Here is the next instalment of the dialogue. Whereas the previous one ended on an optimistic note, this one is quite the reverse: plausible arguments are given that suggest that the 
********************************************************
😐 Can I make a slightly cheeky comment?
🙂 OK
😐 Well, over the years I’ve heard about a number of approaches that people have had to famous problems, including the P versus NP problem, that have the following characteristic. Somebody who works in a different area of mathematics comes in and claims that the right way of solving the famous problem is to reformulate it as a problem in their area. They then make grand claims for the reformulation, and there’s quite a bit of excitement, though also scepticism from those who have thought hardest about the problem, and ten years later nothing has actually happened. I’m usually a little suspicious of these reformulations, unless they feel so natural as to be almost unavoidable. So the fact that you like additive combinatorics and are trying to reformulate the P versus NP problem (or even just the formula-complexity problem) as a problem in additive combinatorics makes me very slightly wary.
🙂 Yes, I was conscious of that myself, although the
8) No no, absolutely not. I admit that there’s a lot I don’t know in this area, and I could easily have missed some serious objection to your proposals.
🙂 Also, I’ve been thinking a bit about your objection that the
8) Ah, that’s much more interesting. What is it?
🙂 I can summarize it as follows. I have the following picture of what a random function of circuit complexity (or perhaps formula complexity — let me be vague about this, since we can always think about it properly later if we want to develop this heuristic argument further) looks like. It springs from a result that appeared in a little known paper by Gowers about 15 years ago. In it, he defined a model of random computable functions, though in fact they were rather special functions because they were reversible, and proved that if you choose a function of complexity 


😐 You’re losing me a bit here.
🙂 Let me not bother to say precisely what the model is. But to say that it is approximately 


😐 So in a weak sense Gowers’s random model was a pseudorandom generator.
🙂 In a very weak sense, yes, but still quite an interesting sense.
8) Did you know that if Gowers had waited a decade or so then he could have had a stronger result for free?
🙂 Eh? He told me he had wondered about stronger results, but got nowhere.
8) That’s amusing, because it has subsequently been proved that almost
🙂 So you’re saying that in fact he defined a generator that was pseudorandom for circuits of constant depth, and provably so. I must ask him whether he knows about that.
Anyhow, all I need for this discussion is the original result. Let us take “random computable function” to mean a function that comes from his model. I should add that Gowers was not in fact the first to define reversible computations, though he rather sweetly appeared to think he was. In particular, they are important in quantum computation. But the result about almost 

What follows is plausible guesswork. I’m going to guess that a random function of complexity
In other words, what I’m saying is that if you choose a random function of complexity 
If that is correct, then how might we detect the structure? Well, a fairly natural idea is to look at a 
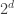
This is supposed to give an answer to the following question. If we are presented with lots of random computable functions, then it makes sense to talk about almost 
8) Hmm, that does make me feel somewhat happier with your idea. But it also suggests to me that there might be other ways of exploiting these large-scale correlations. You haven’t given any particular reason to go for subspaces rather than arbitrary sets of size
🙂 True, but you have to admit that subspaces are pretty natural objects.
Actually, wait a moment. Now that I’ve gone to the trouble of explaining my heuristic picture of what a random low-complexity function is like, I’m starting to wonder whether I might have stumbled on a two-line proof that P
8) You haven’t, but go on, let’s hear it all the same.
🙂 Well, the idea is closely related to what I was saying just now. I was thinking of a random function of complexity
8) I hope there’s going to be more to your argument than looking at random restrictions, because those have been done to death.
🙂 I’m slightly worried about that, I have to admit, because I don’t seem to be using much more. But just hear me out.
8) OK.
🙂 Well, suppose you’ve got a function 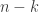



We have been searching for a difference between random low-complexity functions and purely random functions. Well, here it is: a random low-complexity function has just a limited number of possible restrictions, whereas a purely random function is completely arbitrary.
8) Hmm, I don’t yet see what’s wrong with your argument, but I do have a proof that it’s wrong.
😐 How can one prove that an argument is wrong without seeing what is wrong with it?
8) That’s not mysterious at all. For example, one can show that it implies something false. But that’s not what I’m going to do here. Rather, I’d just like to point out that the property that 🙂 claims distinguishes between random low-complexity functions and purely random functions is a natural property.
🙂 You mean, not only have I proved that P
8) Er, I think not.
🙂 Cool it, I was joking.
8) You had me there for a moment.
😐 Can you explain why this property is natural? In fact, what property are we talking about?
8) I assume that what 🙂 has in mind is to look at the restrictions of 

😐 Ah, thanks. But doesn’t that also show what’s wrong with the argument? After all, if there are only 


🙂 Oops, you’re right. To see in an extreme way why the argument is wrong, one could take the case 


