This post is one of three threads that began in the comments after the post entitled A combinatorial approach to density Hales-Jewett. The other two are Upper and lower bounds for the density Hales-Jewett problem , hosted by Terence Tao on his blog, and DHJ — the triangle-removal approach, which is on this blog. These three threads are exploring different facets of the problem, though there are likely to be some relationships between them.
Quasirandomness.
Many proofs of combinatorial density theorems rely in one way or another on an appropriate notion of quasirandomness. The idea is that, as we do, you have a dense subset of some structure and you want to prove that it must contain a substructure of a certain kind. You observe that a random subset of the given density will contain many substructures of that kind (with extremely high probability), and you then ask, “What properties do random sets have that cause them to contain all these substructures?” More formally, you look for some deterministic property of subsets of your structure that is sufficient to guarantee that a dense subset contains roughly the same number of substructures as a random subset of the same density.For example, suppose you are trying to find a triangle in a dense graph. (We can think of a graph with 
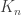



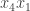
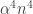
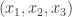
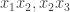


This might seem a slightly disappointing answer to the question. We are trying to guarantee the expected number of one small subgraph and we assume as our quasirandomness property something that appears to be equally strong: that we have the expected number of another small subgraph. How can that possibly be a good thing to do?
A first answer is that if you have the right number of 4-cycles then it doesn’t just give you triangles: it gives you all small subgraphs. But an answer that is more pertinent to us here is that we can draw very useful consequences if a graph does not have the right number of 4-cycles. For example, we can find two large sets of vertices 



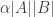
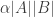
This sort of local-to-global implication is extremely useful. The local property can be used to show that sets have substructures. And if the local property fails, then one has some global property of the set that can be exploited in a number of ways.
It is not too important for the purposes of this thread to understand what all these ways are. But one of them does stand out: a global property is useful if it allows you to find a substructure of the main structure such that the intersection of
So one question that it would be very good to answer is this: what on earth do we mean by a quasirandom subset of ![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002)
![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002)
Obstructions to uniformity.
If one wants to devise a proof that depends on a quasirandomness property, then one wants that property itself to have some properties. These are (i) that it should have a local definition that allows one to show that quasirandom sets contain many combinatorial lines; (ii) that every non-quasirandom set should be non-quasirandom for a global reason (such as intersecting a large structured set more densely than expected); and (iii) that every set that is non-quasirandom for a global reason like this should look “too dense” in some substructure that is similar to the main structure.
One of the main purposes of this thread is to understand (ii) in the case of the density Hales-Jewett problem. What are the global reasons for a set not to have roughly the expected number of combinatorial lines? These are what is meant by obstructions to uniformity. The dream is to be able to say, “It’s clear that a set with one of these global properties will not necessarily have the expected number of combinatorial lines. But in fact, the converse is true too: if a set does not have the expected number of combinatorial lines then it must have one of these global properties.”
How might we work out what the obstructions to uniformity are? There are two possible approaches, both of which are valuable. One is just to think of as many genuinely different ways as we can for a set to fail to have the expected number of combinatorial lines. Another is to devise a local quasirandomness property and to see what we can deduce if that local property does not hold. So far, all the discussion has centred on the first approach, though in the end it is the second approach that one would have to use (as it is in other contexts where the theory of quasirandomness is applied).
There was quite a bit of discussion about the first approach in the “obstructions to uniformity” thread on the combinatorial approach to density Hales-Jewett post. It was summarized by Terence Tao in his comment number 148, so I won’t give lots of links here (though I will give some). But let me briefly say what the obstructions we now know of are, and add one that has not yet been mentioned.
Example 1. One fairly general class of obstructions is obtained as follows. Let 
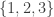



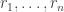
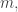
![x\in[3]^n](https://s0.wp.com/latex.php?latex=x%5Cin%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002)

Suppose now that 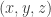




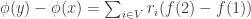
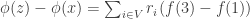

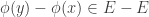



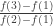
The example given is what one might call an extreme obstruction. If 


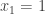
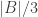
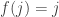

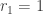

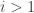
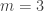

Example 2. The next class of obstructions is closely related to obstructions that occur in the corners problem. Suppose that 

![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

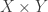

![{}[n]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
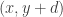
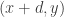




These facts about corners naturally suggest the following class of obstructions in the DHJ problem. This class is a generalization that I should have spotted of a class that was suggested in my comment 116 . It also relates very interestingly to some of the discussion over on the Sperner thread about simpler forms of DHJ. (See for example comment 335 and comment 344. )
Let 


![2^{[n]}](https://s0.wp.com/latex.php?latex=2%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The discussion over at the Sperner thread has almost certainly already given us the tools to deal with a set
Example 3. This is an intriguing example introduced by Ryan O’Donnell in comment 92. He considers (amongst other similar examples) the set 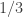
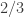
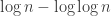
It is easy to see that a number of variants of this example can be defined. (For example, one can permute the ground set, or one can ask for a run whose length varies according to where you are, etc. etc.)
What next?
If we are going to try to prove that a non-quasirandom set must have an easily understood obstruction to uniformity, our task will be much easier if we can come up with a single description that applies to all the examples we know of. That is, we would like a single global property that is shared by all the above examples (and any other examples there might be) and that allows us to obtain a density increase on a substructure. In comment 148, Terry did just that, defining a notion of a standard obstruction to uniformity. However, I do not yet understand his definition well enough to be able to explain it here, or to know whether it covers the more general version of Example 2 above. Terry, if you’re reading this and would like to give a fully precise definition, it would be very helpful and I could update this post to include it.
The main questions for this thread, it seems to me, are these.
1. What would be a good definition of a quasirandom subset of
2. Have we thought of all the ways that a set can have too many combinatorial lines? (Ryan’s example is troubling here: it seems to contain an idea that could be much more widely applicable. One might call this the “or” idea.)
3. Do we have a unified description of all the obstructions to uniformity that we have thought of so far, or, even better, a description that might conceivably apply to all obstructions to uniformity?
Comments on this post should begin at 400.

