A couple of years ago I spoke at a conference about mathematics that brought together philosophers, psychologists and mathematicians. The proceedings of the conference will appear fairly soon—I will give details when they do. My own article ended up rather too long, because I found myself considering the question of “essential equality” of proofs. Eventually, I cut that section, which was part of a more general discussion of what we mean when we attribute properties to proofs, using informal (but somehow quite precise) words and phrases like “neat”, “genuinely explanatory”, “the correct” (as opposed to merely “a correct”), and so on. It is an interesting challenge to try to be as precise as possible about these words, but I found that even the seemingly more basic question, “When are two proofs the same?” was pretty hard to answer satisfactorily. Since it is also a question on which we all have views (since we all have experience of the phenomenon), it seems ideal for a post. You may have general comments to make, but I’d also be very interested to hear of your favourite examples of different-seeming proofs that turn out, on closer examination, to be based on the same underlying idea (whatever that means).
A general remark that becomes clear quickly when one thinks about this is that there are fairly standard methods for converting one proof into another, and when we apply such a method then we tend to regard the two proofs as not interestingly different. For example, it is often possible to convert a standard inductive proof into a proof by contradiction that starts with the assumption that 
The usual approach is the minimal-counterexample one: if there is a positive integer that cannot be factorized, let 
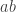


Now let’s give the inductive version. We need the “strong” principle of induction. Suppose, then, that we have proved that every integer up to 

(I missed out the proof that the induction starts, just as I did not check in the first proof that there exists a number that can be factorized.)
That’s a rather boring example of sameness of proofs—boring because they are so obviously the same, and one can even point to a mechanical procedure that converted one into the other (which can be applied to many other proofs). More interesting are examples where the sameness becomes apparent only after a more complicated process of transformation. At this point, I’d like to mention the theorem that I discussed in great detail in the bit that I removed from my article: the irrationality of 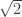
Very briefly, here’s the standard proof. If 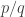



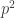




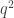
Now, equally briefly, here is another proof. Suppose again that 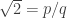
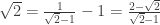
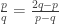

Now there are some similarities between those two arguments: both assume that 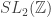
Here, though, is a third argument for the irrationality of 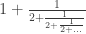
Here’s a fourth. Let 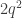
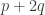
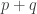


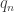




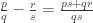

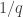
I won’t demonstrate it here, but it’s not too hard an exercise to see that the second, third and fourth proofs are all essentially the same. (At some point, perhaps I’ll put a link to a more detailed account of exactly why, at least for the second and third. The fourth has only just occurred to me.) For instance, the construction of the sequence 
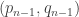
To repeat: for the time being I am interested in responses of two kinds. First, I’d like to see lots of examples of proofs that turn out to be essentially the same when they might not initially seem that way. Secondly, I’m keen to see examples of “conversion techniques”—that is, methods for transforming a proof into another that is not interestingly different. See this comment for some interesting links, though here I am not so much looking for a formal theory right down at the level of logical formulae. Rather, I would like as good a picture as possible of high-level equivalence of proofs.
Some general questions are quite interesting. For instance, if two proofs are essentially the same, must there always be some more general perspective from which one can see that the only differences between them consist in arbitrary choices that do not affect the argument in an important way? (A simple example of what I mean is something like replacing “Let 


October 4, 2007 at 3:22 pm |
I think it should end up being analogous to a more concrete situation I can sketch.
Consider a formal system, and construct from it a category. The objects are the well-formed formulæ, and the morphisms between them are proofs. This is particularly well-trodden ground. Better mathematicians than I have pointed out that in the predicate calculus, conjunction behaves like a product, implication behaves like exponentiation, and so on.
Anyhow, from this, let’s add another layer of formal structure: rewrite rules. A proof says that we can replace part of a formula by another chunk of formula, but a rewrite rule will say we can replace part of a proof by another chunk of proof. These will play the role of 2-morphisms in our category.
John Baez has spoken in his seminar about the particular case of typed lambda calculi, which are cartesian closed categories. When we change the tools like beta-reductions from equalities to arrows, we start talking about cartesian closed 2-categories, which hopefully will give insight into the use of lambda-calculi as models of computation, since the 2-morphisms now have the sense of a process.
Anyhow, at the higher level you’re talking about, we still have a notion of statements as objects and proofs as morphisms from hypotheses to comclusions. The equivalences of proofs you’re looking for should be 2-isomorphisms.
But there are 2-morphisms that are not invertible. In particular, you have 2-isomorphisms between the second, third, and fourth proof of the irrationality of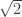 . Is it possible that the first proof is connected by only a 2-morphism? That is, can its proof be “rewritten” into one of the other forms by using a non-invertible rule, or vice versa?
. Is it possible that the first proof is connected by only a 2-morphism? That is, can its proof be “rewritten” into one of the other forms by using a non-invertible rule, or vice versa?
October 4, 2007 at 4:10 pm |
Here are two worked examples that I wrote a while back. First, I discussed the infinitude of primes: I argue that Euclid’s proof and Fürstenberg’s proof are essentially the same. Then, I talked about the Brouwer fixed-point theorem in two dimensions, in which I slowly perturb the traditional category-theoretic and Sperner’s-lemma-based proofs towards each other, but I concluded that those proofs are merely “homotopic”, not “essentially the same”. In both entries, my method of analysis was simply a careful unpacking of the proofs into their most basic statements.
October 4, 2007 at 5:12 pm |
Dear Tim,
I can think of four general ways in which one might try to capture the notion of equivalence between proof A and proof B: semantic, syntactic, algorithmic, and conceptual.
In the semantic (or model-theoretic) approach, one would try to describe the largest set of models to which proof A “naturally” generalises, and compare that set to the corresponding set for proof B. For instance, proof A of a linear algebra fact about real vector spaces might easily extend to complex vector spaces, but not to vector spaces with torsion or to modules of commutative rings, PIDs, or whatever, whereas proof B might have a different range of generalisation. There are at least two difficulties though with this approach; firstly, a proof sometimes has to be rewritten or otherwise “deconstructed” until it becomes obvious how to extend it properly, e.g. a proof involving real vector spaces, which relies crucially at one point on (say) the fact that the reals are totally ordered, may need to be modified a bit so that one no longer relies on that fact, so that extension becomes possible. Of course, one could argue that one has a genuinely different proof at this point. The second problem is if the proof itself uses model-theoretic techniques; for instance, in the previous post we discussed proofs which naturally worked for vector spaces over finite fields, but then could be extended to other vector spaces by model-theoretic considerations. One may need some sort of “second order model theory” (ugh) to properly analyse such proofs semantically.
Examples of syntactic approaches would include the ones that John described above, or use ideas from “proof mining” (which are useful, for instance, in converting “infinitary” proofs to “finitary” ones or vice versa). One can also work in the spirit of “reverse mathematics”: declare a certain “base theory” to be “obvious”, and then isolate the few remaining non-obvious steps in a proof which are external to that theory. For instance, consider my post on Pythagoras’ theorem. This theorem is of course a result in Euclidean geometry. As a base theory, one could use the strictly smaller theory of affine geometry, which can handle concepts such as linear algebra and area, but not lengths, angles, and rotations. Relative to affine geometry, one can deconstruct a proof of Pythagoras, and what one eventually observes is that at some point in that proof one must (implicitly or explicitly) use the fact that rotations preserve area and/or length. By isolating the one or two non-affine steps in the proof one can get a handle on the extent to which two proofs of Pythagoras are “equivalent”. In PDE, I like to compare arguments by assuming that every harmonic analysis estimate one needs, or every algebraic identity (e.g. conservation law or monotonicity formula) one needs, is “obvious”, leaving only the higher-level logic of the proof (e.g. iteration arguments, or expressing exact solutions as limits of approximate solutions, etc.).
The algorithmic approach is fairly similar to the syntactic one, but it only works well if the proof itself can be expressed as an algorithm. So instead of comparing proofs, let us compare two constructions, Construction A and Construction B, of some type of object (e.g. an expander graph). One crude way to detect differences between these constructions is to look at their complexity: for instance, Construction A might be polynomial time and Construction B be exponential time, which is fairly convincing evidence that the two constructions are “different”. But suppose now they are both exponential time. One could still argue that Construction B is equivalent to Construction A if one could run Construction B in (say) polynomial time assuming that every step in Construction A could be called as an “oracle” in O(1) time, and vice versa. This would say that, modulo polynomial errors, Construction A and Construction B use the “same” non-trivial ingredients, though possibly in a different order. So for instance, if one had a Gaussian elimination oracle which ran in time O(1) (once the relevant matrix was loaded into memory, of course), could one obtain a constructive Steinitz exchange lemma in time, say, linear in the size of the data (i.e. quadratic in the dimension n?) That would be a convincing way to conclude that Steinitz is “essentially a special case of” Gaussian elimination.
The last approach – conceptual – looks harder to formalise; this is the type of thing I had discussed in my “good mathematics” article. There is definitely a sense in which two different proofs of the same result (or of analogous results in different fields) are somehow “facing the same difficulty”, and “resolving it the same way” at some high level, even if at a low level the two proofs and results are quite different (e.g. one result concerns arithmetic progressions in subsets of Z_N and uses Fourier analysis and additive combinatorics, the other concerns multiple recurrence in a measure-preserving system and uses ergodic theory and spectral theory). One could imagine in those cases that there is some formal Grothendieckian abstraction in which the two proofs could be viewed as concrete realisations of a single abstract proof, but in practice (especially when “messy” analysis is involved) I think one has to instead proceed non-rigorously, by deconstructing each proof into vague, high-level “strategies” and “heuristics” and then comparing them to each other.
October 4, 2007 at 5:59 pm |
One result for which one typically sees many different proofs in undergraduate/beginning graduate studies is the Weierstrass approximation theorem of continuous functions on a segment by polynomials. There are two “schools of thought” which seem to emerge from those I know:
(1) the Stone-Weierstrass version
(2) the convolution/regularization version; among these one can include for instance the Bernstein-polynomials proof, though at first sight it may look quite different if phrased in probabilistic terms.
Are (1) and (2) really “different”? I think yes (in part because it seems they naturally generalize to different things), but maybe others can show some links…
October 4, 2007 at 6:20 pm |
Hmm. I do remember that conversation about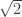 several years ago, but can’t quite reconstruct what I was thinking of at the time. Right now I can see that all four proofs touch in some way or another on
several years ago, but can’t quite reconstruct what I was thinking of at the time. Right now I can see that all four proofs touch in some way or another on  , but in different ways.
, but in different ways.
For the first proof, you are (implicitly) using the identity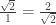 . Equivalently, the linear transformation
. Equivalently, the linear transformation 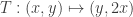 has
has  as an eigenvector, and so it suffices to show that T has no eigenvector in
as an eigenvector, and so it suffices to show that T has no eigenvector in  in the sector
in the sector 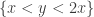 . One then observes from parity considerations that (x,y) cannot be an eigenvector if y is odd. But then (x,y) lies in the range of
. One then observes from parity considerations that (x,y) cannot be an eigenvector if y is odd. But then (x,y) lies in the range of  , and
, and 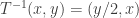 has a smaller x coordinate, and so we can set up an infinite descent
has a smaller x coordinate, and so we can set up an infinite descent 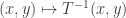 of eigenvectors, which is not possible in
of eigenvectors, which is not possible in  .
