Note added 12/9/09: It seems that many people are looking at this post, because Derren Brown claims to have used “deep mathematics” combined with “the wisdom of crowds” to predict the lottery. All I can say is that this is obvious nonsense. Whatever method you use to predict the lottery, the drawing of the balls is a random process, so you will not improve your chances of being correct. Brown has done a clever trick — I won’t speculate about his methods, as I’m not interested enough in them — but his explanation of how he did it is not to be taken seriously.
In this post I shall discuss the proofs of two statements in real analysis, one of which is clearly deeper than the other. My aim is to shed some small light on what it is that we mean when we make that judgment. A related aim is to try to demonstrate that a computer is in principle capable of “having mathematical ideas”. To do these two things I shall attempt to explain how an automatic theorem prover might go about proving the two statements in real analysis: in one case this is quite easy and in the other quite hard but by no means impossible. In the hard case what interests me is the precise ways that it is hard, which I think say something about the notion of depth in mathematics.
The first statement is that if a function  is continuous, then for every
is continuous, then for every  and every sequence
and every sequence 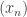 that converges to we also have that
that converges to we also have that  converges to
converges to  . Most experienced mathematicians would not regard this as a deep statement because proving it is “just an exercise” rather than a result that “needs an idea”. (Spotting that it is a useful statement is a different matter, but it’s not what I’m talking about here.)
. Most experienced mathematicians would not regard this as a deep statement because proving it is “just an exercise” rather than a result that “needs an idea”. (Spotting that it is a useful statement is a different matter, but it’s not what I’m talking about here.)
I shall now give a proof of the statement in such a way that every step of the proof is the obvious thing to do, where by “obvious” I mean in some sense “algorithmic”. I could go into more detail about how these obvious steps could be carried out by an actual program, but then what I wrote would be much less readable. So I’m compromising by giving a slightly higher-level discussion. But if anyone thinks I’m using that to sneak in a trick that only a human could spot then I’ll be happy to elaborate on parts of the proof later. So here goes.
We want to show that if  is continuous, then it commutes with taking limits. Suppose then that
is continuous, then it commutes with taking limits. Suppose then that  converges to . We would like to prove that converges to . Therefore we must let
converges to . We would like to prove that converges to . Therefore we must let  and find some
and find some  such that
such that 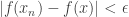 whenever
whenever 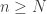 . (That is just translating the definition, which is clearly an automatic process.)
. (That is just translating the definition, which is clearly an automatic process.)
How can we find such an ? Well, what could possibly imply that ? To answer this question we write out the information we have and simply look at it to see if anything has a statement resembling as a conclusion. And we notice that the definition of continuity of ends with the assertion 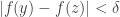 . (For safety’s sake, we give all our dummy variables different names.) So we focus on the whole definition:
. (For safety’s sake, we give all our dummy variables different names.) So we focus on the whole definition: 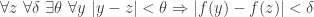 .
.
So the obvious thing to try is taking  to be
to be  ,
,  to be and
to be and  to be . We’re free to do the first two as the above assertion starts with “
to be . We’re free to do the first two as the above assertion starts with “ “, but what about the third? Well, we also have a “
“, but what about the third? Well, we also have a “ ” but it comes with the condition that
” but it comes with the condition that 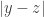 , or rather
, or rather 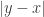 , should be at most
, should be at most  , which depends somehow on and . So we can conclude the following: if
, which depends somehow on and . So we can conclude the following: if 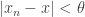 then .
then .
Now let’s recall precisely what we want to prove. We would like to show that there exists such that if then . From what we have just shown, it will be sufficient to prove that . And now we see that just such a conclusion appears at the end of the definition of the convergence of to , and it is easy to see that the premise is exactly what we want too as it gives us our .
Incidentally, the converse of this statement can also be proved in a fully justified doable-in-principle-by-computer way too. (In fact, I discussed both directions many years ago on my web page.) However, I only really need one sample of “non-deep” mathematics to illustrate my point, so I won’t discuss the converse here. Instead, let’s move to the second statement, which is a beautiful problem that is often set to Cambridge undergraduates. It can serve either as a hard problem for those who have done a first course in analysis (one that perhaps one or two people per year are capable of solving) or a hardish exercise in applying the Baire category theorem.
It’s quite interesting to discuss how a computer could solve the problem if it had the hint that the Baire category theorem should be applied, but then it becomes more like the first example: it can be done by “pattern matching”. But then one would feel that the computer had cheated and been told the idea. So it is even more interesting to see how a computer could solve the problem from scratch, succeeding where all but a handful of students fail.
The statement in question is this. Let be a continuous function and suppose that for every 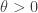 the sequence
the sequence 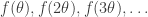 tends to 0. Prove that tends to 0 as
tends to 0. Prove that tends to 0 as 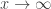 . If you haven’t seen this before and want to get the most out of this post then you should (of course) make a serious attempt to solve this beautiful problem before reading on.
. If you haven’t seen this before and want to get the most out of this post then you should (of course) make a serious attempt to solve this beautiful problem before reading on.