February 8, 2009 at 6:08 pm |
400. Quasirandomness.
In comment number 109, I asked for the go-ahead to do certain calculations away from the computer. Nobody responded to the request, which suggests to me that making requests that demand blog comments for their replies is not a good idea. In future, if I have such a request I will do it via a poll. (If anybody else wants me to fix up a poll for them, I think I now understand how to get such a poll to appear in a comment, so I’d be happy to do it for them.) However, given that I have not been granted permission to do these calculations, I am going to do them in public instead. The result may be a mess, but I hope that if it is, then at least it will be an informative mess.
What I want to do is prove a counting lemma for triangles in a special class of tripartite graphs, where the vertices are subsets of![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and any edge has to join disjoint sets. (This class has already been much discussed.) Such a lemma would say that if all three parts of the graph are quasirandom, then the number of triangles is roughly what you expect it to be. At this stage, we do not know what “quasirandom” means, so we might seem to have a serious problem. However, this may well not be a problem, since the existing definitions of quasirandomness didn’t just spring from nowhere and turn out to be useful: one can derive them by attempting to prove counting lemmas and seeing what hypotheses you need in order to get your attempts to work. That is what I plan to try to do here.
, and any edge has to join disjoint sets. (This class has already been much discussed.) Such a lemma would say that if all three parts of the graph are quasirandom, then the number of triangles is roughly what you expect it to be. At this stage, we do not know what “quasirandom” means, so we might seem to have a serious problem. However, this may well not be a problem, since the existing definitions of quasirandomness didn’t just spring from nowhere and turn out to be useful: one can derive them by attempting to prove counting lemmas and seeing what hypotheses you need in order to get your attempts to work. That is what I plan to try to do here.
Let me give the definitions that I will need in order to state a counting lemma formally (with the exception of the definition of “quasirandom”, which I’m hoping will emerge during the proof). I shall follow standard practice in additive combinatorics, and attempt to prove a result about![{}[-1,1]](https://s0.wp.com/latex.php?latex=%7B%7D%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) -valued functions rather than about sets. Let
-valued functions rather than about sets. Let  ,
, 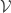 and
and 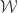 be three copies of the set of all subsets of
be three copies of the set of all subsets of ![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) of size between
of size between  and
and 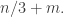 Let us write
Let us write 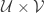 not for the usual Cartesian product, but rather for the set of all pairs
not for the usual Cartesian product, but rather for the set of all pairs  such that
such that 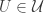 ,
,  and
and 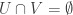 , and similarly for the other two possible products, and also for the product of all three. (I called this the Kneser product in another comment, and may do so again in this thread.) Here is the counting lemma.
, and similarly for the other two possible products, and also for the product of all three. (I called this the Kneser product in another comment, and may do so again in this thread.) Here is the counting lemma.
Lemma. Let ,
,  and
and  be
be  -quasirandom functions from
-quasirandom functions from 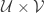 ,
,  and
and 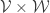 to
to ![\null[-1,1]](https://s0.wp.com/latex.php?latex=%5Cnull%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , respectively. Then the absolute value of the expectation of
, respectively. Then the absolute value of the expectation of 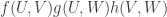 over all triples
over all triples 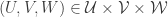 is at most
is at most 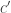 , where
, where 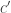 tends to zero as
tends to zero as  tends to zero.
tends to zero.
No guarantee that this is a remotely sensible formulation, but it’s a first attempt. To be continued in my next comment.
February 8, 2009 at 6:31 pm |
401. Quasirandomness.
To understand the lemma, it is helpful to bear in mind the example where each of ,
,  and
and  is a function that randomly takes the values 1 or -1.
is a function that randomly takes the values 1 or -1.
Now let’s attempt to prove it, using standard Cauchy-Schwarz methods. To avoid overburdening the notation, I will adopt the following convention concerning whether it is to be understood that sets are disjoint. If I write something like then
then  and
and  are disjoint, whereas if I write
are disjoint, whereas if I write  then they are allowed to overlap. An exception is that if I use the same letter twice then overlap is allowed: so if I write
then they are allowed to overlap. An exception is that if I use the same letter twice then overlap is allowed: so if I write 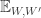 then
then  and
and 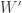 do not have to be disjoint. I will also write
do not have to be disjoint. I will also write 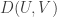 for the set of
for the set of  that are disjoint from both
that are disjoint from both  and
and  , and so on. I hope it will be clear.
, and so on. I hope it will be clear.
With the benefit of many similar arguments to base this one on, we try to find an upper bound for the fourth power of the quantity that ultimately interests us. Here goes:
Before I continue, I need to decide whether it is catastrophic to apply Cauchy-Schwarz at this point. The answer is no if and only if I have some reason to suppose that the function is reasonably constant (by which I mean that it doesn’t do something like being zero except for a very sparse set of
is reasonably constant (by which I mean that it doesn’t do something like being zero except for a very sparse set of  ). It seems OK, so let’s continue:
). It seems OK, so let’s continue:
Now let’s use the fact that is bounded above by 1 in modulus to get rid of it. (This looks ridiculous as we’re throwing away all that quasirandomness information about
is bounded above by 1 in modulus to get rid of it. (This looks ridiculous as we’re throwing away all that quasirandomness information about  . But experience with other problems suggests that we shall need just one of the three functions to be quasirandom.)
. But experience with other problems suggests that we shall need just one of the three functions to be quasirandom.)
Now we multiply out the inner bracket.
Now interchange the order of summation.
Hang on. That was wrong, and the first point where something happens that is interestingly different from what happens in other proofs of this kind. The problem is that there is a big difference between interchanging expectations and interchanging summations round here. In fact, even the very first step, which looked innocuous enough, was wrong. I’ll pause here and reflect on this in another comment.
February 8, 2009 at 6:41 pm |
402. Standard obstructions to uniformity
I’ll try here to clarify my earlier comment 148. Let me start by reviewing the theory of corners in
in ![{}[n]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) , or more precisely
, or more precisely  to avoid some (extremely minor) technicalities.
to avoid some (extremely minor) technicalities.
Say that a dense set is _uniform for the first corner_ if for any other dense sets B, C, the number of corners
is _uniform for the first corner_ if for any other dense sets B, C, the number of corners  with
with 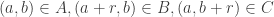 is close to the expected number. It is standard that A is uniform for the first corner if and only if it does not have an anomalous density on a dense Cartesian product
is close to the expected number. It is standard that A is uniform for the first corner if and only if it does not have an anomalous density on a dense Cartesian product 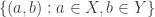 . There are similar results for the other corners, e.g. B is uniform on the second corner iff there is no anomalous density on a dense sheared Cartesian product
. There are similar results for the other corners, e.g. B is uniform on the second corner iff there is no anomalous density on a dense sheared Cartesian product  , etc.
, etc.
One can of course replace sets by functions: a function f(a,b) is uniform for the first corner iff it does not have an anomalous average on dense Cartesian products, etc.
Now return to DHJ. Given a set A in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , we can define the function
, we can define the function 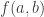 on
on ![{}[n]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) to be the number of elements of A with a 1s and b 2s (and thus c=n-a-b 3s, which I will ignore here). Let me call this function f the global richness profile for A. We know that one good way to construct combinatorial line-free sets A is to ensure that f(a,b) is supported on a set with no corners (indeed, all the best examples in my own thread on this project come this way). More generally, it is pretty clear that A is not going to be quasirandom for the third point of combinatorial lines if its richness profile f is not uniform for the first corner. (I managed to interchange “first” and “third” in my notational conventions, but please ignore this for the sake of discussion.)
to be the number of elements of A with a 1s and b 2s (and thus c=n-a-b 3s, which I will ignore here). Let me call this function f the global richness profile for A. We know that one good way to construct combinatorial line-free sets A is to ensure that f(a,b) is supported on a set with no corners (indeed, all the best examples in my own thread on this project come this way). More generally, it is pretty clear that A is not going to be quasirandom for the third point of combinatorial lines if its richness profile f is not uniform for the first corner. (I managed to interchange “first” and “third” in my notational conventions, but please ignore this for the sake of discussion.)
That’s the “global” obstruction to uniformity. One can also do something similar using “local” obstructions. Consider a reasonably large subset S of [n], and define the local richness profile of A to be the number of elements of A which have a 1s in S and b 2s in S (and thus |S|-a-b 3s in S). Now, if the local richness profile is supported on a corner-free set, then it is not quite true that A has no combinatorial lines; but the lines in A now must have all their wildcards outside of S, so this should cut down substantially on the number of lines in A (compared with the random set A) if S is even moderately large. For similar reasons, I would expect A to fail to be quasirandom for the third point of a combinatorial line if
of A to be the number of elements of A which have a 1s in S and b 2s in S (and thus |S|-a-b 3s in S). Now, if the local richness profile is supported on a corner-free set, then it is not quite true that A has no combinatorial lines; but the lines in A now must have all their wildcards outside of S, so this should cut down substantially on the number of lines in A (compared with the random set A) if S is even moderately large. For similar reasons, I would expect A to fail to be quasirandom for the third point of a combinatorial line if 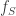 is not uniform for the first corner, and analogously for the other two points of the combinatorial line.
is not uniform for the first corner, and analogously for the other two points of the combinatorial line.
Boris suggested replacing the set S with a more general integer-valued weight![w: [n] \to {\Bbb Z}](https://s0.wp.com/latex.php?latex=w%3A+%5Bn%5D+%5Cto+%7B%5CBbb+Z%7D&bg=ffffff&fg=333333&s=0&c=20201002) , which should accomplish a similar effect.
, which should accomplish a similar effect.
One can localise these local obstructions even further, by working with slices of A instead of all of A, e.g. by fixing some moderate number of coordinates and then considering a local or global richness profile for the slice on the remaining coordinates (or some subset S thereof, or some weight w). If this profile fails to be quasirandom for most slices, or its density deviates from the mean for most slices, then this should also be an obstruction to uniformity.
So I guess my formalisation of a “standard obstruction to uniformity” for the third point of a combinatorial line for a set![A \subset [3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) of density
of density  , would consist of a small set T of fixed indices, then a disjoint large subset S of sampling indices, and dense sets X, Y of
, would consist of a small set T of fixed indices, then a disjoint large subset S of sampling indices, and dense sets X, Y of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) (or more precisely
(or more precisely ![{}[|S|]](https://s0.wp.com/latex.php?latex=%7B%7D%5B%7CS%7C%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) such that for most of the
) such that for most of the  choices
choices  of the fixed indices, the local richness profile
of the fixed indices, the local richness profile  , defined as the number of elements of A with coordinates
, defined as the number of elements of A with coordinates  on T, and with a 1s in S and b 2s in S, has density significantly different from
on T, and with a 1s in S and b 2s in S, has density significantly different from  on
on  . (Actually, as I write this it occurs to me that one may need X, Y to depend on
. (Actually, as I write this it occurs to me that one may need X, Y to depend on  .)
.)
Anyway, that’s my proposal for the standard obstruction… hopefully it makes some sense.
February 8, 2009 at 6:54 pm |
403. Standard obstructions to uniformity.
Thanks very much for that Terry. I’ve just read it rather quickly, and I get the impression that because it focuses strongly on the cardinalities of sets, it may not have picked up the full (and new since your comment 148 ) generality of Example 2 in my post above. I’m not over-worried about that, as I have a strong feeling that that example can be dealt with. But if I am right that it isn’t a standard obstruction to uniformity then it would be good to try to generalize the definition.
February 8, 2009 at 7:45 pm |
404. Quasirandomness.
What, then was the problem with the first line of the calculations in 401? What I did was to replace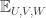 by
by  Here, the first expectation was over disjoint triples
Here, the first expectation was over disjoint triples 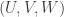 while the second took an expectation over disjoint pairs
while the second took an expectation over disjoint pairs  of the expectation over all sets
of the expectation over all sets  that were disjoint from
that were disjoint from 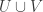 . And there is a huge difference between the two, since in the second we count all disjoint pairs
. And there is a huge difference between the two, since in the second we count all disjoint pairs  equally, whereas in the first we count a pair
equally, whereas in the first we count a pair  far more if the size of
far more if the size of  is smaller, since then there are many more
is smaller, since then there are many more  that are disjoint from
that are disjoint from  and
and  . And since the sizes of the sets are not fixed, this is a serious concern.
. And since the sizes of the sets are not fixed, this is a serious concern.
For now I’m going to restrict attention to the simpler set-up where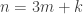 for some smallish
for some smallish  and all our sets have size
and all our sets have size  . So now the sizes of the sets
. So now the sizes of the sets 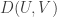 will always be
will always be  . However, while this corrects the first line, it doesn’t get us out of the woods, because there is no trick like that that we can pull off to sort out the second interchanging of the order of summation. And that is because there is no getting away from the fact that
. However, while this corrects the first line, it doesn’t get us out of the woods, because there is no trick like that that we can pull off to sort out the second interchanging of the order of summation. And that is because there is no getting away from the fact that 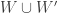 can vary in size.
can vary in size.
However, it now occurs to me that this may not be such a huge problem. The reason is that most of the time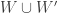 is of maximal size
is of maximal size 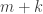 , since the smallness of
, since the smallness of  makes it rather unlikely that a point will be in the complement of both
makes it rather unlikely that a point will be in the complement of both  and
and 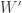 . (What’s more, the probability that the complement has size
. (What’s more, the probability that the complement has size  goes down like
goes down like  while the gain in the number of pairs
while the gain in the number of pairs  goes up like
goes up like 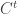 , so the exceptions should be insignificant.)
, so the exceptions should be insignificant.)
I’m not sure that this reasoning is correct, but for now let us pretend that the problem doesn’t exist and that that interchange of summation was after all legal, except that I should have written
So the next stage is to apply Cauchy-Schwarz, which gives us
Now I’m getting worried because fixing determines
determines  , and this feels wrong. So I’m going to start all over again, this time using sums rather than expectations.
, and this feels wrong. So I’m going to start all over again, this time using sums rather than expectations.
February 8, 2009 at 8:00 pm |
405. density-increasing-strategies & quasirandomness
Few remarks (which may be wrong so please correct me or hint if they are) Let me split them and start with one).
a) when we talk about quasi-randomness we often talk about “codimension-one-quasi-randomness” we start with the characteristic function f of the set, we show that if the number of desirable configuration is not what we expect then the function has some large correlation with some other function g; then we use it to somehow show that the set has higher density on a small dimensional “space” (subcube of some kind.)
We can talk about conditions for quasirandomness that refer directly about
low dimensional subspaces. i.e. look at all the various irregular examples that we have and ask: do we see there unusually high density for combinatorial subspace (or some more complicated gadget) of lower dimension – square root of n, log n etc.
(It is true that we do not have any proof-techniqus that jumps directly to low dimensional subspaces or “varieties” without passing through a codimension 1 gadget.)
February 8, 2009 at 8:14 pm |
Dear Tim, maybe rule 6 should be slightly relaxed and people could make off-line few-hour calculations without general concensus; (actually after just reading the rules, I would consider also a no-rules version of this endeavor.) In any case, I expect a wide concensus on letting you do the sum version on-line if you so prefer and perhaps granting you a wider mandate for related calculations. (I vote yes on both.)
February 8, 2009 at 8:34 pm |
406. Quasirandomness.
This time I do everything with sums and try to interpret it later. The disjointness conventions are as before. I haven’t repeated the remarks between lines.
Now we divide by the factor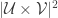 . Having done that we multiply out the inner bracket.
. Having done that we multiply out the inner bracket.
Now interchange the order of summation.
Now the difficulty we face is much clearer. Normally one should apply Cauchy-Schwarz only if a function is broadly speaking reasonably constant. But here the inner sum is far bigger if is small, and in fact it is zero for most
is small, and in fact it is zero for most  and
and 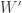 . So let’s try to think what a typical quadruple of sets
. So let’s try to think what a typical quadruple of sets 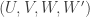 looks like if we know that all four sets have size
looks like if we know that all four sets have size  , and all six pairs of them are disjoint apart from the pair
, and all six pairs of them are disjoint apart from the pair  . (I’m still assuming, for simplicity, that
. (I’m still assuming, for simplicity, that 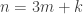 for some smallish
for some smallish  and that all sets have size
and that all sets have size  .)
.)
I now realize I made a mistake earlier. If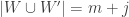 , then the number of disjoint pairs
, then the number of disjoint pairs  in
in 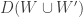 is
is 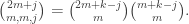 If you decrease
If you decrease  by 1, the first of these binomial coefficients goes up by a factor of approximately 2, but the second goes up by more like
by 1, the first of these binomial coefficients goes up by a factor of approximately 2, but the second goes up by more like 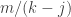 . As for the number of pairs
. As for the number of pairs  such that
such that 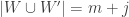 , it equals
, it equals  . The second of these goes down by a factor of about
. The second of these goes down by a factor of about 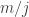 and the third goes down by a factor of about
and the third goes down by a factor of about 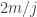 . So it still seems as though the sum is dominated by pairs with
. So it still seems as though the sum is dominated by pairs with  .
.
Ah, I’m forgetting that I should be thinking about the square of the inner sum, and now things look a lot healthier. So if you decrease by 1, then the square of the inner sum goes up by about
by 1, then the square of the inner sum goes up by about  and the number of
and the number of  pairs goes down by around
pairs goes down by around  . So some kind of concentration should occur
. So some kind of concentration should occur that makes these two equal, which is
that makes these two equal, which is  . (I admit it: I cheated and used a piece of paper there.)
. (I admit it: I cheated and used a piece of paper there.)
around the
I need to stop this for a while. To be continued.
February 8, 2009 at 10:48 pm |
407. Quasirandomness.
I think at this point it helps to bring in at least one expectation. Where I’ve written I will now write
I will now write  , where
, where  is the number of disjoint pairs
is the number of disjoint pairs  in
in 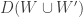 , and then apply Cauchy-Schwarz. That gives me
, and then apply Cauchy-Schwarz. That gives me
Now the first bracket is just the number of quadruples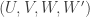 of sets of size
of sets of size  such that all sets with different letters are disjoint. So let’s drop it and try to estimate the second.
such that all sets with different letters are disjoint. So let’s drop it and try to estimate the second.
In this model, we are assuming that and
and  both have size
both have size  . So I’m allowed to replace
. So I’m allowed to replace 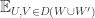 by
by 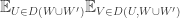 . That gives
. That gives
which by Cauchy-Schwarz and the boundedness of is at most
is at most
Expanding the bracket gives us
This is a slight mess but it makes me hopeful, for reasons that I’ll explain in my next comment.
February 8, 2009 at 11:29 pm |
409. Standard obstructions to uniformity
Tim, you’re right, Example 2 (where the 1-set, 2-set, and 3-set of A are independently constrained) is quite different from the class I had in mind. It may be that this is the more fundamental example, and I will try to think about whether the other examples we have can be reformulated to resemble this one. It may take some time before I will be able to look at it, though.
February 8, 2009 at 11:30 pm |
410. Quasirandomness.
The above calculation ends up with something a little bit strange, but here’s what I hope might happen if it is tidied up. Given any we can define a bipartite graph whose vertex sets are the set of all
we can define a bipartite graph whose vertex sets are the set of all  that are disjoint from
that are disjoint from  and the set of all
and the set of all  that are disjoint from
that are disjoint from  and whose edges are pairs
and whose edges are pairs  (still the Kneser product). If we restrict
(still the Kneser product). If we restrict  to this bipartite graph, we can “count 4-cycles”, or rather evaluate the sum of
to this bipartite graph, we can “count 4-cycles”, or rather evaluate the sum of 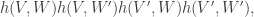 restricted to this bipartite graph. Could one perhaps hope that if this sum is on average small, then the function
restricted to this bipartite graph. Could one perhaps hope that if this sum is on average small, then the function  is sufficiently quasirandom to make the original sum (at the beginning of 406) or expectation (at the beginning of 401) small? The calculations above suggest that something like that is true. But one needs to be wary since the intersection of the neighbourhoods of
is sufficiently quasirandom to make the original sum (at the beginning of 406) or expectation (at the beginning of 401) small? The calculations above suggest that something like that is true. But one needs to be wary since the intersection of the neighbourhoods of  and
and 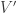 will get rapidly smaller as
will get rapidly smaller as  gets bigger, and this probably needs to be allowed for somehow. But instead of trying to sort that out, I want to speculate a bit, on the assumption that it can be made to work.
gets bigger, and this probably needs to be allowed for somehow. But instead of trying to sort that out, I want to speculate a bit, on the assumption that it can be made to work.
February 9, 2009 at 12:13 am |
411. Obstructions to uniformity.
As a result of thinking about what sort of global obstruction to uniformity might come out of the failure of quasirandomness of the type just discussed, it has just occurred to me to wonder whether in fact all the obstructions we have so far are special cases of Example 2. That is, if is one of our basic examples of a set with the wrong number of combinatorial lines, can we always find collections of sets
is one of our basic examples of a set with the wrong number of combinatorial lines, can we always find collections of sets  ,
, 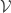 and
and 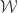 such that
such that  correlates unduly with the set of all sequences
correlates unduly with the set of all sequences  with
with  ,
, 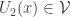 and
and  , and this set of sequences is dense. (Recall that
, and this set of sequences is dense. (Recall that  is the
is the  -set of
-set of  is the set of coordinates i where
is the set of coordinates i where  .)
.)
Let’s try Example 1. To keep things simple, let’s go for the example of the sum of all the coordinates being a multiple of 7. What could we take as ,
, 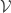 and
and 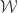 in this case? Easy: we can take them all to consist of all sets for which the number of elements is a multiple of 7. (If
in this case? Easy: we can take them all to consist of all sets for which the number of elements is a multiple of 7. (If  isn’t a multiple of 7, then we can find
isn’t a multiple of 7, then we can find 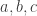 such that
such that 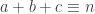 and
and 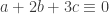 mod 7 and ask for sets in
mod 7 and ask for sets in  to have cardinality congruent to
to have cardinality congruent to  etc.) It’s clear that if we had different weights but still worked mod 7 we could do something similar, and I’m pretty sure that generalizing to structured sets in Abelian groups doesn’t make things substantially harder. Of course, all this is to be expected because of Terry’s comments about standard obstructions.
etc.) It’s clear that if we had different weights but still worked mod 7 we could do something similar, and I’m pretty sure that generalizing to structured sets in Abelian groups doesn’t make things substantially harder. Of course, all this is to be expected because of Terry’s comments about standard obstructions.
How about Ryan’s example? There we could simply take ,
, 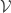 and
and 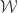 to consist of all sets that contain a run of
to consist of all sets that contain a run of  consecutive elements.
consecutive elements.
Based on that, here is a conjecture.
Conjecture: Let be a subset of (the union of a suitable triangular grid of slices near the centre of)
be a subset of (the union of a suitable triangular grid of slices near the centre of) ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) that does not have the expected number of combinatorial lines. Then there are set systems
that does not have the expected number of combinatorial lines. Then there are set systems  ,
, 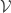 and
and 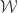 such that for a dense set of sequences
such that for a dense set of sequences  we have
we have  ,
, 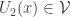 and
and  , and such that, setting
, and such that, setting  to be the set of all such sequences, the density of
to be the set of all such sequences, the density of  in $B$ is significantly greater than the density of
in $B$ is significantly greater than the density of  .
.
This conjecture is a direct analogue of a fact that is known to be true for corners. (This fact was basically mentioned by Terry in comment 402.) It’s a slight generalization of what Terry was suggesting, and I think there’s a definite chance that it could have dealt with question 3 in the main post.
