Just as I thought that Polymath5 was perhaps beginning to lose momentum, it has received a sudden boost, in the form of this comment of Terry’s, which has potentially completed one of the hoped-for steps of the proof strategy, by establishing that if there is a counterexample to EDP, then there is a “moral counterexample” that is completely multiplicative.
There are a few points that need clarifying here (which I am just repeating from Terry’s comment). The first is that the multiplicative counterexample is over the complex numbers: that is, it is a sequence with values in 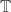


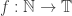
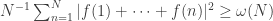

Since this is asking for something substantially stronger than unbounded partial sums, it makes sense to ask whether this stronger conjecture is true. The answer is that it seems to be about as plausible as EDP itself: that is, the key examples we have seem to behave similarly for both measures of growth. In particular, the mean-square partial sums of the function 
Now it seems reasonable to regard this problem as “morally the same” as the problem of proving that a completely multiplicative 
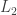

At the moment, quite a lot of attention is being given to algorithms of the kind I discussed in EDP2. These are algorithms where each time you choose a value at a prime, you follow through all its easy consequences (there are various ways that this notion can be formalized) before looking at the next prime. Some time ago, I used an algorithm like this to find a maximal-length multiplicative sequence of discrepancy 2. The interest now is in whether one can prove by hand that that length (which was 246) is maximal. To read more about this, I recommend looking at a page on the wiki that Sune created, in which he gave a rather clear and concise description of the kind of algorithm we are talking about. And there is also a lengthy discussion of the algorithm following this comment.
I have to admit that from a theoretical point of view, my enthusiasm for this algorithm has dwindled. I had hoped that we would be able to identify regions that were full of odd-smooth numbers, and show that the discrepancy and multiplicativity constraints from those regions were too numerous to be simultaneously satisfiable. If that were the case, then it might be possible to prove it by examining carefully how the algorithm performed, and showing that for each discrepancy
Before embarking on an attempt like this, it is worth thinking about when, in general, analysing an algorithm can be useful for proving a theorem. Here, for example, is a theorem where it does not seem to be useful. One can prove van der Waerden’s theorem for 2 colours and arithmetic progressions of length 3 as follows. At each stage I choose R if I can, and otherwise blue, and if I can’t choose R or blue I backtrack. The proof then goes like this: R, RR, RRB, RRBR, RRBRR, RRBRRB, RRBRRBB, RRBRB, RRBRBB, RRBB, RRBBR, RRBBRR, RRBBRRB, RRBBRRBB, RRBBRB, RRBBRBR, RB, RBR, RBRR, RBRRB, RBRRBR, RBRRBRB, RBRRBB, RBRB, RBRBB, RBRBBR, RBRBBRR, RBRBBRB, RBRBBRBR, RBB, RBBR, RBBRR, RBBRRB, RBBRRBB, RBBRRBBR, RBBRB, RBBRBR, B. At that point I can argue by symmetry: if there is no sequence beginning with R then there cannot be one beginning with B.
Now I actually have a soft spot for this proof, which is simply a depth-first search, and would be quite interested to know more about it. For example, if I run a depth-first search but looking for progressions of length 4, then how will the lengths of the sequences I look at at each stage behave? (The maximum length will be the van der Waerden number W(2,4).) How many sequences will I end up looking at? Can I cut this down a lot by exploiting self-similarities in the tree? (To put that another way, I could build up little lemmas that would tell me that certain subsequences would lead fairly quickly, but not instantly, to contradictions, and I would then not have to keep demonstrating those contradictions over and over again. That would happen every time I backtracked, and the further back the backtracking went, the more powerful the lemma would be.) However, the point I want to make is the negative one that it seems incredibly unlikely that a proof of van der Waerden’s theorem could come out of analysing this algorithm. I don’t know how to justify this assertion convincingly, but what goes on in my head is a thought like this: oh dear, if van der Waerden’s theorem is false, then this algorithm won’t ever terminate, so to prove that it terminates I’m going to need van der Waerden’s theorem. Perhaps another way of putting it is to say that the algorithm merely searches through all possible colourings: it doesn’t have an obvious theoretical advantage over literally writing out all colourings of 

How about an example where analysing an algorithm does help to prove a theorem? One such is a proof of Hall’s theorem. This can be done by describing an algorithm for creating a matching, and proving that the only reason it could have for getting stuck would be if Hall’s condition was violated. Similarly, Bézout’s theorem can be proved by using Euclid’s algorithm to define better and better integer combinations of the original two numbers. Somehow, in both these cases the algorithm is what one might call the algorithmic version of an already existing theoretical proof, whereas this is not the case for brute-force algorithms.
That was not a very successful attempt to distinguish between algorithms that help you prove things and algorithms that don’t. (One other point is that efficient algorithms seem to be more useful for proving theorems than inefficient ones. I’d be interested to know of a counterexample to this — a situation where one can obtain an interesting theorem by proving that a certain inefficient algorithm terminates.) However, in the particular case of searching for long multiplicative sequences of low discrepancy, there is another argument that I find particularly convincing, which I think of as Sune’s test. It can be summarized with the following slogan: your analysis has to apply to the function
My reason for being so pessimistic is based on what the algorithm would do to the function 

As a result, I think we are more or less forced to look for theoretical arguments. Here is one possible general proof strategy.
1. Develop a notion of “almost character-like” functions.
2. Prove that a multiplicative sequence that is not almost character-like must have unbounded discrepancy.
3. Prove that a multiplicative sequence that is almost character-like must have unbounded discrepancy.
I would expect 3 to be easy once one had a decent answer to 1. The real challenge is to answer 1 in a way that allows one to prove a good theorem that answers 2.
I have suggested a couple of very preliminary ideas in the direction of 1. I won’t repeat them here. However, I will mention that there is a notion of closeness for multiplicative sequences that has proved itself useful in several contexts. An interesting discussion can be found in this paper of Granville and Soundararajan, starting on page 207. The simplest notion of closeness they mention is this: given multiplicative functions 


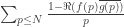


Granville and Soundararajan have various results that show that multiplicative functions with certain properties (such as partial sums that grow linearly) must be close to characters that very obviously have those properties. Two questions we might think about are these. Suppose we have a multiplicative function that is
More generally, if

January 30, 2010 at 4:04 pm |
I’ve had a little look at the paper of Balog, Granville and Soundararajan that is linked to from the wiki. It strikes me that it gives us information that could be extremely useful. In the post above and in one or two of my comments about character-like functions, I have expressed a hope that one might be able to prove that a multiplicative function is either not like any character, in which case one might be able to obtain a lower bound on partial sums in one way, or it is very character-like, in which case one might be able to do it another way. But if you look at page 3 of the paper just mentioned, you will see that they are discussing results that are very like this. Let be a multiplicative function and write
be a multiplicative function and write  for
for  . We would expect
. We would expect  to be
to be 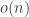 unless
unless  has some very special structure mod
has some very special structure mod  , and indeed this is the case. Either that estimate is valid for all
, and indeed this is the case. Either that estimate is valid for all  , or there is some “exceptional modulus”
, or there is some “exceptional modulus”  such that the estimate is true whenever
such that the estimate is true whenever  is not a multiple of
is not a multiple of  , and there is a character mod
, and there is a character mod  such that whenever
such that whenever  is a multiple of
is a multiple of  we have that
we have that  is approximately equal to
is approximately equal to  .
.
In the first case, we have no correlation with any arithmetic progression, which sounds to me as though it ought to be enough, by some Fourier argument, to give unbounded partial sums. Having said that, it would be essential to use multiplicativity, since for example a function that randomly chose, for each
function that randomly chose, for each  , whether to send
, whether to send 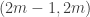 to
to 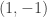 or to
or to 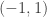 wouldn’t correlate with anything and would have bounded partial sums. (However, it would not have bounded HAP sums.)
wouldn’t correlate with anything and would have bounded partial sums. (However, it would not have bounded HAP sums.)
Hmm, maybe that’s not so clear after all. So let me ask the following question, very closely related to EDP. Suppose you have a sequence with bounded discrepancy. Does it follow that there is some arithmetic progression along which the partial sums grow linearly? Obviously the answer is yes if no sequence has bounded discrepancy, but the idea is that this problem should be easier as we’re allowed the extra hypothesis that the sequence doesn’t correlate with any AP. (Note that our experimental examples do seem to correlate significantly with some APs.)
sequence with bounded discrepancy. Does it follow that there is some arithmetic progression along which the partial sums grow linearly? Obviously the answer is yes if no sequence has bounded discrepancy, but the idea is that this problem should be easier as we’re allowed the extra hypothesis that the sequence doesn’t correlate with any AP. (Note that our experimental examples do seem to correlate significantly with some APs.)
The other half of the dichotomy is that the sequence mimics the behaviour of the character mod
mod  . That would be a big step in the direction of showing that the function
. That would be a big step in the direction of showing that the function  resembled a character-like function.
resembled a character-like function.
January 30, 2010 at 8:33 pm
If I’m not mistaken, you can take Theorem 2.3 (or the more precise Corollary 1) of that paper, and then combine this with Terry’s Fourier Reduction Lemma. This then says that the \omega(N) lower bound holds for character-like sequences, no? It then remains to treat the non-character-like sequences. Unfortunately, there does not appear to be precise information for this latter case, except that the average value converges to zero.
By the way, if anyone can read German, reference [21] of the paper may be useful to decipher.
January 31, 2010 at 5:40 pm
Yes, it does seem that Theorem 2.3 implies that a multiplicative function g(n) of bounded discrepancy doesn’t pretend to be n^{it}. I think my arguments below for characters chi also extend to twisted characters chi n^{it} (basically because n^{it} varies slowly on an interval such as [N, N+O(M)] when N is much larger than M) so we should be able to eliminate all pretense to twisted characters also.
