To a casual observer it may look as though the frequency of comments to Polymath5 is dauntingly fast — much faster than it was for Polymath1, say. However, I think appearances are misleading, because many of the comments are very short, and on the whole they are easy to understand because they are not too theoretical. I’ll give the usual roundup later in this post, but I thought I’d begin with a few remarks about the polymath process itself, because I think that Polymath5 has already demonstrated a few things that were not clear, or at least were less clear, before.
The most obvious, given the way the discussion has been going so far, is that the process is ideal for problems where there is the potential for an interplay between theory and experiment. When looking at DHJ, we looked at both theory and experiment, but the two were fairly disjoint. This was due to the nature of the problem: it is not computationally feasible to gather data about DHJ except in very low dimensions, and it is therefore difficult to draw any general conclusions from the results. But for the Erdős discrepancy problem the situation is quite different, and we have learned a huge amount from looking at long sequences that have been generated experimentally. (The main three things we have learned are that they can be surprisingly long, that if they are surprisingly long then they probably have to have some multiplicative structure, and that they have this structure in a approximate sense rather than an exact one.)
Why is this significant? Well, one of the points of polymath-style collaborations was supposed to be that it would greatly speed up the process of making and evaluating those little conjectures that you hope will shed light on a problem and, if you are lucky, turn into useful lemmas. The thought was that some people could throw out guesses, and a group of people each with slightly different expertise would be able to assess the plausibility of those guesses much more quickly than any single individual. So both the generation and evaluation of the guesses would happen much more quickly. But here we have a further speed-up, which is that the experimental evidence already alters the prior plausibility of guesses. For instance, one can conjecture with some confidence that an infinite sequence with bounded discrepancy must have a lot of multiplicative structure: before, that would have been much more speculative. (The fact that random sequences fail miserably suggests that some structure is needed, so I suppose I should add that the key word above is “multiplicative”.)
A second difference between Polymath5 and Polymath1 is that there is an additional tool available now, namely mathoverflow. This may sound like a minor addition, but I think it could turn out to be highly significant. Several people noted that the difficulty of keeping up with the discussion was a notable barrier to participation in Polymath1. Presumably this meant that even if some of the questions that were being asked were self-contained, the people who might know the answers to those questions would not necessarily have the time or inclination to search for them (especially as they might not expect to find them). But now, every time a self-contained question arises that seems as though it might be doable by somebody with the right knowledge, it can be posted on mathoverflow, where people can answer it without having to follow what’s going on in the wider discussion. For the purposes of giving credit where it is due, it might be good to have a page on the wiki that lists all questions related to the project that have been asked on mathoverflow and briefly describes their status. (One can also see what they are by using the polymath5 tag at mathoverflow itself.) Needless to say, any crucial help that we get from mathoverflow will be appropriately acknowledged in any paper that might result from the project.
I find it interesting that the wiki for Polymath5 has a rather different flavour from that of the wiki for Polymath1: it is more focused on the discussion itself and less on background knowledge. It will be interesting to see whether when the more theoretical discussion begins the character of the wiki will change.
A small difference between Polymath5 and Polymath1 is that we are (so far at least) not numbering the comments, and instead are making full use of the threading, which I am still allowing only up to depth 1. I think this has worked rather well, especially when people provide links to comments that they refer to. It means that some of the chronological feel of the discussion, which I think is important, is preserved, but it is also split to some extent into mini-discussions, so that when one looks back at the comments later they are better organized. If we can keep this going, and are also assiduous about putting useful information (experimental results, observations, lemmas, outlines of proof strategies, etc.) on the wiki, then I hope that the barrier to late entry will be much lower than it was for Polymath1.
Returning to the mathematics, in the last few hours it has emerged that there is a striking pattern in the original sequence of length 1124. I am so interested in it that I don’t really have the energy to write about anything else that has been discussed in the last 100 comments, but perhaps I’ll add a brief summary later. (Right now I want to get this post out fast because when I last looked there were 99 comments and probably there are 100 by now, or at any rate will be very soon.)
I now think it likely that we will come up with a formula that gives something very close to the 1124 sequence. If so, then I am keeping my fingers very firmly crossed that it will give an infinite sequence with sublogarithmic discrepancy. But we shall see: some computation is still needed before we will know what the formula is. There is also a chance that we will obtain a formula but with parameters that have to be chosen for each prime, and that we will not be able to see how to choose them in general. In that case, we may at least obtain a very efficient algorithm for finding extremely long sequences of low discrepancy.

January 16, 2010 at 9:43 pm |
I’m going to re-raise my question about how to unify the (proposed) construction of an extension of the 1124-sequence with the construction of quasi-multiplicative sequences. Here’s a stab at a definition of quasi-multiplicative in the same style:
A sequence is quasi-multiplicative if there exists an integer and, for each prime p, a rational number
and, for each prime p, a rational number 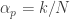 such that when
such that when 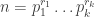 , we define
, we define  (mod 1), and set
(mod 1), and set  to be +1 or -1 based on whether
to be +1 or -1 based on whether 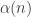 lies in some subinterval of [0, 1).
lies in some subinterval of [0, 1).
I don’t think this is quite the same as before — in particular I don’t see how to factor through a non-cyclic group — but it’s reasonably close.
January 16, 2010 at 10:04 pm
This is pretty much from my brain to the keyboard, so there’s a very good chance some of it will be incorrect.
Okay, a little more about this. Using the above definition and taking a sequence of sequences (this might deserve a better name, particularly if the approach I’m taking turns out to be fruitful) of this form where the are approximations to real numbers
are approximations to real numbers 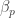 , we’ll get a sequence of sequences that converges pointwise to the sequence with
, we’ll get a sequence of sequences that converges pointwise to the sequence with 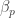 .
.
Running through the calculations quickly in my head, if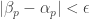 , the sequences should agree at values of n divisible by fewer than
, the sequences should agree at values of n divisible by fewer than 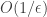 primes, which means that if you can get sublogarithmic discrepancy with the above definition (even allowing the
primes, which means that if you can get sublogarithmic discrepancy with the above definition (even allowing the  s to be irrational) you can get it with a quasi-multiplicative sequence.
s to be irrational) you can get it with a quasi-multiplicative sequence.
So the improvement would have to come, I think, from the signs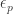 . To be honest I'm not sure yet why these are useful — anyone have an explanation?
. To be honest I'm not sure yet why these are useful — anyone have an explanation?
January 16, 2010 at 10:34 pm
Of course — the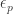 mean that we’re multiplying pointwise by a completely multiplicative sequence. So all we’re doing is taking pointwise products of these limits of sequences of quasi-multiplicative sequences, which I think the product of two quasi-multiplicative sequences is a quasi-multiplicative sequence with the product of the underlying groups as the new underlying group. It’s possible I did something wrong in my analysis, but this makes me pessimistic about the prospect of getting a sub-logarithmic sequence.
mean that we’re multiplying pointwise by a completely multiplicative sequence. So all we’re doing is taking pointwise products of these limits of sequences of quasi-multiplicative sequences, which I think the product of two quasi-multiplicative sequences is a quasi-multiplicative sequence with the product of the underlying groups as the new underlying group. It’s possible I did something wrong in my analysis, but this makes me pessimistic about the prospect of getting a sub-logarithmic sequence.
January 16, 2010 at 10:31 pm |
No time to respond to Harrison’s ideas for the moment, but I wanted to make one more remark. The fact that the shift associated with seems to be roughly proportional to
seems to be roughly proportional to  puts me very much in mind of Dirichlet series once again (since
puts me very much in mind of Dirichlet series once again (since  ). But it also makes me wonder whether the irrational rotation associated with
). But it also makes me wonder whether the irrational rotation associated with  should also be proportional to
should also be proportional to  . There are all sorts of reasons that this would make sense. It begins to look as though a good sequence could be defined as follows. You take an interval
. There are all sorts of reasons that this would make sense. It begins to look as though a good sequence could be defined as follows. You take an interval  mod 1 and some real number
mod 1 and some real number  . You then define
. You then define  to be 1 if
to be 1 if 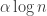 belongs to
belongs to  mod 1 and -1 otherwise. Finally, you multiply
mod 1 and -1 otherwise. Finally, you multiply  by some completely multiplicative function.
by some completely multiplicative function.
Again this is semi-guesswork in that I haven’t checked that the above idea is sensible. But it feels to me as though it or some modification of it could be significant. (What it doesn’t appear to explain, however, is the observation that the shifts don’t grow monotonically but only approximately monotonically. But maybe some refinement of the idea would deal with that too.)
January 16, 2010 at 10:52 pm |
Tim, I’m trying to understand how, given the values taken by your function , one might deduce (or guess) the
, one might deduce (or guess) the 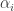 and
and 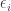 . I see that the sequence
. I see that the sequence  for prime
for prime  has different statistics depending on
has different statistics depending on 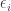 : if
: if 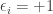 then it will be
then it will be 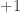 if and only if
if and only if  (so slightly more often than not), while if
(so slightly more often than not), while if 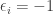 it will be
it will be 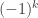 if and only if
if and only if  , which is
, which is 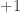 about half the time. But we only have a few (
about half the time. But we only have a few (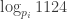 ) terms of each of these sequences, not enough to deduce much with confidence, except that if we get two
) terms of each of these sequences, not enough to deduce much with confidence, except that if we get two  s in a row it must be
s in a row it must be  . And I can't quite see how to get a handle on the
. And I can't quite see how to get a handle on the 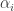 , even assuming they are multiples of
, even assuming they are multiples of  . Am I missing something simple?
. Am I missing something simple?
January 17, 2010 at 1:07 am
I’ll have to think about this. Meanwhile, I’ve been looking at your data on the wiki, and checking for the multiplicativity of the signs. I see that it doesn’t work completely. For example,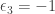 ,
, 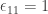 , but
, but  . Also
. Also  . Another thing I need to think about is whether I can explain these new anomalies away (or even whether they are anomalies at all).
. Another thing I need to think about is whether I can explain these new anomalies away (or even whether they are anomalies at all).
January 17, 2010 at 6:22 am
Apologies, I made a typo at 25: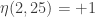 . And 33 was one of the few that didn’t exactly match any shift (unless you want to go up to a shift of 8).
. And 33 was one of the few that didn’t exactly match any shift (unless you want to go up to a shift of 8).
This makes the agreement between the two 1124 sequences even better: now they agree at , and the second one does have complete multiplicativity in its
, and the second one does have complete multiplicativity in its 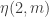 .
.
January 17, 2010 at 7:06 am
And I made another typo at 33: so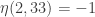 , which is good news. Sorry about that!
, which is good news. Sorry about that!
January 16, 2010 at 11:35 pm |
I’ve added a page to the wiki with a table of values of and
and  , defined (subject to anomalies) by
, defined (subject to anomalies) by
for the first few values of and
and  .
.
January 17, 2010 at 12:03 am |
And I’ve just done the same experiment on the second 1124 sequence and found, rather amazingly, the same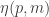 and
and  for all pairs listed in the table apart from
for all pairs listed in the table apart from  ,
, 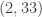 ,
,  ,
, 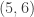 and all of the
and all of the  .
.
January 17, 2010 at 1:46 am |
It would be good to think more systematically about what kind of function we might be looking for, by listing the properties that this function seems to have. Writing instead of
instead of  , the main property is the equation that Alec wrote above, namely that if
, the main property is the equation that Alec wrote above, namely that if  , then
, then  . But we also appear to know that
. But we also appear to know that  is comparable to
is comparable to  (since if we multiply by
(since if we multiply by  then we should shift by exactly 1, and the amount we shift seems to be approximately monotonic). Note that
then we should shift by exactly 1, and the amount we shift seems to be approximately monotonic). Note that 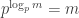 , so
, so 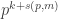 is a power of
is a power of  that is close to
that is close to  . In other words, in some strange sense we’ve got something like
. In other words, in some strange sense we’ve got something like  , which looks ridiculous except that the second
, which looks ridiculous except that the second 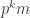 isn’t exactly equal to
isn’t exactly equal to 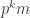 . So it’s sort of telling us that the sequences for
. So it’s sort of telling us that the sequences for  and
and 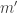 will tend to be equal or minus small shifts of each other when
will tend to be equal or minus small shifts of each other when  and
and 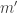 are close, as we do indeed observe. Here, “close” means that their logs to base
are close, as we do indeed observe. Here, “close” means that their logs to base  are additively close (where the difference is independent of
are additively close (where the difference is independent of  ).
