I do not know how to make this question fully precise (except in ways that make the answer uninteresting), but I have wondered about it for a long time, and it has arisen again in the discussion following my recent post on the Banach space constructed by Spiros Argyros and Richard Haydon. Here I would like to say enough to enable others to think about it. One could think of this post as the beginning of polymath2, but I expect polymath2 to be somewhat different from polymath1 for various reasons: it will involve different people, it may well go much more slowly than polymath1 (I would like to think of it quietly chugging away in the background), and I am not comfortable with some of the mathematics that will be essential to formulating a good conjecture. On a more practical level, I think that having a wiki for polymath 1 (see my blogroll for a link) has worked very well as a way of organizing our collective thoughts on the density Hales-Jewett theorem, and if polymath2 gets off the ground then I would expect an accompanying wiki to be part of it from the very beginning.
A typical argument that shows that a Banach space contains a classical space.
The first thing to say is that all “normal” Banach spaces (by which, for simplicity, I will mean separable Banach spaces of infinite real sequences) contain either  or
or  for some
for some  For example, a space that is sometimes useful is the Lorentz space where the norm of a sequence
For example, a space that is sometimes useful is the Lorentz space where the norm of a sequence  is the supremum over all finite sets
is the supremum over all finite sets 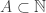 of
of 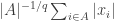 . Here
. Here  is the conjugate index of some
is the conjugate index of some  (meaning that
(meaning that 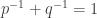 ) and the norm is designed to agree with the norm on all characteristic functions of finite subsets of
) and the norm is designed to agree with the norm on all characteristic functions of finite subsets of  (and to be the smallest such norm that has certain symmetry properties).
(and to be the smallest such norm that has certain symmetry properties).
Here is a sketch of a proof that this Lorentz space contains . You just define a sequence of vectors 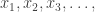 where each
where each  is the characteristic function of a set
is the characteristic function of a set  , multiplied by
, multiplied by 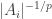 (the sets are disjoint and this normalization makes into a vector of norm 1), and you do so in such a way that the sizes of the increase very rapidly. Then when you work out the norm of any vector
(the sets are disjoint and this normalization makes into a vector of norm 1), and you do so in such a way that the sizes of the increase very rapidly. Then when you work out the norm of any vector  in the subspace generated by the , you have to choose some set
in the subspace generated by the , you have to choose some set  and work out
and work out  . You find that makes a decent-sized contribution to this sum only if has size reasonably comparable to that of , which happens for at most one
. You find that makes a decent-sized contribution to this sum only if has size reasonably comparable to that of , which happens for at most one  .
.
Tsirelson’s space.
Next, let me give the definition of Tsirelson’s space. Given a vector (that is, infinite sequence) and a finite subset  of , we write
of , we write  for the sequence that’s in and 0 outside . In other words, it is the pointwise product of with the characteristic function of . We also write
for the sequence that’s in and 0 outside . In other words, it is the pointwise product of with the characteristic function of . We also write 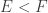 if the maximum element of is less than the minimum element of
if the maximum element of is less than the minimum element of  . Let us call a sequence
. Let us call a sequence 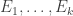 admissible if
admissible if 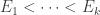 and also
and also 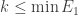 . Then there are several equivalent ways of defining the norm on Tsirelson’s space. For simplicity we shall define it just for finitely supported vectors (that is, sequences that are eventually zero). To define the whole space one just takes the completion (though that is actually completely unimportant for the problem of whether Tsirelson’s space contains or ).
. Then there are several equivalent ways of defining the norm on Tsirelson’s space. For simplicity we shall define it just for finitely supported vectors (that is, sequences that are eventually zero). To define the whole space one just takes the completion (though that is actually completely unimportant for the problem of whether Tsirelson’s space contains or ).
1. The first definition is that it is the smallest norm such that for every finitely supported vector we have the equation

where the maximum is over all admissible sequences .
2. The second definition is an inductive one. Let us define 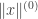 to be
to be 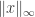 and for each
and for each 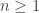 let us define
let us define

where again the maximum is over all admissible sequences . It is straightforward to prove inductively that 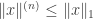 for every , so for each the numbers
for every , so for each the numbers 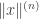 form an increasing bounded sequence. Therefore they converge to a limit
form an increasing bounded sequence. Therefore they converge to a limit 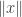 , and it is easy to see that the norm thus defined is the smallest that satisfies the equation given in definition 1.
, and it is easy to see that the norm thus defined is the smallest that satisfies the equation given in definition 1.
3. If and  are finitely supported non-zero vectors, write
are finitely supported non-zero vectors, write 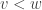 if the maximum
if the maximum  for which
for which 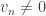 is smaller than the minimum
is smaller than the minimum  for which
for which 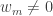 . Given a set
. Given a set 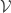 of finitely supported vectors, let
of finitely supported vectors, let 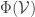 be the set of all vectors of the form
be the set of all vectors of the form 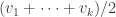 such that
such that 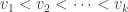 and
and  is less than or equal to the minimum of the support of
is less than or equal to the minimum of the support of 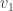 . Let
. Let 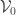 be the set of all vectors that are
be the set of all vectors that are  in one coordinate and zero everywhere else. Let
in one coordinate and zero everywhere else. Let 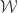 be the closure of under the operation
be the closure of under the operation 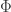 . Then
. Then 
4. Similar to 3 except that instead of talking about the closure of one defines 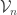 to be
to be 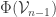 and defines to be the union of the
and defines to be the union of the 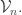
The problem in a nutshell.
Actually, there are two problems, and both have to be solved if there is to be a satisfactory answer to the main question of this post. The first is to find a definition of “explicitly definable” that allows one to define all “normal” spaces such as -spaces, Lorentz spaces, Orlicz spaces, Schreier spaces, etc. (ideally, one could also find an appropriate definition that worked for function spaces as well, so that one could also define  spaces, Sobolev spaces, Besov spaces, and so on) but does not allow “inductive” definitions of the Tsirelson type. The second is to show that every space that is explicitly definable according to the given definition contains or .
spaces, Sobolev spaces, Besov spaces, and so on) but does not allow “inductive” definitions of the Tsirelson type. The second is to show that every space that is explicitly definable according to the given definition contains or .
Combinatorialization.
I have given definition 3 above because I think it has the potential to “combinatorialize” the problem. Note that the coordinates of the vectors in each are all either 0 or negative powers of 2, so they can be identified with infinite sequences of non-negative integers, all but finitely many of which are zero. Thus, one can perhaps focus on weak systems of arithmetic that make it possible to define some sets of such sequences but impossible to define the one naturally associated with Tsirelson’s space (so it would somehow have to outlaw closure operations of the type in 3).
Just to be clear what the combinatorialization is, if we replace each vector in by an integer sequence by replacing 0 with 0 and 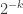 with , then the operation takes a sequence of already existing finitely supported sequences with the minimum of the support of at least and replaces it by
with , then the operation takes a sequence of already existing finitely supported sequences with the minimum of the support of at least and replaces it by 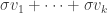 , where
, where  is the sequence that adds 1 to all non-zero coordinates. For example, if we already have the sequences
is the sequence that adds 1 to all non-zero coordinates. For example, if we already have the sequences 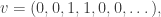
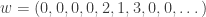 and
and  , then we can form the sequence
, then we can form the sequence  .
.
Tim Chow is checking with his f.o.m. friends whether anybody has any ideas about this. I look forward to what he has to say when he reports back, or indeed to any direct communication from the f.o.m. people themselves.
At some point I should give the rather nice proof that Tsirelson’s space does not contain or , but strictly speaking it isn’t actually needed for this problem. Perhaps I’ll put it on the wiki when that gets going (if it gets going).
This entry was posted on February 17, 2009 at 8:59 pm and is filed under polymath2, Straight maths. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

February 18, 2009 at 9:53 am |
1. A long time ago when I was thinking about this I had the thought that perhaps you need general recursion rather than primitive recursion to enumerate all the sequences that you can generate according to the rules above. Then at some point I persuaded myself that I could do it with just primitive recursion. I have not yet managed to reconstruct my argument. (Note that from the combinatorial version one can turn it into a problem about defining a set of integers, by associating with the sequence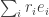 the positive integer
the positive integer  where
where  is the
is the  th prime.)
th prime.)
Actually, I think I remember it now: the idea was to generate, for each in turn, all possible sequences that are zero after the
in turn, all possible sequences that are zero after the  th place. I think the fact that one can do that means that the set is automatically primitive recursive.
th place. I think the fact that one can do that means that the set is automatically primitive recursive.
Looking at it again, I have a different, but possibly related, idea. Suppose you yourself wanted to enumerate by hand all the sequences you can generate. And let’s suppose also that you wanted to do it in a brutally simple way. Then you would probably find yourself wanting to have a library of sequences that you had already generated, and you might well need that library to get arbitrarily large as you went along. Here I am talking just about the number of sequences you need to keep track of, and not their lengths. In other words, perhaps, to use a word inspired by computer-science jargon, there is a sense in which the “width” of your calculation has to be unbounded. (Roughly speaking, the width of a computation is the amount of storage space you need to carry it out and the width of a problem is the minimum width of any computation that carries it out. Here I am assuming, very informally, that each sequence takes up just one unit of space.)