But wait a moment.
8) Here we go again …
🙂 Sorry, but there’s something else to check. What if, instead of looking at restrictions to subspaces generated by 


8) I don’t think so, because now it’s no longer the case that the restriction of a function of complexity at most
🙂 Oh yes, you’re right. But perhaps it must still be quite special. How many functions can you get by taking a function of
Hmm, one way of thinking about it is this. Each such function is obtained by taking a Boolean string of length 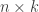
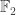
But in a funny kind of way I regard this as a further justification for the
8) It wouldn’t determine it exactly, because it wouldn’t distinguish between a function 



🙂 That’s fine by me. All I’m trying to argue here is that there must be some relationship between the various 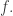

😐 Can I just ask something here?
🙂 Of course.
😐 It’s that you seem to be focusing on the
🙂 Ah yes. Let me make clear once and for all what I’m doing here. I’m focusing on the 
😐 I see. Thanks.
I also have another worry, and in fact it’s a worry about dual norms. If I understand you correctly, your plan is to prove that every low-complexity function has a small
🙂 Yes, that’s exactly right.
😐 Now to prove the latter, you need to show that the clique-hiding function correlates with a function with very small
🙂 Yes, that’s also correct.
😐 That function 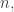
🙂 Fine, if it makes you happier.
😐 Now let’s define a property S to be “has good correlation with 


🙂 Indeed.
😐 But checking whether a function correlates with 
😦 Oh dear. I think you’ve just killed off the whole approach.
8) Er … I think you are both forgetting something. Far be it from me to defend the approach in general, but at least against this attack I can. To violate the theorem of Razborov and Rudich, you need a polynomially computable property that distinguishes between low-complexity functions and random functions. All this property S does is distinguish between low-complexity functions and one single function in NP.
🙂 Oh yes. Phew!
8) Another way of putting it is this. :|’s property S is not a natural property, because although it can be computed in polynomial time (probably anyway), it fails the largeness condition: if you choose a random function, it is incredibly unlikely to correlate with
But :|’s observation is still interesting, since it shows that if the approach works, then it can be formulated in two ways. One way, the dual-norm approach, gives you a property that is non-constructive but large (to use the terminology of Razborov and Rudich) and the other gives you a property that is constructive but not large. But they’re essentially the same argument.
🙂 That’s interesting. I had the feeling that it was much more promising to try to sacrifice constructivity than largeness, but now it seems that there isn’t much difference. I wonder whether one can identify a general class of properties that can be converted in this way, since the argument seemed quite general.
8) It looks as though it ought to happen a lot. Roughly speaking, if your original property R is large but not constructive, then at some point you need to exhibit a function 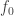



😐 I have another worry.
🙂 Fire away.
😐 Well, you admitted that you were going to want to prove that the clique-hiding function had a large
🙂 Yes, that’s right.
😐 But I thought you were saying that Viola and Wigderson’s result was state of the art. Is it reasonable to hope to exhibit any function with small
🙂 Hmm, that does sound more challenging than one would ideally like. But it doesn’t require us to improve on the result of Viola and Wigderson (which, you should recall, we very much don’t want to be able to do) since the function with small
8) OK, I think you escape for now. But there’s a worry I had much earlier in our discussions. We didn’t discuss it much then and I think we badly need to.
🙂 I had a vague feeling that there was some serious problem we hadn’t addressed, but I’m afraid I’ve forgotten what it was.
8) Let me remind you then. Some time ago, I came up with the following argument that suggested that the 

🙂 Oh yes, and I then argued that “almost exactly half” meant within 


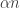

8) Right, but the problem with that is that if 


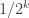
🙂 I think this is something we have to think about seriously, but as I said earlier, we shouldn’t get too worried if the norms of all Boolean functions are incredibly close to 1. For instance, we can always look at the 
8) So you are hoping that random polynomial-computable functions will have 

🙂 I suppose so.
8) But what earthly reason is there to suppose that that is the case? Here, in my view, is a far more plausible guess: that the 