Of course, this still leaves the most difficult part untouched, namely the hypothetical “inverse theorem” that says that bounded discrepancy can only occur when one is correlating with a character…
February 2, 2010 at 7:28 pm
It would then be interesting to compare your proof to the proof of Theorem 2.3, though I assume the latter is (unnecessarily for us?) more involved, since the terms are more explicit. In any case, I’ll make a note of the “black box” proof on the wiki.
For the more difficult “inverse theorem,” there may be some things to gain from that Wirsing paper [21], and since no one here seems to speak German, I will type it into Google translator and post the result on the wiki here.
As an aside, the linguistic difficulty for “multiplicative function” just re-occurred to me, and I hope no one else is confused about it as they read these number theory papers. That is, in the number theory papers, their “multiplicative functions” are functions which are multiplicative for numbers which are co-prime. I’m not sure if that affects the applicability of the theorem in a positive way.
January 30, 2010 at 4:40 pm |
Here’s another thought, very undeveloped at the moment, but in the Polymath spirit I want to express it before thinking further.
If one looks at Terry’s Fourier reduction argument, one sees that the pigeonhole argument could potentially give quite a lot more information if the function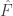 is never huge, since then we would be able to deduce that there are several different
is never huge, since then we would be able to deduce that there are several different  for which the estimate holds.
for which the estimate holds.
Now it seems to me that if there are enough different for which the estimate holds, then one has a task that is potentially easier: to prove that amongst a large number of genuinely distinct multiplicative functions, there must be at least one that has a partial sum that is at least
for which the estimate holds, then one has a task that is potentially easier: to prove that amongst a large number of genuinely distinct multiplicative functions, there must be at least one that has a partial sum that is at least  in absolute value. (At first one might think that that would be difficult, as there are quite a lot of character-like functions. But there are not all that many if the base stays low, and they cease to be good when the base gets high.)
in absolute value. (At first one might think that that would be difficult, as there are quite a lot of character-like functions. But there are not all that many if the base stays low, and they cease to be good when the base gets high.)
If, on the other hand, there is some such that
such that 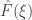 is close to its largest possible modulus, then one is well on the way to proving some kind of periodicity, which also should be pretty useful.
is close to its largest possible modulus, then one is well on the way to proving some kind of periodicity, which also should be pretty useful.
January 30, 2010 at 5:18 pm
Regarding ways to squeeze more out of the pigeonhole argument, I mentioned in “>this comment that there is in fact a tight equivalence between an EDP type problem and a completely multiplicative EDP type problem. Namely, the Hilbert space version of EDP (where f takes values in the unit sphere of a Hilbert space, rather than {-1,+1}), is equivalent to establishing the divergence
for all _probabilistic_ completely multiplicative functions g taking values in S^1. This logical equivalence is discussed at the bottom of the Fourier reduction page.
Intuitively, when the function F has its energy dispersed into different Fourier frequencies, then the probabilistic function g will be dispersed into multiple completely multiplicative functions . It is plausible that this makes it difficult for the average discrepancy of all of these functions to always be small, but making this rigorous would require some sort of “repulsion phenomenon” that asserted that if one multiplicative function g had bounded discrepancy, this would make it harder for a completely different multiplicative function g’ to have bounded discrepancy. This is a different phenomenon from the usual repulsion phenomenon for characters (if one character is biased on the primes, then it is very hard for any other character to be biased on the primes – this is how Siegel’s theorem is proven, for instance) and I don’t see even a heuristic reason why it should be true yet.
. It is plausible that this makes it difficult for the average discrepancy of all of these functions to always be small, but making this rigorous would require some sort of “repulsion phenomenon” that asserted that if one multiplicative function g had bounded discrepancy, this would make it harder for a completely different multiplicative function g’ to have bounded discrepancy. This is a different phenomenon from the usual repulsion phenomenon for characters (if one character is biased on the primes, then it is very hard for any other character to be biased on the primes – this is how Siegel’s theorem is proven, for instance) and I don’t see even a heuristic reason why it should be true yet.
January 30, 2010 at 5:18 pm
Tim, the URL I was trying to put above is
January 30, 2010 at 5:51 pm
Ah yes. I’d read that comment but not digested it properly, so I didn’t spot that it was exactly saying what happens if you squeeze as much as possible out of the argument.
January 30, 2010 at 5:20 pm |
Suppose we have a multiplicative function that is +-1 except on multiples of p and 0 at multiples of p. Suppose also that its partial sums are bounded. Must it be the Legendre character mod p?
This question seems as hard as showing that all +-1 multiplicative functions g have bounded discrepancy. If has discrepancy at most C, then the function
has discrepancy at most C, then the function 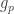 formed from g by zeroing out g on the multiples of p has discrepancy at most 2C, since the partial sum of g_p up to N is equal to the partial sum of g up to N, minus g(p) times the partial sum of g up to N/p.
formed from g by zeroing out g on the multiples of p has discrepancy at most 2C, since the partial sum of g_p up to N is equal to the partial sum of g up to N, minus g(p) times the partial sum of g up to N/p.
January 30, 2010 at 5:48 pm
Oh yes. I was worried that it felt rather similar in spirit to the original problem, but I didn’t see that it was exactly equivalent.
January 31, 2010 at 10:59 am
I don’t think the two questions are equivalent. I asked the same question for p=3, knowing that a counterexample to EDP would give an example, but I don’t think an example of such a function would give a counterexample to EDP. and 0 on multiples of of these primes, and that the function has bounded discrepancy. Must it be one of the n functions we get by taking the Legendre character mod
and 0 on multiples of of these primes, and that the function has bounded discrepancy. Must it be one of the n functions we get by taking the Legendre character mod  for some i, and turn off the other primes?
for some i, and turn off the other primes?
Some related thoughts: If we have a counterexample to EDP and “turn off” a finite numbers of primes, we will still have a function with bounded discrepancy. So we could ask: Suppose we have a multiplicative function that is +-1 except on numbers divisible with at least one of
We can only expect to keep the discrepancy bounded if we turn off a finite number of primes, but we might still learn something if we turn off an infinite number of primes. This suggests two questions:
Can we find a set of primes such that no multiplicative function that is 0 on numbers divisible by at least one of these primes and +-1 on all other numbers have bounded discrepancy?
For any C, can we find at set of primes, such that a multiplicative function that is 0 on numbers divisible by at least one of these primes and +-1 on all other numbers has discrepancy >C?
(I think there is a chance that these questions could be easier than EDP)
The latest question is related to the last paragraph in this old comment of mine,
February 1, 2010 at 9:22 pm
A related question: For which p do there exist multiplicative functions that is +1 or -1 on primes and 0 on primes >p and has bounded discrepancy? That should be easy to investigate for small p, because there is only a finite numbers of such function. For p=2 the answer is yes.
and 0 on primes >p and has bounded discrepancy? That should be easy to investigate for small p, because there is only a finite numbers of such function. For p=2 the answer is yes.
February 1, 2010 at 11:11 pm
Sune’s question prompts me to ask a similar question that I’ve been pondering in relation to the general (non-multiplicative) EDP. What if we only require bounded discrepancy on HAPs with differences that are -smooth (that is, divisible by no primes greater than
-smooth (that is, divisible by no primes greater than  )? Can we get an infinite sequence? Again, for
)? Can we get an infinite sequence? Again, for  the answer is yes: the Thue-Morse sequence works. But I don’t know the answer for
the answer is yes: the Thue-Morse sequence works. But I don’t know the answer for  .
.
February 2, 2010 at 12:14 am
Can one do that by a substitution sequence of order (or whatever the right term is) 6? For instance, start with 1 -1 1 -1 1 -1 and then turn each 1 into that same sequence and each -1 into minus that sequence. Clearly it’s bounded if you take an HAP with difference a power of 6. More generally, if it’s bounded for d then it’s bounded for 6d. It’s also bounded for 3, and slightly less obviously for 2.
Hmm, I don’t see how to prove it for say 1024. Have you thought about this sort of example?
Actually, I think maybe a better approach is just to use a fairly greedy algorithm. For example, perhaps one could build a (2,3)-multiplicative sequence (meaning that f(2x)=f(2)f(x) and f(3x)=f(3)f(x) for every x) and keep its partial sums bounded. It seems very unlikely that there will be enough constraints to stop that being possible.
February 2, 2010 at 12:27 am
In fact, here’s a possible argument, but not fully checked so it may go wrong. (What is needed is a small case check — the cases I’ve looked at seem OK.) I’ll choose the values in blocks of 6. When I get to a new block, the 2- and 3-multiplicativity will tell me what the values are at 6m, 6m+2, 6m+3 and 6m+4, and I am free to choose the values at 6m+1 and 6m+5. I claim I can do this so that all six values sum to zero. The only thing that can go wrong is if all four fixed values are the same. But the values at 6m, 6m+2 and 6m+4 won’t be the same if the values at 3m, 3m+1 and 3m+2 aren’t all the same. So I’ll also insist that I never give a block of three of that form all the same sign.
So finally the claim I need to prove is that if the values at 6m, 6m+2 and 6m+4 are not the same, then I can choose the values at 6m+1 and 6m+5 such that all six values add up to zero and the function is not constant on either of the blocks 6m, 6m+1, 6m+2 or 6m+3, 6m+4, 6m+5. That’s the bit I haven’t checked, but so far it looks OK.
February 2, 2010 at 12:30 am
I have now checked it …
February 2, 2010 at 8:36 am
Ah yes, thanks! I’d considered the substitution sequences, but hadn’t thought through the consequences of a partial multiplicativity constraint. I think your construction can give discrepancy 3 on the 3-smooth HAPs.