On then to the proof. The aim, as with the previous result, is to present the proof in such a way that every step is “the obvious” thing to do, or at least sufficiently obvious that it would be one of the first things that a well-programmed computer would try.
Let us begin with steps that really are automatic, such as translating the problem into more formal language and converting “for all”s into “let”s (by which I mean that if you want to prove a statement that begins “for every x in A” you start by writing “let x be in A”, and so on). In this case we are trying to prove that tends to 0, so we let be positive. We would now like to find  such that
such that  whenever
whenever 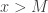 . But simple pattern-matching lets us down: the obvious (and only) statement available to us that resembles is the statement
. But simple pattern-matching lets us down: the obvious (and only) statement available to us that resembles is the statement 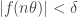 that comes at the end of a formal definition of the hypothesis of the problem. And that is true only if
that comes at the end of a formal definition of the hypothesis of the problem. And that is true only if  is at least as big as some that depends on in a way that we know nothing about.
is at least as big as some that depends on in a way that we know nothing about.
This is a point where many human mathematicians will feel stuck. But one move that sometimes helps is to do something else that can be easily automated and aim for a proof by contradiction, so let’s try it.
If we cannot achieve our goal then for every there exists such that 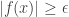 . And now, if we want a contradiction, we must prove that there exists such that
. And now, if we want a contradiction, we must prove that there exists such that  does not tend to 0. Writing out this last statement in full gives us
does not tend to 0. Writing out this last statement in full gives us 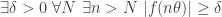 .
.
Now we make three observations. First, it is fairly clear that we shall need to use the fact that is continuous. (I have thought quite hard about how a computer might come to this realization, or at least construct, when asked, an example of a discontinuous function that does not tend to zero despite the fact that  always does. I’ll save my conclusions about that for another post. For now let us be satisfied with the idea that the continuity of was given as a hypothesis and the computer will naturally tend to see what comes of using the hypotheses.) Second, there is a promising resemblance between
always does. I’ll save my conclusions about that for another post. For now let us be satisfied with the idea that the continuity of was given as a hypothesis and the computer will naturally tend to see what comes of using the hypotheses.) Second, there is a promising resemblance between  and . Third, we are trying to construct a real number that satisfies an infinite set of conditions, one for each .
and . Third, we are trying to construct a real number that satisfies an infinite set of conditions, one for each .
Let us think about the last observation first. How does one construct a real number with infinitely many properties? A standard answer, and one that is closely bound up in the very idea of a real number, is to construct it as the limit of a sequence. But what will make that limit satisfy all the properties? To make this question slightly more concrete, let us call the properties 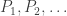 and let the sequence be
and let the sequence be 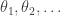 , converging to . We don’t have much to play with here: all we can say about each
, converging to . We don’t have much to play with here: all we can say about each 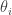 and each
and each 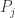 is whether or not has property . And our main information about is that the get close to it.
is whether or not has property . And our main information about is that the get close to it.
As we build our sequence , how can we make sure that its limit at least has property 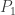 ? A natural answer is to insist that every belongs to some closed set
? A natural answer is to insist that every belongs to some closed set 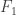 , all of whose elements satisfy property . Here I am using “closed” in the sense of “closed under taking limits”. The most basic examples of closed sets are closed intervals, and this thought leads us to one of the basic theorems of real analysis: that a nested intersection of closed bounded intervals is non-empty. But I prefer to think of this statement as yet another version of the completeness axiom, and it leads us to the following basic real-number-constructing principle, which I would imagine a computer as having been taught rather than as having invented: if you want to construct a real number that has properties , then see if you can construct a nested sequence of closed bounded intervals
, all of whose elements satisfy property . Here I am using “closed” in the sense of “closed under taking limits”. The most basic examples of closed sets are closed intervals, and this thought leads us to one of the basic theorems of real analysis: that a nested intersection of closed bounded intervals is non-empty. But I prefer to think of this statement as yet another version of the completeness axiom, and it leads us to the following basic real-number-constructing principle, which I would imagine a computer as having been taught rather than as having invented: if you want to construct a real number that has properties , then see if you can construct a nested sequence of closed bounded intervals 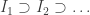 (of non-zero length) such that every
(of non-zero length) such that every 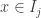 has property . If you can, then any in the intersection will have all the properties simultaneously.
has property . If you can, then any in the intersection will have all the properties simultaneously.
Now let us return to the problem at hand. Property  is the property that there exists such that
is the property that there exists such that  . So let us suppose that we have already constructed the closed bounded interval
. So let us suppose that we have already constructed the closed bounded interval 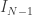 and see if we can find a closed subinterval
and see if we can find a closed subinterval  all of whose elements satisfy .
all of whose elements satisfy .
It would be nice to avoid the language of intervals, so let ![\null [a,b]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) be the interval . Our task is then to find real numbers
be the interval . Our task is then to find real numbers  and
and  such that
such that 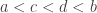 (that makes a subinterval) and such that for every with
(that makes a subinterval) and such that for every with 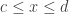 there exists such that (that makes every element of
there exists such that (that makes every element of 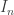 satisfy property ).
satisfy property ).
