If you are a mathematical researcher, do you ever stop to ask yourself what the point is of all your research? Do you worry that the world could get along just fine without it?
One person who doesn’t lose any sleep over doubts like this is Emmanuel Candès, who gave the second plenary lecture I went to. He began by talking a little about the motivation for the kinds of problems he was going to discuss, which one could summarize as follows: his research is worthwhile because it helps save the lives of children. More precisely, it used to be the case that if a child had an illness that was sufficiently serious to warrant an MRI scan, then doctors faced the following dilemma. In order for the image to be useful, the child would have to keep completely still for two minutes. The only way to achieve that was to stop the child’s breathing for those two minutes. But depriving a child’s brain (or indeed any brain, I’d imagine) of oxygen for two minutes is not without risk, to put it mildly.
Now, thanks to the famous work of Candès and others on compressed sensing, one can reconstruct the image using many fewer samples, which reduces the time the child must keep still to 15 seconds. Depriving the brain of oxygen for 15 seconds is not risky at all. Candès told us about a specific boy who had something seriously wrong with his liver (I’ve forgotten the details) who benefited from this. If you want a ready answer for when people ask you about the point of doing maths, and if you’re sick of the Hardy-said-number-theory-useless-ha-ha-but-what-about-public-key-cryptography-internet-security-blah-blah example, then I recommend watching at least some of Candès’s lecture, which is available here, and using that instead. Then you’ll really have seized the moral high ground.
Actually, I recommend watching it anyway, because it was a fascinating lecture from start to finish. In that case, you may like to regard this post as something like a film review with spoilers: if you mind spoilers, then you’d better stop reading here.
I have to admit that as I started this post, I realized that there was something fairly crucial that I didn’t understand, that meant I couldn’t give a satisfactory account of what I wanted to describe. I didn’t take many notes during the talk, because I just wanted to sit back and enjoy it, and it felt as though I would remember everything easily, but there was one important mathematical point that I missed. I’ll come back to it in a moment.
Anyhow, the basic mathematical problem that the MRI scan leads to is this. A full scan basically presents you with the Fourier transform of the image you want, so to reconstruct the image you simply invert the Fourier transform. But if you are sampling in only two percent of directions and you take an inverse Fourier transform (it’s easy to make sense of that, but I won’t bother here), then you get a distorted image with all sorts of strange lines all over it — Candès showed us a picture — and it is useless for diagnostic purposes.
So, in a moment that Candès described as one of the luckiest in his life, a radiologist approached him and asked if there was any way of getting the right image from the much smaller set of samples. On the face of it, the answer might seem to be no, since the dimension of the space of possible outputs has become much smaller, so there must be many distinctions between inputs that are not detectable any more. However, in practice the answer is yes, for reasons that I’ll discuss after I’ve mentioned Candès’s second example.
The second example was related to things like the Netflix challenge, which was to find a good way of predicting which films somebody would like, given the preferences of other people and at least some of the preferences of the person in question. If we make the reasonable hypothesis that people’s preferences depend by and large on a fairly small number of variables (describing properties of the people and properties of the films), then we might expect that a matrix where the 


And thus we arrive at the following problem: you are given a few scattered entries of a matrix, and you want to find a low-rank matrix that agrees pretty well with the entries you observe. Also, you want it the low-rank matrix to be unique (up to a small perturbation) since otherwise you can’t use it for prediction.
As Candès pointed out, simple examples show that the uniqueness condition cannot always be obtained. For example, suppose you have 99 people with very similar preferences and one person whose preferences are completely different. Then the underlying matrix that describes their preferences has rank 2 — basically, one row for describing the preferences of the 99 and one for describing the preference of the one eccentric outlier. If all you have is a few entries for the outlier’s preferences, then there is nothing you can do to guess anything else about those preferences.
However, there is a natural assumption you can make, which I’ve now forgotten, that rules out this kind of example, and if a matrix satisfies this assumption then it can be reconstructed exactly.
Writing this, I realize that Candès was actually discussing a slight idealization of the problem I’ve described, in that he didn’t have perturbations. In other words, the problem was to reconstruct a low-rank matrix exactly from a few entries. An obvious necessary condition is that the number of samples should exceed the number of degrees of freedom of the set of low-rank matrices. But there are other conditions such as the one I’ve mentioned, and also things like that every row and every column should have a few samples. But given those conditions (or perhaps the sampling is done at random — I can’t remember) it turns out to be possible to reconstruct the matrix exactly.
The MRI problem boils down to something like this. You have a set of linear equations to solve (because you want to invert a Fourier transform) but the number of unknowns is significantly larger than the number of equations (because you have a sparse set of samples of the Fourier transform you want to invert). This is an impossible problem unless you make some assumption about the solution, and the assumption Candès makes is that it should be a sparse vector, meaning that it has only a few non-zero entries. This reduces the number of degrees of freedom considerably, but the resulting problem is no longer pure linear algebra.
