The Large Deviation Heuristic: an example – triangle-free graphs
Here is a very general probabilistic-based heuristic that seems to give good predictions for questions related to EDP. I will refer to this heuristic as “LDH”. (In my polymath5 comments I referred to it as PH – probabilistic heuristic)). I am thankful to Noga Alon and to Yuval Peres for some helpful help.
Here is an example: Suppose we want to study the following extremal problem.
What is the largest number of edges in a graph on n vertices with no triangle.
If we use the probabilistic method we can ask what is the probability that a random graph in 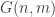



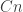

LDH:
1) Estimate naively the probability that a random graph in G(n,m) contains no triangle.
2) Choose m so that this estimated probability behaves like 1 over the number of graphs with n vertices and m edges.
So let’s implement this plan. The probability that a random graph in 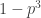
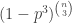



LDH prediction for Mantel-Turán problem: The maximum number of edges in a triangle-free graph behaves like 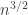
In other words, the LDH gives two predictions that we will refer to as the “firm” prediction and the “weak” prediction.
A) (The firm prediction.) There exist triangle-free graphs with
and
B) (The weak prediction.) There are no (substantially) larger triangle-free graphs.
Prediction A is correct. There are indeed triangle-free graphs with 
Excercise: What is the LDH prediction for the question: How large can a subset of the integers {1,2,…,n} be if it contains no 3-term arithmetic progression?
We would like to propose the following points regarding the large deviation heuristic:
- LDH predictions about the existence of some combinatorial objects are quite often true. (We refer to such predictions as the firm predictions.)
- LDH weak predictions are blind to various structured examples. Sometimes, if we understand the relevant structures we can update the large deviation predictions. (I will come back to this at the end of the post.)
- LDH predictions appear to be quite good for the Erdős Discrepancy Problem (EDP) and for variations of EDP. This is what we are going to discuss now.
Since LDH is based on a heuristic method to compute probabilities it is quite possible that different heuristics will give different answers but, overall, we did not encounter this.
Problem 1: Find natural examples where the LDH firm prediction, namely the prediction for the existence of certain combinatorial objects, fails.
Problem 2: Find ways to improve the LDH when it fails. (Especially when the answer is known by other methods).
What does LDH predict for EDP?
Direct Computation
We consider the multiplicative version of Erdős Discrepancy Problem . The number of multiplicative 

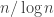
What we need to compute is:
What is the value of
so that the probability
of a random
satisfies
?
This question can be formulated in terms of a simple random walk of length 
Problem 3 (the answer is known): What is this value
Towards answering problem 2, I asked over Mathoverflow “What is the probability that a random walk of length n will be confined to the interval
What is the probability that the simple random walk of n steps will be confined to the interval
And a few hours later I received the following reply from Yuval:
Gil, the confinement probability in
where
is known: it is
. This is classical and you can find it e.g. in Feller volume 2 or in Spitzer’s book. This holds for all
. So the answer to your query is that
for a suitable
So, we get:
The LDH prediction for the EDP is that the maximum discrepancy of a multiplicative sequence of
. (The same prediction applies to general sequences.)
General sequences and positive correlations.
If we consider general 



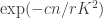

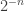
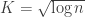
Problem 4: Fix two positive integers 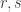

1) For a maximal HAP of gap 
2) For a maximal HAP of gap 
Are these two events positively correlated when
Indirect computations
At an earlier time, I had a version of the LDH based on gaps between vanishing partial sums. Let me discuss it here. We start with the following question: What is a probability that a sequence of 
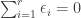