If anyone can think of an obstruction to uniformity that is not of this form, then they will have demonstrated that DHJ is different in a very interesting way from the corners problem. Such an example would give a big new insight into the problem. But I’m an optimist and at the moment I am guessing that the conjecture is true.
[Note: if this comment seems to ignore Terry’s comment 409, it’s because his comment appeared while I was writing it.]
February 9, 2009 at 7:49 am |
[…] A third thread about obstructions to uniformity and density-increment strategies is forthcoming alive and kicking on Gowers’s […]
February 9, 2009 at 8:13 am |
412. The conjecture in 411 is, I am afraid, too optimistic. Observe that there are at most wildcards in every combinatorial line that is contained in a union of slices near the center of
wildcards in every combinatorial line that is contained in a union of slices near the center of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . That is because the number of
. That is because the number of  ‘s does not vary by more than that.
‘s does not vary by more than that.
Thinking of an element of![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as a word of length
as a word of length  in
in 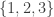 , let
, let 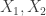 be the number of occurrences of subwords
be the number of occurrences of subwords  , and
, and  respectively (“subword” means a sequence of _consecutive_ letters). Let
respectively (“subword” means a sequence of _consecutive_ letters). Let 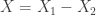 . Note that typically
. Note that typically  varies in the interval of length
varies in the interval of length  around origin. Thus, if
around origin. Thus, if  , it is reasonable to suppose that
, it is reasonable to suppose that 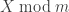 is going to be distributed uniformly in
is going to be distributed uniformly in 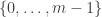 . Assume it is. Choose
. Assume it is. Choose  for the sake of definiteness (we need it to be greater than
for the sake of definiteness (we need it to be greater than 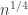 for what follows). Define
for what follows). Define  by the condition
by the condition 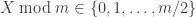 . The density of
. The density of  is
is  , but I claim that the number of combinatorial lines is close to
, but I claim that the number of combinatorial lines is close to  .
.
Indeed in a typical combinatorial line, the letters adjacent to wildcards are not wildcards themselves. By symmetry, as change value of wildcards the expected change in is equal to expected change in
is equal to expected change in  . Since both
. Since both  and and
and and  are concentrated in an interval of length
are concentrated in an interval of length  (recall that the number of wildcards is
(recall that the number of wildcards is 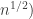 , we infer that typically
, we infer that typically  does not change by more than
does not change by more than 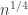 . Since
. Since  , if a combinatorial line contains a single element of
, if a combinatorial line contains a single element of  , then it is very likely to be wholly contained in
, then it is very likely to be wholly contained in  .
.
It seems intuitively clear to me that there is no density increment on of the kind desired in comment 411.
of the kind desired in comment 411.
February 9, 2009 at 8:56 am |
413. Correlation with “Cartesian semi-products”
I found a weird variant of the conjecture in 411 that I don’t know how to interpret. Let be a dense subset of
be a dense subset of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) without combinatorial lines, or equivalently a collection of partitions
without combinatorial lines, or equivalently a collection of partitions ![{}[n] = A \cup B \cup C](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D+%3D+A+%5Ccup+B+%5Ccup+C&bg=ffffff&fg=333333&s=0&c=20201002) of [n] that does not contain a “corner”
of [n] that does not contain a “corner”  .
.
Now pick a random subset C of [n] of size about n/3 (up to errors) and look at the slice of
errors) and look at the slice of  with this C as the third set in the partition. This is basically a set system in
with this C as the third set in the partition. This is basically a set system in ![{}[n] \backslash C](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D+%5Cbackslash+C&bg=ffffff&fg=333333&s=0&c=20201002) , which we expect to be dense on the average. Now, following the proof of Sperner as in 331, let us pick a random maximal chain
, which we expect to be dense on the average. Now, following the proof of Sperner as in 331, let us pick a random maximal chain ![\emptyset = A_0 \subset \ldots \subset A_{n-|C|} = [n] \backslash C](https://s0.wp.com/latex.php?latex=%5Cemptyset+%3D+A_0+%5Csubset+%5Cldots+%5Csubset+A_%7Bn-%7CC%7C%7D+%3D+%5Bn%5D+%5Cbackslash+C&bg=ffffff&fg=333333&s=0&c=20201002) . On the average, we expect this chain to be dense in the equator (the part of the chain with cardinality
. On the average, we expect this chain to be dense in the equator (the part of the chain with cardinality 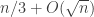 . Thus
. Thus  contains roughly
contains roughly  triples of the form
triples of the form ![(A_j, [n] \backslash (A_j \cup C), C)](https://s0.wp.com/latex.php?latex=%28A_j%2C+%5Bn%5D+%5Cbackslash+%28A_j+%5Ccup+C%29%2C+C%29&bg=ffffff&fg=333333&s=0&c=20201002) where
where  . Let J be the set of all such j.
. Let J be the set of all such j.
Since avoids all combinatorial lines, this means that
avoids all combinatorial lines, this means that  must avoid the “Cartesian semi-product”
must avoid the “Cartesian semi-product”
which implies that the set
avoids the Cartesian product . In particular, it fails to be quasirandom with respect to such products, and so by two applications of Cauchy-Schwarz, it must have an anomalously large number of rectangles. Averaging over all choices of C and over all choices of maximal chain, this seems to imply that
. In particular, it fails to be quasirandom with respect to such products, and so by two applications of Cauchy-Schwarz, it must have an anomalously large number of rectangles. Averaging over all choices of C and over all choices of maximal chain, this seems to imply that  contains an anomalously large number of “rectangles”
contains an anomalously large number of “rectangles”
where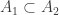 and
and  all have cardinality about
all have cardinality about 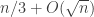 . If it were not for the additional constraints
. If it were not for the additional constraints 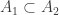 ,
,  , this would start coming quite close to the conjecture in 411. As it is, I don’t know where to take this next.
, this would start coming quite close to the conjecture in 411. As it is, I don’t know where to take this next.
February 9, 2009 at 9:11 am |
414.
I was going to add that all the examples I mentioned in 148 happened to be of the right form for the conjecture in 411, but Boris in 412 seems to have created a totally new species of non-quasirandom set that needs to be understood better. This example is of course consistent with what I just discussed at 413, by the way: in a typical “Cartesian semi-product”, the 132 and 123 statistics don’t vary by much more than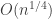 , and so such semi-products are likely to either lie totally in
, and so such semi-products are likely to either lie totally in  or totally outside of
or totally outside of  .
.
(Incidentally, these Cartesian semi-products are closely related to the sets S discussed in Tim’s 331.)
February 9, 2009 at 10:24 am |
415. Obstructions to uniformity.
No time for serious mathematics at the moment, but I did want to give my gut reaction to the last few comments. First, my usual experience when making an overoptimistic conjecture is to go to bed, wake up, and see why it’s nonsense (perhaps not immediately, but at some point when my mind wanders back to it and I’m in a more sceptical mood). With this collaboration it’s different: I wake up and find a counterexample on the blog!
Having said that, I did very much like that 411 conjecture, so when I get the time I plan to do two things, unless someone has already done them. First is to try to define some set systems that do, contrary to expectation, give rise to a correlation with Boris’s example. But at the moment I share his intuition that the roles of the coordinate values are somehow too intertwined to make this possible, so my main reason for doing this would be to try to get at a proof that it really is a new obstruction, or at least a sketch of a proof. (That may not be too difficult to achieve, so I’ll check from time to time to see if someone else has already done it.)
Other things that one could do in response to the example are to try to formulate a yet more general notion of obstruction to uniformity that includes his example. I don’t have any idea yet what that might look like, but it would be great if we could come up with something simple. It would also be good to find a combinatorial subspace in which his set is unusually dense. (Maybe Terry has done that above — I haven’t yet followed his comments enough to be able to see.) And finally, I would like to think hard about what obstructions to uniformity would arise naturally from a set’s not being quasirandom according to the definition that half-emerged from the calculations leading up to 410. (In 411 I just jumped to conclusions, and it now looks as though I did so prematurely.) Here I would take my cue from the way I proved one version of the regularity lemma for hypergraphs. I was in precisely this situation: there were a lot of bits of local non-uniformity (in small neighbourhoods) and one somehow had to add them up to obtain a global non-uniformity. It turned out to follow because the neighbourhoods with the local non-uniformities were nicely spread about. I think there’s a good chance of pulling off a similar trick here. (An argument of the type I’m talking about appears in Section 8 of my 3-uniform hypergraphs paper in the run-up to the proof of Lemma 8.4, but our situation might be slightly simpler as we’re talking about graphs rather than hypergraphs.)
Terry, I’m looking forward to understanding Cartesian semi-direct products better, but I’m coming to see the kind of thing you’re doing. Actually, the more I think about it, the more I wonder if it is the kind of thing I was hoping to get to in the calculations at the beginning of this thread. If so, then the remarks towards the end of the previous paragraph of this comment could be helpful in taking things further.
February 9, 2009 at 10:26 am |
416. Obstructions to uniformity.
It also occurs to me that Boris’s thought processes could be extremely helpful here. Did that example just jump out of thin air? If not, then were there some preliminary “philosophical thoughts” that led to it? If the latter, then it could be useful to know what they were so that we have a better chance of making correct guesses about how a proof might go.
February 9, 2009 at 11:45 am |
417. quasirandomness. (405 (point a) continued)
So a concrete question is this: suppose that a set of density c has density at most 2c on all combinatorial subspaces of dimension 100 log n (or log^2 n; or n^{1/1000}) does it necessarily have the right number of combinatorial lines? (Is any of our non quasi random example violate it?)
(Of course in the next procedural remark by “on-line” I meant “off-line”.)
February 9, 2009 at 5:08 pm |
418. Answer to 416: My thought process was simple: First the analogue of Tim’s conjecture for Sperner is false (if one thinks of Sperner as DHJ(2,1), then it is not true that obstructions come from DHJ(2,0) because there is no DHJ(2,0)), and hence the conjecture should be false. Second, one needs some example where coordinates are somehow linked together. Third, if we try to impose a condition on number of pairs 12, then the only condition I really know how to impose is a modular condition. It fails to give a counterexample since if one element of the combinatorial line has some number of these, it tells us next to nothing about the number of 12’s in other elements of the combinatorial line because the number of 12’s decreases by a lot when we change wildcard from 2 to 3. Well, then I thought about compensating for this huge change by forming some linear combination. My first construction was to count number of 12, 23, and 31 and add them weighted with third roots of unity. Finally, I simplified the construction.
Comment regarding to 417: If we take any known obstruction to the uniformity of density and take a union with a random set of density
and take a union with a random set of density  wouldn’t we obtain an example Gil seeks?
wouldn’t we obtain an example Gil seeks?
February 9, 2009 at 6:57 pm |
419. Just a quick comment, will respond at length later when I am less busy: Boris’s 412 example has the property that all coordinates have extremely low influence: modifying a 1 to a 2, say, is unlikely to move you from A to not-A, or vice versa. As a consequence, it is easy to find lots of subspaces with a density increment, just by selecting a moderate number of indices and jiggling them from 1 to 2 to 3 independently.
Presumably one can more generally push the density increment argument to reduce to sets A in which all indices (and maybe sets of indices) have small influence, but I have not thought about this carefully.
February 9, 2009 at 7:02 pm |
420. Obstructions to uniformity.
Boris, many thanks for that — as I hoped, it was very illuminating. In particular, your initial step is thought-provoking. My first reaction to it is to try to prove you wrong by formulating DHJ(2,0), but with no particular hope of success. If indeed your reasoning is right, then it’s good news in a way, because it suggests that we can get a better understanding of obstructions in DHJ(3,2) by thinking a bit harder about obstructions in DHJ(2,1).
Here’s what DHJ(2,0) might say. (In order to do this I’m keeping open comment 344 in a different tab and trying to extend the definition of DHJ(j,k) downwards to DHJ(0,k).) For every empty subset![E\subset[k]](https://s0.wp.com/latex.php?latex=E%5Csubset%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) you have a set
you have a set 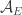 of functions from
of functions from  to the power set of
to the power set of ![\null[n]](https://s0.wp.com/latex.php?latex=%5Cnull%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that the images of all points in
such that the images of all points in  are disjoint.
are disjoint.
So far so good: there is precisely one such function, so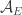 is a singleton that contains just that trivial function.
is a singleton that contains just that trivial function.
Now we define to be the set of all ordered partitions of
to be the set of all ordered partitions of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into
into  sets
sets  such that for every empty subset
such that for every empty subset  of
of ![{}[k]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) the sequence
the sequence  belongs to
belongs to 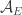 . But that happens for every ordered partition of
. But that happens for every ordered partition of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into
into  sets, so
sets, so  corresponds to the set of all sequences.
corresponds to the set of all sequences.
So I claim that DHJ(0,k) is the assertion that![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) contains a combinatorial line!
contains a combinatorial line!
This doesn’t really affect the substance of what Boris is saying, but it allows us to reexpress it. The conjecture DHJ(0,k) (which, come to think of it, I think I see how to prove), suggests a class of 0-level obstructions: you may well not get the expected number of combinatorial lines if you have the wrong correlation with the constant function 1 — that is, if you have the wrong density. So the real point that Boris is making is that having the wrong density is not the only obstruction to Sperner (whereas it is to the trivial one-dimensional analogue of corners, since the number of one-dimensional corners is precisely determined by the density of the set).
Thus, Boris’s thought processes do indeed contain a valuable new insight: that we should think hard about obstructions to Sperner, because these will feed into DHJ as an additional source of obstructions to DHJ(2,3), over and above the ones that come from DHJ(1,3). In this way, we see that there is something about DHJ(2,3) that genuinely goes beyond what happens for corners.
Unfortunately, it is still completely mysterious to me what that extra something is, but equally it is clear that what we must try to do is generalize Boris’s obstruction as much as we possibly can and hope that we can reach a new and more sophisticated conjecture. A good start will be to see what we can do with obstructions to Sperner. (And perhaps there is some hope here, as people already seem to have thought about it. If anyone feels like giving a detailed summary of what is known, they will be doing me at least a big favour.)
February 9, 2009 at 7:55 pm |
421. Boris, i do not think your example is a counter example. If you take the obstructions for pseudorandomness (at least the 2 I checked) you gets large combinatorial subspaces in the set. E.g. if the number of 1,2,3 coordinates is divisible by 7 or if there is a long runs.
OK i see, what you probably suggest is this: start with a obstruction with high density say 7/8 take a random subset of it which has density c and then even in the large combinatorial spaces the density will be below 8/7. (You do not need to add anything random) Right.
Anyway, we can still ask: If the number combinatorial lines is more than 10 times or less than 1/10 times the expected number, must we have a combinatorial subspace of dimension 100logn or log^2n or n^1/100 that the density on it is more than 1.01c.
February 9, 2009 at 10:00 pm |
422. This is response to Terry’s #413.
Let me just try to rephrase it in my own language. Let be a subset of
be a subset of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) of density at least
of density at least  .
.
Form a random “subcube” as follows: Pick a random string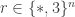 by choosing each coordinate to be
by choosing each coordinate to be  with probability
with probability 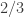 and
and  with probability
with probability 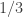 . Let
. Let 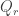 be the subcube
be the subcube 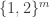 , given by taking all ways of filling in
, given by taking all ways of filling in  with
with  or
or  . (Here
. (Here  is the number of
is the number of  ‘s in
‘s in  .) For a given string
.) For a given string  , let’s abuse notation slightly by writing
, let’s abuse notation slightly by writing 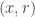 for the associated string in
for the associated string in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) .
.
It is easy to see that with probability at least over the choice of
over the choice of  , the density of
, the density of  on
on 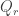 is at least
is at least  , a positive constant.
, a positive constant.
So we can apply some kind of souped-up Sperner. In particular, I believe it should be relatively easy to show that contains many “half-lines” on
contains many “half-lines” on 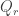 . I.e., if we look at pairs
. I.e., if we look at pairs 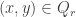 such that
such that  and
and 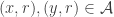 , it should be that the set of
, it should be that the set of  ‘s involved in such half-lines has positive density in
‘s involved in such half-lines has positive density in 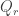 , and the same for the
, and the same for the  ‘s.
‘s.
But since was random from the right distribution, we conclude the following: Look at all “half-lines” in
was random from the right distribution, we conclude the following: Look at all “half-lines” in  ; i.e., pairs
; i.e., pairs  with the potential to be the
with the potential to be the  – and
– and  -points of a combinatorial line. Then the
-points of a combinatorial line. Then the  ‘s participating in these half-lines have positive density in
‘s participating in these half-lines have positive density in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , and same for the
, and same for the  ‘s.
‘s.
Now it almost seems like we’re there, because we have a pretty dense set of half-lines. We just need to find one point in to cap off a half-line. I guess the trouble is that, while the set of points capping off a half-line has positive density in
to cap off a half-line. I guess the trouble is that, while the set of points capping off a half-line has positive density in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , it still might completely miss
, it still might completely miss  . So perhaps the goal should be to show that either these capping points are *very* dense, or else we can see some structure in them out of Sperner.
. So perhaps the goal should be to show that either these capping points are *very* dense, or else we can see some structure in them out of Sperner.
February 9, 2009 at 10:31 pm |
423. Re Boris’s example #418:
One thing I do not quite understand: What is the definition of “typical combinatorial line”?
February 9, 2009 at 10:55 pm |
424. Re Terry’s #419.
I’m still a bit confused by this density-increment search. One finds counterexamples with the “wrong” number of combinatorial lines, but then one says, “Aha, but if I fix these coordinates this way, I get a large density increment.”
Now Boris gives a counterexample in which each coordinate has low “influence”. This is the only way to beat the above density-increment parry — if your example has coordinates with large influence, then you can of course fix these coordinates to get density increment.
But now in #419 Terry says, “Aha, if the coordinates all have *low* influence, we should be able to find a density increment.”
It seems like we can always find a density increment! This is related to my comment #123.
February 9, 2009 at 11:00 pm |
425. Answer to Ryan’s question in #423: it is not important, as long as the definition is invariant under permutation of![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The only thing the construction uses is that no combinatorial line uses more than
. The only thing the construction uses is that no combinatorial line uses more than  wildcards. Then if we take an orbit of any combinatorial under the action of symmetric group on
wildcards. Then if we take an orbit of any combinatorial under the action of symmetric group on ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) most elements of the orbits will have virtually no adjacent wildcards.
most elements of the orbits will have virtually no adjacent wildcards.
February 9, 2009 at 11:03 pm |
426. I do not follow Ryan’s argument in #424. If there are variables of large influence, it does not mean we can fix them to get density increment. Think of XOR function on the Boolean cube. All coordinates have large influence, but on every coordinate subcube the density is still .
.
February 9, 2009 at 11:04 pm |
427. Re 424,419
Now I’m confused by Ryan’s comment. If is a random set, then doesn’t every coordinate have large influence? And you can’t get a density increase. Apologies if this shows that I don’t properly understand what “influence” means.
is a random set, then doesn’t every coordinate have large influence? And you can’t get a density increase. Apologies if this shows that I don’t properly understand what “influence” means.
February 9, 2009 at 11:08 pm |
428. Obstructions and possible technical simplification.
I would like to draw attention to my comments 365 and 366 because they could be relevant here. Boris, if we use this alternative measure on![\null [3]^n](https://s0.wp.com/latex.php?latex=%5Cnull+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , then does your example disappear?
, then does your example disappear?
February 9, 2009 at 11:27 pm |
429. Answer to #428: I do not think it disappears. It has density 1/2 on every . This example seems to be rather hard to kill since as mentioned in #425 the only thing it really uses is invariance under permutations of
. This example seems to be rather hard to kill since as mentioned in #425 the only thing it really uses is invariance under permutations of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
Actually, now thinking about it, there is a way to simplify/modify the example from #412 somewhat. I considered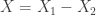 , but I could consider
, but I could consider  or simply the number of subwords
or simply the number of subwords 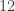 . Yes, these quantities do vary by a lot, but this variation is predictable: it has some mean
. Yes, these quantities do vary by a lot, but this variation is predictable: it has some mean  that can be computed explicitly, and is concentrated in the interval around
that can be computed explicitly, and is concentrated in the interval around  of length
of length 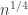 . Choose
. Choose  so that
so that 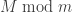 is distance at least
is distance at least 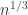 from zero (large sieve should tell us that this can be done for most
from zero (large sieve should tell us that this can be done for most  , and maybe there is some elementary argument to do it for all
, and maybe there is some elementary argument to do it for all  that I do not see). Then define
that I do not see). Then define  by condition that
by condition that 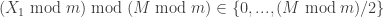 .
.
February 9, 2009 at 11:31 pm |
430. Influence vs. Bias
Ah, where is Gil when you need him :-). There is a distinction between influence and bias for, say, a boolean function of n boolean inputs.
of n boolean inputs.
We say that the input has large influence if, whenever we flip
has large influence if, whenever we flip  , we have a high probability of flipping
, we have a high probability of flipping  . Having low influence means that f is close to being invariant in the
. Having low influence means that f is close to being invariant in the  direction, where
direction, where  is the standard basis.
is the standard basis.
We say that there is large bias in the direction (or more precisely, the basis vector
direction (or more precisely, the basis vector 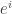 in the dual space, but never mind this), if f has a density increment on the hyperplane
in the dual space, but never mind this), if f has a density increment on the hyperplane 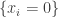 or on the hyperplane
or on the hyperplane  .
.
There is only a partial relationship between the two properties: low influence implies low bias, but not conversely; for instance, as pointed out above, a random boolean function has low bias but high influence for each variable.
High bias leads directly to a density increment and so we “win” in this case. We also “win” if there are many directions of low influence, because f is close to constant on subspaces generated by these directions and is therefore going to be unusually dense on some of them. But there is the great middle ground of low bias, high influence sets (such as the random set) in which we have to do something else.
February 9, 2009 at 11:47 pm |
431. Obstructions.
Boris, in 425 you said you used the fact that the set of wildcards has size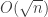 . With the measure where all slices are the same size, I think the size of the set of wildcards of a typical line becomes
. With the measure where all slices are the same size, I think the size of the set of wildcards of a typical line becomes 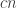 instead. So I allowed myself to be hopeful, because you needed
instead. So I allowed myself to be hopeful, because you needed  and you also needed
and you also needed  to be bigger than the square root of the size of the set of wildcards. But I admit that I still don’t feel as though I fully understand your example, so there may well be an obvious answer to this question.
to be bigger than the square root of the size of the set of wildcards. But I admit that I still don’t feel as though I fully understand your example, so there may well be an obvious answer to this question.
February 9, 2009 at 11:52 pm |
431. Locality in the edit metric.
Something just occurred to me that, in retrospect, was extremely obvious. We know already that we may as well restrict our dense sets to have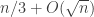 1s, 2s, and 3s, which means we may as well restrict our combinatorial lines to have at most
1s, 2s, and 3s, which means we may as well restrict our combinatorial lines to have at most  wildcards.
wildcards.
This implies that the points on our combinatorial lines differ by at most in the edit (Hamming) metric. In contrast, the diameter of the cube
in the edit (Hamming) metric. In contrast, the diameter of the cube ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) is n.
is n.
Because of this, our obstructions to uniformity need to be at the scale of rather than n in the edit metric. Boris’s example is a good example of this; it’s basically a union of Hamming balls of radius m for some
rather than n in the edit metric. Boris’s example is a good example of this; it’s basically a union of Hamming balls of radius m for some 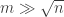 .
.
So maybe conjecture 411 can be recovered by somehow localising it to Hamming balls of size ? There is a major technical issue coming from the fact that the metric is hugely non-doubling at this scale, but perhaps if one is careful one can still localise properly.
? There is a major technical issue coming from the fact that the metric is hugely non-doubling at this scale, but perhaps if one is careful one can still localise properly.
February 9, 2009 at 11:53 pm |