Before we attack this (by now not terribly hard) problem it feels as though we need to choose our . From string-matching we more or less know that will depend on (since the only lower bounds we have for values of are that there are arbitrarily large with 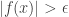 ). And here there is a very useful method that human mathematicians use all the time: just guess the simplest possible dependence and make adjustments if it doesn’t work. The simplest non-trivial dependence would be
). And here there is a very useful method that human mathematicians use all the time: just guess the simplest possible dependence and make adjustments if it doesn’t work. The simplest non-trivial dependence would be  , which turns out to work later if we “adjust” it to
, which turns out to work later if we “adjust” it to 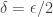 . Another method, again used by human mathematicians, is “let be a positive real number to be chosen later”. Here one sort of pretends to have chosen and as the proof proceeds one finds that must satisfy certain conditions for the argument to work. One then shows that these conditions can be satisfied. Let us adopt the latter approach here.
. Another method, again used by human mathematicians, is “let be a positive real number to be chosen later”. Here one sort of pretends to have chosen and as the proof proceeds one finds that must satisfy certain conditions for the argument to work. One then shows that these conditions can be satisfied. Let us adopt the latter approach here.
At this stage a computer may well not see its way to the end of the proof, but another thing it can certainly do is look about for places to apply the continuity hypothesis. And since there is only one thing we know about the values taken by (that they have modulus for arbitrarily large ), there is only one place we can apply this hypothesis.
To elaborate, we know that 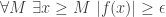 , and we also know that
, and we also know that  . To apply the second statement we must choose values for and
. To apply the second statement we must choose values for and  . The only real number we have around is (which depends on ) so let us choose to be . That gives us the statement
. The only real number we have around is (which depends on ) so let us choose to be . That gives us the statement 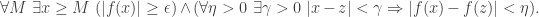
Rearranging this to bring the quantifiers as far as possible to the left, we obtain the equivalent statement 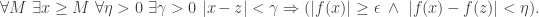
Now an applying-the-triangle-inequality module will leap into action and observe that from the final two inequalities it follows that 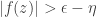 . The end of the conclusion we are trying to obtain is for some
. The end of the conclusion we are trying to obtain is for some 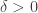 , so string-matching tells us that we would like
, so string-matching tells us that we would like 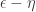 to be positive, and an elementary-inequality module will tell us that the simplest that is both positive and less than is
to be positive, and an elementary-inequality module will tell us that the simplest that is both positive and less than is 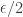 . So let us make this choice of , take to be , and see what we have when we put all the quantifiers back. We have
. So let us make this choice of , take to be , and see what we have when we put all the quantifiers back. We have  . (Incidentally, there should, strictly speaking, have been “
. (Incidentally, there should, strictly speaking, have been “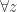 “s in some of the earlier statements, but it is quite common, if sloppy, to regard those as sort of implied by the symbol “
“s in some of the earlier statements, but it is quite common, if sloppy, to regard those as sort of implied by the symbol “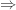 “.)
“.)
Now we observe that we are in a stronger position than before. Although is smaller than , all we knew about was that it was positive, and that’s all we know about . So from the perspective of proving the result, there is absolutely no loss in passing from to . (This is itself a useful principle that it would be quite good to make a bit more formal.) On the other hand, the range of values where  is at least has increased from a single arbitrarily large to an interval of arbitrarily large s.
is at least has increased from a single arbitrarily large to an interval of arbitrarily large s.
Suppose we have some and  such that
such that 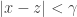 implies that
implies that 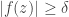 . String-matching tells us that we will be done if we can choose and and an integer such that and such that
. String-matching tells us that we will be done if we can choose and and an integer such that and such that  whenever
whenever 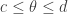 . Elementary manipulation of inequalities tells us that for this we need
. Elementary manipulation of inequalities tells us that for this we need 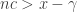 and
and 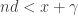 . Let us pretend that we have chosen . Then the Archimedean principle tells us that we can find with and a standard reflex tells us that if there exists such an then there exists a minimal one. So let be minimal such that . Can we now find with
. Let us pretend that we have chosen . Then the Archimedean principle tells us that we can find with and a standard reflex tells us that if there exists such an then there exists a minimal one. So let be minimal such that . Can we now find with 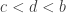 such that ? Obviously we can if and only if
such that ? Obviously we can if and only if  . Now we have not yet chosen , so let us try to choose and in such a way that
. Now we have not yet chosen , so let us try to choose and in such a way that 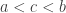 and
and  .
.
Let us focus first on choosing . If we have chosen then we will be able to find our if and only if  and
and 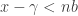 . Let us choose the minimal that satisfies the second inequality. Then
. Let us choose the minimal that satisfies the second inequality. Then 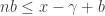 , so
, so 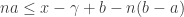 , so we are done if
, so we are done if 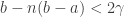 , for which we need to be at least
, for which we need to be at least 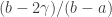 . We have the lower bound
. We have the lower bound 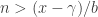 , and
, and  can be made arbitrarily large (because we may as well impose the bound
can be made arbitrarily large (because we may as well impose the bound  if it helps, which it does). Therefore, we can have our lower bound on .
if it helps, which it does). Therefore, we can have our lower bound on .
