I am very happy to say that I have recently received a generous grant from the Astera Institute to set up a small group to work on automatic theorem proving, in the first instance for about three years after which we will take stock and see whether it is worth continuing. This will enable me to take on up to about three PhD students and two postdocs over the next couple of years. I am imagining that two of the PhD students will start next October and that at least one of the postdocs will start as soon as is convenient for them. Before any of these positions are advertised, I welcome any informal expressions of interest: in the first instance you should email me, and maybe I will set up Zoom meetings. (I have no idea what the level of demand is likely to be, so exactly how I respond to emails of this kind will depend on how many of them there are.)
I have privately let a few people know about this, and as a result I know of a handful of people who are already in Cambridge and are keen to participate. So I am expecting the core team working on the project to consist of 6-10 people. But I also plan to work in as open a way as possible, in the hope that people who want to can participate in the project remotely even if they are not part of the group that is based physically in Cambridge. Thus, part of the plan is to report regularly and publicly on what we are thinking about, what problems, both technical and more fundamental, are holding us up, and what progress we make. Also, my plan at this stage is that any software associated with the project will be open source, and that if people want to use ideas generated by the project to incorporate into their own theorem-proving programs, I will very much welcome that.
I have written a 54-page document that explains in considerable detail what the aims and approach of the project will be. I would urge anyone who thinks they might want to apply for one of the positions to read it first — not necessarily every single page, but enough to get a proper understanding of what the project is about. Here I will explain much more briefly what it will be trying to do, and what will set it apart from various other enterprises that are going on at the moment.
In brief, the approach taken will be what is often referred to as a GOFAI approach, where GOFAI stands for “good old-fashioned artificial intelligence”. Roughly speaking, the GOFAI approach to artificial intelligence is to try to understand as well as possible how humans achieve a particular task, and eventually reach a level of understanding that enables one to program a computer to do the same.
As the phrase “old-fashioned” suggests, GOFAI has fallen out of favour in recent years, and some of the reasons for that are good ones. One reason is that after initial optimism, progress with that approach stalled in many domains of AI. Another is that with the rise of machine learning it has become clear that for many tasks, especially pattern-recognition tasks, it is possible to program a computer to do them very well without having a good understanding of how humans do them. For example, we may find it very difficult to write down a set of rules that distinguishes between an array of pixels that represents a dog and an array of pixels that represents a cat, but we can still train a neural network to do the job.
However, while machine learning has made huge strides in many domains, it still has several areas of weakness that are very important when one is doing mathematics. Here are a few of them.
- In general, tasks that involve reasoning in an essential way.
- Learning to do one task and then using that ability to do another.
- Learning based on just a small number of examples.
- Common sense reasoning.
- Anything that involves genuine understanding (even if it may be hard to give a precise definition of what understanding is) as opposed to sophisticated mimicry.
Obviously, researchers in machine learning are working in all these areas, and there may well be progress over the next few years [in fact, there has been progress on some of these difficulties already of which I was unaware — see some of the comments below], but for the time being there are still significant limitations to what machine learning can do. (Two people who have written very interestingly on these limitations are Melanie Mitchell and François Chollet.)
That said, using machine learning techniques in automatic theorem proving is a very active area of research at the moment. (Two names you might like to look up if you want to find out about this area are Christian Szegedy and Josef Urban.) The project I am starting will not be a machine-learning project, but I think there is plenty of potential for combining machine learning with GOFAI ideas — for example, one might use GOFAI to reduce the options for what the computer will do next to a small set and use machine learning to choose the option out of that small set — so I do not rule out some kind of wider collaboration once the project has got going.
Another area that is thriving at the moment is formalization. Over the last few years, several major theorems and definitions have been fully formalized that would have previously seemed out of reach — examples include Gödel’s theorem, the four-colour theorem, Hales’s proof of the Kepler conjecture, Thompson’s odd-order theorem, and a lemma of Dustin Clausen and Peter Scholze with a proof that was too complicated for them to be able to feel fully confident that it was correct. That last formalization was carried out in Lean by a team led by Johan Commelin, which is part of the more general and exciting Lean group that grew out of Kevin Buzzard‘s decision a few years ago to incorporate Lean formalization into his teaching at Imperial College London.
As with machine learning, I mention formalization in order to contrast it with the project I am announcing here. It may seem slightly negative to focus on what it will not be doing, but I feel it is important, because I do not want to attract applications from people who have an incorrect picture of what they would be doing. Also as with machine learning, I would welcome and even expect collaboration with the Lean group. For us it would be potentially very interesting to make use of the Lean database of results, and it would also be nice (even if not essential) to have output that is formalized using a standard system. And we might be able to contribute to the Lean enterprise by creating code that performs steps automatically that are currently done by hand. A very interesting looking new institute, the Hoskinson Center for Formal Mathematics, has recently been set up with Jeremy Avigad at the helm, which will almost certainly make such collaborations easier.
But now let me turn to the kinds of things I hope this project will do.
Why is mathematics easy?
Ever since Turing, we have known that there is no algorithm that will take as input a mathematical statement and output a proof if the statement has a proof or the words “this statement does not have a proof” otherwise. (If such an algorithm existed, one could feed it statements of the form “algorithm A halts” and the halting problem would be solved.) If 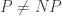
The broad answer is that while the theoretical results just alluded to show that we cannot expect to determine the proof status of arbitrary mathematical statements, that is not what we try to do. Rather, we look at only a tiny fraction of well-formed statements, and the kinds of proofs we find tend to have a lot more structure than is guaranteed by the formal definition of a proof as a sequence of statements, each of which is either an initial assumption or follows in a simple way from earlier statements. (It is interesting to speculate about whether there are, out there, utterly bizarre and idea-free proofs that just happen to establish concise mathematical statements but that will never be discovered because searching for them would take too long.) A good way of thinking about this project is that it will be focused on the following question.
Question. What is it about the proofs that mathematicians actually find that makes them findable in a reasonable amount of time?
Clearly, a good answer to this question would be extremely useful for the purposes of writing automatic theorem proving programs. Equally, any advances in a GOFAI approach to writing automatic theorem proving programs have the potential to feed into an answer to the question. I don’t have strong views about the right balance between the theoretical and practical sides of the project, but I do feel strongly that both sides should be major components of it.
The practical side of the project will, at least to start with, be focused on devising algorithms that find proofs in a way that imitates as closely as possible how humans find them. One important aspect of this is that I will not be satisfied with programs that find proofs after carrying out large searches, even if those searches are small enough to be feasible. More precisely, searches will be strongly discouraged unless human mathematicians would also need to do them. A question that is closely related to the question above is the following, which all researchers in automatic theorem proving have to grapple with.
Question. Humans seem to be able to find proofs with a remarkably small amount of backtracking. How do they prune the search tree to such an extent?
Allowing a program to carry out searches of “silly” options that humans would never do is running away from this absolutely central question.
With Mohan Ganesalingam, Ed Ayers and Bhavik Mehta (but not simultaneously), I have over the years worked on writing theorem-proving programs with as little search as possible. This will provide a starting point for the project. One of the reasons I am excited to have the chance to set up a group is that I have felt for a long time that with more people working on the project, there is a chance of much more rapid progress — I think the progress will scale up more than linearly in the number of people, at least up to a certain size. And if others were involved round the world, I don’t think it is unreasonable to hope that within a few years there could be theorem-proving programs that were genuinely useful — not necessarily at a research level but at least at the level of a first-year undergraduate. (To be useful a program does not have to be able to solve every problem put in front of it: even a program that could solve only fairly easy problems but in a sufficiently human way that it could explain how it came up with its proofs could be a very valuable educational tool.)