February 2, 2010 at 9:08 am
The other method gives discrepancy 2. It ought to be possible to work out explicitly what sequence it gives (given certain methods of choosing if you are not forced), and this might perhaps even be interesting.
February 2, 2010 at 10:53 am
Sorry, being blind — which other method? (The substitution sequence has discrepancy 3 on its 2-HAP…)
February 2, 2010 at 11:44 am
I started describing it in the final paragraph of my first response to your question, and worked out the details in the subsequent comment. The basic idea is to define a function in blocks of six (but starting with 1-5), making sure at each stage that it satisfies the following conditions.
(i) f(2x)=f(2)f(x)
(ii) f(3x)=f(3)f(x)
(iii) the sum of the values of f in any block of six is 0
(iv) f never takes the same value on all three of f(3y), f(3y+1), f(3y+2).
It is not hard to check that you can do this. Condition (iv) is needed in order for it to be possible to guarantee condition (iii) at the block that begins at 6y.
I now realize that this has discrepancy 3 after all, but that is just a parity difficulty: if you define your HAPs to include zero and make the first block 0-5 instead of 1-5 (and do not insist on any multiplicativity properties involving 0) then you can get discrepancy 2.
February 2, 2010 at 1:46 pm
Hm, I still don’t see how to get discrepancy 2 with these conditions if you include zero. Every combination of assignments of to 0, 2 and 3 leads me to a contradiction.
to 0, 2 and 3 leads me to a contradiction.
Maybe an example will clarify my misunderstanding. If I send 0 to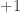 and 2 and 3 to
and 2 and 3 to  , the sequence (starting at 0) must begin like this:
, the sequence (starting at 0) must begin like this:
Now 7 and 11 must go to by (iii), so 14 must go to
by (iii), so 14 must go to 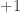 , so
, so  . I get similar contradictions in other cases.
. I get similar contradictions in other cases.
February 2, 2010 at 2:07 pm
You’re right. My mistake was not to notice that if you don’t have multiplicativity involving 0, then you can’t afford just to look at partial sums. So it looks as though this method cannot do better than a discrepancy of 3.
It might be possible to do the blocks of 6 going from 6m+1 to 6(m+1) instead. Actually, why did I even think that would be problematic? When I’ve got a new block to fill, it will have preassigned values at 6m+2, 6m+3, 6m+4 and 6m+6. So I’ll be safe if I make sure that 3m+1, 3m+2, 3m+3 do not all have the same value. So it seems that I can just reflect my previous proof. So I’m pretty sure discrepancy 2 does come out of this method if one applies the method more sensibly than I was doing above.
February 2, 2010 at 2:13 pm
Here’s a little check. I’ll start with the first block:
+ – – + – +
That gives me the first two blocks looking like this:
+ – – + – +
? – + + ? –
and my conditions allow me to fill the question marks in either as + – or – +. Opting for the first, for no particular reason, I get the following (up to block 3):
+ – – + – +
+ – + + – –
? – + + ? –
Once again I am free to fill in the question marks as + -, so the next stage is
+ – – + – +
+ – + + – –
+ – + + – –
? – – + ? +
This time my move is forced. I must put a plus in the first place and a minus in the second (so the function isn’t constant on either the first three terms in the block or the second three). So I get
+ – – + – +
+ – + + – –
+ – + + – –
+ – – + – +
and so on and so on.
February 2, 2010 at 2:24 pm
Yes, that definitely works!
January 30, 2010 at 5:38 pm |
Regarding the algorithmic approach to excluding multiplicative sequences of discrepancy 2, I (like Sune) find Jason’s argument fascinating. It relies on the following observation: if one already knows the partial sum f(a)+…+f(b), and if one knows f(n) for the _odd_ numbers n between 2a and 2b, then this is enough (together with f(2)) to recover the partial sum f(2a)+…+f(2b).
I am thinking now that perhaps the correct “game board” to play on is the graph on the natural numbers, in which each edge from a to b is marked with the set of all possible values one currently knows about the partial sum f[a,b] := f(a)+…+f(b). (This includes the loops a=b, which correspond to the “1SAT” information known about each individual f(a)). Note that parity and discrepancy already restricts this partial sum quite a bit:
* if a is odd and b is even, then f[a,b] is -4,-2,0,2, or 4.
* if a is even and b is odd, then f[a,b] is -2,0, or 2.
* if a and b have the same parity, then f[a,b] is -3, -1, 1, or 3.
* if b is even, f[1,b] is -2,0, or 2.
* if b is odd, then f[1,b] is -1 or 1.
(If we wish to assume drift 3 as well as discrepancy 2, we get to remove the “4”s as well, but perhaps this could be considered cheating.)
We then have the following basic moves:
* (Squares) We can start with f[n^2,n^2]=1 for all n.
* (Multiplicativity) given any two of f[a,a], f[b,b], and f[ab,ab], we can deduce the third.
* (Additivity) given any two of f[a,b], f[b+1,c], and f[a,c], we can deduce the third. In particular the set of possible values of two of these can be used to constrain the set of possible values of the third.
* (Jason’s deduction) If we know f[k,k], and we know all but one of f[a,b], f[ka,kb], and f[kn+1,kn+k-1] for all n between a and b, then we can deduce the remaining piece of information.
* Guessing.
As far as I can see this already covers all of the known deductions we have already made by hand… and it looks temptingly automatable (except for the guessing part).
January 30, 2010 at 5:52 pm
I forgot perhaps the most important axiom in the above: that f[a,a] is always known to be +1 or -1.
There is another potential deduction available: if f(a) is known to have opposite sign to f(b), then f(ab) is known to be -1. In particular, if f[a,b] and f[a+1,b-1] are known to be equal, then f[ab,ab] is known to be -1. (In fact, I think that given any two of f[a,b], f[a+1,b-1], f[ab,ab], one can deduce the third.)
Call a and b _connected_ if the value of f[a+1,b] is known. Then we can divide the natural numbers into connected components, and the goal is to connect as much as possible to 0. For purposes of visual representation, it may be worthwhile to mark the 0-connected component by a different colour (this was part of what I was trying to do with the | notation).
January 31, 2010 at 12:23 am
If I understand correctly, f[a,b] will always be either an interval of evens or an interval of odds? That is, it’s never possible to arrive at something like f[a,b]={4,0}?
January 31, 2010 at 2:13 am
Hmm, I guess you’re right; with the type of moves listed above one always preserves the interval property. I could potentially imagine some crazy chain of deductions which could somehow eliminate f[a,b]=2 while leaving both f[a,b]=0 and f[a,b]=4 untouched, but I can’t think of one off hand…
January 30, 2010 at 7:37 pm |
I can prove a very weak result towards the claim that a bounded discrepancy multiplicative function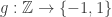 cannot be too close to a nonprincipal Dirichlet character
cannot be too close to a nonprincipal Dirichlet character  of conductor q, at least when q is prime. Namely, I can establish the bound
of conductor q, at least when q is prime. Namely, I can establish the bound
for some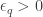 depending on q and on the discrepancy bound on g, and for sufficiently large N. This beats the trivial bound by an epsilon. The idea is that if g looks too much like chi on those numbers coprime to q, then it will look like a Walters counterexample in general.
depending on q and on the discrepancy bound on g, and for sufficiently large N. This beats the trivial bound by an epsilon. The idea is that if g looks too much like chi on those numbers coprime to q, then it will look like a Walters counterexample in general.
Indeed, suppose this were not the case. Informally, this means that for a random number n chosen coprime to q, we have with probability
with probability  .
.
Now pick two numbers n, m at random with n-m of size , for some k to be picked later, and look at the drift
, for some k to be picked later, and look at the drift  . There are basically k contributions to this drift; the contribution of those g(l) with l coprime to q; the contribution of those g(l) with l divisible by exactly one copy of q; and so forth up to those g(l) divisible by k-1 copies of q. (The contribution of the remaining term is O(1)).
. There are basically k contributions to this drift; the contribution of those g(l) with l coprime to q; the contribution of those g(l) with l divisible by exactly one copy of q; and so forth up to those g(l) divisible by k-1 copies of q. (The contribution of the remaining term is O(1)).
Let’s look at the contribution of those g(l) with l coprime to q. With probability , all the g(l) here will equal chi(l). The partial sum chi(n)+…+chi(m) fluctuates with some non-zero variance as n, m vary (in fact the variance is about sqrt(q)), so this contribution to g(n)+…+g(m) also fluctuates with this variance (up to errors of
, all the g(l) here will equal chi(l). The partial sum chi(n)+…+chi(m) fluctuates with some non-zero variance as n, m vary (in fact the variance is about sqrt(q)), so this contribution to g(n)+…+g(m) also fluctuates with this variance (up to errors of  ). Crucially, this contribution only depends on the last digit of the base q expansion of n,m (up to errors proportional to epsilon).
). Crucially, this contribution only depends on the last digit of the base q expansion of n,m (up to errors proportional to epsilon).
Now look at the contribution of g(l) with l divisible by exactly one copy of q. With probability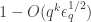 , this is equal to g(q) times a character sum which depends only on the second-to-last digit in the base q expansion of n, m, and so the covariance with the first contribution will be small.
, this is equal to g(q) times a character sum which depends only on the second-to-last digit in the base q expansion of n, m, and so the covariance with the first contribution will be small.
Similarly for all the k contributions to the drift. Thus the drift has a total variance proportional to k, which leads to a contradiction with bounded discrepancy if k is chosen large enough (and then eps is chosen small enough).
There may be some hope to amplify the epsilon gain to a much stronger gain using Granville-Soundarajan technology, but I was not able to push this through.