That argument can of course be very significantly tidied up. The basic idea is that every sufficiently large real number is a multiple of an element of 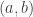 , since the intervals
, since the intervals 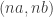 start to overlap when gets large. So if is sufficiently large then we can choose and with and
start to overlap when gets large. So if is sufficiently large then we can choose and with and 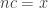 . (But the computer needs an extra idea to try for the stronger statement rather than the weaker statement .) Having chosen such a pair
. (But the computer needs an extra idea to try for the stronger statement rather than the weaker statement .) Having chosen such a pair 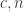 we can easily choose in such a way that and .
we can easily choose in such a way that and .
If you agree that the above account does demonstrate that the proof can be generated in a fairly automatic way from a rather small and simple set of precise problem-solving techniques in real analysis, then there are two possible reactions. One would be to say that the proof is less deep than it looks, and only appears deep in its usual presentation because the Baire category theorem is used as a piece of magic (which we might refer to as the “insight” of certain mathematicians from around a century ago). Another would be to search for differences between the way the second proof is generated and the way the first one is. And a definite difference is that the second involves a process of construction: of the nested closed intervals . The fact that we just went ahead and did the construction in a fairly automatic way does place some upper bound on the depth, and it is perhaps the automatic nature of this stage of the proof that encourages one to abstract out what has been done and formulate the Baire category theorem.
Let me be more precise about the difference. At times during both proofs we needed to find real numbers with certain properties. However, only in the second proof did we need to find a real number with an infinite sequence of properties, which resulted from the fact that the string of quantifiers in the statement we wished to prove had “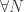 ” after the “
” after the “ “. In order to find the real number with infinitely many properties, we converted the problem into one about constructing a sequence, which then meant that we were back in the world of finding real numbers with just finitely many properties.
“. In order to find the real number with infinitely many properties, we converted the problem into one about constructing a sequence, which then meant that we were back in the world of finding real numbers with just finitely many properties.
I’ll end with a brief remark that I hope to elaborate on in a future post. It seems that a significant challenge for an automatic theorem prover is to deal with statements that do not have uniquely obvious proofs. (This of course relates to my earlier post on when two proofs are the same.) And this non-uniqueness often arises when a construction is involved. If one is asked to construct a mathematical object, one can sometimes create an artificial uniqueness by imposing extra properties on what one is constructing, or restrictions on how one goes about constructing it (such as always trying the simplest thing first, whatever that may mean in the given context). But it is not always easy.
To illustrate this, here is a simple problem where the non-uniqueness seems to create difficulties for a computer: find an injection from 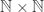 to
to  . In a later post I shall discuss this example, but for now let me just try to explain why it is difficult. The reason is that if you want to approach it systematically, then you need to choose values of the function for each pair of integers
. In a later post I shall discuss this example, but for now let me just try to explain why it is difficult. The reason is that if you want to approach it systematically, then you need to choose values of the function for each pair of integers 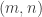 in turn. But what does “in turn” mean? It seems to require you to put the pairs in order, and that is rather close to what you were asked to do in the first place. (However, “rather close” turns out not to mean “identical”.) I mention this problem here just to suggest in a tentative way that non-uniqueness of this kind may also be a major contributor to our perceptions of depth in mathematics.
in turn. But what does “in turn” mean? It seems to require you to put the pairs in order, and that is rather close to what you were asked to do in the first place. (However, “rather close” turns out not to mean “identical”.) I mention this problem here just to suggest in a tentative way that non-uniqueness of this kind may also be a major contributor to our perceptions of depth in mathematics.
This entry was posted on July 25, 2008 at 12:54 pm and is filed under Demystifying proofs, Somewhat philosophical. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

July 25, 2008 at 4:21 pm |
“Suppose we have some x and \gamma such that |x-z|<\gamma implies that |f(x)|\geq\delta.”
Don’t you mean:
“Suppose we have some x and \gamma such that |x-z|<\gamma implies that |f(z)|\geq\delta.”?
[Thank you very much — error now corrected.]
July 25, 2008 at 5:10 pm |
For the “difficult” analysis problem, perhaps I am not understanding the problem, but isn’t there a much simpler solution? Why does the computer have to follow a circuitous route? what’s wrong with this sort of solution (perhaps I don’t fully understand the problem): construct a collection of intervals I_n = { [p/n,(p+1)/n) | p is a natural number }, and then state that for any positive real number z is contained in some interval in I_n, since {p| p <= zn } has a least upper bound, which may be written as p, then zn<p+1 hence z is contained in [p/n,(p+1)/n). Then for any epsilon greater than zero, we can just choose a big N that’s greater than 2 divided by epsilon (using the Archimedean property), and then 1/N 0 such that f(m/N) M. Then we would have any x> (M+1)/N, we have x is contained in some [p/N,(p+1)/N) and that p > M, and since the length of the interval is less than epsilon/2 (by construction) we have, by the triangle inequality:
|f(x)|=|f(x)-p/N+p/N| <= |f(x)-p/N|+|p/N| < epsilon
Thus the statement is proven.
