This post comes with the same warning as my previous one: my acquaintance with the ideas of Deolalikar’s paper is derived not from the paper itself (apart from a glance through it to get some kind of general impression) but from some of the excellent commentary that has been taking place on the blogs of Dick Lipton and Scott Aaronson. One comment that many people, including me, have found very useful has been one of Terence Tao, who attempted to summarize the state of the discussion up to the time he made the comment. Here is a portion of his summary.
The paper introduces a property on solution spaces, which for sake of discussion we will call “property A” (feel free to suggest a better name here). Formally, a solution space obeys property A if it can be efficiently defined by a special family of LFP formulae, the monadic formulae (and there may be additional requirements as well, such as those relating to order). Intuitively, spaces with property A have a very simple structure.
Deolilakar then asserts
Claim 1. The solution space to P problems always obey property A.
Claim 2. The solution space to k-SAT does not obey property A.
The latest from Dick Lipton’s blog seems to be that Neil Immerman has identified two serious flaws with Deolalikar’s proof. However, Tao, commenting on that, has pointed out that Deolalikar’s general strategy has not yet been shown to be hopeless in the way that, say, an attempted natural proof would have been shown to be hopeless by Razborov. In this post, I’d like to argue that it might be hopeless. I’m not sure I can say what that means in the abstract, so let me just give the argument.
First, here is a slightly more detailed version of Tao’s summary, provided on Dick Lipton’s blog by Albert Atserias.
If I may I would rephrase the thing as follows. Let “polylog-parametrizable” be a property of solution spaces yet to be defined.
Claim 1: The solution spaces of problems in P are polylog-parametrizable.
Claim 2: The solution space of k-SAT is not polylog-parametrizable.
Now, Claim 1 could be split as follows:
Claim 1.1: The solution spaces to problems in Monadic LFP are polylog-parametrizable.
Claim 1.2: Every problem in LFP reduces to a problem Monadic LFP by a reduction that preserves polylog-parametrizability of the solution spaces.
From these Claim 1 would follow from Immerman-Vardi Theorem (we need successor or linear order of course).
Perhaps Claim 1.1 could be true (we know a lot about Monadic LFP, in particular unconditional lower bounds using Hanf-Gaifman locality). But Claim 1.2 looks very unlikely. The reduction that Deolalikar proposes is standard but definitely does not preserve anything on which we can apply Hanf-Gaifman locality.
What I would like to do here is attempt to reinforce Atserias’s conclusion, by explaining why it seems to me very unlikely, unless somebody can tell me an amazing idea that gets round the problem (that is an important qualification, since one’s mathematical intuition can certainly be affected by unexpected ideas) that Claim 1.2 could be true. To do that, I’ll exhibit a specific problem in P that just doesn’t feel as though it could be reduced.
All this is completely independent of what any of the words in Atserias’s summary mean. I don’t know what polylog-parametrizability is (my comfort here is that I know of nobody apart from Deolalikar who does), or what the Immerman-Vardi theorem states, or what Hanf-Gaifman locality or monadic LFP are. And one thing Deolalikar’s paper has done is make me quite curious about these concepts and results. But for the purposes of this discussion, all that really matters is that polylog-parametrizability should mean something vaguely like what its name suggests.
OK, the problem in P I have in mind is this. Let me start with the following model of a random circuit (which I have discussed before in my sequence of “conversations between smileys” about the P versus NP problem in late 2009). Start with a 01 sequence of length 




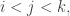
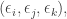



Now just repeat this process for, say, 
Not very much has been proved rigorously about functions like this, but what little is known points to a conclusion of the following kind: their solution spaces (that is, the set of input sequences that give rise to a 1) are very very hard to distinguish from random subsets of 

Now whatever polylog-parametrizability might mean, it doesn’t sound like something that would apply to a purely random function. Indeed, Tao describes it as a “simplicity” property. This already worries me — why doesn’t Deolalikar’s argument fall foul of the natural-proofs barrier?
The suggested answer to this is that Deolalikar uses uniformity in an essential way. Note that the random computable functions I defined above are not uniform — I was giving a different circuit (or rather, something that can easily be realized by a circuit) for each 

Now Deolalikar could simply counter that, whether I like it or not, he has found a simplicity property of pseudorandom computable functions. But if that assertion is in doubt, then it is legitimate to step back and consider the general strategy, as I am now doing, and ask whether something might conceivably be salvaged from Deolalikar’s proof attempt. And I have tried to present reasons to be pessimistic about this.
I don’t feel as though the arguments in this post are watertight. Indeed, somewhere I read a rather sophisticated comment (which I cannot relocate) about how Deolalikar might be evading the natural-proofs barrier, and it may be that a similar comment would deal with my worries. Also, my total lack of understanding of any of the logic and finite model theory used in the argument means that I am not properly taking account of the possibility that the property involves some kind of trace that a function in P has of how it has been put together. (However, if I was given the solution space of a pseudorandomly computable function in P, I wouldn’t fancy my chances of reconstructing the circuit that led to it …)
So to finish with, here are my main two questions. Apologies if they have already been answered in other places.
1. Is polylog-parametrizability supposed to be a “simplicity” property that applies to functions in P but not to random functions?
2. If so, then can anyone give me a half-plausible idea of how it might distinguish between a function computed by a pseudorandom circuit of length
I have a feeling that the answer to 1 may in fact be no, and that Deolalikar is claiming that almost all functions are simple, but that at a certain critical probability random k-SAT has very delicate features that are shared by very few functions and that make it complex. But I’d still like to be sure about this.