To explain in slightly more detail what I mean, let me contrast it with enumerating all finite sets such that the cardinality of
such that the cardinality of  is at most the minimal element of
is at most the minimal element of  . Here, if we want to list all such sets that are subsets of
. Here, if we want to list all such sets that are subsets of  , then we don’t need to remember anything much. We can just think of each set as a binary expansion, and having found set number
, then we don’t need to remember anything much. We can just think of each set as a binary expansion, and having found set number  we work out the binary expansion of the next integer, see whether the corresponding set is shorter than the size of its minimal element, and include it if and only if it is.
we work out the binary expansion of the next integer, see whether the corresponding set is shorter than the size of its minimal element, and include it if and only if it is.
Turning imprecise thoughts like this into precise ones is difficult, though, because one needs to rule out “tricks” like encoding lots of sequences as a single sequence in order to fit them into one unit of storage space. I haven’t managed to think of a good way of doing that, but I cannot be the first person to have faced this problem, so perhaps there is a way of dealing with it.
February 18, 2009 at 4:12 pm |
Hello Tim. I too am looking forward to seeing any responses Tim Chow receives from FOM. Is it possible that the notion of ‘explicitly defined’ you’re after might be related to the computational complexity of calculating the norm — that is, of calculating the norm to a given accuracy on the space of sequences supported in 1…n? Or is this barking up the wrong tree entirely?
February 18, 2009 at 7:42 pm |
Alec, Tim himself asked a similar question in the comments on the post about the space of Argyros and Haydon. As I pointed out there, at least one obvious conjecture one might make along these lines is false, because if you modify the definition of Tsirelson’s space so that the admissibility condition changes from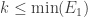 to
to 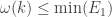 for some very slowly growing function
for some very slowly growing function  , then you can calculate the norm of any vector supported on
, then you can calculate the norm of any vector supported on  using at most a linear number of arithmetical operations. And the space still doesn’t contain
using at most a linear number of arithmetical operations. And the space still doesn’t contain  or
or  .
.
That doesn’t completely rule out some kind of computational complexity, however: it just means that if one wants to talk about the time taken by an algorithm, then that time will have to depend on something more sophisticated than the support size of a vector. I don’t have any candidates that I can’t immediately dismiss.
In my comment above, there was the germ of another idea, which was that perhaps one should think not about the time-complexity of an algorithm but the space-complexity. So far, this idea feels more promising, but that could be because I haven’t thought about it hard enough for the flaws to emerge. But the optimist in me thinks that perhaps one could come up with some computational procedures that were very restricted in some ways (so that you couldn’t cheat by doing various encodings) but generous in others (so that you could for example store an entire vector with one unit of storage) and then prove that a computation that can be done with bounded storage leads to a space that contains or
or  .
.
Obviously, even if that idea doesn’t turn out to be a non-starter, a lot more thought would be needed to turn it into a proper conjecture.
February 20, 2009 at 2:42 am |
Interesting discussion, though not one where I can think of anything meaningful that might lead to progress on the problem. I do however have one thought regarding hopes of getting at L^p etc.
It strikes me that we are really asking about explicitly definable norms on spaces of functions *on a given base set*. That is, if one considers the unit circle and asks for a definition of L^p(T), this is by any sense we’d desire a definable norm. But if we take Fourier transforms, is the corresponding sequence space on Z “definable” or not? On the one hand, yes, it’s just all the double series which arise as Fourier series of L^p(T)-functions. Yet actually “computing” the norm (in the loose sense) seems a more remote task than an l^p or Lorentz-type sequence space norm.
Apologies for not explaining this very well, and it is such an obvious misgiving/confusion that I’m sure the “resolution” is well known…
February 20, 2009 at 4:01 am |
Here’s one way to probe “how much induction” is involved in proving the existence of Tsirelson’s space. Does the existence of the norm on Tsirelson’s space imply the existence of some fast-growing function?
For example, Goodstein’s theorem says that a certain process always terminates after a finite number of steps. If f(n) denotes the number of steps until termination when n is the starting number, then f is a very fast-growing function. The speed of growth of this function tells us that Goodstein’s theorem isn’t provable in first-order Peano arithmetic PA, because f grows too fast for PA to prove that f is total (i.e., everywhere defined).
So can we cook up a function whose everywhere-definedness is guaranteed by the existence of the Tsirelson norm, and which grows extremely fast? Induction over sets of trees is often a promising way to get fast-growing functions. I think I understand the definition of the Tsirelson norm now, but I don’t have much feel for it yet, and in particular am not sure how to use it to encode some ridiculously long search.
February 20, 2009 at 4:11 am |
One additional remark: the fact that computing the norm will use only a linear number of operations if you modify the definition of Tsirelson’s space using a very slow-growing function isn’t necessarily an immediate deal-breaker, because you might be able to use the inverse of the slow-growing function as your fast-growing function. In other words, we may still be in business even if there’s a fast-growing function in Tsirelson’s original setup that can be killed by modifying the definition, as long as the killing can occur only at the cost of introducing a fast-growing function in the new definition.
February 20, 2009 at 5:03 am |
Tsirelson space does indeed gives rise to very fast growing functions.
The unit vector basis of the space is not subsymmetric. (Subsymmetric basis has the property that it is equivalent to all of its subsequences.) But it is not easy to find subsequences of the basis which are not equivalent to the basis. You have to take a very fast growing subsequence of indices to find one. I will have to check the exact statement but I think it was beyond the fast growing hierarchies.
February 20, 2009 at 6:37 am |
Computing the Tsirelson norm appears to be within the reach of primitive recursion, so it does not by itself lead to very fast growing functions. However, proving that the Tsirelson space has all of its claimed properties appears to be much more difficult. In other words, the norm itself may have relatively little computational content, but the statement that the space does not contain a subspace isomorphic to one of the classical spaces may be much stronger.
The Blum-Shub-Smale machine model looks like a promising way to measure the complexity of the Tsirelson space construction. This machine model uses of real numbers as primitive objects and rational functions as primitive operations and was designed to measure the complexity of computation with real numbers. With this model, there appears to be a rather dramatic gap between the complexity of the classical spaces and that of the Tsirelson space. (I don’t know enough about the Orlicz, Schreier and Lorentz spaces to estimate their complexity in this context.)
February 20, 2009 at 11:22 am |
A few comments to make here. First of all, although computing the norm on Tsirelson’s space does seem to be primitive recursive (in some suitable model of real computation), it is relatively simple to use the norm to define rapidly growing functions. Indeed, I think it is the case that if you want to find a vector such that
such that 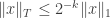 then you need the support size of
then you need the support size of  to have something like an Ackermann dependence on
to have something like an Ackermann dependence on  . Of course, the function that takes
. Of course, the function that takes  to the minimum of
to the minimum of 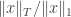 is not itself primitive recursive, but that does not necessarily matter. Sorry — I think I mean the inverse of that function.
is not itself primitive recursive, but that does not necessarily matter. Sorry — I think I mean the inverse of that function.
I don’t know much about the Blum-Shub-Smale model, but some of its properties, such as treating real numbers and rational functions as primitives, are very much the kind of thing I think is needed here. My instinct is that one should have a generous supply of primitives but greatly restrict what can be done with those primitives. But it would probably go further than what Blum, Shub and Smale did, because the primitives would be tailored to sequence spaces rather than real numbers.
For example, perhaps one could allow all functions built up from rational functions, exp, log, trigonometric functions, etc., as primitive operations on the reals. And given an allowable function f on the reals, one could allow the pointwise operation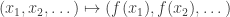 , and also the operation
, and also the operation 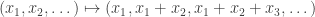 , and the operation
, and the operation 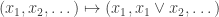 , and the operation
, and the operation 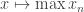 , and so on.
, and so on.
This would make, say, the -norm explicitly definable, since one would first do the pointwise operation
-norm explicitly definable, since one would first do the pointwise operation 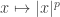 , then the partial-sums operation, then the limit operation, and finally one would take the
, then the partial-sums operation, then the limit operation, and finally one would take the  th root.
th root.
Note that what I’m looking for here has nothing to do with time complexity: it is more like the distinction between computable and noncomputable.
One final remark: if one did manage to prove that a space with an efficiently computable norm must contain or
or  then one would have proved unconditionally that the Tsirelson norm was not efficiently computable. However one defined “efficiently computable”, that would be a pretty interesting result. But I take that to be a sign that it is not the way to go …
then one would have proved unconditionally that the Tsirelson norm was not efficiently computable. However one defined “efficiently computable”, that would be a pretty interesting result. But I take that to be a sign that it is not the way to go …
February 20, 2009 at 2:29 pm |
Your first remark is very interesting: it implies that the statement “Tsireslson’s space does not contain a copy of ” is not provable in weak systems of first-order and second-order arithmetic.
” is not provable in weak systems of first-order and second-order arithmetic.
Blum-Shub-Smale have considered generalizations along the lines of what you suggest. Their basic model makes sense over any ring, in particular the ring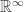 . Moreover, they have studied amendments to better handle “large indices” for that ring. As for the inclusion of exponentials, logarithms, and trigonometric functions, they wouldn’t have much adverse effects on the basic model, but I suspect that the characterization of “re” sets as countable unions of basic semi-algebraic sets may fail to have an analogue for this modified model.
. Moreover, they have studied amendments to better handle “large indices” for that ring. As for the inclusion of exponentials, logarithms, and trigonometric functions, they wouldn’t have much adverse effects on the basic model, but I suspect that the characterization of “re” sets as countable unions of basic semi-algebraic sets may fail to have an analogue for this modified model.