Why would a computer miss out on that proof? (unless it is wrong, in which case never mind).
July 25, 2008 at 5:19 pm |
For what accepted value of ‘many years ago’ could you have had a web page?
July 25, 2008 at 6:08 pm |
This is an excellent and deep article – don’t see too much of these on the Internet. It is a shame that people dont pay much attention to maths anymore.
July 25, 2008 at 9:26 pm |
Dear Jo: It appears that wordpress is eating some of your < and > signs (it sometimes interprets them as HTML tags), making your argument rather hard to decipher. You might want to use < or > instead (or enter latex mode and use \leq and \geq instead.)
Another way to view why the second statement is significantly harder than the first is that it has to use much more of the structure of the real line (and in particular, its completeness) than the first statement. The first statement works for any metric space, and so there are a very small number of inputs (the metric space axioms) that a computer would have to experiment with to find a proof; the second statement requires the field and completeness properties of the reals, and possibly also the order property as well (does the statement hold over the complex numbers, or the p-adics?); the statement fails for instance for the rationals (take a continuous function which is mostly zero except when very close to a multiple of some fixed Diophantine number, e.g. the golden ratio, at which point it spikes up to equal 1).
July 25, 2008 at 9:31 pm |
I suggest you check out the coq theorem prover http://coq.inria.fr
Its one of the strongest computerized theorem proving tools currently in use, and in fact and in fact has an approach to representing proofs which means you can’t distinguish between two proofs of the same result if all that you are given is the proof object rather than the script which constructed it.
July 26, 2008 at 2:22 am |
I would love to see that proof. The obvious one uses the Axiom of Choice and as such I don’t think qualifies as “doable-in-principle-by-computer”. The only one I know that does not use the axiom of choice is even worse – involves constructing a choice function for subsets of rational numbers.
July 26, 2008 at 8:58 pm |
Tao: “does the statement hold over the complex numbers”
I am not sure what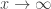 means when x is complex, but isn’t
means when x is complex, but isn’t  a counterexample?
a counterexample?
However, if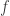 is a continuos function and for every complex
is a continuos function and for every complex 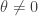 and every sequence
and every sequence  of gaussian integers such that
of gaussian integers such that 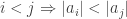 the sequence
the sequence 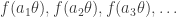 tends to 0,
tends to 0, 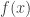 tends to 0 as
tends to 0 as 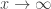 . This can be proven in the same way as the original statement, you just have to prove that for any open subset S of complex numbers any sufficiently large complex number z can be written as a gaussian integer times an element in S. And S must contain a disk and the disks obtained by multiplying this disk by the gaussian integers must overlap, because their centers form a grid, but their radii are proportional to the distance from 0.
. This can be proven in the same way as the original statement, you just have to prove that for any open subset S of complex numbers any sufficiently large complex number z can be written as a gaussian integer times an element in S. And S must contain a disk and the disks obtained by multiplying this disk by the gaussian integers must overlap, because their centers form a grid, but their radii are proportional to the distance from 0.
July 28, 2008 at 11:53 am |
[…] Tim Gowers: What is deep mathematics? […]
July 28, 2008 at 12:20 pm |
It seems like it would be hard for a computer to come up with the proof using the Baire Category theorem. By setting $E_n = \{x\geq 1:|f(nx)|\leq\varepsilon\}$ and letting $F_n = \cap_{k\geq n} E_k$, we get that $\cup_{k\geq 1} F_k = [1,\infty)$, and hence (by BCT) some $F_j$ contains an interval $[s,t]$. So $|f(\ell x)|\leq\varepsilon$ for all $\ell\geq j$ and $x\in [s,t]$, or $|f|\leq\varepsilon$ on $[\ell s,\ell t]$ for all $\ell\geq j$. This is fairly straightforward.
Of course, we want to show that this implies that $|f(x)|\leq \varepsilon$ for all sufficiently large $x$, but it’s not immediately obvious to me that this is true. The insight, I guess, is that the left endpoint of $[\ell s,\ell t]$ is only ‘moving’ at a constant speed, whereas the length of $[\ell s,\ell t]$ is increasing linearly in $\ell$, so as soon as $L$ is large enough that the length of $[Ls,Lt]$ is at least $s$, there are no more gaps — that is, the union of $[\ell s,\ell t]$ over $\ell\geq L$ is $[Ls,\infty)$, and hence $|f(x)|\leq\varepsilon$ for $x\geq Ls$. This seems like a tricky thing for a computer to get.