).
I’ll continue this line of thought, but along slightly different lines, in a separate comment.
January 17, 2010 at 1:59 am |
Going back to Dirichlet series, I’m now wondering whether it might be fruitful to think about the complex case. It seems that somehow the 1124 sequence is trying to be the complex case but can’t because it’s forced to be a sequence.
sequence.
I’m wondering about what we can say about the HAP-discrepancy of functions of the form , where
, where  is a completely multiplicative
is a completely multiplicative  function and
function and  is a real number. This makes
is a real number. This makes  itself completely multiplicative, so we’re asking about its partial sums.
itself completely multiplicative, so we’re asking about its partial sums.
Why might an expression like this be small? Well, let’s take Walters’s example (I realize that it probably predates Walters, but I heard it from Walters before e.g. the preprint of Borwein and Choi came out), namely the function that’s 1 if the last non-zero digit in ternary is 1 and is -1 otherwise. Recall that to calculate the partial sums of this we partition the integers up to according to which is the last digit not to be zero. So now we could do the same but throwing in the extra
according to which is the last digit not to be zero. So now we could do the same but throwing in the extra  term.
term.
This will give us a whole lot of sums of a rather similar type, but each time we multiply by 3 we rotate by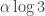 or something like that.
or something like that.
At this point I can’t see what’s going to happen. I think the most likely is that the growth is still logarithmic but that it is slightly harder to prove that (which would be disappointing). There seems to me to be a small chance that things are messed up in a random-like way that causes the growth to go down to something more like (which would be pretty nice). And I think there’s almost zero chance that it will be any better than that. Even the “small chance” looks pretty small, since it seems like a version of the trick of alternating the signs associated with 3, 9, 27, etc., which gained only a factor of 2.
(which would be pretty nice). And I think there’s almost zero chance that it will be any better than that. Even the “small chance” looks pretty small, since it seems like a version of the trick of alternating the signs associated with 3, 9, 27, etc., which gained only a factor of 2.
January 17, 2010 at 5:52 pm
I’ve thought about this a bit further, and it really doesn’t seem as though it’s going to lead to a sequence with sublogarithmic growth unless there is something about the signs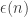 that is already miraculously good. In particular, I don’t think that using a character-like function is going to work. (However, my saying this shouldn’t put off anyone who wants to investigate it for themselves.)
that is already miraculously good. In particular, I don’t think that using a character-like function is going to work. (However, my saying this shouldn’t put off anyone who wants to investigate it for themselves.)
A different thought, based on the same circle of ideas, is that we might be able to improve the 1124 example by taking the best multiplicative sequence we can and using it to define a quasi-multiplicative sequence that makes use of the group (and a subset that is something like an interval of length
(and a subset that is something like an interval of length  in one copy of
in one copy of 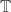 and the complement of that interval in the other).
and the complement of that interval in the other).
I’m still not quite sure what to do about the shifts, but one idea is simply to define to be
to be 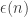 if
if  mod 1 and
mod 1 and 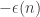 otherwise. It might be that that was “too perfect” to give a sequence of length 1124 and discrepancy 2, but it would be interesting even if it made only a few mistakes, so to speak. I’ll try to be more precise about what
otherwise. It might be that that was “too perfect” to give a sequence of length 1124 and discrepancy 2, but it would be interesting even if it made only a few mistakes, so to speak. I’ll try to be more precise about what  and
and  should be in a future comment.
should be in a future comment.
January 17, 2010 at 7:35 am |
I’ve taken a different approach to finding long sequences of low discrepancy. First I generate an initial +- sequence of length N, and calculate all the partial sums. Then I go back over each element in the sequence many times, switching its value if that helps some objective function of the partial sums. I haven’t played with it too much yet, but finding N=10000 discrepancy 3 is easy, as is N=100000 discrepancy 4.
Right now I’m using an objective function with a reward for decreasing the absolute value of the sum of a HAP x and penalty for increasing it, both proportional to x and 10^sum.
Here’s an example of a N=3000 discrepancy 2 sequence, if someone could verify that then I’d guess the search doesn’t have a bug:
++—+++—+-+—+—-++—+–+–++++–++++-+——-+–++++–+–+++–+-+–+-+—–++++—+-+++-+++++–+-+-+-+-++–++-++++-++—+-++++-+-++++-+—–+++++–+-++-++-+—+–+++++-+-++–++++-++-++++-+-+-+-++-+++-+–+–+—+++++-+–+—++-+—+++-+-+++—+—+++++—-+++–+–+-+-+++–+–+++-++—+++-+–+-+–++-+—++++—+–+++-++—-++—–+++-+++——++–+++-+–+-+–+–++—++++++-+++++-++++-+—-++++-+-+—++–+-++-++-+++++—-+-+-+++-+–++—++-++—-+–+++-+—+–+—–+—+++—++++—-+++-+-++-+—-+-+-++—+—-++-+++-+—-++++++-+++-+-+—+——–++—+—+–++–++-+–+–+–+–+-+–++—+-+-+-+-++-+++–+—+-++—+—-+-++-++++—++–+-+—+-+-+++—++–+-+–++-++–++-+-++++-+++-+–+–+-+-++—++—–++—+++-+-+-+++—+++-+++++++-++-++-+-+++—+——-+++-+—+++-++-++++–+–++–++–++++-+-+-+++-+–++++-+——+–+++-+-++–+–+-+++-++—+-+——+-+–++-++++———+—++-++–+-+-++++++—+-+-++-++——++—++———-+-+-+++++—–+-+-++–+-++-+-++-+–+-+—-+-+++–++++-+-+–++++++-+++++-+++–+-++—–++-+-++++-++++-+++—-++-+-+-++–++-++—-++–+++-+—-+——+-++++-+—–+++–+—-+-++++–++-++++-++++-+—+-++—+-+-++—-+++–++—+-++++++—+-+–+-++-+—-++++—++-+++—++-+–++++-+—+-+-++-+-+-+++-+-++–++-+++-+—++-++-+-+++–+-+–+–++++-+-+++-+-+++-++–++–++-+-+—–+-++——+++++—+-+-++—+++-++-++-++–++-++-+-+——-+++++–+—+–+-+—+–+++-+++–+-++-++–++–+—++++++++-+++—-+++++-+++–+++++—+—-+—++—–+++++-++–++—-+-++-++–++-++++++–+–+++—+-++–+-+-++-++-++-+-++++-+—-++–+—-+—++-+—–+-+—-+-++–+-++-+-+-+-+-+-++—+++-+—+-+-+-++—+–+-++-++-+–+—-+—+–+++++++++++-++-+—+-++—++-++-+–+++-+++++-+–+—-+-+++—++++++—+–+++–+-++-++–++–+-+—+-+-+-+++—++-+++++-+-+++++-+–++-++-+-+–+—–+++++++++-+–+++-+-+—-++++—++—+–++-+–+-++-+-+++++-+–+–+–+++—+++–+-+—++–+++-+-++-+–+-++—–+-+-++—+++——-+—+++—-+——+-++++—-++—–+–+–+-+-+++-+–++–++—++–+-++–+++-++–+++++—–+—+-++–+——+-++-+—-++++-++—–++–+-+-+—–+–+—+——+–+-+—+++-+-+–+++-++++-+-++—++—+—-++++-++-+-+–++++++-++—-++++——++++++–+-++-++-+++-+-+-+++-+-+—-+–+–++-+++-+++–+-+–++++–+++++-++-++—-+—++++–+–++-+—+–+–+++—++—+-+-++-++++—+++-++-+++–++—++++++-+—-+-++-+++–+-++-++-++–+—-+–+-++++-++–+–++-+–++–+-++–++++++–+-+-+-+-++–++–+-+——-++-++++-+–++-++++–+—–++–+++++++-++–+++-+-++—+–+——-++—++-++-+-+–+–+–+—++–+++++++—++—–+++-++—–+++++–+–++-++–++++—+-+–++–++-+-++-+—++—-+-++-+–+++–+–+-++-+–+–+++-++++++-+++–++–+–+–++++++–+—+—–++-+++—+–++–+–++++++——++—+++—++—-++++—-+++-+-+++-+++–+-+-+++—+-+—-+—+–+-+—+-+-++—-+—++-++-+++—+-++-++—+——++-++–+–+-++—-++–+-+–+-++–+++-++-+-+—–+-+—+-+-+-+++++++++++-+—+—-+–+—-++++-+-+—+-++-+++++++-+++-++-++++-++—++++++++-++-+-++–+–+–+–+++–+—-++++++–++-+-++—–+++–+-+++-+-+—+-
January 17, 2010 at 7:41 am
That’s pretty amazing. Please could you post it with spaces in between the symbols, as WordPress messes up concatenated hyphens.
January 17, 2010 at 7:44 am
It looks as though your sequence has six pluses in a row (near the end). Is this a formatting error?