.
The second proof is based on the identity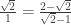 , or equivalently that vector
, or equivalently that vector  is an eigenvector for the linear transformation
is an eigenvector for the linear transformation 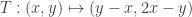 . So the irrationality of
. So the irrationality of 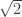 is equivalent to asserting that this particular transformation T does not have an eigenvector in
is equivalent to asserting that this particular transformation T does not have an eigenvector in  in
in 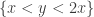 . We then observe that Tv has a smaller x coordinate than v; since T preserves eigenvectors, we again have an infinite descent. But this proof avoids the use of parity; it’s something to do with the fact that this transformation has determinant -1 (and thus can be inverted within the integers) whereas the previous one had determinant -2 and so needed a parity condition to invert. (This is where
. We then observe that Tv has a smaller x coordinate than v; since T preserves eigenvectors, we again have an infinite descent. But this proof avoids the use of parity; it’s something to do with the fact that this transformation has determinant -1 (and thus can be inverted within the integers) whereas the previous one had determinant -2 and so needed a parity condition to invert. (This is where  is supposed to come in and explain everything, but I can’t recall exactly how.)
is supposed to come in and explain everything, but I can’t recall exactly how.)
The third argument is based on the fact that is a fixed point of
is a fixed point of  , and thus
, and thus 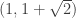 is an eigenvector of
is an eigenvector of 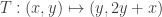 in the sector
in the sector  . This time, the determinant is 1, so we are genuinely in
. This time, the determinant is 1, so we are genuinely in  . The continued fraction algorithm can be viewed projectively as a dynamical system on the first quadrant of the plane which maps
. The continued fraction algorithm can be viewed projectively as a dynamical system on the first quadrant of the plane which maps  to
to 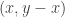 when
when  and
and  to
to 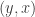 otherwise. This dynamical system terminates for any element of
otherwise. This dynamical system terminates for any element of  by an infinite descent; but when applied to an eigenvector
by an infinite descent; but when applied to an eigenvector  of T, it maps to
of T, it maps to  after three steps, giving a contradiction again.
after three steps, giving a contradiction again.
The fourth proof has a slight typo: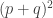 should be
should be  . The identity
. The identity  is equivalent to the assertion that
is equivalent to the assertion that 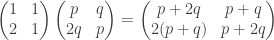 has a determinant which is the negative of the determinant of
has a determinant which is the negative of the determinant of  . So the sequences
. So the sequences  really have to do with powers of the matrix
really have to do with powers of the matrix  , or equivalently the transform
, or equivalently the transform  . I think your argument here is basically equivalent to the observation that
. I think your argument here is basically equivalent to the observation that 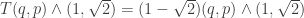 , setting up an infinite descent for
, setting up an infinite descent for 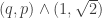 which is incompatible with
which is incompatible with 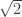 being rational. (Actually, your proof is a little different, it seems to essentially use the fact that
being rational. (Actually, your proof is a little different, it seems to essentially use the fact that 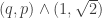 stays bounded under iteration, while (q,p) goes to infinity, but it is much the same thing.
stays bounded under iteration, while (q,p) goes to infinity, but it is much the same thing.
October 4, 2007 at 6:32 pm |
Dear Emmanuel,
I think the key to both proofs of Weierstrass’s theorem is that at some point one needs to obtain an approximation to the identity near every point of the domain, since by taking linear combinations of such things one gets a dense subset of C(X). To get the approximation to the identity, it suffices (by closure under multiplication) to get a function which is 1 at a specified point x_0 and less than 1 elsewhere, since one can then raise this function to a large power to improve the quality of the approximation.
It is at this point that proofs (1) and (2) diverge. Proof (2) simply writes down a function with the desired property, e.g.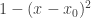 . Proof (1) proceeds by observing that, since polynomials separate points, one can find a function which is 1 at x_0 and less than 1 at some arbitrarily specified other point x_1. One then takes the “min” of several of these functions (exploiting compactness) to get what one needs (modulo controllable errors). There is then an auxiliary step to observe that the min operation can itself be approximated by polynomials, which can be done either by appeal to Weierstrass (which is a little circular, admittedly, unless one then uses proof (2)) or by explicitly writing down an approximant.
. Proof (1) proceeds by observing that, since polynomials separate points, one can find a function which is 1 at x_0 and less than 1 at some arbitrarily specified other point x_1. One then takes the “min” of several of these functions (exploiting compactness) to get what one needs (modulo controllable errors). There is then an auxiliary step to observe that the min operation can itself be approximated by polynomials, which can be done either by appeal to Weierstrass (which is a little circular, admittedly, unless one then uses proof (2)) or by explicitly writing down an approximant.
So I guess proof (2) is a shortcut version of proof (1), in which one uses the explicit structure of the domain X=[0,1] and of the ring of polynomials to write down polynomial approximations to the identity.
October 4, 2007 at 6:56 pm |
Here’s another example of result where there seem to be quite a few proofs (at least in the sense that books may include two or three): the existence of Brownian motion as a mathematical object.
Here again, I know two apparently different concepts at play:
(1) some kind of abstract existence theorem for stochastic processes, plus a general continuity criterion (Kolmogorov);
(2) writing down an “explicit” (in some sense) sequence of processes which converge (in law) to the required one (Lévy, the invariance principle, Bernstein polynomials, …)
Here I can see a fairly strong link between the two, in that the proof of convergence in law is often (explicitly or not) quite similar to the general continuity criterion. But does it qualify has making the proofs “the same”?
October 4, 2007 at 7:14 pm |
In response to John Armstrong, I think the problem with that sort of approach to proof equivalence is that it tends to get bogged down in technicalities very fast, because it focuses too much on the specific syntactic moves in a proof. All sorts of tricky things come up with cut-eliminations (which might apparently change the number of times a rule is invoked in the proof) or even just doing operations in different orders.
This is a very difficult project that people have thought about for a while, but I don’t know if people have really gotten anywhere on it yet. We probably need more good examples, as Gowers is suggesting, to get our intuitions really going, so we can even figure out what criteria a good notion of proof equivalence should satisfy. (Like whether or not it should even be an equivalence relation!)
Or maybe it would help to approach this in some sort of opposite direction? If we start by thinking about what makes “the correct” proof of a theorem, then perhaps that will shed light on what sorts of modifications to a proof are inessential?
October 4, 2007 at 7:39 pm |
Kenny, you’re right that that specific approach gets bogged down in the specific moves you choose. But, so does the formalist approach to mathematics in general.
We generally “do mathematics” at a much higher level than strict formalism, whether or not we believe in the formalist view. Still, there’s an unspoken analogy between how a high-level mathematical proof works and how a low-level formal deduction works. All I’m saying is that there’s a way of talking about “proof-morphisms” in the formalist approach, and so there should be an analogue of such things in the actual way we do proofs in real mathematics.
October 4, 2007 at 7:42 pm |
Yet another example… (I fiind this very interesting, as people can see…)
There are quite a few proofs of the fact that

 ; the crucial case is when
; the crucial case is when  is a real-valued character (like the Legendre symbol). (And this fact is itself the crucial final ingredient in proving Dirichlet’s theorem on primes in arithmetic progressions)
is a real-valued character (like the Legendre symbol). (And this fact is itself the crucial final ingredient in proving Dirichlet’s theorem on primes in arithmetic progressions)
is non-zero for a non-trivial Dirichlet character
Here the two most distinct approaches seem in stark contrast: one is the algebraic proof of Dirichlet, which uses the exact class number formula to express as an obviously non-zero number (e.g.,
as an obviously non-zero number (e.g.,  is, in the case
is, in the case  , essentially equal to
, essentially equal to  where
where  is the class number of an associated imaginary quadratic field), and the other is analytic, and there are many variants, e.g., compare upper/lower estimates for
is the class number of an associated imaginary quadratic field), and the other is analytic, and there are many variants, e.g., compare upper/lower estimates for

Despite the differences, there are very strong links; in particular the inner sum above is the number of ideals of norm in the quadratic field occuring in the first proof, and this “explains” its properties, in particular that it is
in the quadratic field occuring in the first proof, and this “explains” its properties, in particular that it is  for
for  a square (though one does not need the quadratic field to prove this).
a square (though one does not need the quadratic field to prove this). , and then for lower bounds for class numbers.
, and then for lower bounds for class numbers.
However, I wouldn’t say the proofs are “the same”; the first requires as an extra step some form of quadratic reciprocity; moreover, this proof more or less remains stuck there, whereas the other is really the basis for many arguments towards lower bounds for
October 4, 2007 at 11:27 pm |
I’ll see if I can think of some less simple examples, but a fairly elementary situation where two proofs can be regarded as essentially the same is when a proof relies on compactness and you can choose whether to use open covers or convergent subsequences. For example, to prove that every continuous real-valued function on on
on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is bounded we can either assume not and find a sequence
is bounded we can either assume not and find a sequence 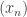 such that
such that  tends to infinity, find a limit point
tends to infinity, find a limit point  , and derive an easy contradiction, or we can use continuity to surround each point with an open interval where
, and derive an easy contradiction, or we can use continuity to surround each point with an open interval where  is bounded and pick a finite cover of such intervals.
is bounded and pick a finite cover of such intervals.
Why do we want to call these two proofs essentially the same? After all, the equivalence between Heine-Borel and Bolzano-Weierstrass, though simple, is not a complete triviality. However,the basic fact one uses in both proofs is the same: that every is contained in an interval in which
is contained in an interval in which  is bounded. The rest of the proof is somehow standard compactness window-dressing: if you want to prove it by contradiction, you use Bolzano-Weierstrass, and if you want to prove it “forwards” then you use Heine-Borel. In general, I think I could justify an assertion along the following lines: if you use Heine-Borel in a proof then you can convert it into a proof using Bolzano-Weierstrass by zeroing in on the fact that you plug into Heine-Borel and plug it into Bolzano-Weierstrass instead.
is bounded. The rest of the proof is somehow standard compactness window-dressing: if you want to prove it by contradiction, you use Bolzano-Weierstrass, and if you want to prove it “forwards” then you use Heine-Borel. In general, I think I could justify an assertion along the following lines: if you use Heine-Borel in a proof then you can convert it into a proof using Bolzano-Weierstrass by zeroing in on the fact that you plug into Heine-Borel and plug it into Bolzano-Weierstrass instead.
Of course, this can’t be completely correct, because there are compact topological spaces that fail to be sequentially compact. But I think it’s safe as long as we stick to subsets of , say.
, say.