A more distant dream is of course to get automatic theorem provers to the point where they can solve genuinely difficult problems. Something else that I would like to see coming out of this project is a serious study of how humans do this. From time to time I have looked at specific proofs that appear to require at a certain point an idea that comes out of nowhere, and after thinking very hard about them I have eventually managed to present a plausible account of how somebody might have had the idea, which I think of as a “justified proof”. I would love it if there were a large collection of such accounts, and I have it in mind as a possible idea to set up (with help) a repository for them, though I would need to think rather hard about how best to do it. One of the difficulties is that whereas there is widespread agreement about what constitutes a proof, there is not such a clear consensus about what constitutes a convincing explanation of where an idea comes from. Another theoretical problem that interests me a lot is the following.
Problem. Come up with a precise definition of a “proof justification”.
Though I do not have a satisfactory definition, very recently I have had some ideas that will I think help to narrow down the search substantially. I am writing these ideas down and hope to make them public soon.
Who am I looking for?
There is much more I could say about the project, but if this whets your appetite, then I refer you to the document where I have said much more about it. For the rest of this post I will say a little bit more about the kind of person I am looking for and how a typical week might be spent.
The most important quality I am looking for in an applicant for a PhD or postdoc associated with this project is a genuine enthusiasm for the GOFAI approach briefly outlined here and explained in more detail in the much longer document. If you read that document and think that that is the kind of work you would love to do and would be capable of doing, then that is a very good sign. Throughout the document I give indications of things that I don’t yet know how to do. If you find yourself immediately drawn into thinking about those problems, which range from small technical problems to big theoretical questions such as the ones mentioned above, then that is even better. And if you are not fully satisfied with a proof unless you can see why it was natural for somebody to think of it, then that is better still.
I would expect a significant proportion of people reading the document to have an instinctive reaction that the way I propose to attack the problems is not the best way, and that surely one should use some other technique — machine learning, large search, the Knuth-Bendix algorithm, a computer algebra package, etc. etc. — instead. If that is your reaction, then the project probably isn’t a good fit for you, as the GOFAI approach is what it is all about.
As far as qualifications are concerned, I think the ideal candidate is somebody with plenty of experience of solving mathematical problems (either challenging undergraduate-level problems for a PhD candidate or research-level problems for a postdoc candidate), and good programming ability. But if I had to choose one of the two, I would pick the former over the latter, provided that I could be convinced that a candidate had a deep understanding of what a well-designed algorithm would look like. (I myself am not a fluent programmer — I have some experience of Haskell and Python and I think a pretty good feel for how to specify an algorithm in a way that makes it implementable by somebody who is a quick coder, and in my collaborations so far have relied on my collaborators to do the coding.) Part of the reason for that is that I hope that if one of the outputs of the group is detailed algorithm designs, then there will be remote participants who would enjoy turning those designs into code.
How will the work be organized?
The core group is meant to be a genuine team rather than simply a group of a few individuals with a common interest in automatic theorem proving. To this end, I plan that the members of the group will meet regularly — I imagine something like twice a week for at least two hours and possibly more — and will keep in close contact, and very likely meet less formally outside those meetings. The purpose of the meetings will be to keep the project appropriately focused. That is not to say that all team members will work on the same narrow aspect of the problem at the same time. However, I think that with a project like this it will be beneficial (i) to share ideas frequently, (ii) to keep thinking strategically about how to get the maximum expected benefit for the effort put in , and (iii) to keep updating our public list of open questions (which will not be open questions in the usual mathematical sense, but questions more like “How should a computer do this?” or “Why is it so obvious to a human mathematician that this would be a silly thing to try?”).
In order to make it easy for people to participate remotely, I think probably we will want to set up a dedicated website where people can post thoughts, links to code, questions, and so on. Some thought will clearly need to go into how best to design such a site, and help may be needed to build it, which if necessary I could pay for. Another possibility would of course be to have Zoom meetings, but whether or not I would want to do that depends somewhat on who ends up participating and how they do so.
Since the early days of Polymath I have become much more conscious that merely stating that a project is open to anybody who wishes to join in does not automatically make it so. For example, whereas I myself am comfortable with publicly suggesting a mathematical idea that turns out on further reflection to be fruitless or even wrong, many people are, for very good reasons, not willing to do so, and those people belong disproportionately to groups that have been historically marginalized from mathematics — which of course is not a coincidence. Because of this, I have not yet decided on the details of how remote participation might work. Maybe part of it could be fully open in the way that Polymath was, but part of it could be more private and carefully moderated. Or perhaps separate groups could be set up that communicated regularly with the Cambridge group. There are many possibilities, but which ones would work best depends on who is interested. If you are interested in the project but would feel excluded by certain modes of participation, then please get in touch with me and we can think about what would work for you.

April 28, 2022 at 11:22 am |
I would like to briefly comment on the 5 points you make about what you consider limitation of AI
2 & 3. Transfer learning has become quite common where the learning for one task is used for another. The principle here is that a lot of the learning is a “nice semantic representation” of a domain (e.g. mathematics) including compositions. This transfers to another task. It also means that sometimes the second task can be learnt with very few examples.
1, 4 & 5. To some extent a semantic internal representation with compositions can be considered understanding. Beyond this, these are simply ill-defined subjective notions, which historically have changed as AI has managed these – something is described as needing genuine understanding, and then described as being purely mechanical once AI solves it.
April 28, 2022 at 11:23 am
I made this anonymously by accident so copied it below. My apologies.
April 28, 2022 at 11:23 am |
I would like to briefly comment on the 5 points you make about what you consider limitation of AI
2 & 3. Transfer learning has become quite common where the learning for one task is used for another. The principle here is that a lot of the learning is a “nice semantic representation” of a domain (e.g. mathematics) including compositions. This transfers to another task. It also means that sometimes the second task can be learnt with very few examples.
1, 4 & 5. To some extent a semantic internal representation with compositions can be considered understanding. Beyond this, these are simply ill-defined subjective notions, which historically have changed as AI has managed these – something is described as needing genuine understanding, and then described as being purely mechanical once AI solves it.
April 28, 2022 at 11:51 am |
[…] Article URL: https://gowers.wordpress.com/2022/04/28/announcing-an-automatic-theorem-proving-project/ […]
April 28, 2022 at 12:03 pm |
Echoing Siddhartha Gadgil on points 2 & 3: there has been a major change in transfer learning the past few years. It is now common for models to train unsupervised to solve one problem, and then to be able to transfer that understanding to many other downstream problems, with a very small number of examples. An overview that I found eye-opening is here: https://arxiv.org/abs/2108.07258
April 28, 2022 at 1:05 pm |
A small correction: it would be fairer to say that the Liquid Tensor Experiment project is led by Johan Commelin rather than Kevin Buzzard.
April 28, 2022 at 5:09 pm
Yes, I worded that badly. What I meant was that Kevin Buzzard is the person who got the Lean group going, but I absolutely agree that Johan Commelin led the Liquid Tensor Experiment. I will reword to make that clearer.
April 28, 2022 at 1:42 pm |
This is something I have been very interested in, however my commitments at work and present lack of mathematical ability means it’s something longer term for me. I would love to participate and hear what you and the group are doing and am happy to help out with administrative tasks like maintaining the website, and other technical matters.
I watched your speech on youtube a couple of years back, glad to hear you are still doing the project and congratulations on the grant.
Please let me know if there is scope to be a silent observer / admin assistant or the like
April 28, 2022 at 1:43 pm |
This is something I have been very interested in, however my commitments at work and present lack of mathematical ability means it’s something longer term for me. I would love to participate and hear what you and the group are doing and am happy to help out with administrative tasks like maintaining the website, and other technical matters.
I watched your speech on youtube a couple of years back, glad to hear you are still doing the project and congratulations on the grant.
Please let me know if there is scope to be a silent observer / admin assistant or the like. My email is ashok dot khanna at hotmail dot com
April 28, 2022 at 3:56 pm |
As mentioned on HN, my hunch is that building “justified” proofs that avoid computer-driven brute force search ought to be the same as building proofs in a logic where _finding_ a proof is computationally easy. We know that such logics exist (e.g. the multi-modal logics that have been proposed for use in the semantic web have been specifically chosen for computational tractability; in practice, multi-modal logic can also be viewed as a subset of FOL.). If so the problem is roughly equivalent to reducing useful subsets of math to such logics.
