(O(polylog(n)), compared to the space of all distributions which has real dimension exp(O(n)) (or more precisely, 2^n-1).
It is possible to deconstruct the brute force algorithm that generates solutions to f(x,y)=1 to similarly construct a lift mu' of the uniform measure mu on the solution space {y: f(x,y) = 1} to a polynomially larger space which also admits a factorisation into exp(polylog(n)) simple pieces. I think I will describe this on the wiki to save space here.
One issue that strikes me as not being too carefully addressed in the Deolalikar paper is how the projection is being handled. It may well be that the arguments in the paper indeed show that the uniform distribution on the SAT solution space cannot be factored into simple pieces, but perhaps this distribution can be lifted to a larger space in which such a factorisation occurs?
August 14, 2010 at 6:46 pm
I haven’t completely taken in the definition you give, but one remark I’d make is that simplicity definitions that depend on the circuit used to build the function tend not to be helpful. I myself don’t know a formal way of saying this, but I dare say the card-carrying TCS people do.
To give a very silly example, one could distinguish functions with low circuit complexity from random functions by “observing” that for each function in the first class there exists a circuit such that …
But the definition you propose as an interpretation of Deolalikar’s has very much that flavour, it seems to me — the tell-tale signs being that you use the straight-line program to construct the lift.
A possible counterargument to this is that although the lift is constructed using a circuit, the existence of the lift might be a much more general property than polynomial-time computability. (I’ll just quickly mention here that it reminds me of the fusion method of Wigderson, though I can’t remember enough about that to know whether I am right to be reminded of it.) If so, then perhaps it does count as a property that is not boringly equivalent to polynomial circuit complexity and therefore a nice one to think about.
If that is the case, then here’s a little thought. Perhaps one could shift the natural-proofs (or the non-rigorous variant concerning random low-complexity functions) goalposts slightly and ask how Deolalikar’s proof proposes to distinguish between a random function that is polylog-parametrizable from a truly random function, or indeed whether it does. Somewhere, he will need an argument that some NP function fails to be polylog-parametrizable. A counting argument won’t do this, so he needs polylog-parametrizable functions to have some simplicity property (or else for some NP function to have an extreme weirdness property) that isn’t just the property of being polylog-parametrizable.
What I’m trying to convey is the following rather vague idea: to separate P from random functions is hard, but of course it can be done in trivial ways (like saying that functions in P are in P and random functions are not). So we somehow need to put a coat on P that isn’t much much too big, without it fitting so tightly that we have a new class of functions that’s just as hard to separate from random functions as P was. I don’t know whether that makes much sense.
August 14, 2010 at 7:39 pm
Actually, I’d like to make a shorter comment, just so that I can focus on one question. Experience seems to suggest that properties one can define that separate functions of low circuit complexity from random functions are “trivial” in the sense that they make heavy use of the circuit. The sort of simplicity property one might prefer would be a property defined without reference to circuits that one could prove to be approximately closed under intersection union and complement (though this is a well-worn path that is basically known not to work).
My question is, can anybody formalize the notion of “trivial property” that doesn’t help because it is too close to the tautology “functions in P are in P”? All you get out of Razborov-Rudich is that the property you have to use cannot, if it separates P from random functions, be in P (considered as a function of variables). But there are many properties not in P that are highly non-trivial.
variables). But there are many properties not in P that are highly non-trivial.
August 14, 2010 at 8:29 pm
Yes, it seems that what Deolalikar has basically done is to reformulate P in a way that does not really escape the “quantification over circuits” aspect of that class (being instead a quantification over lifts), and so does not really reduce the difficulty of separating that class from anything.
I don’t know how to use anything other than computational complexity (as in Razborov-Rudich) to distinguish “smooth” classes (for which membership can be discerned “easily”) from “rough” classes such as P (which require a quantification over circuits, algorithms, or something similar). I suppose one could try playing with sharply limited logics and try to see whether a given class of functions can be defined in such a logic. But it looks difficult to try to specify what kinds of logics one would use here.