January 17, 2010 at 7:45 am
Oh that’s not the best, it seems to have mushed up double – signs. Try this:
+ + – – – + + + – – – + – + – – – + – – – – + + – – – + – – + – – + + + + – – + + + + – + – – – – – – – + – – + + + + – – + – – + + + – – + – + – – + – + – – – – – + + + + – – – + – + + + – + + + + + – – + – + – + – + – + + – – + + – + + + + – + + – – – + – + + + + – + – + + + + – + – – – – – + + + + + – – + – + + – + + – + – – – + – – + + + + + – + – + + – – + + + + – + + – + + + + – + – + – + – + + – + + + – + – – + – – + – – – + + + + + – + – – + – – – + + – + – – – + + + – + – + + + – – – + – – – + + + + + – – – – + + + – – + – – + – + – + + + – – + – – + + + – + + – – – + + + – + – – + – + – – + + – + – – – + + + + – – – + – – + + + – + + – – – – + + – – – – – + + + – + + + – – – – – – + + – – + + + – + – – + – + – – + – – + + – – – + + + + + + – + + + + + – + + + + – + – – – – + + + + – + – + – – – + + – – + – + + – + + – + + + + + – – – – + – + – + + + – + – – + + – – – + + – + + – – – – + – – + + + – + – – – + – – + – – – – – + – – – + + + – – – + + + + – – – – + + + – + – + + – + – – – – + – + – + + – – – + – – – – + + – + + + – + – – – – + + + + + + – + + + – + – + – – – + – – – – – – – – + + – – – + – – – + – – + + – – + + – + – – + – – + – – + – – + – + – – + + – – – + – + – + – + – + + – + + + – – + – – – + – + + – – – + – – – – + – + + – + + + + – – – + + – – + – + – – – + – + – + + + – – – + + – – + – + – – + + – + + – – + + – + – + + + + – + + + – + – – + – – + – + – + + – – – + + – – – – – + + – – – + + + – + – + – + + + – – – + + + – + + + + + + + – + + – + + – + – + + + – – – + – – – – – – – + + + – + – – – + + + – + + – + + + + – – + – – + + – – + + – – + + + + – + – + – + + + – + – – + + + + – + – – – – – – + – – + + + – + – + + – – + – – + – + + + – + + – – – + – + – – – – – – + – + – – + + – + + + + – – – – – – – – – + – – – + + – + + – – + – + – + + + + + + – – – + – + – + + – + + – – – – – – + + – – – + + – – – – – – – – – – + – + – + + + + + – – – – – + – + – + + – – + – + + – + – + + – + – – + – + – – – – + – + + + – – + + + + – + – + – – + + + + + + – + + + + + – + + + – – + – + + – – – – – + + – + – + + + + – + + + + – + + + – – – – + + – + – + – + + – – + + – + + – – – – + + – – + + + – + – – – – + – – – – – – + – + + + + – + – – – – – + + + – – + – – – – + – + + + + – – + + – + + + + – + + + + – + – – – + – + + – – – + – + – + + – – – – + + + – – + + – – – + – + + + + + + – – – + – + – – + – + + – + – – – – + + + + – – – + + – + + + – – – + + – + – – + + + + – + – – – + – + – + + – + – + – + + + – + – + + – – + + – + + + – + – – – + + – + + – + – + + + – – + – + – – + – – + + + + – + – + + + – + – + + + – + + – – + + – – + + – + – + – – – – – + – + + – – – – – – + + + + + – – – + – + – + + – – – + + + – + + – + + – + + – – + + – + + – + – + – – – – – – – + + + + + – – + – – – + – – + – + – – – + – – + + + – + + + – – + – + + – + + – – + + – – + – – – + + + + + + + + – + + + – – – – + + + + + – + + + – – + + + + + – – – + – – – – + – – – + + – – – – – + + + + + – + + – – + + – – – – + – + + – + + – – + + – + + + + + + – – + – – + + + – – – + – + + – – + – + – + + – + + – + + – + – + + + + – + – – – – + + – – + – – – – + – – – + + – + – – – – – + – + – – – – + – + + – – + – + + – + – + – + – + – + – + + – – – + + + – + – – – + – + – + – + + – – – + – – + – + + – + + – + – – + – – – – + – – – + – – + + + + + + + + + + + – + + – + – – – + – + + – – – + + – + + – + – – + + + – + + + + + – + – – + – – – – + – + + + – – – + + + + + + – – – + – – + + + – – + – + + – + + – – + + – – + – + – – – + – + – + – + + + – – – + + – + + + + + – + – + + + + + – + – – + + – + + – + – + – – + – – – – – + + + + + + + + + – + – – + + + – + – + – – – – + + + + – – – + + – – – + – – + + – + – – + – + + – + – + + + + + – + – – + – – + – – + + + – – – + + + – – + – + – – – + + – – + + + – + – + + – + – – + – + + – – – – – + – + – + + – – – + + + – – – – – – – + – – – + + + – – – – + – – – – – – + – + + + + – – – – + + – – – – – + – – + – – + – + – + + + – + – – + + – – + + – – – + + – – + – + + – – + + + – + + – – + + + + + – – – – – + – – – + – + + – – + – – – – – – + – + + – + – – – – + + + + – + + – – – – – + + – – + – + – + – – – – – + – – + – – – + – – – – – – + – – + – + – – – + + + – + – + – – + + + – + + + + – + – + + – – – + + – – – + – – – – + + + + – + + – + – + – – + + + + + + – + + – – – – + + + + – – – – – – + + + + + + – – + – + + – + + – + + + – + – + – + + + – + – + – – – – + – – + – – + + – + + + – + + + – – + – + – – + + + + – – + + + + + – + + – + + – – – – + – – – + + + + – – + – – + + – + – – – + – – + – – + + + – – – + + – – – + – + – + + – + + + + – – – + + + – + + – + + + – – + + – – – + + + + + + – + – – – – + – + + – + + + – – + – + + – + + – + + – – + – – – – + – – + – + + + + – + + – – + – – + + – + – – + + – – + – + + – – + + + + + + – – + – + – + – + – + + – – + + – – + – + – – – – – – – + + – + + + + – + – – + + – + + + + – – + – – – – – + + – – + + + + + + + – + + – – + + + – + – + + – – – + – – + – – – – – – – + + – – – + + – + + – + – + – – + – – + – – + – – – + + – – + + + + + + + – – – + + – – – – – + + + – + + – – – – – + + + + + – – + – – + + – + + – – + + + + – – – + – + – – + + – – + + – + – + + – + – – – + + – – – – + – + + – + – – + + + – – + – – + – + + – + – – + – – + + + – + + + + + + – + + + – – + + – – + – – + – – + + + + + + – – + – – – + – – – – – + + – + + + – – – + – – + + – – + – – + + + + + + – – – – – – + + – – – + + + – – – + + – – – – + + + + – – – – + + + – + – + + + – + + + – – + – + – + + + – – – + – + – – – – + – – – + – – + – + – – – + – + – + + – – – – + – – – + + – + + – + + + – – – + – + + – + + – – – + – – – – – – + + – + + – – + – – + – + + – – – – + + – – + – + – – + – + + – – + + + – + + – + – + – – – – – + – + – – – + – + – + – + + + + + + + + + + + – + – – – + – – – – + – – + – – – – + + + + – + – + – – – + – + + – + + + + + + + – + + + – + + – + + + + – + + – – – + + + + + + + + – + + – + – + + – – + – – + – – + – – + + + – – + – – – – + + + + + + – – + + – + – + + – – – – – + + + – – + – + + + – + – + – – – + –
January 17, 2010 at 8:04 am
I calculate a discrepancy of 51, from the 3 sequence (and note that the sum of the first 17 terms is -3).
January 17, 2010 at 8:11 am
Quite right, thank you. Disregard! (I left out many partial sums.)
January 17, 2010 at 8:12 am |
The 1124 sequence has values
+ – + – – + – – + – +
on the subsequence 1, 2, 4, 8, …, 1024.
A relevant way to compress this +/- sequence is
Is this what was meant by “a golden ratio related sequence” here?
January 17, 2010 at 9:48 am
Sorry — I was lazy about writing it down. What I did was to begin by taking the integer parts of multiples of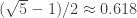 . That gave me the sequence 0 1 1 2 3 3 4 4 5 6 6 7 8 8 9 9 … I then took the difference sequence of this sequence, getting 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 … I then observed that if you forget the first four values you get 0 1 0 1 1 0 1 1 0 1 0 … which matches the sequence at powers of 2 if you associate 0 with + and 1 with -. Thus, my criterion would be like yours except that it would ask for the fractional part of
. That gave me the sequence 0 1 1 2 3 3 4 4 5 6 6 7 8 8 9 9 … I then took the difference sequence of this sequence, getting 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 … I then observed that if you forget the first four values you get 0 1 0 1 1 0 1 1 0 1 0 … which matches the sequence at powers of 2 if you associate 0 with + and 1 with -. Thus, my criterion would be like yours except that it would ask for the fractional part of 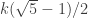 to lie in a certain interval that would be a shift of yours.
to lie in a certain interval that would be a shift of yours.
Actually, looking again at your definition, I notice that the fractional parts of and
and  are the same, so presumably what we did is essentially identical.
are the same, so presumably what we did is essentially identical.
January 19, 2010 at 8:49 am
I had an off-by-one error. It should be:
January 17, 2010 at 8:20 am |
This doesn’t look right. The 2-subsequence quickly gets to 3 (+ – + + – + +) and there is a sequence of 7 “-” near the beginning.
January 17, 2010 at 9:30 am |
“A small difference between Polymath5 and Polymath1 is that we are (so far at least) not numbering the comments, and instead are making full use of the threading, which I am still allowing only up to depth 1.”
Is it possible to have the comments numbered (chronologically) while keeping the depth 1 threading? This can be useful for a) refering to an old comment, b) seeing “what is new”
January 17, 2010 at 9:47 am |
[…] discussion threads, polymath5 devoted to Erdos’s discrepency problem is on its way on Gowers’s blog. While a theoretical post with several possible attacks on the problem is planned, there is […]
January 17, 2010 at 10:28 am |
Here’s another experiment that could be worth doing. If (and I’m still not wholly sure about this) the sequence at powers of 2 really is given according to where multiples of the golden ratio land mod 1 (and I think there should be a nice formulation of this according to the last digit of an integer with respect to the Fibonacci basis — I’ll check that in a moment), then after the initial – + – – + – – + – + it will have to continue with a -. Also I don’t think you ever get – + – + so in fact it will have to continue with – – + -.
So how about taking the 1124 sequence, assuming the powers-of-2 sequence begins – + – – + – – + – + – – + – and deducing everything one can about the values beyond 1124? (This might work better if one backtracked a little from the 1124 sequence, in case some of the choices up to there are “wrong”.) That would immediately give the values at all even numbers up to 2248, multiples of 4 up to 4496, and so on up to multiples of 16 up to around 18000.
I was hoping one could play a similar game with powers of 3, but one can’t do it in a simple way. The reason is that the sequence starts + + + – – – and that does not tell us whether the next term will be + or -. However, one could perhaps split into a small number of cases. What we do know is that the sequence of minuses will continue for a while and then switch back, and that the length of the next sequence of pluses will be at least 2. (I’m assuming that we are taking multiples of a real number and taking + or – according to whether they do or do not lie in some interval mod 1.)
Thus, each small number like 3,5 or 7 will lead to a rather small number of cases to look at, so the product should be smallish too. And for each case, one can fill in quite a high proportion of values and then search by the usual methods for sequences that take those values at those places. (It could well be that those values would instantly force quite a lot of other values.)
There seems to me to be at least some chance that by cutting back the existing 1124 sequence to say half its length and then extending it again by first assuming that the existing patterns persist and then filling in the gaps would lead to a longer sequence. But there’s another argument that says that it won’t work: the patterns are so good already that assuming they persist won’t really change anything. But it could change something as it would place a higher priority on choosing the values at even numbers and multiples of 3, say, so it might avoid a situation where you do something like choosing a value at some prime near 600, sacrificing the pattern to fit in round that prime, and only paying the penalty much later at 1125. In any case, I think one will only really know whether it works by trying it.
January 17, 2010 at 10:35 am |
Recall that to write a number in Fibonacci base, you remove the largest Fibonacci number from it and repeat that process. Here are the first few numbers in Fibonacci base (but I’ll write them as sums of non-consecutive Fibonacci numbers).
1, 2, 3, 3+1, 5, 5+1, 5+2, 8, 8+1, 8+2, 8+3, 8+3+1, 13, 13+1, 13+2, 13+3, 13+3+1, 13+5, 13+5+1, 13+5+2, 21
Now let’s write a new sequence that’s 1 if the Fibonacci sum ends in a 1 and 0 otherwise. That gives us 1 0 0 1 0 1 0 0 1 0 0 1 0 1 0 0 1 0 1 0 0 … Again, a small segment of that (0 1 0 0 1 0 0 1 0 1) matches the powers-of-2 sequence.
January 17, 2010 at 11:18 am |
Response to the last comment in the previous thread: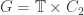 .
.
If I understand the idea correctly, the hypothesis is that this is a quasi-multiplicative sequence, with
January 17, 2010 at 11:28 am
I wondered about that myself, and am in two minds about whether it works. What would be the subset of that you’re supposed to land in? It needs to have the property that typically when you multiply over and over again by a number, there is either a bias towards – or a bias towards +, but in general there shouldn’t be a bias. I haven’t quite managed to fit this into the framework of quasimultiplicativity to my satisfaction.
that you’re supposed to land in? It needs to have the property that typically when you multiply over and over again by a number, there is either a bias towards – or a bias towards +, but in general there shouldn’t be a bias. I haven’t quite managed to fit this into the framework of quasimultiplicativity to my satisfaction.
January 17, 2010 at 11:53 am
I think the type of function you defined in this comment is on that form. A prime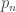 is send to
is send to 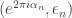 .
.
“It needs to have the property that typically when you multiply over and over again by a number, there is either a bias towards – or a bias towards +, but in general there shouldn’t be a bias.”
This function will have this pattern when you multiply by a even number, but not when you multiply by odd numbers. Why do you think there should be a bias for odd numbers?
January 17, 2010 at 12:19 pm
That’s a good point — I have absolutely no reason to think that.
January 17, 2010 at 12:30 pm
“I haven’t quite managed to fit this into the framework of quasimultiplicativity to my satisfaction.”
Admittedly the “correct” definition for this type of sequence hasn’t been totally formalized, but the definition you proposed in the last post really does seem to be quasimultiplicative (although only in the “weak” sense where we allow any function from our underlying group to {0,1}).
“It needs to have the property that typically when you multiply over and over again by a number, there is either a bias towards – or a bias towards +, but in general there shouldn’t be a bias.”
Since we’re multiplying by C_2, the overall bias is cancelled out — the “local” bias at p comes from the fact that we’re working entirely in a projection group. 🙂
January 17, 2010 at 12:32 pm
I guess I should say “the ‘local’ bias at 2”, since of course isn’t a subgroup.
isn’t a subgroup.
January 17, 2010 at 2:23 pm |
A bit more food for thought. I wanted to try to get a handle on the seemingly multiplicative function that determines the signs that are appearing in the 1124 sequence. I’ve written it out up to 42 (taking Alec’s data and putting in the values at even numbers too. (The value at 2n is the same as it is at n.) The resulting completely multiplicative sequence has discrepancy 2, which is nice. Also, writing it out in blocks of 7, we get this:
+ + – + – – –
+ + – + – – –
+ + – + – – +
+ + – + – – –
+ + – + – – +
+ + – + – + +
In other words, it seems to be trying to be periodic with period 7, which may perhaps explain why 7 exhibits strange behaviour. Indeed, it could be something like one of these Walters-type sequences but base 7 rather than base 3.