(The problem of tractability also comes up wrt. type systems in computer languages, and of course “modality” in logic has been usefully applied to both human language/cognition and commonly used PL constructs such as monads.)
April 28, 2022 at 5:18 pm
What you write is very similar to the lines along which I have been thinking, up to but not including the part where you say “We know that such logics exist.” I myself do not know about that, and would be very grateful for pointers to the relevant literature — especially if there’s something that’s reasonably gentle and doesn’t assume too much expertise in logic.
April 28, 2022 at 6:15 pm
The Wikipedia articles on “Fragment (logic)” (on the general search for computationally tractable syntactic fragments of FOL) and “Description logic” (the independent development of [multi-]modal logic that was adopted for uses on the semantic web) link to several useful references, inclusing a “description logic complexity navigator”. The Stanford Encyclopedia of Philosophy has articles on “Modal logic”, “Modal logic, history of” and “Multi-modal logic” has articles that, while perhaps being overly broad for your purposes, provide references wrt. aspects in computational complexity that apply to the same. Not sure if this is helpful, but I’m not aware of anything that doesn’t seem to assume quite a bit of familiarity or expertise about these subjects.
April 28, 2022 at 10:18 pm |
I am interested in your human-oriented automated theorem proving project. I think a traditional symbolic AI approach could be feasible.
Is the source code for your existing ROBOT system available on GitHub ?
April 28, 2022 at 11:57 pm |
I am very uncomfortable with the claim that I am “spearheading” any project. Here is the truth of the matter. In 2017 I became very excited about the idea of formalising a large classical mathematics library, however I was not the only one; I just happened to have the loudest trousers and the most senior academic position, and I also spent a lot of time explaining the dream to young people, because at the beginning they were more receptive than established mathematicians. Lean’s mathematics library `mathlib` is a free and open source project, maintained by 23 very hard-working people who are listed here https://github.com/leanprover-community/mathlib/ and I am not one of them. I am a contributor, no different to hundreds of other people. I think the work is important, but I’m certain that they do too, and their vision of where the project is going is no less important than mine.
April 29, 2022 at 2:16 pm
OK, I’ll try to think of an appropriate form of words that does justice to your role in energising a lot of people but doesn’t imply some kind of hierarchical structure to the Lean community. Please let me know if you still think I’ve got it wrong.
April 29, 2022 at 4:10 pm |
Fascinating project! I wish more verification projects took a GOFAI approach. Most languages like Lean rely on inhuman proof search tactics to be usable. A declarative verification language where each line of a proof is a new goal – effectively a new mini proof-automation problem – has the potential to become a much more readable and usable framework.
My intuition is that we are still far away from GOFAI automation of complete theorems. Historically, even simple concepts like Cantor diagonalization required a very specific background, intuition and perspective built on decades of prior work. It’s not clear how an algorithm would find the proper abstractions and structures – the “secret sauce” – of even simple undergrad-level proofs.
This is why I’m fascinated by GOFAI verification, which is a strictly simpler subproblem. Maybe computers cannot yet reproduce the “secret sauces”, but they should be able to understand and formalize and “solve” each step of a proof given to them one line at a time.
But I’m a non-academic software dev, so judge my comment with a grain of salt
April 29, 2022 at 4:36 pm |
And here is where I would put my ethics…IF I HAD ANY!!!
April 29, 2022 at 6:45 pm |
I have a specific comment to try and improve the move you make with proving $\sqrt{2}$ irrational. You introduce “suppose $q,p$ are somehow minimal”, but this still seems rather rabbity to me: it requires you to have thought about what it means for a pair to be minimal, and depending on context there are many degrees of freedom here.
I think a much more general move would be: “suppose I have one example; can I make another one?”, which I think you’ll agree is an extremely useful move in many situations. Stated more abstractly, this is a subgoal of the common tactic “attempt to generate more solutions given the one you’ve already got” as a fully general thing you’ll often do when exploring. In this case of course we are then trying to derive a contradiction because we have already aimed at the conclusion “false”.
Then (handwaving a bit) you only really need to play around with the move “let $q, p$ be some other expressions” before it becomes quite plausible to do “let $p = 2k$”, and then you simplify and derive that both $p$ and $q$ are even, and you’ve generated another solution.
This gets you to “$2q^2 = p^2$, and $p=2m$ is even, and $q=2n$ is even, and $2n^2 = m^2$”. I think good mechanical principles could then lead you to recognise the duplication and hence that you can repeat this process to create an infinite descending sequence of naturals. This then pattern-matches against the fact “there is no infinite descending sequence of naturals”, which I claim (with barely any justification) is easier to pattern-match than “there exists a minimal $n$ such that $P(n)$” because it’s already concretely instantiated.
May 2, 2022 at 6:06 pm
I don’t have an immediate response to this but just wanted to say that I read it with interest.
April 29, 2022 at 7:30 pm |
You wrote:
> Allowing a program to carry out searches of “silly” options that humans would never do is running away from this absolutely central question.
Perhaps this is obvious, but I would caution you to distinguish (1) “searches that humans are consciously aware of performing” from (2) “searches that proceed subconsciously, and result either in nothing, or in seemingly-unexplained new ideas, or judgements about the relative attractiveness of ideas”.
I postulate that my own “exploratory math thought” (and probably everyone’s thought about many topics) has a large amount of (2) going on “behind the scenes”, and that this is the only reason the stream of ideas that a person becomes consciously aware of has a decent proportion of fruitful ideas.
April 29, 2023 at 9:01 pm
Thank you! I was going to make exactly this point, but less elegantly. I feel like this is often missed.
April 30, 2022 at 3:44 am |
Sorry for the french langage in the comment, I wrote it as an e-mail, and just réalisesed that it was a comment, like on the math blog !
April 30, 2022 at 3:54 am
Quel projet enthousiasmant. Au début, j’ai trouvé étrange cette volonté de se passer du machine learning, puisque nous humains avons nous-même appris et continuons sans cesse d’apprendre (même si on a l’impression sans doute justifiée que l’apprentissage de routine est en substance different de celui qui nous a mené de non mathématicien à mathématicien). Il me paraissait étrange de vouloir se passer d’un fondement de l’intelligence humaine pour fabriquer une machine orientée humain. Mais comme vous l’avez mentionné dans la métaphore du software et du hardware, il est permis de penser que certains principes plus ou moins universels ont traversé de façon anecdotique notre longue expérimentation pour se matérialiser et que dès lors, on ait pas nécessairement besoin d’implémenter ce prétexte de l’expérimentation à notre machine et directement lui insuffler ces principes. Ceci sous-entend peut-être que les “principes” qui engendrent ce qu’il y a de commun entre notre expérimentation et le machine learning ne sont pas fondamentaux, non pas seulement au regard de trouver des preuves mais de trouver des preuves naturelles et compréhensibles. Ceci me semble être un pronostique très engagé et je suis fasciné par cette position ! Ceci influence ce qui aurait de prime abord été mon pronostique personnel – qui ne vaut pas grand chose au regard de mes humbles compétences. Si ce projet ne venait pas d’un grand mathematicien tel que Gowers, j’aurais été tenté de penser que la tâche est impossible ou mènerait à des résultats insatisfaisants et incomplets et que l’implémentation d’une forme d’auto-apprentissage au moins aussi volumineux que celui qui a été le nôtre depuis notre naissance, sans parler des phénomènes de sélection naturelle qui ont mené à notre espèce, est nécessaire à la façon même de trouver les preuves, je ne me serais d’ailleurs pas posé la question de la nécessité incontournable de ce facteur.
Pour être bien sûr de comprendre ce paradigme, j’ai quelques questions :
1) est-ce qu’en cas de succès inespéré, où pour une classe M’ incluse dans B, suffisamment proche de M, le fait que pour tout entier n, et tout élément de M dont la preuve est de taille n, la machine trouve une preuve (human like) en un temps polynomial impliquerait P=NP ?