432. Aha…. I missed the point about typical line having length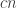 with your measure. It does seem that the example disappears.
with your measure. It does seem that the example disappears.
February 9, 2009 at 11:56 pm |
433. Locality in the edit metric cont.
(The numbering on my previous comment should be 432.)
To illustrate what I mean by localising the obstruction, consider the problem of obstructions to length three progressions in . Fourier analysis tells us that the obstructions are given by plane waves
. Fourier analysis tells us that the obstructions are given by plane waves 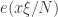 on the whole interval [N].
on the whole interval [N].
But now suppose one is only interested in counting progressions of some much smaller length O(m) (e.g.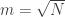 ). Then the right kind of obstructions are given by local plane waves – waves which look like a plane wave
). Then the right kind of obstructions are given by local plane waves – waves which look like a plane wave 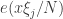 on each interval
on each interval  of length m, but whose frequency
of length m, but whose frequency 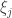 can vary arbitrarily with j.
can vary arbitrarily with j.
Of course, one just zoom in on an interval of length m where the original set A is quite dense and get rid of this technicality; similarly here, we may have to zoom into a Hamming ball and work locally on that ball.
February 10, 2009 at 12:15 am |
434. We can assume that the density is uniform across all smallish Hamming ball. That is because if we get a density increment on a smallish Hamming ball, we get a density increment on a tiny combinatorial cube by double-counting analogous to comment #132 from the original thread. Thus, we can increment density on Hamming balls until we are stuck.
February 10, 2009 at 12:29 am |
Re 426, 427, 430, distinction between influence and bias:
Right, my mistake. Most of the examples I’ve been thinking about have been “monotone”, in which case the notions coincide.
February 10, 2009 at 3:31 am |
436. Quasirandomness
To answer Gil’s question: if we manage to settle DHJ(1,3) (or more generally to find lots of combinatorial lines in our “obstructions to uniformity”), we should presumably be able to iterate and also find lots of combinatorial subspaces in all of the obstructions to uniformity. If we double count properly, this should (hopefully) tell us that any set which has anomalous density on an obstruction to uniformity has an anomalous density on at least one combinatorial subspace, and then we “win”.
February 10, 2009 at 3:37 am |
437. Soft obstructions to uniformity
One possible route to keep in mind, by the way, is to back away from the “hard” goal of explicitly classifying all “obstructions to uniformity” in a very concrete manner, but instead settle for a “soft” classification which expresses these obstructions as something like a “dual function” from my primes in AP paper with Ben Green. In some cases, one can tools such as an enormous number of applications of the Cauchy-Schwarz inequality to deal with these sorts of dual functions.
Another example of a “soft” obstruction to uniformity, this time for length three progressions in [N], is that of an almost periodic function: a function![f: [N] \to {\Bbb C}](https://s0.wp.com/latex.php?latex=f%3A+%5BN%5D+%5Cto+%7B%5CBbb+C%7D&bg=ffffff&fg=333333&s=0&c=20201002) whose shifts
whose shifts  are “precompact in
are “precompact in  ” in some quantitative sense. One can show that these guys contain all the obstructions to uniformity by a soft argument based primarily on Cauchy-Schwarz (and does not use the Fourier transform). [Using the Fourier transform, of course, one can approximate almost periodic functions by quasiperiodic functions, e.g. bounded linear combinations of characters, thus moving from soft obstructions to hard obstructions]. It is also not hard to prove (again by “soft” means avoiding Fourier analysis) that almost periodic functions have lots of 3-term APs (and also the important strengthening that functions close to an almost periodic function also has lots of 3-term APs; there are some subtle issues with the hierarchy of epsilons here that I don’t want to discuss here).
” in some quantitative sense. One can show that these guys contain all the obstructions to uniformity by a soft argument based primarily on Cauchy-Schwarz (and does not use the Fourier transform). [Using the Fourier transform, of course, one can approximate almost periodic functions by quasiperiodic functions, e.g. bounded linear combinations of characters, thus moving from soft obstructions to hard obstructions]. It is also not hard to prove (again by “soft” means avoiding Fourier analysis) that almost periodic functions have lots of 3-term APs (and also the important strengthening that functions close to an almost periodic function also has lots of 3-term APs; there are some subtle issues with the hierarchy of epsilons here that I don’t want to discuss here).
Anyway, it is another option to consider if the “hard” classification problem turns out to be too complicated.
February 10, 2009 at 7:36 am |
438. density-increase-strategies, quasi randomness.
Can somebody remind me what is DHJ(1,3) DHJ(2,3) and DHJ(1,2)? thanks!
The point I was making is that our strategy for a proof for a density theorem is
1) Find obstruction to quasirandomsess in terms of inner product with some function in a class of “obstraction” (This is what I referred to as a codim 1 condition)
2) deduce that this implies an increased density on lower dimensional subspace, and iterate.
In may be possible (although I am not aware how) to move directly from having too many or too few combinatorial lines to a statement about density on small dimensional spaces.
Also we can look at the example and see if the density increase on small spaces does not sugget “too good to be true” result. For example, if in all these obstructions we get a subspace of linear size with density-increase of (1+t) then this will imply a bound of the form 3^n/n^alpha which is toogood.
BTW, there is a large density of people interested in the density HJ around here. The approach we are taking is a fixed k approach. Saharon Shelah gave the best bound for HJ using inductive argument which juggles different ks and diffferent dimensions for the combinatorial subspaces. He was quite interested to see if approaches of similar nature can apply for DHJ.
Regarding Ryan’s long runs/tribe-like examples; It looks that this may extend to sets defined by a large class of bounded depth circuits.
February 10, 2009 at 9:11 am |
439. Local obstructions.
I’ve just woken up with a better grasp of what Terry is talking about in 431 and 433, so I’d like to rephrase it here (not very much actually, but perhaps just enough to be useful).
Terry points out that because, as we know, our example could live in a central area of slices of width around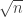 (meaning that the numbers of 1s, 2s and 3s are always within
(meaning that the numbers of 1s, 2s and 3s are always within  of
of  ), for the simple reason that almost all sequences in
), for the simple reason that almost all sequences in ![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) have this property, the set of wildcards in any combinatorial line can be assumed to have size at most
have this property, the set of wildcards in any combinatorial line can be assumed to have size at most  . This means that what happens at one sequence
. This means that what happens at one sequence  should have nothing much to do with what happens at another sequence
should have nothing much to do with what happens at another sequence  if their Hamming distance (the number of coordinates where they differ) is substantially greater than
if their Hamming distance (the number of coordinates where they differ) is substantially greater than 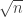 .
.
This immediately suggests a generalization of the obstructions considered in Conjecture 411. The idea would be this: you would move a Hamming ball (that is, a ball in the Hamming metric) of radius around in
around in ![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , and in each translate you would have a different obstruction of the type in Conjecture 411.
, and in each translate you would have a different obstruction of the type in Conjecture 411.
The analogy Terry draws is with the case of , where you could partition it into small intervals and have a different Fourier mode in each interval, and that would exhibit nonquasirandom behaviour for local phenomena such as arithmetic progressions of length 3 with small common difference.
, where you could partition it into small intervals and have a different Fourier mode in each interval, and that would exhibit nonquasirandom behaviour for local phenomena such as arithmetic progressions of length 3 with small common difference.
Now if one is going to carry out such a programme, there is an issue that at first appears to be merely technical and then comes to seem more fundamental. It’s that you can’t do something different on each translate because the translates overlap. This is where the importance lies of Terry’s remark that “the metric is hugely non-doubling on this scale”, which I’ll explain in a moment. But first, note that in we don’t have a huge problem: of course the intervals overlap, but you can just partition
we don’t have a huge problem: of course the intervals overlap, but you can just partition  into disjoint intervals and you’re basically OK.
into disjoint intervals and you’re basically OK.
Back to Terry’s remark. What does he mean? He means that if you double the radius of a Hamming ball, then its volume (or cardinality) hugely increases. This has the effect of making it extremely hard to pack Hamming balls efficiently. Now it isn’t essential to use Hamming balls, but if we are going to partition![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) into sets
into sets  and use a different 411-style obstruction in each
and use a different 411-style obstruction in each  , then we will need one crucial property: that if you modify an element of
, then we will need one crucial property: that if you modify an element of  by changing around
by changing around  coordinates, then with non-negligible probability you remain inside
coordinates, then with non-negligible probability you remain inside 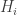 . (Otherwise, the supposed obstruction in
. (Otherwise, the supposed obstruction in 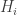 will not affect more than one point per typical combinatorial line.)
will not affect more than one point per typical combinatorial line.)
The isoperimetric inequality in the cube tells us that the sets where you have the best chance of staying inside when you modify an element by a given amount are Hamming balls, and something similar is true in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . And if you do the calculations for Hamming balls, you find that if you modify by
. And if you do the calculations for Hamming balls, you find that if you modify by  for some large constant
for some large constant  , then you hugely expand the set, unless the set is already quite large in which case you get everything.
, then you hugely expand the set, unless the set is already quite large in which case you get everything.
In other words, you cannot do some partitioning argument like this unless you partition into huge Hamming balls, or sets of similar type, which would turn the “local” obstructions into global ones.
I think I’ve actually said a bit more than Terry now — I am claiming that Terry’s “major technical issue” is in fact a fundamental issue that makes it impossible to devise local obstructions of the type he is talking about.
Where does that leave Boris’s example? I don’t have a full explanation for this, but I think it is that he somehow doesn’t do completely unrelated things in each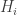 . In other words, it is not a purely local obstruction and can’t be massively generalized in the way suggested above. If anyone else can give a more precise explanation, I’d be very interested.
. In other words, it is not a purely local obstruction and can’t be massively generalized in the way suggested above. If anyone else can give a more precise explanation, I’d be very interested.
February 10, 2009 at 9:17 am |
439. A potential strategy
I think I have a strategy for proving that dense sets![{\mathcal A} \subset [3]^n](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) “with no exploitable structure” contain combinatorial lines, basically by fooling around with the Cartesian semi-products from 413.
“with no exploitable structure” contain combinatorial lines, basically by fooling around with the Cartesian semi-products from 413.
We have a density and an extremely large n. I will also need an intermediate integer
and an extremely large n. I will also need an intermediate integer 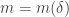 depending only on
depending only on  . I am going to try to find a combinatorial line with at most m wildcards inside
. I am going to try to find a combinatorial line with at most m wildcards inside  , and I think my strategy works unless
, and I think my strategy works unless  has some explicit structure obstructing me, which looks exploitable by other methods.
has some explicit structure obstructing me, which looks exploitable by other methods.
Pick a random point x in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . We are going to look for a line inside the Hamming ball of radius m centred at x. (The discussion above has begin to persuade me that we should be working inside small Hamming balls rather than roaming across all of
. We are going to look for a line inside the Hamming ball of radius m centred at x. (The discussion above has begin to persuade me that we should be working inside small Hamming balls rather than roaming across all of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) .)
.)
It is convenient to embed![{}[3]^n = \{0,1,2\}^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En+%3D+%5C%7B0%2C1%2C2%5C%7D%5En&bg=ffffff&fg=333333&s=0&c=20201002) in
in 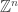 and give the latter the standard basis
and give the latter the standard basis  . Thus for instance
. Thus for instance 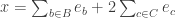 where A, B, C are the 0-sets, 1-sets, and 2-sets of x (thus A, B, C partition [n]). Generically, of course, A, B, C have size about n/3.
where A, B, C are the 0-sets, 1-sets, and 2-sets of x (thus A, B, C partition [n]). Generically, of course, A, B, C have size about n/3.
Now we pick m random elements of A, which will generically be distinct. I’m going to run the Sperner argument used in 413. For
of A, which will generically be distinct. I’m going to run the Sperner argument used in 413. For  , let’s look at the points
, let’s look at the points
thus is the same string as x but with the coefficients at
is the same string as x but with the coefficients at 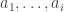 increased from 0 to 1, and the coefficients at
increased from 0 to 1, and the coefficients at  increased from 0 to 2. Each
increased from 0 to 2. Each  has a probability about
has a probability about  of lying in
of lying in  , so on average we expect to have about
, so on average we expect to have about  indices i with
indices i with  . In fact there should be some sort of concentration of measure, unless
. In fact there should be some sort of concentration of measure, unless  has some blatant structure to it which should be exploitable, so I’m going to just assume that we do have
has some blatant structure to it which should be exploitable, so I’m going to just assume that we do have  , where
, where ![I \subset [m]](https://s0.wp.com/latex.php?latex=I+%5Csubset++%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) is the collection of indices i such that
is the collection of indices i such that  .
.
Since avoids all combinatorial lines, we know that the points
avoids all combinatorial lines, we know that the points
lie outside of whenever
whenever 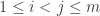 is such that
is such that  . On the other hand, assuming concentration of measure I expect that about
. On the other hand, assuming concentration of measure I expect that about  of the
of the 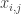 with
with  lie in
lie in  . Applying Cauchy-Schwartz twice, I thus expect to get an anomalously large number of rectangles
. Applying Cauchy-Schwartz twice, I thus expect to get an anomalously large number of rectangles  in
in  , where
, where  . (I’m too lazy to calculate the expected number of rectangles right now, it’s something like
. (I’m too lazy to calculate the expected number of rectangles right now, it’s something like  .)
.)
So far, I’ve mostly been rephrasing 413 in a different language. But now for the new idea: observe from (*) that each depends on a different subset of the random variables
depends on a different subset of the random variables 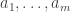 . Because of this, it is likely that the events
. Because of this, it is likely that the events  exhibit a high degree of independence from each other (even after conditioning x to be fixed). Also, assuming concentration of measure again, these events should have probability about
exhibit a high degree of independence from each other (even after conditioning x to be fixed). Also, assuming concentration of measure again, these events should have probability about  . Assuming they behave like jointly independent variables, this should mean that the expected number of rectangles
. Assuming they behave like jointly independent variables, this should mean that the expected number of rectangles  in
in  should be close to what is expected by random chance, contradicting the previous paragraph. (In fact, one does not need joint independence for this; independence of any four
should be close to what is expected by random chance, contradicting the previous paragraph. (In fact, one does not need joint independence for this; independence of any four 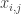 arranged a rectangle will suffice, thanks to linearity of expectation.)
arranged a rectangle will suffice, thanks to linearity of expectation.)
But what if joint independence fails? Then I think what happens is that there is some irregularity in one of the events , in the sense that the
, in the sense that the  -uniform hypergraph
-uniform hypergraph
is non-uniform in the sense of hypergraph regularity (i.e. it has a large octahedral norm, in the notation of Tim’s hypergraph regularity paper). [This is presumably the contrapositive of some nasty counting lemma that one would have to work out.] But I feel that this type of non-uniformity is a very usable type of structure on (it seems to be some sort of hypergraph generalisation of the concept of “low influence”). At any rate, now that we see some uniform hypergraphs enter the picture, it is tempting to break out the hypergraph counting, regularity, and removal machinery and see what one gets.
(it seems to be some sort of hypergraph generalisation of the concept of “low influence”). At any rate, now that we see some uniform hypergraphs enter the picture, it is tempting to break out the hypergraph counting, regularity, and removal machinery and see what one gets.
February 10, 2009 at 12:02 pm |
440. Re: A potential strategy from Terry
I’d like to point out, that the size of the hyperedges of the hypergraph at the end of 439 could be of order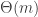 . I believe in order to use a removal lemma machinery here, one may have to chose
. I believe in order to use a removal lemma machinery here, one may have to chose  to be an extremely slow growing function (like inverse Ackerman in
to be an extremely slow growing function (like inverse Ackerman in 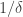 or worse). But this looks bad, as
or worse). But this looks bad, as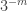 , which contain no combinatorial line with at most
, which contain no combinatorial line with at most  wildcards.
wildcards.
there are subsets of density
February 10, 2009 at 2:08 pm |
441. General strategy
This is an idea that occurs to me after reading Terry’s 439 and sort of half mixing it with my comment 331. In that comment I tried, and miserably failed, to deduce DHJ from corners in exactly the way that Sperner follows from the trivial one-dimensional equivalent of corners. The problem, as I soon discovered, was that you can’t embed grids into![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) in a nice way, analogous to the way you embed lines into
in a nice way, analogous to the way you embed lines into ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) to prove Sperner. (The image of a line is a chain of sets such as empty set, 1, 12, 123, 1234, ….)
to prove Sperner. (The image of a line is a chain of sets such as empty set, 1, 12, 123, 1234, ….)
However, even if you can’t get combinatorial lines to map to combinatorial lines, it does seem as though you can do at least something. Let’s embed a point in the triangular grid into
into ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) by sending
by sending 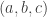 to the point with
to the point with  1s followed by
1s followed by  2s followed by
2s followed by  3s. In fact, I’ll use some slightly more general notation: a1,b2,c3 means what I’ve just said, but e.g. a1,b2,c3,d1,e2 would mean a 1s, b 2s, c 3s, d 1s, e 2s.
3s. In fact, I’ll use some slightly more general notation: a1,b2,c3 means what I’ve just said, but e.g. a1,b2,c3,d1,e2 would mean a 1s, b 2s, c 3s, d 1s, e 2s.
Then we can never have all three of (a1,b2,c3), ((a+b)1,c3) and (a1,(b+c)3). More generally, we can never have (a1,b2,c3,d2), ((a+b)1,c3,d2) and (a1,(b+c)3,d2).
Now in 311 I was trying to use this kind of idea to find a grid with no corners, and thereby to deduce that was sparse in that grid, and hence (by a suitable averaging) that it was sparse everywhere. But what if instead of going for gold straight away, we merely try to find some kind of local atypical structure all over the place, which we then try to argue must have resulted from a global atypical structure?
was sparse in that grid, and hence (by a suitable averaging) that it was sparse everywhere. But what if instead of going for gold straight away, we merely try to find some kind of local atypical structure all over the place, which we then try to argue must have resulted from a global atypical structure?
In the last paragraph but one, I can associate the sequences I’ve written down with the points (a,b,c), (a+b,0,c), (a,0,b+c). Now it’s not very difficult to find dense sets of triples adding up to n that contain no configurations of that kind. But I think it is less easy to make them quasirandom. So it seems (and this is one of those situations where another contributor — in this case Terry — has understood what I am writing for some while and I am catching up) that we do have some kind of ubiquitous local non-quasirandomness. (The presence of the 0 is disturbing, but that’s why it could be useful to add a d2 on to the end so that the sequences look more typical.)
I’ve got more to say about this, but no time for several hours so I’ll post the comment as it stands for now.
February 10, 2009 at 8:11 pm |
442. General strategy.
Let me amplify on one small comment that I made in the penultimate paragraph of the previous comment. I said, “I think it is less easy to make them quasirandom”. Here’s what I mean. The possible pairs (a+b,0,c), (a,0,b+c) form a 1-parameter family, since a+b+c is required to equal n. If r<s and we have the pairs (r,0,n-r) and (s,0,n-s), then we are forbidden to have the point (r,s-r,n-s). Thus, if R is the set of r such that the line (r1,(n-r)3) belongs to A, we find that A is not allowed to contain any point of the form (r,s-r,n-s) with r and s in R. Since the outer two coordinates determine the middle one in a simple way, we obtain a forbidden set that is basically a
Cartesian product of R with itself, or rather in a natural one-to-one correspondence with RxR.
It seems to follow that either R is very small or we have a density increment on a different Cartesian product (of R with its complement or of the complement with itself). If R is often very small, then by considering the extra d2 above and averaging, one might hope to get some kind of global non-quasirandomness, whereas if R is often large we might hope to find global non-quasirandomness for the reason outlined in the above paragraph.
A key point in all this is how to argue that one can patch together all the little bits of non-quasirandomness in order to obtain a big bit. I’ll think about that in another comment.
February 10, 2009 at 8:24 pm |
443.
Dear Mathias,
Yes, we have to take m to be a rapidly growing function of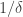 to avoid the problems you describe. But I don’t think this is necessarily a problem for two reasons. Firstly, the hypergraph is going to be on about n/3 vertices, with n extremely large compared to both m and
to avoid the problems you describe. But I don’t think this is necessarily a problem for two reasons. Firstly, the hypergraph is going to be on about n/3 vertices, with n extremely large compared to both m and 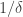 , so hypergraph regularity is still going to say something nontrivial. Secondly, I am not planning to rely solely on hypergraph regularity to finish the job; I envision something along the lines of “the hypergraph counting lemma (combined with the Sperner argument) will produce a combinatorial line unless one of the hypergraphs here is not
, so hypergraph regularity is still going to say something nontrivial. Secondly, I am not planning to rely solely on hypergraph regularity to finish the job; I envision something along the lines of “the hypergraph counting lemma (combined with the Sperner argument) will produce a combinatorial line unless one of the hypergraphs here is not  -regular”, and then the hope is to use this irregularity (which is some sort of assertion of low influence, I think) to locate a density increment or some other structural control on the original set in
-regular”, and then the hope is to use this irregularity (which is some sort of assertion of low influence, I think) to locate a density increment or some other structural control on the original set in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) .
.
The point is that Sperner+Cauchy-Schwarz seems to eliminate the role of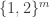 from the task of detecting combinatorial lines in
from the task of detecting combinatorial lines in  , leaving only the need to understand the distribution of
, leaving only the need to understand the distribution of  in positions containing at least one zero. This is the type of situation in which hypergraph regularity/counting/removal theory kicks in – we want to understand solutions to a system of equations, each of which only involves a proper subset of the variables.
in positions containing at least one zero. This is the type of situation in which hypergraph regularity/counting/removal theory kicks in – we want to understand solutions to a system of equations, each of which only involves a proper subset of the variables.
Tim: I think we are trying to do almost exactly the same thing, though instead of working with a random embedding of the big triangular grid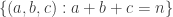 , I am working with a random embedding of the much smaller grid
, I am working with a random embedding of the much smaller grid 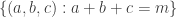 , which I like to think of as pairs
, which I like to think of as pairs 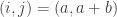 with
with  . To embed this grid into
. To embed this grid into ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , one has to pick a random base point x, which has 0s at some set A of size about n/3, and then pick m indices
, one has to pick a random base point x, which has 0s at some set A of size about n/3, and then pick m indices 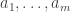 . The pair
. The pair  then embeds into the point x with the coordinates at
then embeds into the point x with the coordinates at 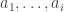 increased from 0 to 1, and the coordinates from
increased from 0 to 1, and the coordinates from 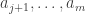 increased from 0 to 2, creating the point that I called
increased from 0 to 2, creating the point that I called 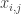 previously.
previously.
You observed that in the big triangular grid, that (r,0,n-r), (s,0,n-s), (r,s-r,n-s) cannot all embed into A. In my notation, if one lets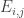 be the event that
be the event that 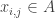 , this is the assertion that for any
, this is the assertion that for any 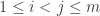 , the events
, the events 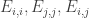 cannot all be true. On the other hand, we expect each of the events
cannot all be true. On the other hand, we expect each of the events 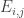 to occur with probability
to occur with probability  , which means that with high probability, the
, which means that with high probability, the 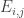 must avoid a dense Cartesian product, and thus the joint event
must avoid a dense Cartesian product, and thus the joint event 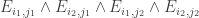 for
for 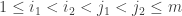 must occur with probability noticeably higher than
must occur with probability noticeably higher than  .
.
But the key is that each of the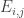 only depend on a proper subset of the random variables
only depend on a proper subset of the random variables 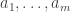 , and this is the place where the hypergraph counting lemma should step in and say something useful.
, and this is the place where the hypergraph counting lemma should step in and say something useful.
February 10, 2009 at 9:19 pm |
444. Sperner and nonquasirandomness.
I want to do a little exercise. It goes like this. Suppose I take random chains as in the proof of Sperner, and I find that the average number of elements of in each chain is