January 17, 2010 at 3:19 pm
Looking at that again, there is only one truly anomalous value. The last number in each row comes at a multiple of 7, so we do not expect it to repeat. Rather, we expect the values at multiples of 7 to copy the basic pattern + + – + – -, and indeed they do (but with the sign reversed, just as Kevin was doing base 3). The one irritation is at 41. I can’t understand why we should get a + there, but I’ve checked and we definitely do seem to.
So the way I see it at the moment, 7 used to seem anomalous, but can now be understood as the basis with respect to which a completely multiplicative function is defined (by taking a completely multiplicative function on the non-zero residues mod 7 and then defining f(n) to be the value of
on the non-zero residues mod 7 and then defining f(n) to be the value of  on the last non-zero digit base 7 if that is an odd number of places from the end and minus that if it’s an even number of places from the end). These functions are a slight generalization (because of the alternating signs) of what Borwein, Choi and Coons call character-like functions in their paper. However, 41 still seems utterly anomalous. Does it behave strangely for the other 1124-length sequences?
on the last non-zero digit base 7 if that is an odd number of places from the end and minus that if it’s an even number of places from the end). These functions are a slight generalization (because of the alternating signs) of what Borwein, Choi and Coons call character-like functions in their paper. However, 41 still seems utterly anomalous. Does it behave strangely for the other 1124-length sequences?
January 17, 2010 at 3:30 pm
In partial answer to that question I’ve had a look at the second 1124 sequence and things don’t seem to be much better. This time 37 behaves irritatingly: the values at 37, 74, 148, 296, 592 are + – – – +.
January 17, 2010 at 3:51 pm
Thinking about it a bit further, I’m less worried about that strange value at 41. It probably just means that we have a completely multiplicative function that happens to coincide with a character-like function all the way up to 40 and then deviates from it. Out of interest, I’m going to work out some more values and see where it gets us.
January 17, 2010 at 8:28 pm
So, up to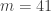 , we have
, we have 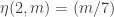 (Legendre symbol) when
(Legendre symbol) when 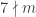 .
.
January 17, 2010 at 9:49 pm
As for the multiples of 7, the sequence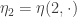 seems to be emulating
seems to be emulating
for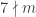 . Of course it does get hard to tell once you get up to numbers like 343.
. Of course it does get hard to tell once you get up to numbers like 343.
January 17, 2010 at 10:20 pm
That’s what I meant by saying it was character-like to base 7.
January 18, 2010 at 8:17 am
Right — I got excited because I thought this would let us find very long sequences by just playing with the shifts . I’m not so sure now, because of the imperfection of a couple of the shifted sequences, but haven’t quite ruled it out.
. I’m not so sure now, because of the imperfection of a couple of the shifted sequences, but haven’t quite ruled it out.
January 17, 2010 at 4:45 pm |
I’ve worked out a few more values of the sign sequence. Here they are, still in groups of 7. Some sequences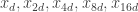 do things like + – + – + or + – + + +. I give both these sequences a minus sign (since they have a preponderance of pluses) but I’ll mark them with an asterisk and a question mark, respectively, since I am much less confident of their values. Also, the later values, where I have only
do things like + – + – + or + – + + +. I give both these sequences a minus sign (since they have a preponderance of pluses) but I’ll mark them with an asterisk and a question mark, respectively, since I am much less confident of their values. Also, the later values, where I have only  to go on, should be taken with a pinch of salt. I’ve put an X if I really have no evidence either way.
to go on, should be taken with a pinch of salt. I’ve put an X if I really have no evidence either way.
1+ 2+ 3- 4+ 5- 6- 7-
8+ 9+ 10- 11+ 12- 13- 14-
15+ 16+ 17- 18+ 19- 20- 21+
22+ 23+ 24- 25+ 26- 27- 28-
29+ 30+ 31- 32+ 33- 34- 35+
36+ 37+ 38- 39+ 40- 41+ 42+
43- 44+ 45- 46+ 47-? 48- 49-*
50+ 51+ 52- 53+? 54- 55- 56-
57+ 58+ 59- 60+ 61-* 62- 63-
64+ 65+ 66- 67- 68- 69X 70+
71X 72+ 73X 74+ 75- 76- 77-
78+ 79+ 80- 81+ 82+ 83- 84+
There are a few anomalous values, but the only failure of multiplicativity is the fact that the value at 49 is -1 when it should be +1. Since this was one of the dubious assignments, it is not necessarily all that worrying. (In fact, it isn’t all that worrying anyway, since for character-like functions one doesn’t really use multiplicativity along powers of when calculating the HAP sums.)
when calculating the HAP sums.)
The partial sums of this sequence are good up to about 60 (by which point the partial sum is 0). If we “correct” the value at 61 by making it + and give 69 a – (justified by multiplicativity), then we hit -3 at 69.
So a brief summary of the properties of this sequence are that it starts out character-like (in a slightly generalized sense) to base 7, is completely multiplicative except at 49, and has pretty good but not optimal discrepancy.
January 17, 2010 at 7:14 pm
Just edited the table on the wiki, making somewhat more informed choices where there are several possibilities, generally preferring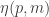 and
and  to as functions of
to as functions of  to be multiplicative and monotonic respectively. Only the cases
to be multiplicative and monotonic respectively. Only the cases  and
and  had no exact shifts available; and I think one cannot ensure
had no exact shifts available; and I think one cannot ensure 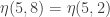 without a sharp lack of monoticity in
without a sharp lack of monoticity in  . But in general it seems quite easy to meet the requirements of exact multiplicativity and near-monoticity.
. But in general it seems quite easy to meet the requirements of exact multiplicativity and near-monoticity.
January 17, 2010 at 6:50 pm |
I have a tentative explanation for some of the phenomena that can be observed in Alec’s diagram where he looked at graphs of partial sums of sequences of the form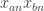 , where
, where  and
and  are fixed integers. Note that if the HAPs
are fixed integers. Note that if the HAPs 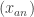 and
and  are equal, then the gradient will be 1, and that if a sequence is completely multiplicative then all functions will either be
are equal, then the gradient will be 1, and that if a sequence is completely multiplicative then all functions will either be 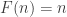 or
or  , so have gradient 1 or -1. What is actually observed is more complicated than we expected: the gradients seem to have a tendency to take one value for a while and then to switch to some other value. However, the functions seem to become smoother later on.
, so have gradient 1 or -1. What is actually observed is more complicated than we expected: the gradients seem to have a tendency to take one value for a while and then to switch to some other value. However, the functions seem to become smoother later on.
To see why this might be the case, let us consider the sequences and
and 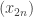 , with the data about the sequences
, with the data about the sequences 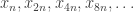 in mind. Whether or not
in mind. Whether or not 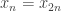 depends on the shift associated with
depends on the shift associated with  . Most of the time the shift will be such that you have two different signs, but from time to time you get a pair where the signs are the same. Also, the amount by which you shift grows (as a general tendency) at a logarithmic rate, so the general tendency is for
. Most of the time the shift will be such that you have two different signs, but from time to time you get a pair where the signs are the same. Also, the amount by which you shift grows (as a general tendency) at a logarithmic rate, so the general tendency is for  to be roughly constant for longer and longer stretches (roughly doubling each time) and to be negative most of the time.
to be roughly constant for longer and longer stretches (roughly doubling each time) and to be negative most of the time.
So it looks to me as though the curves Alec is sketching should have a kind of self-similarity property that is not all that apparent simply because we do not have enough data.
All this makes me think that it would be very nice to have an extremely long sequence, even if we had to allow some of the HAP-sums to hit 3 or -3 from time to time.
January 17, 2010 at 6:55 pm |
I should mention that we haven’t taken the “Matryoshka” sequences to their extreme. Let me recap the situation, and then say why I think there’s room for improvement. Fix a positive integer m and a function f from {1,2,…,m-1} into an additive group G (maybe +/-1, or C). Extend f to the natural numbers by setting f(n)=f(n/m) if n is a multiple of m, and f(n)=f(n-m) if n>m but n is not a multiple m.
We have Walters’ example with m=3, and seed 1,-1 (that is, set f(1)=1,f(2)=-1), which gets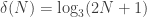 infinitely often. We can sharpen this with m=9 and seed 1, -1, -1, 1, -1, 1, 1, -1, which gets
infinitely often. We can sharpen this with m=9 and seed 1, -1, -1, 1, -1, 1, 1, -1, which gets  infinitely often.
infinitely often.
In general if H is a subgroup of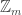 and
and 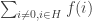 is not zero, then the discrepancy grows linearly. It seems clear to me (not that I’ve written out a proof) that if f sums to zero on every subgroup of
is not zero, then the discrepancy grows linearly. It seems clear to me (not that I’ve written out a proof) that if f sums to zero on every subgroup of 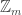 , then the growth of
, then the growth of  is like
is like 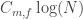 . There are only finitely many seeds (if we are talking about functions into +/- 1), so we can optimize: let
. There are only finitely many seeds (if we are talking about functions into +/- 1), so we can optimize: let 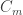 be the smallest of all
be the smallest of all 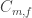 .
.
The above examples give and
and 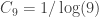 . There were some arguments earlier that
. There were some arguments earlier that 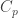 (with p prime) bottoms out, and for at least the most obvious way f of seeding,
(with p prime) bottoms out, and for at least the most obvious way f of seeding, 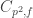 also bottoms out. But it’s also clear that
also bottoms out. But it’s also clear that  . It would seem bizarre to me if turns out that
. It would seem bizarre to me if turns out that 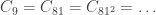 , but that there is no modulus in between that does better.
, but that there is no modulus in between that does better.
January 17, 2010 at 7:31 pm
Ah, I hadn’t fully appreciated the point that’s implicit in what you are saying, namely that working to a composite modulus could be helpful because it allows you to ignore certain arithmetic progressions (ones that aren’t HAPs mod m, so to speak). For example, the following sequence is quite a nice one mod 15 (I’m giving the values taken at 1,2,…,14): +1 -1 -1 +1 -1 +1 +1 -1 +1 +1 -1 -1 +1 -1. I’ve just checked and it adds up to zero on every subgroup and has partial sums that never go above 2 in modulus. That should lead straightforwardly to an example that gets you a discrepancy of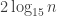 . Perhaps less straightforwardly (via some kind of alternating-signs trick) one could improve that, though it’s not clear because the partial sums hit both 2 and -2. (Borwein, Choi and Coons discuss primes and characters whose sums always remain positive, but I think that doesn’t help us here.)
. Perhaps less straightforwardly (via some kind of alternating-signs trick) one could improve that, though it’s not clear because the partial sums hit both 2 and -2. (Borwein, Choi and Coons discuss primes and characters whose sums always remain positive, but I think that doesn’t help us here.)
I found that example by choosing good looking values at multiples of 3 and 5, after which the extension was more or less forced. Now that I look at it again, I see that I’ve taken the Dirichlet character mod 3 and then instead of filling in the multiples of 3 in the same way I’ve used a Dirichlet character mod 5 instead. So now I’m not sure it’s good for anything, but I think I still agree that there may be room to improve this kind of example.
January 18, 2010 at 5:42 pm
The sequence you gave has discrepancy 2k+1 for the first time at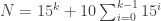 , which means
, which means 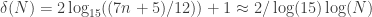 infinitely often. It has discrepancy 2k for the first time at
infinitely often. It has discrepancy 2k for the first time at  , which means
, which means 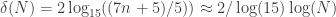 i.o..
i.o..
So, I’m confirming your arithmetic 🙂 . Note: , so this isn’t a new record.
, so this isn’t a new record.
January 17, 2010 at 7:29 pm |
I found that the polymath5 wiki site was very helpful in catching up here :-). I had a thought about generalising the problem in order to find easier cases to attack that did not require any number theory.
Let us say that a sequence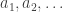 in an (infinite) abelian group
in an (infinite) abelian group 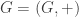 has the bounded discrepancy property if there exists a function
has the bounded discrepancy property if there exists a function  such that the partial sums
such that the partial sums 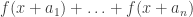 are uniformly bounded for all
are uniformly bounded for all  and
and  . The Erdos problem is equivalent to asking whether the set
. The Erdos problem is equivalent to asking whether the set 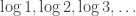 in the reals (or in the log-rationals) has the bounded discrepancy property.
in the reals (or in the log-rationals) has the bounded discrepancy property.