Just to check, let’s prove that the distance between a closed set and a disjoint closed bounded set
and a disjoint closed bounded set  is positive. The Heine-Borel proof tells us to include each point of
is positive. The Heine-Borel proof tells us to include each point of  in an open ball that’s disjoint from
in an open ball that’s disjoint from  . And now I remember something that once worried me, which is that we have to apply a small trick: we cover
. And now I remember something that once worried me, which is that we have to apply a small trick: we cover  by finitely many open balls
by finitely many open balls  in such a way that
in such a way that  is disjoint from
is disjoint from  . Then if
. Then if  is the minimal
is the minimal 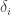 , we find that the distance from
, we find that the distance from  to
to  is at least
is at least  , since each point
, since each point  is distance at most
is distance at most 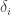 from some
from some  and hence distance at least
and hence distance at least 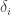 from
from  .
.
The Bolzano-Weierstrass proof works out more simply. If the result is false, then pick a sequence of points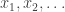 in
in  with
with  tending to 0. This has a convergent subsequence, with a limit point
tending to 0. This has a convergent subsequence, with a limit point  , and we also get a sequence in
, and we also get a sequence in  that converges to
that converges to  , so
, so 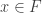 , by the fact that
, by the fact that  is closed, contradicting the disjointness.
is closed, contradicting the disjointness.
The thing that bothered me is that there was no analogue in that proof of the “replace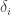 by
by 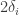 ” trick, whereas usually one likes to feel that it’s impossible to avoid the work in a proof — all you can do is shift it around. It’s doubly strange because in a certain sense compactness is stronger than sequential compactness: it implies sequential compactness more easily than sequential compactness implies it. And yet the proof using sequential compactness was easier.
” trick, whereas usually one likes to feel that it’s impossible to avoid the work in a proof — all you can do is shift it around. It’s doubly strange because in a certain sense compactness is stronger than sequential compactness: it implies sequential compactness more easily than sequential compactness implies it. And yet the proof using sequential compactness was easier.
So perhaps I won’t after all manage to give some precise “translation scheme” for interchanging sequential compactness proofs and compactness proofs.
This reminds me of a very irritating mathematical difficulty I once had and never resolved. A very nice result in Banach spaces was proved (by Nicole Tomczak-Jaegermann) with the help of induction on countable ordinals. All my experience had taught me that such proofs could be converted into equivalent proofs using a double induction. But I was unable to be precise about how, and I never managed to convert that one.
October 5, 2007 at 2:50 am |
[…] When are two proofs essentially the same? A couple of years ago I spoke at a conference about mathematics that brought together philosophers, psychologists and […] […]
October 5, 2007 at 9:13 am |
(Just) after a good night’s sleep I think I sorted out my problem in my previous comment. One can prove the theorem about distances between sets by noting that the distance is a continuous function of
is a continuous function of  , which therefore attains its minimum on
, which therefore attains its minimum on  . The latter fact can easily be proved by Heine-Borel. The “key fact” that is then needed is that every point
. The latter fact can easily be proved by Heine-Borel. The “key fact” that is then needed is that every point  is contained in a ball, every point of which has positive distance from
is contained in a ball, every point of which has positive distance from  . This is what was achieved more constructively with the
. This is what was achieved more constructively with the 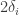 above. Precisely the same fact is also needed in the sequences proof, but this time it is hidden inside the simple statement that
above. Precisely the same fact is also needed in the sequences proof, but this time it is hidden inside the simple statement that 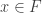 . How do we prove this? Well, for each
. How do we prove this? Well, for each  in the convergent subsequence we take some
in the convergent subsequence we take some 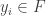 such that
such that  . We then need to know that the
. We then need to know that the  converge to the same limit, and this is the point where addition of distances and the triangle inequality are involved.
converge to the same limit, and this is the point where addition of distances and the triangle inequality are involved.
So this result does, after all, illustrate the general idea that if two proofs are essentially the same then they should involve the same amount of work. I should, however, qualify that, since it is possible to insert unnecessary work into a proof without changing its essential character. So it might be better to say that they involve the same “irreducible core” of work, or something like that.
A clear message that comes out of Terry’s first comment is that a general way of distinguishing between two proofs is to show that one proof “yields more” than the other. This could be an algorithm, or an efficient algorithm, or an explicit construction, or a generalization (either through a weaker hypothesis or through a stronger conclusion).
Here’s a rather extreme example: the usual combinatorial proof of van der Waerden’s theorem could not be regarded as the same as proving it by first proving Szemeredi’s theorem and then deducing van der Waerden’s theorem, since the latter also gives you a theorem that was an open problem long after the former was first proved. Of course, that counts as putting in unnecessary work if you use one of the proofs of Szemeredi’s theorem that needs van der Waerden’s theorem (or something very similar) as a step along the way. But not all of them do.
This raises another issue, very closely related to sameness of proofs. It’s the idea that one statement can be “stronger” than another. If two theorems A and B are both proved, then in a stupid sense they are equivalent, since each one implies the other. (To prove B just junk A and prove B, and vice versa.) The non-stupid sense in which we use the word “implies” requires a “genuine use” of a statement used to imply another statement. But that’s another fairly hard idea to make precise. (Maybe a category theorist would like to say that A genuinely implies B if there is a proof of B from A that is not homotopic to the proof A implies “0=0” implies B. So now we’re back to sameness of proofs.)
Returning to the word “stronger,” it’s also interesting that we often describe one statement as stronger than another when we are about to prove that the two statements are equivalent. We say that A is stronger than B if “A implies B” is the “trivial direction” of the equivalence. For example, the statement that there is a perfect matching in a bipartite graph is “stronger” than the statement that the graph satisfies Hall’s condition. Or the statement that a group “belongs to one of these families or else is one of these 26 groups” is stronger than the statement that
“belongs to one of these families or else is one of these 26 groups” is stronger than the statement that  is finite and simple.
is finite and simple.
I mention this just to make the point that, in the light of Terry’s observations, perhaps I should refine my earlier questions. Are there good examples of genuinely different proofs of the same statement that are not different because of their other consequences? If so, then how might one go about showing that they were genuinely different? Here, I’m trying to rule out simple examples such as proving B directly versus proving a much stronger statement A and deducing B. Incidentally, the previous paragraph gives, I think, another way in which two proofs can be different: one proof may use axioms while the other uses a classification theorem and then verifies the statement for each example that comes out of the classification.
October 5, 2007 at 10:46 am |
Does anyone know if anyone has created toy logics in which it’s possible to say something interesting about homotopies between proofs?
October 5, 2007 at 4:37 pm |
Coming back to the example of non-vanishing of , it comes to me that at a certain (very high) level, the two approaches are “the same”: the algebraic proof and analytic proof can be said to approach the result by deriving it from the fact that the product
, it comes to me that at a certain (very high) level, the two approaches are “the same”: the algebraic proof and analytic proof can be said to approach the result by deriving it from the fact that the product  , where
, where  is the Riemann zeta function, has a pole at
is the Riemann zeta function, has a pole at 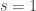 . However, the approaches diverge then in how to approach this goal, and I think that at a lower level the difference is genuine.
. However, the approaches diverge then in how to approach this goal, and I think that at a lower level the difference is genuine.
This suggests that it might be useful to look at similarity of proofs by trying to see at what level — if any — they start to diverge. This makes sense because two proofs of the same statement are identical at the highest level (where the statement itself is seen as an axiom, or a black box for further arguments), so the divergence level is (in a very rough sense) always well-defined.
October 5, 2007 at 5:47 pm |
What about the following proof: a rational number is the same thing
as an assignment of an integer to every prime, which is zero for all
but finitely many primes, i.e. a divisor (by uniqueness of prime factorization).
Squaring acts on rational numbers (in this representation) by multiplying all
these integers by 2. So a number is the square of a rational if and only
if all these numbers are even. 2 assigns 0 to every prime except 2, to which
it assigns 1 (which is not even).
This is a “proof by canonical form”: find a canonical form for a certain class
of objects in which the object in question has a form in which the desired
property is obvious. In this respect it’s a little bit like proof 3 above (except
that the canonical form is for 2 rather than for sqrt(2)). Maybe this should
be called the “A=B” method (after Wilf-Zeilberger . .)
October 5, 2007 at 7:06 pm |
Danny, I like that point. The proof you mention could also be thought of as a proof that uses a classification theorem — in this case classifying the rationals by their multiplicative structure — so it illustrates well what I was trying to say in an earlier comment about another way in which proofs can be different. (But in this case one could perhaps argue that you only need to know how 2 appears in the factorization, and even just the parity, so it’s not quite clear whether one really does want to call it different, or just the same with some extra unneeded stuff thrown in. I’m not sure what my opinion is there.)
While musing on Terry Tao’s remarks about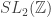 I came up with another proof. I was thinking about whether there was a nice infinite set of proofs, of which the first two I gave were just two particularly simple examples. Terry’s suggestion is to think about
I came up with another proof. I was thinking about whether there was a nice infinite set of proofs, of which the first two I gave were just two particularly simple examples. Terry’s suggestion is to think about  integer matrices with
integer matrices with 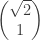 as an eigenvector. The general form of such a matrix is
as an eigenvector. The general form of such a matrix is  . It was convenient if the determinant was
. It was convenient if the determinant was  , but that gives you the Pell equation
, but that gives you the Pell equation 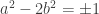 and means that you’ll end up with powers of the matrix
and means that you’ll end up with powers of the matrix 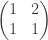 already considered. However, here’s a proof based on a matrix with determinant
already considered. However, here’s a proof based on a matrix with determinant 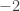 .
.
First, observe that is equal to
is equal to 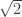 . Observe also that
. Observe also that  is strictly between
is strictly between  and
and  . It follows that if
. It follows that if 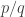 is a fraction that equals
is a fraction that equals 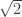 , then
, then  is a smaller fraction that also equals
is a smaller fraction that also equals 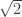 . I haven’t yet worked out the most general proof along these lines.
. I haven’t yet worked out the most general proof along these lines.
A rather silly argument that combines the first two proofs I gave earlier is to use a matrix with an entry that is half an odd integer. It’s possible to use a suitable matrix of this kind to convert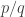 into a smaller fraction, but you need the fact that
into a smaller fraction, but you need the fact that  is even to be sure that that the numerator and denominator of the smaller fraction are integers. I won’t embarrass myself by putting up the details.
is even to be sure that that the numerator and denominator of the smaller fraction are integers. I won’t embarrass myself by putting up the details.
October 5, 2007 at 9:51 pm |
A thought that occurred to me a while after reading Emmanuel’s last comment, and also connected with the different proofs of the irrationality of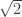 , and indeed Terry’s idea of thinking about constructions, is this. Often a mathematical statement begins with a universal quantifier, but to prove it one ends up needing to construct something. To take an example, we might decide to prove the irrationality of
, and indeed Terry’s idea of thinking about constructions, is this. Often a mathematical statement begins with a universal quantifier, but to prove it one ends up needing to construct something. To take an example, we might decide to prove the irrationality of 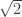 by infinite descent, and then decide that what we needed was a
by infinite descent, and then decide that what we needed was a  integer matrix with
integer matrix with 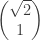 as an eigenvector with eigenvalue less than 1. This approach to the problem then turns into the problem of constructing such a matrix, which can be done in many different ways. Given two such constructions, one might say that the proof was the same at the top level (since the idea for proving the universally quantified statement was the same) but different at a lower level (since the idea for constructing a matrix was different).
as an eigenvector with eigenvalue less than 1. This approach to the problem then turns into the problem of constructing such a matrix, which can be done in many different ways. Given two such constructions, one might say that the proof was the same at the top level (since the idea for proving the universally quantified statement was the same) but different at a lower level (since the idea for constructing a matrix was different).