What is the probability that a simple random walk of length t will not reach zero in the interval
?
For our purposes all we need to know is that this probability tends to some constant strictly between 0 and 1. The precise value is related to a classic question and let me cite another email by Yuval Peres about it:
The probability that a simple random walk
willnot meet 0 in the time interval [s,t], where s=xt, tends asto
. This is one of the two classical arcsine laws for random walks that you can find in many sources, including e.g. Durrett’s book or proposition 5.7 page 137 in My Brownian book . There you will see this law applies to all random walks with increments of mean zero and finite variance. More combinatorial arguments for the special case of SRW can be found in Feller vol I, as well as in these slides.
Given a random walk on the line we will try to estimate the probability that we can find sequence of indices 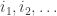
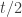
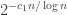
(Firm prediction) There exists a multiplicative sequence of length 
(Weak prediction) This is best possible.
Some additional gymnastics allow us to move from the prediction regarding multiplicative sequences of length 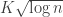
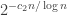
Here too the computation for general sequences gives the same outcome and indicates positive correlation between events which in the heuristic are pretended to be independent.
(Let me remark that over the polymath5 threads there were several remarks in the direction of trying to show that there are no
Variations of EDP and related discrepancy problems:
Variations
Let me mention briefly several variations of EDP and what LDH says about them. The LDH is responsible for the guesses we propose in the previous post for variations E1-E8 of EDP.
The weak LDH predictions will not change if we consider 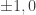
If we consider only HAPs with prime power differences the LDH prediction is the square root of 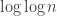
The firm prediction of the LDH predicts a polylog(n) discrepancy (in fact even 
Probabilistic analogs for EDP
Problem 5: Does the LDH give good predictions for discrepancy problems for random hypergraphs  and
and  $on {1,2,…,n}?
$on {1,2,…,n}?
Let 
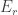
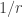
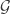
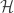

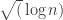
LDH and the six standard deviation theorem
Of course, it is of interest to understand the LDH predictions (both for 
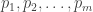



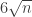
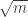



Roth’s theorem and how the LDH predicts the answer
Recall that Roth’s theorem is about the discrepancy of the hypergraph whose edges correspond to all arithmetic progressions in {1,2,…,n}.
The LDH predicts the correct answer, at least roughly. The probability that a maximal AP of gap r will be confined to [-K,K] is 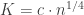

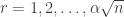

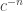

Problem 6: Are the methods of proving upper bounds for the disrepancy problem for APs relevant for proving better upper bounds for EDP, its extensions, and its variations?
Large deviations for extremal graph properties revisited
Graph limits and the work of Chatterjee and Varadhan
We started this post by trying to answer a classical problem in extremal graph theory using a probabilistic heuristic which is based on large deviation estimates. It would not be irresponsible to say that the heuristic estimates proposed a very poor prediction to the extremal problem we considered.
Let 
One of the important discoveries in graph theory which is related both to additive number theory and to probability theory is the notion of limits of graphs. This notion is connected to the famous Szemeredi lemma. The theory of limits of graphs sheds new light on extremal graph theory; in a sense it tells us what the relevant structures for
A recent paper entitled The large deviation principle for the Erdős-Rényi random graph by Sourav Chatterjee and S. R. S. Varadhan revealed a connection between large deviation for properties of Erdős-Renyi graphs and graphons – limits of graphs. (It complements a large body of related results obtained by various other methods.) Here is the abstract.
Abstract: What does an Erdős-Renyi graph look like when a rare event happens? This paper answers this question when p is fixed and n tends to infinity by establishing a large deviation principle under an appropriate topology. The formulation and proof of the main result uses the recent development of the theory of graph limits by Lovasz and coauthors and Szemeredi’s regularity lemma from graph theory. As a basic application of the general principle, we work out large deviations for the number of triangles in G(n,p). Surprisingly, even this simple example yields an interesting double phase transition.
So we can “morally” understand why the weak prediction of LDH fails for the property of “including a triangle”. To obtain a better prediction we also need to condition on various relevant limit structures of the random graph.
LDH for the triangle-free process
Consider the following graph process. We start with the empty graph on 
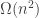
Extremal problems for bipartite graphs
Problem 7: Let
It turns out that for extremal problems on graphs the LDH gives quite similar predictions to those obtained by the rigorous well known edge-deletion method based on the following proposition:
Proposition: If, for a random graph with n vertices and 2m edges, the expected number of copies of 
For Turán-type problems, the LDH’s predictions are quite similar to those obtained by the edge-deletion method. (I am not aware of a similar trick for discrepancy problems.)The LDH predicts the existence of
The LDH prediction are still far from the correct answer. Erdős conjectured that for any bipartite 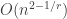