Je pense que oui… à moins de rendre M’ inintéressant et loin de M. Je fais cette remarque (qui est quand même une question… car je ne suis pas certain de la réponse que j’en donne) non pas pour vous demander si vous pensez que P=NP (hahaha^^) mais pour vous demander si j’ai raison d’en déduire que, si la direction de cette recherche a peu de chance d’aboutir à ce spectaculaire extrême, elle n’en est pas moins ambitieuse, et est sans doute le fruit d’une intuition que quelque chose de très spectaculaire également (peut-etre pas autant que P=NP^^) est envisageable… au moins en théorie. Et ceci est renforcé par le fait que, si d’un côté on sera sans doute très satisfait que seule une partie satisfaisante des problèmes d’un bon M’ soit résolu en un temps correct, le projet demande, “en plus” que les preuves soient éloquentes et ergonomiques (appelons ça une bonne preuve). J’ai d’ailleurs deux question :
1′) Est,-ce que si la machine (je dis “machine” pour désigner l’automate depuis le debut) est capable de donner une “bonne preuve” mais en un temps médiocre (disons beaucoup plus long qu’un autre algorithme) cela constituera tout de même un succès? Est ce que c’est une préoccupation au moins aussi importante que la rapidité ? Je suppose que si la machine est capable de donner une bonne preuve en un temps exponentiel ,on sera content puisque c’est le temps qu’il faut à de la brute force pour y arriver, quelle est la classe des fonctions f tel que si on a une bonne preuve en o(f(n)) on sera content? Il me semble que cette question est intéressante car elle nous permettrait de mesurer le prix d’une “bonne preuve”
2) un autre problème que je souhaite soulever est celui du fair-play : si on demande qu’il n’y ait pas de triche, je pense que nous ne devons pas demander à la machine d’exceller dans un domaine où nous tirons notre competence de notre expérience et d’une spécificité peut-être pas si universelle qu’on le croit. Par exemple depuis qu’on est né on est dans l’espace 3d, on expérimente la topologie de R^3 avec plusieurs de nos sens, et ces notions nous sont tellement intuitives qu’on pourrait croire qu’elles sont premieres. On expérimente la compacité et la connexité depuis qu’on est bébé, et on a construit les notions topologiques pour generaliser ces concepts devenus intuitifs. Certes ils sont universels mais peut-être pas plus que d’autres qu’auraient pu créer une intelligence hors de notre/nos “espace/s familier/s” , intelligence qu’on ne pourrait peut-être pas imaginer mais dont on peut supposer l’existence lors d’une expérience de pensée, je ne parle pas d’une intelligence artificielle ni même terrestre ni même extraterrestre mais extra spatio-temporelle en quelque sorte. Puisque pour parler vulgairement tout concept se généralise et se reproduit en tout, il n’est pas étonnant que nos problématiques humaines se généralisent, et on ne doit, je pense , pas y voir outre mesure, une expression de leur universalité mais plutôt l’expression d’une universalité plus globale propre aux mathématiques elles-mêmes, c’est donc à autre degré de “meta” que se situe selon moi cette universalité. Il est possible que la raison pour laquelle on trouve les probleme de M interessants est due justement au fait qu’on est plus aptes à les résoudre et qu’une autre forme d’intelligence extra spatio-temporelle même supérieure a la nôtre ne serait pas capable de résoudre, mettrait dans “son” propre B\M (je précise que je considère cette intelligence dans un but théorique et que je ne sais pas si c’est pertinent d’imaginer que puisse exister une intelligence ailleurs que dans notre univers ni même un autre univers et que cette métaphore est une façon comode d’exprimer le caractère eventuellement subjectif de ce qui pourrait nous sembler universel, certes cette intelligence extra spacial n’a sans doute aucun sens mais peut-être pas plus que la notion d’universalité elle-même, je termine cette parenthèse
Certes nous rendons le concept de compacité universel en le définissant ailleurs que dans R^3, mais nous avons R^3 pour exemple fondateur et en tous cas c’est un exemple fondateur. Non seulement on demande à la machine de ne pas tricher, en “deep learnant” , mais en plus on lui donne des objets sans la béquille dont nous disposons, objet que nous trouvons intéressant parcequ’il nous concerne, simple parcequ’il nous est familier et dont nous avons acquis l’expertise inconsciente par des processus semblables à ceux dont le deep learning n’est sans doute qu’une extrême simplification. Je trouve que c’est donc “unfair” et qu’on devrait identifier les problèmes de M qui relèvent en fait , malgré notre première impression d’une spécificité humaine, et peut-être se concentrer sur les autres, dans un premier temps, cela suppose bien sûr qu’on soit capable de les identifier d’une façon ou d’une autre même de façon grossière…
Cette question est sans doute théoriquement du moins philosophiquement intéressante mais en pratique cela semble difficile de dire des choses très precises et de l’énergie des actions en conséquence alors peut-être qu’un compromis fructueux serait de considérer des problèmes plus proche du discret.
Si on veut faire de la topologie par exemple on pourrait donner à étudier des problèmes où intervient la topologie produit de 2^N plus proche des machines. Le fait de donner un domaine de problème à prouver proche de celui dont est constitué l’algorithme est je pense d’un intérêt stratégique sur le long terme qu’il n’est pas ridicule d’envisager comme non trivial.
April 30, 2022 at 12:41 pm
There was a bug in the text, when I speak about “parenthèse ” that I close … there was no more parenthèse. And also somewhere in the text the word “energie” occures but was not ment to be written, I don’t relember which word it wanted ro write at this place.
May 3, 2022 at 6:37 pm
Let me try to answer part of your question (in English, as that will be a lot quicker for me). I definitely don’t think that P=NP, though in a way that doesn’t make too much difference to the project at the moment, since even if P=NP we have no idea what an efficient algorithm for solving NP problems could be like, and much more of an idea of how to solve “natural” maths problems, even if there are plenty of mysteries about it.
But your follow-up question about whether there might be some statement that isn’t P=NP but is nevertheless still very interesting aligns with a fantasy I have, which is that it might be possible to identify a complexity class within NP that consists of NP problems with some extra property that makes them feasible. One difficulty with making this fantasy real is to come up with even a conjectured property that doesn’t make that statement trivial and uninteresting — I don’t want to end up saying little more than that a proof is easy to find if it is easy to find, or to say that it’s easy if some particular proof-finding algorithm finds it in a short time (or short expected time if it’s randomized). What I’d like is to identify structural properties of proofs, or rather “fully justified proofs” (that is, proofs together with convincing motivations for the steps) and for it to be a non-trivial theorem that proofs with those properties can be found in reasonable time.
The question about how our physical intuition feeds into our problem-solving ability is of course an important one. I’m hoping to be able to sidestep it for the time being, because it seems difficult to design a model of the world that would be suitable for providing that kind of intuition to a program, but it may be that that will restrict the kinds of problems we can hope to get a program to solve.
May 6, 2022 at 2:13 pm
May 6, 2022 at 3:38 pm
As my comment was too long to fit, I used my own blog to answer. I did’t know I had a blog, and I will soon take advantage of it to make the comment more easy to read (I will do an little abstract and put more subtitles…) anyway as it is quite long, I don’t expect to be read yet, so I feel more confortable that it is not a long comment anymore but a page that can be read if wanted.I still wanted to writenotes and thoughts, so it seems like a good compromize : I put ideas but the volume of the text is not anymore kind of “impolite”, as I don’t especially aspect to be read (of course if it is the case I would be very happy!)
April 30, 2022 at 4:20 pm |
You have the set of all proofs partitioned into Mathematics and Boring. This seems a little prejudicial. A less biased way to name them is Human Mathematics and Other.
What kinds of proofs are in Other? Certainly there is a lot of boring junk in there, and we can say that Boring is a subset of Other. But what about the proofs that are in Other but not in Boring? Non-boring non-human proofs. So let’s say we have a three-way partition of all proofs: Human Mathematics, Boring, and Mysterious.