Actually, in this example you don’t really need much of an idea to find the matrix. You just note that it has the form and find that all you need to make the proof work is to satisfy the inequality
and find that all you need to make the proof work is to satisfy the inequality  . Above, I took
. Above, I took  and
and  , but obviously one can find many many other examples: indeed, for any non-zero integer
, but obviously one can find many many other examples: indeed, for any non-zero integer  there is an
there is an  that does the job (though, amusingly, I’m using the irrationality of
that does the job (though, amusingly, I’m using the irrationality of 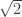 when I say that).
when I say that).
October 7, 2007 at 11:37 pm |
Can we prove that there is no bijection between the integers and the real numbers without using a “diagonal argument”? Could this be a result with essentially one proof?
October 8, 2007 at 8:44 am |
Manuel,
Cantor’s original proof that the real numbers are uncountable is (essentially) as follows:
We claim that no sequence f(n): N —> [a, b] is onto. Let f(n) be any sequence and let a_1 < b_1 be the first two distinct members of the sequence f(n). Then f(n) must attain at least two distinct values in [a_1, b_1], call the first ones a_2 < b_2.
By completeness of the reals the above sequence of nested closed intervals has a nonempty intersection. Say c is in the intersection. If f(N) = c then since c is in [a_N, b_N] we have N > 2N which is impossible. So c must not be in the image of f(n).
Should this proof be regarded as essentially the same as the diagonal argument? I’m not sure. My own judgment is that it is because at bottom both proofs are applications of the completeness of the reals (as they must be!) and don’t depend on any other properties of the reals. But this judgment seems highly subjective to me.
How about the usual approaches to the fundamental theorem of algebra?
http://en.wikipedia.org/wiki/Fundamental_theorem_of_algebra#Proofs
I consider the proofs listed in the wikipedia article under complex analysis and topology to be “essentially the same” as one another while the proofs listed under “algebraic proofs” seem essentially different from the proofs by complex analysis and topology. I would be interested in others’ responses to this example.
October 8, 2007 at 8:47 am |
… f(n) must attain at least two distinct values in [a_1, b_1], call the first ones a_2 2i….
I’m genuinely perplexed at why my comment typeset so poorly. I apologize for the boldface letters.
October 8, 2007 at 10:43 am |
Jonah, I’ve corrected your first comment so that it looks OK — you’d put < instead of “ampersand lt semicolon” and because the next letter was a b you ended up with a lot of bold face. In general, I’ve got a policy of quietly editing people’s comments when they don’t compile properly. I don’t change what anyone says though.
I’ve thought about the two proofs of the uncountability of the reals, and in my view they really are the same. Here’s a slight variant of Cantor’s argument as presented by you. Suppose that![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is countable, and enumerate it as
is countable, and enumerate it as  . Then inductively construct nested closed intervals
. Then inductively construct nested closed intervals ![\null [ p_{n}, q_{n} ]](https://s0.wp.com/latex.php?latex=%5Cnull+%5B+p_%7Bn%7D%2C+q_%7Bn%7D+%5D&bg=ffffff&fg=333333&s=0&c=20201002) of positive length such that
of positive length such that ![a_n\notin [p_n,q_n]](https://s0.wp.com/latex.php?latex=a_n%5Cnotin+%5Bp_n%2Cq_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This is obviously possible, and can be done in many different ways. (Your argument is different only in that you chose a specific way of constructing these intervals, which happened to depend on the sequence
. This is obviously possible, and can be done in many different ways. (Your argument is different only in that you chose a specific way of constructing these intervals, which happened to depend on the sequence  .) Then an element of the intersection of the intervals
.) Then an element of the intersection of the intervals ![\null [p_n,q_n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bp_n%2Cq_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) cannot be any of the
cannot be any of the  .
.
To turn that into the usual diagonal argument, you simply choose![\null [p_n,q_n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bp_n%2Cq_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) to be an interval of all points with a given first
to be an interval of all points with a given first  digits in their decimal expansion (except that it’s slightly more convenient to take the right end-point of this interval as well). You choose the
digits in their decimal expansion (except that it’s slightly more convenient to take the right end-point of this interval as well). You choose the 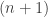 st digit to be 3 or 6 according to whether the
st digit to be 3 or 6 according to whether the 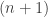 st digit of
st digit of  is or is not one of 5 or 6, say.
is or is not one of 5 or 6, say.
So this fits nicely into the scheme of what I was mentioning earlier. We actually prove a more precise statement: for every countable sequence of reals (in
of reals (in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) there is a sequence of nested closed intervals
) there is a sequence of nested closed intervals ![\null [p_n,q_n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bp_n%2Cq_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that
such that  does not belong to
does not belong to ![\null [p_n,q_n]](https://s0.wp.com/latex.php?latex=%5Cnull+%5Bp_n%2Cq_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) . In some sense, the proof of the “for every” part always seems to be the same, while the proof of the inner “there is” part can be done in many different ways. But demonstrating the “there is” part is sufficiently simple that these different approaches don’t really feel all that different. Or perhaps the real reason is that one can describe a sort of “nondeterminate algorithm” (with steps like, “If
. In some sense, the proof of the “for every” part always seems to be the same, while the proof of the inner “there is” part can be done in many different ways. But demonstrating the “there is” part is sufficiently simple that these different approaches don’t really feel all that different. Or perhaps the real reason is that one can describe a sort of “nondeterminate algorithm” (with steps like, “If  is less than
is less than 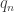 then pick
then pick  and
and 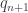 such that
such that 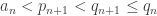 “) and the “different approaches” that we want to identify consist in making this algorithm determinate — or, if you prefer, in different proofs that the indeterminate steps can be specified precisely.
“) and the “different approaches” that we want to identify consist in making this algorithm determinate — or, if you prefer, in different proofs that the indeterminate steps can be specified precisely.
Going back to the original question of Manuel, I think it would be very interesting to show that any proof, or perhaps any “sensible” proof, of the uncountability of the reals must involve a diagonal argument of some sort. It certainly seems to be the case. Recasting it in the terms of the last paragraph makes it almost obvious that it is the case, but I haven’t quite demonstrated that you have to use the nested closed intervals property. However, one does have the basic problem, “Given a sequence , construct a real that is not an element of the sequence.” Since the reals are defined as limits of sequences in one way or another, one does seem to be forced to construct another sequence in such a way that its limit is not one of the
, construct a real that is not an element of the sequence.” Since the reals are defined as limits of sequences in one way or another, one does seem to be forced to construct another sequence in such a way that its limit is not one of the  . And then one appears to be forced to deal with each
. And then one appears to be forced to deal with each  in turn, and the obvious way of constructing a sequence that does not have
in turn, and the obvious way of constructing a sequence that does not have  as a limit is to make sure that eventually it lives inside a closed interval that does not contain
as a limit is to make sure that eventually it lives inside a closed interval that does not contain  . Actually, that’s equivalent of course. One could do stupid things like not ensuring that the sequence avoids
. Actually, that’s equivalent of course. One could do stupid things like not ensuring that the sequence avoids  until you reach the
until you reach the  th term of the sequence. This would be like taking not the obvious diagonal but something similar that did the job equally well. I’d say that this paragraph is a fairly convincing informal argument that there is essentially only one proof of the uncountability of the reals, but I’m not sure how I’d go about making it more formal.
th term of the sequence. This would be like taking not the obvious diagonal but something similar that did the job equally well. I’d say that this paragraph is a fairly convincing informal argument that there is essentially only one proof of the uncountability of the reals, but I’m not sure how I’d go about making it more formal.
October 8, 2007 at 11:02 am |
One more thought. Here’s a proof of uncountability of the reals that probably ends up being the same, but it might take a bit of thought to see how. You first prove that there is a countably additive measure on the reals that gives the usual length to open and closed intervals. Then the measure of a countable set is zero while the measure of![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is 1.
is 1.
A good place to start if one wants to see why this is the same proof is the exercise (the significance of which I understand after reading Imre Leader’s forthcoming article on measures for the Princeton Companion) of showing that if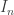 is an interval of length
is an interval of length  and if the
and if the  s sum to less than 1, then the intervals
s sum to less than 1, then the intervals 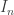 cannot cover all of
cannot cover all of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . You need this to get going with measure theory and it depends fundamentally on the completeness of the reals.
. You need this to get going with measure theory and it depends fundamentally on the completeness of the reals.
October 8, 2007 at 2:28 pm |
Actually, here’s a more detailed answer to whether the “measure-theoretic proof” is just the usual proof in disguise. The Lebesgue measure of a set X is the infimum of the sum of lengths of a countable collection of intervals that covers X. It’s easy to prove that the measure of a countable set is zero, but how do you prove that the measure of the interval![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is not zero? You take any countable collection of open intervals with lengths adding up to less than 1/2, say, and prove that the union of this collection is not the whole of
is not zero? You take any countable collection of open intervals with lengths adding up to less than 1/2, say, and prove that the union of this collection is not the whole of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The reason it isn’t is that if
. The reason it isn’t is that if 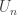 is the union of the first
is the union of the first  open intervals, then the complement
open intervals, then the complement 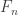 of
of 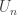 is a finite union of closed intervals of total length at least 1/2. (This is because if you write
is a finite union of closed intervals of total length at least 1/2. (This is because if you write ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) as a finite union of intervals, whether open or closed, then their lengths must add up to at least 1, a fact that is easy to prove.) Therefore, the sets
as a finite union of intervals, whether open or closed, then their lengths must add up to at least 1, a fact that is easy to prove.) Therefore, the sets 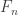 are a nested collection of non-empty closed sets, so they have a non-empty intersection.
are a nested collection of non-empty closed sets, so they have a non-empty intersection.
This appears to be a slightly more general argument, as it involves nested intersections of closed sets that are more general than intervals. Moreover, that is necessary: if you try to find your point that is not in the union of the open intervals by constructing an intersection of closed intervals, you can’t keep the th closed interval large enough to guard against one of the later open intervals containing it. And perhaps the reason we have a somewhat different proof is that we have proved something stronger: instead of merely showing that a countable union of intervals of length 0 cannot be all of
th closed interval large enough to guard against one of the later open intervals containing it. And perhaps the reason we have a somewhat different proof is that we have proved something stronger: instead of merely showing that a countable union of intervals of length 0 cannot be all of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) we’ve shown it for a countable union of intervals of any lengths that add up to less than 1 (if we’re prepared to modify the argument a tiny bit).
we’ve shown it for a countable union of intervals of any lengths that add up to less than 1 (if we’re prepared to modify the argument a tiny bit).