The point of doing this is that one can consider other model problems in which the number theory structure is not present. For instance, consider the “free” problem when there are no additive relations between the . If the free sequence did not have the bounded discrepancy sequence, then no other sequence could have it either, by pullback.
. If the free sequence did not have the bounded discrepancy sequence, then no other sequence could have it either, by pullback.
Unfortunately, the free sequence does have the bounded discrepancy property: without loss of generality (by foliation into cosets) one can assume G is generated by the , and then take a homomorphism
, and then take a homomorphism  (the analogue of a completely multiplicative function) such that the partial sums
(the analogue of a completely multiplicative function) such that the partial sums  are bounded. It may be that homomorphisms are “characteristic” for this problem, in the sense that any function f with the
are bounded. It may be that homomorphisms are “characteristic” for this problem, in the sense that any function f with the 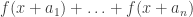 bounded must somehow correlate with a homomorphism, but this seems rather optimistic.
bounded must somehow correlate with a homomorphism, but this seems rather optimistic.
But perhaps one can start looking at other sequences. At present I can’t think of _any_ sequence without the bounded discrepancy property, except for trivial examples in which one of the is repeated infinitely often. (Actually, I take that back: since
is repeated infinitely often. (Actually, I take that back: since  always needs to be bounded, one can presumably force a contradiction if there are enough “bounded” sequences of the form
always needs to be bounded, one can presumably force a contradiction if there are enough “bounded” sequences of the form  .) But perhaps it may be worthwhile to figure out some necessary or sufficient conditions for the bounded discrepancy property.
.) But perhaps it may be worthwhile to figure out some necessary or sufficient conditions for the bounded discrepancy property.
January 17, 2010 at 7:46 pm
Oddly enough, a couple of weeks ago (when I was in Egypt) I came up with a somewhat similar (but definitely not identical) idea from a completely different angle. Write for the HAP
for the HAP 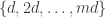 . Let’s call a set
. Let’s call a set  of positive integers large if for every
of positive integers large if for every  and every
and every  function
function  on
on  there exist
there exist  and
and  such that the sum
such that the sum  has modulus at least
has modulus at least  . Clearly, if
. Clearly, if  is a large set and you partition it into sets
is a large set and you partition it into sets 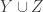 , then at least one of
, then at least one of  and
and  is large (since otherwise just choose bounded-discrepancy functions on
is large (since otherwise just choose bounded-discrepancy functions on  and
and  and put them together to form one on
and put them together to form one on  ). Note also that if you believe the conjecture (that bounded discrepancy is impossible) then you have to believe that all HAPs are large. This made me think that we had some kind of Ramsey property until I noticed the awkward fact that it is probably the case that a superset of a large set does not have to be large. The reason is that I’m fairly sure that (again, subject to the truth of the conjecture) the set of integers that are 1 mod 3 is large, but the set of integers that are 1 or 2 mod 3 is trivially not large — just send n to 1 or -1 according to whether it is 1 or 2 mod 3. Nevertheless, I couldn’t help wondering whether IP* sets had to be large, and couldn’t instantly think of a counterexample. In fact, I couldn’t even think of an IP set that wasn’t large, but I think I was being fairly stupid there: it would be a bit of a miracle if they all were.
). Note also that if you believe the conjecture (that bounded discrepancy is impossible) then you have to believe that all HAPs are large. This made me think that we had some kind of Ramsey property until I noticed the awkward fact that it is probably the case that a superset of a large set does not have to be large. The reason is that I’m fairly sure that (again, subject to the truth of the conjecture) the set of integers that are 1 mod 3 is large, but the set of integers that are 1 or 2 mod 3 is trivially not large — just send n to 1 or -1 according to whether it is 1 or 2 mod 3. Nevertheless, I couldn’t help wondering whether IP* sets had to be large, and couldn’t instantly think of a counterexample. In fact, I couldn’t even think of an IP set that wasn’t large, but I think I was being fairly stupid there: it would be a bit of a miracle if they all were.
January 17, 2010 at 8:06 pm |
[…] By kristalcantwell There is a new thread for polymath5. There is also this post. There is a sequence of 1124 values of plus or minus one which has […]
January 17, 2010 at 10:05 pm |
The depth first search seems to be progressing – Alec has noted over 2,000,000,000 sequences of length 1124 on backtracking to 233. The other attempts to achieve long sequences of discrepancy 2 have not yet reached that far.
So the first sequence of length 1124 is special, because it is the first in the search ordering. The second reported sequence is ‘near’ the beginning.
Some observations: 1125 = 9 x 125 = 5 x 225.
In a strictly multiplicative sequence the value at 1125 would therefore be determined by the value at 5 (225 being a square number).
225 is the next significant value that a backtracking algorithm will reach, which might make a difference to the ‘blockage’ at 1125 – but it may be necessary to go back to 5 to make progress.
It might be worth exploring why the value 675 (=27 x 25) does not cause similar problems.
January 17, 2010 at 11:08 pm
Mark, I wrote down some of the places where the “quasi-multiplicative” structure of the 1124 sequences started to fail, but I can’t seem to find the appropriate place in my notes.
I did write a comment on it earlier, though, and another significant value for the first sequence (I think it occurs in the second too) is 32*33. Which, I don’t actually know that I can connect it to the 675 vs 1125 thing, but I thought I’d put the data point out there.
January 18, 2010 at 2:32 am
What is the search order (of which the 1124 sequence is first)?
January 18, 2010 at 8:38 am
I believe that the order is depth first tree search looking at f(n)=1 before f(n)=-1
So it would begin
1
1, 1
1, 1, 1 x
1, 1, -1
1, 1, -1, 1
January 18, 2010 at 9:21 am
For the sequences I have given there is not really any easily defined search order such as the natural DFS order. The program uses non-chronological backtracking and that means that the searhc order is dynamically defined by the problem itself and not something that can be easily described.
January 18, 2010 at 12:36 am |
Fascinating pattern time again.
I tried repeating the shifts-and-signs exercise on the sequence of length 1112 that Alec found, since the result of the exercise was clearly destined to be different. That is because he created the sequence by initially imposing constraints such as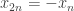 , so for example we know that every sequence
, so for example we know that every sequence  will alternate + and – (with perhaps a few errors later on).
will alternate + and – (with perhaps a few errors later on).
It therefore made sense to look at subsequences of the form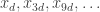 . These, it turns out, have period 3, so they are either things like – + + – + + – + + or things like – – + – – + – – +, though not as long. Because of this, it is not quite so easy to tell what the shifts are, but here is a table of the sequences. Eventually I had the bright idea of tabulating the shifts mod 3, which, as we shall see, led to something. It also means there’s not much point in giving the sequences, as everything except their length follows from the shift and the sign. I count the sequence + – – + – – … as having positive sign and zero shift (since it’s the sequence that you get when
. These, it turns out, have period 3, so they are either things like – + + – + + – + + or things like – – + – – + – – +, though not as long. Because of this, it is not quite so easy to tell what the shifts are, but here is a table of the sequences. Eventually I had the bright idea of tabulating the shifts mod 3, which, as we shall see, led to something. It also means there’s not much point in giving the sequences, as everything except their length follows from the shift and the sign. I count the sequence + – – + – – … as having positive sign and zero shift (since it’s the sequence that you get when 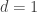 ). I should mention that all the sequences were perfect: no anomalous values, at least as far as I went.
). I should mention that all the sequences were perfect: no anomalous values, at least as far as I went.
So I’m no longer tabulating the data. I’ll just present a bunch of ordered triples (d, shift(d), sign(d)).
(1,0,+), (2,0,-), (3,2,+), (4,0,+), (5,0,-), (6,2,-), (7,1,-), (8,0,-), (9,1,+), (10,0,+), (11,0,-), (12,2,+), (13,0,+), (14,1,+), (15,2,-), (16,0,+), (17,0,-), (18,1,-), (19,0,+), (20,0,-), (21,0,-), (22,0,+), (23,0,-), (24,2,-), (25,0,+), (26,0,-), (27,0,+).
The interesting (but by now not too surprising as we are expecting structure) thing is that the map from d to shift(d) is a homomorphism in the following sense: shift(ab)=shift(a)+shift(b). This compares in a rather fascinating way with the shifts in the 1124 case. There, it seems that we were dealing with an irrational rotation and the shifts were of roughly logarithmic size. So it’s the same homomorphism, since , but it’s more “real” than “mod
, but it’s more “real” than “mod  ” in flavour. In other words, this 1112 construction really is fundamentally different from the 1124 one.
” in flavour. In other words, this 1112 construction really is fundamentally different from the 1124 one.
It also seems easier to handle. If we do a few more calculations like the ones I’ve just done, might we get a formula that agrees with the sequence almost everywhere? It seems like a sensible first target. After that, we can stare a bit more at the 1124 example.
It’s quite interesting that the only primes that do not map to zero in the shift homomorphism are 3 and 7.
As I write, I realize that a lot more comes out of these two homomorphisms. For example, it agrees perfectly with all the subsequence data: there are six possibilities for the pair (shift(d),sign(d)) and that gives you exactly the partition that is observed, except that you need to amalgamate the classes 809 and 873 and the classes 3286 and 3222 (indicating that later on some anomalies will arise — perhaps these will be interesting).
Here is a formula of a type that should fit the sequence very well indeed. Let take the value 0 at 0 and 1 at 1 and 2. Write
take the value 0 at 0 and 1 at 1 and 2. Write  for shift(d) and let sign(d) be equal to
for shift(d) and let sign(d) be equal to  . Then define
. Then define  to be
to be 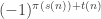 . Does anyone have the time/inclination/ability to program a computer to work out, as far as one can, the functions s and t and then choose further values to make the fit as good as possible?
. Does anyone have the time/inclination/ability to program a computer to work out, as far as one can, the functions s and t and then choose further values to make the fit as good as possible?
January 18, 2010 at 8:10 am
Fascinating again, particularly the fact that the shift function is a homomorphism — as, now you mention it, it is in the 1124 case but without reduction modulo .
.
I’m certainly keen to write such a program, and will try to find time to do so today.
January 18, 2010 at 9:59 am
Actually, you give my slightly more credit than is due here, because what I was saying about the 1124 case was that is a homomorphism, so since our shifts appeared to grow logarithmically we could say that the amount of the shift was at least approximately a homomorphism. What I hadn’t spotted until reading your message is that those shifts are an exact homomorphism for all the values that appear on your table.
is a homomorphism, so since our shifts appeared to grow logarithmically we could say that the amount of the shift was at least approximately a homomorphism. What I hadn’t spotted until reading your message is that those shifts are an exact homomorphism for all the values that appear on your table.
I haven’t checked, but I’m fairly sure it’s true, and easy to prove, that if for every the sequences
the sequences  are all shifts of each other, then the shifts must be homomorphisms. I’m rather busy today, but if nobody’s provided a proof by this evening then I’ll try to do that and put it on the wiki.
are all shifts of each other, then the shifts must be homomorphisms. I’m rather busy today, but if nobody’s provided a proof by this evening then I’ll try to do that and put it on the wiki.
A question that interests me now is whether we will be able to explain all the anomalies in the 1112 and 1124 sequences (perhaps as structure breaking up as it turns into more sophisticated structure) or whether those sequences are best described as starting with a highly structured object as a kind of template and making little unstructured adjustments to them towards the end in a desperate bid to keep the discrepancy below 2.
January 18, 2010 at 11:04 am
I won’t have much time to look at this till this evening, but can we summarize some of these observations by saying that functions of the form
where is a completely multiplicative
is a completely multiplicative 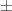 -valued function,
-valued function,  is a homomorphism from
is a homomorphism from  to
to  , and
, and  is some sequence with periodic or quasi-periodic properties, are good candidates for low discrepancy?
is some sequence with periodic or quasi-periodic properties, are good candidates for low discrepancy?
January 18, 2010 at 1:26 pm
Tiim, you wrote (24,2,+) above; I think this should be (24,2,-). I’m relieved about this, as it makes the signs multiplicative.
Thanks — I’ve now changed it.
January 18, 2010 at 6:35 pm
Addendum: as Tim has already surmised, this is very much analogous to a complex-valued function of the form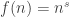 where
where  , the real part of
, the real part of  corresponding to
corresponding to  and the imaginary part to
and the imaginary part to  .
.