The Mysterious class is touched on briefly in the post:
> It is interesting to speculate about whether there are, out there, utterly bizarre and idea-free proofs that just happen to establish concise mathematical statements but that will never be discovered because searching for them would take too long.
To my ears, this wording suggests that Mysterious proofs are strange anomalies that might crop up occasionally. But Mysterious proofs are far more numerous than Human Mathematical proofs. In the grand scheme of things, Human Mathematical proofs are the unusual case.
Suppose we were to enumerate all proofs, and that we do this in careful and discerning manner so as to avoid being deluged with Boring junk. We would find that, especially as the lengths of the proofs increase, it would still be quite difficult to pick out the Human Mathematical proofs. Most of the proofs would be incomprehensible to us, but we would have no grounds for saying that they are incomprehensible in an absolute sense. Maybe humans just aren’t smart enough! An extreme version of this point of view (proposed by Doron Zeilberger) says that humans definitely aren’t smart enough, and in fact any proofs that humans are capable of understanding are ipso facto trivial.
So if I may offer a vague and most non-actionable suggestion, there might be some value in starting from the assumption that Human Mathematical proofs exhibit some kind of radical simplicity. Maybe there is some nice way to characterize that simplicity.
It would also be illuminating to examine a Mysterious proof, although by definition such proofs are difficult to obtain. They are said to be “idea-free”. Can that be formalized?
April 30, 2022 at 4:35 pm |
Re. §8.1 and “rabbits out of the hat”, do you think there’s some additional immediacy to certain objects or constructions which are more familiar to people in general (e.g. chessboards, etc.), influencing their perception of full justification or at the very least ameliorating the feeling of “rabbit out of the hat”? Is the project’s vision of fully-justified proofs to somehow produce proofs biased towards this immediacy?
May 1, 2022 at 11:30 am |
I think $\mathbb{M}$ is essentially the theorems we *humans* can prove. Where the human component is the important part
Over millions of years of evolution we are wired to think and argue about the environment we live in. Historically the first areas of mathematics were number theory and geometry, as they deal with objects that appear in everyday life. The development of early algebra and analysis is therefore heavily influenced by this advantage.
I think a computer program, without any of this intuition, is unlikely to find two balls that separate two points in $\mathbb{R}^2$ without an insane effort (brute force). On the other hand, us, humans, we defined Hausdorff and $\mathbb{R}^2$ in a way that is natural to us and that let’s us use our intuition easily.
When I try to solve this problem, I first expand the definition of Hausdorff, use my mental image of $\mathbb{R}^2$ as the plane. And then I imagine two blobs that separates them, realize the simplest blob is a ball and end up with the result. Every step is effortless, as I (and everyone else), know the plane really well.
This is certainly true in early mathematics, that is more down to earth, and where most humans have a strong background and therefore advantage over computers. But I think it applies to higher mathematics as well, but we have to create the mental image with effort.
As a working mathematician, I perform the following steps:
1: Play with the object I am studying, so my mental image is as accurate as possible
2: Justify my observations with proofs, guided by my intuition about the object
3: Generalize the proofs and abstract them out to a larger context
A stage of mathematics is considerably easier if you don’t have to deal with step 1. First year undergrads can answer the Hausdorff question, right after they learn the definition of Hausdorff. Someone who studied number theory for a while, can answer that $n^7-77$ is never a Fibonacci number with less effort, as they are familiar with residues and Euler’s totient function. Proving it from scratch would require an insane effort, rediscovering all that theory.
I believe this is the main difference between $\mathbb{B}$ and $\mathbb{M}$
May 1, 2022 at 11:23 pm |
I second the reply of Anonymous (May 1, 2022 at 11:30 am) which emphasized the importance of mental images, for example when proving R^2 is Hausdorff. As they said:
“I … use my mental image of R^2 as the plane… Every step is effortless, as I (and everyone else), know the plane really well.”
For me as well, I would never think about a problem involving R^2 without using some “mental image” of it.
But what actually *is* a mental image? I contend that this is a very important question, since (IMHO) your project can’t succeed without answering it reasonably well, at least in an operational sense. So I’ll indulge in a somewhat long comment about it.
(I note there are some people, perhaps including some mathematicians, who claim to never experience “mental images”. I suspect they still have them and use them, but are unaware of that, since they don’t experience them in a manner that “imitates seeing”. I also suspect that a mental image is as much based on human instincts/abilities for perceiving and controlling motion of hands and body relative to environment, as it is on seeing.)
I think a mental image is something like a “theory” or “mental playground” — an imagined place described (at any one time) by a number of simple assertions (similar to the statement-lines in your “ROBOT-proof-finding stories”, but also including meta-statements about those statements), and where certain rules are operative. The rules are not only about “the definition of the plane” (or whatever the image is about), but about “what can be readily constructed or thought about in the plane”.
Specifically, my mental image of the plane (perhaps with certain contents like points, curves, or regions) lets me construct closed curves around bounded sets of things, zoom in, imagine lines connecting things, etc. It comes with some tendencies to prefer doing some of these things more often.
It also comes with more than one way to construct or scan the entire plane inductively — for example, I know that I can lay out a grid of points (eventually reaching “far enough in any direction” to be near any point in the plane), then zoom in and make finer grids to better approximate any given point; and by constructing a few lines, picking points on them, and constructing lines between those points, I can reach any specific point in a few steps.
I can also run a variety of algorithms in the mental plane, and know they’ll work (and will provably work), such as one to sweep out a region inside a closed curve, using a movable curve anchored at both movable ends to the inside boundary of the region.
I presumably know all this from a combination of lots of built-in spatial intuition (developed over time by evolution, and probably accidently over-represented in typical mathematicians), plus lots of experience doing thinking with this kind of mental image.
And the same holds for several other important kinds of mental images (some of them not usually directly “visual”), including ones that focus on linear order, metaphorical order of control, hierarchical structure, certainty of being able to trust rules, games, algorithms, etc. More precisely, I can make use of any or all of those aspects at once (and probably another 30 or so I’m not listing or don’t know about explicitly), when imagining any “situation”.
==
To be specific about “proving R^2 is Hausdorff” — once I understand the goal, I just imagine two points (in my image they have specific positions, but I somehow know I can treat those positions as generic), zoom in so they’re not too close, observe I can construct disjoint regions around them (since good enough example regions come readily to mind), and do so. I might need to think a bit about “how to formalize that this can be done”, which would include observing that there’s a positive distance between the points, that balls of radii summing to less than that distance will work, etc. But (as you and others observed) it certainly starts with just “knowing I can easily make regions like that”. This “knowing” comes from just “trying it and seeing that it easily works”, with both the “trying” and the “confidence that it works generically and reliably” (even before I formalized it) coming from built-in abilities of the mental image. (BTW, in a specific image with two balls, the balls being disjoint (if they are) is one of the “statements” that make up the image, whether or not I needed to think about it at that time.)
(I admit that I have seen that problem before, and for all I know I’ve seen or been taught that specific proof, so I can’t accurately simulate discovering it for the first time, let alone, discovering/inventing “the definition of Hausdorff”, which is arguably the *real* creative act related to this example.)
==
I’m sure there is more to say — for example, about how mental images relate to finding good subtasks or choosing modes — but this comment is already long. Is my most important point — that your project can’t succeed without formalizing and using “mental images” about the situations being reasoned about — obvious? It is controversial?
May 2, 2022 at 6:29 pm
I have had very similar thoughts about the Hausdorff problem and the role played by mental models. The conclusion I draw is that it would be difficult for the project to succeed fully without grappling with that problem, but I’m nevertheless fairly confident that quite a lot of interesting partial progress can be made before not having that kind of modelling becomes a real problem.
I also think, but this is quite speculative, that it may be possible to represent our geometric intuition in a more symbolic form that would be less efficient than what we do as humans but nevertheless helpful for computers.
I saw a problem recently that raises this issue in a rather acute way. It asks whether you can create a Venn diagram with four circles: that is, can you find four circles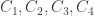 in the plane such that for every subset
in the plane such that for every subset 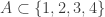 there is a point
there is a point 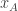 in the plane such that
in the plane such that  if and only if
if and only if 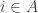 ?