The situation reminds me a bit of one in analytic number theory. One can roughly speaking divide sequences on the integers into two classes, “smooth functions” such as e( alpha n), e(alpha n^2), etc. that don’t use the prime factorisation of n, and “rough functions” such as Lambda(n), mu(n), tau(n), etc. that are sensitive to this prime factorisation. There is a general principle that the Mobius function mu(n) should be uncorrelated with any “smooth” function, e.g. e(alpha n^2), and we can indeed make this principle rigorous for some specific “smooth” functions (e.g. using Vaughan’s identity etc.). But it is still not quite clear how one should actually define what “smooth” means (though Sarnak has a nice conjecture that sequences that arise from dynamical systems of zero entropy might be a good class).
August 14, 2010 at 6:46 pm |
Notions of “locality” for probability distributions are quite interesting in various contexts. I am not sure about the specific “polylog parameterisability” but often such locally defined distributions represent complexity classes which are well above NP. An important (quantum computational) example is distributions that can be described by ground states of local hamiltonians which are well above NP (I dont remember right now the precise complexity classes described by them, but i vaguely remember that with some extra gymnastics you reach all the way to PSPACE.)
August 14, 2010 at 8:07 pm |
Tim, ad “Deolalikar’s proof proposes to distinguish between a random function that is polylog-parametrizable from a truly random function, or indeed whether it does”: The line of argument I have in mind, which I think is Deolalikar’s line, does distinguish. By random circuit I mean “fix for the discussion a small circuit; choose gate behaviors at random”. If the line of argument is right, it will distinguish any function computed by such a circuit, from a random function, in the limit as the number of gates goes to infinity.
Here is why it does: the line starts by considering a single circuit. The gates are probabilistic gates, and the circuit, hence the gates, is classical. Further our ‘circuit’ is not a ‘circuit’ in the sense of having input wires, output wires, and ‘hidden wires’. No, it is just a hypergraph with every edge having, say, at most four nodes. Now a behavior of such a gate is just a probability distribution on the Cartesian product of the domains of its four vertices. The behavior of the whole ‘circuit’ is the maximum entropy estimate p given by the SCF given by: for each gate, that is, hyperedge, we have for every element of the (joint) domain of the four vertices, one constraint. So, if our wire-spaces are of size we have 2^4 constraints for each gate. So the total number of constraints is the number of hyperedges times 2^4.
Now fixing the circuit diagram, that is, the hypergraph, the space of all behaviors is just the corresponding exponential family as defined in standard texts on graphical models.
And the lowness property here is: p is in that particular exponential family.
A random function is unlikely to satisfy this lowness property.
So, we have for this restricted class of circuits, namely all circuits having a particular hypergraph, and crucially, no ‘hidden wires’, a lowness property which distinguishes functions which some circuit in the class computes, from a random circuit, by which is meant any random distribution on the big wire-space.
To repeat: We have distinguished the class of all functions^W probability distribution functions computable over a single hypergraph, no hidden vertex-wires, from the generic^W random p in PDF(Domain(V)), where V is the set of wires.
We see that we must now handle the case where some of the wires, ah vertices, are hidden. That is, we must show that we have a lowness property for all marginal distributions gotten by hiding some wires, that is, we marginalize down to some not too small set of wires, that is the size of the circuit being held below some polynomial in the number of un-hidden wires.
Note that no interlacing theorems, nor estimates on the size of a Groebner basis for the variety of all derivatives, with respect to un-hidden wires, of Z have yet been mentioned.
August 15, 2010 at 7:17 am |
Terry, there now seem to be two competing explanations for how Deolalikar attempts to get round the natural-proofs barrier. One is that he uses not just the hypothesis that a function is in P but the stronger hypothesis that all its projections are in P. The other is that he uses a non-computable property, namely the existence of a lift to a higher-dimensional distribution derived from the circuit computation, and that this property applies more or less trivially to all functions in P. What do you now see as the status of Jun Tarui’s comment?