January 18, 2010 at 7:31 pm
That’s not quite what I surmised, or what I think actually. I think it has to be more like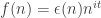 , where
, where 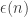 is a completely multiplicative function taking values in
is a completely multiplicative function taking values in 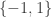 . But you may be seeing something I’m not seeing.
. But you may be seeing something I’m not seeing.
January 18, 2010 at 7:44 pm
Sorry, I was merely replacing (for the sake of the analogy) that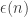 with a multiplicative
with a multiplicative  -valued function (
-valued function ( ). Actually my thought process went via multiplicative continuous functions
). Actually my thought process went via multiplicative continuous functions  , which are much more constrained.
, which are much more constrained.
January 18, 2010 at 7:28 am |
Hmm — it occurs to me that it might be useful to come at this from a dynamical perspective, since (for instance)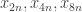 , etc., are the numbers that get mapped to
, etc., are the numbers that get mapped to  under iterated application of the transformation
under iterated application of the transformation  .
.
Loosely speaking, I think we want there to be only a few different sign sequences obtained from the orbit of an initial point; unfortunately I have no idea how to make this rigorous. To anyone who knows more about dynamical systems: Is it possible to reformulate the “exponential sequences property” in dynamical terms?
January 18, 2010 at 10:07 am
It was thoughts such as those that lay behind my recent mathoverflow question, which now has a very interesting set of answers. (To get from that to our set-up you have to “translate along geometric progressions”.) My concern there was with what we could do to a general sequence, but from the answers I think the answer is that we can’t get very far in the direction of the kind of structure we are looking for by applying the maps and passing to limits. However, if we add the additional extremely strong hypothesis of bounded discrepancy then we may be able to say a whole lot more — something to think about when the theoretical side of the project starts in earnest (which I plan to do when the next thread begins, so very soon).
and passing to limits. However, if we add the additional extremely strong hypothesis of bounded discrepancy then we may be able to say a whole lot more — something to think about when the theoretical side of the project starts in earnest (which I plan to do when the next thread begins, so very soon).
January 18, 2010 at 2:09 pm |
I’ve filled in the gaps between the existing n=6 and n=48 cases on the short sequence statistics page: http://michaelnielsen.org/polymath1/index.php?title=Short_sequences_statistics
A trivial observation that has probably been made before: the number of sequences of discrepancy 2 for $n=2^m$ is the twice that of $n= (2^m)-1$.
January 19, 2010 at 1:30 am
The numbers for lengths 81 and 82 seem to be out of order.
January 18, 2010 at 2:17 pm |
[…] 18.01.10: continuando no quinto. […]
January 18, 2010 at 7:50 pm |
This is a response to Alec’s comment about promising candidates for low discrepancy, which seems to me to deserve a depth-0 comment. As Alec points out, the patterns spotted so far in the long low-discrepancy sequences all seem to be saying that there is a completely multiplicative function , a homomorphism
, a homomorphism  that takes multiplication on the natural numbers (which we could extend to the positive rationals if we wanted a group homomorphism) to addition on
that takes multiplication on the natural numbers (which we could extend to the positive rationals if we wanted a group homomorphism) to addition on  , and a periodic-like
, and a periodic-like  -valued function
-valued function  defined on
defined on  , and then the long sequence behaves very much like
, and then the long sequence behaves very much like 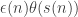 .
.
What does “periodic-like” mean? There are two interestingly different cases. The first case is a genuinely periodic function such as + – – + – – + – – …, and the second is more like + – + – – + – – + – + … The first of these needs no explanation. The second is obtained by taking multiples of the golden ratio and seeing whether they lie, mod 1, in a certain interval of length equal to the golden ratio (in which case one puts -1).
In other words, in both cases you take an interval mod 1 and multiples of some real number
mod 1 and multiples of some real number  and define
and define  according to whether
according to whether 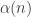 lies in
lies in  mod 1. In the periodic case
mod 1. In the periodic case  is rational, and in the periodic-like case it is irrational. (I have been saying “quasi-periodic” but this turns out to have a different meaning. I’m not sure what the right technical term is.)
is rational, and in the periodic-like case it is irrational. (I have been saying “quasi-periodic” but this turns out to have a different meaning. I’m not sure what the right technical term is.)
If is irrational and we define
is irrational and we define  to be
to be  according to whether or not
according to whether or not  lies in
lies in  , then the sequence
, then the sequence 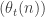 determines
determines  . Thus, we can associate a unique real number with our shifts. That is, it is natural to think of
. Thus, we can associate a unique real number with our shifts. That is, it is natural to think of  as a function from
as a function from  to the reals. If
to the reals. If  is rational this is no longer the case — a small
is rational this is no longer the case — a small  will make no difference — so in this case it is natural to think of it as a function to a cyclic group (which might be nice to think of as roots of unity).
will make no difference — so in this case it is natural to think of it as a function to a cyclic group (which might be nice to think of as roots of unity).
I’ve got more to say but must stop for the time being. One of the main things I wanted to say was that I’m impatient for someone to start searching for good sequences that are given exactly by a formula of this general type. And it would also be good to try to understand theoretically why they seem to work so well. (I am now a bit less optimistic that they will lead to sublogarithmic growth — I think they may just optimize the logarithmic growth in a clever way.)
January 18, 2010 at 9:36 pm
Terminology-wise: Almost periodic?
On looking for reasonably good discrepancy-2 sequences (length > 700, say) that are given exactly by this kind of formula:
I wonder if it’s possible to search for “long” discrepancy-3 sequences which are completely multiplicative, and then try and “smooth out” the places where there’s a partial sum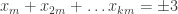 by picking the “right” values for
by picking the “right” values for  and
and  . I suspect that low-discrepancy sequences have a bit too much structure for this to be efficient, but I’d be interested to be wrong.
. I suspect that low-discrepancy sequences have a bit too much structure for this to be efficient, but I’d be interested to be wrong.
January 18, 2010 at 9:57 pm
A few preliminary comments on the 1112 sequence Tim started to analyse. If we continue this analysis as far as we can, choosing signs and shifts according to the patterns observed in the first three terms of each powers-of-3 sequence (continuing as long as we actually have three terms), the only primes that don’t fit one of the six expected patterns are 53, 67, 71, 73, 89 and 113. (In other words — since three-quarters of all random triples would be expected to — the pattern rather breaks down at 53.) By choosing the signs at these primes by hand (and the shifts, though they’re not important, as it turns out), one can get a sequence with discrepancy 2 up to 115. If we are slightly more careful and step up through the primes, changing our selection whenever doing so increases the limit of discrepancy-2, we end up changing the selections at 23, 31, 113 and 127, to get discrepancy 2 up to 141.
I shall try a more sophisticated search and see how much further it gets.
January 19, 2010 at 2:25 pm
I now have a C program chugging away doing depth-first search for sequences with this simple structure (where each prime is associated with a sign and a shift of the pattern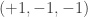 modulo
modulo  ). Unfortunately, it isn’t as easy as I’d hoped: the multiplication of possibilites makes the search very slow. So far it hasn’t got further than the completely multplicative sequence of length 246 (and only got that far when set up to search zero shifts first). Until we have a few more ideas about the likely distribution of shifts and signs, this approach probably won’t succeed in generating long sequences.
). Unfortunately, it isn’t as easy as I’d hoped: the multiplication of possibilites makes the search very slow. So far it hasn’t got further than the completely multplicative sequence of length 246 (and only got that far when set up to search zero shifts first). Until we have a few more ideas about the likely distribution of shifts and signs, this approach probably won’t succeed in generating long sequences.
January 19, 2010 at 3:24 pm
This looks to me like a case where a pure depth-first search won’t be nearly as good as a depth-first search with a bit of look-ahead. That is, each time you choose a shift/sign for a prime , I think you should assign all values that are forced by quasimutliplicativity (the name I’m temporarily giving to sequences that satisfy the shift/sign condition), and then fill in any further values that are forced by the discrepancy condition, followed by further quasimultiplicativity deductions if there are any, etc. I would expect that to be (i) not all that hard to program and (ii) much faster than a pure depth-first search.
, I think you should assign all values that are forced by quasimutliplicativity (the name I’m temporarily giving to sequences that satisfy the shift/sign condition), and then fill in any further values that are forced by the discrepancy condition, followed by further quasimultiplicativity deductions if there are any, etc. I would expect that to be (i) not all that hard to program and (ii) much faster than a pure depth-first search.
But it may be that you are doing something like this anyway.
January 18, 2010 at 9:37 pm |
I tried another way of looking for low-discrepancy sequences, by phrasing it as a quadratic program (QP). For a sequence of length n, you can make an n-by-n matrix D, with each row d encoding the numbers
which need to be summed to count the discrepancy with gap d. D =
1 1 1 1 …
0 1 0 1
0 0 1 0
0 0 0 1
…
Then let G = D’D, and try to find x to minimize x’Gx.
This has a degenerate solution when x is all 0’s. So I added the constraint “x_1 = 1”, which should in turn force other x_i to be not equal to 0.
I used an off-the-shelf QP solver (Angelo Furfaro’s uQuadProg library).
The GPL’ed source code is available at
http://keyfitz.org/jburdick/software/discrepancy_search_20100118.tar.gz
Running it for n = 10, the x’s (and their signs, with ‘.’ for 0) were:
1 -0.428571 -0.285714 0 -0.285714 0.142857 -0.142857 0 0 0.142857
+–.-+-..+
There were a bunch of 0’s. After I added a constraint on the first of those, “x_4 = 1”, the signs of the length-200 sequence were:
+–+-+–.+—++.-.–++-+.+.—-.+++.-+++—-.+-…+–.++++-+-+..+—+–.-+.-+–..+-+++++-.+-+++.-…—+-+-.–+.–+-.++-.++-..-.+–+++.+—++++.++.–.-+.-++-++.+.—+–.-.—..++-.–+++-+-.–.-+-.-.-.
I haven’t computed the discrepancy for that yet (but then, it includes
some 0’s, so I can’t.)
It looks vaguely like there might be a pattern, but it’s not the same as the length 1124 sequence.
Questions:
– can you get rid of the 0’s? (My guess is that they’re cases where
+1 or -1 would work as well, and so you can just constrain the first
0 to be +1 or -1, and try solving with the additional constraint. But
that’s just a guess.)
– can you get longer low-discrepancy sequences this way? (I hope to check this fairly soon, but this requires getting rid of the 0’s. And larger n’s do slow down the solver.)
– can you force the x’s to not “drop off” as they do? (Ideally, we’d like to constrain “|x_i| >= 1”, but it seems like it’s hard to phrase that as a quadratic program, unfortunately.)
January 18, 2010 at 10:56 pm |
Here’s some laboriously collected data, namely the prime factorizations of all the numbers where the first two 1124 sequences differ, which can be found in this table of Thomas’s. Why did I bother to do this? Well, since there are many sequences of length 1124, it may be better to try to understand them as a family rather than individually, so that we don’t search for patterns where they don’t exist (as they probably don’t much, for example, in the values taken at large primes).
What I originally planned to do was look at the values along geometric progressions, just as we have been doing for the 1124 and 1112 sequences. But I ended up with a table so full of pluses that it was completely uninteresting, or rather not an efficient way of conveying the information.
If you look at these numbers with geometric progressions in mind, you will see that there are very few geometric progressions that contain more than one of the numbers, especially if the common ratio is small. This suggests that the new sequence is changed in ways that preserve the pattern (since changing the occasional plus to a minus can have the effect of merely shifting the almost periodic sequence) but I haven’t checked that that is what is happening when there are numbers like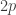 or
or 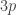 .
.
Here are the factorizations.
1 (I find it quite odd that the two sequences should differ at 1, but there it is. It may be there simply to cancel out the effects of changing other primes a bit later on.)
7
37
41
47
49=7×7
61
67
74=2×37
82=2×41
101
103
107
109
191
193
262=2×131
263
271
274=2×137
289=17×17
295=5×59
305=5×61
307
319=11×29
329=7×47
341=11×31
343=7x7x7
358=2×179
359
361=19×19
362=2×181
377=13×29
379
383
391=17×23
393=3×131
397
403
409
411=3×137
413=7×59
419
421
433
437=19×23
467
469=7×67
537=3×179
541
542=2×271
543=3×181
554=2×277
571
599
607
641
643
653
661
701
709
811
813=3x7x13
821
823
827
831=3×277
857
859
883
887
932=2x2x233
934=2×467
955=5×191
958=2×479
964=2x2x241
965=5×193
1051
1055=5×211
1065=3x5x71
1069
1074=2x3x179
1076=2x2x269
1081=23×47
1084=2x2x271
1094=2×547
1097
1109
Not too many patterns seem to leap out of that, but that is in a way my point. While writing that I suddenly thought it might have been better to put it on the wiki. I’ll do that now as well.