🙂 Hmm … we should think a bit about this. It feels like an approachable question: given a subspace 
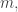
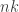
8) Yes, but I thought we’d convinced ourselves that we couldn’t use the
🙂 That is a question to which I’d like to return.
😐 Sorry to interrupt, but 🙂 seems to have made a weird mistake.
🙂 Always possible. But what is it this time?
😐 Well, you gave a lower bound of 
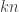
🙂 Damn. You’re right of course.
Except …
8) !@£$%^&*()
🙂 Look, as ever what I’m about to say may be rubbish, but it would be silly just to give up without making completely sure that the approach can’t be rescued. And I’ve just had a small thought in that direction. Any objections?
8) Sorry — I wasn’t actually objecting. I just thought that we had now made completely sure. We seem to have an argument that makes it highly plausible that this approach cannot lead to superlinear lower bounds for anything.
🙂 I’m not sure we’ve completely convinced ourselves that that is the case for formula size. But in any case what I want to propose now is a very slight modification of the approach. So far, we’ve been looking at the
Now the argument just given suggests that the largeness we can hope for if we have a function of superlinear complexity is smaller than the largeness we trivially get from the degenerate configurations in the calculation of the
😐 What do you mean? If we did that then we wouldn’t even have a norm!
🙂 Yes, but who says we need a norm?
😐 It seems pretty fundamental to your approach if you ask me. For example, you’ve made a big thing of the merits of dual norms.
🙂 Ah, I should tell you that norms are not fundamental for defining dual norms.
😐 What? Isn’t that a trivially false statement?
🙂 Not at all. The construction we used to define dual norms is a special case of the following more general construction. Given any bounded set 


So my next suggestion is to let 
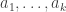
I’ve chosen a few details of that definition arbitrarily (for instance, perhaps it would be better to take Boolean functions only). However, the point I want to make is that the smallest possible non-zero value of the “non-degenerate 
8) Wow, you really are prepared to sacrifice your fingernails to remain hanging on to the cliff aren’t you.
🙂 I agree that this variant of the
😐 But won’t it be extraordinarily delicate to look at the error term?
🙂 Not necessarily. All we’re asking is the following question, which seems to me to be not all especially delicate, though it could be tricky. I’m about to repeat myself, because it’s the question I asked before you pointed out my silly mistake to me. You take a 
😐 But for that you need a model of “random function of complexity
🙂 I know. That sounds pretty hard. But we do have the advantage that at this stage we are just looking for a heuristic argument that will answer the question of whether we can hope for a decay that is at most exponential or whether we would in fact get a faster decay. Also, we could try it out on that model that Gowers looked at. That gives a very concrete question.
😐 Can you tell me in more detail how that model works?
🙂 Certainly. It’s a way of defining an easily computable function from 


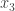

And now, to define a random computable function one simply takes a random composition of basic operations. The nice thing about this is that it gives you a random walk, and there are lots of clever techniques for bounding the convergence rate of random walks. And what I find promising is that random walks are just iterations of linear maps, so they definitely don’t converge faster than exponentially. At this stage, that’s just a vague heuristic, but it gives me hope.
8) Why?
🙂 Well, let me try to use this model to create a problem that’s relevant to our discussion. We don’t want a function from 
If we do that, then what we are interested in is the following question. Let 
If it is, then that would give us reasonable grounds for guessing that perhaps it is impossible to avoid a bias of at least 
8) A quick question. Would that property distinguish between random low-complexity functions and purely random functions? How much bias do you expect in the purely random case?
🙂 Help — yes, that’s important. Well, when we choose a random function 

8) OK, now your approach really is dead isn’t it?
🙂 Unfortunately it does seem to be. I suppose it’s just conceivable that one could prove that a specific
8) Just to depress you further, I think we should revisit the question of whether the approach is naturalizable. If it is, then not only will the approach have failed, but it will have done so for an uninteresting reason.
🙂 Hey, that sounds fun.
8) If we go back to my random sampling idea, armed with the new thought that we can’t hope to get smaller than exponential bias in the formula for the norm, then it would seem that we do not need to sample more than exponentially many random subspaces in order to find such bias as there is. And exponentially many subspaces means polynomially many in

🙂 I see your point, but I think it’s not really a question of my proof naturalizing, since I was looking for a bias that was even smaller than exponential, but simply of being wrong, because random functions do not have bias that’s as good as that.
I’m sufficiently chastened by my experiences so far that I’m not going to hope that we’re hitting some fundamental new obstacle to proving complexity bounds. I basically agree with you that Razborov and Rudich can explain the difficulties I’ve just had. But I think it might be interesting to understand as well as possible what the consequences of their obstacle are. For instance, if one can prove a reasonably general result that says, “Every proof of such-and-such a kind naturalizes,” then one is not discovering a fundamental new obstacle, but one might still be performing a useful service to people who want to prove that P
Another project I quite like is to find heuristic arguments for the impossibility of certain sorts of proofs. If one is searching for a proof, then a convincing nonrigorous argument that certain kinds of proofs don’t exist can be a very good reason not to look for such proofs. Of course, a certain caution is needed, as heuristics can be wrong, but they are still useful. So, for example, I would like to know what follows from the assumption that random functions in Gowers’s model are indistinguishable from genuinely random even permutations of

