The story so far: our three characters, :), 8) and :|, have discussed in detail an approach that 🙂 has to proving complexity lower bounds. At the beginning of the discussion, they established that the idea would be very unlikely to prove lower bounds for circuit complexity, which is what would be needed to prove that P
***************************************
🙂 After all that, I have to say that I’m still slightly disappointed that it seems that even if the ideas I’ve been having could be got to work, they are most unlikely to show that P
😐 I didn’t really understand why not. Can somebody remind me?
8) I can. Recall that a formal complexity measure is a function 



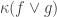

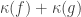



🙂 Hmm … it seems that you need a pretty strong statement to back up what you’ve just said. If I can find a formal complexity measure 

8) I’d have to check. But if you take a fairly random circuit, then the obvious way of turning it into a formula certainly does require the size of that formula to be exponential, and it’s hard to see how to do any better.
😐 How do you mean, “the obvious way of turning it into a formula”?
8) Well, if you’ve got a sequence of functions 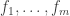










If you don’t count the basic functions in the definition of circuit complexity, then the circuit complexity of 
😐 Great, thanks, I believe you. In fact, it’s sort of obvious really: as you increase the length of the sequence of functions, to get the formula complexity of 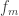
Actually, couldn’t one use this thought to tackle the formula-size question? Perhaps one way to produce a function in NP with large formula size is actually to produce a function in P with large formula size by picking a random sequence of Boolean operations.
8) Two comments on that. One is that a random sequence of Boolean operations will give you a function of low circuit complexity, but that’s not quite the same as a function that can be computed in polynomial time. The second is that you’ll still need a proof that your random function has high formula complexity.
[See this comment of Ryan Williams for an explanation of why the first objection can be dealt with.]
😐 I was wondering whether maybe it would have maximal formula complexity in the following sense: the obvious formula really is the best you can do, as long as you obey some simple rules that don’t allow you to produce a shorter formula in a trivial way. For example, you can shorten 

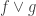

8) If that’s the sort of thing you’d like to do, then let me tell you something depressing. It’s a well-known approach that morally ought to give a lower bound for formula complexity, but nobody has managed to get it to work.
Suppose that 







Now choose a random function 


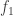


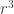

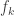





😐 That’s pretty cool. So what’s wrong with the argument?
8) Just the fact that I stated a major lemma and didn’t prove it. I didn’t justify the statement that the shortest formula for 
😐 I suppose another point is that even if this argument worked, it wouldn’t actually give a superpolynomial bound for formula size, because the function
8) You’re right. In the absence of any further tricks, what this argument would show is that there was a function of polynomial circuit complexity and superpolynomial formula size. [See again Ryan Williams’s comment.] But even without any new ideas, one would in principle be able to use this approach to obtain arbitrarily large polynomial lower bounds for formula size.
😐 How would you do that?
8) Well, even if we can’t choose a random function
😐 Sorry to be slow, but how would you do even that?
8) You’d look at every single Boolean function of 
😐 Wow. There are 
8) Yes. That’s why I used the phrase “in principle” earlier. But even distinguishing between polynomial circuit complexity and polynomial formula size would be very interesting.
🙂 Er, excuse me.
8) Yes?
🙂 We seem to have got sidetracked. I was just wondering whether it would be possible to return to the main topic.
8) How do you mean, “the main topic”?
🙂 I mean the question of whether any of the ideas we’ve been discussing could be used to prove that P
8) Ah yes, your obsession with the million-dollar prize …
🙂 That’s not fair. I absolutely agree that the formula-size problem is a great problem, but that doesn’t mean we shouldn’t even think about circuit complexity.
8) Relax, I’m just teasing you. Everyone would prefer to solve the P versus NP problem if there was a chance of doing so, including me.
🙂 OK, well perhaps you’d like to answer a question that’s been bugging me. Here is a proof that the notion of a formal complexity measure is very natural if one is thinking about formula size. We’ve already discussed it, but let me quickly go through it again just so I can be clear about the question I want to go on to ask.
One can arrive at the notion of a formal complexity measure by asking the following question: if we define 