Then again, maybe it can just solve for the smallest $\ell$ such that $\ell t > (m+1) s$ (by looking for the smallest $\ell$ for which the right endpoint of one interval lies to the right of the left endpoint of the next interval), and noting that the inequality holds for all larger $\ell$ (since $t>s$)
July 28, 2008 at 12:21 pm |
First of all, it’s a long time since I proved anything so I may be
wrong. Secondly, the markup is probably going to be terrible, there
seems to be no preview button and I can’t find wordpress’s help
section for markup. Finally, apologies if this is straying too far
from the original idea of proof automation but I think this answers
the question of whether this is true for Complex also. I can’t really
claim that this proof is discoverable by pattern matching as it’s not
really an epsilon-delta proof. That said, if I haven’t made a mistake,
the problem becomes “easy” if you consider a compactification of R and
maybe looking at compactifications is a reasonable strategy for
theorem provers.
Anyway, I think you can capture all of the fiddly parts and the proof-by-contradiction inside the Heine-Borel Theorem instead of using the Baire Category Theorem, which seems to be a bit more heavy-weight.
The essence is to show that for any δ > 0, there is a single
Nδ such that |f(nX)| Nδ. The conclusion follows from the fact that
any Real > Nδ is something in [0,1] times an integer
at least as big as N and therefore |f| will be < δ for this Real
too.
Let X ∈ Real. We are given that f(nX) -> 0 as n ->
∞. More formally, ∀ δ > 0, ∀ X ∈ Real,
∃ Nδ,X ∈ Natural such that |f(nX)| <
δ ∀ n > Nδ,X. Since f(X) is continuous
there is an open set, Oδ,X containing X such that
|f(Nδ,X y)| < δ ∀ y ∈
Oδ,X (it is the inverse image of (-δ,
δ)).
For a fixed δ, {Oδ,X: X ∈ [0,1]} gives
us an open cover of [0,1] and Heine-Borel tells us that there is a
finite subcover. This means we have a finite set of
Oδ,X, each with an Nδ,X and we can
take the maximum Nδ,X and call it
Nδ. This is a Natural such that |f(nX)| Nδ.
Now let X ∈ Real, X > Nδ. Let N = [X]+1,
where [] is the greatest integer function and let θ = X/N. Note
that θ ∈ [0,1] and N > Nδ. So
|f(Nθ)| < δ. That is, |f(X)| < δ.
So all you need is the compactness of [0,1] and the fact that you
can generate all of Real+ from [0,1] and multiplication by Natural. So
it seems that is true for Complex or RealN etc. where
you take x -> ∞ to mean |x| -> ∞ and you use [-1,1]
instead of [0,1].
If Real itself was compact you could skip the scaling step
entirely. I think rephrasing the question in terms of Real &union;
{-∞ ∞} makes it almost trivial but I must admit I’m going
beyond what I can remember from my student days, I expect someone will
tell me that rephrasing it like that causes something else to break.
I think it would be reasonable for a theorem prover to start by
choosing a δ to aim for and use continuity to construct the
cover of Real from the inverse images of (-δ, -δ). It
would get stuck then and I don’t know whether there is a reasonable
automated bridge to the solution from there.
July 28, 2008 at 12:37 pm |
Yuck, a less mangled version of my comment is available on on my blog.
July 31, 2008 at 11:34 am |
I have deleted what used to be the previous three comments, having been asked to do so by their author. (In general, my policy is to amend comments in small ways if the author would obviously approve of my doing so, and if I delete one there has to be a good reason for it. Disagreeing with the commenter is an insufficient reason. Incidentally, if you follow the link to Fergal Daly’s blog you will see my response to his comment.)
July 31, 2008 at 3:00 pm |
My “proof” was incorrect and in fact, thinking about it a bit more,
it’s kind of obvious that there is no way to constrain all such
functions on any particular interval because for any given interval, I
can produce a function that is not constrained on that interval but
behaves well from then onwards.
As you said, completeness seems to be required. You can produce a
continuous function from Rational->Rational that has the n, 2n, 3n
property but not the -> 0 property. For example,
g(x) = 1/(x^2 – 1/2) + 2 for 0 < x < sqrt(1/2)
g(x) = 1/(x^2 – 1/2) – 2 for sqrt(1/2) < x <= 1
h(x) = g(x – [x])
f(x) = h(x) / x
is 0 on whole numbers but spikes to infinity at whole numbers +
sqrt(2). For any x ∈ Rational, h(nx) cycles through a finite
number of values for n ∈ Natural and so f(nx) -> 0 but f does not
-> 0
August 5, 2008 at 6:31 pm |
It doesn’t seem particularly deep to me, I’m afraid. Is there something wrong with the following proof? Dijkstra-esque notation, I’m afraid: f.x is f applied to x, ‘x -{a->b}-> y’ is ‘lim(a->b) x = y’. The lines enclosed in { } are comments. The ‘=’ between lines is logical equivalence.
f.x -{x->inf}-> 0
= { definition of limits over real numbers }
(forall y : y.n -{n->inf}-> inf : f.y.n -{n->inf}-> 0 )
= { with T > 0, define q := y/T >
(forall y : T * q.n -{n->inf}->inf : f.(T * q.n) -{n->inf}-> 0 )
= { T * q.n -{n->inf}->inf /\ T > 0 == q.n -{n->inf}-> inf }
(forall y : q.n -{n->inf}-> inf : f.(T * q.n) -{n->inf}-> 0)
inf}-> 0
where that last connective is logical implication backwards, ‘comes from.’ It requires a few theorems about limits that should be part of every basic calculus course.