But even this doesn’t make it a genuinely different proof of the uncountability of the reals , any more than it would be a genuinely different proof if we first used the diagonal argument and then said, “Oh, and by the way, here’s a proof of Fermat’s last theorem thrown in.” If we just want to prove that the set isn’t all of
isn’t all of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) then we can choose any old open intervals around the
then we can choose any old open intervals around the  and use the measure-theoretic argument to prove that their union is not all of
and use the measure-theoretic argument to prove that their union is not all of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . But if we’re allowed to do that, then we can make their sizes go to zero sufficiently rapidly that it is possible to use nested intervals for the argument, rather than more general nested closed sets.
. But if we’re allowed to do that, then we can make their sizes go to zero sufficiently rapidly that it is possible to use nested intervals for the argument, rather than more general nested closed sets.
Despite all that, maybe one could say that there is in fact a very slight difference between the two approaches. If you prove the result using nested intervals, then there is a tiny effort needed to construct those intervals. If you use more general closed sets, then you can simply take the complement of the open sets you are considering, so constructing the closed sets no longer takes any effort, but now you are looking at more complicated sets.
The proof that a nested intersection of non-empty closed subsets of![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is non-empty is basically the same as the proof for intervals: their infs tend to a limit that belongs to the intersection. However, maybe this shouldn’t quite make us think that the proofs are essentially the same because if you generalize to higher dimensions it does seem to be genuinely harder to prove that a nested intersection of arbitrary closed sets (or even of finite unions of closed boxes) is non-empty than it is if those sets are just boxes: the inf trick no longer works.
is non-empty is basically the same as the proof for intervals: their infs tend to a limit that belongs to the intersection. However, maybe this shouldn’t quite make us think that the proofs are essentially the same because if you generalize to higher dimensions it does seem to be genuinely harder to prove that a nested intersection of arbitrary closed sets (or even of finite unions of closed boxes) is non-empty than it is if those sets are just boxes: the inf trick no longer works.
October 8, 2007 at 6:47 pm |
The Kazhdan-Lusztig conjecture was proved by translating the question through several areas of mathematics, until it reached a form that could be treated by Deligne’s theory of weights. At the end of Bernstein’s D-module notes, he mentions that one wouldn’t need to go through the business of varieties over finite fields if one had a satisfactory theory of mixed Hodge modules (does this exist now? I’m behind on recent developments). Let’s suppose such a theory existed, and we had a proof using it. Would such a proof be equivalent? If we had a good theory of mixed motives, I suppose one could claim that both proofs were equivalent, since we would be using two realizations of the same machine. At least, I imagine this is what Bernstein had in mind. My question is, are two proofs equivalent if the equivalence requires a conjecture?
October 8, 2007 at 7:08 pm |
Here’s another example: three proofs of the Weil conjectures. I think Deligne’s original proof used a lot of l-adic monodromy on Lefschetz pencils, Laumon’s proof used some kind of sheafy Fourier transform, but still revolved around the l-adic cohomology theory set out in SGA, and Kedlaya’s proof also used a sheafy Fourier transform, but in the language of p-adic differential equations. Kedlaya said that he was guided by strong analogies between the l-adic and p-adic worlds, but formalizing this as an equivalence of proofs seems a bit ambitious with our current state of knowledge.
October 9, 2007 at 12:48 am |
My gut feeling (but no more than that) about whether two proofs can be equivalent if the equivalence is just a conjecture is that they can. It seems to me to be a bit like the two-dimensional equivalent of asking whether a mathematical statement can be provable if it is just a conjecture. Also, it seems clear that two proofs can be equivalent in a highly non-trivial way, so why not in a way that is so non-trivial that it actually depends on an unsolved conjecture? However, coming up with good examples of such a phenomenon is very interesting.
On a more mundane note, a fairly simple example of a result that seems to have genuinely different proofs is Fermat’s little theorem. I know of three: the deduction from Lagrange’s theorem, the deduction from the fact that multiplying by permutes the non-zero elements of
permutes the non-zero elements of 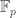 and the inductive proof based on the fact that the binomial coefficients
and the inductive proof based on the fact that the binomial coefficients  are multiples of
are multiples of  when
when  . Can anyone identify any two of those proofs? (It might be possible for the first two, perhaps.)
. Can anyone identify any two of those proofs? (It might be possible for the first two, perhaps.)
Another question for algebraic number theorists out there. Gauss’s law of quadratic reciprocity famously has a vast number of proofs. How many genuinely distinct proofs are there? Even a rough estimate would interest me.
October 9, 2007 at 6:29 am |
Coincidentally, I was just reading yesterday one of Euler’s proof of Fermat’s little theorem in a translation of his original paper. It’s essentially the first one mentioned above, tailored to the case of a cyclic group (and with unusual style and notation as one would expect) but clearly recognizable. What’s interesting is that at the end Euler specifically states that this is a completely different proof from the one with binomial coefficients, because it leads to many other results. (Those are essentially his words, though I don’t have the book handy just now to quote it).
Concerning quadratic reciprocity, this
site of F. Lemmermeyer lists 224 published ones, and classifies them roughly (and has references), which seems to indicate that the number of fairly distinct ones is maybe 40 or 50. I think one can identify some of these (e.g., many arguments are based on Gauss sums or cyclotomic fields, and these can be certainly made to correspond in some cases), but that would probably leave at least 10 genuinely different arguments.
October 9, 2007 at 11:07 am |
I guess a lot of things traditionally called “metatheorems” supply examples of transformation techniques for proofs.
Category theory has several. There’s the “duality principle”: that the axioms of category theory are unchanged by reversing the directions of all the morphisms and all the compositions, and so every time you prove something about the situation one way around, you can rewrite the proof to prove a dual statement.
I suppose that, logically, that’s a different thing: the rewriting process here yields a proof of a different statement. But there’s no reason not to be interested in such things.
For an honest example, there’s Freyd’s embedding theorem. The textbook statement is that any abelian category can be embedded fully and faithfully into a category of modules. But the point, philosophically, is that it allows you to prove things in abelian categories by imagining you’re working in a category of modules. In particular, you can “choose elements” of your objects, even though they’re just objects of an abstract category, and don’t really have elements. There is a rewriting technique which replaces such a proof using “elements” with one that doesn’t abuse notation in this manner.
October 9, 2007 at 7:14 pm |
This is a very interesting post! I noticed that assertively claiming that two very different proofs of the same theorem are essentially equal is something which can gain you a lot of respect. It shows not only a complete understanding of the two different proofs but understanding deep connections that nobody else see. Maybe one can gain even more respect by claiming that two different proofs for two entirely different theorems are essentially the same but here some caution is advised.
Concerning the question of when two proofs are equal or similar or different, one formal aspect regarding proofs of existence (like fixed point theorems) is the complexity classes of Christos Papadimitriou. These classes can be regarded as a rough (computational complexity) classification of mathematics’ basic tricks and this may lead to a formal notion of different proofs. (In this classification 2 proofs leading to polynomial algorithms are equivalent.)
Here are a few test cases for equality and inequality of proofs:
1) I have a friend who always tell me that the inductive proof of the crossing number inequality (recently featured in Terry’s blog) given by Ajtai Chvatal Newborn and Szemeredi is equivalent to the probabilistic proof. This always surprised me since to me they look different (and in particular I feel that I understand much better the probabilistic one.)
2) There are many proofs of Cayley formula for the number of trees on n labeled vertices. (A book of J W Moon lists quite a few and there are many more.) Can you classify them?
3) Turan’s theorem for the number of edges for a graph on n vertices required to guarantee a triangle has many proofs, and it almost looks that any strategy to prove is doomed to succeed. Which of these proofs are different?
October 10, 2007 at 1:06 am |
Regarding the related question when two proofs are entirely different, there are some cases where there is a clear difference between two types of proofs e.g. the distinction between constructive/non constructive proofs; effective/non-effective proofs; Proofs based on randomized construction/ proof based on explicit construction. In these three cases one type of proofs is usually much harder than the other.
This reminds me also of the long-time mathematical endeavor of finding an “elementary proof” of the prime number theorem. The precise meaning of “elementary proof” in this case was not entirely clear to me. (At some points I convinced myself that the distinction is manifested in that the “elementary proofs” apply to certain formulations of the PNT when you replace all primes by a dense subset of primes; but I am not sure this is correct.)
In all the cases above entirely different proofs reflect a different mathematical task to start with. It can be interesting to bring more examples of entirely different proofs for (really) the same theorem, when the distinction is not of the nature that one proof (to start with) tries to achieve some much harder goal (effective; constructive; explicit; elementary; bijective, not using CH; computerized; not computerized; etc..)
October 10, 2007 at 5:03 am |
I forgot another case of distinction between proofs which is the case of simple proofs vs difficult proofs. Unlike the distinction between effective/non-effective; constructive/non constructive, etc., there is something paradoxical about the (all important) endeavor of finding simple proofs for difficult theorems. To start with, there is a strong positive correlation between the difficulty of the proof and the difficulty of finding it. But finding simple proofs for difficult theorems is usually very difficult.
It is like the well known paradox:
Rare things tend to be more expensive;
Cheap horses are rare;
Therefore, cheap horses tend to be more expensive.
(Finding difficult proofs for easy theorems is also quite interesting from time to time.)
October 10, 2007 at 5:49 am |
One rather famous distinction between types of proof is in algebraic geometry: the proof via “complex analytic methods” versus the proof via “algebraic methods”. The former includes using just about any facet of the ordinary topology on a complex variety, so for example, one has Poincare duality proven either as Poincare might have, or the way Artin did. Of course, Artin proved it for etale cohomology, but he also proved a comparison theorem that relates that to singular cohomology, so it seems there are two proofs which cannot, even in principle, be reduced to the same thing (since the etale cohomology theorem applies to varieties in positive characteristic too!). I am no doubt revealing my ignorance by trying to talk about this, however…
Actually, it seems to me that anything that can be proven with complex analysis or with something else will have two essentially different proofs; complex analysis is good like that. There is, for example, an amusing computation of the Fresnel integral using differentiation under the integral sign: let
using differentiation under the integral sign: let  , observe that the derivative can be computed by elementary means, and that I(t) vanishes as t approaches infinity. That gives you a differential equation which you can solve and then plug in t = 0. You can also do it using the residue theorem, which involves integrating over a triangular contour; I have trouble seeing how these could be the same proof. Perhaps they are, though.
, observe that the derivative can be computed by elementary means, and that I(t) vanishes as t approaches infinity. That gives you a differential equation which you can solve and then plug in t = 0. You can also do it using the residue theorem, which involves integrating over a triangular contour; I have trouble seeing how these could be the same proof. Perhaps they are, though.