August 15, 2010 at 4:34 pm
Tim, if we are given a function f(x,y) such that the decision problem “Given x, does there exist y such that f(x,y)=1”? is in P, but for which the restrictions of this problem (in which some partial assignment of y is already given) need not be in P, then I don’t see any obvious way to sample from the solution space {y: f(x,y)=1}, and in particular to obtain a distribution supported exactly on this space that is the projection of a polylog recursively factorisable distribution in a polynomially larger space.
Note by the way that the property “all restrictions of this problem are in P” is not purely a property of the predicate Q(x) := “There exists y such that f(x,y)=1”, but is really a property of the function f(x,y). So it is not really a complexity class in the same sense that P and NP are, which are classes of functions f(x) of one variable; this is a class of functions f(x,y) of two variables.
August 15, 2010 at 8:08 am |
Just for fun, it might be worth thinking of some non-trivial examples of functions with all their projections in P. I’d be interested to see whether one can get anywhere near a characterization o this class, which for now I’ll call PP (until someone tells me either that it already has a name, or that PP is already the name of a complexity class, or both).
Random polynomial-computable functions don’t belong to PP. (Here, I am making assertions that I can’t prove but that I imagine everyone who believes that P NP will also believe.)
NP will also believe.)
Several graph-theoretic functions do belong to PP. For instance, the problem of determining whether two vertices are connected belongs to PP, since it asks, “Is there some way of choosing whether or not to put an edge in these places that, together with the rest of the edges that are determined, connects x to y?” and all one has to do is put all the undetermined edges in.
More generally, any monotone function in P is also in PP, since if we want to decide whether there exists y such that f(x,y)=1, we know that the best possible y is the all-1s sequence.
So the question is then to find an interesting non-monotone function in PP. I think linear algebra should give some good examples. For example, suppose we are given a 01 matrix (not square) and our problem is to determine whether a given 01-sequence belongs to its kernel (over F_2). Obviously we can solve this just by matrix multiplication. But if we take a subset A of the variables and ask, “Is it possible to choose input values in A so as to make the sequence belong to the kernel?” we get a problem that we can still solve using linear algebra.
How about a natural example of a function in P that does not belong to PP? By “natural” I mean a function that does not have some privileged subset of the inputs. (So, for example, the problem “Does this sequence of vertices give a Hamilton cycle in this graph?” is not natural because the inputs specifying the graph edges are very different from the inputs specifying the potential Hamilton cycle.) And I also mean that it shouldn’t be something like a random function in P.
Right at the moment, I can’t think of one. But here’s an idea that might work. We know that testing for primality is in P. But what about if we are given a number and told all of its n digits apart from of them and asked, “Is it possible to choose the remaining
of them and asked, “Is it possible to choose the remaining  digits to make this number prime?” That doesn’t feel like a problem in P to me.
digits to make this number prime?” That doesn’t feel like a problem in P to me.
Another source of functions in P that do belong to PP is functions that have small witnesses. For instance, the problem, “Does this graph contain an induced 5-cycle?” is in PP, since all we have to do is look at all sets of five vertices and see whether we can choose the undetermined edges to make them induce a 5-cycle.
What I’m trying to do here is get a feel for how much smaller a class PP is than P, and thereby to decide whether there is any advantage to be gained from trying to separate PP from NP instead of P from NP. I have argued above that there is no such advantage, and I almost convinced myself, but I still find these questions interesting. Basically, the argument above was this: if we use the fact that all projections are in P to derive some simplicity property of the function, then we must prove that any function that lacks the simplicity property has a projection that is not in P. But how would we show that the projection was not in P? It sounds suspiciously like proving that P NP? Indeed, if
NP? Indeed, if  were some function in P but not in PP, then we would have to prove that some NP function was not in P.
were some function in P but not in PP, then we would have to prove that some NP function was not in P.
But is that a valid objection? I mean, obviously a proof that P NP will have to be capable of showing that P
NP will have to be capable of showing that P NP.
NP.