The point that I missed was what sparse vectors have to do with MRI scans, since the image you want to reconstruct doesn’t appear to be a sparse vector. But looking back at the video I see that Candès addressed this point as follows: although the image is not sparse, the gradient of the image is sparse. Roughly speaking, you get quite a lot of patches of fairly constant colour, and if you assume that that is the case, then the number of degrees of freedom in the solution goes right down and you have a chance of reconstructing the image.
Going back to the more general problem, there is another condition that is needed in order to make it soluble, which is that the matrix of equations should not have too many sparse rows, since typically a sparse row acting on a sparse vector will give you zero, which doesn’t help you to work out what the sparse vector was.
I don’t want to say too much more, but there was one point that particularly appealed to me. If you try to solve these problems in the obvious way, then you might try to find algorithms for solving the following problems.
1. Given a system of underdetermined linear equations, find the sparsest solution.
2. Given a set of entries of a matrix, find the lowest rank matrix consistent with those entries.
Unfortunately, no efficient algorithms are known for these problems, and I think in the second case it’s even NP complete. However, what Candès and his collaborators did was consider convex relaxations of these problems.
1. Given a system of underdetermined linear equations, find the solution with smallest 
2. Given a set of entries of a matrix, find the matrix with smallest nuclear norm consistent with those entries.
If you don’t know what the nuclear norm is, it’s simple to define. Whereas the rank of a matrix 

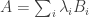
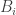
It’s a standard fact that convex relaxations of problems tend to be much easier than the problems themselves. But usually that comes at a significant cost: the solutions you get out are not solutions of the form you originally wanted, but more like convex combinations of such solutions. (For example, if you relax the graph-colouring problem, you can solve the relaxation but you get something called a fractional colouring of your graph, where the total amount of each colour at two adjacent vertices is at most 1, and that can’t easily be converted into a genuine colouring.)
However, in the cases that Candès was telling us about, it turns out that if you solve the convex relaxations, you get exactly correct solutions to the original problems. So you have the following very nice situation: a problem is NP-complete, but if you nevertheless go ahead and try to solve it using an algorithm that is doomed to fail in general, the algorithm still works in a wide range of interesting cases.
At first this seems miraculous, but Candès spent the rest of the talk explaining to us why it isn’t. It boiled down to a very geometrical picture: you have a convex body and a plane through one of its extreme points, and if the plane is tangent to the body then the algorithm will work. It is this geometrical condition that underlies the necessary conditions I mentioned earlier.
For me this lecture was one of the highlights of the ICM, and I met many other people who greatly enjoyed it too.

August 25, 2014 at 12:00 pm |
A good math result could be motivating to anyone in any line of work. What is worrying are continuing problems with communication. E.g., consider Catalan conjecture: no mention of the solution in mass media, moreover the title in
Click to access S0273-0979-03-00993-5.pdf
is not accurate, as the problem can be stated without the mention of the word “equation”.
August 25, 2014 at 1:03 pm |
Tim,
To get a bird’s eye view of the development in these two areas, compressive sensing and advanced matrix factorizations, you might want to check these two pages I curate;
Advanced matrix factorizations:
https://sites.google.com/site/igorcarron2/matrixfactorizations
Compressive Sensing, The Big Picture
https://sites.google.com/site/igorcarron2/cs
Since all these problems are NP-hard in general, we have seen a lot of activities on how to relax those and have had a slew of different algorithms to implement each of these relaxations. In my view, what has really changed the view of most people is the discovery that beyond asymptotics, most of these relaxations yields good results up to sharp phase transitions and instead of usual long infightings about asymptotics and attendant constants which used to be an issue for the longest time, these phase transitions are pretty much the acid test of certain problems yielding true insights (see http://nuit-blanche.blogspot.fr/2013/11/sunday-morning-insight-map-makers.html).
And “…yes, we expect the mathematicians to clear the waters there…” ( http://nuit-blanche.blogspot.fr/2013/10/sunday-morning-insight-watching-p-vs-np.html )
Cheers,
Igor.
August 25, 2014 at 1:19 pm |
Were there any new big ideas in compressed sensing in the last 2-3 years?
August 25, 2014 at 1:29 pm
I’d say a quite few by using additional structure in the signal.
August 25, 2014 at 9:16 pm
This is a good question.
While I had watched Candès’ lecture before it was referred to here -and I enjoyed it very much- I must say that I was left with the feeling that compressed sensing seems to be stuck exactly in the same place where it was circa 2010/2011.
There have been a lot of incremental research but the basic idea, the applications targeted, and the most general results seem to be the same. Nothing really revolutionary seems to have been produced since that would make all other sampling methods obsolete. Compressed sensing seems to have found its niche in MRI -which is onto itself significant-, but that’s about it.
The Netflix Prize was awarded in 2009. While privacy considerations have prevented newer editions, it doesn’t seem to me that there has been any significant progress towards beating the methods used by the team who won the 2009 edition using compressed sensing ideas.