January 30, 2010 at 9:24 pm
OK, I can prove a much stronger bound, namely
(at least when q is prime, but I’m pretty sure the composite case works also). The argument is significantly more technical and I placed it at
http://michaelnielsen.org/polymath1/index.php?title=Bounded_discrepancy_multiplicative_functions_do_not_correlate_with_characters
The idea is this. If the above estimate fails, then by Wintner’s theorem, the sum
is bounded. This allows us to factorise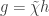 , where
, where 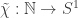 is a multiplicative function extending
is a multiplicative function extending  to the integers not coprime to q, and h is a multiplicative function which equals 1 at all primes dividing q, and which is close to 1 in the sense that
to the integers not coprime to q, and h is a multiplicative function which equals 1 at all primes dividing q, and which is close to 1 in the sense that  is finite. It turns out that the role of h can be averaged away by a version of the Maier matrix method, the upshot being that if g has bounded discrepancy, then
is finite. It turns out that the role of h can be averaged away by a version of the Maier matrix method, the upshot being that if g has bounded discrepancy, then 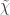 has bounded average drift on short random intervals. But the type of analysis that shows that the average drift of the Walters example diverges then shows that the average drift of the modified character
has bounded average drift on short random intervals. But the type of analysis that shows that the average drift of the Walters example diverges then shows that the average drift of the modified character 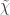 is also unbounded, contradiction.
is also unbounded, contradiction.
January 30, 2010 at 9:28 pm
p.s. the specific unproven fact I need to extend to the composite q case is the following: prove that if \tilde \chi: {\Bbb N} \to S^1 is an extension of a Dirichlet character \chi of some conductor q by setting the values of \tilde \chi(p) to some unit complex number for each p dividing q, then \tilde \chi has unbounded mean square drift, i.e.
for some (which can depend on the conductor q).
(which can depend on the conductor q).
January 30, 2010 at 9:55 pm
Correction: Wintner’s theorem is only applicable in the case when g and chi are real. In the complex case, we can still say that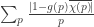 diverges, but this is not quite enough; one has to also show that
diverges, but this is not quite enough; one has to also show that  diverges too. A model case would be to establish unbounded average drift for
diverges too. A model case would be to establish unbounded average drift for  where
where 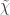 is a Walters example.
is a Walters example.
January 30, 2010 at 11:12 pm |
Tim, in the second paragraph of this post, last sentence, you write “Turning this round, in order to prove EDP it is sufficient to find a completely multiplicative function…”. Do you mean “Turning this round, in order to prove EDP it is sufficient to show that for any completely multiplicative function…”?
January 30, 2010 at 11:53 pm
I did mean that and have now changed it — thanks.
January 31, 2010 at 2:15 am |
[…] thread for Polymath5 By kristalcantwell There is a new thread for polymath5. One goal that is close to being reached that of deriving a counterexample that is […]
January 31, 2010 at 8:35 am |
Here’s a nice family of examples of non-multiplicative sequences, taking values on the unit circle, with discrepancy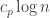 (as n goes to infinity), and
(as n goes to infinity), and  (as p goes to infinity).
(as p goes to infinity).
In short, we can have discrepancy grow arbitrarily slowly, as long as it is logarithmic. This doesn’t give sublogarithmic growth, though, as far as I can tell. “The obvious compactness argument” doesn’t work but the union of the ranges of the sequences is not finite.
Fix a prime p (might work with any odd number, haven’t checked). Set
If you take p=3, you get our old multiplicative friend $\mu_3$, but for other primes it won’t be multiplicative. The discrepancy is worst when the base p expansion of N has alternating blocks of digits (p-1)/2, 0, and the blocks themselves have length (p-1)/2. That is, when
This means that is bounded by
is bounded by 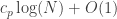 (and
(and 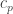 cannot be improved), where
cannot be improved), where
with B_p being the maximum (over K) absolute value of the sum of K distinct (p-1)-th roots of unity. Symmetry insists that K=(p-1)/2, and an integral shows that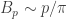 as p goes to infinity.
as p goes to infinity.
January 31, 2010 at 8:49 am
Actually, this doesn’t give , but
, but  . Same discrepancy, though. 🙂
. Same discrepancy, though. 🙂
January 31, 2010 at 9:07 am
Left out a key part, so here goes again:
where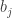 is the least significant nonzero base-p digit of k, i.e.,
is the least significant nonzero base-p digit of k, i.e.,
and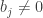 .
.
Now we get correctly.
correctly.
January 31, 2010 at 12:54 pm
That is extremely interesting. As far as putting together the examples goes, how about simply choosing a very rapidly increasing sequence and starting with
and starting with 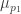 for a long time, then letting
for a long time, then letting  take over for much much longer, and so on. It seems to me that that should give sublogarithmic growth, but I have not checked this properly.
take over for much much longer, and so on. It seems to me that that should give sublogarithmic growth, but I have not checked this properly.
January 31, 2010 at 1:13 pm
Thinking about it slightly further, I see that all you get out of that argument is a function that agrees with a sublogarithmic function for most of its values, but has occasional “big bits” just when a new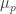 takes over. It seems just about conceivable that the big bits could be controlled if the sequence of the
takes over. It seems just about conceivable that the big bits could be controlled if the sequence of the  grows at a very carefully chosen rate, but perhaps you’ve already tried that.
grows at a very carefully chosen rate, but perhaps you’ve already tried that.
January 31, 2010 at 1:53 pm
Actually, I can’t seem to reproduce your calculations. E.g. if I take to be the number whose base-p expansion consists of a string of p-2 digits each equal to p-2, then for each digit I get a contribution proportional to p, and they are all pointing in reasonably similar directions, so the total seems to be proportional to
to be the number whose base-p expansion consists of a string of p-2 digits each equal to p-2, then for each digit I get a contribution proportional to p, and they are all pointing in reasonably similar directions, so the total seems to be proportional to 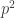 , whereas you seem to be claiming that it should be more like p. Am I misunderstanding something?
, whereas you seem to be claiming that it should be more like p. Am I misunderstanding something?
More generally, if I do your alternating blocks up to , then I seem to get about
, then I seem to get about 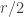 contributions of size
contributions of size  . But
. But 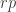 is logarithmic in
is logarithmic in  with a constant equal to about
with a constant equal to about 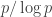 .
.
January 31, 2010 at 1:59 pm
Kevin, when you talk about “discrepency” do you mean the minimum of |u(1)+u(2)+…+u(s)| over all s, or the minimum of |u(r)+u(2r)+…+u(sr)| over all s and r?
January 31, 2010 at 5:26 pm
@Gil: I mean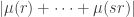 with
with  , but actually I can get away with just taking
, but actually I can get away with just taking  , i.e., the discrepancy over all HAPs of length at most N.
, i.e., the discrepancy over all HAPs of length at most N.
@Gowers: the sum of p-2 (p-1)-th roots of unity has length 1, not proportional to p. Here’s what it looks with p=5:
1, i, -1, -i, *, 1, i, -1, -i, *, 1, i, -1, -i, *, …
and the * positions are filled in with i times original sequence. So take, for example, the number 93=(333)_5 = 3+3*5+3*5^2, and look at the 1-HAP. The non starred entries cancel perfectly up 90 (any multiple of 5), so the 0-th digit contributes The 1-th digit is telling the same story, but different by a factor of i, and the 2-th digit also. The total sum is i+i(i)+i^2(i)= -1.
The 1-th digit is telling the same story, but different by a factor of i, and the 2-th digit also. The total sum is i+i(i)+i^2(i)= -1.
If we take a HAP with a different difference (relatively prime to 5), then we encounter 1,i,-1,-i in a different order, but the partial sums can never be larger than the sum of (p-1)/2 distinct (p-1)-th roots of unity, which is proportional to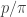 . But the partial sums can’t all be in the same direction, so we can only use some of the digits (specifically, (p-1)/2 consecutive of them) before their contributions start canceling.
. But the partial sums can’t all be in the same direction, so we can only use some of the digits (specifically, (p-1)/2 consecutive of them) before their contributions start canceling.
January 31, 2010 at 6:59 pm
I still don’t understand. I thought you were taking (p-1)th roots of unity. So if they all had the same real part (say) then their sum would be proportional to
(p-1)th roots of unity. So if they all had the same real part (say) then their sum would be proportional to  .
.
February 1, 2010 at 12:21 am
Mea culpa. I’ve put a page on the wiki about these “sequences inside sequences”, together with some more careful analysis.
January 31, 2010 at 10:59 am |
During the weekend I have had my laptop running a numerical optimization of the bounds for which we discussed in EDP3. I only have the newer version of Mathematica on my laptop so the computer power is a bit limited, going to very large N won’t be possible. I have stopped it at N=162, the program became very slow there due to convergence issues.
which we discussed in EDP3. I only have the newer version of Mathematica on my laptop so the computer power is a bit limited, going to very large N won’t be possible. I have stopped it at N=162, the program became very slow there due to convergence issues.
The function seem to grow with N in some averaged sense but so far it is very slow. The largest value so far is at N=106. Of course these values just given upper bounds so the actual might look a lot smoother than this.
might look a lot smoother than this.