in each chain is 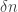 , but the average of the square of this number is not about
, but the average of the square of this number is not about 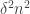 . What does that tell us about
. What does that tell us about  ?
?
One obvious thing it tells us is that the number of pairs in
in  is larger than expected—at least if one interprets “number of pairs” is interpreted appropriately. Let’s just quickly see what we actually get. If I pick a random pair
is larger than expected—at least if one interprets “number of pairs” is interpreted appropriately. Let’s just quickly see what we actually get. If I pick a random pair  (not necessarily in
(not necessarily in  ) by choosing a random maximal chain and then a random pair of elements of it, then what is the probability that I pick the particular pair
) by choosing a random maximal chain and then a random pair of elements of it, then what is the probability that I pick the particular pair  ? Let’s assume that
? Let’s assume that  and
and 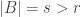 . Then the probability that the chain passes through
. Then the probability that the chain passes through  is
is 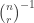 , and the probability that it passes through
, and the probability that it passes through  given that it passes through
given that it passes through  is
is  . Finally, the probability that I pick the pair
. Finally, the probability that I pick the pair  given that the chain passes through both
given that the chain passes through both  and
and  is
is  . So the weighting of pairs is according to the following model: first pick a random pair of slices (according to the uniform distribution) and then pick a random pair
. So the weighting of pairs is according to the following model: first pick a random pair of slices (according to the uniform distribution) and then pick a random pair  from that pair of slices.
from that pair of slices.
Thus, the hypothesis that has too many pairs is the hypothesis that if you pick a random pair
has too many pairs is the hypothesis that if you pick a random pair  as in the above paragraph, then there is a more than
as in the above paragraph, then there is a more than 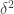 chance that both
chance that both  and
and  belong to
belong to  .
.
Can we use this to get a global conclusion? In a non-quasirandom bipartite graph the trick is to choose a random edge and take the neighbourhoods of its vertices. Since there are too many 4-cycles, the resulting induced bipartite graph is on average too dense. What would be the analogue here?
The obvious one would be to choose a random point of and take the set of all pairs
and take the set of all pairs  such that
such that 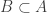 or
or  . This gives a structure (one might visualize it as a sort of “double cone”) that typically contains more points of
. This gives a structure (one might visualize it as a sort of “double cone”) that typically contains more points of  than it should. But this doesn’t count as a global obstruction because it is absolutely tiny compared with
than it should. But this doesn’t count as a global obstruction because it is absolutely tiny compared with ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) . So the next question is whether it is possible to have a set of density
. So the next question is whether it is possible to have a set of density  (according to the slices-equal weighting of
(according to the slices-equal weighting of ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) ) such that (i) it intersects many of these “double cones” in density significantly different from
) such that (i) it intersects many of these “double cones” in density significantly different from  and (ii) one cannot obtain a density increase on a subspace in any simple way.
and (ii) one cannot obtain a density increase on a subspace in any simple way.
I have to bath my 15-month-old now, so will pursue this later if nobody else has.
February 11, 2009 at 12:22 am |
445. Tim, I’m just reading your ecercise, It might be more relevant to us to consider sets of size . In general, I don’t see why do you have
. In general, I don’t see why do you have  and not
and not  elements in a random chain.
elements in a random chain.
February 11, 2009 at 12:22 am |
446. Sperner and nonquasirandomness
Tim, I think in order to get a meaningful answer one has to localise the chains somewhat. Currently, one can get a ridiculously large number of pairs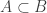 from a very small
from a very small  by using the extreme ends of the chain, for instance by letting
by using the extreme ends of the chain, for instance by letting  be those A for which
be those A for which 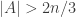 or
or 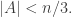
To move things closer to my proposals in 439, 443, I would instead do this: pick a random A in [n], then pick m random points in the complement of A (where m is bounded in n, e.g.
in the complement of A (where m is bounded in n, e.g.  ), and then look at the random variable X, defined as the number of
), and then look at the random variable X, defined as the number of 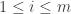 such that
such that  lies in
lies in  . This variable X has expectation about
. This variable X has expectation about  ; what can we say if it has significant variance?
; what can we say if it has significant variance?
February 11, 2009 at 12:30 am |
447. Obstructions to Sperner.
I feel that we haven’t thought about this hard enough. Boris’s remark in 418 that obstructions to Sperner (=DHJ(1,2)) don’t follow from lower-level obstructions is something we still need to come to terms with.
It seems that one source of obstructions is “usually continuous” sets, by which I mean sets where if you pick a random sequence and change a random coordinate then you will usually not change whether that sequence belongs to the set. Except that as I write that I see that there is absolutely no reason to believe that it is true. As you go up a random chain, even if you only rarely switch from belonging to the set to not belonging, or the other way, you may well get the expected density by the end. (Note that all these discussions are very different if we take the uniform measure on![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , but I am trying to push the slices-equal measure.)
, but I am trying to push the slices-equal measure.)
If we let $\mathcal{A}$ be the collection of all sets that contain , then what happens? The density is
, then what happens? The density is  , but this is not quite as trivial a fact as usual: it follows from the fact that the bijection from a set to its complement is measure preserving. If we pick a random pair
, but this is not quite as trivial a fact as usual: it follows from the fact that the bijection from a set to its complement is measure preserving. If we pick a random pair  then there’s obviously a correlation between
then there’s obviously a correlation between  containing 1 and
containing 1 and  containing 1 — indeed, it’s about as extreme a correlation as one could hope for. What’s more, we can think about it like this: if we pick a random chain, then we will add in the element 1 at a random moment between 1 and n, so the intersection of
containing 1 — indeed, it’s about as extreme a correlation as one could hope for. What’s more, we can think about it like this: if we pick a random chain, then we will add in the element 1 at a random moment between 1 and n, so the intersection of  with the chain has a density that is uniformly distributed between 0 and 1, which means that the mean square density of
with the chain has a density that is uniformly distributed between 0 and 1, which means that the mean square density of  in a random chain is
in a random chain is 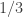 , rather than the
, rather than the 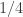 that it is supposed to be.
that it is supposed to be.
I now see that what I’m groping for is something like this: we want more or less any monotone set system that isn’t too much like the collection of all sets of size at least . What I mean by that is the following. If
. What I mean by that is the following. If  is a monotone set, then given any chain, it will start outside
is a monotone set, then given any chain, it will start outside  and then end up inside. So the density of the intersection is determined by the point at which your set first joins
and then end up inside. So the density of the intersection is determined by the point at which your set first joins  .
.
So one method of building an obstruction would be to take a reasonably dense subset of
of ![\binom{[n]}{n/3}](https://s0.wp.com/latex.php?latex=%5Cbinom%7B%5Bn%5D%7D%7Bn%2F3%7D&bg=ffffff&fg=333333&s=0&c=20201002) , say, and take all sets that contain a set in
, say, and take all sets that contain a set in  . But this isn’t going to give a set of density
. But this isn’t going to give a set of density  unless the sets in
unless the sets in  are very bunched together, or else their upper shadows are very soon going to be pretty well everything.
are very bunched together, or else their upper shadows are very soon going to be pretty well everything.
I know this has already been discussed, but it feels as though it will be hard to come up with examples that aren’t based on heavy bias (or influence if we stick to these monotone examples, or similar). Boris had something for two layers, but what happens if we are forced to look at several layers, as we are with the slices-equal measure? It’s tempting to look at Fourier expansions, as Gil suggested in 29.
February 11, 2009 at 12:44 am |
448. Obstructions to Sperner.
My response to both Jozsef and Terry is the same. I’m very deliberately not localizing, because I’m hoping to use a different measure in DHJ, where you choose a point by first choosing a random slice according to the uniform distribution and then choosing a random point in the slice.
There are several motivations for that. First of all, it is exactly what one does when proving Sperner via random chains: you get the stronger result that you just need the sum of the densities in all the layers to be greater than 1. In a sense, it is rather artificial to go on and say that the middle layer is the largest.
Secondly, if you do this then there is a real chance that the distribution of a random point, given that it belongs to a randomly chosen combinatorial line, is not horribly different from the distribution of a random point full stop. All this I said in my comment near the end of the 300s thread. (To be precise, it’s comments 365 and 366.)
Thirdly, proving DHJ for this measure is equivalent to proving it for the uniform measure, by the usual averaging trick. (I confess that I haven’t actually checked this, but it is surely true.)
So when Terry says that the sets of size at least 2n/3 or at most n/3 form a ridiculously small set system, I say no they don’t: that set system has density 2/3 in the slices-equal measure.
Similarly, when Jozsef says that a set of density might well intersect a random chain in only
might well intersect a random chain in only  , he is talking about the uniform measure. But in the equal-slices measure the density of a set is defined to be the expected density of the intersection with a random chain!
, he is talking about the uniform measure. But in the equal-slices measure the density of a set is defined to be the expected density of the intersection with a random chain!
Having said all that, there may well be other objections to my proposals.
[Off to bed now. I look forward to plenty of reading material when I wake up …]
February 11, 2009 at 4:25 am |
449. Obstructions to Sperner
Dear Tim, I’m leery of working globally because one is going to encounter things like Boris’s counterexample 412 again. Also, while I suppose one could work with all layers
layers 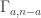 of
of ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as you are proposing, and even give them all equal weight, this seems very strange to me, since we know that we may without loss of generality restrict to the middle
as you are proposing, and even give them all equal weight, this seems very strange to me, since we know that we may without loss of generality restrict to the middle  (or more precisely
(or more precisely 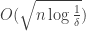 ) layers, since all the other layers add up at most to a set of density
) layers, since all the other layers add up at most to a set of density  and thus can be discarded without loss of generality at the very first step (at the trifling cost of replacing the density
and thus can be discarded without loss of generality at the very first step (at the trifling cost of replacing the density  with
with  ).
).
Nevertheless, the idea of trying to work out what the consequences are of knowing that has “low influence” in the sense that flipping one digit does not change membership in
has “low influence” in the sense that flipping one digit does not change membership in  as often as it should, looks like a promising one. I think my own arguments in 443 say that we are done unless the influence (or something like the influence) is somewhat less than the influence of the random set, though the influence is not so low that we automatically get huge subspaces.
as often as it should, looks like a promising one. I think my own arguments in 443 say that we are done unless the influence (or something like the influence) is somewhat less than the influence of the random set, though the influence is not so low that we automatically get huge subspaces.
More thoughts on this later…
February 11, 2009 at 5:08 am |
450 DHJ(j,k)
To answer Gil’s question in 438, here is what I understand DHJ(j,k) to mean:
DHJ(j,k): Every dense subset of![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) which has “complexity at most j” contains a combinatorial line (of length k).
which has “complexity at most j” contains a combinatorial line (of length k).
Now, what does “complexity at most j” mean? We’re still negotiating a precise definition, I think, but here was one proposal. We can think of an element x of![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as a partition of [n] into k sets
as a partition of [n] into k sets 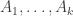 . Now suppose we only considered j of these sets, say the first j
. Now suppose we only considered j of these sets, say the first j 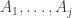 – call this a j-shadow of x, so that there are
– call this a j-shadow of x, so that there are  different j-shadows of x. When j=k-1, each j-shadow of x can be used to recover x completely, but for smaller values of j, each j-shadow only gives partial information as to what x is.
different j-shadows of x. When j=k-1, each j-shadow of x can be used to recover x completely, but for smaller values of j, each j-shadow only gives partial information as to what x is.
Now, let us call a set![{\mathcal A} \subset [k]^n](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%7D+%5Csubset+%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) sub-basic of complexity at most j if membership of a point
sub-basic of complexity at most j if membership of a point ![x \in [k]^n](https://s0.wp.com/latex.php?latex=x+%5Cin+%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) in
in  can be defined purely in terms of a single j-shadow of x (e.g. the first j sets
can be defined purely in terms of a single j-shadow of x (e.g. the first j sets 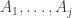 .) Example: the set
.) Example: the set  of all strings with exactly a 3s is a sub-basic set of complexity 1. the set of all strings with exactly b occurrences of the substring 31 is a sub-basic set of complexity 2.
of all strings with exactly a 3s is a sub-basic set of complexity 1. the set of all strings with exactly b occurrences of the substring 31 is a sub-basic set of complexity 2.
Observe that every subset of![{}[k]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) is a sub-basic set of complexity k-1.
is a sub-basic set of complexity k-1.
Define a basic set of complexity at most j to be the intersection of sub-basic sets of complexity j. Example: the set of strings in
of strings in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) with a 1s, b 2s, and c 3s is a basic set of complexity 1. (My notation here is coming from point set topology, in particular the notion of a sub-base and base of a topology.)
with a 1s, b 2s, and c 3s is a basic set of complexity 1. (My notation here is coming from point set topology, in particular the notion of a sub-base and base of a topology.)
Finally (and continuing the toplogical analogy) one could define a set of complexity j to be the union of a bounded number of basic sets of complexity j.
With these conventions, DHJ(k-1,k) is the same as DHJ(k). DHJ(1,3) is DHJ(3) specialised to those sets of the form
of the form  , where membership of a string
, where membership of a string ![x \in [3]^n](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) in
in 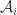 is determined entirely by the i-set of x.
is determined entirely by the i-set of x.
February 11, 2009 at 5:31 am |
451 01-insensitivity
One key insight in Shelah’s proof of Hales-Jewett is that if you have a colouring of 012 strings which is “01”-insensitive in the sense that flipping a 0 to a 1 or vice versa does not affect the colour of the string, then the k=3 HJ theorem collapses to the k=2 HJ theorem.
In a similar spirit, if a dense subset of
of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) is mostly 01-insensitive in the sense that flipping a random 0 entry of a random element of
is mostly 01-insensitive in the sense that flipping a random 0 entry of a random element of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) to a 1 (or flipping a random 1 entry to 0) is almost certain not to change the membership status of that string in
to a 1 (or flipping a random 1 entry to 0) is almost certain not to change the membership status of that string in  , then (by looking at a randomly chosen medium-dimensional slice of
, then (by looking at a randomly chosen medium-dimensional slice of  ) we can reduce this instance of DHJ(3) to DHJ(2). This notion of “mostly 01-insensitive” is close to Tim’s notion of “usually continuous” from 447 or the notion of “low (average) influence” we have been discussing previously, but note that it is only about 0 and 1; it doesn’t say anything about what happens if a 0 is flipped to a 2, for instance.
) we can reduce this instance of DHJ(3) to DHJ(2). This notion of “mostly 01-insensitive” is close to Tim’s notion of “usually continuous” from 447 or the notion of “low (average) influence” we have been discussing previously, but note that it is only about 0 and 1; it doesn’t say anything about what happens if a 0 is flipped to a 2, for instance.
After talking with Tim Austin a bit about how the Furstenberg-Katznelson proof proceeds, I am beginning to think that instead of just incrementing density, we may also have to increment “01-insensitivity”. I think I can push my arguments in 413, 439 to say something along the lines of “either we have enough quasirandomness to find a combinatorial line, or else there is a little bit of 01-insensitivity present”. By a “little bit” of insensitivity, I mean that if we take a random string x, and then flip one of the 0s of x randomly to a 1 to create a random string y, then there is a small amount of correlation (something like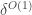 ) between the events
) between the events  and
and  . [I am oversimplifying here; I need a more generalised notion of insensitivity, but this is the flavour of what I think is possible.]
. [I am oversimplifying here; I need a more generalised notion of insensitivity, but this is the flavour of what I think is possible.]
At present I don’t see how to iterate this observation (though I can imagine bringing in existing Ramsey theorems, and perhaps also multidimensional Szemeredi, to assist here), to try to increase the 01-insensitivity through repeated passage to sub-objects until we get to the point where Shelah’s observation lets us drop from k=3 to k=2. Tim Austin tells me that this is broadly how the ergodic theory proof of DHJ proceeds; at some point I should go read that paper more thoroughly and see this for myself.
February 11, 2009 at 5:53 am |
450. In #444 Tim asks what can we conclude if the average number of elements in the chain is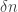 , but the average of the square is much different from
, but the average of the square is much different from  . My hunch is that it should imply that there is a pair
. My hunch is that it should imply that there is a pair ![(i,j)\in \binom{[n]}{2}](https://s0.wp.com/latex.php?latex=%28i%2Cj%29%5Cin+%5Cbinom%7B%5Bn%5D%7D%7B2%7D&bg=ffffff&fg=333333&s=0&c=20201002) such that swapping the order of
such that swapping the order of  and
and  . The intuition is that if it is not the case, then some kind of Azuma-type or isoperimetric inequality should establish concentration. This is probably very similar to what Terry suggests in #449.
. The intuition is that if it is not the case, then some kind of Azuma-type or isoperimetric inequality should establish concentration. This is probably very similar to what Terry suggests in #449.
My experience working on forbidden subposet generalization of Sperner suggests Tim is probably right in wanting to weight everything. The reason for this is that even if we working with a few levels near the middle level, then though the vertices (=the sets) are are weighted approximately the same in all of them, the edges (=the pairs ) are weighted very differently according to the distance between the levels that contain them. The weight scales like
) are weighted very differently according to the distance between the levels that contain them. The weight scales like  .
.
The reason why weighting edges is unavoidable is that if suppose we know by density considerations that there are pairs $\latex A\subset B$ in our set family, but we want to give a bound on the number of pairs . Then the optimal bound will depend strongly on how far the levels on which the family lives are from one another.
. Then the optimal bound will depend strongly on how far the levels on which the family lives are from one another.
So, even if we localize to a stack of layers of size , we probably will have to weight edges anyways.
, we probably will have to weight edges anyways.
Unfortunately, I cannot see anything resembling chains for![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) .
.
February 11, 2009 at 6:11 am |
451.
Boris, I think the random model I have in 439 (in which one is looking at random embeddings of![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) into
into ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , and then analyses correlations between elements of the resulting random subset of
, and then analyses correlations between elements of the resulting random subset of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) , rather than deal directly with the original set in
, rather than deal directly with the original set in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) ) seems to do the edge weighting you want automatically. (It also fits well with the ergodic theory approach to these sorts of problems.)
) seems to do the edge weighting you want automatically. (It also fits well with the ergodic theory approach to these sorts of problems.)
The analogue of the chains for![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) (or for the embedded copy of
(or for the embedded copy of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) ) seem to be the strings consisting of a connected string of 1s, 0s, and 2s. For instance we get triangles such as this one in
) seem to be the strings consisting of a connected string of 1s, 0s, and 2s. For instance we get triangles such as this one in ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=333333&s=0&c=20201002) :
:
0000 0002 0022 0222 2222
1000 1002 1022 1222
1100 1102 1122
1110 1112
1111
note that every right-angled triangle with the hypotenuse on the diagonal of the above grid is a combinatorial line. My strategy in 439 is to look at all the random embeddings of this type of picture into![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , and then use Cauchy-Schwarz to eliminate the role of the diagonal and only focus on the interior (in which all strings have at least one 0 in them, which sets one up for hypergraph counting lemmas). Tim Austin tells me that this is related to the van der Corput type lemmas used in the ergodic proof of DHJ, which is an encouraging sign for me.
, and then use Cauchy-Schwarz to eliminate the role of the diagonal and only focus on the interior (in which all strings have at least one 0 in them, which sets one up for hypergraph counting lemmas). Tim Austin tells me that this is related to the van der Corput type lemmas used in the ergodic proof of DHJ, which is an encouraging sign for me.
February 11, 2009 at 11:30 am |
452. Slices-equal weights.
I’m not wedded to my suggestion of putting a different measure on![\null[3]^n](https://s0.wp.com/latex.php?latex=%5Cnull%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) (or
(or ![{}[2]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) for that matter) but I think the idea has enough going for it that I don’t want to drop it unless I see a truly convincing argument for doing so. And at the moment I don’t.
for that matter) but I think the idea has enough going for it that I don’t want to drop it unless I see a truly convincing argument for doing so. And at the moment I don’t.
First of all, no argument that is given from the perspective of the uniform measure can be an argument against using a different measure. One has to step outside both. So this informal argument of Terry doesn’t persuade me:
Also, while I suppose one could work with all layers of as you are proposing, and even give them all equal weight, this seems very strange to me, since we know that we may without loss of generality restrict to the middle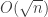 (or more precisely
(or more precisely  ) layers, since all the other layers add up at most to a set of density
) layers, since all the other layers add up at most to a set of density  and thus can be discarded without loss of generality at the very first step (at the trifling cost of replacing the density
and thus can be discarded without loss of generality at the very first step (at the trifling cost of replacing the density  with
with  ).
).
Of course if you are working with the uniform measure you can discard everything that isn’t near the middle, but if you are working with the slices-equal measure then you can’t. So the equal-slices measure is different, but that doesn’t make it “very strange”, any more than it’s very strange to use the uniform measure because WLOG you can restrict to a set (if you’re a slices-equal person) that keeps away from the middle layer. To summarize: no argument that basically boils down to saying that the slices-equal measure is different from the uniform measure carries any weight: it’s supposed to be different!
A more serious point raised by Terry is the general one that global arguments are vulnerable to Boris-type counterexamples. But, as discussed in 428, 429, 431, 432, it is not completely obvious that that is the case with the slices-equal measure. The reason is that then the wildcard sets become (I’m fairly sure, but must check) of linear size. What’s more, I think the standard deviation of the size of the wildcard set is linear too. So it seems to me that the phenomena that Boris was exploiting don’t arise with the slices-equal measure.
I was therefore allowing myself to hope that conjecture 411 might actually be true for the slices-equal measure.
However, I am still disturbed by Boris’s point that the analogue of this one level down seems to be false (since the number of pairs in Sperner doesn’t just depend on the density). That is why I wanted to think hard about what the obstructions to uniformity are for Sperner with the slices-equal measure.
pairs in Sperner doesn’t just depend on the density). That is why I wanted to think hard about what the obstructions to uniformity are for Sperner with the slices-equal measure.
I just want to add, once again, that the slices-equal measure has one very strong argument going for it, from the point of view of what is natural, which is that all (I think) the proofs of Sperner prove something about the slices-equal measure and only at the very end convert that into a statement about the uniform measure.
One reason for resisting the slices-equal measure is that it is less symmetric than the uniform measure. However, the formulations of Sperner/DHJ are not symmetric either, or rather the symmetries they do have are also symmetries of the slices-equal measure.
Another argument for its naturalness is that it seems rather strange to look only for lines with very small wildcard sets, when almost all lines have linear-sized wildcard sets. With the uniform measure, this is forced, but that is because of the unfortunate fact that the measure of a typical point on a typical line is radically different from the measure of a typical point. Note that this is an argument for the unnaturalness of the uniform measure that is taken from an external perspective: we would like a measure that doesn’t get completely distorted when you condition on belonging to a random combinatorial line, we then look at the two measures, and we find that the slices-equal measure does better in that respect.
I’m not at all dismissing Terry’s very interesting suggestions for dealing with things locally. It’s more that I would love to do something global if it turned out to be possible, so I’d like to invite people to attempt to find reasons for its not being possible. For example, if there is an obstruction to uniformity that’s not of type 411 then I may well be forced to abandon my hopes of a global argument. If no such reason is forthcoming, then I think we should keep global arguments in play.