8) Indeed.
🙂 The idea behind our previous discussion was this. In principle, one can prove that a function 

8) Let me quickly interject here that in their paper Razborov and Rudich showed that if a formal complexity measure is ever large, then it will be large for a positive fraction of all Boolean functions. So if you believe that natural proofs can’t solve the formula-size problem either, as you seem to do, then you definitely can’t use a polynomially computable formal complexity measure.
🙂 Right, that just confirms what I was saying.
Anyhow, on to my question. I’m just wondering whether we can go through the whole thought process again, but this time for circuit complexity. But I seem to have got stuck at the very first step.
8) How do you mean?
🙂 Well, the first step of the previous argument was to look for properties satisfied by the function 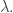





8) Ah ha, that is a very good question, particularly as there isn’t any reason to think that that statement can be strengthened.
😐 Why do you say that?
8) Well, suppose that 
🙂 What? You mean it’s even worse than it is for
8) I think so. The trivial bound requires you to add 1.
I ought to say that the argument I’ve just given is another “obvious” argument that is not in fact known to be correct. I claimed that calculating the max of two functions that depend on disjoint sets of variables cannot be done more efficiently than the obvious way of doing it. But if that is really so, then one can obtain arbitrarily large linear lower bounds for circuit complexity as follows. Let 





🙂 What you’ve just said manages to be more irritating than one might have thought possible. I’m trying to say something about circuit complexity, and you have managed convince me not only that I can’t, but also that I won’t even be able to make rigorous the demonstration that I can’t.
8) Welcome to the wonderful world of unconditional results in theoretical computer science.
Hey, cheer up.
😦
8) OK, let me try to say something to make you feel better. I want to point out that you’re not forced to define
🙂 I feel better already. Tell me more.
8) I’d better warn you that what I’m about to say is less promising than it might at first seem. It’s still worth mentioning, but promise me you won’t get too excited about it. It’s a brilliant idea of Razborov, but he has also proved that it cannot be used to obtain interesting lower bounds for circuit complexity.
🙂 What is it with this guy?
8) Well, I think like you he’d love to prove that P
Anyhow, let’s not worry about that for now. I just want to show you that there is a different notion of formal complexity measure, where you allow it to take values that are sets rather than numbers.
To explain what I mean, let’s suppose that we have a function 







😐 Hang on. It seems to me that you are implicitly taking your sets to have some notion of size attached to them.
8) Yes I am. What I want is for
Here is a set of axioms that would be very useful to us if we could obtain them. The idea is to allow a small error on the right-hand side. That is, instead of asking for 



If that is the case, then what can we say about 




🙂 OK, I’ve got lots of questions about this, but here are just two to get started. How might one go about defining a useful set-theoretic complexity measure like this? And is there some trivial argument, as there is the case of formula complexity, that gives a kind of “maximal” set-theoretic complexity measure such that the size of
8) Let me deal with the first of these questions by telling you about Razborov’s method of approximations. The idea of this is to construct a lattice 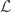


🙂 Aren’t you going to assume anything about those operations? For example, shouldn’t they be associative?
8) Oddly enough, we don’t need to assume that, but if
Indeed, what we want from 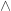

Now suppose that we have a straight-line computation 



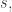










😐 Something’s bothering me here. It’s that your function
8) You’re absolutely right of course. I must apologize. But it turns out that for some problems, one can prove highly non-trivial lower bounds using this kind of idea, though I have in fact oversimplified what Razborov did.
The bad news is that Razborov has proved that the method of approximations doesn’t yield even superlinear lower bounds for circuit complexity, unless you allow extra variables, in which case you can produce a suitable lattice in a trivial universal way.
🙂 Ah, that’s sounding close to an answer to my second question. But perhaps we can think about it for ourselves.
Wait, there is indeed a spectacularly trivial set-theoretic complexity measure if it’s allowed to depend on how the function is computed.
😐 What’s that?
🙂 You just take the set of all functions that you used in the computation. Then if 