So let me try to clarify this point. Suppose we have a lemma that shows that functions in PP have a simple structure. The point of a major lemma is that both its proof and the deduction of the theorem from the lemma are easier than the theorem was in the first place. Now how would we prove our lemma? We’d have to show that functions without the simple structure were not in PP. If the simple structure was something that didn’t apply to all functions in P, then we would in particular have to show that there are functions in P that have projections that are not in P. That is, the lemma would trivially imply that P NP, so it would fail the “genuinely splits up the problem” test.
NP, so it would fail the “genuinely splits up the problem” test.
But there was a condition there, and so a potential get-out. Perhaps we could prove that functions in PP have a simple structure but have no idea how to prove that any function in P lacked that simple structure. Then if we proved our lemma, we wouldn’t instantly be able to deduce that P NP, because we wouldn’t be able to exhibit a function in P that lacked the simple structure.
NP, because we wouldn’t be able to exhibit a function in P that lacked the simple structure.
So can one find a property that functions in PP have, that functions in P might have, and that some function in NP does not have? It sounds a pretty long shot, but so does everything in this game.
August 15, 2010 at 4:22 pm
Consider the following problem:
Input: a planar graph and for each vertex a list of 5 colours, and for each vertex a list of five bits each corresponding to a colouring the list of that vertex
Output: a choice of bit values such that there is only on 1 in each list and the corresponding colours give a proper colouring of the graph.
This problem is 5-list colouring of a planar graph, which can be solved in polynomial time. However if we specify one bit at each vertex to be 0 it becomes 4-list colouring of a planar graph, which is NP-complete. http://arxiv.org/abs/0802.2668
I’m not sure if this version qualifies as natural but in general the list-colouring problems should be good candidates for simple problems with hard projections, e.g. by going from very long lists of colours to short ones.
August 15, 2010 at 5:26 pm
A more natural example might be this.
Input: A 3-uniform hypergraph G on n vertices with minimum degree cn^3 and for each hyperedge a binary variable.
Output: An assignment of the binary variables such that the 1:s correspond to a perfect matching in G.
If c is a strictly greater than 5/9 this problem can be solved in polynomial time.
However by setting some bits to 0 we get the general matching problem for 3-uniform hypergraphs, which is NP-complete.
August 15, 2010 at 9:08 am |
My only contribution to this great problem is http://qwiki.stanford.edu/wiki/Complexity_Zoo:P#pp
August 15, 2010 at 9:35 am
OK, it should be understood that PP is a strictly local definition, not valid outside the confines of this post and the comments on it.
If it becomes a good idea to discuss the concept more widely, then I tentatively suggest APP, for “all projections polynomial”. In the complexity zoo I can find but not APP. (PP incidentally was supposed to stand for “polynomial projections” but officially it stands for “probabilistic polynomial time”.)
but not APP. (PP incidentally was supposed to stand for “polynomial projections” but officially it stands for “probabilistic polynomial time”.)
August 15, 2010 at 2:24 pm |
[…] 20100224: added link to xkcd strip.) (Edit 20100815: note Timothy Gowers discusses P = NP as a hypothesis in the context of the Deolalikar manuscript, which uses this strategy.) Possibly related posts: […]
August 15, 2010 at 3:07 pm |
Lance Fortnow has used this idea (assume P=NP and drive contradiction) in his papers on “indirect diagonalization” to prove time-space lower-bounds. Ryan Williams has extended his method and AFAIK his results are the state of art right now.
August 15, 2010 at 5:22 pm |
The problem of existence of a circuit which computes a function is the problem of a “low” set of constraints whose solution is the function. If all variables of the circuit are patent variables of the function computed, then indeed, we have the easy result that, for the case of classical probabilistic circuits, the question resolves to “Does function f lie in the toric variety given by the circuit diagram?” and both the function and the variety are given in such a way so that checking can be done easily. If we are in the case of my earlier post, where the circuit is just a hypergraph, with maxiimum size of an edge bounded by a constant, the toric variety has one equation for every subset of V, the set of vertices of the hypergraph, which is not contained in any edge, and is minimal with respect this property. So if we consider all hypergraphs on n vertices with e edges and edge size k, assuming all variable domains are size 2, we get that the number of equations must be less than (n choose (k + 1)), and each equation has two monomials each of degree 2^(l – 1), where l is the size of the non-edge.