August 13, 2010 at 11:11 am |
I’d like to add that I’ve now read the beginning of Chapter 3 of Deolalikar’s paper a few times. I find his definition hard to understand: I don’t see precisely what it means to specify a distribution with a certain number of parameters. However, let’s take a pseudorandom computable function. How could we describe its solution space efficiently?
The distribution is certainly ample, since about half of all possible inputs belong to it. But the function mixes things up so much that it also seems to me that the various correlations amongst the n random variables (obtained if you take a random n-bit solution) will not be reducible in any sense I can think of.
August 13, 2010 at 2:15 pm |
A thought on defining parameters is as follows: Consider specifying a class, C, of distributions (characterized, say, by conditional independence). Suppose one would like a homeomorphism to class C from a subset of R^k; then the smallest such k would define the number of parameters required to define this class. I am not sure if it makes sense, but this is the best attempt of at least a more nuanced definition (still not complete) that I could think of while trying to capture Deolalikar’s intuition.
August 13, 2010 at 3:25 pm |
So, basically, the point is that if you get an infinite number of monkeys to design polynomial-length circuits, then the output of a typical such (or pseudorandomly selected) monkey circuit is, according to general belief, indistinguishable from that of a genuinely random function, and so it is unlikely that any sort of “simplicity” criterion can separate the two. (This sounds quite close to the belief that pseudorandom number generators exist, and so perhaps this is a spiritual cousin of the natural proofs barrier after all.)
This does look to be getting at the very heart of the matter, and is quite convincing to me at least that the whole “bound complexity using the structure of the solution space” strategy is indeed doomed to failure. I’ll point it out on Lipton’s blog.
August 13, 2010 at 4:23 pm
That’s a fair summary of what I think. Actually, I’d say it’s a bit closer than a spiritual cousin of the natural proofs barrier — more like an illegitimate sibling. It’s not rigorous, and I’m not sure whether it yields any insights that are not rigorously yielded by the natural proofs, but I find the general principle, that the output of a random circuit is incredibly hard to distinguish from a random function, easier to think about than the more precise natural proofs result. Also, when you say, “according to general belief,” I don’t actually feel that I can speak for the TCS community here. Somebody did once make an interesting comment on this blog, however, which was that Razborov believes more strongly that the output of a random circuit is pseudorandom than that factorizing is hard. (I hope I’m representing the comment and Razborov’s beliefs correctly.)
Another point is that it is conceivable that some very clever simplicity criterion could work, but the phrase polylog-parametrization doesn’t sound sufficiently weird and contorted to feel plausible.
August 13, 2010 at 5:47 pm
Incidentally, the model of using random reversible logic circuits to build a random polynomial length circuit reminds me of the product replacement algorithm in the theory of random walks:
http://en.wikipedia.org/wiki/Nielsen_transformation
This may only be a superficial similarity though.
August 13, 2010 at 6:39 pm |
[…] Deolalikar’s manuscript (in a soundbite: it doesn’t work and can’t be fixed). The objection of Timothy Gowers is also worth reading. Possibly related posts: (automatically generated)P might not be equal to NP […]
August 13, 2010 at 7:32 pm |
Over at Dick’s blog, Jun Tarui points out that I may have oversimplified somewhat when describing Deolalikar’s strategy. Deolalikar is not quite analysing the solution spaces {x: Q(x)=1} of a problem Q that may or may not be in P. Instead, he is considering satisfiability problems “Given x, does there exist y for which R(x,y)=1?” that may possibly be in P, and considering the fibres { y: R(x,y) = 1 } where x is selected in some way from the feasible set, rather than the solution set { x: R(x,y)=1 for some y}. Nevertheless it seems that one can modify your objection to deal with this case also, as I commented over at the other blog.
August 13, 2010 at 11:11 pm |