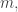



I’m still interested to know whether there might exist a set-theoretic complexity measure that applies to functions rather than to computations of functions. Has Razborov shown that they cannot exist?
8) I’m not sure. What I can say is that his method of approximations doesn’t give you one. If you wanted it to do so then you’d have to find some way of associating with each 







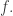
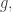


🙂 I don’t think an additive combinatorialist would give up just yet.
8) What do you mean?
🙂 Well, I can see that there is a problem with random functions 


8) If you want to try something like that, then you’ve still got some serious thinking to do.
🙂 Why?
8) Well, if you take two independent random Boolean functions 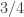




🙂 I see what you mean. That looks pretty bad. But does it show that no set-theoretic complexity measure that depends just on
8) I’m not sure. I’d be quite surprised if one existed. But perhaps it’s possible to find one in a trivial way.
🙂 It’s difficult to see how one could define such a set without making any reference to circuits. So perhaps one would have to associate a set with each straight-line computation and then for each
😐 I’m not sure I like the sound of that. For instance, if you apply it to the “trivial” function that associates with each computation the set of Boolean functions involved in that computation, then you don’t get anything interesting when you intersect over all computations.
🙂 Yes, you’re right. One would probably have to do something fairly clever.
It’s a very long shot, but I wonder whether the 




In fact, I can’t face thinking about it for now. I need a rest.
8) 😐 OK, see you again some other time.
🙂 But just to end on not too depressed a note, I’d like to point out that a property such as “The set of functions that witness that the dual norm of