February 20, 2009 at 8:46 pm |
The comments about fast-growing functions are very promising. However, I would like to pin down some details, especially B. Sari’s suggestion. Ackermann’s function isn’t bad, but something faster than that would be even better. For example, something that grows faster than the Wainer hierarchy would suggest unprovability in PA. Then you might hope to prove a theorem of the form, “`Every separable Banach space has a copy of c_0 or l_p’ is not disprovable in ACA_0” (where ACA_0 is, roughly speaking, the `reverse mathematics equivalent’ of PA).
I’m not sure whether Blum-Shub-Smale is relevant here. First off, there are other models of computation for real numbers out there, such as the one studied in Weihrauch’s book “Computable Analysis.” Perhaps more importantly, something may fail to be BSS-computable simply because it’s “not algebraic enough” (e.g., the Mandelbrot set) and for the present problem I suspect we don’t want algebraic considerations to intrude. The computational content here seems to be essentially combinatorial. We will eventually need to refer to reals, but that can be done in second-order arithmetic (a real number can be identified with a set of integers). So my instinct is that thinking about the BSS angle is less promising (at this stage anyway) than thinking about fast-growing functions.
February 20, 2009 at 10:32 pm |
Let me say two things just to place the comments about fast-growing functions into some kind of perspective. First of all, I’m fairly sure that the thing I referred to about the Ackermann function (which I think was proved by Steven Bellenot) is both an upper and a lower bound. Actually, I may have misremembered the result. I think the place where Ackermann functions show up (or perhaps another place) is if you ask yourself whether a subspace of Tsirelson’s space generated by a subsequence of the standard basis is equivalent to the space itself (via the obvious linear map). The answer is no in general, but I think you have to pick a subsequence , where
, where 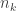 has Ackermann growth in
has Ackermann growth in  .
.
In any case, I don’t see any obvious way of generating even faster-growing functions.
It’s also not clear to me that you get the Ackermann function showing up for every space that fails to contain or
or 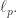 I think the time has come to mention Schlumprecht’s space. I’ll assume that the definition of Tsirelson’s space has been sufficiently digested that it will be enough for me to give just one form of the definition, corresponding to the first definition I gave of the Tsirelson norm, but it too can be rephrased in terms of closure operations, sequences of norms, etc.
I think the time has come to mention Schlumprecht’s space. I’ll assume that the definition of Tsirelson’s space has been sufficiently digested that it will be enough for me to give just one form of the definition, corresponding to the first definition I gave of the Tsirelson norm, but it too can be rephrased in terms of closure operations, sequences of norms, etc.
The basic equation that defines the Schlumprecht norm is this.
where this time the maximum is over all and all sequences
and all sequences 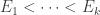 . Here
. Here  is a function that satisfies a few properties such as not growing too fast, being concave, equalling 1 at 1, etc. An example that works is
is a function that satisfies a few properties such as not growing too fast, being concave, equalling 1 at 1, etc. An example that works is 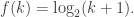 Note that we do not require that
Note that we do not require that  is at most the minimal element of
is at most the minimal element of  . This time, if we try to split
. This time, if we try to split  up into too many pieces, our “punishment” is to have to divide by
up into too many pieces, our “punishment” is to have to divide by 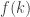 .
.
I’m far from certain that super-fast-growing functions come into the picture here. But we do still need to do a somewhat non-primitive feeling recursion (even if it’s hard to say precisely what that means).
February 20, 2009 at 11:38 pm |
If I understand correctly, Ackermannian growth shows up in proving that is not subsymmetric (as suggested by B. Sari) but not necessarily in proving that
is not subsymmetric (as suggested by B. Sari) but not necessarily in proving that  and
and  are not equivalent?
are not equivalent?
I suspect that Ackermannian growth is the best that one could hope to extract from Tsirelson’s space (without outside help). The intuition here is that Tsirelson’s space is associated to the Shreier family, which has length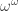 , which is also the proof theoretic ordinal associated to the totality Ackermann function. Constructing a space with a (generalized) Schreier family of length
, which is also the proof theoretic ordinal associated to the totality Ackermann function. Constructing a space with a (generalized) Schreier family of length 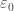 (or longer) may lead to faster growth…
(or longer) may lead to faster growth…
From the reverse mathematics point of view, it looks at first glance that much of the properties of are provable in ACA0. However, there is one way to immediately get beyond ACA0: are there results about Tsirelson’s space that make use of the Nash-Williams Barrier Theorem for the Shreier family?
are provable in ACA0. However, there is one way to immediately get beyond ACA0: are there results about Tsirelson’s space that make use of the Nash-Williams Barrier Theorem for the Shreier family?
February 21, 2009 at 1:27 am |
Although the reverse mathematics of Tsirelson’s space looks like an interesting topic (at least to me), it’s pretty clear that this is not the right framework to answer the original question of whether every “definable” Banach space must contain or
or  . There is however one area of logic that does regularly produce results of this kind: model theory.
. There is however one area of logic that does regularly produce results of this kind: model theory.
Traditional model theory may not be the most suitable venue since it would have a hard time dealing with the topological aspects of Banach spaces. However, many relatively recent developments are designed to include certain topological structures within the framework of model theory. Two such venues come to mind. The first is Boris Zilber’s analytic Zariski geometries, pseudo-analytic structures, etc. The second, is a line of thought that started from Itai Ben-Yaacov’s compact abstract theories (cats) and has since led to some form of continuous logic. I must admit that I know very little about these aspects of model theory, just enough to see a potential connection.
February 21, 2009 at 6:24 am |
I have found Bellenot’s results on fast growing functions (which confirm what Gowers wrote). To summarize, here are some key facts about that are not provable in RCA0:
that are not provable in RCA0:
1. For every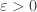 and every
and every  , there is a finitely supported vector
, there is a finitely supported vector  such that
such that  and
and 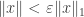 .
.
2. No block basic sequence of the standard basis of is equivalent to the standard basis of
is equivalent to the standard basis of  .
.
3. There is a bounded block basic sequence of the standard basis of which is not equivalent to the standard basis of
which is not equivalent to the standard basis of  .
.
In other words, although Tsirelson’s space is definable in RCA0, none of its defining properties are provable in that system.
I think that hereditary versions of 1 and 3 would lead to still faster growing functions all the way up the Wainer hierarchy below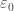 . Thus full arithmetic induction would be necessary to prove these extended facts.
. Thus full arithmetic induction would be necessary to prove these extended facts.
February 21, 2009 at 9:36 am |
Tim, would you be willing to conjecture that every Banach space not containing c_0 or l_p necessarily gives rise to a function that grows faster than every primitive recursive function? “Gives rise” is a little vague here, I know, but I just want to get a sense for whether you think something like this might be true.
Part of the problem here seems to be that “not containing c_0 or l_p” is a slightly weird condition, and it’s hard to see how to derive an interesting consequence purely from that assumption. But to solve the original problem, that’s what we have to do. If “gives rise to a non-primitive-recursive function” doesn’t seem like a plausible logical consequence of “doesn’t contain c_0 or l_p” then we have to cook up some other precisely stated property that *does* follow logically from “doesn’t contain c_0 or l_p.” This must be the case regardless of what approach is used (reverse mathematics or model theory or computational complexity or whatever).
February 21, 2009 at 11:11 am |
Tim, I don’t at the moment see enough evidence to be happy to make such a conjecture. In particular, I would be reluctant to do so unless somebody knew of a way to get fast-growing functions out of Schlumprecht’s space (see my previous comment). So my hunch is that there is not going to be a proof along these lines.
About your second paragraph, I have two remarks. The first is that what I had imagined was more like the contrapositive of what you are suggesting: that is, I had imagined deducing “contains or
or  ” from “can be defined in a nice simple way”. My hope was that there would be a natural class of definitions, generated certain operations, and that one would be able to prove inductively that all spaces defined in that way contained
” from “can be defined in a nice simple way”. My hope was that there would be a natural class of definitions, generated certain operations, and that one would be able to prove inductively that all spaces defined in that way contained  or
or  . As for the weirdness of the condition, I should mention another known result, due, if I remember correctly, to Zippin. It’s a characterization of the spaces
. As for the weirdness of the condition, I should mention another known result, due, if I remember correctly, to Zippin. It’s a characterization of the spaces  and
and  . Given a sequence space, a block basis is defined to be a sequence of unit vectors
. Given a sequence space, a block basis is defined to be a sequence of unit vectors 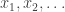 such that every element of the support of
such that every element of the support of  is less than every element of the support of
is less than every element of the support of 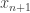 . These are very natural things to consider, for reasons that I won’t go into here. Zippin’s result is that a sequence space is isomorphic to
. These are very natural things to consider, for reasons that I won’t go into here. Zippin’s result is that a sequence space is isomorphic to  or
or  if and only if for every block basis the map that takes the standard basis to the block basis is an isomorphism (meaning that the norm is distorted by at most a constant factor). I hope I’ve remembered that correctly. Anyhow, it means that, in principle at least, in order to prove that a space contains
if and only if for every block basis the map that takes the standard basis to the block basis is an isomorphism (meaning that the norm is distorted by at most a constant factor). I hope I’ve remembered that correctly. Anyhow, it means that, in principle at least, in order to prove that a space contains  or
or  one could prove a more abstract stability statement: that there is a block basis that is equivalent to all its blockings. This, I imagine, would feel a lot less weird to a logician, since fixed-pointy things in partially ordered sets are not weird at all.
one could prove a more abstract stability statement: that there is a block basis that is equivalent to all its blockings. This, I imagine, would feel a lot less weird to a logician, since fixed-pointy things in partially ordered sets are not weird at all.