?
I personally would find such a question much harder to solve if I couldn’t draw, or at least imagine, a diagram and instead had to solve it purely analytically. (Actually, I haven’t yet got round to solving it, though I’m pretty sure I know what the answer is.) So I would hazard a guess that this problem would be a very difficult challenge for a program of the kind I hope the team will develop.
It would be of some interest to find a simpler such example — ideally of a problem that humans find very easy but for which diagrams seem to be completely essential. (I think the Hausdorff one doesn’t come into that category — it can be done analytically without too much trouble, even if most humans would in fact visualize circles in the plane.)
Actually, on writing that I think I have an example: it’s to prove that the complete graph on five vertices isn’t planar. Diagrams help one’s thinking a lot for that question, but I think it’s easier than the Venn-diagrams question.
May 2, 2022 at 6:32 pm
A quick PS: the statement I made about the non-planarity of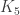 being reasonably easy to prove is in one sense not accurate, as I think it may need the Jordan curve theorem, but if we take notions of inside and outside as “obvious” then it’s OK. To avoid this issue one could ask for the edges to be straight-line segments.
being reasonably easy to prove is in one sense not accurate, as I think it may need the Jordan curve theorem, but if we take notions of inside and outside as “obvious” then it’s OK. To avoid this issue one could ask for the edges to be straight-line segments.
May 2, 2022 at 9:55 pm
> I also think, but this is quite speculative, that it may be possible to represent our geometric intuition in a more symbolic form that would be less efficient than what we do as humans but nevertheless helpful for computers.
I agree, and personally I would even say “I believe this”, only grudgingly admitting that it’s speculative.
I should emphasize that by a “mental image” I don’t mean to imply anything different from this, even as a theory of what happens in humans! Specifically, I don’t limit that concept to “geometric” information. Even in a human mental image about a geometric figure, I think it doesn’t generally contain enough info to fully specify geometry, or even to prove that’s possible. Instead, I think it’s made of lots of essentially symbolic assertions about relationships, which include topological ones and approximate geometric ones. (Plus lots of symbolic metainfo or other info which is not of those kinds.) (Perhaps it also includes lots of “numerical weights” to go with some of the symbolic subexpressions or identifiers, which govern how often attention gets directed to them vs. the others, and what kind of attention.)
I speculate that the main way the human version of this would differ from what your program might contain in a few years, would be to have far more rules, many of which were almost-duplicates or differed only in which (hypothetical) “internal variables” they referred to, because they’d been “learned by the brain” rather than “programmed by hand”. But I agree with your speculation that hand-programming fewer rules can provide a useful-enough approximation to that for many simple purposes. In some ways it will be “better than human”, e.g. each rule can be applied to any set of variables of the right types.
==
About this example:
> … to prove that the complete graph on five vertices isn’t planar. Diagrams help one’s thinking a lot for that question, but I think it’s easier than the Venn-diagrams question.
> … if we take notions of inside and outside as “obvious” …
My mental image for this would permit topological plane-embedded graphs with “semi-geometric” curved edges, would also think about regions inside closed curves, and would permit a known directed cyclic order of edges around each vertex. It would permit *very* approximate lengths and angles (for this problem, those would end up having to be ignored or generalized-over). (In my own brain, I suspect it’s impossible for me *not* to have a definite though very-approximate measurement on every length or angle; the desire to generalize over some of those is a separate piece of metainfo.)
Then the attempt to solve that problem would be a case analysis, as the attempted embedding was constructed, hopefully also noticing lots of symmetry (leading to several “WLOG” steps).
I would also have to implicitly understand that concept of “embedding” — the graph already exists by definition in a non-embedded way, my task is only to embed it (or prove I can’t).
==
Given a bunch of hints and rules which suffice to make that problem solvable, it would then be an interesting experiment to understand which subsets of them, and/or variant “weights” on their uses, also suffice. (I’ll say more about that kind of experiment later.)
May 3, 2022 at 1:31 am
Another important point about a “mental image” (according to my theory of them) is illustrated by my “image of a 10×10 grid”. (I say “my image” only to try not to state more than I have evidence for. I imagine things are similar for many other people who think about math. That said, there could also be important individual differences.)
The “mental content items” of my image of a 10×10 grid do NOT include 100 grid points. They don’t even include ten explicit columns of grid points, and/or the corresponding grid lines.
Instead, the grid as a whole is one item, and the ability to imagine subitems (points, columns of points (or corresponding grid lines), rows of points, various edges or faces, and more complex embedded objects, not to mention various kinds of patterns or functions on top of those) is “implicit”.
That is, whenever needed, I can bring to mind one or a few of the grid points, whether at specific or generic positions, and imagine them. (But probably not more than 3 or 4 at once, unless they’re in some kind of pattern.)
So when I first imagine the grid, it seems like I imagine fairly explicitly at least one corner point (this time it’s at the top right), plus the two “grid lines” intersecting it (or more precisely the nearby parts of those lines, but I can “zoom out” to see all of the outer 4 lines if needed); and I have a sense of the rest of the points and grid lines “being there”, which includes the illusion of actually seeming to see a lot of them at once, but I have evidence that I don’t really represent lots of them individually.
==
An example of that evidence: given k, let t(k) be this mental task: imagine a grid of k by k decimal digits. Make up an arbitrary digit for each grid point (don’t permit them to have any obvious pattern). Memorize those digits in your head. Be confident you really memorized them and can repeat them unchanged tomorrow.
I think I could do t(2) easily (though I’d still have to repeat the digits several times or more, to be sure I’d remember them tomorrow, as opposed to remembering them once after 10 minutes). I think with some difficulty (and less confidence about “tomorrow”) I could do t(3). For t(4) it would already be a big challenge — I could probably do it, but I’d sure rather not have to. And for t(8) I’d certainly have to break up the task, and possibly invent new memorization methods based on ones I’ve heard of, and even then I’m not confident I’d do it accurately.
==
Then if I need to use that grid for anything, I imagine other things on top of it, plus metainfo about anything mentioned so far.
A hypothesis about the “limit on short term memory size”: no more than k things of any one type allowed at one moment in a mental image, for k = something like 4 or 7. (But it’s ok to make new ones explicit and let old ones get forgotten, as needed and usually without noticing it.)
If a “simulated mathematician” is allowed to use paper, then it might contain several “mental images” while working on one problem, but some of them are allowed to “be on paper”, which means they can have more components but must be more stable. To be realistic, each “image on paper” should have an associated “image in the head” which is the subset of its items being thought about at a given moment, and is subject to the same strict item-count limitations as any other “image in the head”.
==
Even an equation or expression (like the ones that show up in some of the ROBOT stories) may often be one of these “images on paper”, with each visible symbol, each subexpression, and each identifier used in it, being a separate “mental content item”. The corresponding “image in the head” has the usual item-count limitations, so it may well be incomplete at any given time.
One effect of those limits is to provide a strong incentive to notice symmetry or other patterns in written expressions (or anything else being imagined, or studied on paper). Another is to help mitigate combinatorial explosion in possible things to think about at a given moment.
May 3, 2022 at 1:06 pm
I think our attitudes here are very well aligned!
May 2, 2022 at 12:28 am |
(If I’m wrong that one can always “sweep out the region inside a closed curve” — if I need to also assume the curve is piecewise smooth — that’s just evidence this mental image was developed for human thinking rather than formal thinking!)
May 3, 2022 at 10:15 am |
I’m anon from May 1st
I think my point with the mental images wasn’t properly communicated. I don’t think an implementation of space is necessary to recreate visual/geometric thinking.
My point is, that most beginner problems, where undergrads feel a big advantage over computers, arise from the real world, and our intuition about the real world gives us this advantage. This is something that computer programs lack, and that’s why, I think, they can’t tackle even the basics.