October 12, 2009 at 12:16 am |
At some point, the dialog assumes that the number of functions of circuit complexity at most is upper bounded by
is upper bounded by  . The bound, however, should be
. The bound, however, should be  ; heuristically, if we count the number of distinct circuits of size
; heuristically, if we count the number of distinct circuits of size  , then for each of the
, then for each of the  gates we need to specify from which of the other
gates we need to specify from which of the other  gates the two inputs are coming from. Rigorously, it has been shown that each of the
gates the two inputs are coming from. Rigorously, it has been shown that each of the 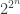 functions is computable by a circuit of size at most
functions is computable by a circuit of size at most  .
.
October 12, 2009 at 8:36 am
Oh yes — that was careless of me. I had got used to because it was correct when
because it was correct when  is polynomial in
is polynomial in  and then allowed my brain to switch off.
and then allowed my brain to switch off.
October 12, 2009 at 6:11 am |
In the context of counting arguments its probably simplest to think of circuit size as the number of bits it takes to describe the circuit. (Although indeed in this case one should suspect any lower bound that’s smaller than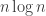 .)
.)
Regarding your conjecture that random invertible circuits of size S yield pseudorandom functions, I remember asking Sasha Razborov what he thinks about it, and he said that he believes that this or similar constructions can yield pseudorandom functions more than he believes that integer factoring is hard. Indeed I agree with the intuition that in the right model random functions of small complexity are hard to invert and perhaps even pseudorandom (there are also such candidates that are very shallow functions, where each output bit only depends on a constant number of the input bits, though in this case they can only be pseudorandom up to a point).
Indeed, that model of invertible circuits is interesting in a way similar to constant depth threshold circuits (TC0). On the one hand, it’s a very limited model and it seems hard to compute very simple functions in it. On the other hand, it’s rich enough so it plausibly contains pseudorandom functions (in this particular case pseudorandom even permutations) and hence any lower bound for it will have to be “un-natural”. So these models look like a reasonable place to try to first cross the natural proof barrier.
–Boaz Barak
October 13, 2009 at 2:41 am
“he believes that this or similar constructions can yield pseudorandom functions more than he believes that integer factoring is hard.” Just to make sure that I follow: these two beliefs are not in conflict but sort of in a similar direction right?
October 13, 2009 at 8:15 am
Gil, unless I’m missing something the answer to your question is a simple yes. I find this piece of information about Razborov fascinating for two reasons. One is that I completely agree with it but had never heard the view expressed by anyone else. The other is that it shows that the strength of one’s belief in a complexity hypothesis of that kind does not have to be determined by its status as one of the “official” hardness beliefs (since if Razborov’s aren’t then it cannot be compulsory).
October 13, 2009 at 2:36 pm
First a disclaimer: this is based on what I remember from 2001, so I may not be representing Sasha’s beliefs perfectly accurately. Let me speak for myself: I’ll be more surprised if there is no way to generate a one-way function using some kind of a simple combination of random local operations (am not committing to Gowers’s particular model) than if there exists a polynomial-time algorithm for factoring.
To answer Gil’s question: both beliefs (factoring is hard, inverting random circuits is hard) imply P different from NP and even that one-way functions exist (and in factoring’s case even public key cryptography). So, in that sense they can be said to be in the same direction.
But there is another sense in which they are in a different direction, which is that they have different reasons why they may be true.
The reason that most people believe that factoring is hard is empirical: people have tried *very* hard for a *long* time, and couldn’t do it, even not come up with a heuristic algorithm that’s just conjectured to work.
Note however that the empirical evidence does include non-trivial algorithms (classical and quantum) that took some time to discover (though the best classical running time hasn’t been improved in about 20 years). Perhaps some people also have number theoretic reasoning why a better algorithm shouldn’t exist- I don’t know of such reasonings but that’s not saying much.
The reason one believe assumptions of the other nature is a combination of both empirical and “philosophical” considerations. The empirical evidence is weaker than factoring, but still one can look at these constructions as similar in nature to problems such as breaking block ciphers, and solving random constraint satisfaction problems (e.g. random 3SAT) that people have worked on.
The “philosophical” considerations are based on a bold assumption that we have some understanding of the nature of computational hardness, and that for such combinatorial problems there is some kind of threshold that either they can be easily solved using known algorithms (e.g. the solution space is convex) or they can’t be solved at all better than brute force. You can say that predictions made by this intuition have been empirically confirmed (e.g. NP hardness, hardness of approximation, (partial) dichotomy theorems).
The philosophical considerations are to some extent reasons why one would believe that an algorithm doesn’t exist, and is not just very very hard to find.
I don’t know if there is a set of “official” hardness beliefs – in cryptography we invent new assumptions all the time. There are just hardness assumptions that have more empirical evidence behind them.
–Boaz Barak
October 12, 2009 at 11:55 am |
[…] Some academic questions tackled. Ought/is and complexity. […]