February 21, 2009 at 3:29 pm |
It turns out that there is already a body of literature in model theory regarding the original question of whether every “definable” Banach space contains a or
or  . The first paper along these lines was by Krivine and Maurey [Israel J. Math. 39 (1981), 273–295] where they show that every stable Banach space contains
. The first paper along these lines was by Krivine and Maurey [Israel J. Math. 39 (1981), 273–295] where they show that every stable Banach space contains  or
or  . (Stability is an important model theoretic idea that was designed to prove some nice classification results of this kind.) Since then, José Iovino has developed the theory much further. Iovino has several papers on the subject on his web page [http://zeta.math.utsa.edu/~rux164/], some of which are aimed at non-logicians.
. (Stability is an important model theoretic idea that was designed to prove some nice classification results of this kind.) Since then, José Iovino has developed the theory much further. Iovino has several papers on the subject on his web page [http://zeta.math.utsa.edu/~rux164/], some of which are aimed at non-logicians.
February 21, 2009 at 3:36 pm |
I have a couple more remarks to make on the subject of what a conjecture might look like, including one that I had not previously had, or at least not completely consciously.
The first is that a long time ago I proved a result I quite liked, motivated by the question of showing that explicit spaces contained or
or  . However, the result isn’t quite what you would expect, because it includes a lot of spaces that aren’t even definable. Let us call a space combinatorial if it is defined by means of a system
. However, the result isn’t quite what you would expect, because it includes a lot of spaces that aren’t even definable. Let us call a space combinatorial if it is defined by means of a system  of finte sets in the following simple way:
of finte sets in the following simple way: 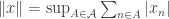 . I showed that every combinatorial space contains
. I showed that every combinatorial space contains  or
or  . (We need to assume that
. (We need to assume that  contains all singletons just to make sure we’ve got a norm, and without loss of generality if
contains all singletons just to make sure we’ve got a norm, and without loss of generality if  and
and 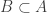 then
then  .) I also generalized this observation somewhat. I never published the result, because I gave a talk about it at a conference and someone pointed out to me that it was known that spaces for which the unit ball of the dual space has only countably many extreme points must contain
.) I also generalized this observation somewhat. I never published the result, because I gave a talk about it at a conference and someone pointed out to me that it was known that spaces for which the unit ball of the dual space has only countably many extreme points must contain  . My result was an easy consequence of that: if you have a nested sequence
. My result was an easy consequence of that: if you have a nested sequence 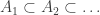 of sets in
of sets in  , then the basis vectors in the union of the
, then the basis vectors in the union of the  generate
generate  , and if you don’t have such a sequence, then every element of
, and if you don’t have such a sequence, then every element of  is a subset of some maximal element
is a subset of some maximal element  , and all the extreme points of the dual space are sequences that take the value
, and all the extreme points of the dual space are sequences that take the value  on a maximal set and 0 outside it. So I had proved (by a similar method) a special case of a known result.
on a maximal set and 0 outside it. So I had proved (by a similar method) a special case of a known result.
I mention this because it suggests that what makes a space fail to contain or
or  is not so much the computability of the norm, but rather the extent to which it is non-combinatorial. It is for this reason that I am not sure that rapidly growing functions are what is truly important here.
is not so much the computability of the norm, but rather the extent to which it is non-combinatorial. It is for this reason that I am not sure that rapidly growing functions are what is truly important here.
My second remark is to make this suggestion slightly more precise, and also to change it a little bit. As it stands, it has the defect that it rules out all consideration of spaces for
spaces for 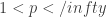 , and of course we would rather not do that. So how could one generalize the thoughts that motivated this simple result?
, and of course we would rather not do that. So how could one generalize the thoughts that motivated this simple result?
To do this I want to go back to the idea of defining a set of norming functionals by means of a closure operation. It strikes me that one could perhaps attack the general problem in two stages, as follows.
(i) Mathematical stage. Define a class of allowable operations. Then define the complexity of a set of sequences (that, for convenience, is required to contain the standard basis) to be the minimal
of sequences (that, for convenience, is required to contain the standard basis) to be the minimal  such that every element of
such that every element of  can be generated using at most
can be generated using at most  operations. Here
operations. Here  can be any ordinal. Then prove that if
can be any ordinal. Then prove that if  has finite complexity and we define a norm
has finite complexity and we define a norm 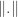 by
by  , then the resulting sequence space contains
, then the resulting sequence space contains  or
or  as a subspace generated by a block basis.
as a subspace generated by a block basis.
(ii) Metamathematical stage. Come up with an inductive notion of explicit definability for which it is easy and natural to check that standard spaces are explicitly definable, and prove that every explicitly definable space has finite complexity.
I suppose the mathematical stage involves a bit of metamathematics too, since one has to decide what operations to allow. But just to give an idea of the kind of thing I have in mind, if you just allow addition of disjointly supported sequences and multiplication by a scalar between and
and  , then Tsirelson’s space has infinite complexity, and I’m pretty sure I can prove that a space of finite complexity contains
, then Tsirelson’s space has infinite complexity, and I’m pretty sure I can prove that a space of finite complexity contains  or
or  .
.
As I write, I realize that it is still quite difficult to incorporate the other spaces into this picture. For example, what operations would give rise to all sequences of
spaces into this picture. For example, what operations would give rise to all sequences of 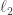 norm at most 1? Perhaps one would have to say something like this: if
norm at most 1? Perhaps one would have to say something like this: if  are already in
are already in  , then you are allowed to include all linear combinations
, then you are allowed to include all linear combinations 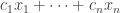 such that
such that  . But you have to choose them all—you can’t go for some and not others. In general, you would be allowed to do something like that as long as the set of coefficients you allowed had an easy description.
. But you have to choose them all—you can’t go for some and not others. In general, you would be allowed to do something like that as long as the set of coefficients you allowed had an easy description.
February 21, 2009 at 6:55 pm |
I found Iovino’s paper Applications of Model Theory to Functional Analysis very enlightening. (Especially the short Banach Space Theory/Model Theory dictionary on page 2 of the intro.)
The plan you just outlined is very strongly related to the model theoretic approach. Zippin’s characterization of the classical spaces is a form of indiscernibility in the model theoretic sense, which explains why stability shows up. The “two stage plan” outlined above is quite similar to the notion of Morley rank used in model theory, which is the typical tool to handle questions related to stability.
It seems to me that Iovino et alii may have already answered the question in full, it is just a matter of translating the model theoretic ideas back into the language of Banach space theory. Even if the question is not fully answered by their work, the translation is still a necessary step to determine exactly what remains to be done.
February 21, 2009 at 8:31 pm |
François, I think it could be helpful to look at Iovino’s papers, especially as he discusses notions of definability in Banach spaces. But I think the Krivine-Maurey work is a bit different, as the notion of stability is quite strong. Maybe, however, it would be a useful black box in an eventual proof: one could perhaps show that every definable space contained a stable subspace or something like that. But let me make clear that the thing that really interests me is the fact that all known examples of spaces that do not contain or
or  are variants or elaborations of Tsirelson’s original construction, in the sense that they all use the trick of defining a norm in terms of itself. That is the striking phenomenon that I would love to explain.
are variants or elaborations of Tsirelson’s original construction, in the sense that they all use the trick of defining a norm in terms of itself. That is the striking phenomenon that I would love to explain.
February 22, 2009 at 1:33 am |
Stability is not the right thing to look at, but the main theorem of Definable types over Banach spaces appears to be the right type of black box. The theorem characterizes those spaces that contain or
or  as those with reasonably definable types. The “definable type” condition is a little technical, but it is definitely something that would be reasonable to expect and to check in an “explicitly defined” space.
as those with reasonably definable types. The “definable type” condition is a little technical, but it is definitely something that would be reasonable to expect and to check in an “explicitly defined” space.
February 22, 2009 at 2:11 am |
The “striking phenomenon” clarifies your perspective a lot. I would rephrase it as an “apparent impredicativity,” but I’m not sure how to make the phenomenon more precise. (Especially since the definition of is definitely predicative in the usual sense of that word.)
is definitely predicative in the usual sense of that word.)
Perhaps it is simply the fact that the norm is defined as a fixed-point. Note that primitive recursion is a fixed-point in the same way. To characterize the line between Tsirelson space and the classical space in terms of computability, one would have to look at some very weak subrecursive hierarchies. Not too weak though, since its probably necessary to keep some kind of limiting processes.
One possibility is to put some complexity constraints on the definition of the norm restricted to finite dimensional subspaces. For example (not necessarily realistic), ask that the norm of vectors in is approximable in polynomial time, uniformly in
is approximable in polynomial time, uniformly in  . However, this doesn’t feel quite right to me.
. However, this doesn’t feel quite right to me.