I believe to model mathematics (and to differentiate $\mathbb{M}$ from $\mathbb{B}$), an important aspect is the “play with the objects” process. As the intuition about the object guides the new discoveries and further areas of mathematics. The things we prove are the observations we make about these objects that are intuitive.
(Note: I’m not trying to trivialize maths here, just say that in the search space of possible proofs we choose the ones we feel natural, not some magical NP certificate path.)
And for early mathematics (like geometry and number theory) a lot of it is built inside us.
May 3, 2022 at 1:16 pm
I agree with a lot of this. As an example, the way we think about smallish positive integers is heavily influenced by the kind of “play” you allude to. For example, if the number 1023 comes up in a problem, I will, thanks to a lot of playing with numbers, immediately notice that it is , and although that may be irrelevant, it’s actually quite likely to be helpful, since numbers of that sort of size don’t tend to be one off a power of 2.
, and although that may be irrelevant, it’s actually quite likely to be helpful, since numbers of that sort of size don’t tend to be one off a power of 2.
The short-term challenge that creates for developing a human-style prover is to try to provide the prover with the fruits of that kind of play without requiring it to do the playing and consequent learning for itself. In the longer term, perhaps one could (almost certainly with the help of machine learning) create a system that could explore and discover “useful number facts” for itself (and similar facts in other domains) and store them in a way that made them accessible at the right moments, but that seems like an ambitious project, though I would guess that it’s one that people are already working on.
It may be that we have a slight difference of opinion in that I think one can set that last challenge aside for the time being and still make substantial progress, whereas I think you think that without it we’ll hit a brick wall fairly soon.
May 3, 2022 at 3:11 pm
I don’t think that the project will hit a brick wall. In fact, I believe the idea is really good and I hope it will succeed. I think logic (and early formalization) was done with a similar goal in mind back in the days. It is unfortunate that it did not help in proving theorems a lot. I find it interesting to ask whether a closer look at our thinking can help with that (solving problems algorithmically).
I just want to highlight that parts of mathematics are “cleaner from humans” than others. I think (even advanced) questions from algebra, like “what are the finite simple groups”, can simply pop up with just playing with numbers/structures/abstraction, noticing stuff and so on.
Meanwhile the Hausdorff question, unless you are guided by human apriori knowledge, is further down the line. For example, it is not immediately obvious that a continuous extension of the rationals, as in the real numbers, is useful. We know that it is a good model for the line, but I would count adding this knowledge as cheating.
Anyways, I’m excited to see what new information this project uncovers about the way we think.
May 4, 2022 at 1:57 am |
You have defined a “fully justified proof” as “a proof together with convincing motivations for the steps”.
I suggest that a better term would be either “motivated proof”, or (if you think that fails to imply the motivation is included with the proof), “explicitly motivated proof”. (Or maybe there is something still better.)
I think “justified proof” is too likely to be interpreted as just meaning “valid proof” (one with reasoning that ought to be persuasive). That is, any proof in a formal language using an accepted set of axioms (and passing a well-tested proof checker) could be arguably called “justified”; so could a clearly written informal but correct-seeming proof.
May 4, 2022 at 4:26 am |
About play, hints, and the database of proofs:
gowers wrote, replying to “Anon from May 1st”:
> … the way we think about smallish positive integers is heavily influenced by the kind of “play” you allude to … The short-term challenge that creates for developing a human-style prover is to try to provide the prover with the fruits of that kind of play without requiring it to do the playing and consequent learning for itself.
From your manifesto and other comments, I think your approach to that challenge is to formalize the results of that kind of play in hand-programmed “hints” or “built-in skills”, then construct the prover so it can make use of those, presumably in a flexible way to permit experimentation.
I agree. I think it’s important that the “database of explicitly motivated proofs” can include multiple proofs of the same theorem, in which different sets of hints were used, so their effect can be compared. It’s also desirable for the proofs to be “reproducible” — that is, if the “prover runs” which lead to those proofs can be reconstructed precisely later (by recording their exact inputs, including hint sets used, other parameters, and exact version of the prover itself), so project observers can browse proofs (or the stories of finding them) at any level of detail, and can even create tools to statistically study those stories (e.g. for comparing effects of different hint-sets over large problem sets).
Then instead of arguing about whether use of some hint is “cheating” (which I fear will inevitably be subjective and relative, and often controversial), we can discuss whether it helps many problems or only a few, whether it slows down other problems, whether it can be effectively replaced with other hints which are more primitive or general, etc. We can even discuss whether a hint is “human” or “superhuman”, based on whether it makes the system better than any humans at certain kinds of problems, or if the stories of how it’s being used don’t look “natural”.
(If a project observer doesn’t like a hint, they can contribute a better one, along with new experiments (i.e. new reproducible motivated proofs) showing how their hint affects certain problems in ways they like.)
==
The more advanced question of how a hint can be learned also becomes more definite that way, at least for a hint represented as a formal expression (as opposed to a “built-in skill” represented by an optionally-used software module). It turns into the more concrete question “how could this formally-expressed hint have been invented or discovered from this database of proof-finding-experience”? At some future time, we could even repeat the same experimental process to try out various “hints about how to learn new hints from experience” on a fixed proof-finding-database.
May 5, 2022 at 5:24 am |
This comment is about:
– the data structure of a “motivated proof” (optionally including the full story of its generation);
– how “prover modes” (as discussed in the manifesto) fit into that;
– a “story editor” UI, for developing motivated proofs and their prover hints.
(As in all my comments, everything is merely “IMHO”.)
==
I think the general case of a “motivated proof” has a modular or hierarchical structure, not just the linear structure of a ROBOT proof. This is the same kind of structure as in a normal written proof, if that contains subsections for establishing propositions or lemmas, whose details can be ignored outside them, except for the “output” itself (e.g. the proven sub-theorem). (Within the sections, the structure might be much like that of a ROBOT proof.)
When a motivated proof includes the full story of how it was made, it also needs subsections for goals which were attempted but not achieved. Those would have “failure outputs” which (hopefully) say something about why they failed (which can help guide higher-level decisions in the prover). A reader interested only in learning math from the proof would skip the failed subsections; a reader who wanted to understand the proving process might see their inputs and outputs, but skip their internals; a reader wanting a complete “debugging view” of the prover run would need to see everything inside the failed subsections.
(Likewise, the database of all “motivated proofs” ought to include the ones in which the entire proof failed, though only some readers will want to see those in search results. Strictly speaking, it’s a database of “motivated proof attempts”, some successful.)
==
If the proving algorithm maintained several “mental images” which it periodically worked to improve or expand, or later retried a failed subsection with revised parameters or other new input, the overall structure would be more complex, but should still be understood in a modular/hierarchical way.
==
When a subsection starts running, it has goals (e.g. “prove this” or “prove something of this form”), and several kinds of inputs — the assertions and external data it can use (e.g. theorem libraries), and things affecting the prover algorithm, i.e. “hints”, “skills”, the “mode”, and maybe other parameters.
The nature of those prover algorithm parameters is up for much discussion and experimentation. But it seems clear that, since each subsection is created due to some rule running at a higher level, that rule may want to alter some of those parameters inside that subsection it creates. That would be how “changes of mode” were organized — the mode (or any other parameter) could differ in different subsections, or in a subsection compared to its enclosing section.
==
Finally, a specialized UI for browsing a motivated proof can be used not only for understanding it or debugging the prover, but for developing new hints for the prover — that is, as a “story editor”. The “story” is about “how the prover managed to solve this problem” (or perhaps “how we hope it will solve it someday”); we edit it by adding or changing hints or other parameters (and seeing immediately how they change what happens), or by adding comments about what we hope can happen, perhaps adding hoped-for outputs “by hand” so we can debug later sections of the proof before earlier sections are fully working. (Of course, the UI needs to clearly warn us when the proof contains any hoped-for goal statement that is assumed but not presently achieved. We might then alter some hint, and observe that some parts of the proof work better and others worse.)