October 16, 2009 at 8:00 pm |
Can’t do the latex, but there is a point about half way through where Rho(Fm) is used with “V” notation rather than “U” (Here is a set of axioms which would be very useful to us …)
And thank you for a cogent and interesting summary.
October 16, 2009 at 9:01 pm
Thanks very much — I’ve corrected it now.
October 16, 2009 at 9:27 pm |
You raise the following “direct product conjecture:” if has circuit complexity
has circuit complexity  and
and 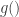 has circuit complexity
has circuit complexity  , is it the case that
, is it the case that  has circuit complexity
has circuit complexity  ?
?
The intuition is that there should be no other way to compute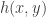 than to first compute
than to first compute  and
and  , since the two are “independent.” This basic intuition is not necessarily true: take two operations
, since the two are “independent.” This basic intuition is not necessarily true: take two operations  such that
such that  is much easier to compute than
is much easier to compute than  and such that a distributive law applies.
and such that a distributive law applies.
Then computing is strictly easier than computing
is strictly easier than computing  and then
and then  , because one can do the computation
, because one can do the computation  instead.
instead.
In fact I think that there are known counterexamples to the “direct product conjecture” above. Specifically (and this would apply to your candidate for a super-linear bound) if is any function, and
is any function, and  , then the function
, then the function
should always be computable in size at most . This contradicts the direct product conjecture if we pick
. This contradicts the direct product conjecture if we pick  to be a function of maximal circuit complexity
to be a function of maximal circuit complexity  .
.
Maybe someone who knows a bit more about circuit complexity can confirm? My idea would be to sort the input sequence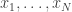 using a sorting network realizable as a circuit of size
using a sorting network realizable as a circuit of size  . Next we say that given the truth-table of
. Next we say that given the truth-table of  , and given a sorted sequence of inputs
, and given a sorted sequence of inputs  , there is a two-tape Turing machine that computes
, there is a two-tape Turing machine that computes  in time
in time  , and so it can be simulated by a circuit of size
, and so it can be simulated by a circuit of size  . Use this circuit, with the truth-table of
. Use this circuit, with the truth-table of  hard-wired into it, to turn the sequence
hard-wired into it, to turn the sequence  produced by the sorting network into the sequence
produced by the sorting network into the sequence  . Now compute the OR of the above bit sequence
. Now compute the OR of the above bit sequence
October 17, 2009 at 4:47 pm |
(I really hope this comes out right, because I haven’t tried WordPress Latex before.)
Luca: Yes, if the function has circuit complexity
has circuit complexity  where
where  is very high, then computing
is very high, then computing  copies of
copies of  can indeed have much lower circuit complexity than
can indeed have much lower circuit complexity than  . A version of your idea is illustrated in Lemma 2 of
. A version of your idea is illustrated in Lemma 2 of
Click to access 75-215.pdf
which discusses these questions at length. (The above link is just an old tech report of Wolfgang Paul, but I can’t seem to find a free version of the published paper online.)
Tim: Suppose you find an infinite sequence of circuits (constructed randomly, or however you like) such that
of circuits (constructed randomly, or however you like) such that  has circuit complexity at most polynomial in
has circuit complexity at most polynomial in  , and formula complexity that grows superpolynomially in
, and formula complexity that grows superpolynomially in  .
.
Then there is an explicit polynomial time computable function that has superpolynomial formula complexity. Namely, the function which is
which is  iff the circuit described by
iff the circuit described by  on input
on input  outputs
outputs  .
.
If has high formula complexity, then any circuit family which correctly computes
has high formula complexity, then any circuit family which correctly computes  must also have high formula complexity. Otherwise, I could just plug in the (polynomial length) code of each
must also have high formula complexity. Otherwise, I could just plug in the (polynomial length) code of each 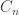 as input into the appropriate small formulas for
as input into the appropriate small formulas for  , and now I have small formulas that compute
, and now I have small formulas that compute  .
.
So you do not need to worry if your circuits are inefficient to compute; in this case you get that for free.
October 17, 2009 at 5:39 pm |
Also, Chapter 10.2 of Ingo Wegener’s book “The Complexity of Boolean Functions” available at
Click to access cobf.pdf
contains more information about this direct product stuff, which Wegener calls “mass production”.
October 19, 2009 at 5:51 am |
In a slightly different context (circuit and not formula complexity, multibit output) the canonical counterexample for the “direct sum” question (does copies of
copies of  has circuit complexity
has circuit complexity  times the circuit complexity of f) is fast matrix multiplication. (This has to do with Luca’s example of the distributive law.)
times the circuit complexity of f) is fast matrix multiplication. (This has to do with Luca’s example of the distributive law.)
This example is in the case where we consider functions with multiple bits of output, and hence the operation is not OR but simple concatenation, where it seems “obvious” that you could not compute copies of the function on
copies of the function on  independent inputs without paying
independent inputs without paying  times the price.
times the price.
But by simple counting you know that there is a linear function such that
such that  has circuit complexity
has circuit complexity  (e.g., take
(e.g., take  to be computed by a random matrix), but if you look at the function
to be computed by a random matrix), but if you look at the function  that is defined as
that is defined as  then this is just multiplying the matrix
then this is just multiplying the matrix  by the matrix
by the matrix  and can be done in
and can be done in  time.
time.
October 19, 2009 at 5:54 am |
p.s. I learned from Avi Wigderson that one should use “direct sum” for questions of this form (does the amount of resources grow when combining functions) and “direct product” to questions of the form: “does the probability of successfully computing the function decreases exponentially when combining functions”
October 20, 2009 at 12:14 am |
This reminds me of a chess book I once read. There was an analysis of a chess game as I recall. There were several participants in a dialog involvign various features of chess analysis. The use of emoticons also reminds me of the ongoing project of translating Moby Dick into Japanese emoticons. Today was the deadline for the raising of the 3500 dollars needed and apparently they have reached their goal:
Also on this survey article:
http://cacm.acm.org/magazines/2009/9/38904-the-status-of-the-p-versus-np-problem/fulltext
There is a mention of Geometric complexity theory. So apparently there is an approach using complexity that works although the authors say it may take one hundred years to reach an answer. There is this reference:
Mulmuley, K. and Sohoni, M. Geometric complexity theory I: An approach to the P vs. NP and related problems. SIAM Journal on Computing 31, 2, (2001) 496–526.