February 22, 2009 at 1:20 pm |
I’ve had a look at the theorem you mention and it certainly has me curious. Unfortunately I don’t understand the statement well enough to know to what extent it relates to what I am interested in. If you were able to give an explanation for the non-expert I would be very grateful. (In particular, I don’t really understand the conclusion: if you take E to be the zero subspace do you get a copy of or
or  ? If so, why is it interesting to take an arbitrary E?)
? If so, why is it interesting to take an arbitrary E?)
Just to recap about complexity, I’m convinced that polynomial-time computability is not the right concept here, for two reasons. One is that it is easy to produce variants of Tsirelson’s space where the norm is approximable in polynomial time (in terms of the maximum n for which the nth coordinate is not zero) and you still don’t get or
or  . The other is that if one tried to prove a result in terms of non-polynomial-time computability, one would be in danger of proving that P does not equal NP. (The Tsirelson norm would be in NP because to prove that the norm of a vector x is at least c one just has to exhibit a norming tree.) And it feels as though that would be too easy a method of solving that particular problem — though I suppose one should make absolutely sure that it doesn’t work …
. The other is that if one tried to prove a result in terms of non-polynomial-time computability, one would be in danger of proving that P does not equal NP. (The Tsirelson norm would be in NP because to prove that the norm of a vector x is at least c one just has to exhibit a norming tree.) And it feels as though that would be too easy a method of solving that particular problem — though I suppose one should make absolutely sure that it doesn’t work …
February 22, 2009 at 8:19 pm |
Here is a first attempt to distill the relevant parts of Iovino’s paper on definable types.
Types.
Let be a (suitable) superspace of
be a (suitable) superspace of  . The quantifier-free type of a point
. The quantifier-free type of a point 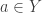 over
over  is the function
is the function 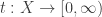 defined by
defined by 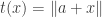 . The idea is that
. The idea is that  captures all the (“quantifier-free”) information about
captures all the (“quantifier-free”) information about  that can be seen using only objects from
that can be seen using only objects from  . Another point of view is that
. Another point of view is that  is a description over
is a description over  of an “imaginary point”
of an “imaginary point”  . (Compare with the correspondence between field extensions and ideals in polynomial rings.)
. (Compare with the correspondence between field extensions and ideals in polynomial rings.)
There are some technical restrictions on how is related to
is related to  (it has to be an approximate elementary extension). For our purposes, we may assume that
(it has to be an approximate elementary extension). For our purposes, we may assume that  is separable and the relevant types are precisely those that happen to be of the form
is separable and the relevant types are precisely those that happen to be of the form  . This is how Krivine and Maurey define types.
. This is how Krivine and Maurey define types.
Definability.
The quantifier-free definable subsets of as those sets that can be obtained from the basic sets
as those sets that can be obtained from the basic sets
by taking finitely many unions, intersections, and complements. If one prohibits taking complements, we obtain the class of positive quantifier-free definable sets. If we restrict the centers to be finite linear combinations of elements of a set
to be finite linear combinations of elements of a set  , we obtain the sets that are (positive) quantifier-free definable over
, we obtain the sets that are (positive) quantifier-free definable over  .
.
From the point of view of logic, it is better to think of these as “formal expressions” rather than just sets, which allows us to make the following definition. If is a quantifier-free definable set and
is a quantifier-free definable set and  , the
, the  -approximation
-approximation  is the set obtained by the same formal expression, except that one replaces every
is the set obtained by the same formal expression, except that one replaces every  by
by 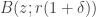 and every
and every 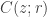 by
by 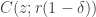 . (This makes more sense when
. (This makes more sense when  is positive quantifier-free definable.)
is positive quantifier-free definable.)
To say that the type is (positive) quantifier-free definable means that for every
is (positive) quantifier-free definable means that for every  , every interval
, every interval ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and every
and every 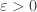 there are a (positive) quantifier-free definable set
there are a (positive) quantifier-free definable set  and a
and a  such that:
such that:
(1) If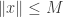 and
and 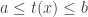 then
then 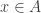 .
.
(2) If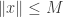 and
and 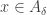 then
then 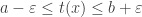 .
.
This is a rather technical definition, but you can think of it as saying that is “effectively approximately measurable” with respect to the algebra generated by the sets
is “effectively approximately measurable” with respect to the algebra generated by the sets 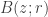 and
and 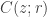 .
.
The Black Box.
I will now state the most useful consequence of Iovino’s Theorem for our purposes.
Theorem. Let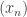 be a bounded sequence in a Banach space
be a bounded sequence in a Banach space  such that no normalized block sequence of
such that no normalized block sequence of 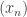 converges. If every type over
converges. If every type over  is (positive) quantifier-free definable, then for every
is (positive) quantifier-free definable, then for every 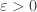 there is a block sequence in
there is a block sequence in 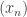 which is
which is 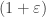 -equivalent to the standard basis of
-equivalent to the standard basis of  or
or  for some
for some 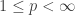 .
.
Iovino’s main result is an equivalence between two stronger statements, but I don’t think the stronger form is interesting to us. (The finite dimensional spaces in Iovino’s main theorem don’t seem to be relevant from the Banach space perspective. From the logic perspective, they serve mostly to house finite lists of parameters from the ambient space
in Iovino’s main theorem don’t seem to be relevant from the Banach space perspective. From the logic perspective, they serve mostly to house finite lists of parameters from the ambient space  .)
.)
February 22, 2009 at 8:31 pm |
Correction: The second paragraph on types should mention that the sequence is taken from
is taken from  (rather than some ambient space
(rather than some ambient space  ).
).
February 22, 2009 at 9:04 pm |
Remark: When is positive quantifier-free definable, we may as well take
is positive quantifier-free definable, we may as well take  to be the usual
to be the usual  -nbhd around the set
-nbhd around the set  . This avoids the “formal expression” business and simplifies “definability” a great deal.
. This avoids the “formal expression” business and simplifies “definability” a great deal.
February 22, 2009 at 9:41 pm |
I asked the same question when I saw that paper some time ago as Gowers did. I don’t understand the statement either. It seems to me that the author doesn’t prove anything about the spaces containing or
or  but rather it says something about having
but rather it says something about having  or
or  spreading models.
spreading models.
Even that is not clear. In the follow up paper the connection with spreading models is explicitly stated in Theorem 11.9 but the proof doesn’t seem to be correct. The proof claims if a sequence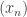 generates a spreading model 1-equivalent to
generates a spreading model 1-equivalent to  basis so does all of its block bases. A counterexample is: take a block basis $\latex (x_n)$ which generates such a spreading model in the Schlumprecht space $S$ (existence is proved by Kutzarova and Lin). Since the space is block minimal, some block sequence of $\latex (x_n)$ is equivalent to the unit vector basis of $S$, which is subsymmetric and generates $S$ as a spreading model.
basis so does all of its block bases. A counterexample is: take a block basis $\latex (x_n)$ which generates such a spreading model in the Schlumprecht space $S$ (existence is proved by Kutzarova and Lin). Since the space is block minimal, some block sequence of $\latex (x_n)$ is equivalent to the unit vector basis of $S$, which is subsymmetric and generates $S$ as a spreading model.
February 22, 2009 at 11:25 pm |
I was hoping that someone would check the correctness of the Banach space statements in Iovino’s papers.
The error in 11.9 of the Semidefinability paper may be just a minor omission. Iovino assumes that the spreading model for case (1) comes from a definable type (as in the matching case of 11.7). In this case the spreading model appears to be unique (see 6.1 of the Definable Types paper).
February 23, 2009 at 3:48 am |
Perhaps it would be helpful if I painted a very, very broad strokes outline of Iovino’s argument for (1) implies (2) from the Definable Types paper, and clarify the role of the finite dimensional spaces in the statement of the main theorem.
in the statement of the main theorem.
First, he shows that condition (1) implies the existence of stable types. These are types for which the convolution on the span of
for which the convolution on the span of  extends to a separately continuous, commutative convolution on the closure of the span of
extends to a separately continuous, commutative convolution on the closure of the span of  in the space of types.
in the space of types.
Then, he further refines the stable type so that he can pick a $p \in [1,\infty]$ such that
so that he can pick a $p \in [1,\infty]$ such that  (where
(where 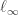 is code for
is code for  ) is block finitely represented in every element of the closure of the span of
) is block finitely represented in every element of the closure of the span of  . (This is a variation on Krivine’s Theorem.)
. (This is a variation on Krivine’s Theorem.)
Finally, he builds a sequence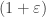 -equivalent to
-equivalent to  in steps. To do this he has to push and pull finite pieces of the sequence in and out of the
in steps. To do this he has to push and pull finite pieces of the sequence in and out of the  ‘s and use the convolution to glue them back together in a coherent way. (This step is not an explicit construction, it is an existence proof of the type “there is a way to do this without ever shooting yourself in the foot.”)
‘s and use the convolution to glue them back together in a coherent way. (This step is not an explicit construction, it is an existence proof of the type “there is a way to do this without ever shooting yourself in the foot.”)
Note that this argument is basically a “localized” version of the proof of the Krivine-Maurey theorem that Iovino gives in the Applications paper.
February 23, 2009 at 5:58 am |
I’ve emailed Bellenot and Iovino to invite them to join this discussion.
February 23, 2009 at 4:33 pm |
Thanks Tim Chow! I hope that Iovino and other continuous model theorists out there will join this discussion. Meanwhile, here is an alternative approach to definability which may be more palatable to the analyst.