If it turns out that the only obstructions to Sperner (in the slices-equal set-up) are ones that depend on a tiny number of variables, then we might be lucky and find that Conjecture 411 is true. At first that seems strange, when it’s false one level down. But the point is that the assumption of disjointness that we have all over the place concerns pairs of sets, at whatever level one is, so it could be that Sperner is exceptional because it occurs at a level below the level of the disjointness restriction. In other words, examples that depend on just a few variables affect you at all levels, but when you get to DHJ they can be absorbed into Conjecture 411, whereas for Sperner they can’t.
This is, as usual, an optimistic suggestion, and as usual I welcome a cold blast of realism if anyone can supply it.
February 11, 2009 at 2:42 pm |
453. (Clarification to 452) In particular, do you conjecture that a dense set in the slices-equal measure must contains a combinatorial line? This is stronger than DHJ, right? (Can you prove it as a consequence of DHJ?)
(Just to make sure I understood correctly: slice equal measure is this: you give equal weight to all solutions of a+b+c =n and then splt this weight uniforly for all sequences of a ‘0’s b 1’1s and c ‘2’s. Indeed this natural measure appears in various places.)
February 11, 2009 at 3:04 pm |
454. Re Sperner.
It was suggested in #446 to pick a random , form
, form  by taking a random “upwards” walk of length
by taking a random “upwards” walk of length 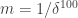 , and then look at the random variable
, and then look at the random variable 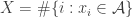 , where
, where  has density
has density  . Although the
. Although the  ‘s are not uniformly distributed, they are very close to being so, since
‘s are not uniformly distributed, they are very close to being so, since  is small. Hence the expectation of
is small. Hence the expectation of  should be very nearly
should be very nearly  .
.
Consider the case that is a monotone subset (“up-set”). Then
is a monotone subset (“up-set”). Then  will be very nonconcentrated. Indeed, conditioned on
will be very nonconcentrated. Indeed, conditioned on  (probability
(probability  ), so are all the
), so are all the  ‘s. I.e., in this case,
‘s. I.e., in this case,  is
is  with probability
with probability  and therefore nearly
and therefore nearly  with probability
with probability  .
.
On the other hand, it’s not clear that this is an immediate problem for the plan; in #439, one may well be even happier to have with
with  probability.
probability.
February 11, 2009 at 3:32 pm |
455. If we want a ridicously-hyper-optimistic statement extending LYM to 3-letters alphabet we can take this: Consider all blocks of slices
of slices  not containing a combinatorial line. Let
not containing a combinatorial line. Let  be a subset of
be a subset of 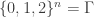 without a combinatorial line, then the sum of densities of
without a combinatorial line, then the sum of densities of  in some weighted collections of blocks which form a fractional covering of
in some weighted collections of blocks which form a fractional covering of  is at most 1.
is at most 1.
February 11, 2009 at 4:03 pm |
456. There is another finer notion of slices which may be a righter extensions from the k=2 case. Here you grade the elements of according to words in ‘0’ and ‘1’ that you obtain by arasing the ‘2’s. It would be nice to see (estimate) what is the maximum size of unions of such fine slices without a combinatorial line.
according to words in ‘0’ and ‘1’ that you obtain by arasing the ‘2’s. It would be nice to see (estimate) what is the maximum size of unions of such fine slices without a combinatorial line.
February 11, 2009 at 4:18 pm |
457. Slices-equal measure
It occurs to me that there may in fact be essentially no difference of opinion between Tim’s “global, slices-equal measure” viewpoint and my “local, uniform-measure” viewpoint, because in order to get from a slices-equal measure DHJ to a uniform measure DHJ, one has to average on local subspaces anyway. (Note that one can easily construct sets of large uniform measure with small slices-equal measure, e.g. the strings![x \in [2]^n](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) with
with 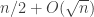 1s, and conversely, so localisation is necessary here.)
1s, and conversely, so localisation is necessary here.)
February 11, 2009 at 5:20 pm |
458. Sorry for the double-post above. [Now sorted out — Tim.] I guess it was already clear from the first para of Terry’s #451 that if is, say, “01-monotone”, meaning that changing a 1 to a 0 cannot take you out of
is, say, “01-monotone”, meaning that changing a 1 to a 0 cannot take you out of  , then DHJ holds for
, then DHJ holds for  , and even with the lower density $\latex \approx 1/\sqrt{n}$ of Sperner. This already covers a number of my previous obstruction examples; e.g., having runs of 0’s or having plurality digit 0.
, and even with the lower density $\latex \approx 1/\sqrt{n}$ of Sperner. This already covers a number of my previous obstruction examples; e.g., having runs of 0’s or having plurality digit 0.
February 11, 2009 at 5:40 pm |
459. Slices-equal measure
Terry, I was going to say something similar. It seems to me that localization and slices-equal measure are different ways of forcing typical lines to contain typical points. But the difference is more of a technical one than a fundamental one. I am hoping that slices-equal measure will turn out to be technically rather convenient, but I haven’t done enough calculations with it to be certain that it will be.
Gil, I’m pretty sure that DHJ for the slices-equal measure is an easy consequence of DHJ, and vice versa. Here’s a sketch of how to prove that DHJ for any reasonably continuous measure (meaning that the weight of a point is usually very similar to the weight of a neighbouring point) is equivalent to the usual DHJ. You just pick some such that
such that  and pick a random subspace by randomly fixing
and pick a random subspace by randomly fixing 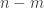 coordinates and letting the remaining
coordinates and letting the remaining  vary. Suppose
vary. Suppose  has density
has density  in measure 1. Then the average density in one of these subspaces is roughly
in measure 1. Then the average density in one of these subspaces is roughly  . Moreover, by hypothesis the measure in almost all of the subspaces is almost uniform, so we can apply the normal DHJ to get it for the funny measure. And in the reverse direction, if we regard each tiny subspace as a copy of
. Moreover, by hypothesis the measure in almost all of the subspaces is almost uniform, so we can apply the normal DHJ to get it for the funny measure. And in the reverse direction, if we regard each tiny subspace as a copy of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) and apply the funny measure to it, then the average of all these funny measures will be roughly uniform, so once again we can find a subspace where
and apply the funny measure to it, then the average of all these funny measures will be roughly uniform, so once again we can find a subspace where  is dense with respect to the funny measure. (Note that I needed continuity of the funny measure only in one direction of this equivalence.)
is dense with respect to the funny measure. (Note that I needed continuity of the funny measure only in one direction of this equivalence.)
Gil, I’m not sure I understand your hyper-optimistic conjecture, but let me give one of my own. Apologies if it’s the same. Let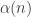 be the minimal density that guarantees a non-trivial aligned equilateral triangle in the set of non-negative (a,b,c) such that a+b+c=n. Then if the slices-equal measure of A is greater than
be the minimal density that guarantees a non-trivial aligned equilateral triangle in the set of non-negative (a,b,c) such that a+b+c=n. Then if the slices-equal measure of A is greater than  , A must contain a combinatorial line. This conjecture, if true, is trivially best possible since a corner-free union of slices contains no combinatorial line. It is also a direct generalization of Sperner. I wonder if there’s some simple way of seeing that it is false.
, A must contain a combinatorial line. This conjecture, if true, is trivially best possible since a corner-free union of slices contains no combinatorial line. It is also a direct generalization of Sperner. I wonder if there’s some simple way of seeing that it is false.
February 11, 2009 at 6:16 pm |
460. The ergodic perspective
I think I now see more clearly the way to put my approach and Tim’s approach on a common footing, and that is using the lessons drawn from the ergodic theory approach to density Ramsey problems that proceeds via the Furstenberg correspondence principle.
Now before everyone runs away screaming, let me try to explain the Furstenberg philosophy without actually using the words “ergodic”, “limit”, “infinite”, or “measure space” (though I will need “random” as a substitute for “measure space”).
In a nutshell, the philosophy is this:
* Study a global dense object by looking at a random local suboject. This trades a globally dense deterministic object for a pointwise dense random object
for a pointwise dense random object  . Furthermore, this random object obeys various symmetry (or more precisely, stationarity) properties.
. Furthermore, this random object obeys various symmetry (or more precisely, stationarity) properties.
So, one gets much more structure on the object being studied, provided that one lets go of the idea of thinking of this object deterministically, and instead embracing its random nature.
being studied, provided that one lets go of the idea of thinking of this object deterministically, and instead embracing its random nature.
Let me give some concrete examples of this philosophy. Firstly, Roth’s theorem in , with N assumed prime for simplicity. To locate length three progressions in a set
, with N assumed prime for simplicity. To locate length three progressions in a set  , what one can do is pick a medium size number m, and look at a random arithmetic progression
, what one can do is pick a medium size number m, and look at a random arithmetic progression  of length m in
of length m in  . One can then pull back the deterministic set A by this progression to create a random subset
. One can then pull back the deterministic set A by this progression to create a random subset ![A' := \{ j \in [m]: a+jr \in A \}](https://s0.wp.com/latex.php?latex=A%27+%3A%3D+%5C%7B+j+%5Cin+%5Bm%5D%3A+a%2Bjr+%5Cin+A+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) of
of ![{}[m]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) . If we can find a progression of length 3 in A’ with positive probability, then we get a progression of length 3 in A (in fact, we get lots of such progressions; this is essentially the proof of Varnavides theorem).
. If we can find a progression of length 3 in A’ with positive probability, then we get a progression of length 3 in A (in fact, we get lots of such progressions; this is essentially the proof of Varnavides theorem).
The original deterministic set A had global density . Because of this, the random set A’ has a better property: it has a pointwise density
. Because of this, the random set A’ has a better property: it has a pointwise density  , in the sense that every j in [m] belongs to A’ with probability
, in the sense that every j in [m] belongs to A’ with probability  . From linearity of expectation this implies that the expected density of A’ with respect to uniform measure of [m] is
. From linearity of expectation this implies that the expected density of A’ with respect to uniform measure of [m] is  , but it is far stronger – indeed, it implies that the expected density of A’ with respect to any probability measure on [m] is
, but it is far stronger – indeed, it implies that the expected density of A’ with respect to any probability measure on [m] is  .
.
Similarly, the deterministic set A has no symmetry properties: A+1, for instance, may well be a completely different set from A. However, the random set A’ has an important symmetry property: the random set A’+1, while being different from A’, has the same probability distribution as A’ (ignoring some trivial issues at the boundary of [m]; in practice one eliminates this by taking the limit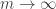 ). In the language of probability theory, we say that the probability distribution of A’ is stationary; in the language of ergodic theory, we say that the transformation
). In the language of probability theory, we say that the probability distribution of A’ is stationary; in the language of ergodic theory, we say that the transformation 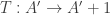 is a measure-preserving transformation with respect to the probability distribution
is a measure-preserving transformation with respect to the probability distribution  of A’.
of A’.
Now, we know that the events ,
,  ,
, 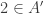 each occur with probability
each occur with probability  . If they were independent, then we would have
. If they were independent, then we would have 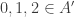 with probability
with probability  and we would get Roth’s theorem. But of course they could be correlated – but one can try to quantify this correlation by a variety of tools, e.g. using the spectral theory of the measure-preserving transformation T (this is the analogue of using Fourier analysis in the original combinatorial setting). This is the starting point for the ergodic theory method for solving density Ramsey theory problems.
and we would get Roth’s theorem. But of course they could be correlated – but one can try to quantify this correlation by a variety of tools, e.g. using the spectral theory of the measure-preserving transformation T (this is the analogue of using Fourier analysis in the original combinatorial setting). This is the starting point for the ergodic theory method for solving density Ramsey theory problems.
Now we return to Hales-Jewett. Similarly to above, if we wish to study a subset of
of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) which has density
which has density  wrt uniform measure, we can take a random m-dimensional subspace of
wrt uniform measure, we can take a random m-dimensional subspace of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) (where I will be a little vague for now as to exactly what “random” means; there are a variety of options here) and pull back the deterministic
(where I will be a little vague for now as to exactly what “random” means; there are a variety of options here) and pull back the deterministic  to get a random subset
to get a random subset  of
of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) . Again, finding lines in
. Again, finding lines in  will generate lines in
will generate lines in  (and there will be an appropriate Varnavides statement).
(and there will be an appropriate Varnavides statement). ensures that the random subset
ensures that the random subset  has pointwise density very close to
has pointwise density very close to  (there is a slight distortion here, as pointed out in Ryan.454, but it is minor). Thus, the expected density of
(there is a slight distortion here, as pointed out in Ryan.454, but it is minor). Thus, the expected density of  with respect to any particular measure on
with respect to any particular measure on ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) – be it uniform, slices-equal, or anything else – is basically
– be it uniform, slices-equal, or anything else – is basically  .
.
Also as before, the global density of
It is at this point that the three approaches to the problem (ergodic approach, Tim’s approach, and my approach) begin to diverge.
The ergodic theory approach would then proceed by studying correlations between events such as “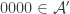 ,
, 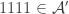 ,
,  . If these events are independent, we are done; otherwise, we hope to discern some usable structural information on
. If these events are independent, we are done; otherwise, we hope to discern some usable structural information on  out of this. The original set
out of this. The original set  is not used at all in the ergodic theory approach; it’s only legacies are the pointwise density and stationary properties it bestows on
is not used at all in the ergodic theory approach; it’s only legacies are the pointwise density and stationary properties it bestows on  .
.
Tim’s approach is proceeding by using the first moment method to locate a specific deterministic instance of which is dense wrt slices-equal measure, and then proceeding from there. As with the ergodic theory method, the original set
which is dense wrt slices-equal measure, and then proceeding from there. As with the ergodic theory method, the original set  (which was dense in the uniform measure, rather than slices-equal) is now discarded, and one is now working entirely with the slices-equal-dense
(which was dense in the uniform measure, rather than slices-equal) is now discarded, and one is now working entirely with the slices-equal-dense  . As I understand it, Tim is then trying to show that lack of combinatorial lines in
. As I understand it, Tim is then trying to show that lack of combinatorial lines in  will force some new structure on
will force some new structure on  .
.
My approach starts off similarly to the ergodic theory approach – studying correlations between events such as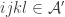 – but the difference is that once a correlation is detected, I try to see what this tells me about the original set
– but the difference is that once a correlation is detected, I try to see what this tells me about the original set  , in particular to show that it has some “low-influence”, “insensitivity”, “mostly continuous”, or “monotone” like properties. I have a vague idea of trying to iterate this procedure until we have enough structure on
, in particular to show that it has some “low-influence”, “insensitivity”, “mostly continuous”, or “monotone” like properties. I have a vague idea of trying to iterate this procedure until we have enough structure on  to either pass to a denser subspace or find combinatorial lines directly, but I have not worked this part out yet.
to either pass to a denser subspace or find combinatorial lines directly, but I have not worked this part out yet.
February 11, 2009 at 6:28 pm |
461. Ergodic perspective cont.
Perhaps one more remark to illustrate the connection between my approach and Tim’s approach. For sake of illustration I will take m=4, since I can then use the triangular grid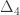 from 451.
from 451.
The construction in 460 gives a random subset of
of ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=333333&s=0&c=20201002) , with pointwise density essentially
, with pointwise density essentially  . In particular, the equal-slices density of
. In particular, the equal-slices density of  in
in ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=333333&s=0&c=20201002) has expectation about
has expectation about  , and similarly the uniform density of
, and similarly the uniform density of  on
on 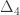 has expectation about
has expectation about  .
.
But because a permutation of a cube is still a cube, we see that applying any of the 4! permutations of the indices to will give a new random set with the same probability distribution as
will give a new random set with the same probability distribution as  ; thus
; thus  is stationary with respect to the action of
is stationary with respect to the action of 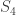 on
on ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=333333&s=0&c=20201002) .
.
But observe that equal-slices measure is nothing more than the uniform measure on averaged by the action of
averaged by the action of  (
( intersects each slice in exactly one point). So the expected density of
intersects each slice in exactly one point). So the expected density of  wrt equal slices measure is necessarily equal to the expected density of
wrt equal slices measure is necessarily equal to the expected density of  wrt uniform measure
wrt uniform measure  . But the fact that both of these densities are
. But the fact that both of these densities are  is weaker than the statement that the pointwise density of
is weaker than the statement that the pointwise density of  is
is  , which is what I think we should be using.
, which is what I think we should be using.
February 11, 2009 at 6:44 pm |
460. Taxonomy of slices
This is more a general-organization comment, but at some point could we get together a “taxonomy of slices”? I’m starting to lose track of all the different methods people are proposing.
I believe it also might be helpful to apply the slices side-by-side to a single example to get an impression of how the sets are different.
February 11, 2009 at 6:52 pm |
462. Ergodic perspective.
Terry, thanks for that useful summary. I think it’s helped me to understand the ergodic side of things better. Let me test that, chiefly for my own benefit, by trying to put part of it in my own words. The idea would be that you take a random copy of![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) in
in ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) and intersect it with
and intersect it with  . If you do that, then instead of a function from
. If you do that, then instead of a function from ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) to
to  you’ve got a Bernoulli random variable at each point of
you’ve got a Bernoulli random variable at each point of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) , which is 1 with probability
, which is 1 with probability  (the density of
(the density of  ) and 0 with probability
) and 0 with probability  .
.
At first it seems as though one has gained precisely nothing by doing this. For example, here’s a way of obtaining some random variables: you take a dense set![\mathcal{B}\subset [3]^m](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D%5Csubset+%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) , and for each permutation
, and for each permutation  of
of ![{}[m]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002) you let
you let  be the set of sequences you get by taking a sequence in
be the set of sequences you get by taking a sequence in  and using
and using  to permute its coordinates. Then the probability that the random set
to permute its coordinates. Then the probability that the random set  contains a combinatorial line is trivially the same as the probability that
contains a combinatorial line is trivially the same as the probability that  contains a combinatorial line (and moreover the expectation of the characteristic function of
contains a combinatorial line (and moreover the expectation of the characteristic function of  is
is  ).
).
However, the point is that if you know that the random set![\mathcal{B}\subset[3]^m](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D%5Csubset%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) comes from random restrictions of a much larger set
comes from random restrictions of a much larger set ![\mathcal{A}\subset[3]^n](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BA%7D%5Csubset%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) , then you will be very surprised if with probability 1 it is always obtained from some fixed set by a simple permutation of the coordinates. A phenomenon like that would have the potential to show that
, then you will be very surprised if with probability 1 it is always obtained from some fixed set by a simple permutation of the coordinates. A phenomenon like that would have the potential to show that  has some very strange and exploitable structure. More generally, if the elements of the random set exhibit significant dependences, this should come from structure in
has some very strange and exploitable structure. More generally, if the elements of the random set exhibit significant dependences, this should come from structure in  , and if they are independent then as you point out you get a combinatorial line.
, and if they are independent then as you point out you get a combinatorial line.
If that sketch is not too wide of the mark, then I see that extreme localization of the kind you propose does potentially give you quite a lot of extra resources. And given that the ergodic-theory proof is known to work it is always encouraging if one’s argument has formal similarities with it. My feeling about slices-equal is that it’s a bit of a long shot, but it might be possible to get away without that extra power and obtain a stronger result as a consequence. But if that doesn’t work out, then we know that we’ve got localization to fall back on. Or we could have two parallel threads, one exploring a global approach and one a local approach. This one is already getting to the point where it takes a boring amount of time to load on to my computer, and the 300s thread seems to have come to a standstill for now.
Incidentally, it occurs to me that we as a collective are doing what I as an individual mathematician do all the time: have an idea that leads to an interesting avenue to explore, get diverted by some temporarily more exciting idea, and forget about the first one. I think we should probably go through the various threads and collect together all the unsolved questions we can find (even if they are vague ones like, “Can an approach of the following kind work?”) and write them up in a single post. If this were a more massive collaboration, then we could work on the various questions in parallel, and update the post if they got answered, or reformulated, or if new questions arose.
February 11, 2009 at 7:01 pm |
463. Speaking of ergodic theory:
If anyone’s interested in reading the ergodic
proof for k=3, we’ve been discussing it in seminar
in Memphis; the proof can be found on my webpage.
(You need the 1989 paper of Furstenberg and Katznelson,
in which the proof is set up but not given, too; that’s
on Katznelson’s webpage.) It’s far less intimidating
than the general proof as given in their 1991 paper.
Is there a proof (of the kind you guys are looking for)
of the IP Szemeredi theorem for k=3? That would seem
to be logically prior.
February 11, 2009 at 7:23 pm |
464. Varnavides.
Something I’ve been meaning to do for quite a while is prove, or at least sketch a proof, that a Varnavides-type statement holds for the slices-equal measure. I don’t think it’s going to be hard, but I want to check it to be sure. (It is supposed to be another argument in favour of slices-equal, though I can see that the local approach gives a local Varnavides statement, so it’s not an argument that slices-equal is more natural than localization, but it is an argument that slices-equal is more natural than a global uniform approach.)
Let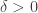 , and let
, and let  be large enough that every subset of
be large enough that every subset of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) of density at least
of density at least 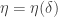 contains a combinatorial line. (Here,
contains a combinatorial line. (Here,  is a constant to be chosen later.) Now choose a small constant
is a constant to be chosen later.) Now choose a small constant  (depending on
(depending on  ) and embed
) and embed ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) randomly into
randomly into ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as follows. First pick
as follows. First pick  integers
integers 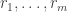 independently, randomly and uniformly from
independently, randomly and uniformly from  . Next, randomly pick disjoint sets
. Next, randomly pick disjoint sets 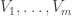 , with
, with  . Finally, randomly assign 1s, 2s and 3s to the complement of the union of the
. Finally, randomly assign 1s, 2s and 3s to the complement of the union of the  . Sorry, I don’t mean that. I mean that you randomly choose
. Sorry, I don’t mean that. I mean that you randomly choose  and then you randomly assign
and then you randomly assign  1s,
1s,  2s and
2s and  3s to the coordinates in the complement of the union of the
3s to the coordinates in the complement of the union of the  . And now define a
. And now define a  -dimensional combinatorial subspace by fixing the coordinates outside the
-dimensional combinatorial subspace by fixing the coordinates outside the  according to the random assignment of 1s, 2s and 3s, and taking all possible
according to the random assignment of 1s, 2s and 3s, and taking all possible 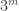 assignments to the rest of the coordinates that are constant on the
assignments to the rest of the coordinates that are constant on the  . (Since
. (Since  is constant, I don’t think it matters if one does this uniformly, but I would prefer to do even this in a slices-equal way. That is, I choose
is constant, I don’t think it matters if one does this uniformly, but I would prefer to do even this in a slices-equal way. That is, I choose 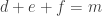 randomly and then I randomly choose
randomly and then I randomly choose  of the sets
of the sets  to get a 1, etc.)
to get a 1, etc.)
There are a few statements that I don’t immediately see how to argue for without going away and doing calculations. I claim that there is some constant such that the proportion of copies that intersect
such that the proportion of copies that intersect  in a density of at least
in a density of at least  is at least
is at least  . I also claim that no combinatorial line is significantly more likely than average to belong to a copy. And from that I claim that a double-count gives that a random combinatorial line has a probability depending on
. I also claim that no combinatorial line is significantly more likely than average to belong to a copy. And from that I claim that a double-count gives that a random combinatorial line has a probability depending on  only of belonging to
only of belonging to  .
.
I might try to think about justifying those statements a bit better.
February 11, 2009 at 7:56 pm |
465. Hyper-optimistic conjecture
Terry, re last paragraph of 459, it occurs to me that with your upper-and-lower-bounds thread you may already know that the hyper-optimistic conjecture is false. Do you know of any example that beats the best example that’s constant on slices?
February 11, 2009 at 9:13 pm |
466. Various