January 18, 2010 at 11:19 pm
I have been wondering whether it would be good to have a small sample of these 1124-length sequences to work with, including some of the ones which have emerged later in the search process? (If they are still being generated in large numbers, a few could be recorded for posterity)
This would give more data out of which to think about patterns, but even now we seem to have been sampling from quite a small part of the search space.
January 18, 2010 at 11:30 pm
I agree that that would be nice. Or perhaps we could have some kind of description of the space. For example, are there lots of numbers that are the same for every single sequence? Do the same patterns appear in every sequence when you look at geometric progressions with small common ratio? Are the signs and shifts the same at small values? It could be that the correct description of these sequences is that you have a promising pattern that you use as your base, and you then mess about with it by changing the values at highly non-smooth numbers.
January 18, 2010 at 11:33 pm
That would be quite easy to do, though they would fall into two large families — those generated by backtracking from the first and second sequences — and members of each family would not differ until the mid-200s, so they may not be that useful for analysis.
However, it has just occurred to me that it might be worth revisiting the other sequence that Klas posted — the one of length over 1000 that didn’t (in a short time) generate one of length 1124, since it may well have different structure.
January 18, 2010 at 11:40 pm
So I’ve just re-run the backtracking program from Klas’ other 1008-length sequence, and it gets you quickly to 1091. I’ll put that on the wiki now.
January 19, 2010 at 1:38 am
I’ve had a quick look at that. I could easily have made a mistake, but if my counting is correct then the values at powers of 2 are – + – – + – – + – +, which is consistent with a golden-ratio-generated sequence (or what I now learn from Kevin is called a Sturmian sequence). I suppose it could also conceivably be a sequence that’s periodic with period 3 and has an anomaly at the end. That would probably become clearer if we looked at other GPs with common ratio 1/2.
January 19, 2010 at 12:35 am |
I’m trying to get up to speed with this project, and have a few naïve questions about the search for >1124-length discrepancy 2 sequences.
As far as I can see from the comments, 2 billion or so sequences of length 1124 have been found, but none longer than 1124. Are the searches done in such a way that all 1125-length sequences that are a known 1124-length sequence, with +1 or -1 added to the end, have been checked? If not, the remainder of this comment is irrelevant…
If so, is it surprising that none of these 1125-length sequences have discrepancy 2? For the short sequences I’ve looked at (length 86 and shorter), the number of discrepancy 2 sequences of length n has never been less than half the number of such sequences of length n-1. It would seem then that at least one of the following is true:
– The number of sequences of length 1125 is much (at least 10^9) times smaller than the number of sequences of length 1124
– The length 1124 sequences found so far all share some property that makes them very unlikely to generate longer sequences.
Is either of these suspected to be the case?
January 19, 2010 at 12:49 am
“For the short sequences I’ve looked at (length 86 and shorter), the number of discrepancy 2 sequences of length n has never been less than half the number of such sequences of length n-1.”
This may well be true for small n, but we should expect that the number of discrepancy-2 sequences can drop off by any fraction when n has enough prime factors.
The 1124-sequences are generated by a program written by Alec. If it can naively extend a sequence, I think it does. But all the known length-1124 sequences are generated by “tracking back” from one of two initial sequences of length about 700, so at the very least all the 1124 sequences in either of those two families will share a lot of properties.
January 19, 2010 at 1:41 am
Perhaps a mathoverflow question: can anybody think of an example of a combinatorial class whose counts grow pretty much exponentially with size, like the short sequence lengths in Chris Johnson’s table, and then go to zero, or even just start going down?
January 19, 2010 at 2:14 am
How about the number of 2-colourings of with no monochromatic arithmetic progression of length 5, or anything like that?
with no monochromatic arithmetic progression of length 5, or anything like that?
January 19, 2010 at 1:27 am |
A very small point. From Greg Kuperberg’s answer to my mathoverflow question I discovered that a slick way to describe the sequence that seems to be giving the values at powers of 2 in the 1124 sequence is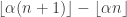 . If
. If  , then this is (a shift of) the sequence we appear to get (when 0s and 1s are converted into +s and -s).
, then this is (a shift of) the sequence we appear to get (when 0s and 1s are converted into +s and -s).
January 19, 2010 at 5:18 am
Isn’t this exactly what you described in this post?
January 19, 2010 at 8:58 am
Yes it is. Somehow I’d never actually written the expression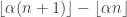 even though I had thought it, so it seemed sort of new when I saw it.
even though I had thought it, so it seemed sort of new when I saw it.
January 19, 2010 at 1:32 am |
Terminology: a 01 sequence determined by whether nx mod1 is in an interval of length x ( assuming x is in (0,1)) is called a Sturmian sequence. The set of n where such a sequence is 1 is called a Beatty sequence.
A standard reference for these is the book of Lothaire which Can be found through Google. Title is Algebraic Combinatorics on Words, not the book on algorithms. A better book that is harder to locate is Automatic Sequences by Shallit and Allouche. The Walters type functions are also automatic sequences…
January 19, 2010 at 5:03 am |
Regarding this Tim’s comment , I set out to calculate marginal probabilities of a sequence of length n passing a set of d HAP tests, for and
and 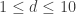 . “Passing a d HAP test” here means that
. “Passing a d HAP test” here means that 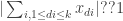 , so, at least for these small examples, passing one test makes a sequence more likely to pass another. I’ll add the gory details to the Wiki.
, so, at least for these small examples, passing one test makes a sequence more likely to pass another. I’ll add the gory details to the Wiki.
I realize that the sequences are small, so here are some analytical results, the little bit that I managed to get. Calling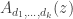 the generating function of sequences that pass HAP tests for d’s in the subscript, we have
the generating function of sequences that pass HAP tests for d’s in the subscript, we have
From this, one gets that grows exponentially with n, as
grows exponentially with n, as 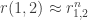 where
where ![r_{1,2} = \frac{2^{3/4}}{\sqrt{3} \sqrt[4]{4-\sqrt{10}}} \approx 1.01493\/](https://s0.wp.com/latex.php?latex=r_%7B1%2C2%7D+%3D+%5Cfrac%7B2%5E%7B3%2F4%7D%7D%7B%5Csqrt%7B3%7D+%5Csqrt%5B4%5D%7B4-%5Csqrt%7B10%7D%7D%7D+%5Capprox+1.01493%5C%2F&bg=ffffff&fg=333333&s=0&c=20201002) .
.
I suspect we’d get similar behavior for other pairs of d’s, I haven’t checked yet. Producing generating functions for more than two d’s is unfortunately beyond my capabilities at the moment.
May this resurrect hope in probabilistic methods?
January 19, 2010 at 5:24 am
The point is that if one calls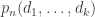 the marginal probability that an n-length sequence simultaneously passes HAP tests for
the marginal probability that an n-length sequence simultaneously passes HAP tests for 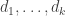 , but not necessarily only those tests, and writes
, but not necessarily only those tests, and writes 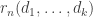 for
for  , counts on sequences up to 30 in length show that all the r’s are >1, i.e. a sequence passing one or more d HAP tests makes it more likely to pass a HAP test for another d…
, counts on sequences up to 30 in length show that all the r’s are >1, i.e. a sequence passing one or more d HAP tests makes it more likely to pass a HAP test for another d…
January 19, 2010 at 7:21 am
I also get
January 19, 2010 at 10:33 am
I think your problem may be that you are using the “greater than” and “less than” symbols, which causes problems because WordPress often interprets them as html symbols. To get round it one can type ampersand gt semicolon or ampersand lt semicolon (where of course by “ampersand” and “semicolon” I mean & and ; ). If you tell me in words what it means to pass a d HAP test (I don’t find it quite obvious from what survives in your comment) then I’ll finish editing what you wrote. I think I’ve got most of it to compile properly now.
January 19, 2010 at 4:08 pm
Ah, of course, thanks. I’ll just repost the whole (slightly corrected) thing. Here we go, fingers crossed…
Regarding this Tim’s comment , I set out to calculate marginal probabilities of a sequence of length n passing a set of d HAP tests, for and
and 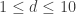 . “Passing a d HAP test” here means that
. “Passing a d HAP test” here means that  for all
for all 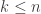 . Obviously, for any n, the only non-trivial tests are for
. Obviously, for any n, the only non-trivial tests are for  . Calling
. Calling 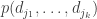 the probability that a sequence passes tests for
the probability that a sequence passes tests for  , but not necessarily only those tests, I looked at the ratios
, but not necessarily only those tests, I looked at the ratios  , for all available sequences of d’s, and surprisingly they all turn out to be > 1, so, at least for these small examples, passing one test makes a sequence more likely to pass another. I’ll add the gory details to the Wiki.
, for all available sequences of d’s, and surprisingly they all turn out to be > 1, so, at least for these small examples, passing one test makes a sequence more likely to pass another. I’ll add the gory details to the Wiki.
I realize that the sequences are small, so here are some analytical results, the little bit that I managed to get. Calling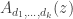 the generating function of sequences that pass HAP tests for d’s in the subscript, we have
the generating function of sequences that pass HAP tests for d’s in the subscript, we have
From this, one gets that grows exponentially with n, as
grows exponentially with n, as 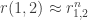 where
where ![r_{1,2} = \frac{2^{3/4}}{\sqrt{3} \sqrt[4]{4-\sqrt{10}}} \approx 1.01493\/](https://s0.wp.com/latex.php?latex=r_%7B1%2C2%7D+%3D+%5Cfrac%7B2%5E%7B3%2F4%7D%7D%7B%5Csqrt%7B3%7D+%5Csqrt%5B4%5D%7B4-%5Csqrt%7B10%7D%7D%7D+%5Capprox+1.01493%5C%2F&bg=ffffff&fg=333333&s=0&c=20201002) .
.
I suspect we’d get similar behavior for other pairs of d’s, I haven’t checked yet. Producing generating functions for more than two d’s is unfortunately beyond my capabilities at the moment.
January 19, 2010 at 9:28 am |
I have some silly algebraic/geometric thoughts (which, now that I’m writing them down, I realize are probably well-known and may help explain why the problem is so hard) which I’ll go ahead and put out there now, since it now seems probable that I’ll miss the official launch of the theoretical part of the project and will very likely be unable to seriously contribute to it for a couple of days.
Question: Let have discrepancy bounded by a constant. Then is it true that f must have zeroes?
have discrepancy bounded by a constant. Then is it true that f must have zeroes?
Obviously an affirmative answer would imply EDP, and it’s probably out of reach. If we allow f to have zeroes, then there are certainly a lot of examples with bounded discrepancy, but the most obvious ones seem to come from ring homomorphisms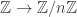 .
.
This is where I start waving my hands vigorously until a real arithmetic geometer (or at least a real mathematician) steps in: We might try to think of any integer-valued sequence as factoring through some sort of ring homomorphism from . Better yet, we’ll flip the arrows and think of an integer-valued sequence as having a morphism to Spec(Z); since Spec(Z) is a final object in the category of schemes, perhaps we can ask if (some special class of) integer-valued sequences must “factor through” a scheme to have bounded discrepancy.
. Better yet, we’ll flip the arrows and think of an integer-valued sequence as having a morphism to Spec(Z); since Spec(Z) is a final object in the category of schemes, perhaps we can ask if (some special class of) integer-valued sequences must “factor through” a scheme to have bounded discrepancy.
Now I’ll start waving my hands to the point where you’re probably concerned for the health of my wrists. If there is in fact some arithmetic-geometry approach to the “algebraically structured” problem (and there probably is, even if it’s far from what I talked about above, since there’s so many connections to number theory) we might ask if the “unstructured” sequences correspond to some softer category of spaces. This doesn’t seem entirely unreasonable, since there’s some notions of convergence and completion going on which hint at moving from something like algebraic to analytic spaces.
If all of what I’ve said above is true, or even sort of true, then there’s a geometric way of looking at EDP. I’d be highly interested in such a thing, and trying to understand the geometric aspects (if they exist) would likely be useful for many other people as well.