October 10, 2007 at 8:15 am |
In the case of the Prime Number Theorem, the stated goal (e.g., in one of Hardy’s lectures on Ramanujan’s work, if I remember right) was to find a proof that does not use complex analysis. It was hoped that this would imply significant new insight into the study of prime numbers, especially with respect to those problems that were then still unsolved, such as the Goldbach, prime $k$-tuples, conjectures. However, the proof of Selberg (and Erdös) didn’t really have such an effect, and elementary proofs have not yet recovered the same results provided by the standard complex-analytic proofs (with respect to remainder terms, and uniformity in arithmetic progressions).
October 10, 2007 at 5:51 pm |
With all this discussion of elementary vs non-elementary proofs, is there scope for a loop back to your wonderful earlier post on Cauchy’s theorem as generalization of f’=0 => f = constant?
October 10, 2007 at 10:58 pm |
I’ve seen two proofs that . The first one is the standard proof using Fubini and polar coordinates. The second involves constructing two functions
. The first one is the standard proof using Fubini and polar coordinates. The second involves constructing two functions 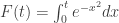 and
and  , and noting with derivatives that
, and noting with derivatives that 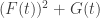 is constant. It seems quite beautiful, and I learned it from W. Luxemburg.
is constant. It seems quite beautiful, and I learned it from W. Luxemburg.
I’m curious if there is an analytic reason for someone to come up with the function G, because it seems to come out of nowhere. It might also suggest some way that these two proofs are equivalent.
October 11, 2007 at 11:47 am |
Scott, that’s an interesting challenge. It looks to me as though there might be a perspective from which those two proofs could be similar in a way that has been discussed in earlier comments: that they have the same basic strategy, but that that strategy involves constructing something that can be constructed in many different ways. However, in this case the construction is a sufficiently non-trivial process for it to be questionable whether one would want to regard the proofs as the same. I haven’t worked this out properly but let me say why I think it looks like a possibility.
The quantity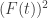 can be regarded as the integral of
can be regarded as the integral of 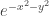 over the square
over the square ![\null [0,t]^2](https://s0.wp.com/latex.php?latex=%5Cnull+%5B0%2Ct%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) . Thus, one could regard
. Thus, one could regard  as a guess for what that integral ought to be (but at the moment I don’t see how the guess was made) and the differentiation trick as just a verification that the guess is correct. The first proof could be regarded as using the formula
as a guess for what that integral ought to be (but at the moment I don’t see how the guess was made) and the differentiation trick as just a verification that the guess is correct. The first proof could be regarded as using the formula 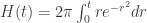 as a guess for what the integral of
as a guess for what the integral of 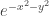 ought to be over a circle of radius
ought to be over a circle of radius  . Probably that can be proved correct by differentiation as well.
. Probably that can be proved correct by differentiation as well.
Thus, it looks to me as though the basic strategy is, “Find a two-dimensional set on which you can work out the integral of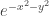 .” (Of course, I really mean a set that grows with a parameter
.” (Of course, I really mean a set that grows with a parameter  .) Once you’ve had that idea, it turns out that there is more than one such set.
.) Once you’ve had that idea, it turns out that there is more than one such set.
Having said that, the formula for does seem rather non-obvious and seems to involve a distinctly “new idea.” Most notably, unlike in the circle case, it gives an integral that (as far as I can see) is just as hard to calculate as the original one, but which happens to behave very nicely when
does seem rather non-obvious and seems to involve a distinctly “new idea.” Most notably, unlike in the circle case, it gives an integral that (as far as I can see) is just as hard to calculate as the original one, but which happens to behave very nicely when  is 0 or infinity. So it would be very interesting to know where this comes from, and also whether there are any other proofs that fit into this general scheme.
is 0 or infinity. So it would be very interesting to know where this comes from, and also whether there are any other proofs that fit into this general scheme.
October 11, 2007 at 2:09 pm |
On second thoughts, perhaps it doesn’t take an idea to come up with so much as a leap of faith that the integral over the square will be easy to calculate, coupled with the thought (which is fairly standard, so perhaps not quite an idea in the true sense) that it might be worth differentiating it to see what one gets. If you do, then you want to calculate
so much as a leap of faith that the integral over the square will be easy to calculate, coupled with the thought (which is fairly standard, so perhaps not quite an idea in the true sense) that it might be worth differentiating it to see what one gets. If you do, then you want to calculate 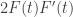 , which works out to be
, which works out to be 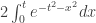 . It’s quite natural to make the substitution
. It’s quite natural to make the substitution 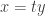 , which leads to
, which leads to  . Then it’s quite natural to notice that the integrand can be antidifferentiated with respect to
. Then it’s quite natural to notice that the integrand can be antidifferentiated with respect to  , so this is
, so this is 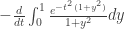 . And now we obviously want to use the fundamental theorem of calculus, so we want to evaluate this integral for
. And now we obviously want to use the fundamental theorem of calculus, so we want to evaluate this integral for 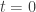 and
and 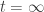 … and we can.
… and we can.
The initial leap of faith isn’t really a piece of magic, since the square and the circle are the two simplest two-dimensional sets that one might try. So the above seems to me to be a plausible account of how the function might have been discovered.
might have been discovered.
October 11, 2007 at 2:11 pm |
I think I see why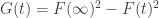 . The right hand side is the integral of
. The right hand side is the integral of 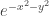 over the complement of the square
over the complement of the square ![\null [0,t]^2](https://s0.wp.com/latex.php?latex=%5Cnull+%5B0%2Ct%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) . By the symmetry of the problem over the line
. By the symmetry of the problem over the line 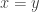 , this is
, this is
 .
. to get
to get
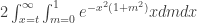 . The integral on x is now elementary (substitute
. The integral on x is now elementary (substitute  ) and I think the remaining integral on m is your formula for
) and I think the remaining integral on m is your formula for  .
.
Now, make the substitution
This can be seen as similar to, but not quite the same as, the standard proof. In the standard proof, we change to polar coordinates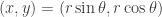 . Then the integral on r is elementary and the integral on
. Then the integral on r is elementary and the integral on  is trivial. In the new proof, we change to “(slope, intercept)-coordinates”:
is trivial. In the new proof, we change to “(slope, intercept)-coordinates”: 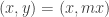 . The integral on x becomes elementary for the same reason that the integral on r did previously.
. The integral on x becomes elementary for the same reason that the integral on r did previously.
This suggests to me a general strategy of proof. Choose any parametrized convex curve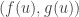 cutting off a corner of the positive orthant. Make the substitution
cutting off a corner of the positive orthant. Make the substitution 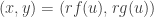 . The integral on r will always be elementary; hope that you can deal with the integral on u. So the standard proof is to cut off the corner with a quarter-circle, and the modified proof is to cut it off with a square.
. The integral on r will always be elementary; hope that you can deal with the integral on u. So the standard proof is to cut off the corner with a quarter-circle, and the modified proof is to cut it off with a square.
October 11, 2007 at 2:14 pm |
Gaah! I can’t get my TeX back to see what went wrong! The first formula that didn’t parse should be![\null [0,t]^2](https://s0.wp.com/latex.php?latex=%5Cnull+%5B0%2Ct%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) — I was just making sure we all knew what I meant by “the square”. The second formula that didn’t parse was just the expression for polar coordinates
— I was just making sure we all knew what I meant by “the square”. The second formula that didn’t parse was just the expression for polar coordinates  .
.
October 11, 2007 at 2:20 pm |
David, I’ve noticed that for some strange reason WordPress doesn’t seem to recognise closed intervals if they occur at the beginning of a LaTeX expression, even if you’ve done everything completely correctly. But I’ve discovered a stupid trick that deals with the problem: instead of writing “latex [0,1]” inside the dollars I write “latex \null [0,1]”. Ridiculously, that seems to cure it. I’ve edited your two comments above so that they do parse, partly using that trick and partly removing a backslash that had attached itself to the letter r in “r \sin \theta”.
October 12, 2007 at 12:17 am |
This seems to be a pretty satisfying answer. David’s general strategy also works well if you decompose of the lower half of the quadrant into hyperbolas and do a hyperbolic trig substitution. However, the square version seems to be special in that it produces a one-dimensional proof in a way that the other two do not, in the sense that a first-term calculus student could parse it without knowning Fubini.
I’ve encountered a similar vanishing problem in LaTeX itself, when I tried to start some aligned equations with a Lie bracket, so it might not be a problem with WordPress. By the way, you can find the original TeX in the alt text of the image.
October 12, 2007 at 10:54 am |
Here are two proofs that a dense subset of must contain a “Hilbert cube” of dimension
must contain a “Hilbert cube” of dimension  : that is, a subset of the form
: that is, a subset of the form  . More precisely, for any
. More precisely, for any  there exists an
there exists an  such that any subset
such that any subset  of
of  of size at least
of size at least  must contain such a set (with the
must contain such a set (with the  not equal to zero). I’ll just sketch the arguments very briefly.
not equal to zero). I’ll just sketch the arguments very briefly.
The first approach is to find (using an averaging argument) some such that the intersection of
such that the intersection of  with
with  is reasonably large. (It’s not too hard to get
is reasonably large. (It’s not too hard to get 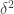 times an absolute constant.) Then you are left needing to find a
times an absolute constant.) Then you are left needing to find a 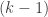 -dimensional cube in this intersection, which you do by induction.
-dimensional cube in this intersection, which you do by induction.
The second approach is to prove a stronger result, namely that you can find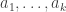 such that for a significant proportion of
such that for a significant proportion of  the cube defined above is a subset of
the cube defined above is a subset of  . This you can prove as follows. By induction the result is true for
. This you can prove as follows. By induction the result is true for  . This gives you
. This gives you 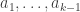 and a big set
and a big set  of
of  such that the corresponding cube is a subset of
such that the corresponding cube is a subset of  . Since
. Since  is dense, some difference occurs frequently in
is dense, some difference occurs frequently in  , and you can make this difference your
, and you can make this difference your 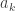 .
.
This illustrates a phenomenon that occurs frequently. You want to prove a statement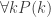 by induction. You can either use a simple argument to deduce
by induction. You can either use a simple argument to deduce 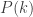 from
from  or you can use
or you can use  to deduce
to deduce 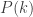 from
from 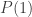 (which itself is proved by a simple argument). In other words, you can think of
(which itself is proved by a simple argument). In other words, you can think of  either as
either as 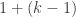 or as
or as  .
.
Often the work needed is more or less the same, as the above example illustrates. But sometimes one approach seems to be rather easier than the other (unfortunately I haven’t managed to think of any examples yet), and I’m not sure that I believe in a general principle that says that one can always convert one sort of inductive proof into the other. So perhaps we have here a grey area, where proofs can be similar but it’s not obvious whether we should regard them as the same.
October 12, 2007 at 3:43 pm |
Oh! I know that LaTeX bug. It occurs when your TeX code is being fed as a parameter into a macro somewhere, and LaTeX, failing to “quote” the square bracket, interprets it as an additional optional parameter to the macro. The most common way I know to produce this bug is to have an item in a list that starts with a square bracket (arguably, this case is a feature.) For example, this LaTeX should cause trouble:
There are two types of parenthesis used in some-programming-language-or-other:
\begin{enumerate}
\item (), used to control the order of operations
\item [], used to call a function or index into an array
\end{enumerate}
The standard solution is to write {[}.