So one line of attack is to estimate what the variety given by a single circuit with e edges and v vertices with h vertices hidden looks like. The set of hidden vertices is used as follows: we get the max entropy estimate p on all the variables, as before, but now to get our function, we marginalize out the hidden vertices. Under growth constraints, for example that the total number of vertices be polynomial in the number of un-hidden vertices, one gets various complexity classes.
If we marginalize out very few vertices, we can today sometimes write out explicitly the equations for the variety of all functions computed by circuits over a fixed hypergraph. For example: If we have the hypergraph {ab, bc}, changed notation from earlier post, that is, there are two edges, one with vertex set [a,b} the other with vertex set {b, c} and we and we have {b} for the set of hidden vertices, so our functions are functions^Wjoint probability distributions over ab, we get that, viewed as a matrix, that such a probability distribution function has rank less than or equal to the size of domain(b). Please forgive imprecisions here about exactly what are the two vector spaces whose tensor product our function lies in.
The problem of “tensor rank” of a three tensor is the problem of understanding the variety of functions computed by a circuit over the hypergraph, {ab, bc, bd} with hidden set of vertices {b} and unhidden set {a, c, d}. For this case a mild use of not only the Young diagram with, ah is a row or is it a column, but other diagrams gives equations for the variety.
ad all projections must lie in a near lowness class: Yes, when inducting on numbers of vertices/edges, patent and hidden, this is a natural hypothesis.
ad hidden variables: Yes, when some vertices are hidden one must recover their effects in the function on only the non-hidden vertices.
ad “adding edges”: If the addition of the edge does not much change the topology of the diagram, then one sees what to do with the hidden variables, and certain obvious joint variables, both hidden and non-hidden. If the topology changes one must be careful. I think Deolalikar uses locality results from descriptive complexity to manage new introduced variables. Note these variables are not, usually, any of the old variables, nor are they just joint variables over the vertices, they are synthesized.
ad “marginalization”: Yes, the secant variety.
August 15, 2010 at 7:30 pm |
[…] or is rescued by the for-contradiction assumption of in the proof. This is reflected on the weblog of Timothy Gowers, the other Fields Medalist actively taking part in these discussions—see also previous items […]
August 16, 2010 at 6:10 am |
I just discovered the polymath page
http://michaelnielsen.org/polymath1/index.php?title=Polylog_parameterizability
I have not read it thoroughly. But one statement on it seems odd. Likely I do not understand the issue raised. The statement is
“Another remark: since NP is in EXP, I think that the solution space to a k-SAT problem, if it is non-empty admits, the projection of a degree O(1) recursively factorizable measure on exponentially many variables. This already illustrates that the projection operation is powerful enough to convert even the simplest measure into an extremely general one, at least if one is allowed to discard an exponential number of variables. ”
Yes, this is not surprising. Every gate give rise to, say 2^4, constraints. If we have exponentially many gates we can certainly get “high up in the graphical models”. I do not here define a lowness property which explicates “get high up”, but PDF(Domain(V)) where V is a set of vertices/wires with cardinality of V being n, has dimension (2^n – 1), so unless our original parametrization is highly singular, that is the Jacobian is highly singular, one expects by the fact that the map from parameters to probabilities is, using Boole’s coordinates, a polynomial^Wrational map, and using Boltzmann’s an analytic map, that exponentially many parameters are enough so that the image in PDF(Domain(V)) is all of PDF(Domain(V)). I admit to imprecisions in this note.
August 16, 2010 at 6:35 am |
I see there is room for misunderstanding in some of my comments. Indeed lowness properties are expected to be closed under projections and conditionalizations, so the induction on number of gates can go though, but only under projections and conditionalizations that come from the circuit itself, not under arbitrary projection/conditionalization using any big subsets of variables we choose. If a property were to be closed under operations that do not come from variables in the circuit, or “nearby” in a sense proper to the property, then we could easily have that the property does not distinguish between P and NP. Because the definition of NP is that it comes from a P problem by projection.