I believe Deolalikar’s lowness in the space of graphical models property holds. Deolalikar’s attempt takes account of a known difficulty, which encourages me to think that Deolalikar is in command of the main insight here, even though this particular proof of the lowness property may fail. The sort of lowness property I have in mind does not hold of your random circuit. I hope to put out a note before a decade^Wyear on this.
August 13, 2010 at 11:22 pm |
Oi, here is I hope address:
Click to access Boole.four.page.summary.for.1.August.2006.Cork.conference.Sulzberger.pdf
Please forgive pleonastic repetition!
August 13, 2010 at 11:25 pm |
Oi, here is, I hope, right address:
Click to access Boole.four.page.summary.for.1.August.2006.Cork.conference.Sulzberger.v.5.pdf
Please forgive repetition!
August 14, 2010 at 7:21 am |
Why cite only Razbarov for inventing the natural proofs barrier?
August 14, 2010 at 8:03 am
That was a piece of absent-mindedness on my part. Many thanks for pointing it out — I have now added Rudich’s name to the sentence in question.
August 16, 2010 at 6:07 am |
Deolalikar’s attempt to define the class P precisely in terms of FO formulas can also be seen as part of a serious attempt to bridge computability and provability.
Although not immediately obvious, the roots of the PvNP problem may lie in how we define the satisfiability of the atomic formulas of the first order arithmetic PA under an interpretation (following Tarski’s inductive definitions of the satisfaction, and truth, of the formulas of a formal language under an interpretation).
For instance, if an n-ary atomic formula [f(x1, x2, …, xn)] of PA interprets under the standard interpretation I_Standard of PA over the domain N of the natural numbers as the arithmetical relation f(x1, x2, …, xn), and the PA numeral [ai] as the natural number ai, then [f(x1, x2, …, xn)] is defined as satisfied under I_Standard for any given sequence of numerals [a1, a2, …, an] if, and only if, f(x1, x2, …, xn) is effectively verifiable instantiationally over N, and f(a1, a2, …, an) holds for the natural number sequence (a1, a2, …, an).
(See Lemmas 16 & 17 in the link below.)
There is, however, an alternative interpretation I_Algorithmic of PA over N where, if an n-ary atomic formula [f(x1, x2, …, xn)] of PA interprets under I_Algorithmic as the arithmetical relation f(x1, x2, …, xn), and the numeral [ai] as the natural number ai, then [f(x1, x2, …, xn)] is defined as satisfied under I_Algorithmic for any given sequence of numerals [a1, a2, …, an] if, and only if, f(x1, x2, …, xn) is effectively computable (decidable) algorithmically over N, and f(a1, a2, …, an) holds for the natural number sequence (a1, a2, …, an).
(See Lemma 18 in the link below.)
Now, it can be argued that the interpretation I_Algorithmic is sound; and that a PA formula [f] is provable if, and only if, f interprets under I_Algorithmic as an arithmetical relation that is effectively computable (decidable) algorithmically as always true over N.
(See Theorems 4 & 6 in the link below.)
This could be the bridge that Deolalikar appears to be implicitly seeking by his argumentation since, in view of Goedel’s construction of a PA formula that is PA-unprovable but effectively verifiable as always true over N, it would immediately follow that P=/=NP (irrespective, however, of the precise definitions of the classes P and NP).
(See Theorem 7 in the link below.)
Click to access 27_Resolving_PvNP_Update.pdf
August 22, 2010 at 8:57 am |
[…] הפעילות בבלוגים שקקה חיים. ובמתמטיקה המודרנית עיקר הפעילות מתבצעת באינטרנט – בפוסטים, בפלטפורמות העבודה השונות (נושא שראוי לפוסט בפני עצמו) – וכמובן: בתגובות. לדעתי, יש כבר אנשים שעובדים על הבעיה מבלי לקרוא את הטיוטה עצמה, אלא ע"פ הידע בפוסטיםתגובות בלבד. בחזית המגיבים עומד, כמעט כמו תמיד בשנים האחרונות, טרנס טאו. שעושה רושם שלח על עצמו את המשימה להתמחות בכל תת-תחום מתמטי. בינתיים המגיבים מצאו שתיים (וחצי) בעיות מהותיות עם ההוכחה. דאולאליקר הגיב לחלקן, בעיקר ע"י כך שאמר שהוא כותב גירסא מלאה, טכנית, שתפורסם בעתיד הקרוב. את המגיבים זה לא סיפק, והם נראים עדיין סקפטים למדי (מה שלא אומר הרבה, היות וכל הכרזה על פתרון בעיה כזאת מחויבת מעצם הגדרת הבעיה להיות מלווה בסקפטיות). מה שבינתיים העביר את הדיון לשאלות מהותיות יותר, כמו 'האם האסטרטגיה הכללית של ההוכחה יכולה להיות יעילה?' […]
September 10, 2010 at 3:36 pm |
Can anyone translate the last comment or tell what is stated therein?
September 12, 2010 at 8:03 am |
No I can’t translate, sorry. But http://www.reverso.net will attempt a
translation if you want to see the current state of automatic on-demand free online translation.
When I tried it I extracted a sentence “In the meantime the reactors found two ( and half ) essential problems with the proof.” but
I have no idea whether that is in any way faithful to the sentiment
actually expressed.