Insight from people current with the state of the art in compressed sensing would be appreciated.
August 26, 2014 at 3:45 pm
I haven’t followed developments closely in the last few years, but among recent developments have been to use compressed sensing methods to perform phase reconstruction and superresolution (see e.g. Candes’ slides at http://www.itsoc.org/resources/media/isit-2013-istanbul/CandesISIT2013.pdf , which are focused on more recent applications than the ones in his ICM talk). The applications here are not as dramatic as those in MRI, but it may take a few more years for the applied side of these new developments to bear fruit.
August 27, 2014 at 3:07 am
Thanks Terence (or Terry, whichever you prefer 🙂 ),
I skimmed through the ISIT presentation that you provided. I think that both are interesting applications, but the one that is probably most likely to gain traction, if compressed sensing comes with a practical implementation, is superresolution. Digital imaging is everywhere and I see it could be a very interesting application: getting high resolution images from from low resolution ones (subject to some application dependent constrains that would solve the uncertainty inherent to the problem) .
In a previous life (like 8 years ago), I did some experiments with the existing methods at the time of reconstructing audio signals from the magnitude of the Fourier coefficients. Not an easy problem by any means. My conclusion was that it is something one should try to avoid doing unless there is no choice. There are very few practical situations in which those phase coefficients are not available in any way or that the phase coefficients cannot be reasonably estimated from time delays.
I must add that I am humbled that you thought that addressing my question was worth your time :).
August 27, 2014 at 2:57 pm
As Terry said some of the other development are not as dramatic as “saving children’s life through faster MRI sampling” because of hardware. MRI does not require a change of hardware to experiment with the sampling reductionbrought forth by compressive sensing Pretty much everything else does. When that is the case, Compressive Sensing just becomes of the ways to get an answer from detectors and sometimes it is difficult to make it shine against well oiled signal processing chains already in place (CT scanners is one example Ihave in mind). I have highlighted some of the other breakthroughs earlier (structured sparsity, asymptotic sparsity and advanced marix factorization. In terms of hardware, it currently either blends in to current signal processing chains or it may open some totally different avenues ( shameful self promotion, http://www.nature.com/srep/2014/140709/srep05552/full/srep05552.html).
Igor.
August 28, 2014 at 4:53 am
Thanks Igor,
I find sampling theory fascinating. So much so, that I did my PhD research on it years ago. I got a degree in engineering but it could have been as well a PhD in applied math since sampling is what it was all about.
If it weren’t because I have made a few controversial remarks in a blog of an influential Fields Medalist, I wouldn’t mind to provide a link to my own work :).
I stopped working on sampling as soon as I graduated, but I still try to follow as much as I can, that’s why I was eager to learn about what Emmanuel Candès had to say at the ICM.
I know that most mathematicians by training consider applied math a sort of waste, but in this day and age, applied math is more relevant than it has ever been given the complexity of the systems we build and the amount of information these systems need to process.
Besides, the beauty of mathematics from my point of view, and here comes yet another controversial remark, is that mathematical concepts are as real as the physical world, only the physical world is a “subset” of all the mathematical reality, the subset that our sensors perceive. Richard Feynman said that nature speaks the language of mathematics, which is true, but I think it is because nature is a subset of the larger mathematical realm: God himself.
August 25, 2014 at 2:14 pm |
Here is a piece that Jordan Ellenberg wrote for Wired about compressed sensing and faster MRIs for children.
August 25, 2014 at 6:30 pm |
Thanks for linking, Mark, but I should warn that the Wired piece, probably more than most things I write for a general audience, really required a lot of oversimplification and dumbing down, and the readership of this blog will definitely get more from Emmanuel’s talk itself!
August 25, 2014 at 8:21 pm |
Jordan: Fair enough. I figured that pointing out that it was published in Wired constituted fair warning.
August 25, 2014 at 10:07 pm |
Reblogged this on Math Online Tom Circle.
August 30, 2014 at 7:29 pm |
I’m wondering if you could model the person’s head moving around as well, so that you don’t even need to stop the breathing at all. Possibly it’s sort of like correcting for “camera shake”, which there are methods for. Although I guess a lot of the movement wouldn’t be rigid motions (and so harder to deal with), and presumably you’d need a significantly longer scan time. (You could test on 15-second still images to develop the method / measure its accuracy, although ideally they wouldn’t be needed.)
November 25, 2014 at 3:07 pm |
[…] In his PhD thesis, Candès developed “curvelets”, a new variant on the technique of data representation known as wavelets. He described this work in “What is a curvelet?”, which appeared in the Notices of the AMS in December 2003 (freely available at http://www.ams.org/notices/200311/what-is.pdf). For a compelling description of Candès’s work, see the entry in Timothy Gowers’s blog, “ICM2014 — Emmanuel Candès plenary lecture” (https://gowers.wordpress.com/2014/08/25/icm2014-emmanuel-cands-plenary-lecture/). […]