1 1
2 0.5
3 0.666667
4 0.5
5 0.6
6 0.483479
7 0.503304
8 0.479167
9 0.447818
10 0.460806
11 0.472545
12 0.468074
13 0.585487
14 0.710418
15 0.581781
16 0.609681
17 0.526271
18 0.821528
19 0.555702
20 0.544255
21 0.636351
22 0.638662
23 0.620485
24 0.593714
25 0.580997
26 0.619162
27 0.580855
28 0.594115
29 0.685231
30 0.640371
31 0.54843
32 0.555241
33 0.54944
34 0.630623
35 0.665369
36 0.745321
37 0.68153
38 0.694372
39 0.688013
40 0.716293
41 0.661672
42 0.61903
43 0.669616
44 0.882534
45 0.646652
46 0.64194
47 0.720927
48 0.715691
49 0.714287
50 0.714992
51 0.6873
52 0.714129
53 0.673898
54 0.666955
55 0.649217
56 0.645026
57 0.614902
58 0.744963
59 0.578639
60 0.622614
61 0.607828
62 0.613894
63 0.608645
64 0.644923
65 0.615707
66 0.610113
67 0.780978
68 0.876556
69 0.762183
70 0.735395
71 0.670059
72 0.694098
73 0.641678
74 0.73389
75 0.873068
76 0.705054
77 0.70888
78 0.701652
79 0.624973
80 0.610835
81 0.636283
82 0.652326
83 0.660632
84 0.765096
85 0.579408
86 0.580369
87 0.605098
88 0.592405
89 0.720926
90 0.781486
91 0.827351
92 0.7502
93 0.8206
94 0.884964
95 0.766429
96 0.752079
97 0.697562
98 0.640478
99 0.704579
100 0.730287
101 0.630705
102 0.639509
103 0.681307
104 0.817685
105 0.678058
106 0.897829
107 0.690394
108 0.687429
109 0.770485
110 0.840522
111 0.676706
112 0.788423
113 0.684691
114 0.695113
115 0.761684
116 0.69835
117 0.712146
118 0.734709
119 0.714968
120 0.692735
121 0.680937
122 0.689354
123 0.687253
124 0.708181
125 0.686347
126 0.683641
127 0.87761
128 0.876063
129 0.717313
130 0.651288
131 0.692895
132 0.692185
133 0.691533
134 0.687049
135 0.788358
136 0.838413
137 0.648503
138 0.711188
139 0.660303
140 0.643054
141 0.665965
142 0.670468
143 0.670249
144 0.666047
145 0.665071
146 0.672926
147 0.694047
148 0.679214
149 0.764711
150 0.762369
151 0.871283
152 0.809401
153 0.787526
154 0.816172
155 0.72975
156 0.725393
157 0.749477
158 0.715519
159 0.735794
160 0.739057
161 0.707623
162 0.646294
January 31, 2010 at 6:54 pm
I had the thought that, since we’re optimizing a rational expression whose gradient is easily calculated, that “FindMinimum” might be a better route than “Minimize”. The downside is that FindMinimum (which will just follow the gradient from a starting point to a local minimum) depends on a starting point. But even if you have to choose many starting points (randomly, with Gaussian distribution?) it should still be fast.
Also, you should put these numbers (and more interestingly the values for y_i that achieve them) on the wiki!
January 31, 2010 at 7:50 pm
I have been using the NMinimize function which is in the newer versions of Mathematica. It is a ne function tries to find the global minimum.
I had intended to provide the y_i too but due to a mistake of mine the program only kept the values for the last N. But I’ll run the program again and put the results on the wiki.
January 31, 2010 at 9:19 pm
I have now started the new run. I have used randomness and more iteration for each N. The values are now consistently smaller and less noisy, but the program is also slower. I’ll post the results of the nights run on the wiki tomorrow. including the values of the y_i.
The results are now very close to those Kevin obtained earlier, the first few values as read from my progress print out are
2 0.5
3 0.5
4 0.5
5 0.4801338227148131
6 0.4834785819233648
7 0.4438473047036603
8 0.44836058320767935
February 1, 2010 at 1:46 pm
I have now posted the bounds and values for
values for  on the wiki http://michaelnielsen.org/polymath1/index.php?title=Omega(N)
on the wiki http://michaelnielsen.org/polymath1/index.php?title=Omega(N)
The formatting of the solutions is not very human friendly right now, but I can try to do something about that later when I add some more values.
The values of the minima are now smaller and less noisy in their behaviour than those found by the first program.
February 2, 2010 at 10:06 am
I have now added upper bounds for N up to 84, and a plot of the bounds. The program is quite slow now so unless there is a request for more values I will stop at N=84.
January 31, 2010 at 2:38 pm |
Here’s an observation. It’s very simple (and I’m sure others have also noticed it) but I mention it because it places some restrictions on what a proof could look like.
I’m still thinking about how one might go about proving that a multiplicative function that is not character-like has large discrepancy. One of the things I was hoping to show was some kind of dichotomy: if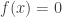 for every multiple of
for every multiple of  and
and  otherwise, I was hoping that
otherwise, I was hoping that  would either have to be similar to the Legendre character mod
would either have to be similar to the Legendre character mod  or it would become like a random function. But that is nonsense (and indeed, I had already basically seen that it was nonsense, but two bits of my brain had become disconnected), since you can just take another character-like function and zero out the multiples of
or it would become like a random function. But that is nonsense (and indeed, I had already basically seen that it was nonsense, but two bits of my brain had become disconnected), since you can just take another character-like function and zero out the multiples of  . (The particular lemma I was trying to prove before I realized I was being stupid was that in the case
. (The particular lemma I was trying to prove before I realized I was being stupid was that in the case 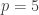 you would either have to have the Legendre character or you would at some point get four pluses or four minuses in some interval. That is false if you take
you would either have to have the Legendre character or you would at some point get four pluses or four minuses in some interval. That is false if you take  at non-multiples of 5.)
at non-multiples of 5.)
January 31, 2010 at 2:46 pm |
Here, however, is an amusing question. Suppose that you have a multiplicative function that is zero at multiples of 5 and at non-multiples. Suppose also that
at non-multiples. Suppose also that  for every
for every  . Does it follow that
. Does it follow that  is the Legendre character? So far I have thought about it non-theoretically: a brute-force algorithm with a bit of looking ahead easily shows (without any guessing) that it has to be the Legendre character at least as far as 35. I’ll carry on the process and see where I get.
is the Legendre character? So far I have thought about it non-theoretically: a brute-force algorithm with a bit of looking ahead easily shows (without any guessing) that it has to be the Legendre character at least as far as 35. I’ll carry on the process and see where I get.
Of course, the algorithm will go on successfully for ever if it gets to and there are no twin primes beyond
and there are no twin primes beyond  , but this may not be the way to go …
, but this may not be the way to go …
January 31, 2010 at 3:55 pm |
Latest on the above calculation is that I’ve now got it up to 100, but I had some trouble with 53, because you have to go a long way with 53 before you reach a multiple that has no prime in its little cluster of 4. However, 53 times 12 is 636, and the numbers 637 and 638 are both 53-smooth, and 639 is 9 times 71 and it so happens that 71 is forced (by the values at 2,3,5 and 37).
At the moment it looks as though it is very unlikely that the algorithm won’t just work for ever (even if there are plenty of twin primes), but whether there is any hope of proving it I’m not sure.
January 31, 2010 at 5:02 pm
There is an obvious follow up question to this one: let be a prime and let
be a prime and let  be a completely multiplicative function that has modulus 1 at non-multiples of
be a completely multiplicative function that has modulus 1 at non-multiples of  and zero at multiples of
and zero at multiples of  and sums to zero on every block of
and sums to zero on every block of 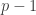 consecutive non-multiples. Must
consecutive non-multiples. Must  be a non-trivial Dirichlet character? (In the real case, must it be the Legendre character?)
be a non-trivial Dirichlet character? (In the real case, must it be the Legendre character?)
I think this question may be rather hard, but perhaps there is some hope of proving that must be close to a Dirichlet character (in the Granville-Soundararajan sense). Or, even less ambitiously, perhaps there is some chance of proving that when
must be close to a Dirichlet character (in the Granville-Soundararajan sense). Or, even less ambitiously, perhaps there is some chance of proving that when  is some small prime like 5.
is some small prime like 5.
I also didn’t mention the easy fact that if then we are done very simply, because you are always given the value at one of
then we are done very simply, because you are always given the value at one of  and
and 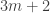 and that determines the value at the other. (Usually the determined value is whichever is even, but when
and that determines the value at the other. (Usually the determined value is whichever is even, but when 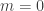 we know the value at 1.)
we know the value at 1.)
February 1, 2010 at 1:22 am
It seems likely that w can prove that there exists an N such that if f is known to be forced to equal the Dirichlet character up to N, then it is equal the Dirichlet character everywhere, which in principle reduces things to a finite verification.
The reason is that if one can specify f up to N, then one can already get f(p) for “most” primes of size between N and 2N, because most of them are going to be in a 5-block of N-smooth numbers. Indeed, of the N/log N or so primes in this range, sieve theory (Brun’s theorem, basically) tells us that at most O( N / log^2 N ) primes are unlucky enough to share a 5-block with a prime, or twice a prime. Call these the _unlucky_ primes.
But then I think we can amplify this, because we can also work out f(p) if ap lies in a 5-block that does not involve any other unlucky primes for some a << N. With this, I think one can soon winnow down the set of unlucky primes to have size O( N / log^A N) for any fixed A.
There is a problem if one has a lot of non-smooth numbers in near-perfect arithmetic progression. Standard heuristics (Cramer model) suggest that this can't happen, but I get the feeling that this sort of problem remains highly open. Still, conditional on standard number-theoretic conjectures one should be able to establish that there are only finitely many potentially unlucky primes.
February 1, 2010 at 10:01 am
Essentially you are giving a theoretical justification for the algorithm I was describing, and my experience bears out what you write quite well (including parts of it that I didn’t write about). The first really problematic block of smooth numbers came between 100 and 110, where one has the primes 101, 103, 107 and 109 (lying in a nice arithmetic progression of length 5) and the non-smooth number 106, which happened to be twice the rather troublesome prime 53. With some effort I eventually established that 53 was OK, as I reported above, but that doesn’t help with the primes.
My guess is that by looking at a few multiples of each of 101, 103, 107 and 109 one would find for each one a non-unlucky place where it was surrounded by sufficiently smooth (or odd-smooth) numbers, but I agree that it seems hard to prove this unconditionally for all primes.