October 12, 2007 at 4:16 pm |
Here is an example, in elementary number theory, of the phenomenon Prof. Gowers discusses in his previous post. We write![{[}a_1,...,a_n]](https://s0.wp.com/latex.php?latex=%7B%5B%7Da_1%2C...%2Ca_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) for the continued fraction
for the continued fraction  . Define
. Define  by the reucrrence
by the reucrrence
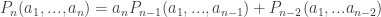
 ,
,  . Define
. Define  by the same recurrence with
by the same recurrence with 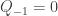 and
and 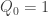 . Then a basic result about continued fractions is
. Then a basic result about continued fractions is
![{[}a_1, ..., a_n]=P_n(a_1, ..., a_n)/Q_n(a_1,...,a_n).](https://s0.wp.com/latex.php?latex=%7B%5B%7Da_1%2C+...%2C+a_n%5D%3DP_n%28a_1%2C+...%2C+a_n%29%2FQ_n%28a_1%2C...%2Ca_n%29.&bg=ffffff&fg=333333&s=0&c=20201002)
with initial conditions
Every student that I have ever seen try to prove this (I taught at PROMYS for four years) tries to use induction, starting from
![{[}a_1,...,a_n]=a_1+1/[a_2,...,a_n]](https://s0.wp.com/latex.php?latex=%7B%5B%7Da_1%2C...%2Ca_n%5D%3Da_1%2B1%2F%5Ba_2%2C...%2Ca_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
![{[}a_1,...,a_{n-1}, a_n]=[a_1,...,a_{n-1}+1/a_n]](https://s0.wp.com/latex.php?latex=%7B%5B%7Da_1%2C...%2Ca_%7Bn-1%7D%2C+a_n%5D%3D%5Ba_1%2C...%2Ca_%7Bn-1%7D%2B1%2Fa_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
This proof can be made to work, but it is hard. However, there is a very easy proof if you start from
I think there is a mental block against doing it this way, because the terms in the continued fraction will no longer be integers, but it produces a much simpler proof.
October 19, 2007 at 7:54 am |
To me, the first proof is analytical, the other three algebraic.
Besides, good problems have unique solutions.
January 22, 2011 at 12:37 pm
Number theoretic uses Bezout: Let w=sqrt2=a/b. (a,b)=1 so there are integers c,d, such that ad-bc=1.
0=(a-bw)(c+dw)=ac+adw-bcw-bdw^2=ac-2bd+w,
thus w is an integer.
October 23, 2007 at 10:39 am |
Here’s another example of a result with two proofs that look different and are both quite simple. Perhaps they can be unified — I have not tried.
The statement to be proved is that every finite subgroup of the multiplicative group of non-zero complex numbers must be the group of all th roots of unity, for some
th roots of unity, for some  . This question came up on a Cambridge question sheet for a first-year course on groups, and this term I am what we call a “supervisor” for the course (that is, I see students in pairs and discuss their solutions and attempted solutions).
. This question came up on a Cambridge question sheet for a first-year course on groups, and this term I am what we call a “supervisor” for the course (that is, I see students in pairs and discuss their solutions and attempted solutions).
Here’s the proof that occurred to me. Let be such a group. Then any element of
be such a group. Then any element of  has finite order (something that had been proved in an earlier question via the usual pigeonhole-principle argument), and therefore must be a root of unity. Now choose an element of
has finite order (something that had been proved in an earlier question via the usual pigeonhole-principle argument), and therefore must be a root of unity. Now choose an element of  with minimal argument. If that doesn’t generate the whole of
with minimal argument. If that doesn’t generate the whole of  then a Euclid-algorithm style calculation shows that its argument isn’t minimal — contradiction.
then a Euclid-algorithm style calculation shows that its argument isn’t minimal — contradiction.
This was the very first question sheet of the course, so I think that was the intended proof, but one of my students suggested using Lagrange’s theorem instead. That quickly leads to a short solution: every element of must be a
must be a  th root of unity, and there are only
th root of unity, and there are only  of them, so we are done.
of them, so we are done.
These two proofs certainly have quite significant surface differences: the second uses a piece of algebra that can’t immediately be read out of the first, and the first uses the minimal argument, which doesn’t seem to come into the second. So any unification would have to be from a deepish perspective. Or perhaps they really are different proofs.
October 23, 2007 at 11:42 pm |
I think you can get enough of Lagrange from the first argument in this situation. Your Euclidean algorithm/ minimal argument is basically exactly how one proves that subgroups of cyclic groups are cyclic – it is then pretty easy to prove that you have Lagrange for the cyclic groups so I suppose there is some similarity. Beyond that I guess they are intrinsically different.
October 24, 2007 at 10:16 am |
The second proof generalises to (for example) the quaternions, but I can’t see how the first proof would. More convincingly (to me), the first proof also shows that the group is cyclic, whereas the second proof doesn’t. I don’t think I’m missing some small variation of the second proof that would show this, because the transliteration of the second proof to the quaternions certainly couldn’t.
But I’m not sure which subset, if any, of those observations really shows that the proofs are different.
October 25, 2007 at 6:29 pm |
Simon, I don’t think I understand what you are saying about quaternions. For instance, could be the group
could be the group  , which is not cyclic. The second proof would break down because there are more than eight 8th roots of unity, and the first hardly gets started. But perhaps you had a different generalization in mind.
, which is not cyclic. The second proof would break down because there are more than eight 8th roots of unity, and the first hardly gets started. But perhaps you had a different generalization in mind.
I also don’t quite understand what it means to say that the second proof doesn’t show that the group is cyclic: if it shows that it’s the group of th roots of unity then surely it does.
th roots of unity then surely it does.
October 25, 2007 at 7:43 pm |
Sorry – the “generalization” I had imprecisely in mind was just that consists of
consists of 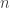 th roots of unity, not that it is all of them, which isn’t a generalization of the result you gave.
th roots of unity, not that it is all of them, which isn’t a generalization of the result you gave.
I think the first proof shows in passing, as part of its argument, that the group is cyclic, whereas with the second proof, you have to go back at the end and look at the group you’ve proved you have, and check that it’s cyclic. I’m not sure whether that’s a real distinction between the proofs. My rather poor point about the quaternions was just that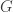 needn’t be cyclic there, so there can’t be any generalization of the first proof there that uses some other definition of minimal element. Now that I’ve looked at some of your web pages, I see that I was thinking vaguely along the lines of “quaternions are another model for the complex numbers”, in a way slightly reminiscent of your page about why it isn’t obvious that the integers are bounded in the reals.
needn’t be cyclic there, so there can’t be any generalization of the first proof there that uses some other definition of minimal element. Now that I’ve looked at some of your web pages, I see that I was thinking vaguely along the lines of “quaternions are another model for the complex numbers”, in a way slightly reminiscent of your page about why it isn’t obvious that the integers are bounded in the reals.
November 29, 2007 at 5:07 am |
I’m surprised by the amount of insight about algebraic number theory that i gained reading your proof of the irrationality of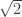 , i mean it really helped me to better understand many things that i was supposed to already know.
, i mean it really helped me to better understand many things that i was supposed to already know.
Actually the first two proofs are quite similar if you think about valuations: a valuation is a multiplicative function from a field to that respects the triagular inequality, ie
that respects the triagular inequality, ie  and
and 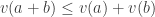 , and
, and  only if
only if 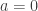 . It can be proved that all such valuations over the rational number are (up to equivalence) the usual absolute value (
. It can be proved that all such valuations over the rational number are (up to equivalence) the usual absolute value (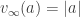 ) and given by prime numbers (
) and given by prime numbers (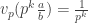 , where
, where  and
and  are prime with
are prime with  ), so they can be thought of as a suitable generaliation of prime numers and ideals, providing additionally a “prime at infinity”. All valuations share important properties, for instance they induce a topology with respect to which you can take the completion, etc.
), so they can be thought of as a suitable generaliation of prime numers and ideals, providing additionally a “prime at infinity”. All valuations share important properties, for instance they induce a topology with respect to which you can take the completion, etc.
In the first proof of the irrationality of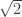 , you are taking a fraction
, you are taking a fraction  where
where  and
and  minimize the valuation at the prime 2 (by dividing the numerator and denominator by the biggest common power of 2), and you get an absurd because
minimize the valuation at the prime 2 (by dividing the numerator and denominator by the biggest common power of 2), and you get an absurd because  cannot possibly be equal to
cannot possibly be equal to  . In the second proof, you are choosing
. In the second proof, you are choosing  and
and  with smallest absolute value (and so smallest valuation at
with smallest absolute value (and so smallest valuation at  ), and then apply a tranformation (an element of
), and then apply a tranformation (an element of 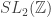 ) that leaves the value of the fraction, supposed to be equal to
) that leaves the value of the fraction, supposed to be equal to 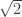 , unchanged, but decreases the valuation at
, unchanged, but decreases the valuation at  of the denominator, absurd by minimality. So, by what i’m understanding, most of the difference in the proofs comes by how the “non-archimedean” valuation at 2 and the “archimedean” one at
of the denominator, absurd by minimality. So, by what i’m understanding, most of the difference in the proofs comes by how the “non-archimedean” valuation at 2 and the “archimedean” one at  work, possibly an experienced number theorist may give us a better explaination of this fact.
work, possibly an experienced number theorist may give us a better explaination of this fact.
December 17, 2007 at 12:26 am |
Hi,
Can’t leave it unsaid that the second proof mentioned for the irrationality of $\sqrt{2}$ can be seen in a beautiful manner:
Take an actual triangular piece of paper of sizes p,p,q (assuming $p^2=2q^2$). You can now fold one of the sides on the diagonal, and get yourself a smaller triangle of sizes $p-q,p-q,2q-p$, revealing that $2(p-q)^2=(2q-p)^2$, and contradicting the minimality of $p,q$ if you assumed that in advance.
January 1, 2008 at 8:41 am |
Even more fundamentally, I have often reflected on the assertion that two mathematical statements are equivalent. Certainly if one proves that A is equivalent to B, where neither A or B is known to be true, the statement has practical value in that if one resolves the validity of one of the statements she also resolves the validity of the other. However one often finds that an author remarks that two statements known to be true are equivalent. The first example that comes to mind is: “The Prime Number Theorem is equivalent to the non-vanishing of the zeta function on the line Re(s)=1.”
So what does this mean? One might say that this means that if we assume the first we can prove the second and vice verse. But along these lines any two true statements are equivalent. I would protest this by saying that “The Pythagorean theorem is equivalent to the Prime Number Theorem.” Now one might try to correct this by saying that we mean that A and B are equivalent if the proof of B uses A and the proof of A uses B. But, in the Prime Number Theorem example, certainly there are proofs of the Prime Number Theorem that do not make use of the fact that Re(s)=1. Now if I had tried to point to an example (say the Selberg-Erdos “Elementary” proof, or Wiener’s using his Tauberian Theorem) someone might dive into a discussion about how the zeta function is really lurking in the background of these. But even if someone presented a case that every known proof of the prime number theorem relied on that fact that the zeta function doesn’t vanish on the line Re(s)=1, this certainly doesn’t imply that there doesn’t exist a proof the proceeded without use of the fact. Moreover while I’m not sure what we do mean when we say “A is equivalent to B” I’m pretty sure it should be a mathematical assertion and not a statement about the literature in existence on the result.