Randall, thanks for the pointer to your notes (which, incidentally, are at http://www.msci.memphis.edu/~randall/preprints/HJk3.pdf ). I will try to digest them.
It looks like it is indeed soon time to close this thread and open some new ones. I can host a thread on ergodic-flavoured combinatorial approaches, focusing on my localisation approach and also on trying to explicate the Furstenberg-Katznelson proof of DHJ (I am imagining some internet version of a “reading seminar”). Then I guess Tim could try to summarise the other main active thread (based on obstructions to Sperner, etc.; my approach, incidentally, doesn’t seem to directly need to understand Sperner obstructions, though it does need to understand the closely related concept of low influence).
I will also try to translate the hyper-optimistic conjectures 455, 459 to something that the 200-299 thread can chew on. Gil, can you explain your conjecture in 455 in more detail? I’m afraid I didn’t really get it (e.g. I don’t know what a “block” or a “fractional covering” is).
As for all the “background” of discarded questions (e.g. the IP-Szemeredi thing Randall mentioned was already brought up all the way back in Jozsef’s comment 2)… here I think this is a job that requires more manpower than we have right now, since the “foreground” threads are already keeping all of us very busy. It also feels like this stuff would be better placed in something like a wiki than in a blog thread. I would say for now that we just continue the “active” threads for now and leave the trawling through the remainder for a later point in time if our current active threads get stuck.
February 11, 2009 at 9:18 pm |
467. Various cont.
Actually, what I might do is set up a Google Document to hold random threads, questions, etc. that can be collaboratively edited. This has worked pretty well for the 200-299 thread so far.
Here’s one little tidbit from that thread which might be useful here. Currently, the best for which we can combinatorially prove DHJ(3) is 0.633. Thus, for instance, we don’t know without ergodic theory that if one takes 60% of
for which we can combinatorially prove DHJ(3) is 0.633. Thus, for instance, we don’t know without ergodic theory that if one takes 60% of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) for large n, that one gets a combinatorial line. So, if one wants to play with a quantitative value of delta: take 0.6.
for large n, that one gets a combinatorial line. So, if one wants to play with a quantitative value of delta: take 0.6.
We also have an example of a subset of![{}[3]^{99}](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E%7B99%7D&bg=ffffff&fg=333333&s=0&c=20201002) of density >1/3 that still has no combinatorial line. So even with moderately enormous dimension, it is not possible to handle delta=1/3.
of density >1/3 that still has no combinatorial line. So even with moderately enormous dimension, it is not possible to handle delta=1/3.
February 11, 2009 at 10:04 pm |
468. Ergodic perspective
Re Tim’s 462: yes, this is one way of thinking about the ergodic perspective, as providing a inter-related (and presumably correlated) network of Bernoulli random variables (aka “events”), and the game is to get enough control on how these events overlap each other that one can eventually find a line of three events which are simultaneously satisfied with positive probability.
By the way, another distinction between the three approaches lies in the range of m to pick, a point which has already been alluded to by Tim (when referring to my approach as “extreme localization”). In my approach I am picking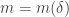 to just depend on
to just depend on  (in fact I think I may be able to take a very concrete m, e.g.
(in fact I think I may be able to take a very concrete m, e.g.  ). In the ergodic approach,
). In the ergodic approach,  is a very slowly growing function of n (so in the limit, m is infinite). For Tim’s approach, one can take m close to
is a very slowly growing function of n (so in the limit, m is infinite). For Tim’s approach, one can take m close to  (or anything smaller, so long as it is still sufficiently large depending on
(or anything smaller, so long as it is still sufficiently large depending on  ).
).
February 11, 2009 at 10:30 pm |
469. IP Roth:
Just to be clear on the formulation I had in mind (with apologies for the unprocessed code) [now processed — Tim]: for every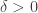 there is an
there is an  such that any
such that any ![E\subset [n]^{[n]}\times [n]^{[n]}](https://s0.wp.com/latex.php?latex=E%5Csubset+%5Bn%5D%5E%7B%5Bn%5D%7D%5Ctimes+%5Bn%5D%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) having relative density at least
having relative density at least  contains a corner of the form
contains a corner of the form  . Here
. Here  is the coordinate basis for
is the coordinate basis for ![{}[n]^{[n]}](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D%5E%7B%5Bn%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) , i.e.
, i.e. 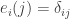 .
.
Presumably, this should be (perhaps much) simpler than DHJ, k=3.
February 11, 2009 at 10:45 pm |
469. Hyper-optimistic conjecture
Ah, I see now that Gil’s conjecture is a weakening of Tim’s conjecture in which one takes a different measure on the space of slices than the uniform measure. As Tim’s is more concrete, that’s the one I’ve posted on the 200-299 thread to be tested for small n.
February 11, 2009 at 11:27 pm |
470. Google document
OK, I’ve set up a repository for unsolved questions for Polymath1 at
http://docs.google.com/Doc?id=dhs78pth_15dfw8jhz4
Unlike the spreadsheet over at 200-299, I can’t make this editable by the general public (I suppose there are security risks in documents that are not present in spreadsheets), but I’ll add Tim as a “collaborator”, and anyone else who asks can have permission to edit it also.
February 11, 2009 at 11:54 pm |
471. Re Terry’s strategy (#439).
Hi Terry, could you help me understand the strategy a bit in the case that is, say, the set of strings in
is, say, the set of strings in 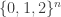 whose 0-count is congruent to 0 mod
whose 0-count is congruent to 0 mod 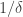 ? (Assume
? (Assume  is an integer.)
is an integer.)
I’m worried about the first concentration of measure statement. Or does this set already have some exploitable blatant structure — perhaps being a 1-sub-basic complexity set?
Thanks!
February 12, 2009 at 12:23 am |
472. Terry’s strategy 439
It’s true, the first concentration of measure statement breaks down; either all the lie in
lie in  (when the number of 0s in x is equal to m mod
(when the number of 0s in x is equal to m mod 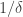 ) or none of them do.
) or none of them do.
But it turns out we don’t really need that particular concentration, it’s enough to have a lot of in
in  with positive probability, which is true from the first moment method.
with positive probability, which is true from the first moment method.
A more necessary concentration of measure is the assertion that the density of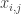 that lie in
that lie in  is close to
is close to  . In this particular case, this is true: the set of pairs
. In this particular case, this is true: the set of pairs  with
with  is given by
is given by 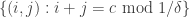 , where c is some constant depending on m and x.
, where c is some constant depending on m and x.
The second moment method tells us that we can get some concentration of measure (enough for our purposes, in fact) as soon as we have small pairwise correlations between the events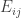 , which are the events that
, which are the events that  . Now, in your example, there are extreme pair anti-correlations: for instance,
. Now, in your example, there are extreme pair anti-correlations: for instance, 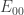 and
and  are never simultaneously true. To put it another way, if we take an element in
are never simultaneously true. To put it another way, if we take an element in  and flip a 0 to 1, we always leave
and flip a 0 to 1, we always leave  as a consequence.
as a consequence.
This is certainly some sort of structure. But can we exploit it? Well, one thing I was thinking of is that in the setup in 439, the m different generators of the embedded m-dimensional cube are just single basis vectors; to put it another way, I’m playing with a string with m distinct wildcards, with each wildcard being used exactly once. But one could instead have each of the m wildcards appear r times (or a Poisson number of times, or whatever), e.g. picking
of the embedded m-dimensional cube are just single basis vectors; to put it another way, I’m playing with a string with m distinct wildcards, with each wildcard being used exactly once. But one could instead have each of the m wildcards appear r times (or a Poisson number of times, or whatever), e.g. picking 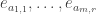 at random and defining
at random and defining
Then the correlation between, say, and
and  relates to what happens when one flips r 0s to 1s, rather than just a single 0 to 1. This continues to be negatively correlated until r hits
relates to what happens when one flips r 0s to 1s, rather than just a single 0 to 1. This continues to be negatively correlated until r hits 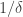 (or a multiple thereof), at which point the correlation shoots up to be massively positive and in fact we find an abundance of combinatorial lines.
(or a multiple thereof), at which point the correlation shoots up to be massively positive and in fact we find an abundance of combinatorial lines.
So we probably have to average over the “dilation” scale r rather than just set it equal to 1 as is done currently. (Much like with the corners problem: it’s not enough to look for corners of size 1, or any other fixed size, but we must average over the length r of the corner. Actually, one should probably let each of the m wildcard symbols appear a different number of times, e.g. assign a Poisson process to each.) In the current example, averaging r over any range significantly larger than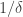 will eliminate pair correlations. In fact, if one allows each wildcard symbol to have an independent number of occurrences, triple correlations such as between
will eliminate pair correlations. In fact, if one allows each wildcard symbol to have an independent number of occurrences, triple correlations such as between 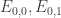 and
and  also seem to vanish, which incidentally yields combinatorial lines already (since
also seem to vanish, which incidentally yields combinatorial lines already (since 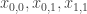 form a line).
form a line).
February 12, 2009 at 12:47 am |
Metacomment.
Just briefly on the subject of new threads, I’m not completely convinced that the multiple-threads idea has worked. Or rather I think it has partially worked. It seems that the upper-and-lower bounds thread was sufficiently separate that it has thrived on its own. But the experience of the other two threads was that once the 400 thread was opened the 300 thread died pretty rapidly. (Actually, at some point I wouldn’t mind revisiting it, but that’s not my main point.) So in effect we’ve just had one linear thread, but at any given moment we’ve been reasonably focused and not had too many different discussions going on at once.
As a result, I’m not sure that splitting up into a global thread and a local thread is a good idea. I think that many of the ideas for one approach are likely to be relevant to the other, and I also think it is possible for the two discussions to coexist. I think the one thing I might suggest (but I’d be interested in other people’s opinion on this and everything else) is that we should restrict the number of comments further. An advantage of the multiple threads was that we had multiple summaries: I think it would be quite good to be forced to summarize more often. Also, a number of people have commented that it is difficult to catch up with the discussion if you come to it late. We should try to start each thread in a way that makes it as self-contained as possible. (I think it is legitimate to expect people to read the posts, but we should try not to force them to wade through hundreds of comments.)
February 12, 2009 at 1:08 am |
473. Obstructions.
Something I want to think about, but won’t be able to think about tonight as I’m going to have to stop this soon, is whether it is possible to put together a lot of local obstructions to get a global one. What I mean is this. Let us regard a point in![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as a pair of disjoint sets (A,B) (which are the 1-set and 2-set of a sequence). Suppose that an argument of the Cartesian semi-products variety (see Terry 413) can be used to prove that for a large number of sets H (in the slices-equal measure) you get unexpectedly many 4-cycles, by which I mean quadruples (A,B), (A,B’), (A’,B’), (A’,B) of points with all four sets contained in H. (Here H would in fact arise as the complement of some set C.) Just to make my question a bit more concrete, let me go for an extreme statement and suppose that what actually happens is that for many H you have two systems
as a pair of disjoint sets (A,B) (which are the 1-set and 2-set of a sequence). Suppose that an argument of the Cartesian semi-products variety (see Terry 413) can be used to prove that for a large number of sets H (in the slices-equal measure) you get unexpectedly many 4-cycles, by which I mean quadruples (A,B), (A,B’), (A’,B’), (A’,B) of points with all four sets contained in H. (Here H would in fact arise as the complement of some set C.) Just to make my question a bit more concrete, let me go for an extreme statement and suppose that what actually happens is that for many H you have two systems  and
and  of subsets of
of subsets of  such that there are many disjoint pairs
such that there are many disjoint pairs  and they are all points in the original dense set. (In previous terminology, I want to suppose that many sets
and they are all points in the original dense set. (In previous terminology, I want to suppose that many sets  contain a large Kneser product.) Can we somehow piece together these set systems
contain a large Kneser product.) Can we somehow piece together these set systems  and
and  to obtain set systems
to obtain set systems  and
and  such that the set of disjoint pairs
such that the set of disjoint pairs  correlates with the original dense subset of
correlates with the original dense subset of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) ?
?
If the answer is no, I feel it ought to be obviously no: you would just more or less randomly choose your and
and  . But if for some reason that turns out to be difficult (because there is too much overlap and in order to get compatibility on the overlap you are forced to relate the various
. But if for some reason that turns out to be difficult (because there is too much overlap and in order to get compatibility on the overlap you are forced to relate the various  to each other and similarly the
to each other and similarly the  ) then perhaps you can get from local to global in the way I would like.
) then perhaps you can get from local to global in the way I would like.
I’m not sure how easy it would be to prove a lemma of the desired kind, but I’m hoping it will be easyish to decide whether anything like that has a chance of being true. And now it’s bedtime.
February 12, 2009 at 1:21 am |
Metacomment
I guess the number of active threads is, in practice, bounded by the number of distinct groups of active participants. The participants in the 200 thread are largely disjoint from those in the 300 and 400 threads, but the 300 and 400 participants have been basically the same, so the 400 thread has basically served as an update to the 300 thread.
Perhaps we can still have two threads: one thread (the 500 thread?) would be the local and global approaches to the problem, and another thread, which I could host, would be a slower-paced “reading course” on the ergodic proof of k=3 DHJ, presumably using Randall’s notes as a guide. This would probably proceed by different rules than the existing threads, since the aim is now to understand a paper rather than to solve a problem (I will have to think about what the ground rules of such a reading course would be). But I would imagine that the readership here would be a bit disjoint from the one in the “mainstream” threads – in particular, I expect more ergodic theorists to participate – and so should be able to operate independently.
February 12, 2009 at 1:25 am |
474.
Re Terry’s metacomment — that all sounds pretty sensible to me, so let’s do it unless someone comes up with an objection to the plan in the near future.
Re 473, I just wanted to add (in case there was any misunderstanding) that when I counted quadruples above, it was with slices-equal measure, so you couldn’t say things like that almost all the sets A and B had roughly the same size, etc. etc.
February 12, 2009 at 1:41 am |
475. Obstructions.
Thinking about it a bit further, I now think 473 is true and not that hard. More details tomorrow if I wake up in a similar frame of mind.
February 12, 2009 at 1:51 am |
476. A Fourier approach to Sperner. (This would probably make more sense in the 300’s thread, but I concur with Tim’s #472.5.)
I was thinking about Terry’s approach and his #472. (Thanks for that, btw; I agree that the second concentration of measure is the important one and that it holds in my simple example.) More specifically, I was trying to think about the “structure” of the pairs (half-lines, as I was calling them in #134). This led me to think again about a Fourier approach to Sperner. Not sure if it has any relevance at all to DHJ(3), but I thought I’d throw it out there.
(half-lines, as I was calling them in #134). This led me to think again about a Fourier approach to Sperner. Not sure if it has any relevance at all to DHJ(3), but I thought I’d throw it out there.
One difficulty with such an approach (discussed already in comments #29–#37) is that it’s not immediately clear how to come up with a good distribution on pairs with
with  . But I think Terry’s idea of localising quite severely — to “constant” distances like
. But I think Terry’s idea of localising quite severely — to “constant” distances like 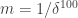 — is very promising.
— is very promising.
Since things are always better in Fourier-land when one uses a product distribution, I suggest the following:
Let denote
denote  . Let
. Let 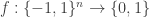 be the indicator of a subset
be the indicator of a subset ![\mathcal{A} \subseteq [2]^n](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BA%7D+%5Csubseteq+%5B2%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) of density
of density  . Jointly choose a pair of strings
. Jointly choose a pair of strings 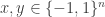 as follows:
as follows:
For each coordinate , independently:
, independently: , set
, set  a random
a random  bit.
bit. , set
, set 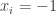 ,
, 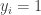 .
. and
and  with probability
with probability  .
.
. with probability
. with probability
Finally, reverse the roles of
Under this distribution, certainly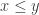 or vice versa always, with the distance between them being distributed roughly as Poisson(m). The strings
or vice versa always, with the distance between them being distributed roughly as Poisson(m). The strings  and
and  are not uniformly distributed (which is annoying) but they are nearly so assuming
are not uniformly distributed (which is annoying) but they are nearly so assuming  small.
small.
To be continued in the next post. (PS: sorry, I guess I’m violating the “Don’t calculate on scratch paper” rule.)
February 12, 2009 at 1:52 am |
477. A Fourier approach to Sperner. (cont’d)
If one does the usual Fourier analysis thing, one gets that the probability of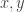 both in
both in  equals
equals
where is 0 if
is 0 if  is odd, and is
is odd, and is  otherwise, depending on the parity of
otherwise, depending on the parity of  .
.
I believe (and feel free to press me on this) that with some linear/matrix algebra, one can show that this expression is approximately
where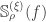 is the “noise stability of
is the “noise stability of  at
at  under the
under the  -biased distribution”.
-biased distribution”.
This post is getting long, so let’s say this is roughly something like![\mathbb{E}[f(u)f(v)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28u%29f%28v%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  is a random string and
is a random string and  is formed by flipping each coordinate of
is formed by flipping each coordinate of  with probability
with probability  . Rather like the original distribution, but note that
. Rather like the original distribution, but note that  and
and  are likely incomparable.
are likely incomparable.
Even if you buy my calculations, you may ask what this has bought. I guess it’s that this noise stability is a fairly well understood quantity, so we pretty much know exactly what kind of have this quantity near
have this quantity near  , what kind of
, what kind of  have this quantity near
have this quantity near 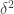 , etc.
, etc.
February 12, 2009 at 3:56 am |
478. Reading seminar
I’ve begin a “reading seminar” on the ergodic proof of DHJ at
No idea how lively it will be, but I will try to “read aloud” my way through paper #1 at least, and see if anyone jumps in to help out. I expect the pace to be slower than on these threads.
February 12, 2009 at 5:26 am |
479. Followup to #472.
Hmm, what if the set is just the strings whose plurality digit is 0? This will very likely have either all or none of the
is just the strings whose plurality digit is 0? This will very likely have either all or none of the  ‘s in
‘s in  , if I’m not mistaken. Of course, being “monotone” this set has plenty of structure; I’m just wondering what we’re seeking.
, if I’m not mistaken. Of course, being “monotone” this set has plenty of structure; I’m just wondering what we’re seeking.
Indeed, there are Boolean functions (see “The Influence of Large Coalitions” by Ajtai and Linial) where every subset of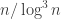 coordinates has negligible “influence” — meaning, almost surely the function is determined as soon as you fix the other
coordinates has negligible “influence” — meaning, almost surely the function is determined as soon as you fix the other 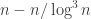 coordinates randomly. These should be easy to adapt to the
coordinates randomly. These should be easy to adapt to the ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) setting.
setting.
February 12, 2009 at 6:28 am |
480. Reply to #479
Yeah, that’s a pretty blatant violation of concentration of measure. But the plurality set you give has very low influence, and as such it is very easy to create combinatorial lines (or even moderately large combinatorial subspaces) – just pick a random element in
you give has very low influence, and as such it is very easy to create combinatorial lines (or even moderately large combinatorial subspaces) – just pick a random element in  and jiggle one or more of the coordinates, and with high probability you’ve created a combinatorial line in
and jiggle one or more of the coordinates, and with high probability you’ve created a combinatorial line in  .
.
Low influence, as we’ve said before, leads to an “instant win” for us. Almost as instant a win is near-total “01-insensitivity”, which is like low influence but restricted to swapping 0 and 1, rather than the full range of swapping 0, 1, and 2. I discussed this in 451. In terms of the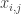 , this type of insensitivity is basically the same as saying that the event
, this type of insensitivity is basically the same as saying that the event  is almost maximally positively correlated with
is almost maximally positively correlated with  .
.
What I don’t understand well yet, though, is what happens when there is a smaller amount of positive correlation; this gives a little bit of insensitivity, but not so much that the argument in 451 immediately applies. A typical example here might be a random subset of, say, the set in 479. Maybe some sort of “regularity lemma” describes all moderately-correlated sets as unions of random subsets of very highly correlated (and thus very structured and low-influence or insensitive) sets?
February 12, 2009 at 6:31 am |
Metacomment.
Michael Nielsen has kindly transplanted the google document above to a Wiki format, where it really can be edited by everyone, and which allows for LaTeX support, creation of subpages, etc:
http://michaelnielsen.org/polymath1/index.php?title=Main_Page
So I guess this can serve as the “background” repository for the project, to complement the “foreground” threads here and on my blog.
(We’re also running out of numbers on this thread… time to start the 500 thread soon!)
February 12, 2009 at 7:03 am |
480. Z_k Roth:
I’d like to propose a further simplification of the problem, motivated by Gowers’ observations in post 31. Here it is: For all $\delta>0$, there is an $n$ such that any $E\subset {\bf Z}_3^n$ having relative density at least $\delta$ contains a configuration $\{a,a+\sum_{i\in \alpha} e_i,a+2\sum_{i\in \alpha} e_i\}$, where $e_i=(0,0,\ldots ,0,1,0,\ldots ,0)$, the “1” occurring in the $i$th place. (Addition is modulo 3.)
I will assume no decent quantitative version of this is known. (If I’m mistaken, the following may be ignored.)
This is stronger than just getting $\{a,a+b,a+2b\}$ for some $b\in {\bf Z}_3^n$, which, if I understand things properly, one could obtain via Roth’s density increment method. And, indeed, the set $A$ mentioned in post 31, the one which has sequences where the number of 0s, 1s and 2s all multiples of 7, will contain too many of these configurations.
On the other hand, the ergodic story suggests (heuristically, at least) that restrictions may come into play under “quadratic” Fourier analysis (perhaps modulo some normalization of some kind). The basis for this heuristic is the existence of an ergodic proof of the result (never written down) in which a compact extension of the Kronecker factor is shown to be characteristic. (This is dramatically different from DHJ or even IP Roth, where I should think no distal factor would be characteristic, suggesting that perhaps no degree of $\alpha$-uniformity would yield constraints on the number of configurations.)
This is only a heuristic, but the implication seems to be that perhaps the above mentioned result is at the approximate level of “depth” of existence of progressions of length 4 in sets of positive density in ${\bf N}$. And, if all this is right, that it’s the sort of problem that might be attacked by familiar methods.
February 12, 2009 at 9:49 am |
481. Various types of slices and ultra-optimism
My UO conjecture meant to be an extension of the LYM inequality which is stronger than just saying that maximum untichain is the maximum slice. Here we have various slices and we can conjecture that the maximum size of a line-free set is attained at the union of slices (which do not contain a line). We can also conjecture (as Tim’s) that the maximum measure (when every slice has the same overall measure) for line-free set is attained with union of slides. (This reduces to LYM for the sperner case.) I think that my conjecture (or at least what I meant) is a bit stronger. Unlike the Sperner case there are many ways to cover or fractionally cover all slices by line-free union of slices.
Now there are several meanings for “slices”. The coarser is $\latex \Gamma_{a,b,c}$ but there are finer ones. One finer one is to associate to each word in ‘0’ and ‘1’ the slice
in ‘0’ and ‘1’ the slice  of all words of length n in 0 1 2 that if you arase the 2s you get
of all words of length n in 0 1 2 that if you arase the 2s you get  .
.
We can ask if the ultra optimistic conjecture for line-free sets is true for union of slices $\latex \Gamma_w$. (This seems a feasible problem.)
We can also talk together about such slices in all 3 directions.
There is an even finer division to slices. Consider all triples of words in 0-2 and 1-2 respectively. Than let
in 0-2 and 1-2 respectively. Than let 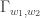 be all words of length n in 012 s.t. when you delete 2 you get
be all words of length n in 012 s.t. when you delete 2 you get 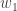 and when you delete 1 you get
and when you delete 1 you get 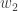 . We can ask if blocks in finer slices gives us better examples than blocks in courser slices.
. We can ask if blocks in finer slices gives us better examples than blocks in courser slices.
(If yes, we can update our ultra optimistic conj.) (Again you can take slices in all 3 possible “directions”).
February 12, 2009 at 10:03 am |
482.
Randall, your question sounds a bit like that of looking for progressions of length 3 whose difference is one less than a prime, which was tackled by Bergelson-Host-Kra using the nilsequences machinery and the Gowers norms. My guess is that a similar approach would work for your problem, though I didn’t check it.
Gil, I am still having trouble understanding the precise formulation of your conjecture. For instance, what does “fractionally cover” mean? And what is a “block”? Also, what does “erase” or “delete” mean – are you compressing the deleted string, so that for instance deleting 1 from 012 gives you 02? It all sounds quite interesting, but I am afraid I may have to see a formal statement of the conjecture in order to understand it properly.
February 12, 2009 at 10:03 am |
Regarding influences which were mentioned in several comments. It looks that indeed examples with unusual number of lines has unusual (compared to random examples) influence, but it does not look clear how such a property can be exploited to lead to higher density subspaces. So I am not sure if influence would be a useful notion in attacking the problem at hand. But there may be some useful analogies between problems about influences and about finding lines of various types.