August 27, 2012 at 6:35 pm |
“Few weeks ago” (my correspondence with Yuval) refers to July/August 2011..
August 28, 2012 at 7:37 am |
Hi Gil,
Unless I compute wrong, LDH gives prediction O(1) both for the discrepancy of 2 and the discrepancy of 3 permutations, right? (Correct in the case of 2 and wrong in the case of 3.) I think Spencer had a similar intuition why those discrepancies should be in fact constant.
But if you look at the permutations problem and how the LDH estimate is computed, LDH assumes 3 independent random walks, while in fact in choosing the permutations we have quite a lot of freedom in correlating the walks. A lot more freedom than we do with HAPs.
August 29, 2012 at 6:14 am |
Dear Sasho,
To the readers: Here is a link with a description of the 3-permutation problem http://gilkalai.wordpress.com/2011/08/29/alantha-newman-and-alexandar-nikolov-disprove-becks-3-permutations-conjecture/
What you say is very interesting. I will try to check the computations (but like other heuristics LDH can be creatively adjusted at times) In a sense this is a question with one higher level of complication since we have a question on the maximum over a family of hypergraphs.
Is the situation for random permutations known (or even obvious)?
August 29, 2012 at 11:10 am
To my knowledge, it is not known what is the discrepancy of a set system based on 3 (or more) random permutations. (We can let the first permutation be the identity and then pick two other random permutations.)
The pattern from the three permutations with high discrepancy might appear as an induced pattern if we choose long enough random permutations, but it is not clear if the other elements will cancel out the discrepancy from the pattern.
August 29, 2012 at 6:16 pm
My wild guess is that LDH may be closer to the truth for O(1) random permutations. I.e., maybe three randomly permuted simple random walks still have their prefix sums mostly uncorrelated and the discrepancy is actually constant. But I do not know how to formalize anything like this.
August 30, 2012 at 6:54 am |
Another major recent breakthrough in discrepancy theory is the paper Constructive Algorithms for Discrepancy Minimization by Nikhil Bansal http://arxiv.org/abs/1002.2259 . A related important more recent paper is “The determinant bound for discrepancy is almost tight” by Jirka Matousek http://arxiv.org/pdf/1101.0767v1 .
The linear-algebraic notions of discrepancy discussed in these papers may be relevant to various issues of the EDP project.
August 30, 2012 at 9:18 pm |
Regarding the greedy algorithm considered in the previous post. The very nice answer by rlo suggests that this greedy algorithm gives discrepancy close to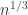 or so, and rlo expect it also for the square free variation. Can an upper bound of
or so, and rlo expect it also for the square free variation. Can an upper bound of 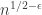 be proved? What about a lower bound of
be proved? What about a lower bound of 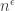 .
.
Another interesting question is if you can improve the greedy algorithm to get lower discrepancy. Our greedy ignore 0’s in intervals. A greedy algorithm that ignore intervals with 0’s was considered in earlier polymath5 threads and to the best of my memory achieve discrepancy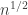 . Maybe a clever interpolation between these two variants will do a better job than both?
. Maybe a clever interpolation between these two variants will do a better job than both?
February 9, 2013 at 3:50 pm |
diaskedastik0.blogspot.gr help me out with any new ideas
October 22, 2015 at 7:12 am |
[…] D(n) tends to infinity but how fast? It is reasonable to think that D(n) behaves asymptotically like . (This is suggested, among other reasons, by certain probabilistic heuristics from EDP23.) […]
September 9, 2019 at 6:01 am |
[…] and also on related results in Discrepancy’s theory, see this post and this one and also this one on Gowers’s […]