March 8, 2008 at 7:18 am |
I don’t know if the following two ways to explain the coverup method for partial fraction decomposition are “interestingly different” or “based on the same underlying idea”. I would like to know.
Here is an elementary explanation:
Multiply both sides by ,
,
By setting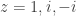 , we get
, we get
Now here is a complex explanation:
Consider
Where is a closed contour to be determined.
is a closed contour to be determined.
We know
Set be a circle of radius
be a circle of radius  around
around 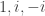 respectively, and use the Cauchy’s integral formula. Again, by the same process, we get:
respectively, and use the Cauchy’s integral formula. Again, by the same process, we get:
May 7, 2008 at 12:17 pm |
[…] Gowers asks When are two proofs essentially the same? For example, it is often possible to convert a standard inductive proof into a proof by […]
May 13, 2008 at 12:48 am |
A good problem to think of in this context would be the classic theorem
“Whenever a rectangle is tiled by rectangles each of which has at least one integer side, then the tiled rectangle has at least one integer side.”
Wagon offers 14 different proofs in “Fourteen proofs of a result about tiling of a rectangle” and he even classifies them according to how they generalize…
http://www.jstor.org/stable/2322213?seq=1
August 7, 2008 at 4:16 am |
I seem to have missed the bulk of the good discussion on this, but this is an issue that has been very much on my mind lately. Awhile ago, I considered two different proofs for the general form of a homogeneous linear recurrence: ordinary generating functions and partial fraction decomposition vs. the Jordan normal form theorem. Whether these two proofs are essentially equivalent has been bothering me for some time. They are sufficiently similar that I suspected for awhile that the first proof can in fact be adapted to a proof of the Jordan normal form theorem, but when I tried to actually write such a proof I couldn’t quite make the jump. This is either because I haven’t tried hard enough or because the second proof offers something “extra.” I think what’s going on is that partial fraction decomposition is essentially a special case of the Jordan normal form theorem (in particular, on companion matrices), but again, I’m not sure. I’d be very glad if anyone could clarify my ignorance on this matter!
More generally, I think Joe brings up a very good point: the definition of “proof homotopy” can be contingent on the current state of mathematics as opposed to anything that could be considered an independent truth. If, for example, two proofs of a result like the Fundamental Theorem of Algebra come from two distinct branches of mathematics and do not appear to relate easily to each other, then perhaps the reason they appear so different is that some deep correspondence between those two branches has not yet been uncovered, and this hypothetical correspondence would reveal those two proofs as essentially the same by placing them in context we don’t yet have. So I guess what I’m suggesting is that if a result appears to have genuinely distinct proofs, then perhaps we do not really understand it!
September 4, 2008 at 2:41 am |
Again I’m late to this discussion because I only just discovered it, but I agree with Kenny that although proof theorists have studied a variety of notions of proof equivalence, they do not come anywhere near to capturing what we intuitively mean by “these two proofs are essentially the same.” So while it’s a very important mathematical activity to think about whether two particular proofs of an important mathematical result are essentially the same, I think it’s highly premature to expect to be able to formalize the notion.
The situation is somewhat better with “these two theorems are equivalent.” As Terry said, in reverse mathematics one posits a very weak “base theory” (RCA_0 is a common choice) and then sometimes you can show that two theorems A and B are equivalent in the sense that (1) both A and B are independent of the base theory and (2) their equivalence can be proved in the base theory. There are many successful examples of this. On the other hand, it doesn’t always capture our intuitions perfectly either. Intuitively one might argue that Sperner’s lemma and Brouwer’s fixed-point theorem are equivalent, but Sperner’s lemma is provable in RCA_0 while Brouwer’s theorem isn’t.
By the way, here’s another proof of the irrationality of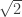 . Let
. Let  be the smallest positive integer such that
be the smallest positive integer such that 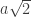 is an integer. Let
is an integer. Let  . Then
. Then 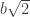 is an integer yet
is an integer yet  is a strictly smaller positive integer than
is a strictly smaller positive integer than  ; contradiction. Is this the same proof as one of those already given? Note that this proof immediately generalizes to show that the square root of an integer
; contradiction. Is this the same proof as one of those already given? Note that this proof immediately generalizes to show that the square root of an integer  is either an integer or an irrational number (i.e., it can’t be a non-integral rational number), if you let
is either an integer or an irrational number (i.e., it can’t be a non-integral rational number), if you let  . The traditional proof of the irrationality of
. The traditional proof of the irrationality of 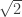 does not generalize so quickly without a detour into unique factorization or something.
does not generalize so quickly without a detour into unique factorization or something.
December 28, 2008 at 1:22 am |
[…] to discuss and that are better discussed here. I have already written about one of my favourites: when are two proofs essentially the same? Another that is closely related is the question of how it can be that two mathematical statements […]
December 28, 2008 at 10:53 pm |
To what extent does the Curry-Howard correspondence capture “sameness” of proof?
It would say that two proofs are the same if they induce the same function between the proposition types.
Tom
January 21, 2010 at 2:40 pm
I think the curry-howard-isomorphism is exactly the way one has to look at this problem. The Terms extracted from proofs are all type-correct and thus have a normal-form which can be calculated by beta-eta-evaluation.
March 22, 2009 at 5:01 pm |
I just started to read Gowers’s and Terry’s blogs a few days ago, and find them very interesting. Sorry to come much too late with the following remark: about the 2 proofs of uncountability of the reals in, say,![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
– Cantor’s original proof, as quoted by Jonah Sinick above, is taking the real interval as they are i.e. a compact and complete metric space, and then detects at least one missing (i.e. not contained in the counting) real number by sequential compactness i.e. Bolzano-Weierstrass. Viewing the real numbers in binary expansion with base 2, the two binary representations of all binary rationals coincide, e.g.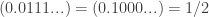
– Whereas the diagonal argument models the reals set-theoretically as a space of sequences of digits: In the example of base 2, the sequences (0,0,1,1,1,..) and (0,1,0,0,0,…) are not the same. This is no coincidence as the topology is now very different: taking a natural base , the space of sequences of natural numbers
, the space of sequences of natural numbers 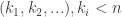 has the desired cardinality
has the desired cardinality  and is a compact and totally disconnected space
and is a compact and totally disconnected space  in the product (Tychonoff) topology. For base
in the product (Tychonoff) topology. For base  this space of 0-1 sequences is homeomorphic to the classical Cantor set.
this space of 0-1 sequences is homeomorphic to the classical Cantor set.
Both spaces are compact, metrizable and complete in their metric topology. But they are far from being homeomorphic: the real interval![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is connected, and the Cantor set is totally disconnected.
is connected, and the Cantor set is totally disconnected.
Thus the a priori purely set-theoretical statement of uncountability of the reals is proven by two methods familiar from the categories of topological and metric spaces, but based on two models of the set of reals which are topologically quite different.
November 1, 2009 at 9:28 am |
Identity of proofs is a booming topic in proof theory, apparently. I don’t understand it at all, but here the blurb of a paper I looked at:
What Is a Logic, and What Is a Proof?
Lutz Straßburger
AbstractI will discuss the two problems of how to define identity between logics and how to define identity between proofs. For the identity of logics, I propose to simply use the notion of preorder equivalence. This might be considered to be folklore, but is exactly what is needed from the viewpoint of the problem of the identity of proofs: If the proofs are considered to be part of the logic, then preorder equivalence becomes equivalence of categories, whose arrows are the proofs. For identifying these, the concept of proof nets is discussed.
23 October 2006
Logica Universalis—Towards a General Theory of Logic, pp. 135–152, Birkhäuser, 2007
PDF of the paper is here: http://www.lix.polytechnique.fr/~lutz/papers/WhatLogicProof.pdf
Site that I got this link from, that has a ton of related stuff: http://alessio.guglielmi.name/res/cos/index.html
June 3, 2010 at 10:12 am |
[…] definir que es que dos pruebas sean la misma o no (por una discusión sobre esto, recomiendo este post). Luego de dar la prueba, voy a comentar porque me parece (al menos un poco) […]
September 18, 2010 at 10:36 pm |
[…] I have no pressing reason for asking the question I’m about to ask, but it is related to an old post about when two proofs are essentially the same, and it suddenly occurred to me while I was bathing my two-year-old […]
January 17, 2012 at 10:00 pm |
[…] and infinite cardinals equally well. (For the finite case it looks that Cantor’s proof is genuinly different than the ordinary proof by […]
June 23, 2014 at 10:23 pm |
This discussion is just great! So full of interesting ideas to think about.
Anyway i was wondering, does the following happen in research?:that the backward exercise of recognising when two proofs are or not equivalent(and in which meaning they can be) seem possibly useful in forward direction of selecting a strategy of a proof when one has to consider many possible ways, and has already found that some of them are failing, and here can be useful to efficiently detect wich apparently new strategy is in some sense equivalent to the failing ones(…meaning that if this would work, then it would give a proof, basically equivalent to the one you’d obtained from the failing strategy wich is incorrect), and so has to be rejected without actually doing it.
It seems that the trade on could be of becoming much faster in discarding a lot of useless approach, but the trade off can lie in the ambiguity of the concept of equivalence:maybe the seemingly equal approach had some very little detail that turned in a different picture, and one was unable to see this from the high level, and so loose an actual proof(…or some unexpected results).
Are there example of this from your research?(i’m an almost graduate student…so i’ve just example from my problem solving session, that sounds pretty silly).
May 9, 2016 at 7:30 pm |
[…] There are infinitely many non-isomorphic proofs of the infinitude of […]
January 4, 2018 at 4:32 am |
sure indeed these appear as say prof dr mircea orasanu and prof horia orasanu
March 25, 2018 at 6:31 am |
the above question is essentially for more other situations of prime numbers as say prof dr mircea orasanu and prof horia orasanu
June 7, 2018 at 6:08 pm |
Hi, the question of measuring the “closeness” of two proofs has already puzzled Hilbert, in his “lost” 24th problem. Worth a read!
January 12, 2019 at 4:16 am |
here we mention that the above shown that the LEBESGUE and LEGENDRE theorems are equivalent observed prof drd horia orasanu and prof dr mircea orasanu in many situations
January 22, 2019 at 7:01 pm |
with confrontation of problem and thus situation with prof dr mircea orasanu and prof drd horia orasanu and are considered important aspects for MONGE the relations that appear other elements surface generated by a plane curve (the generatrix) the plane of which rolls without slipping on a developable surface, called rolling surface (which is therefore the envelope of the plane containing the generatrix and the common polar developable of the parallels).