January 31, 2010 at 8:14 pm |
Here is a natural question I think (I apologize if somebody already raised this question): How about the analogue with natural numbers replaced by the polynomial ring R = Z/2Z[x]? (Of course you can replace 2 by any prime number.)
What would this mean? Consider a function f : R –> {1, -1}. For every integer d and polynomial P the discrepancy D_{d, P} is the absolute value of the sum f(QP) where Q ranges over polynomials of degree less than or equal to d. Is it easy to find such f with low/bounded discrepancy D_{d, P} for all degrees d and polynomials P?
I think the above is the correct version, but an alternative which looks more like the original problem would be to enumerate all polynomials Q_1 = 0, Q_2 = 1, Q_3 = x, Q_4 = x + 1, Q_5,… such that the degree of Q_i is always <= the degree of Q_{i + 1}. Having done this we can define discrepancies D'_{n, P} where we take the absolute value of the sum of f(Q_iP) where i ranges from 1 to n. Again we ask if it is possible to find such f with low discrepancy D'_{n, P} for all integers n and polynomials P?
It seems to me that some of Terry's Fourier reduction argument applies equally well to such f, no? (At least what I understood of it seems to work.) Is this correct, and if so what do we get?
Thanks!
January 31, 2010 at 8:53 pm
Suppose that we have a polynomial . We could define
. We could define 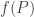 to be 1 if the first
to be 1 if the first  such that
such that  is even and -1 otherwise. It seems to me that that function would have discrepancy 1, but I may have made a mistake or misunderstood the question.
is even and -1 otherwise. It seems to me that that function would have discrepancy 1, but I may have made a mistake or misunderstood the question.
January 31, 2010 at 9:07 pm
Tim, I think your example has unbounded discrepancy: for instance the sum of f(P) for all P of degree at most d seems to be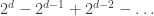 , which diverges exponentially in d. (This is analogous to the multiplicative function f(n) on the integers which equals -1 at 2 but 1 at all other primes.)
, which diverges exponentially in d. (This is analogous to the multiplicative function f(n) on the integers which equals -1 at 2 but 1 at all other primes.)
Actually this seems to be a rather good model question (unsurprising, given how nicely function fields model number fields in so many other ways). Certainly the Fourier reduction should work just fine, and there are analogues of Dirichlet characters and the Walters example. My argument that a bounded discrepancy function can’t correlate with a Dirichlet character should also extend, I think, to this setting. And we have GRH here, for all the good it does us… (and infinitely many twin primes too (in characteristic greater than 2 of course), since Tim raised a connection to that problem in a previous comment).
One could imagine having a rather clean induction-on-degree argument here, which would be much messier in the integer case
January 31, 2010 at 9:13 pm
My reasoning was that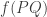 should always equal
should always equal  and that the map
and that the map  is a bijection from the polynomials of degree
is a bijection from the polynomials of degree  to themselves. I’m probably being blind in some way but I still haven’t understood my mistake.
to themselves. I’m probably being blind in some way but I still haven’t understood my mistake.
January 31, 2010 at 9:15 pm
Hang on, I take it back, there does seem to be a key difference between the integer case and the function field case: in the integer case there are many intervals [1,n] inside [1,N] (N of them, in fact) but in the function field case F_q[t] there are only d subspaces to consider inside the polynomials of degree at most d, so having bounded discrepancy is a much weaker constraint in this setting.
Now that I think about it a bit more, I think one could create a completely multiplicative function g on F_q[t] with bounded discrepancy by having g(p)=-1 for precisely half of all the irreducible polynomials p of a given degree d. I’ll check the details and report back soon.
January 31, 2010 at 9:19 pm
I think the map I proposed has that property …
January 31, 2010 at 9:47 pm
Tim: OK, so let’s enumerate the mod 2 polynomials as
0,1,x,x+1,x^2,x^2+1,x^2+x,x^2+x+1,x^3,x^3+1,x^3+x,x^3+x+1,x^3+x^2,x^3+x^2+1,x^3+x^2+x,x^3+x^2+x+1,x^4,… What is the example you are proposing? Note that the first a_i which is nonzero is always 1 mod 2, so I did not understand your example. Thanks.
Terry: Yes, I agree, which is why I gave the second version, but it may also be somehow very different.
January 31, 2010 at 9:53 pm
Oops, you mean i odd/even. OK, sorry
January 31, 2010 at 9:56 pm
This is actually a remarkably subtle problem.
I can find a completely multiplicative function![g: F_p[t]_m \to S^1](https://s0.wp.com/latex.php?latex=g%3A+F_p%5Bt%5D_m+%5Cto+S%5E1&bg=ffffff&fg=333333&s=0&c=20201002) on the monic polynomials in
on the monic polynomials in ![F_p[t]](https://s0.wp.com/latex.php?latex=F_p%5Bt%5D&bg=ffffff&fg=333333&s=0&c=20201002) (this is the correct analogue of the natural numbers, I think) which sums to 1 on the space
(this is the correct analogue of the natural numbers, I think) which sums to 1 on the space  of monic polynomials of degree at most d for every d. The key is to choose g so that the prime discrepancies
of monic polynomials of degree at most d for every d. The key is to choose g so that the prime discrepancies
all vanish, where p ranges over monic irreducibles of degree d. This is possible because the g(p) are completely unconstrained in S^1, and number of such irreducibles of degree d is given by the Riemann hypothesis for function fields, specifically by the formula
and in particular there are always at least two irreducibles of any given degree.
The discrepancies
are related to the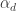 by the Euler product formula
by the Euler product formula
and so if we set all the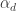 to vanish, all the
to vanish, all the  for
for 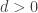 will vanish also, leading to bounded discrepancy.
will vanish also, leading to bounded discrepancy.
The situation becomes more interesting if g is constrained to equal +-1. Then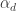 has to be an integer of the same parity as
has to be an integer of the same parity as 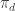 and of equal or lesser magnitude. I don’t know how to determine if one can choose such an
and of equal or lesser magnitude. I don’t know how to determine if one can choose such an 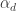 to make the partial sums of
to make the partial sums of  bounded, which is the analogue of bounded discrepancy here. If we choose the
bounded, which is the analogue of bounded discrepancy here. If we choose the 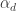 coming from a Dirichlet character with a prime conductor of degree
coming from a Dirichlet character with a prime conductor of degree  , then this almost works (the
, then this almost works (the  vanish for
vanish for 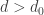 ) but
) but 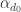 has the wrong parity (we deleted a prime at this degree). Tweaking the parity here causes
has the wrong parity (we deleted a prime at this degree). Tweaking the parity here causes 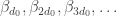 to become non-zero creating the same log-divergence we saw in the Walters example. There is a possibility that one can tweak a character with composite conductor to fix this, but I have not checked this.
to become non-zero creating the same log-divergence we saw in the Walters example. There is a possibility that one can tweak a character with composite conductor to fix this, but I have not checked this.
January 31, 2010 at 10:00 pm
Tim, it is not true that f(Q+1) is always equal to -f(Q) in your example. For instance f(x^2+1) = f(x^2) = 1.
January 31, 2010 at 10:02 pm
I wasn’t taking the first that is non-zero but the first
that is non-zero but the first  such that
such that  is non-zero. So 1 goes to 1, x goes to -1, x+1 goes to 1, x^2 goes to 1, x^2+x goes to -1, x^2+1 goes to 1, x^2+x+1 goes to 1, and so on. To gives one more example, x^7+x^4 goes to 1 because 4 is even.
is non-zero. So 1 goes to 1, x goes to -1, x+1 goes to 1, x^2 goes to 1, x^2+x goes to -1, x^2+1 goes to 1, x^2+x+1 goes to 1, and so on. To gives one more example, x^7+x^4 goes to 1 because 4 is even.
Ah, but I see now that I was making a mistake because it is not the case that and
and 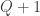 always get different values. However, I think it may be possible to salvage the basic idea.
always get different values. However, I think it may be possible to salvage the basic idea.
What we can say is that if is of the form
is of the form  , then
, then 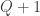 and
and  have different values. For any
have different values. For any  we can partition the polynomials of degree
we can partition the polynomials of degree  into equivalence classes … oh no, this doesn’t work either. OK, I’ve finally seen what I was doing wrong.
into equivalence classes … oh no, this doesn’t work either. OK, I’ve finally seen what I was doing wrong.
January 31, 2010 at 10:03 pm
Terry, just to say that I was writing that last message while you were writing yours …
January 31, 2010 at 10:13 pm
Gah, I messed up the Euler product formula. The situation is more complicated than I thought and also requires knowledge of the higher moments (though these moments collapse in the +-1 valued case. So my S^1 counterexample doesn’t work as stated).
(though these moments collapse in the +-1 valued case. So my S^1 counterexample doesn’t work as stated).
In the +-1 case, the Euler product formula is in fact
where is the number of monic irreducibles p of degree d with g(p)=+1, and m_d is the number with g(p)=-1. It looks quite hard in fact to select n_d and m_d to make the partial sums of beta_d stay bounded.
is the number of monic irreducibles p of degree d with g(p)=+1, and m_d is the number with g(p)=-1. It looks quite hard in fact to select n_d and m_d to make the partial sums of beta_d stay bounded.
February 1, 2010 at 10:02 am
By the way, I meant to say that I liked this question very much (particularly when I saw what was wrong with my “counterexample”).
January 31, 2010 at 10:19 pm |
Let me ask a question about the basic strategy. We consider a multiplicative function and want to examine the discrepency taking to account how the function is related to Direchlet characters. By now we know that if g has positive correlation to a specific character associated to a prime q then it has unbounded discrepency. Now what happend if g has positive “combined” correlation to all characters associated to q. What I mean by “combined” is that we take the sum of correlation squared or something like that. (And I rely of my vague knowledge that these characters for a fixed prime are orthogonal).