Say that a set is “elementary open” if it can be built from the basic sets
by taking finitely many unions and intersections. If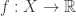 is uniformly continuous on bounded sets, then
is uniformly continuous on bounded sets, then  is (positive quantifier-free) definable iff for all intervals
is (positive quantifier-free) definable iff for all intervals ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and all
and all 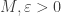 there is an elementary open set
there is an elementary open set  such that
such that
Thus, definability can be seen as a very strong form of continuity.
Because of their finitary nature, elementary open sets are “preserved” in ultrapowers. This puts a lot of constraints on possible extensions of definable functions in ultrapowers (e.g., uniqueness of heirs).
I wonder if definablity is a fundamentally new idea from logic or if it already existed in analysis (in some equivalent form). Similar (perhaps better) ideas could have appeared around the same time as Banach space ultrapowers gained popularity.
February 23, 2009 at 4:39 pm |
Something strange happened in the latex code above. The basic open sets should be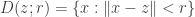 and
and  . (I hope this one works.) [Fixed now — Tim]
. (I hope this one works.) [Fixed now — Tim]
February 23, 2009 at 5:43 pm |
Hello. I am grateful to TC for bringing this very interesting discussion to my attention and inviting me to join.
FD’s description of the main ideas behind my papers on type definability and stability is quite accurate. I couldn’t have given a better explanation.
I actually wrote those papers motivated by Gowers’ question. However, I got to a dead end because, aside from the fact that the existence of enough definable types guarantees the existence of subspaces, I couldn’t see (and I still don’t see) a clear connection between the notion of type definability and the notion of “explicit definability’’ for norms.
subspaces, I couldn’t see (and I still don’t see) a clear connection between the notion of type definability and the notion of “explicit definability’’ for norms.
Answer to BS: the results are both about occurring as a spreading model, and as a subspace; the connection is, as FD indicated, that when the spreading model is given by definable types, the
occurring as a spreading model, and as a subspace; the connection is, as FD indicated, that when the spreading model is given by definable types, the  information can be brought down from the spreading model to the base space.
information can be brought down from the spreading model to the base space.
February 23, 2009 at 7:47 pm |
Thanks for joining us José! I’m glad that my account of your work wasn’t off-track. (Besides having listened to Ben Yaacov speak on cats a few times, I had no notion of continuous model theory until Saturday, so I was starting to feel uncomfortable.)
Since this is intended to be a brainstorming session, it would be helpful if you could share some of your insight on what seem to be promising or dead-end approaches to “explicit definability.” Vague ideas and indefinite perceptions are acceptable, no one is expecting definite answers at this stage.
February 24, 2009 at 4:11 pm |
I still think it’s worth asking whether it’s provable in RCA_0 that Schlumprecht’s space does not contain or
or  .
.
It’s true that even if one succeeds in proving something like “It is unprovable in RCA_0 that not every (separable) Banach space contains or
or  ,” one does not thereby obtain a precise concept of “explicitly definable Banach space.” However, it would at least partially answer the question of why the counterexamples necessarily involve some kind of intricate induction.
,” one does not thereby obtain a precise concept of “explicitly definable Banach space.” However, it would at least partially answer the question of why the counterexamples necessarily involve some kind of intricate induction.
Besides extracting a fast-growing function from Schlumprecht’s space, there are some other ways of demonstrating unprovability in RCA_0. For example, one could try to deduce the weak Koenig lemma from it. That would be reverse mathematics in the true sense: proving an axiom from a theorem. However, it might not even be true that the axiom follows from the theorem.
Another way would be to come up with a model of RCA_0 in which every Banach space *does* contain or
or  .
.
February 24, 2009 at 5:32 pm |
Tim C: I too think that the reverse mathematics of Tsirelson’s and Schlumprecht’s spaces is of great interest. (This is actually why I landed here after your FOM post.) However, let me explain in more detail why reverse mathematics cannot give a reasonable answer to the main question.
The key fact is that to say that a separable Banach space doesn’t contain
doesn’t contain  or
or  is a
is a 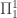 statement. Therefore, since
statement. Therefore, since  already exists in the minimal
already exists in the minimal  -model of RCA0, the statement “there is a separable Banach space that doesn’t contain
-model of RCA0, the statement “there is a separable Banach space that doesn’t contain  or
or  ” is true in every
” is true in every  -model of RCA0.
-model of RCA0.
So any model of RCA0 + “Every separable Banach space contains or
or  ” will necessarily be nonstandard. Because of this, one can’t draw any kind of reasonable conclusion from this about what happens in the real world. For example, we know that there is a nonstandard model of RCA0 where Tsirelson’s space (as defined in that model) contains a copy of
” will necessarily be nonstandard. Because of this, one can’t draw any kind of reasonable conclusion from this about what happens in the real world. For example, we know that there is a nonstandard model of RCA0 where Tsirelson’s space (as defined in that model) contains a copy of  . That doesn’t say anything about the real Tsirelson’s space, it only says that this particular model of RCA0 is very strange.
. That doesn’t say anything about the real Tsirelson’s space, it only says that this particular model of RCA0 is very strange.
Heuristically, since ordinals are omnipresent in constructions related to Tsirelson-like spaces, the various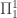 properties of these spaces are likely each equivalent to the wellorderedness of various ordinals. In other words, we know exactly what type of reversals that one can expect from these spaces. Something different from this would be very interesting. In this vein, let me restate a question that I asked earlier: are there interesting properties of
properties of these spaces are likely each equivalent to the wellorderedness of various ordinals. In other words, we know exactly what type of reversals that one can expect from these spaces. Something different from this would be very interesting. In this vein, let me restate a question that I asked earlier: are there interesting properties of  whose proof uses the Nash-Williams Barrier Partition Theorem?
whose proof uses the Nash-Williams Barrier Partition Theorem?
February 24, 2009 at 8:30 pm |
Thanks for the more detailed explanation; I hadn’t thought it through that far. However, let me say a bit more about why I’m still trying to push this angle. As I understand it, the phenomenon to be explained is that the examples of separable Banach spaces that don’t contain or
or  are all “Tsirelson-like” in the sense that they involve some kind of funny induction. I can imagine at least two explanations for this.
are all “Tsirelson-like” in the sense that they involve some kind of funny induction. I can imagine at least two explanations for this.
Explanation 1: There is some as-yet-unspecified concept of “explicitly definable Banach space” such that every explicitly definable Banach space contains or
or  .
.
Explanation 2: There is in fact no reasonable definition of “explicitly definable Banach space,” but any *proof* that some separable Banach spaces do not contain or
or  has to use some (mildly) exotic induction axiom.
has to use some (mildly) exotic induction axiom.
While it’s true that the “Tsirelson space” in the nonstandard model of RCA_0 doesn’t tell you anything directly about the Tsirelson space in the real world, and thus does not help you with Explanation 1, it *would* be relevant to Explanation 2 (if Explanation 2 is correct).
Although the intuitions of everyone else here seem to be in favor of Explanation 1, I want to pose Explanation 2 as a possibility. Even if Explanation 2 is wrong, I for one would like to see an explicit articulation of the reasons for believing that the explanation for the observed phenomenon lies in the *definability of the norm* rather than in the *provability of the theorem*.
February 24, 2009 at 9:35 pm |
It occurred to me after I replied that while your question was “misformulated,” your intuition was still sound. I then “reformulated” your question in the context of Descriptive Set Theory. My “reformulation” is quite different from your “Explanation 2” but it has the same underlying idea (as I will explain at the end of this post).
In the interest of involving as many fields as possible, here are two (possibly easy) questions for Descriptive Set Theorists. The two questions are related to the space of all normalized norms on
of all normalized norms on  (
(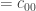 ), i.e., the space of continuous functions
), i.e., the space of continuous functions 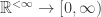 that satisfy the usual norm inequalities and that map each standard basis vector
that satisfy the usual norm inequalities and that map each standard basis vector 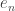 to
to  . This is a Polish space with the natural topology.
. This is a Polish space with the natural topology.
Question 1. The set of all elements of that don’t contain block sequences equivalent to
that don’t contain block sequences equivalent to  or
or  is clearly
is clearly 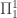 . Is it Borel
. Is it Borel 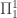 complete?
complete?
Comment: Each or
or  has an associated rank that looks well behaved. Barring any unusual interactions between these, I don’t see why it wouldn’t be Borel
has an associated rank that looks well behaved. Barring any unusual interactions between these, I don’t see why it wouldn’t be Borel 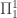 complete. However, my intuition about such things has been wrong before.
complete. However, my intuition about such things has been wrong before.
Question 2. The equivalence (of norms) relation on is a Borel equivalence relation. Where does it sit in the classification of Borel equivalence relations?
is a Borel equivalence relation. Where does it sit in the classification of Borel equivalence relations?
Comment: I haven’t thought about this question much. The answer may be very easy, very hard or even well known (to anyone but me).
The motivation behind these questions is as follows. Whatever “explicitly definable” means, it is likely a Borel subset of . If the answer to Question 1 is positive, then this Borel set can only capture a “small part” of the norms that contain
. If the answer to Question 1 is positive, then this Borel set can only capture a “small part” of the norms that contain  or
or  . Therefore, it is unlikely that such a set would stand out as the obvious notion of “explicitly definable” (i.e., one would always be able to find a reasonable looking norm that is not “explicitly definable”). Also, the answer to Question 2 may partly explain why the Main Question is hard.