When we talk about influence we look at a projections: we look at a subspace describe by a subset of the coordinates (but maybe we can also talk about different notions of subspace for some appropriate notion of “projection” ) and consider the projection of our set to this subspace. For our problem we are more interested in the intersection of our set with various subspaces.
February 12, 2009 at 10:11 am |
484. clarification for slices, also seconding Ryan
Dear Terry,
yes deleting 1 from 012 gives you 02 and from 011220212012
gives you 0220202,
a block of slices is the union of different slices (in our original notion as in the refined ones when you talk only about one direction the slices are disjoint)
(We are only interested in line-free blocks)
We say that a colloection of block of slices covers if every point in
if every point in  is contained in one (or more) of them.
is contained in one (or more) of them.
A fractional collection of blocks is assigning a nonnegative number to every block.
A fractional cover is a fractional collection where for every the sum of weights for blocks containing it is at least 1.
the sum of weights for blocks containing it is at least 1.
Also, I second Ryan that giving analogs to Ajtai-Linial examples may be useful for our problem and perhaps also for the cap set problem. (I will try to explain why sometime later.)
February 12, 2009 at 1:23 pm |
485. Uniformity norms
This is an attempt to push forward in a small way a strategy for a global density-increment strategy. I would like to find a norm on functions from![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) to
to  with the property that if
with the property that if  is small then the expectation of
is small then the expectation of  over all combinatorial lines is small, and if
over all combinatorial lines is small, and if  is large then one can find a structured set on which the average of
is large then one can find a structured set on which the average of  is positive and bounded away from 0. If we’ve got these two properties, then it should be pretty easy to finish the proof.
is positive and bounded away from 0. If we’ve got these two properties, then it should be pretty easy to finish the proof.
Here is my imprecise proposal for such a norm. In fact, it’s imprecise to the extent that it may well not even be a norm: the idea would be to massage the details until it is. I’ll just draw it out of a hat, but of course it hasn’t sprung out of nowhere. It comes from a mixture of various sources: analogies with corners, and also the kinds of things that were coming out of my calculations at the beginning of the 400s, and also Terry’s Cartesian semi-product thoughts.
In all the density-increment proofs we know where the obstructions are of a simplicity that we expect for DHJ(3), a key concept is something like a rectangle: for Roth’s theorem it’s a quadruple , for Shkredov it’s
, for Shkredov it’s 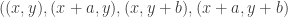 , and for bipartite graphs it’s a 4-cycle
, and for bipartite graphs it’s a 4-cycle  . What would be the obvious quadruples to look at here? Well, we know that we can think of a subset
. What would be the obvious quadruples to look at here? Well, we know that we can think of a subset ![\mathcal{A}\subset{}[3]^n](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BA%7D%5Csubset%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) as a bipartite graph: its elements are pairs of sets
as a bipartite graph: its elements are pairs of sets  such that there exists
such that there exists  such that
such that  is the 1-set of
is the 1-set of  and
and  is the 2-set of
is the 2-set of  . So a natural suggestion (if you don’t think too hard about it) for a norm to put on a function
. So a natural suggestion (if you don’t think too hard about it) for a norm to put on a function  is
is
where the expectation is over all quadruples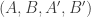 such that the above four pairs are disjoint pairs. (We don’t need complex
such that the above four pairs are disjoint pairs. (We don’t need complex  but if we did then we’d put bars over the second and fourth terms in the product.)
but if we did then we’d put bars over the second and fourth terms in the product.)
What are some immediate objections to this? Well, given such a quadruple, each element has seven possibilities: it can belong to up to two of the four sets but cannot belong to both an
but cannot belong to both an  and a
and a  . Therefore, a random such quadruple is obtained by randomly partitioning
. Therefore, a random such quadruple is obtained by randomly partitioning ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) into seven parts and choosing the first one to be disjoint from all four sets, the second one to be in just
into seven parts and choosing the first one to be disjoint from all four sets, the second one to be in just  , and so on. In particular, the set that’s disjoint from all of them has cardinality very close to
, and so on. In particular, the set that’s disjoint from all of them has cardinality very close to 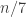 with very high probability, so it’s got nothing much to do with combinatorial lines.
with very high probability, so it’s got nothing much to do with combinatorial lines.
But not so fast. This is uniform-measure speak rather than slices-equal speak,a nd I’m a slices-equal person. If slices are equal, then the fact that is disjoint from
is disjoint from  has a much smaller bearing on their cardinalities. (It does have some effect, but it’s just not a big deal.)
has a much smaller bearing on their cardinalities. (It does have some effect, but it’s just not a big deal.)
So we have no a priori reason to reject this norm. In the next comment I’ll try to argue (as much to myself as to anyone else) that it’s actually good for something.
February 12, 2009 at 1:51 pm |
486. Uniformity norms.
Now for a small technical comment. Suppose we take the subset of consisting of all points
consisting of all points  such that
such that  and
and  . This is an isosceles right-angled-triangular chunk of the integer lattice. And now suppose we try to investigate functions on this set using a box norm (that is, averaging expressions like
. This is an isosceles right-angled-triangular chunk of the integer lattice. And now suppose we try to investigate functions on this set using a box norm (that is, averaging expressions like  We will have a little bit of trouble with this because some points are contained in lots of boxes and some in hardly any. So what we might decide to do instead is a modest localization: choose some square patch of the triangle where the set we are interested in is dense.
We will have a little bit of trouble with this because some points are contained in lots of boxes and some in hardly any. So what we might decide to do instead is a modest localization: choose some square patch of the triangle where the set we are interested in is dense.
We have essentially this problem with a uniformity norm for DHJ if we use the slices-equal measure. To combat it, I want to apologize to the number 3 and lose some symmetry. Recall (or prove as a very easy exercise) that DHJ(3) is equivalent to the following problem: if you have a dense set of pairs
of pairs  of disjoint subsets of
of disjoint subsets of ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) then you can find disjoint sets
then you can find disjoint sets  such that
such that  ,
, 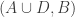 and
and 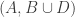 all belong to
all belong to  . I’m going to focus on this version of the statement, but with the added stipulation that the cardinalities of
. I’m going to focus on this version of the statement, but with the added stipulation that the cardinalities of  and
and  are both at most
are both at most  , so that I have a square grid of slices. All the time, I need hardly add, we use slices-equal measure. So a random point in the space is obtained by choosing two random numbers
, so that I have a square grid of slices. All the time, I need hardly add, we use slices-equal measure. So a random point in the space is obtained by choosing two random numbers  and
and  that are at most
that are at most  and then a random pair of disjoint sets
and then a random pair of disjoint sets  and
and  of sizes
of sizes  and
and  .
.
Unfortunately I have to go while I’ve still got a lot to say, and won’t have a chance to add to this for about nine hours, if not more. Anyhow, the next step is to try to do a sort of Sperner-averaging style lift to get from the usual proof that the box norm controls the number of corners to a proof that the above attempt at a uniformity norm controls the number of set-theoretic corners. And if that works, I’d like an inverse theorem for the uniformity norm to tell us that we’ve got a 411-style obstruction.
February 12, 2009 at 5:31 pm |
487. Uniformity norm.
Another technical point. In order to define a norm, we need that expression to be non-negative (and zero only if is zero). To get that we can do the following. For convenience define
is zero). To get that we can do the following. For convenience define  to be zero if
to be zero if  and
and  intersect. Then define the norm as follows. First pick a random permutation. Then take the average of
intersect. Then define the norm as follows. First pick a random permutation. Then take the average of 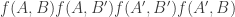 over all quadruples of intervals in the permuted
over all quadruples of intervals in the permuted ![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is then easily seen to have the positive definiteness that one wants. Does it matter that we are now averaging over lots of intersecting pairs of sets? Not really, because the intersecting pairs are given a lot less weight (because intervals, on average, intersect far less frequently than random sets of the same size).
. This is then easily seen to have the positive definiteness that one wants. Does it matter that we are now averaging over lots of intersecting pairs of sets? Not really, because the intersecting pairs are given a lot less weight (because intervals, on average, intersect far less frequently than random sets of the same size).
So this is my revised candidate for a uniformity norm (perhaps with some restriction on the sizes of the sets involved — I’m not sure that matters much any more though).
February 13, 2009 at 12:24 am |
488. Terry’s strategy #439.
I’m still slowly plugging through that post… 🙂
Perhaps it’s not necessary to show that the second concentration of measure (for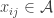 ) holds *because* of small pairwise correlations between the events. For example, it holds anyway in the case of the “mod
) holds *because* of small pairwise correlations between the events. For example, it holds anyway in the case of the “mod 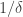 ” set (#472) and the “random subset of plurality” set (end of #480).
” set (#472) and the “random subset of plurality” set (end of #480).
Except, wait: I suppose it doesn’t hold in a variant of #480’s example. Take the set of strings which have at least 0’s in them, where that deviation is cooked up so that the overall density is
0’s in them, where that deviation is cooked up so that the overall density is 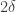 . Then take a random subset of half of these strings.
. Then take a random subset of half of these strings.
In this case, it seems like you could get too *many* of these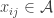 events happening. Is this the problem? I must confess, I haven’t gotten myself up to speed yet on the particulars of the second half of the plan in #439.
events happening. Is this the problem? I must confess, I haven’t gotten myself up to speed yet on the particulars of the second half of the plan in #439.
February 13, 2009 at 12:55 am |
489. Uniformity norms.
Now I would very much like to be able to prove that if has a small uniformity norm in the sense of 486/7, then the expectation of
has a small uniformity norm in the sense of 486/7, then the expectation of 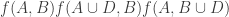 is small. But let me go for the slightly easier task of showing that if
is small. But let me go for the slightly easier task of showing that if  is a 01-valued function and the expectation of
is a 01-valued function and the expectation of 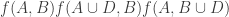 is almost zero, then the expectation of
is almost zero, then the expectation of 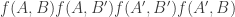 is larger than it should be. Incidentally, my convention now has to be that if the average of
is larger than it should be. Incidentally, my convention now has to be that if the average of  is
is  , then
, then 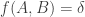 whenever
whenever  and
and  intersect.
intersect.
Actually, I want to revise the definition of the uniformity norm. I take a random permutation as in 486, but I insist that and
and 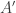 are initial segments (rather than just any old intervals) and that
are initial segments (rather than just any old intervals) and that  and
and  are final segments. But they’re still allowed to overlap, so that the expression for the norm splits up as a sum of squares.
are final segments. But they’re still allowed to overlap, so that the expression for the norm splits up as a sum of squares.
Now let’s go back to Terry’s Cartesian semi-products, as I discussed them in 442. First of all, if we take a random permutation of![{}[n]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002) and then take a random interval
and then take a random interval  in the permuted set, there will on average be several pairs of subintervals
in the permuted set, there will on average be several pairs of subintervals  that partition
that partition  . For fixed
. For fixed  each such pair is of course determined by
each such pair is of course determined by  only. And if we have two such pairs
only. And if we have two such pairs  and
and 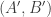 with
with  , then the pair
, then the pair  cannot lie in
cannot lie in  . This means that
. This means that  has to avoid the Cartesian product of the set of all the
has to avoid the Cartesian product of the set of all the  such that
such that 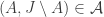 with the set of all the
with the set of all the  such that
such that  . But that gives us a nonuniformity in the function
. But that gives us a nonuniformity in the function  . Averaging over all permutations
. Averaging over all permutations  and all intervals
and all intervals  gives us (I think) that the norm in 486/7 is large.
gives us (I think) that the norm in 486/7 is large.
What I think this sketch shows is that the first stage of the two-step programme is OK: if a set contains no combinatorial lines then its slices-equal uniformity norm is too big. I’ve got to go to bed now, but I’ll write a very brief comment about the second stage.
February 13, 2009 at 1:03 am |
490. Inverse theorem.
The second stage is to prove an inverse theorem for the uniformity norm: that is, to prove that if has a large uniformity norm then it has positive correlation with an exploitable structure (meaning a structure that can be almost uniformly covered by subspaces).
has a large uniformity norm then it has positive correlation with an exploitable structure (meaning a structure that can be almost uniformly covered by subspaces).
The approach one would take to this in a dense bipartite graph would be to take a random edge and take the two neighbourhoods of its end vertices. The analogue here would be to take a random disjoint pair of sets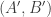 and then to take all disjoint pairs
and then to take all disjoint pairs  such that
such that  and
and  belong to
belong to  . Note that this is a Kneser product of two sets, just as we want, and that on average we expect
. Note that this is a Kneser product of two sets, just as we want, and that on average we expect  to be too dense in it.
to be too dense in it.
I was about to say that the problem is that there are far too few such pairs, but it’s just beginning to occur to me that perhaps that doesn’t matter. I’ve got to go to bed now, but I’m not completely certain that the inverse theorem isn’t almost as trivial here as it is for graphs. I’ll go to bed on that note of hyperoptimism — it feels as though the whole problem could be basically solved, but with me that feeling is extremely unreliable, and all the more so as there’s a giant claim in this paragraph that I haven’t checked at all.
February 13, 2009 at 1:35 am |
491. Inverse theorem.
Oops. Forget last paragraph of 490. It didn’t survive the going-to-bed process. I’ll think about a possible inverse theorem tomorrow.
February 13, 2009 at 10:52 am |
[…] a proof on at least some of the ideas that come out of the proof of Furstenberg and Katznelson, see Terry’s comment 439, as well as the first few comments after it. Another helpful comment of Terry’s is his […]
February 13, 2009 at 11:15 am |
492. DHJ is equivalent for different measures.
Dear Tim,
“I’m pretty sure that DHJ for the slices-equal measure is an easy consequence of DHJ, and vice versa. Here’s a sketch of how to prove that DHJ for any reasonably continuous measure (meaning that the weight of a point is usually very similar to the weight of a neighbouring point) is equivalent to the usual DHJ.”
“…the measure in almost all of the subspaces is almost uniform, so we can apply the normal DHJ…”
I do not understand the argument. Is it ok?
February 13, 2009 at 2:16 pm |
493. DHJ equivalence.
Dear Gil,
I see what you mean. I had in my mind the false idea that the function is roughly continuous in
is roughly continuous in  , when of course that is true only near the centre. I now think you are right and that DHJ for slices-equal measure is a stronger result than DHJ (and therefore, I imagine, not a known result at all). The reason I think that is that Sperner for slicees-equal seems to be stronger than Sperner for the uniform measure.
, when of course that is true only near the centre. I now think you are right and that DHJ for slices-equal measure is a stronger result than DHJ (and therefore, I imagine, not a known result at all). The reason I think that is that Sperner for slicees-equal seems to be stronger than Sperner for the uniform measure.
Of course, the other direction is the one we actually need, so this doesn’t mean that proving DHJ for slices-equal measure is a waste of time.
February 13, 2009 at 3:28 pm |
494. DHJ equivalence.
Actually, perhaps there is a way of deducing slices-equal DHJ from uniform DHJ. Let be a dense subset of
be a dense subset of ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) in the slices-equal measure. Find a small triangular grid of slices
in the slices-equal measure. Find a small triangular grid of slices  where
where  is on average dense, where all
is on average dense, where all 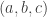 in the grid are close to
in the grid are close to  that are bounded away from 0 and
that are bounded away from 0 and  . Suppose, for the sake of example, that your slices are all very close to
. Suppose, for the sake of example, that your slices are all very close to  . Now choose a random
. Now choose a random 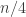 coordinates and fix them to be 3. On average, your set will still be dense, and now you have a new
coordinates and fix them to be 3. On average, your set will still be dense, and now you have a new  (it is the old
(it is the old 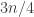 ) and all slices are near the middle so that they all have roughly the same weight.
) and all slices are near the middle so that they all have roughly the same weight.
February 13, 2009 at 10:56 pm |
495. DHJ equivalence.
Actually, on second thought, I do not think the DHJ for sliced-equal measure easily implies DHJ or is easily implied by DHJ. Since the two measures in questions are mutually singular it seems a priori that an easy reduction will be a little miracle.
For Sperner, the result that in the silced-equal measure the maximum measure of an antichain is at most 1/n indeed easily implies that the maximum measure for an antichain in the uniform measure is at most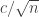 .
.
Now, the heuristic argument from 494 is appealing but suspicious. Will all the slices be sufficiently near the middle, or rather look near but actually be in the shallow boundary of the middle where “roughly the same” still be too “roughly”?
February 14, 2009 at 12:58 am |
496. DHJ equivalence.
There’s no problem getting from an arbitrary measure to the uniform measure. The proof is as follows. Suppose I know that every set that is dense in the measure contains a combinatorial line. Now suppose I want to find a combinatorial line in a set
contains a combinatorial line. Now suppose I want to find a combinatorial line in a set  that has density
that has density  in the uniform measure on
in the uniform measure on ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) if
if  is sufficiently large. Pick
is sufficiently large. Pick  such that every subset of
such that every subset of ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) of
of  -density
-density  contains a combinatorial line. Now randomly embed
contains a combinatorial line. Now randomly embed ![{}[3]^m](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5Em&bg=ffffff&fg=333333&s=0&c=20201002) into
into ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) by choosing
by choosing  variable coordinates and fixing the rest. We may suppose that every point in
variable coordinates and fixing the rest. We may suppose that every point in  has
has 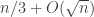 of each coordinate value and that
of each coordinate value and that  . Therefore, changing
. Therefore, changing  coordinates hardly changes the density of a slice. It follows that each point of
coordinates hardly changes the density of a slice. It follows that each point of  is in approximately the same number of these random subspaces. Therefore, by averaging, there is a random subspace inside which
is in approximately the same number of these random subspaces. Therefore, by averaging, there is a random subspace inside which  has
has  -density at least
-density at least  . (We could think of it Terry’s way: as we move the random subspace around, what we effectively have is a bunch of random variables, each with mean approximately
. (We could think of it Terry’s way: as we move the random subspace around, what we effectively have is a bunch of random variables, each with mean approximately  , so by linearity of expectation we’ll get
, so by linearity of expectation we’ll get  -density at least
-density at least  at some point, whatever the measure
at some point, whatever the measure  is.)
is.)
The other way round I am less sure of. I think I’ll have to go away and actually try to write out the calculation rigorously.
February 14, 2009 at 8:21 am |
Another general question (I think we discussed it but I forgot what was the conclusion.) How far can we bound from above the number of wild coordinates in the combinatorial lines so that DHJ (for k=3) is still correct? For Sperner it is enough that the number of wild coordinates tends to infinity as slow as we want, is that so also for DHJ?
February 14, 2009 at 8:41 am |
Dear Gil,
Yes, we can in fact make the number of wildcards bounded by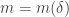 depending only on m. Indeed, one basically takes m to be the first index for which DHJ is true at this density. The pigeonhole principle then tells us that there is an m-dimensional slice of the big set which also has density
depending only on m. Indeed, one basically takes m to be the first index for which DHJ is true at this density. The pigeonhole principle then tells us that there is an m-dimensional slice of the big set which also has density  , and the claim follows.
, and the claim follows.
February 14, 2009 at 9:15 am |
Dear Gil,
In the end I didn’t have to do a calculation to see that my argument for the reverse implication was wrong. If you condition on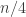 particular coordinates equalling 3, then that hugely affects what slice you are likely to have chosen, so you no longer have slices-equal measure. This is one area where the uniform measure scores over the slices-equal measure.
particular coordinates equalling 3, then that hugely affects what slice you are likely to have chosen, so you no longer have slices-equal measure. This is one area where the uniform measure scores over the slices-equal measure.
February 14, 2009 at 8:17 pm |
497. DHJ for various measures
Thanks Tim and Terry; The implication from general measures to uniform measures is neat and simple. (it is even simpler when the problem is group-invariant like for cap sets.) I suppose that there is no simple implication in the other direction and this has the benefit of making the DHJ problem for the slice-equal measure an open problem.
I find the idea that changing the measure will help (e.g. difficulties described by some counter examples go away) quite appealing. (We talked in the threads about biased Bernoulli measures and about the slice-equal measure which is simply the simple average of all Bernoulli measures.) I wonder if there is a nice basis of orthgonal functions (like the Fourier transform) suitable for the slice-equal measure.
February 15, 2009 at 4:41 am |
498. DHJ for various measures
(Getting squeezed for space in this thread!)
I think I can derive equal-slices DHJ from regular DHJ.
Suppose that![A \subset [3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) has density
has density  in the equal-slices sense. By the first moment method, this means that A has density
in the equal-slices sense. By the first moment method, this means that A has density  on
on  on the slices.
on the slices.
Let m be a medium integer (much bigger than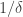 , much less than n).
, much less than n).
Pick (a, b, c) at random that add up to n-m. By the first moment method, we see that with probability , A will have density
, A will have density  on the
on the  of the slices
of the slices  with
with  ,
,  ,
, 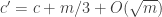 . This implies that A has expected density
. This implies that A has expected density  on a random m-dimensional subspace generated by a 1s, b 2s, c 3s, and m independent wildcards. Applying regular DHJ to that random subspace we obtain the claim.
on a random m-dimensional subspace generated by a 1s, b 2s, c 3s, and m independent wildcards. Applying regular DHJ to that random subspace we obtain the claim.
February 15, 2009 at 9:28 am |
499. Influence strategy of proof
There were several comments regarding the relation with influences, so let me mention a few connections and start with a “strategy” based on influence proofs. (probably related to Ryan’s suggested approach to Sperner.)
a) 0-1
We have a subset A of [or
[or 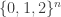 ].
]. be a combinatorial line let
be a combinatorial line let  be the set of fixed coordinates and
be the set of fixed coordinates and  be the set of wild coordinetes.
be the set of wild coordinetes.
Let
Let’s define the projection of A in the direction orthogonal to as the vectors
as the vectors  in
in  such that completing
such that completing  by either the all 0 vector on the
by either the all 0 vector on the  coordinates or the all 1 vector [or the all 2 vector] gives you a vector in A.
coordinates or the all 1 vector [or the all 2 vector] gives you a vector in A.
We can define the influence as the measure of the projection minus the measure of A. if is a single coordinate this is the ususal influence.
is a single coordinate this is the ususal influence.
If A has density c and A contains no lines then its influence in every direction is c. (We would like to show that the influence must be substantially smaller in some directions.)
So we would like to develop some strategy for showing that there is always a direction (maybe restrict our attention to directions for which R is small) so that the influence in this direction is smaller than c. (Or even smaller than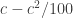 .)
.)
(To immitate these proofs we do not need to adopt the influence/projection terminology and can just talk about combinatorial lines.)
If we try to immitate the influence proofs we need to do the following:
a) To give a Fourier expression for the influence (or equivalently the number of combinatorial lines) in direction with as wild coordinates.
as wild coordinates.
b) To note that (perhaps just when S is small) such an expression must obey some restrictions because it is the Fourier expansion of a set or some similar restraint function.
c) to reach a contradiction, somehow.
(Usually in the influence proofs b is applying some hypercontractive inequality; a major difference is that in these proofs we want to reach a contradiction from having too small influence and here from having too large influence.)
b) 0-1-2
We have a subset A of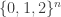 .
. be a combinatorial line let
be a combinatorial line let  be the set of fixed coordinates and
be the set of fixed coordinates and  be the set of wild coordinetes.
be the set of wild coordinetes.
Let
We need to give a Fourier description for the numbers of vectors on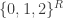 which are the projection of at least 1, and at least 2 vectors from A.
which are the projection of at least 1, and at least 2 vectors from A.
Having no combinatorial line amounts to untypical relations between these two quantities and we want to show that they cannot all hold for every S (or every small S). Again this may be easier for DHJ(2.5) and alike.
In this vague plan, what seems clearly doable (but require calculations) is giving the Fourier expansion for the different projections and influences.
February 15, 2009 at 9:57 am |
500. DHJ for different measurse
hmm. Right!
[We already have a comment 500 over on the other thread, so this looks like the time to declare this thread officially closed! (However, I have something to say about DHJ for different measures, so I’ll do so over there.)]
March 20, 2012 at 1:16 am |
online forex account…
[…]DHJ — quasirandomness and obstructions to uniformity « Gowers's Weblog[…]…
April 4, 2012 at 10:55 pm |
rent moving boxes…
[…]DHJ — quasirandomness and obstructions to uniformity « Gowers's Weblog[…]…