So maybe it make sense to try to consider the case where g has positive correlation with the space of all characters associated to the prime q, not just a single one.
February 2, 2010 at 8:20 am
Of course, this type of distinction requires us to consider q tending to infinity along with N (but probably much slower).
January 31, 2010 at 10:25 pm |
I’m starting a new thread as the old one was getting too confusing. (The transparency of the polymath approach is a double-edged sword: on the plus side, you get to see the thought processes of the participants before they are fully polished, but on the minus side… you get to see the thought processes of the participants before they are fully polished.)
I have changed my mind (again) and now think that it is indeed possible to create a multiplicative function![g: F_p[t]_{monic} \to \{-1,+1\}](https://s0.wp.com/latex.php?latex=g%3A+F_p%5Bt%5D_%7Bmonic%7D+%5Cto+%5C%7B-1%2C%2B1%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) with bounded discrepancy in the sense that
with bounded discrepancy in the sense that  is bounded, in fact it should be possible to keep it in {0,+1} for all d (for p large enough, at least). The point is that the Ponzi strategy of, at each degree d, setting
is bounded, in fact it should be possible to keep it in {0,+1} for all d (for p large enough, at least). The point is that the Ponzi strategy of, at each degree d, setting  to equal whatever it needs to be to fix the discrepancy at degree d to be small, and postponing until later the the consequences of this on the calculations at later d, should actually work in the function field case because one has a huge amount of leeway as to what to set
to equal whatever it needs to be to fix the discrepancy at degree d to be small, and postponing until later the the consequences of this on the calculations at later d, should actually work in the function field case because one has a huge amount of leeway as to what to set  equal to; the parity is constrained, but otherwise any number up to size
equal to; the parity is constrained, but otherwise any number up to size  (which is bsaically the number of monic irreducibles of degree d, by the prime number theorem for function fields) is available. On the other hand, heuristically the bounded discrepancy of g up to degree d should make
(which is bsaically the number of monic irreducibles of degree d, by the prime number theorem for function fields) is available. On the other hand, heuristically the bounded discrepancy of g up to degree d should make 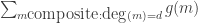 grow sub-exponentially in d (I have not checked this but it looks plausible), so there is enough flexibility to balance the books at each degree, I think.
grow sub-exponentially in d (I have not checked this but it looks plausible), so there is enough flexibility to balance the books at each degree, I think.
January 31, 2010 at 10:36 pm
OK, yes, I agree this should work. Thanks!
January 31, 2010 at 11:00 pm
I wrote up a sketch of the above argument, which in fact gives a completely multiplicative sequence of drift 1 in the function field case if the field is big enough, at
http://michaelnielsen.org/polymath1/index.php?title=Function_field_version
February 1, 2010 at 12:58 am |
Does anyone know whether the following question is either (i) something people know something about or (ii) obviously hopelessly difficult? Let be the Liouville function. What I’d like to know is whether if you choose a random integer
be the Liouville function. What I’d like to know is whether if you choose a random integer  , then the pair
, then the pair 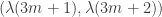 is approximately uniformly distributed in
is approximately uniformly distributed in  . (Does one e.g. run up against the parity problem?) This is, needless to say, a toy problem, but if this is hopeless then I’ll know not to pursue the line of thought that lies behind it. That line of thought, by the way, is that it ought to be the case that if you choose the values of a multplicative function at the primes in a way that has no respect for small congruences, then it should behave randomly, and therefore have unbounded drift. One way of proving unbounded drift would be to show that the function had long strings of 1s, which is of course false for character-like functions, but I’m wondering if there is at least an identifiable class of multiplicative functions for which it is true. But I don’t know whether anyone knows how to say anything about how
. (Does one e.g. run up against the parity problem?) This is, needless to say, a toy problem, but if this is hopeless then I’ll know not to pursue the line of thought that lies behind it. That line of thought, by the way, is that it ought to be the case that if you choose the values of a multplicative function at the primes in a way that has no respect for small congruences, then it should behave randomly, and therefore have unbounded drift. One way of proving unbounded drift would be to show that the function had long strings of 1s, which is of course false for character-like functions, but I’m wondering if there is at least an identifiable class of multiplicative functions for which it is true. But I don’t know whether anyone knows how to say anything about how  relates to
relates to  when
when  is multiplicative.
is multiplicative.
February 1, 2010 at 5:09 am
Yes, this is a very hard problem (as Ben points out below). One person who has made significant progress on a generalization of this problem is A. Hilbebrand. He showed that if is a completely multiplicative function such that
is a completely multiplicative function such that
then
(Hildebrand proved this by combining the Large Sieve with a certain local mean value theorem of his for multiplicative functions.)
I have a paper that proves
(It uses some diophantine approximation, in combination with the local mean value theorem of Hildebrand. My proof is quite different from Hildebrand’s theorem above, and my theorem is not [easily] deducible from Hildebrand’s.)
Also, it is worth noting that Haman, Pintz and Wolke proved that
February 1, 2010 at 3:23 am |
Tim,
I’m pretty sure this last one is indeed hopeless, in that it’s on the level of the Twin Prime Conjecture. Someone (Christian Mauduit I think) once told me that it is not known if the average of $$\lambda (n)\lambda(n+1)$$ for $$n = 1,\dots N$$ is $$1 – o(1)$$ or not (of course it can’t be….)
Ben
February 1, 2010 at 6:16 pm
True… on the other hand, if we take two-parameter patterns, such as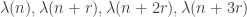 , then we have equidistribution, thanks to our Mobius-nilsequences paper and the inverse conjecture for the Goers norms. Not that this seems to be of any direct use here, as our result only works when the parameters n, r all have the same size (though one could potentially improve this if one assumed some strong bounds on short prime exponential sums).
, then we have equidistribution, thanks to our Mobius-nilsequences paper and the inverse conjecture for the Goers norms. Not that this seems to be of any direct use here, as our result only works when the parameters n, r all have the same size (though one could potentially improve this if one assumed some strong bounds on short prime exponential sums).
February 1, 2010 at 4:11 am |
Coming back to Tim’s toy problem of a completely multiplicative function f that sums to zero on any block 5n+1,…,5n+4 of consecutive numbers coprime to 5, suppose that p is the first prime in which f differs from the Dirichlet character chi. This should presumably lead to a contradiction if p is large enough.
Indeed, if 1 < a < p is any integer coprime to 5, then ap must be within 4 of a non-p-smooth integer, i.e. one divisible by a prime q larger than p, otherwise ap would be in a 5-block in which f and chi were already known to agree, and then f and chi would necessarily agree on ap and hence on p.
In particular, by the pigeonhole principle there is a progression of the form {ap + j, 1 < a < p} with 0 < |j| < 5 that contains a positive density of non-p-smooth numbers. This seems extremely unlikely but I was not quite able to rule it out. Strangely, this problem of producing non-smooth numbers reminds me of some topics we discussed for Polymath4…
February 1, 2010 at 6:20 am
Hmm, I can maybe envisage a 2-stage argument along these lines, but not with details as yet. Suppose one has shown that f(p) = chi_5(p) for all p < X. One wants to extend this to a new range, say X < p < X^2.
Step (i): Show that some variant of your argument works except for o(X) "bad" primes p (this is a pretty strong requirement, I admit…)
Step (ii); If p is bad try and apply your argument again, obtaining some progression ap + j, 0 < a < p, at least 1/5 of whose elements are divisible by a bad prime p (otherwise, there is some a such that ap + 1,…ap+5 are all divisible by only good primes and primes < X, in which case we're done). But no bad prime q (in fact no prime q between X and X^2 at all) can divide ap + j for more than one value of a, by the Chinese Remainder Theorem.
Step (i) is the stumbling block, then.
February 1, 2010 at 4:51 am |
Terry,
The p-smooth numbers less than p^2 have positive density strictly between zero and one, see this reference:
Click to access 09andrew.pdf
So the thing you deem to be extremely unlikely isn’t all that unlikely after all.
The proportion of p smooths less than p^m is also positive, but decays like m^{-m}. So it might be possible to play the game you suggest, but by letting a range over p-smooths up to p^{m-1}. For a suitably large value of m it seems as though one might wind up with an example which is indeed extremely unlikely.
There is a huge literature on smooth numbers in arithmetic progressions (e.g. by Google Search for this expression), so it’s not completely impossible that one might be able to prove these assertions.
A lot of work for a model problem though.
February 1, 2010 at 5:04 am |
Sorry, in my last remark I forgot that we want smooth numbers in our arithmetic progression, not non-smooths. If what I suggested is to have a chance of working, one needs to let a range between 1 and p^{eps} for some small eps.
February 1, 2010 at 5:57 am |
See
Click to access discrepancy.pdf
for a vague suggestion for an approach to proving unbounded discrepancy for completely multiplicative functions. (I decided to write it up as a latex file, instead of a wordpress posting, since it has a few formulas that I might not get to parse without multiple attempts on my part).
completely multiplicative functions. (I decided to write it up as a latex file, instead of a wordpress posting, since it has a few formulas that I might not get to parse without multiple attempts on my part).
February 1, 2010 at 9:48 am
A couple of remarks about that idea. One is that the troublesome example you give is by no means the only one. For instance 1 -1 1 -1 1 -1 … has bounded correlation with any shift of 1 1 -1 -1 1 1 -1 -1 … The other is that I still find myself wanting to apply the Sune test: if you think about what happens with character-like functions such as , then it looks as though to get unbounded discrepancy you’d need your configuration to be exponentially large.
, then it looks as though to get unbounded discrepancy you’d need your configuration to be exponentially large.
I don’t know whether either of these points is a real problem for the idea, but am mentioning them because you’ll probably be able to assess that much more quickly.