. Therefore, it is unlikely that such a set would stand out as the obvious notion of “explicitly definable” (i.e., one would always be able to find a reasonable looking norm that is not “explicitly definable”). Also, the answer to Question 2 may partly explain why the Main Question is hard.
PS: Does already have a name? I gave it the initials for Banach Norm, but I would rather use existing notation, if any.
already have a name? I gave it the initials for Banach Norm, but I would rather use existing notation, if any.
February 24, 2009 at 10:00 pm |
Tim, let me see if I can get at what you’re saying in slightly more detail. First, I’ll see if I can sketch enough of the proof that Tsirelson’s space doesn’t contain for it to be clear what sort of mathematical power is used in it.
for it to be clear what sort of mathematical power is used in it.
First, one proves that every subspace (which I’ll use as shorthand for “subspace generated by blocks” because standard techniques show that we can restrict attention to those) contains copies of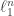 for all
for all  . These copies aren’t quite isometric but the distortion is uniformly bounded, and can in fact be made arbitrarily small. One can even say more: if you want a
. These copies aren’t quite isometric but the distortion is uniformly bounded, and can in fact be made arbitrarily small. One can even say more: if you want a  -accurate copy of
-accurate copy of 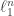 then you can find it in the subspace generated by any
then you can find it in the subspace generated by any  blocks. The proof is easy but I won’t give it here.
blocks. The proof is easy but I won’t give it here.
This rules out (again very easily) and all
and all  spaces with the possible exception of
spaces with the possible exception of  . It remains to prove that you don’t get
. It remains to prove that you don’t get  .
.
Now another result that’s easy to prove — ah, but perhaps this is interesting because the proof is infinitary — is that any space isomorphic to has a (block) subspace that is
has a (block) subspace that is  -isometric to
-isometric to  . The proof is again quite easy: if you know that
. The proof is again quite easy: if you know that 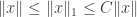 for every
for every  , then you pick a block sequence
, then you pick a block sequence 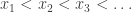 of unit vectors, all the time making
of unit vectors, all the time making 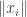 as small as it can be compared with the
as small as it can be compared with the  -norm. Then the ratios may increase, but you get close to the limit and then discard all the initial vectors that were far from the limit. From that point, the triangle inequality tells you that the ratio is never bigger, and the construction tells you that it is never smaller. (Sorry — I didn’t write that carefully and I’ve probably got my smallers and biggers muddled up. But I just wanted to give the logical strength of it — it’s similar in flavour to the proof of the result that a bounded sequence has an increasing or a decreasing subsequence.)
-norm. Then the ratios may increase, but you get close to the limit and then discard all the initial vectors that were far from the limit. From that point, the triangle inequality tells you that the ratio is never bigger, and the construction tells you that it is never smaller. (Sorry — I didn’t write that carefully and I’ve probably got my smallers and biggers muddled up. But I just wanted to give the logical strength of it — it’s similar in flavour to the proof of the result that a bounded sequence has an increasing or a decreasing subsequence.)
Anyhow, all that remains is to show that in any subspace you can find unit vectors
unit vectors  such that
such that 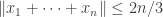 . This is done as follows. First you choose
. This is done as follows. First you choose 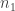 vectors that do generate a copy of
vectors that do generate a copy of  . Let
. Let  be the average of these. If
be the average of these. If 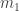 is the maximum of the support of $x_1$, then you set
is the maximum of the support of $x_1$, then you set 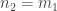 and construct
and construct  in the same way. You keep going like this. The rough idea of the proof is that in order to do anything useful to
in the same way. You keep going like this. The rough idea of the proof is that in order to do anything useful to 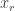 you need at least
you need at least 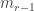 sets
sets 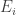 , so they have to start after
, so they have to start after 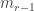 , by the admissibility condition. And this can be used to complete the proof.
, by the admissibility condition. And this can be used to complete the proof.
As I say, my main point is not to make the argument properly comprehensible, but just to demonstrate the sort of induction used in the proof.
My question now to Tim is this. In your Explanation 2 are you imagining the definition of Tsirelson’s space as an important part of the proof that some separable space does not contain or
or  , or are you more interested in the proof, given the definition? My instinct is that the very first step — that there exists a norm that satisfies a certain equation — is crucial.
, or are you more interested in the proof, given the definition? My instinct is that the very first step — that there exists a norm that satisfies a certain equation — is crucial.
I just want to throw out another thought — a rather fanciful one. Suppose one tried to answer the main question by finding a genuinely new type of proof that there was a space that did not contain or
or  . What might such a proof conceivably look like? It seems somehow unlikely that it would consist in giving an unexpectedly clever “direct definition” (whatever that means), but a thought that I have sometimes entertained, and got absolutely nowhere with, is that it might be possible to prove the existence of Banach spaces with strange properties by coming up with some notion of “generic” and proving that a generic Banach space had those properties. I don’t mean anything probabilistic or measure-theoretic: the problem is too infinite-dimensional for that (though there have been some interesting results of a rather different kind proved by pasting together random finite-dimensional spaces). But I have occasionally attempted to do something more Baire-category-ish, with complete lack of success so far. I mention this because it is relevant to Tim’s message: if there were a strange indirect proof of existence, then it would affect the formulation of any result one might try to prove, since one could no longer say that any proof had to go via constructing a Tsirelson-like space, though it might be possible to say that any norm you could define had to use some sort of Tsirelson-like induction.
. What might such a proof conceivably look like? It seems somehow unlikely that it would consist in giving an unexpectedly clever “direct definition” (whatever that means), but a thought that I have sometimes entertained, and got absolutely nowhere with, is that it might be possible to prove the existence of Banach spaces with strange properties by coming up with some notion of “generic” and proving that a generic Banach space had those properties. I don’t mean anything probabilistic or measure-theoretic: the problem is too infinite-dimensional for that (though there have been some interesting results of a rather different kind proved by pasting together random finite-dimensional spaces). But I have occasionally attempted to do something more Baire-category-ish, with complete lack of success so far. I mention this because it is relevant to Tim’s message: if there were a strange indirect proof of existence, then it would affect the formulation of any result one might try to prove, since one could no longer say that any proof had to go via constructing a Tsirelson-like space, though it might be possible to say that any norm you could define had to use some sort of Tsirelson-like induction.
February 24, 2009 at 11:55 pm |
François,
My descriptive set theory background is very sketchy but by the relation of equivalence of norms on I think you mean the equivalence of bases. The complexity of this relation is computed by Rosendal and it is complete
I think you mean the equivalence of bases. The complexity of this relation is computed by Rosendal and it is complete  relation. The relation of isomorphism though is complete analytic on
relation. The relation of isomorphism though is complete analytic on  (I see this notation more often) of standard Borel space of separable Banach spaces.
(I see this notation more often) of standard Borel space of separable Banach spaces.
About Question 1. I am not sure if the class of Banach spaces not containing or
or  is a `nice` subset of
is a `nice` subset of  . Because otherwise you could possibly construct a universal space for this class but not universal for all separable Banach spaces. But I think it is shown that any universal space for all HI spaces is universal for all spaces.
. Because otherwise you could possibly construct a universal space for this class but not universal for all separable Banach spaces. But I think it is shown that any universal space for all HI spaces is universal for all spaces.
February 24, 2009 at 11:59 pm |
It is precisely by considering the problem of constructing a generic space that doesn’t contain or
or  that led me to consider the space
that led me to consider the space  . One of the difficulties is that the target subset of
. One of the difficulties is that the target subset of  appears to be very complex (which is what Question 1 is about).
appears to be very complex (which is what Question 1 is about).
To show that a space with norm doesn’t contain a block sequence
doesn’t contain a block sequence  -equivalent to
-equivalent to  is equivalent to showing that the tree
is equivalent to showing that the tree  of all finite normalized block sequences
of all finite normalized block sequences 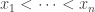 that generate subspaces
that generate subspaces  -equivalent to
-equivalent to 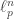 is well-founded. (The block sequences are ordered by end-extension; you may have to flip the tree up side down if your definition of well-founded goes the opposite way that your trees grow.) The ordinal ranks of these trees are the “ranks associated to
is well-founded. (The block sequences are ordered by end-extension; you may have to flip the tree up side down if your definition of well-founded goes the opposite way that your trees grow.) The ordinal ranks of these trees are the “ranks associated to  ” that I alluded to in my comment after Question 1.
” that I alluded to in my comment after Question 1.
The problem with generic and randomized constructions is that they don’t lend themselves easily to constructing well-founded trees, except perhaps “by accident.” Tsirelson’s space is an example where the associated trees are rather short; I don’t know what good would come in trying to construct a space whose trees were rather tall. It seems that successful generic or randomized construction would have to cleverly avoid the well-foundedness issue altogether…
Remark: The final part of Iovino’s argument consists precisely in showing that one of the trees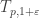 is not well-founded.
is not well-founded.