January 19, 2010 at 9:29 am |
An experiment that we would expect to fail does fail: Take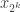 as in the first 1124 sequence, and use
as in the first 1124 sequence, and use 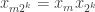 and take
and take  greedily for each odd
greedily for each odd  (comparing which assignment for
(comparing which assignment for  would have the worst impact over all HAPs already completely assigned).
would have the worst impact over all HAPs already completely assigned).
Basically, set all shifts to 0, and ignore ‘s apparent multiplicativity.
‘s apparent multiplicativity.
This results in linear discrepancy.
January 19, 2010 at 10:26 am
That kind of experiment interests me because it hints at possible ideas that might go into a proof. By that I mean that if you impose some condition and it seems to force high discrepancy, then there ought to be a chance of proving that that condition cannot hold in a sequence of bounded discrepancy. Of course, the weaker the condition you impose, the more interesting it becomes. I think the one you’ve just imposed is strong enough to be interesting: it suggests that if one could prove that , then there would be some chance of deducing something about the function
, then there would be some chance of deducing something about the function  .
.
January 19, 2010 at 12:02 pm |
In an earlier comment I wrote this: “I haven’t checked, but I’m fairly sure it’s true, and easy to prove, that if for every the sequences
the sequences  are all shifts of each other, then the shifts must be homomorphisms.”
are all shifts of each other, then the shifts must be homomorphisms.”
I now have checked, and it seems to be false. Let’s define a function such that if
such that if  is coprime to both 2 and 3, then
is coprime to both 2 and 3, then  . To determine
. To determine  , all I now have to do is say what its values are at numbers of the form
, all I now have to do is say what its values are at numbers of the form 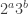 . I define
. I define 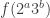 to be
to be  , which is a slick way of saying that
, which is a slick way of saying that 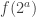 goes + – + – + – + – …,
goes + – + – + – + – …,  goes + + – – + + – – …, and
goes + + – – + + – – …, and 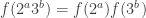 .
.
If I fix some and look at the sequence
and look at the sequence  then I get + + – – + + – – … if
then I get + + – – + + – – … if  is 0 or 1 mod 4, and – – + + – – + + … if
is 0 or 1 mod 4, and – – + + – – + + … if  is 2 or 3 mod 4. So, mod 4, we have
is 2 or 3 mod 4. So, mod 4, we have 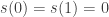 and
and  . This function is not a homomorphism, since, for example,
. This function is not a homomorphism, since, for example, 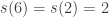 and
and  .
.
One might criticize that example by saying that if you introduce signs then everything can be rescued. However, one can create a slightly more complicated example of a similar kind that cannot be rescued in this way. For instance, one can define at powers of 2 using the sequence + – – + – – + – – … and then define
at powers of 2 using the sequence + – – + – – + – – … and then define 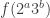 to be
to be  , where
, where 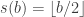 . Again, this
. Again, this  is not a homomorphism, but if you look at what happens along GPs with common ratio 3, you find that you get sequences of the form + + – – – – + + – – – – + + – – – – …, which are all shifts of each other. This time, because of the bias towards -1, there is no hope of using signs to convert one sequence into a non-trivial shift of it.
is not a homomorphism, but if you look at what happens along GPs with common ratio 3, you find that you get sequences of the form + + – – – – + + – – – – + + – – – – …, which are all shifts of each other. This time, because of the bias towards -1, there is no hope of using signs to convert one sequence into a non-trivial shift of it.
I still feel as though it ought not to be too surprising that we are getting homomorphisms, but I am not yet sure what the extra hypothesis should be that would guarantee them. It’s even conceivable that we should be thinking about a slightly more general class of example — after all, my counterexamples above have plenty of structure.
January 19, 2010 at 1:36 pm |
Here’s another observation about the 1124 sequence. If you look at the table at the bottom of this page of Thomas’s, then you will see that the 2-sequence equals minus the 3-sequence all the way up to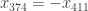 , with just two exceptions (at (142,213) and (146,219)). Thus, if we associate with each number a shift mod 1, then the shift associated with
, with just two exceptions (at (142,213) and (146,219)). Thus, if we associate with each number a shift mod 1, then the shift associated with  ought to be 1/2. If, as seems to be the case, the shift associated with 2 is close to the golden ratio, then the shift associated with 3 ought to be around 0.118. The fact that this is fairly small explains why when you multiply by 3 you get a sequence with longish runs of pluses followed by longish runs of minuses. It also makes it possible to predict how the 3-sequence should continue, so it could provide plausible ways of extending the 1124 sequence.
ought to be 1/2. If, as seems to be the case, the shift associated with 2 is close to the golden ratio, then the shift associated with 3 ought to be around 0.118. The fact that this is fairly small explains why when you multiply by 3 you get a sequence with longish runs of pluses followed by longish runs of minuses. It also makes it possible to predict how the 3-sequence should continue, so it could provide plausible ways of extending the 1124 sequence.
One can of course make other predictions of a similar kind. For instance, the 5 and 6 sequences are the same all the way up to (875,1050). The shift associated with 6 should be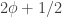 (where
(where  , or about
, or about  mod 1, and therefore so should the shift associated with 5. To be slightly clearer what I mean by this, I think if you multiply repeatedly by 5, you should get a Sturmian sequence that depends on the value mod 1 of multiples of
mod 1, and therefore so should the shift associated with 5. To be slightly clearer what I mean by this, I think if you multiply repeatedly by 5, you should get a Sturmian sequence that depends on the value mod 1 of multiples of  . Unfortunately, we do not have enough data to observe this convincingly, but what we do observe seems consistent with it.
. Unfortunately, we do not have enough data to observe this convincingly, but what we do observe seems consistent with it.
I have some more suggestions but I’d rather put them in a separate comment as they’re on a slightly different, though related, theme.
January 19, 2010 at 3:47 pm
On second thoughts, I didn’t describe properly what should happen when you multiply by 3. It doesn’t correspond to a rotation through 0.118, but rather to a change of sign (resulting from multiplying by 3/2) followed by a shift by 1 (=rotation by 0.618) along the powers-of-2 sequence. Recalling that the powers-of-2 sequence begins + – + – – + – – + -, this leads us to expect that the powers-of-3 sequence should begin + + + + – – – + + + (which I obtain from the previous sequence by flipping every other sign). This is indeed the sequence we get for powers of 3 as far as they go.
January 19, 2010 at 2:27 pm |
Putting together the thoughts in my previous comment and doing a bit of calculation, I have come up with the following formula, which I think agrees with the 1124 sequence on almost all numbers of the form (though there’s an annoying glitch at 49). To describe the formula, let me first define a function
(though there’s an annoying glitch at 49). To describe the formula, let me first define a function  by
by  . That is supposed to satisfy
. That is supposed to satisfy 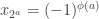 . If it doesn’t, then it should be adjusted until it does.
. If it doesn’t, then it should be adjusted until it does.
Using the various subsequence relations such as 3/2=1, 5=6, 7=-1 (the last one being pretty good but not as perfect as the others), which tend to fail, when they do fail, only on numbers with at least one large prime factor, we arrive at the formula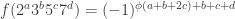 . The appearance of
. The appearance of  is giving us information about the shifts associated with 2,3,5 and 7, while the
is giving us information about the shifts associated with 2,3,5 and 7, while the 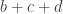 is giving us the signs. We are expecting multiplication-to-addition homomorphisms, which is why these expressions are simple integer combinations of
is giving us the signs. We are expecting multiplication-to-addition homomorphisms, which is why these expressions are simple integer combinations of 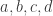 .
.
I haven’t yet checked this formula on a few values, so I may have made the odd mistake here.
Once it is correct, what I propose is that we should extend it a bit further, aiming for a formula that is valid on almost all B-smooth numbers for some suitable cutoff B. Then we should search for examples that are constrained to be given by that formula for smooth numbers, and leave ourselves a free choice for numbers with large prime factors. I think that’s our best chance of finding good examples if pure brute force is no longer working.
January 19, 2010 at 4:30 pm
I’ve now done a few spot checks. Assuming that is defined correctly, it does at least give the correct values at powers of 2,3,5,6 and 7. Given the way I came up with it, that really ought to mean that it’s OK at all numbers of the form
is defined correctly, it does at least give the correct values at powers of 2,3,5,6 and 7. Given the way I came up with it, that really ought to mean that it’s OK at all numbers of the form  . However, the fact that multiplication by 7 doesn’t always flip the sign makes this part of the formula less accurate. For instance, it fails at 126=7×18 (since 18 and 126 get the same value), and it also fails at 686=7x7x7x2, and at 784=7x2x2x2x7.
. However, the fact that multiplication by 7 doesn’t always flip the sign makes this part of the formula less accurate. For instance, it fails at 126=7×18 (since 18 and 126 get the same value), and it also fails at 686=7x7x7x2, and at 784=7x2x2x2x7.
Ah ha. I think I may have a way of explaining the anomalies associated with 7. The sequence you get when you look at the GP 7,14,28,56,112,… is – + – + + – + -. Up to now I’ve been thinking of the first value here as an anomaly, since if you change it to a + then you get something that fits the powers-of-2 sequence more easily. However, if you extend the powers-of-2 sequence backwards by five terms (by which I mean, take the Sturmian sequence it coincides with and extend that backwards by five terms), you get the sequence + – + – – + – + – – + – – + – +, and this is minus the sequence sequence. In other words, it looks as though
sequence. In other words, it looks as though 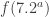 might be
might be  . Note that since 5 is a Fibonacci number,
. Note that since 5 is a Fibonacci number,  is usually equal to
is usually equal to  .
.
So I now propose a small correction factor to the formula above, in the hope that it will magically deal with the problems associated with 7. (I’ll check this later.) The new formula is .
.
January 19, 2010 at 5:02 pm
And now for the moment of truth: what will happen at ? The formula says we should take
? The formula says we should take  . So we’ve got something to refer to, here are the values of
. So we’ve got something to refer to, here are the values of  at -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. They are 0101101011011010. So
at -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. They are 0101101011011010. So 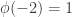 and the answer we get is 1. Now let me go and look it up in the table … damn, it’s -1. Oh well.
and the answer we get is 1. Now let me go and look it up in the table … damn, it’s -1. Oh well.
Hang on, I’m not sure what’s going on here, because 126 wasn’t an anomalous value and it doesn’t take the same value as 18. I don’t understand why I said it did, but it’s good news that it doesn’t. So how on earth can the formula fail? It is correct at 7, 14, 28, 56, since it was cooked up to be. Ah, no it isn’t. The 5 should have been a 6. And what I said about subtracting 5 usually making no difference wasn’t what I should have said. What I now say is that shifting by -6 is usually the same as shifting by +2 , since 8 is a Fibonacci number. So the new formula should have been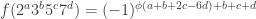 . This little fudge (but it’s not really a fudge — just correcting a mistake) tells us that
. This little fudge (but it’s not really a fudge — just correcting a mistake) tells us that  should be
should be 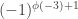 . Since
. Since 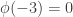 , we get -1 as the answer, which is now correct.
, we get -1 as the answer, which is now correct.
Now let me try out 784=2x2x2x2x7x7. The formula suggests . Since the sequence is built out of 10 and 110 and never has two 10s in a row, we are rather fortunate in being able to tell that
. Since the sequence is built out of 10 and 110 and never has two 10s in a row, we are rather fortunate in being able to tell that 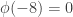 . So the revised formula predicts that the answer is 1. And it is … 1!
. So the revised formula predicts that the answer is 1. And it is … 1!
That is very satisfying, despite the high probability that both my formula and my use of it were wrong and the two mistakes cancelled out.
January 19, 2010 at 6:29 pm
Damn, a further look suggests that 5 was correct after all. I’m getting confused. I am now less confident that the anomaly at 7 can be dealt with in this way, but I hope that with a bit more work I’ll finally nail it.
February 10, 2010 at 12:52 am |
Just a historical note: I heard Walters’ example from Jozsef Beck several years ago. Perhaps unsurprisingly, Beck knows quite a lot about this problem (mostly to the effect that it is totally unapproachable). Both Hochberg and Vijay were his students.
April 4, 2022 at 4:11 pm |
[…] I think it will be useful to gather such examples together. I am partially motivated by the recent polymath5 which, at this stage, have become an interesting experimental mathematics project. So I am […]