Where’s the Baire category theorem? And this is probably a computer findable proof. I wrote it down almost without pausing after one false start.
August 5, 2008 at 6:45 pm |
I withdraw the above proof. I miswrote the implication in the last line. It’s in the other direction.
August 5, 2008 at 7:13 pm |
Alright, sorry to spam, but if theta takes values in the positive reals, isn’t this trivial, namely f is 0 for all positive values?
(forall theta : theta > 0 : lim_{n->infty} f.(theta*n) = 0)
= { definition of limit }
(forall theta : theta > 0 : (forall e : e > 0 : (exists N : N>0 : (forall n : n>=N : |f.(theta*n)| 0 : (forall N : N>0 : (forall theta,n : theta > 0 /\ n>=N : |f.(theta*n)|0 : (forall N : N>0 : (forall T : T>0 : |f.T|0 : (forall T : T>0 : |f.T|0 : |f.T| = 0)
If theta takes on rationals, you can get here by using continuity of the function. If theta takes on integers, you can’t make even the proof you wanted go: the grain’s too coarse.
I’ll probably think of a reason why this is wrong in half an hour and spam you some more. Feel free to delete everything you want.
August 5, 2008 at 7:18 pm |
I did. N is a function of theta, so I can’t switch the quantifiers. I’ll go away now.
August 8, 2008 at 11:02 pm |
Surely this is the type of problem that screams out for an application of the Baire category theorem? One wants to convert a pointwise statement about continuous functions into a uniform one (in an appropriate sense), something Baire category does nicely. This sort of intuition can be reduced to a sort of pattern matching, and then maybe it is not too hard to imagine a computer recognising that Baire might be useful.
August 10, 2008 at 11:19 am |
B.J. I completely agree, and that’s what I was hinting at in what I said. I said “interesting” because it interests me that students often find applying the Baire category theorem quite difficult even when it looks as though it should be quite easy to automate. As for the pointwise-to-uniform matter, I think this is interestingly connected with depth: it seems that in elementary real analysis there’s a first level of statements that can be proved by pure pattern matching, and there’s a second level that can be proved automatically but with rather more effort. And these second-level statements often have some point where one wants to go from a pointwise statement to a uniform one. For instance, the statement that a continuous function on![\null [0,1]](https://s0.wp.com/latex.php?latex=%5Cnull+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is bounded is a simple example of this. And then one somehow isolates a few key principles for proving such statements (Baire category, compactness, etc.) and relative to these key principles the second-level become mere pattern-matching exercises again. Of course this process happens all over mathematics and not just in real analysis, but it can be seen particularly clearly in real analysis, which is why I like it as a source of examples.
is bounded is a simple example of this. And then one somehow isolates a few key principles for proving such statements (Baire category, compactness, etc.) and relative to these key principles the second-level become mere pattern-matching exercises again. Of course this process happens all over mathematics and not just in real analysis, but it can be seen particularly clearly in real analysis, which is why I like it as a source of examples.
August 16, 2008 at 1:09 am |
Terence,
If you take a straightforward p-adic translation of the second statement, it seems to collapse, since the set is dense for x a unit in
is dense for x a unit in 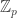 . This forces the continuous function to be identically zero, independently of whatever analogue of “x goes to infinity” we choose.
. This forces the continuous function to be identically zero, independently of whatever analogue of “x goes to infinity” we choose.
One interesting translation is to determine if the pointwise condition that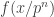 approaches zero as n increases implies the uniform condition that the continuous function f on
approaches zero as n increases implies the uniform condition that the continuous function f on  uniformly approaches zero as the absolute value of x gets large. This seems to be a precise analogue of the Archimedean problem, where we replace nx with something like
uniformly approaches zero as the absolute value of x gets large. This seems to be a precise analogue of the Archimedean problem, where we replace nx with something like 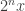 . The step where the open sets (na,nb) are supposed to overlap fails, but I think you can use an argument involving compactness of multiplicative quotients together with e.g. Dini’s theorem.
. The step where the open sets (na,nb) are supposed to overlap fails, but I think you can use an argument involving compactness of multiplicative quotients together with e.g. Dini’s theorem.
August 16, 2008 at 4:00 am |
Upon further reflection, I think we need the following ingredients: a topological abelian group G (in our case, the units in a field), a continuous “absolute value” homomorphism from G to a totally ordered group H, a cocompact subgroup K of G isomorphic to the integers, that maps injectively to H, and a continuous function f on G with the property that for any element in G, translating by K in a fixed direction (order here is induced by H) will cause f to tend toward zero. Then we can conclude that f uniformly goes to zero as absolute value passes in that direction. In the case that H/K is not both connected and non-simply-connected, the proof comes straight from Dini’s theorem applied to a sup function on G/K. Otherwise, we have to do some fiddling with boundaries. I had attempted to let the isomorphism type of K vary, but it seems essential that K have well-ordered “ends”, and this restricts our choice of fields to a small family, namely the locally compact ones.