A “proof story” might start out as mostly informal comments, just recording how someone thinks a specific problem could be solved. It might be divided into proof sections with formalized intermediate states “assumed”, but with the proving itself replaced by comments about the kinds of hints needed to reach those states. Then working hints could be developed gradually. Once the proof worked, if we still thought the hints were too specific (i.e. they were “cheating”), we could try editing them and getting the proof to work again, perhaps with more steps required as the tradeoff for using a more general “hint”.
May 6, 2022 at 1:41 pm
I’m not sure that motivated proof is about motivated prooving, and that, for examaple, showing” where it didn’t work” is an acceptable “motivation” to understand the “natural keys”, but it is also IMHO.
However, it is still a good extremum for the caracterisation of a “motivated proof”, the idea of “explaining the steps” seems to me as if either the proof is not enought motivated, either the explainations are part of the proofs, in this last case, a motivated proof can be very long… why not. The other extremum would be to have a conception of motivated proof (MP) that implies that it should be more or less very close to the shortets proof.
Anyway, the exploration/exploitation of mistakes is, I think, a important point of the process, not so much for the definition of M vs B\M, but for the automate itself.
The idea of giving a library is also imho a good way to parametrize difficulties, and I thing it should be a good thing to use it in an extended way as follow (it has a link with the “mistakes” discussion) :
We can say “library” or “oracle” : it is the data of a “intermediary result” (that we can call a “cut”)that the automate is alowed to use. But “we” know that it is intermediary…. if the automate is able to kind of conjecturate that it is an intermediary result, then it would be a “dual” subject of happyness ,as we would be sometime even more happy that the automate finds that a result is a good “intermediary” candidate, then if the automate is able to proof the intermediary result. So the idea that I have, and that will seam a bit strange, is that we could encourage the automate to MAKE HIS OWN CUTS, without caring “too much” if it is right or wrong. The difficulties are principally included in the “too much”. A good begining for a framework of this idea could be to precize, the most formally as possible, what could be a good cut (some how, independantally of its truth)
I have got three main ideas too bring up the subjcet, I discuted them in a very long comment that I posted yesterday and that were maybe too long to be published, so I will just give the 3 main ideas and eventually discuss them later :
1) use a small set of “mental images” to lead the “cut searching”
2) developpe a “sens of complexity” for the automate, it would be a sens like we have “sight” and “hearing” to evaluate distances
3) exploring the “degrés ludiques” , theory developped by Chalons
————-
By the way have you heard about a result by the same mathematician (Christophe Chalons) that informally sais that “any theorem is the obvious concequnece of some obvious statement” (note the two occurrences of “obvious”, and that “obvious” is formalized in a way that (according too what I’ve been said) is really what we call obvious, the difficulty (the not obvious task) is to find of WHITCH obvious statement, the theorem is an obvious concequence) I will ask for more details, including the formal statement if anyone is intersted
May 6, 2022 at 10:47 pm
@jcamilledo
I don’t understand your description very clearly, but to the extent I can guess your meaning, I think your ideas are interesting. If you are planning to reorganize your blog post, I will gladly read it after you do that. (I don’t understand french, but I can understand the beginning of your current blog post using google translate, so I will try it that way when you say it’s ready.)
I have not heard of the work of Christophe Chalons, and I’d also be interested to hear more about that work.
May 7, 2022 at 1:42 am
@jcamilledo — I can reply now to this part of your comment, which I think I understand:
> … if the automate is able to kind of conjecturate that it is an intermediary result, … we would be sometime even more happy that the automate finds that a result is a good “intermediary” candidate, then if the automate is able to proof the intermediary result.
I think you are saying that (especially if a task fails to prove its goal statement, but not only then), it may be useful for it to come up with an “intermediary result” statement which it can neither prove, nor prove would lead to the goal, but which it still thinks would be a useful intermediate to study, as part of studying the goal.
I will guess that a statement would be a “useful intermediate” if (1) it is likely to be easier to solve than the original goal; (2) if solved, that solution process would likely provide some useful insight into how to achieve the original goal.
I agree with that (if I interpreted it correctly). It reminds me of this known advice for a mathematician facing a hard problem: “first solve a related easier problem”.
I am not sure how a machine could purposefully come up with an intermediate statement like that; but in hindsight, it can’t be harder than some of the other things we’re proposing here, since it would be a necessary consequence of those ways working, that this would sometimes happen.
For example, if it’s possible to come up with an intermediate which *is* a good step on the way to a proof of the goal, then it must also be possible to come up with one which *might be* that, but in some cases turns out not to be that. But very likely it would often be easier, and related enough that its solution could be a useful model. Also, at the time of coming up with it, it may be unclear whether or not it will be a useful step in a larger proof.
This reminds me of another comment here in which someone said something like “the first step is to form a mental picture of the situation being examined, and play with it to further develop one’s understanding of it”. That process of playing with it might include coming up with many simpler problems about the same situation, and solving some of them.
Indeed, one definition of “an understanding (of type T) of situation X” is “the ability to efficiently solve any problem about X (which is expressed in a form based on T)”. In other words, a type T of “understanding of X” consists of a set of problem-templates about situations of the same type as X, coupled with an efficient ability to solve any problem of those kinds, about X. (Or perhaps “most problems” rather than “any problems” of those kinds.)
May 6, 2022 at 11:16 pm |
Just wanted to add that, since one of the goals of the project is to create a system that makes the process of finding proof understandable to human readers, if machine learning with Explainable-AI capabilities is added, for example to decide on the next sub-task chosen in a proof expansion, it could allow the proofs produced to be human-comprehensible while also incorporating machine learning (See e.g. https://www.ibm.com/watson/explainable-ai)
November 5, 2022 at 12:13 pm |
I’m excited you are taking on this challenge.
I worked on automatic proof search problem as my PhD thesis topic, or at least that was Jan Krajicek’s plan. He somehow believed that the construction of implicit resolution is the correct machinery for this but I quickly discovered it’s a complete non-starter. However, it did became clear what the general setting is going to be for this kind of problem.
I have left mathematics long enough that I struggle to recalled most of the precise definitions. But the intuition is basically as follows:
When you talk about backtracking and the like, you are dealing with cut free proofs. In practice this is almost certainly resolution or a variant of such. But for what you are wanting to do you do need cuts. And this is the big deal.
The setting of proof search for extended resolution provided a very clean view of what’s going on. And in fact the first order setting is not all that different. To search for a proof, you need two parts. First of all, you need to define the extension variables, then you do resolution. The resolution part is relatively easy when you have all sorts of DPLL like algorithms that are reasonably efficient. It would be great if you can eliminate unnecessary branches but this is not the main problem.
The central problem is how to define extension variables. In first order sequent calculus this is directly equivalent to cut formulae. And this is where so called “creativity” came in. You don’t just search in a somewhat confined search tree. You need to “invent” cut formulae. The problem of automatically writing computer programmes is also closely related. I have the feeling that if you know how to find cut formulae you have “real” AI.
Hope this helps.
January 7, 2023 at 5:25 pm |
Sounds like a really interesting project! There is quite a lot of literature on ‘mathematical explanation’ in the philosophy of mathematics which I think might be very close to your notion of a ‘justified proof’. In particular, I think Kitcher’s account is very good. (See (1989) “Explanatory Unification and the Causal Structure of the World”, in P. Kitcher and W. Salmon (eds.), Scientific Explanation, Minneapolis: University of Minnesota Press, 410–505.) Ostensibly it deals with scientific explanation but Kitcher also thinks the account to generalises to mathematical explanation (and it does so quite successfully in my opinion). I also think it might give a good account of distinction you mention between genuine understanding and mimicry.
May 2, 2023 at 12:05 pm |
Good.
November 23, 2023 at 12:08 pm |
[…] 详情参考 […]
December 8, 2023 at 1:49 pm |
온라인바둑이
Announcing an automatic theorem proving project | Gowers's Weblog
December 9, 2023 at 10:43 pm |
Toyhaulin.Org
Announcing an automatic theorem proving project | Gowers's Weblog
January 30, 2024 at 11:44 pm |
Do you have any updates on this project? Is this awesome prject still active?