February 1, 2010 at 6:04 pm |
I think I’ve managed to show that a _derivative_ of a bounded discrepancy multiplicative function g correlates with a (possibly principal) character.
Informally, here’s what happens. Let n be a random large number (e.g. drawn uniformly from [N] for some large n). By hypothesis, we have
for every H (much smaller than N). Expanding this out, we get
where are the correlations
are the correlations
(let’s take g real for simplicity, so that I can ignore complex conjugation signs).
Setting H to be a moderately large number, H = O(1), (*) already shows that at least one of the c_h is non-trivial (and negative), indeed, we have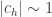 for some non-zero
for some non-zero  . On the other hand, (*) also shows that all the
. On the other hand, (*) also shows that all the  for
for 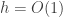 can’t be equal to each other, and in particular it is not hard to see from (*) that there exists some non-negative h=O(1) such that
can’t be equal to each other, and in particular it is not hard to see from (*) that there exists some non-negative h=O(1) such that 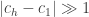 .
.
In other words, we see that the correlations
and
are significantly distinct from each other. But by multiplicativity, the first correlation is (morally) the same as
where n is constrained to be a multiple of h. (This is cheating a bit because we have to pretend that the distribution on [N] is close to that on [hN], but I am hoping that this will be plausible with enough averaging). Thus, the random variable g(n) g(n+h) has a significant bias with respect to the divisibility of n with respect to h, and so g(n) g(n+h) must therefore correlate with a character of conductor h (but this may be the principal character).
Not sure what to make of this observation…
February 1, 2010 at 6:11 pm
(Incidentally, for the record, the way I found this argument was in trying to compute the discrepancy of a Dirichlet character of conductor q for medium size q. Randomness heuristics (and the Polya-Vinogradov inequality suggested to me that this discrepancy was of the order of sqrt(q); I soon found a Fourier-analytic proof of this fact, and then converted it to physical space using correlations. I then observed that the correlations were all the same except when h was not coprime to q, and saw how equality of correlation was related to equidistribution of g(n) g(n+h) wrt small moduli, leading to the above argument.)
February 1, 2010 at 6:14 pm
Huh. I guess this means that these functions g are large in the local U^3 Gowers uniformity norm!? I would not have expected this type of theory to come into play…
February 1, 2010 at 6:24 pm
In case it is relevant, there is a paper of P. Kurlberg on Cohn’s conjecture:
http://arxiv.org/abs/math.NT/0101242
(Par and I had discussed this ages ago, and I think we also discussed possible generalizations that might be relevant, such as where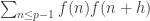 is bounded but not equal to $-1$; but, it is been so long ago, that I have completely forgotten.)
is bounded but not equal to $-1$; but, it is been so long ago, that I have completely forgotten.)
February 1, 2010 at 6:42 pm
I must be missing something very obvious, but how to you get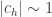 for some
for some  ? I can see how to get
? I can see how to get 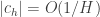 , but that isn’t useful.
, but that isn’t useful.
February 1, 2010 at 6:56 pm
Oh, I guess by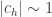 you mean
you mean  , which I suppose shows that you get the correlation you are looking for (though nowhere near as strong as
, which I suppose shows that you get the correlation you are looking for (though nowhere near as strong as  ).
).
February 1, 2010 at 8:34 pm
Very interesting and mysterious. Is it clear if or why this argument breaks when the discrepency behaves like log? (Sorry i misplaces the remark)
February 1, 2010 at 8:58 pm
Terry,
Interesting. It does look, though, that H really has to be O(1), which means that this is not detecting Gowers U^3-type behaviour but rather biases along very short arithmetic progressions.
By the way someone might have already made the following remark, but it should be noted that the condition
N^{-1} E_{n =1}^N | g(1) + … + g(n)}^2 = O(1) … (*)
by itself (that is, without using multiplicativity) does not imply anything very useful about g such as correlating with a character or having a large Fourier coefficient. Indeed if you make sure that g(2m) + g(2m + 1) = 0 for all m and otherwise choose g randomly it will satisfy (*) but will have no useful structure.
February 1, 2010 at 7:34 pm |
I have continued the human proof some more. (I had to branch once.)
February 1, 2010 at 7:46 pm
Nevermind, I was able to easily take out the branch by using the rule that when f(2n)=f(2n+1) there’s a cut between.
So everything up to basically 100 has been forced now.
February 1, 2010 at 8:01 pm
Double checked, I believe I’m done for the day if someone else wants to continue. The interesting logic bits were: (given a=-A, b=-B)
a and b can’t both be – (five -s starting at 10).
A,B can’t both be – (five -s starting at 74)
Therefore a and b can’t both be +, so a and b are alternating.
and a forced move leading to a cut:
The only way for the sum to be 0 with + + c | is if c = -1.
February 1, 2010 at 8:02 pm
I noticed a small oddity at one point but don’t dare to change anything. In the middle of case 1b you explain something by saying “otherwise the sum reaches -3 at 80”, which is surely impossible for parity reasons. In fact, looking a bit harder, it seems to me that the sum reaches -3 at 79, so it looks like a very minor matter.
February 1, 2010 at 8:04 pm
Another thing I don’t understand is that 100 is a perfect square and yet seems to have been given a minus all the way through.
February 1, 2010 at 9:03 pm
Gah, that was my fault, I think. (Yet another case for finding a more computer-verifiable way to do these sorts of calculations.) I’ll try to redo the calculations after lunch. (Also I have to cut out the erroneous computation involving f(59).)
February 1, 2010 at 11:14 pm
With the given numbers I can finish case 1b and hence case 1.
I am looking at the table at
http://michaelnielsen.org/polymath1/index.php?title=Human_proof_that_completely_multiplicative_sequences_have_discrepancy_at_least_2
right after the words so 89 is +
f(58) is positive so f(116) is positive
f(13) is positive and f(9) is a square so f(117) is positive
there is a cut between 116 and 117
f(118) is negative since f(59) is negative
f(7) and f(17) are negative so f(119) is positive
f(3) and f(5) are negative and f(2) is positive so 120 is positive
121 is a square so f(121) is positive
so at 116 the sum is zero at because there is a cut between
116 and 117 at 117 the sum is one since f(117) is positive
at 118 the sum is zero since f(118) is negative and since f(119) f(120) and f(121) are positive at 121 the sum is three and we have shown that if a completely multiplicative sequnce has f(2) equal to 1 and f(37) equal to -1 then it reaches discrepancy 3 before 246.
Since we have previously shown that if a completely multiplicative sequence that has f(2) equal to 1 and f(37)equal to 1 reaches discrepancy 3 before 246 we have any completely multiplicative sequence with f(2) equal to one reaches discrepancy 3 before 246 and that finishes case 1.
February 1, 2010 at 11:57 pm
I was just working out a string of five -ves at 122, 123, 124, 125, 126.
This, with the previous case, seems to suggest that these human algorithms could usefully monitor the sequences at significant gaps between primes.
My string of – is complete with the identification of f(31)=-1.
Krystal’s contradiction is established with values at b,c,f which is completed when f is deduced (just before the value at 31).
246 is in a gap of length 10 between the primes 241 and 251. In a multiplicative sequence:
f(242)=f(2)
f(243)=f(3)
f(244)=f(61)
f(245)=f(5)
f(246)=f(2) x f(3) x f(41)
So ‘odd smooth’ numbers concentrated in a [relatively] ‘large’ gap between primes provide the obstacle to progress.
February 2, 2010 at 4:28 am
I cut-and-paste Kristal’s argument in and started on the f(2) = – 1 case, but I admit I’m as stumped as the computer for the moment. Will ponder where the best break would be.
February 2, 2010 at 5:24 am
Assuming f(5)=+1 seems to be reasonably promising. The computer managed to make a few deductions from this (including f(241), of all things):
http://michaelnielsen.org/polymath1/index.php?title=Computer_proof_that_completely_multiplicative_sequences_have_discrepancy_greater_than_2#Assuming_f.285.29.3D.2B1
February 2, 2010 at 5:33 am
By branching on f(11) I was able to get my computer assistant to eliminate f(5)=+1 completely. So we now unconditionally have f(2)=f(5)=-1. Unfortunately this seems to be the difficult branch: there were no easy deductions from here (see above link).
February 2, 2010 at 9:35 am
It is also the branch that one would expect to be difficult, since it is consistent with or
or 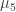 .
.
February 1, 2010 at 8:32 pm |
Very interesting and mysterious. Is it clear if or why this argument breaks when the discrepency behaves like log?
February 2, 2010 at 12:56 am |
Regarding the “human proof” that completely multiplicative sequences have discrepancy at most 2, I finally decided to code a crude proof assistant to help out here. The code (in C) and sample output is at
http://michaelnielsen.org/polymath1/index.php?title=Computer_proof_that_completely_multiplicative_sequences_have_at_least_2
There is no user interface yet; you have to recompile every time you want to do something different. Anyway, the code could not pick up the first non-trivial deduction (that f(2)=+1 implies f(19)=-1) and got stuck even with that assumption, but if you feed in either f(37)=+1 or f(37)=-1 it leads to a contradiction. The deductions it spits out are consistent with what is in the human proof.
So one knows that f(2)=-1. Unfortunately this does not lead to much as it is… one has to make more assumptions.
There appears to be a snowball effect in that once one has a dozen or more primes pinned down (including all of the small ones), then one starts to get a lot of other primes picked up quickly, and soon one reaches a contradiction. But getting to that snowball stage seems tricky…
February 2, 2010 at 12:58 am
By the way, is it easy to change the title of the page (from “at least 2” to “greater than 2”) without messing up all links to it? Actually, I was referring to the human page. The title of your semi-human page has other problems too …
February 2, 2010 at 1:27 am
Done. (The wiki software allows for automatic redirects when moving pages, so there should not be any broken links.(