February 25, 2009 at 12:20 am |
Related to the question of well-founded trees, there are questions that as far as I know have not been answered, concerning just how low the ranks of these trees can be. For example, Krivine’s theorem tells you that every space must contain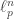 for arbitrarily large
for arbitrarily large  . But can one find a subspace generated by
. But can one find a subspace generated by 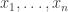 that is within
that is within  of
of 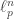 and also satisfies that
and also satisfies that  is at least 100 times the maximum of the support of
is at least 100 times the maximum of the support of  ? One might call this a subspace of dimension
? One might call this a subspace of dimension  . The Tsirelson proof shows that you can’t get
. The Tsirelson proof shows that you can’t get 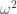 or something like that. Actually, perhaps it’s only
or something like that. Actually, perhaps it’s only 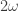 now I come to think about it.
now I come to think about it.
Anyhow, this kind of problem amuses me because of its closeness to the Paris-Harrington theorem. But whereas the Paris-Harrington theorem can be proved by applying the infinite Ramsey theorem, there is no hope of doing that here, since Tsirelson’s space doesn’t contain or
or  . So the problem could be very hard indeed (or if not this one then another one of a similar kind that I know), since one would not expect a proof to be possible in PA, but one cannot use infinitary methods either.
. So the problem could be very hard indeed (or if not this one then another one of a similar kind that I know), since one would not expect a proof to be possible in PA, but one cannot use infinitary methods either.
February 25, 2009 at 12:32 am |
Bunyamin,
Thanks for spotting the typo in Question 2: I did mean equivalence of bases, not of norms.
Thanks also for pointing to Christian Rosendal’s result. One of the relevant papers [Cofinal families of Borel equivalence relations and quasiorders. J. Symbolic Logic 70 (2005)] is not on his website, but the another one is here.
Do you remember a reference for the result on universal HI spaces?
February 25, 2009 at 1:32 am |
To answer Tim’s question, I do include the definition of the norm as part of the proof.
What might tip the balance in favor of Explanation 2 would be something like this. One comes up with a Banach space whose norm is weird-looking but which most people agree is “explicitly defined.” One then proves that it doesn’t contain or
or  . This “new example,” however, turns out not to be so new after all because it’s still based on the same idea underlying the Tsirelson space; however, by some clever tinkering one has managed to shift all the funny induction out of the definition and into the proof. This would be evidence that “explicitly definable norms” won’t save the day. At the same time it would still suggest that a strong induction principle is needed to prove the existence of pathological examples.
. This “new example,” however, turns out not to be so new after all because it’s still based on the same idea underlying the Tsirelson space; however, by some clever tinkering one has managed to shift all the funny induction out of the definition and into the proof. This would be evidence that “explicitly definable norms” won’t save the day. At the same time it would still suggest that a strong induction principle is needed to prove the existence of pathological examples.
On the other hand, if it’s provable in RCA_0 that Schlumprecht’s space is a counterexample, then that would be evidence that it really is the definition of the norm that’s the culprit, rather than the logical strength of “there exists a separable Banach space not containing or
or  .”
.”
February 25, 2009 at 2:10 am |
Universality result is due to Argyros, and it is here.
March 2, 2009 at 8:37 am |
[…] to the original threads and more. (Also a sort of time-table.) Tim Gowers launched a slower-going polymath2 aimed to reach a useful notion of “explicitely defined” Banach space. A […]
March 17, 2010 at 7:33 pm |
[…] the polymath1 project that was devoted to the Density Hales Jewett problem. Since then we had Polymath2 related to Tsirelson spaces in Banach space theory , an intensive Polymath4 devoted to […]
June 7, 2010 at 3:43 pm |
I discern two conceptually different notions of complexity/computability/definability emerging here. First is a combinatorial/analytic notion, which is what Gowers see as distinguishing standard Banach spaces and the Tsirelson space. The second is an arithmetic notion, familiar to the recursion and model theorists.
Our comments began with proposals of formalizing “explicit definability” via complexity of norm (combinatorial) and asymptotic notions of complexity (analysis). Towards the end, as we focused on how model theory could help in this formalization, the proposals involved arithmetic versions of definability.
As Banach spaces use the real numbers as a base field, the real numbers should be treated as a primitive, atomic object. When using recursion theory, the real numbers are coded, resulting in arithmetic versions of complexity, foreign to analytic or combinatorial presentations of Banach spaces.
Banach spaces have a geometry and having or
or  as a subspace could be seen as a regularity property of the geometry. In general, geometry involves the continuum and arithmetic is not well-suited to describe geometry. My suggestion is to focus on formulations of “definability” that are native to the real numbers, and not employ foreign arithmetic systems to judge the complexity of the definition.
as a subspace could be seen as a regularity property of the geometry. In general, geometry involves the continuum and arithmetic is not well-suited to describe geometry. My suggestion is to focus on formulations of “definability” that are native to the real numbers, and not employ foreign arithmetic systems to judge the complexity of the definition.
June 9, 2010 at 11:02 am |
Let me be informal. How are the so-called standard Banach spaces defined? Most often, they are spaces of functions from some measure space X to the real numbers R. The norms on these spaces are defined in by taking supremums or integrals. (Aren’t integrals also supremums over characteristic functions?)
How is the Tsirelson space defined? Via some kind of inductive process involving the natural numbers.
I think the difficulty is that we have been placing notions of definability on a hierarchy relative to the natural numbers N. (I would think that model theory and morley rank is extending this hierarchy relative to the finite ordinals, which still begins with , which is still relative to N). In other words, these notions of definability have to do with recursive process that are arithmetic, and as such foreign to the real numbers, which is more geometric or at least, analytic.
, which is still relative to N). In other words, these notions of definability have to do with recursive process that are arithmetic, and as such foreign to the real numbers, which is more geometric or at least, analytic.
Gowers defined combinatorial spaces, a definition which he didn’t like, describing them as not capturing the notion of “definable Banach space”. This notion of combinatorial spaces does not include the l_p spaces.
Chow and Dorais have considered the amount of recursion needed to define the norm or to describe the functions that the norm can give rise. It has not been easy to separate the Tsirelson space or variant of it from such weak version of recursion.
Combinatorics and weak versions of primitive recursion are opposite ends of a spectrum that are relative to the natural numbers N.
I’m arguing that we should have some kind of R-combinatorial notion. For instance, the supremum operation that takes a subset of R and gives its supremum is a basic operation in analytic. In fact, it is basic to the axiomatic definition of completeness of the reals. How about a language that allows the supremum operation, on top of taking the basic ring operations?
Let me try to formalize what is means for a subspace of the function space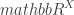 to be a “definable Banach space”. Here X is an abstract measure space. (The purpose of using an abstract measure space instead of N with counting measure is to make clear that I don’t want to rely on N).
to be a “definable Banach space”. Here X is an abstract measure space. (The purpose of using an abstract measure space instead of N with counting measure is to make clear that I don’t want to rely on N).
This language will have two types. One for functions and the other for real scalars
and the other for real scalars  . This two-typed language consists of ring operations of scalars, and ring operations of functions. The key feature is the supremum operation.
. This two-typed language consists of ring operations of scalars, and ring operations of functions. The key feature is the supremum operation.
The idea is somehow to be able to express integration. If we can express integration, then a “definable norm” could be one that the integrand is a definable formula in this two-typed language. For instance to define the integrand for the L_p norm, we first notice that
for the L_p norm, we first notice that 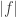 can be expressed in terms of
can be expressed in terms of 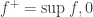 and
and  . Integer powers are just iterated multiplication, rational powers amount to solving an equation
. Integer powers are just iterated multiplication, rational powers amount to solving an equation 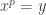 . Taking arbitrary p-th powers can be expressed as a supremum of p_n-norms for a rational sequence increasing to p.
. Taking arbitrary p-th powers can be expressed as a supremum of p_n-norms for a rational sequence increasing to p.
What I suggest is not complete and will like contain many unrigorous parts. What I’m trying to push for is to have a notion of “explicitly definable Banach space” in the manner in which we define it in class. Look at how we define it usually as in class. Take the basic operations like integration and supremum. Find languages to describe this operations. This is the basic process from examples to axiomatization.
What I’m cautious towards is the attempt to reduce this manner of definition in class to other kinds of definability/computability hierarchy like those in recursion or model theory. Recursion theory is an attempt to define complexity of functions from N->N.
We should look at definability of Banach spaces per se, on its own accord, and not true to reduce to another system. We are already aware that the ordinal hierarchy leads to undecidability with dealing with geometry and the real numbers. Let’s try to work on the real numbers as a primitive concept, and not in terms of the natural numbers.
This is my appeal.
January 23, 2015 at 3:17 pm |
[…] ¿Debe un espacio de Banach “explicitamente definido” contener c_0 o l_p? Ahora sabremos la respuesta. […]
October 26, 2015 at 3:18 am |
[…] ¿Debe un espacio de Banach “explicitamente definido” contener c_0 o l_p? Ahora sabremos la respuesta. […]
April 5, 2020 at 6:32 am |
“At some point I should give the rather nice proof that Tsirelson’s space does not contain c_0 or l_p , but strictly speaking it isn’t actually needed for this problem.”
Hi Tim, did you actually gave it? Another question: is Tsirelson’s space related to your works in Banach space theory from the late 80s-early 90s?
April 5, 2020 at 6:33 am |
[…] Boris was a devoted Wikipedian and his Wikipidea user page is now devoted to his memory; Here is a great interview with Boris; A very nice memorial post on Freeman Dyson and Boris Tsirelson on the Shtetl Optimized; Tim Gowers explains some ideas behind Tsirelson’s space over Twitter; and here in Polymath2. […]