I think one could in principle program a computer to ignore some of the data in the problem and focus on multiplicative rather than additive structure, but a step-by-step decomposition of the process escapes me. I didn’t think of doing so until I saw Tao’s comment and attempted a p-adic translation.
August 18, 2008 at 12:18 pm |
[…] mathematics deep. This is, of course, not a new issue and has been dicussed many times before. I suppose this is more an issue of semantics than philosophy, but this is certainly one place the […]
December 14, 2008 at 8:10 pm |
[…] of the Notices of the AMS was devoted to formal proofs and related software tools. Gowers describes here and here what such a computer-assisted theorem-proving might look […]
January 26, 2009 at 4:35 pm |
[…] That’s just one blogger. There are, of course, many other top-notch mathematician bloggers. Cambridge’s Tim Gowers, another Fields Medallist, also runs a blog. Like Tao’s blog, it’s filled with interesting mathematical insights and conversation, on topics like how to use Zorn’s lemma, dimension arguments in combinatorics, and a thought-provoking post on what makes some mathematics particularly deep. […]
July 26, 2009 at 1:52 pm |
[…] f(4a), … tiến tới 0. CMR f(x) tiến tới 0 khi x tiến tới dương vô cùng. (Xem https://gowers.wordpress.com/2008/07/25/what-is-deep-mathematics/). Bài toán trên không đòi hỏi kiến thức gì quá cao (học sinh cuối PTTH có thể […]
August 14, 2009 at 4:36 am |
[…] f(4a), … tiến tới 0. CMR f(x) tiến tới 0 khi x tiến tới dương vô cùng. (Xem https://gowers.wordpress.com/2008/07/25/what-is-deep-mathematics/). Bài toán trên không đòi hỏi kiến thức gì quá cao (học sinh cuối PTTH có thể […]
September 11, 2009 at 10:45 pm |
Mate – you are about to get a billion hits!
Derren Brown just did a special on predicting the lottery and mentioned the theory behind it being ‘deep maths’. You are the #1 google search result for this 🙂
September 12, 2009 at 10:27 pm |
This could have been easily explained as the average of averages, no complicated mathematics and functions and substitutions.
Derren didn’t do anything fantastic, he took 6 people asked them to predict 6 numbers, took another 6 and asked them to predict 6 numbers and so on, a total of 24 people, then the numbers were averaged out to give a final of 6 numbers. See? No messy formulas, My IQ is 2389, beat that Mr. clever-maths-formula guy
September 12, 2009 at 11:30 pm
It doesn’t matter what the details are — mathematics, whether deep or not, didn’t help him predict the lottery. Also, something’s odd about your account: what happened after the first four numbers had been predicted?
September 13, 2009 at 10:49 am |
I agree, it doesn’t matter what the details are, he NEVER predicted the lottery, my post was purely sarcastic. You cannot correctly predict a variable accurately, especially 6 variables.
Derren is a fake, he predicted nothing! Here’s my explanation how he displayed the correct lottery numbers:
1.) Film the show in an EMPTY studio so that you can manipulate camera angles, split screens and more visual effects. If you can “predict” 6 totally random numbers correctly, then how come there were NO live studio audience to bear witness to this amazing miracle with their own eyes.
2.) Derren should have displayed HIS numbers BEFORE the lottery started. Anyone can claim to have predicted something correctly AFTER the results are known. If Derren displayed his selection before the lottery numbers were selected then that would have been believable. Of course he gets out of this by claiming that it’s illegal to display his numbers before the lottery selection.
Without the above, there is just no proof of Derren correctly predicting the numbers.
September 13, 2009 at 8:32 pm
Of course he didn’t predict the numbers, but it still made great television and that is all he aimed to do.
January 25, 2015 at 9:28 pm |
What qualifies as deep mathematics? There might be a lot of answers to this one, I think my favorite is: deep mathematics is when making something very hard look very simple. Or put another way, making something complicated into something trivial. Once the result is obtained it is not that difficult to automate that particular result and others like it, this is what most students do when preparing for exams. The difficulty in obtaining new deep results lie in the fact that you need to think very hard about how to think correctly about your problem. The examples given here already presuppose the foundations being laid, hence the possibility of automating the proofs. The convergence theorems are considered exercises because we have the right definitions to work with. The really interesting question is not whether we can automate computers into proving things in an already axiomatized setting (the answer is obviously yes, albeit this might be a difficult task in practice), but rather how to make the computer come up with the correct way of viewing things in a certain problem. I shall not expand on this issue here, but would love to hear some future comments about this
March 29, 2022 at 10:04 pm |
[…] Here is an elementary proof inspired by this proof. […]
April 3, 2022 at 4:26 pm |
[…] P.S. For a proof without Baire Category Theorem see Gowers’s Weblog […]